
著者:李丹
出典:ウォール・ストリート・ジャーナル
OpenAI の今年最も期待されていた製品が登場しました。
8月7日木曜日(東部時間)、OpenAIは次世代のフラッグシップ人工知能(AI)モデル「GPT-5」のリリースを発表しました。これはOpenAI初の「オールインワン」AIシステムであり、Oシリーズモデルの推論能力とGPTシリーズモデルの迅速な応答能力を融合しています。
OpenAIのCEO、サム・アルトマン氏は、新モデル発表会でGPT-5を高く評価し、「世界最高のモデル」であり、以前のモデルと比べて「大幅なアップグレード」だと評した。また、GPT-5のリリースは、OpenAIにとって汎用人工知能(AGI)の実現に向けた「重要な一歩」となると述べた。
OpenAIは、GPT-5が複数のベンチマークで優れた性能を達成し、プログラミング、数学、健康などの分野で最先端レベルに到達したと発表しました。GPT-5はSWE-bench Verifiedコードテストで74.9%の精度を達成し、火曜日にリリースされたAnthropicの新モデル「Claude Opus 4.1」をわずかに上回りました。GPT-5は幻覚検出能力も大幅に向上し、誤検出率はわずか4.8%で、前身のGPT-4oの20.6%を大幅に下回りました。
今週の木曜日から、GPT-5 はすべての無料 ChatGPT ユーザーと Plus、Pro、Team サブスクリプションの有料ユーザーにデフォルトのモデルとして提供されるようになり、1 週間以内に Enterprise および Edu 有料プランでもリリースされる予定です。
GPT-4oと同様に、GPT-5の無料版と有料版の違いは使用量にあります。Plusユーザーはより広い使用量制限を利用でき、Proユーザーは無制限の使用と拡張版であるGPT-5 Proを利用できます。無料ユーザーの場合、完全な推論機能の利用には数日かかる場合があります。無料ユーザーがGPT-5の使用量制限に達した場合、OpenAIはより小型のGPT-5 miniに切り替えます。
OpenAIは水曜日、ChatGPT製品を米国連邦政府機関に年間1ドルというわずかな料金で提供すると発表しました。具体的には、セキュリティとプライバシー機能が強化されたChatGPTのエンタープライズ版を提供します。
OpenAIはGPT-5を正式に発表したばかりで、Microsoftは木曜日から365 Copilot、Copilot、GitHub Copilot、Azure AI Foundryプラットフォームを含む広範な製品ポートフォリオにGPT-5を統合し、MicrosoftのエンタープライズおよびコンシューマーユーザーがGPT-5の高度な推論機能とプログラミングの利点をすぐに体験できるようにすると発表しました。
GPT-5はプログラミング、クリエイティブライティング、健康の3つの大きな利点を持っています
OpenAI の GPT5 の発表は、GPT-5 が OpenAI の「最もスマートで、最も高速で、最も実用的なモデルであり、専門家レベルの知能を誰もが利用できるようにするための思考能力が組み込まれている」という説明から始まります。
OpenAI によると、OpenAI の「最も強力なモデル」である GPT-5 は、3 つの主要分野で大幅な改善を達成しました。
まず、プログラミング能力です。GPT-5はOpenAIが開発したこれまでで最も強力なコーディングモデルであり、複雑なフロントエンドの生成と大規模なコードベースのデバッグに優れています。1つのプロンプトで、美しくレスポンシブなウェブサイト、アプリ、ゲームを作成できます。初期テスターは、スペース、タイポグラフィ、ホワイトスペースなどのデザイン選択における改善に気づきました。
GitHubから実際のコーディングタスクを取得するベンチマークであるSWE-bench Verifiedでは、GPT-5は思考後の最初の試行で74.9%の精度を達成し、OpenAIの推論モデルo3の69.1%やGPT-4oの30.8%を上回りました。
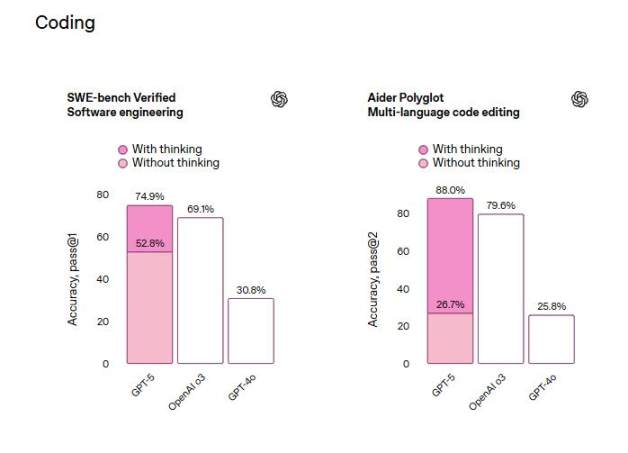
コメンテーターは、これは GPT-5 が火曜日にリリースされた Anthropic の Claude Opus 4.1 や、SWE-bench Verified テストでそれぞれ 74.5% と 59.6% のスコアを獲得した Google DeepMind の Gemini 2.5 Pro よりもわずかに優れたパフォーマンスを発揮することを意味すると指摘した。
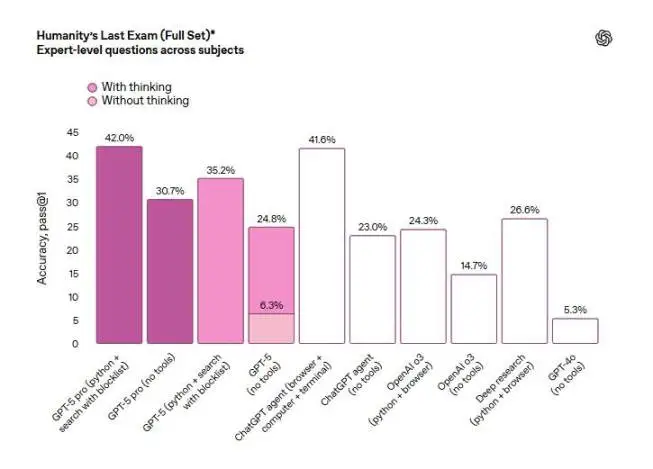
しかし、数学、人文科学、自然科学の様々な分野における専門家レベルのモデルのパフォーマンスを測定する「Humanity's Last Exam」テストでは、推論機能を拡張したGPT-5の強化版であるGPT-5 Proは、ツール使用時に42%のスコアを獲得しました。これは、44.4%を獲得したxAIモデルGrok 4 Heavyよりもわずかに低いスコアでした。
アルトマン氏は、GPT-5は「アンビエントコーディング」と呼ばれる、オンデマンドでソフトウェアアプリ全体を起動するのに特に優れていると述べた。これは、AIを使用して自然言語プロンプトに基づいて機能コードを生成し、開発をスピードアップするものだ。
例えば、OpenAIの研究者たちは、英語圏のユーザーがフランス語を学習するのに役立つウェブアプリを作成するためにGPT-5が必要であることを実証しました。アプリは魅力的なテーマを持ち、フラッシュカード、クイズ、定番のスネークゲーム、そして毎日の学習進捗を追跡する機能を備えている必要があります。
研究者たちは同じプロンプトワードを2つのGPT-5ウィンドウに入力し、数分後には2つの異なるアプリが生成されました。OpenAIの責任者は、これらのアプリには「いくつか欠陥がある」と述べていますが、ユーザーは背景の変更やタブの追加など、AIが生成したソフトウェアを個人の好みに合わせて調整できます。
創作において、GPT-5は、押韻のない弱強五歩格や自然な流れの自由詩といった複雑なライティングタスクを処理できます。OpenAIのChatGPT担当副社長であるニック・ターリー氏は、GPT-5は創作タスクにおいて「より優れたセンス」とより自然な反応を示したと述べています。

健康相談は改善すべき3番目の重要な分野です。
GPT-5は、潜在的な健康問題をより積極的に警告し、ユーザーが医療結果を解釈するのに役立ちますが、OpenAIはChatGPTが医療専門家の代わりになるものではないことを強調しています。
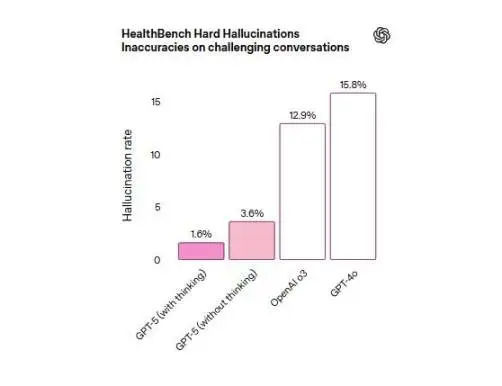
HealthBench Hard Hallucinations と呼ばれるテストでは、思考型 GPT-5 の幻覚エラー率はわずか 1.6% で、それぞれ 15.8% と 12.9% のエラー率を示した GPT-4o モデルと o3 モデルよりも大幅に低くなりました。
新しい安全訓練モデルは幻覚の可能性を大幅に低減します
OpenAIは、GPT-5は以前のモデルよりも信頼性が高く実用的であると主張しています。現実世界の質問に正確に答えることができ、幻覚を経験する可能性が大幅に低くなります。
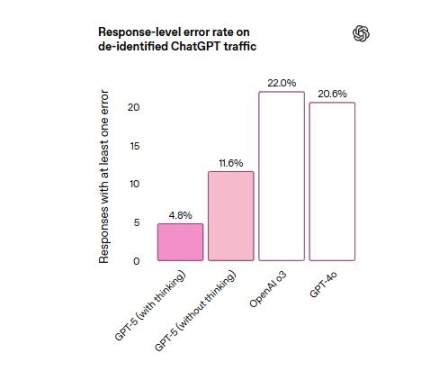
ChatGPTの本番環境トラフィックを表す匿名プロンプトでWeb検索を実行したところ、GPT-5の回答はGPT-4oの回答よりも事実誤認を含む可能性が約45%低くなりました。さらに、GPT-5の回答はo3の回答よりも事実誤認を含む可能性が約80%低くなりました。下の図に示すように、GPT-5の回答のエラー率はわずか4.8%でしたが、GPT-4oの回答では20.6%、o3の回答では22%でした。
OpenAIはまた、GPT-5に「セーフコンプリーション」と呼ばれる新しい安全な学習形式を導入したことを発表しました。これは、安全な範囲内で可能な限り最も役立つ回答を提供するようにモデルを学習させます。場合によっては、ユーザーの質問に部分的に答えたり、高レベルの回答のみを提供したりすることがあります。
拒否が必要な場合、トレーニングされた GPT-5 はユーザーに拒否の理由を透過的に通知し、安全な代替手段を提供します。
制御された実験と OpenAI の製品モデルの両方で、安全性の完了に対するこのアプローチはより微妙で、二重使用の問題をより適切に導き、あいまいな意図に対する堅牢性を高め、不必要な過剰拒否を減らすことがわかりました。
「GPT-5は、タスクが不可能な場合を認識し、推測を避け、以前のモデルよりも明確に制限を説明するようにトレーニングされており、根拠のない主張が減っています」とOpenAIのポストトレーニング責任者、ミシェル・ポクラス氏は述べた。
ChatGPTチャットプリセットの4つのオプションパーソナリティの紹介
OpenAIは、GPT-5のコマンド実行性能が向上し、カスタムコマンドの実行能力もそれに応じて向上したと主張しています。OpenAIは、すべてのChatGPTユーザー向けに、4つのプリセットパーソナリティを備えた新しい研究プレビュー版をリリースする予定です。
最初の 4 つの性格オプション (シニック、ロボット、リスナー、オタク) はすべてオプションであり、ユーザーは ChatGPT とユーザーのコミュニケーション スタイルに合わせていつでも設定で調整できます。
当初はテキスト チャットで利用可能でしたが、4 つのパーソナリティが音声チャットに拡張され、ユーザーはカスタム プロンプトを記述することなく、ChatGPT とのやり取りをカスタマイズできるようになります。簡潔でプロフェッショナルなものから、気配りのあるサポート的なもの、あるいは少し皮肉なものまで、さまざまなやり取りが可能です。
OpenAIによれば、これらの新しい性格はすべて、媚びへつらう行動を減らすという当社の内部評価基準を満たしているか、それを上回っているという。
アルトマン氏はこの歴史的な進歩を称賛したが、GPT-4 を使用した結果は非常に貧弱だった。
木曜日のブリーフィングで、アルトマン氏はGPT-5を高く評価し、AGIへの道のりにおける重要なマイルストーンと位置付けました。彼は次のように述べました。
「歴史上、GPT-5のようなものが登場することは考えられなかったでしょう。」「あらゆる分野の専門家と話しているような感覚を覚えるのは初めてです。」
アルトマン氏はブリーフィング中にGPT-4を酷評する一方で、GPT-5を称賛するほどでした。彼は次のように述べています。
「GPT-4をもう一度使ってみましたが、ひどいものでした。」
GPT-5は、会話の種類、複雑さ、ツール要件に基づいて、迅速な対応を行うか、深い「思考」を行うかを自動的に判断するリアルタイムルーターを備えた統合システムアーキテクチャを採用しています。これにより、ユーザーが適切な設定を選択する必要がなくなり、ChatGPTの使いやすさが向上します。
経済的に価値のあるタスクを対象とした社内ベンチマークテストにおいて、GPT-5は推論モードを使用し、法律、物流、営業、エンジニアリングなど40以上の職種において、約半数のケースでエキスパートレベル以上のパフォーマンスを発揮しました。OpenAIの副社長であるニック・ターリー氏は、「このモデルは本当に優れている」と述べています。
アルトマン氏はGPT-5の使用を、博士号を持つ専門家チームを手元に置いているようなものだと例えました。「多くの新しい分野では、アイデアは限られているものの、それを実際に実行する能力が欠けているのです」と付け加えました。
マイクロソフトは主導権を握るために完全統合
GPT-5のリリース当日、Microsoftは幅広い製品ラインへの統合を発表しました。エンタープライズアプリケーションにおいては、Microsoft 365 CopilotがGPT-5を活用し、複雑な問題への対応、長時間の会話における集中力の維持、ユーザーのコンテキスト理解を向上させます。エンタープライズユーザーは、推論機能を使用してメール、ドキュメント、ファイルを処理できます。
一般ユーザー向けには、Microsoft Copilot の新しいインテリジェント モードが GPT-5 を活用し、ユーザーが最適なソリューションを見つけられるよう支援します。ユーザーは copilot.microsoft.com または Windows、Mac、Android、iOS デバイス上の Copilot アプリから、GPT-5 を無料で体験できます。
開発者は、GitHub CopilotとVisual Studio Codeを通じてGPT-5のサポートにアクセスし、コードの作成、テスト、デプロイを行うことができます。すべてのGPT-5モデルはAzure AI Foundryプラットフォームで利用可能になり、各タスクの複雑さ、パフォーマンス要件、コスト効率に基づいて最適なモデルを選択するAI搭載のモデルルーターも利用できます。
MicrosoftのAIレッドチームは、厳格なセキュリティプロトコルを用いてGPT-5推論モデルをテストしました。その結果、このモデルは、マルウェア生成や不正行為の自動化といった様々な攻撃モードにおいて、OpenAIのこれまでのモデルの中で最も強力なAIセキュリティ構成の一つであることが示されました。



