
強化学習 × Web3 の本当のチャンスは、OpenAI の分散バージョンを複製することではなく、「インテリジェントな生産関係」を書き換えることにあります。
著者: 0xjacobzhao
この独立調査レポートは、IOSG Venturesの支援を受けて作成されました。調査と執筆プロセスは、Sam Lehman氏(Pantera Capital)の強化学習に関するレポートに着想を得ました。貴重なご意見をいただいたBen Fielding氏(Gensyn.ai)、Gao Yuan氏(Gradient)、Samuel Dare氏とErfan Miahi氏(Covenant AI)、Shashank Yadav氏(Fraction AI)、Chao Wang氏に感謝申し上げます。客観性と正確性を追求しておりますが、一部の見解には主観的な判断が含まれており、偏りがある可能性がありますので、ご理解のほどよろしくお願いいたします。
人工知能は、「パターンフィッティング」を主眼とした統計学習から、「構造化推論」を中心とした能力システムへと移行しつつあり、学習後の学習の重要性が急速に高まっています。DeepSeek-R1の登場は、大規模モデル時代における強化学習のパラダイムシフトを象徴するものであり、業界のコンセンサスにつながっています。すなわち、事前学習は汎用モデル構築の基盤となり、強化学習はもはや単なる価値調整ツールではなく、推論チェーンと複雑な意思決定能力の質を体系的に向上させることが証明され、知能を継続的に向上させるための技術的道筋へと徐々に進化しています。
一方、Web3は、分散型コンピューティングネットワークと暗号インセンティブシステムを通じて、AIの生産関係を再構築しています。ロールアウトサンプリング、報酬シグナル、検証可能なトレーニングといった強化学習の構造要件は、ブロックチェーンのコンピューティングパワーの連携、インセンティブ配分、検証可能な実行と自然に整合しています。本レポートでは、AIトレーニングパラダイムと強化学習技術の原理を体系的に分析し、強化学習×Web3の構造的優位性を示すとともに、Prime Intellect、Gensyn、Nous Research、Gradient、Grail、Fraction AIなどのプロジェクトを分析します。
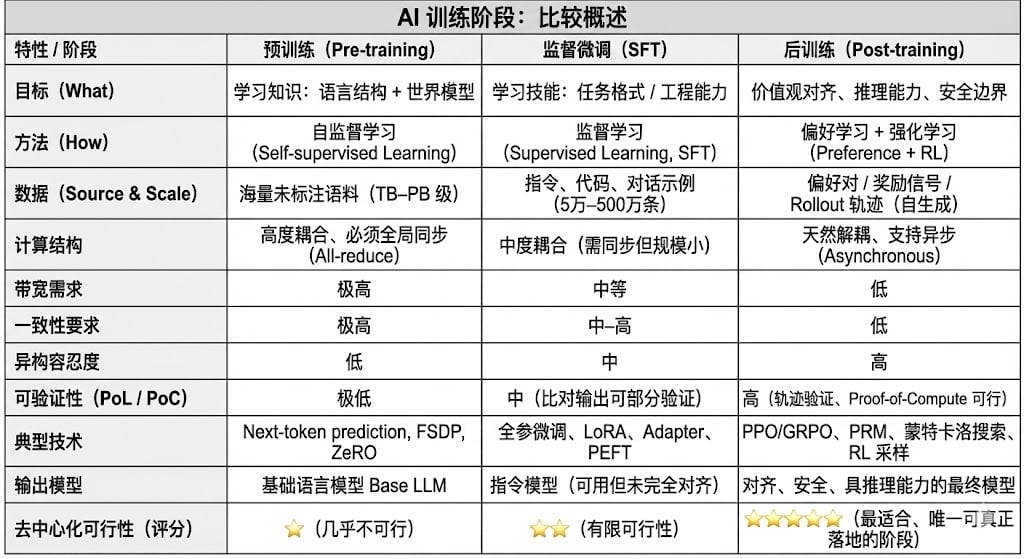
I. AIトレーニングの3つの段階:事前トレーニング、指示の微調整、およびトレーニング後の調整
現代の大規模言語モデル(LLM)の学習ライフサイクル全体は、通常、事前学習、教師あり微調整(SFT)、および事後学習/強化学習(RL)という3つのコアステージに分かれています。これらの3つのステージはそれぞれ、「世界モデルの構築、タスク能力の注入、推論と価値の形成」という機能を果たし、その計算構造、データ要件、検証の難易度によって分散マッチングの度合いが決まります。
事前学習は、大規模な自己教師学習を通じてモデルの言語統計構造とクロスモーダル世界モデルを構築するものであり、LLM機能の基盤となります。この段階では、数千から数万枚のH100画像からなる均質なクラスターに依存し、数兆単位のコーパスをグローバルに同期して学習する必要があり、コストの80~95%を占めます。また、帯域幅とデータ著作権の影響を非常に受けやすいため、高度に集中化された環境で完了させる必要があります。
教師ありファインチューニングは、タスク機能と命令フォーマットを注入するために使用されます。必要なデータ量は少なく、コストの約5~15%を占めます。ファインチューニングは、フルパラメータトレーニングまたはパラメトリック効率的ファインチューニング(PEFT)手法を用いて実行できます。これらの手法の中で、LoRA、Q-LoRA、Adapterが業界で主流の手法です。ただし、勾配同期は依然として必要であり、分散化の可能性は制限されます。
学習後段階は、モデルの推論能力、価値、安全境界を決定する複数の反復的なサブステージで構成されます。手法としては、強化学習システム(RLHF、RLAIF、GRPO)、強化学習を使用しない選好最適化手法(DPO)、プロセス報酬モデル(PRM)などが挙げられます。このステージはデータ量とコストが比較的低く(5~10%)、主にロールアウトとポリシー更新に重点が置かれています。非同期・分散実行を自然にサポートするため、ノードは完全な重みを保持する必要はありません。検証可能な計算とオンチェーンインセンティブを組み合わせることで、オープンで分散化されたトレーニングネットワークを形成でき、Web3に最適なトレーニングステージとなります。
II. 強化学習技術の全体像:アーキテクチャ、フレームワーク、アプリケーション 2.1 強化学習のシステムアーキテクチャとコアコンポーネント
強化学習(RL)は、「環境との相互作用 - 報酬フィードバック - 方策更新」を通じて、モデルが自律的に意思決定能力を向上させるように促します。その中核構造は、状態、行動、報酬、方策からなるフィードバックループと捉えることができます。完全なRLシステムは通常、方策(方策ネットワーク)、ロールアウト(経験サンプリング)、学習者(方策更新)の3つのコンポーネントで構成されます。方策は環境と相互作用して軌道を生成し、学習者は報酬信号に基づいて方策を更新することで、継続的な反復的かつ最適化された学習プロセスを形成します。
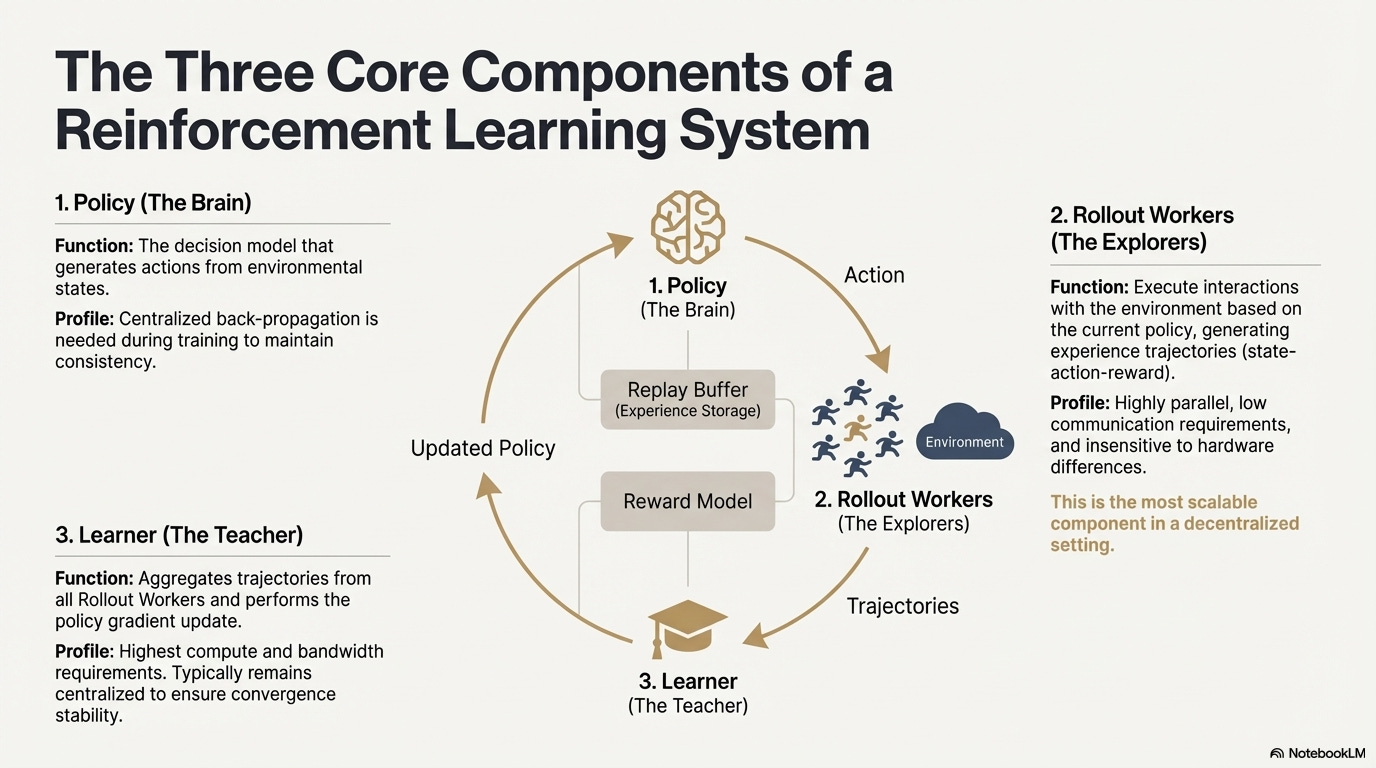
ポリシーネットワーク:環境状態からアクションを生成し、システムの意思決定の中核を担います。学習中は一貫性を維持するために集中的なバックプロパゲーションが必要ですが、推論中は複数のノードに分散して並列実行できます。
ロールアウト:ノードはポリシーに従って環境と相互作用し、状態、アクション、報酬などの軌跡を生成します。このプロセスは高度に並列化されており、通信をほとんど必要とせず、ハードウェアの違いの影響を受けないため、分散環境でのスケーリングに最適なコンポーネントです。
学習器はすべてのロールアウト軌跡を集約し、ポリシー勾配の更新を実行します。これは計算能力と帯域幅に対する要件が最も高いモジュールであるため、収束安定性を確保するために、通常は集中型または軽度集中型の方法で展開されます。
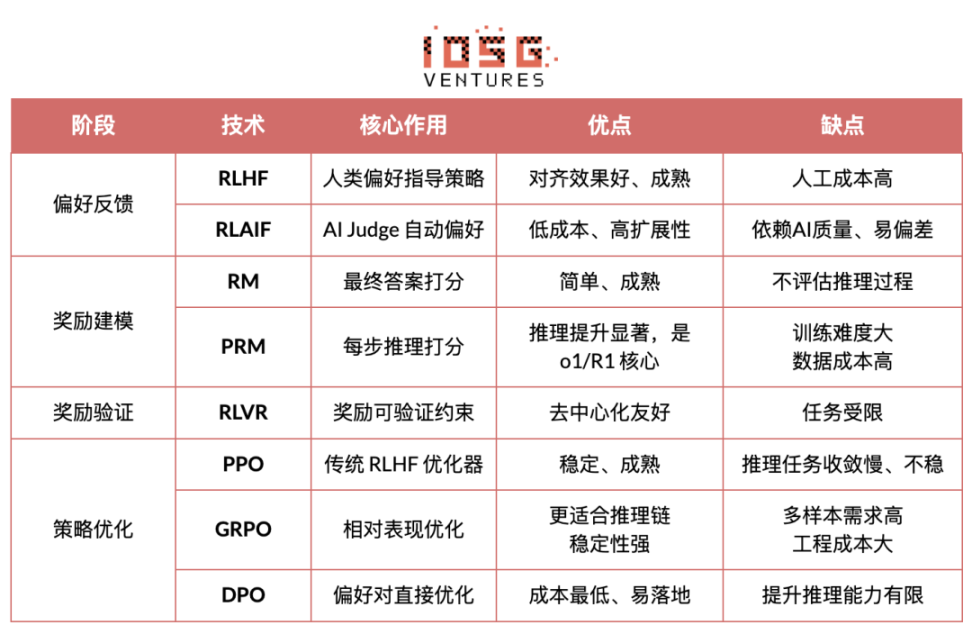
2.2 強化学習段階フレームワーク(RLHF → RLAIF → PRM → GRPO)
強化学習は一般的に 5 つの段階に分けられ、全体的なプロセスは次のようになります。
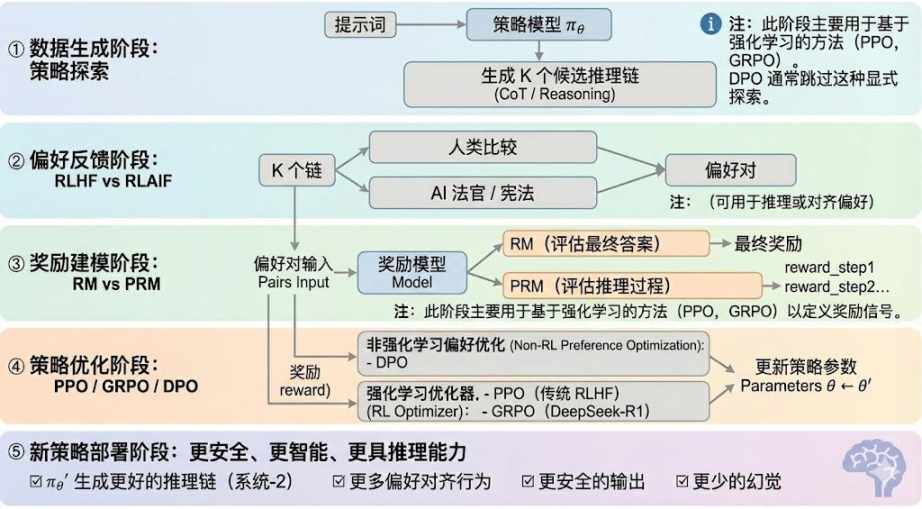
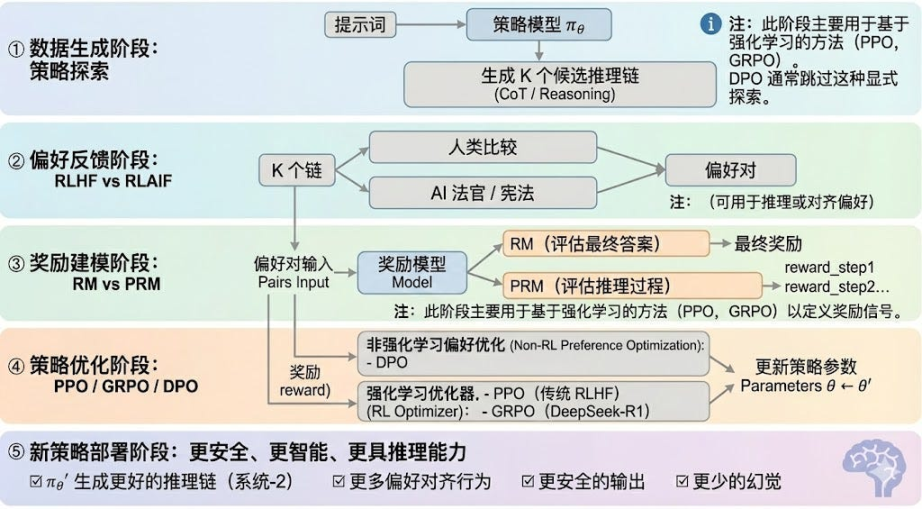
データ生成フェーズ (ポリシー探索): 入力キューが与えられると、ポリシー モデル πθ は複数の候補推論チェーンまたは完全な軌跡を生成し、後続の選好評価と報酬モデリングのサンプル ベースを提供し、ポリシー探索の範囲を決定します。
嗜好フィードバックフェーズ(RLHF / RLAIF):
RLHF(Reinforcement Learning from Human Feedback)は、複数の候補回答、人間の嗜好アノテーション、報酬モデル(RM)のトレーニング、そしてPPO最適化戦略を用いて、モデルの出力を人間の価値観とより一致させます。これは、GPT-3.5からGPT-4への移行における重要なステップです。
RLAIF(AIフィードバックからの強化学習)は、AI判定や憲法ルールを用いた手作業によるアノテーションを置き換え、選好度の獲得を自動化することで、コストを大幅に削減し、スケーラビリティも備えています。Anthropic、OpenAI、DeepSeekといった企業にとって、RLAIFは主流のアライメントパラダイムとなっています。
報酬モデリングフェーズ:選好ベースの報酬モデルは、出力を報酬にマッピングすることを学習します。RMはモデルに「正しい答えとは何か」を教え、PRMはモデルに「正しい推論方法」を教えます。
報酬モデル (RM) は、最終的な回答の品質を評価するために使用され、出力のみにスコアが付けられます。
プロセス報酬モデル(PRM)は、最終的な答えを評価するだけでなく、推論の各ステップ、各トークン、各論理セグメントをスコアリングします。これはOpenAI o1とDeepSeek-R1の主要技術でもあり、本質的にモデルに思考方法を学習させます。
報酬検証フェーズ (RLVR): 報酬シグナルの生成と使用中に「検証可能な制約」を導入して、報酬が可能な限り再現可能なルール、事実、またはコンセンサスから得られるようにすることで、報酬のハッキングやバイアスのリスクを軽減し、オープン環境での監査可能性とスケーラビリティを向上させます。
方策最適化とは、報酬モデルからのシグナルに基づいて方策パラメータθを更新し、より強力な推論能力、より高いセキュリティ、そしてより安定した行動パターンを持つ方策πθ′を得ることです。主流の最適化手法には以下のものがあります。
PPO (近似ポリシー最適化): RLHF の従来のオプティマイザー。安定性に優れていますが、複雑な推論タスクでは収束が遅い、安定性が不十分などの制限に直面することがよくあります。
グループ相対ポリシー最適化(GRPO)は、DeepSeek-R1の中核的なイノベーションです。GRPOは、候補回答グループを単純に順位付けするのではなく、グループ内の優位性の分布をモデル化することで期待値を推定します。この手法は報酬の大きさの情報を保持し、推論チェーンの最適化に適しており、より安定した学習プロセスを実現します。GRPOは、PPO後の深層推論シナリオにおける重要な強化学習最適化フレームワークと考えられています。
DPO(直接選好最適化):強化学習ではない学習後手法。軌道生成や報酬モデル構築は行わず、選好ペアを直接最適化する。低コストで安定しているため、LlamaやGemmaといったオープンソースモデルのアライメントに広く利用されているが、推論能力の向上には寄与しない。
新しいポリシー展開フェーズ:最適化されたモデルは、システム2推論能力の強化、人間またはAIの嗜好に沿った行動、幻覚の発生率の低下、そしてセキュリティの向上を実現します。継続的な反復処理を通じて、モデルは嗜好を学習し、プロセスを最適化し、意思決定の質を向上させ、閉ループを形成します。
2.3 強化学習の産業応用における5つの主要カテゴリー
強化学習は、初期のゲーム理論的知能から、様々な産業における自律的意思決定の中核フレームワークへと進化しました。その応用シナリオは、技術の成熟度と産業への導入状況に基づいて5つの主要なタイプに分類でき、それぞれがそれぞれの方向で重要なブレークスルーをもたらしてきました。
ゲームと戦略システム:これは強化学習(RL)の最も初期の検証分野です。AlphaGo、AlphaZero、AlphaStar、OpenAI Fiveといった「完全情報+明示的報酬」環境において、強化学習は人間の専門家に匹敵、あるいは凌駕する意思決定知能を示し、現代の強化学習アルゴリズムの基礎を築きました。
ロボティクスとエンボディドAI:強化学習(RL)は、ロボットが連続制御、動的モデリング、環境とのインタラクションを通じて、操作、動作制御、クロスモーダルタスク(RT-2やRT-Xなど)を学習することを可能にします。RLは急速に産業化に向けて進んでおり、ロボットの実世界への応用に向けた重要な技術ルートとなっています。
デジタル推論(LLM System-2):強化学習(RL)+PRMは、大規模モデルを「言語模倣」から「構造化推論」へと進化させます。代表的な成果としては、DeepSeek-R1、OpenAI o1/o3、Anthropic Claude、AlphaGeometryなどが挙げられます。その本質は、最終的な答えを評価するだけでなく、推論チェーンレベルで報酬を最適化することです。
科学的発見と数学的最適化 (RL): RL は、ラベルのない複雑な報酬と巨大な検索空間で最適な構造または戦略を追求し、AlphaTensor、AlphaDev、Fusion RL などの根本的な進歩を達成し、人間の直感を超える探索能力を実証しています。
経済意思決定と取引:強化学習は、戦略の最適化、高次元リスク管理、適応型取引システムの構築に用いられます。従来の定量モデルと比較して、不確実な環境下でも継続的に学習できるため、インテリジェントファイナンスの重要な構成要素となっています。
III. 強化学習とWeb3の自然な組み合わせ
強化学習(RL)とWeb3の高い互換性は、両者が本質的に「インセンティブ駆動型システム」であるという事実に起因しています。RLは報酬シグナルに基づいて戦略を最適化しますが、ブロックチェーンは経済的インセンティブに基づいて参加者の行動を調整することで、メカニズムレベルで自然な一貫性を実現します。RLの中核となる要件、すなわち大規模な異種ロールアウト、報酬分配、そして真正性検証は、まさにWeb3の構造的な利点の源泉です。
推論とトレーニングの分離: 強化学習のトレーニング プロセスは、明確に 2 つの段階に分けられます。
ロールアウト(探索的サンプリング):モデルは現在のポリシーに基づいて大量のデータを生成します。これは計算負荷は高いものの、通信量は少ないタスクです。ノード間の頻繁な通信を必要とせず、グローバルに分散されたコンシューマーグレードのGPU上での並列生成に適しています。
更新 (パラメータ更新): 収集されたデータに基づいてモデルの重みを更新します。完了するには高帯域幅の集中ノードが必要です。
「推論とトレーニングの分離」は、分散型の異種コンピューティング パワー構造に自然に適合します。ロールアウトはオープン ネットワークにアウトソーシングし、トークン メカニズムを通じて貢献に応じて決済できますが、モデルの更新は安定性を確保するために集中管理されたままになります。
検証可能性:ZKと学習証明は、ノードが実際に推論を実行しているかどうかを検証する手段を提供し、オープンネットワークにおける誠実性の問題を解決します。コーディングや数学的推論などの決定論的なタスクでは、検証者は回答を確認するだけでワークロードを確認できるため、分散型強化学習システムの信頼性が大幅に向上します。
インセンティブ レイヤーは、トークン ベースのフィードバック生成メカニズムに基づいています。Web3 のトークン メカニズムは、RLHF/RLAIF のプリファレンス フィードバック投稿者に直接報酬を与えることができるため、プリファレンス データ生成は透明性、決済性、許可のないインセンティブ構造を持つことができます。さらに、ステーキングとスラッシュによってフィードバックの品質が制限され、従来のクラウドソーシングよりも効率的で調整されたフィードバック マーケットが形成されます。
マルチエージェント強化学習(MARL)の可能性:ブロックチェーンは本質的に、公開性、透明性、そして継続的に進化するマルチエージェント環境です。アカウント、コントラクト、そしてエージェントは、インセンティブ駆動型の条件下で常に戦略を調整するため、大規模なMARLテストベッドを構築する自然な可能性を秘めています。まだ初期段階ではありますが、公開状態、検証可能な実行、そしてプログラム可能なインセンティブといった特性は、MARLの将来の発展にとって根本的な利点となります。
IV. 古典的なWeb3 + 強化学習プロジェクトの分析
上記の理論的枠組みに基づいて、現在のエコシステムにおける最も代表的なプロジェクトを簡単に分析します。
プライム・インテリクト:非同期強化学習パラダイム
Prime Intellectは、グローバルなオープンコンピューティング市場の構築、トレーニングの障壁の低減、協調型分散トレーニングの促進、そして包括的なオープンソース・スーパーインテリジェンス技術スタックの開発に取り組んでいます。そのエコシステムには、Prime Compute(統合クラウド/分散コンピューティング環境)、INTELLECTモデルファミリー(100億~1,000億以上)、Environments Hub(オープンな強化学習環境センター)、大規模合成データエンジン(SYNTHETIC-1/2)が含まれます。
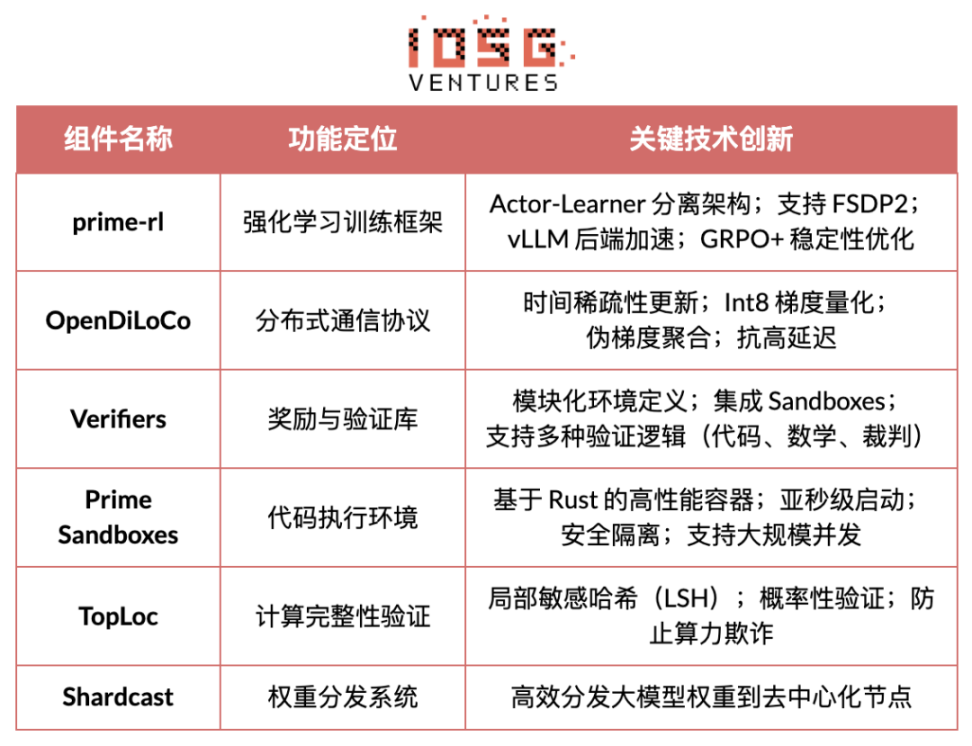
Prime Intellectの中核インフラストラクチャコンポーネントであるprime-rlフレームワークは、非同期分散環境向けに設計されており、強化学習との関連性が非常に高いです。その他のコンポーネントには、帯域幅のボトルネックを克服するためのOpenDiLoCo通信プロトコルと、計算の整合性を保証するTopLoc検証メカニズムが含まれます。
Prime Intellect コア インフラストラクチャ コンポーネントの概要
技術的基礎: prime-rl非同期強化学習フレームワーク
prime-rlは、Prime Intellectの中核となる学習エンジンであり、大規模な非同期分散環境向けに特別に設計されています。アクターと学習器を完全に分離することで、高スループットの推論と安定した更新を実現します。ロールアウトワーカーと学習器は同期的にブロックされなくなり、ノードはいつでも参加または離脱でき、最新の戦略を継続的に取得し、生成されたデータをアップロードするだけで済みます。
アクター(ロールアウトワーカー):モデル推論とデータ生成を担います。Prime Intellectは、アクター側にvLLM推論エンジンを革新的に統合しています。vLLMのPagedAttentionテクノロジーと継続的なバッチ処理機能により、アクターは非常に高いスループットで推論軌跡を生成できます。
学習者(トレーナー):ポリシーの最適化を担当します。学習者は、すべてのアクターが現在のバッチを完了するのを待たずに、共有エクスペリエンスバッファから非同期的にデータを取得し、勾配を更新します。
オーケストレーター: モデルの重みとデータ フローのスケジュールを担当します。
prime-rl の主な革新:
真の非同期性: prime-rl は従来の PPO の同期パラダイムを放棄し、低速ノードを待機せず、バッチ アライメントを必要とせず、いつでも任意の数とパフォーマンスの GPU にアクセスできるようにして、分散 RL の実現可能性の基盤を築きます。
FSDP2とMoEの緊密な統合:FSDP2パラメータスライスとMoEスパースアクティベーションにより、prime-rlは分散環境における数十億のモデルの効率的な学習を可能にします。アクターはアクティブなエキスパートのみを実行するため、GPUメモリと推論コストが大幅に削減されます。
GRPO+(グループ相対ポリシー最適化):GRPOはCriticネットワークを排除し、計算とメモリのオーバーヘッドを大幅に削減し、非同期環境にも自然に適応します。Prime-RLのGRPO+は、安定化メカニズムを通じて、高レイテンシ環境下でも信頼性の高い収束を保証します。
INTELLECT モデル ファミリ: 分散型 RL テクノロジーの成熟度の指標。
INTELLECT-1(10B、2024年10月)は、OpenDiLoCoが3大陸にまたがる異種ネットワークで効率的にトレーニングできることを初めて実証し(通信比率<2%、コンピューティングパワー使用率98%)、地域間トレーニングの物理的な理解を打ち破りました。
INTELLECT-2(32B、2025年4月)は、マルチステップ遅延と非同期環境におけるプライムRLとGRPO +の安定した収束能力を検証し、グローバルなオープンコンピューティングパワーの参加による分散型RLを実現する、最初のPermissionless RLモデルです。
INTELLECT-3(106B MoE、2025年11月)は、120億個のパラメータのみを活性化するスパースアーキテクチャを採用しています。512×H200で学習され、フラッグシップレベルの推論性能(AIME 90.8%、GPQA 74.4%、MMLU-Pro 81.9%など)を達成しています。その総合的な性能は、それ自体よりもはるかに大規模な中央集権型のクローズドソースモデルに匹敵するか、あるいはそれを凌駕しています。
Prime Intellect は、サポート対象のインフラストラクチャ コンポーネントもいくつか構築しました。OpenDiLoCo は、時間的スパース通信と量子化重みの違いにより、地域間のトレーニング通信を数百分の 1 に削減し、INTELLECT-1 が 3 大陸で 98% の使用率を維持できるようにしています。TopLoc + Verifiers は、分散型の信頼できる実行レイヤーを形成し、フィンガープリントとサンドボックス検証をアクティブ化して、推論データと報酬データの信頼性を確保します。SYNTHETIC データ エンジンは、大規模で高品質の推論チェーンを生成し、パイプライン並列処理により、671B モデルがコンシューマー グレードの GPU クラスターで効率的に実行できるようにします。これらのコンポーネントは、分散型 RL におけるデータ生成、検証、および推論スループットのための重要なエンジニアリング基盤を提供します。INTELLECT シリーズは、このテクノロジ スタックが成熟した世界クラスのモデルを生成できることを実証し、分散型トレーニング システムが概念段階から実際のアプリケーション段階に移行していることを示しています。
Gensyn: 強化学習、Swarm、SAPOのコアスタック
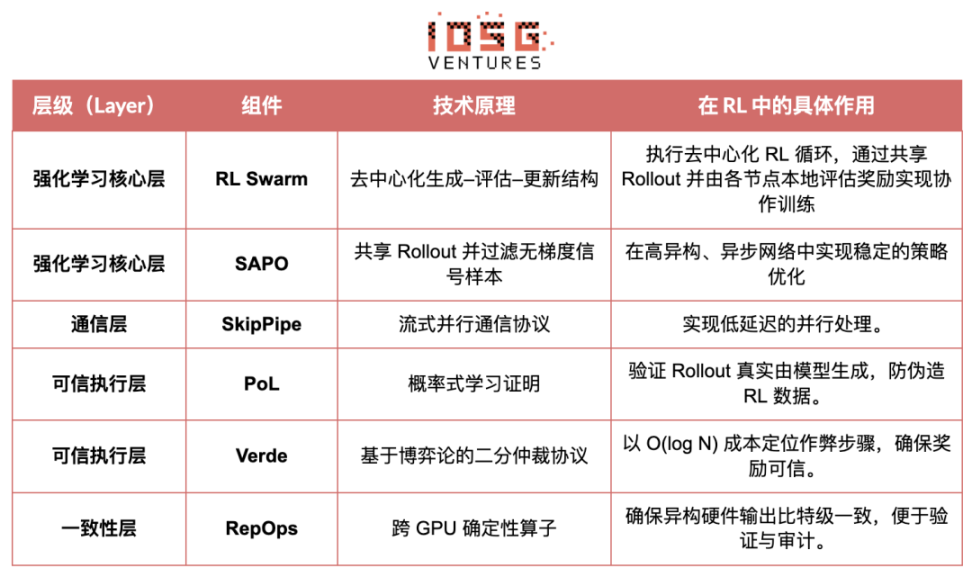
Gensynの目標は、世界中のアイドル状態のコンピューティングパワーを集約し、オープンでトラストレス、そして無限にスケーラブルなAIトレーニングインフラストラクチャを構築することです。その中核となるのは、デバイス間の標準化された実行レイヤー、ピアツーピアの調整ネットワーク、そしてスマートコントラクトを通じてタスクと報酬を自動的に割り当てるトラストレスなタスク検証システムです。強化学習の特性を活用し、GensynはRL Swarm、SAPO、SkipPipeといったコアメカニズムを導入することで、生成、評価、更新の各段階を分離し、異種GPUの「群」を世界中に展開することで集団進化を実現します。最終的には、コンピューティングパワーだけでなく、検証可能なインテリジェンスも提供します。
Gensynスタックの強化学習アプリケーション
RL Swarm: 分散型協調強化学習エンジン
RL Swarmは全く新しい協働モデルを実証しています。これはもはや単純なタスク分散システムではなく、人間の社会学習をシミュレートする分散型の「生成-評価-更新」ループであり、協働学習プロセスに類似した無限ループを備えています。
ソルバー(エグゼキューター):ローカルモデル推論とロールアウト生成を担い、異種ノード間でシームレスに動作します。Gensynは、高スループット推論エンジン(CodeZeroなど)をローカルに統合し、単なる答えではなく、完全な軌跡を出力します。
提案者: カリキュラム学習と同様に、タスクの多様性と適応的な難易度をサポートしながら、タスク (数学の問題、コーディングの問題など) を動的に生成します。
評価者:固定された「判断モデル」またはルールを用いてローカルロールアウトを評価し、ローカル報酬シグナルを生成します。評価プロセスは監査可能であり、悪意のある行為の機会を低減します。
これら 3 つの要素を組み合わせることで P2P RL 組織構造が形成され、集中的なスケジュール設定なしで大規模な共同学習が可能になります。
SAPO:分散型再構成のためのポリシー最適化アルゴリズム:SAPO(Swarm Sampling Policy Optimization)は、「勾配の共有ではなく、ロールアウトの共有と勾配のない信号サンプルのフィルタリング」に重点を置いています。大規模な分散型ロールアウトサンプリングを行い、受信したロールアウトをローカル生成として扱うことで、集中的な調整がなく、ノード間の遅延に大きな差がある環境でも安定した収束を維持します。Criticネットワークに依存し計算コストの高いPPOや、グループ内優位性推定に基づくGRPOと比較して、SAPOはコンシューマーグレードのGPUを極めて低い帯域幅で大規模強化学習の最適化に効果的に活用することを可能にします。
GensynはRL SwarmとSAPOを通じて、強化学習(特に訓練後のRLVR)が分散型アーキテクチャに自然に適していることを実証しています。これは、高頻度のパラメータ同期よりも、大規模で多様なロールアウトに依存するためです。PoLとVerdeの検証フレームワークと組み合わせることで、Gensynは、単一のテクノロジー大手に依存しない、兆パラメータモデルを訓練するための代替パスを提供します。それは、世界中に広がる数百万台の異種GPUで構成される自己進化型スーパーインテリジェントネットワークです。
Nous Research: 検証ベースの強化学習環境「Atropos」
Nous Researchは、分散型で自己進化する認知インフラストラクチャを構築しています。そのコアコンポーネントであるHermes、Atropos、DisTrO、Psyche、World Simは、継続的に進化する閉ループ型インテリジェントシステムとして構成されています。従来の「事前学習-事後学習-推論」という線形プロセスとは異なり、NousはDPO、GRPO、リジェクションサンプリングなどの強化学習手法を採用し、データ生成、検証、学習、推論を継続的なフィードバックループに統合することで、継続的に自己改善する閉ループ型AIエコシステムを構築します。
Nous研究コンポーネントの概要
モデル層:ヘルメスと推論能力の進化
Hermes シリーズは Nous Research の主要なユーザー向けモデル インターフェースであり、その進化は、従来の SFT/DPO アライメントから推論強化学習 (RL) への業界の移行パスを明確に示しています。
Hermes 1~3: 命令整合と初期エージェント機能: Hermes 1~3 は堅牢な命令整合のために低コストの DPO に依存していましたが、Hermes 3 では合成データと新しく導入された Atropos 検証メカニズムを活用しました。
Hermes 4 / DeepHermes: 思考チェーンを通じて System-2 スタイルの遅い思考を重みに組み込み、テスト時間のスケーリングによって数学的パフォーマンスとコード パフォーマンスを向上させ、「拒否サンプリング + Atropos 検証」に依存して高純度の推論データを構築します。
DeepHermes はさらに、配布と展開が難しい PPO の代わりに GRPO を採用し、Psyche 分散 GPU ネットワーク上で推論 RL を実行できるようにして、オープンソース推論 RL のスケーラビリティのためのエンジニアリング基盤を築きました。
Atropos: 検証可能な報酬駆動型強化学習環境
Atroposは、Nous RLシステムの真の要です。ヒント、ツール呼び出し、コード実行、そして複数ターンのインタラクションを標準化されたRL環境にカプセル化し、出力の正しさを直接検証し、決定論的な報酬シグナルを提供することで、高価でスケーラブルでない人間によるアノテーションを置き換えます。さらに重要なのは、分散型トレーニングネットワークPsycheにおいて、Atroposは「審判」として機能し、ノードが真にポリシーを改善しているかどうかを検証し、監査可能な学習証明をサポートし、分散RLにおける報酬信頼性の問題を根本的に解決することです。
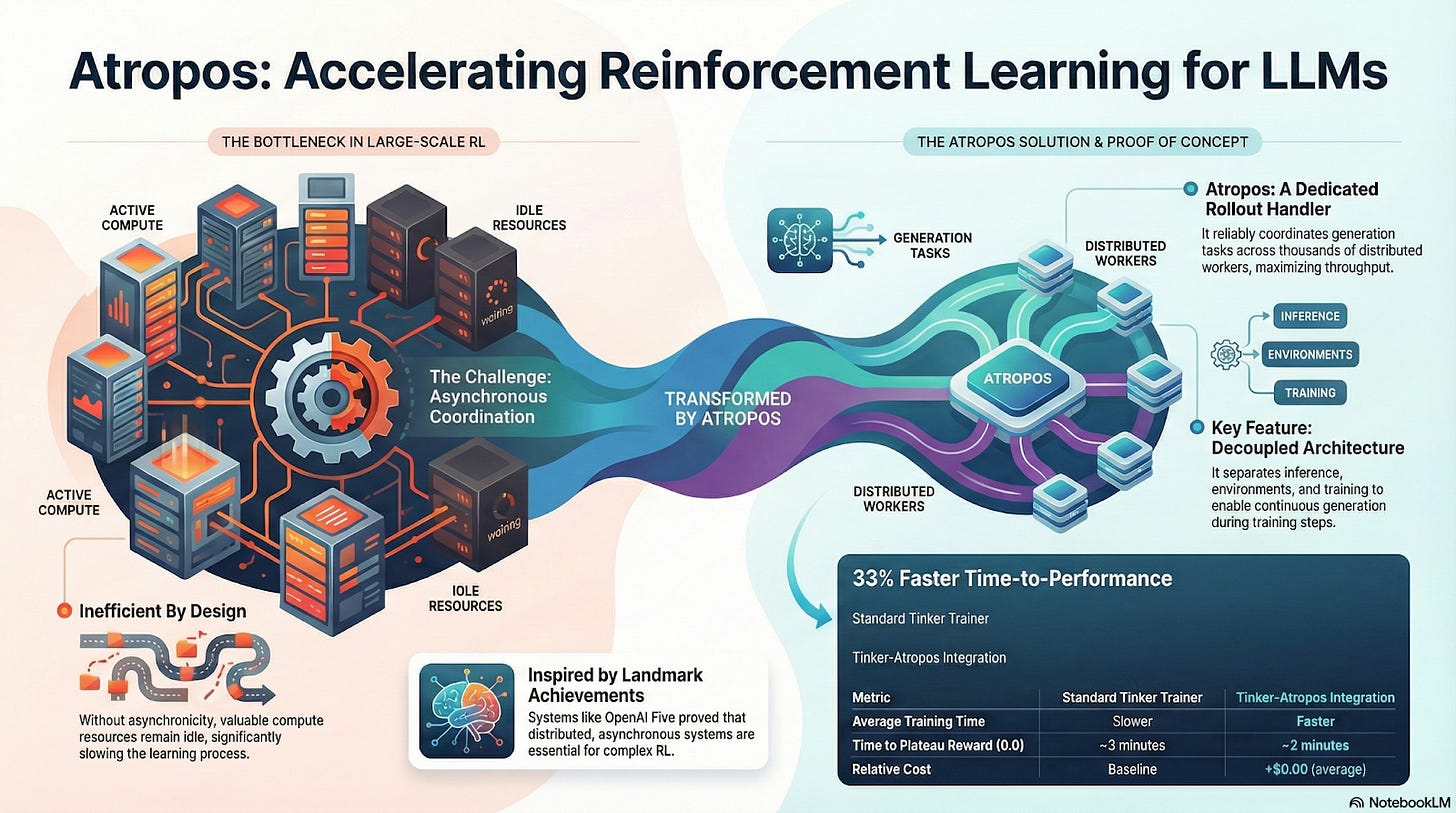
DisTrOとPsyche: 分散型強化学習のための最適化層
従来のRLF(RLHF/RLAIF)トレーニングは、集中型の高帯域幅クラスターに依存しており、オープンソースシステムでは再現できない大きな障壁となっています。DisTrOは、モーメンタム分離と勾配圧縮によってRLの通信コストを数桁削減し、インターネット帯域幅でトレーニングを実行できるようにします。Psycheはこのトレーニングメカニズムをオンチェーンネットワークに展開することで、ノードが推論、検証、報酬評価、重み更新をローカルで実行できるようにし、完全なRL閉ループを形成します。
Nousアーキテクチャでは、Atroposが思考連鎖を検証し、DisTrOが訓練通信を圧縮し、Psycheが強化学習ループを実行し、WorldSimが複雑な環境を提供し、Forgeが実際の推論データを収集し、Hermesがすべての学習結果を重みに書き込みます。強化学習は単なる訓練段階ではなく、データ、環境、モデル、インフラストラクチャを結び付けるNousアーキテクチャの中核プロトコルであり、Hermesをオープンソースコンピューティングネットワーク上で継続的に自己改善できる生きたシステムへと導きます。
勾配ネットワーク:強化学習アーキテクチャ「Echo」
Gradient Networkの中核ビジョンは、「オープンインテリジェンススタック」を通じてAIコンピューティングパラダイムを再構築することです。Gradientのテクノロジースタックは、独立して進化しながらも異種環境で連携可能なコアプロトコル群で構成されています。基盤となる通信から上位層のインテリジェント連携まで、そのアーキテクチャにはParallax(分散推論)、Echo(分散RLトレーニング)、Lattica(P2Pネットワーク)、SEDM/Massgen/Symphony/CUAHarm(メモリ、連携、セキュリティ)、VeriLLM(信頼できる検証)、Mirage(高忠実度シミュレーション)が含まれ、これらが一体となって、継続的に進化する分散型インテリジェントインフラストラクチャを形成しています。
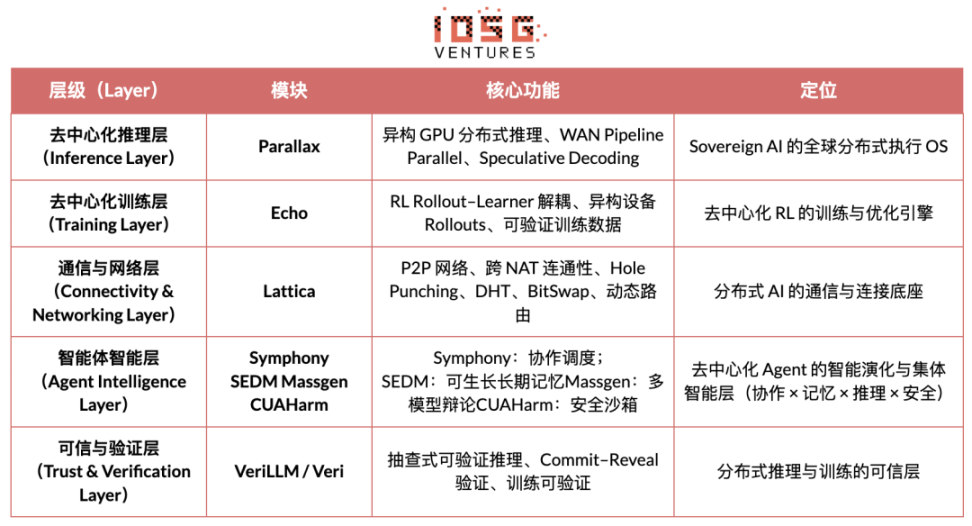
Echo — 強化学習トレーニングアーキテクチャ
EchoはGradientの強化学習フレームワークです。その中核となる設計理念は、強化学習におけるトレーニング、推論、データ(報酬)パスを分離することです。これにより、ロールアウト生成、ポリシー最適化、報酬評価を異種環境において独立してスケールし、スケジューリングすることが可能になります。Echoは推論ノードとトレーニングノードで構成される異種ネットワーク内で協調的に動作し、軽量な同期メカニズムによって広域異種環境におけるトレーニングの安定性を維持します。これにより、従来のDeepSpeed RLHF/VERLにおける推論とトレーニングの混合によって発生するSPMD障害やGPU利用率のボトルネックを効果的に軽減します。
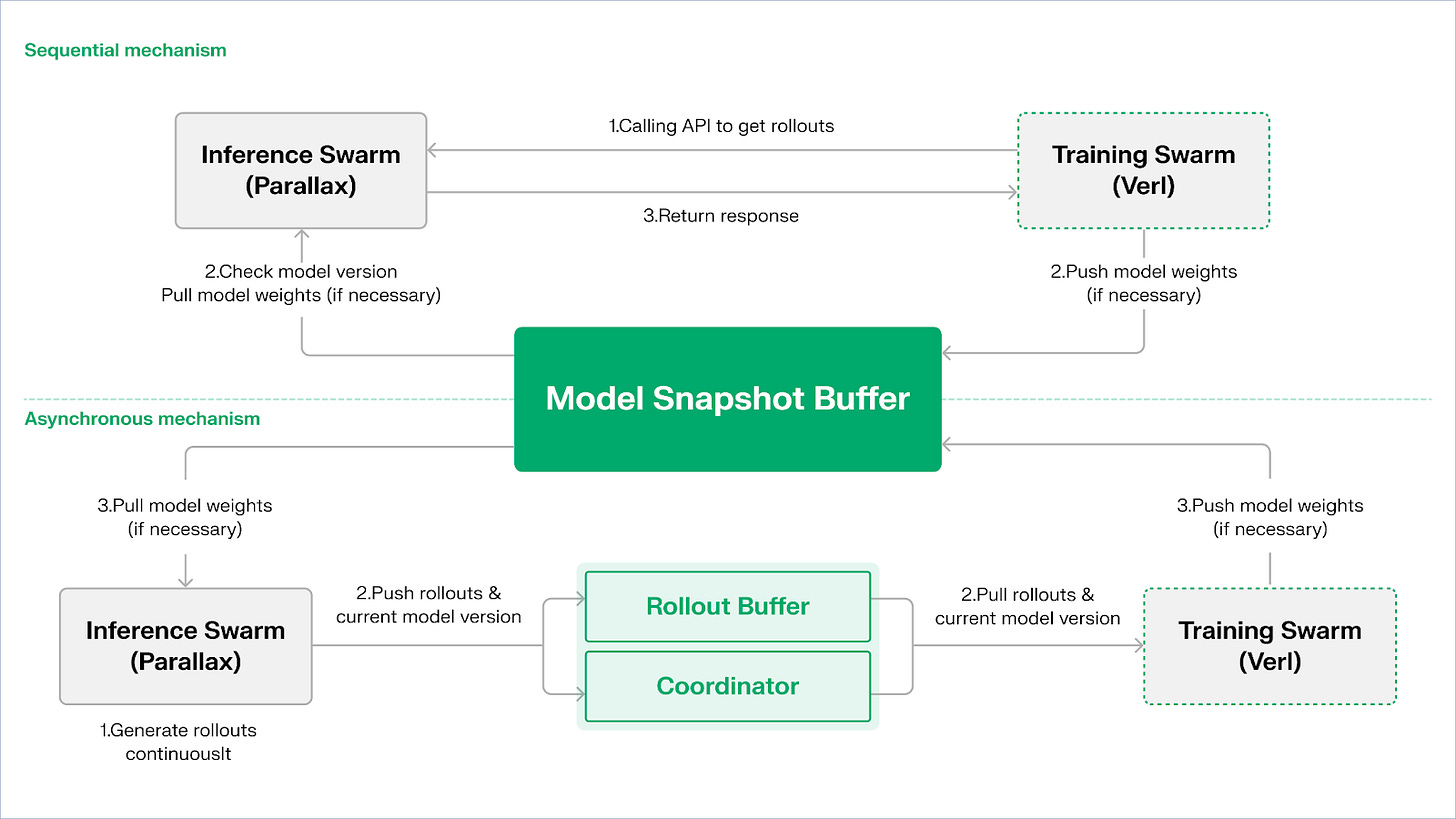
Echoは、推論と学習にデュアルグループアーキテクチャを採用し、計算能力を最大限に活用します。2つのグループは独立して動作し、互いに干渉することはありません。
サンプリング スループットの最大化: コンシューマー グレードの GPU とエッジ デバイスで構成される Inference Swarm は、軌道生成に重点を置いたパイプライン並列方式で高スループットのサンプラーを構築するために Parallax を使用します。
勾配計算能力の最大化: 集中型クラスターまたは世界中の複数の場所で実行できるコンシューマーグレードの GPU ネットワークで構成される Training Swarm は、学習プロセスに重点を置き、勾配の更新、パラメータの同期、LoRA の微調整を担当します。
ポリシーとデータ間の一貫性を維持するために、Echo は順次と非同期の 2 つの軽量同期プロトコルを提供し、ポリシーの重みと軌跡の双方向の一貫性管理を実現します。
シーケンシャル プル モード | 精度優先: トレーニング側では、新しい軌跡をプルする前に推論ノードにモデル バージョンの更新を強制し、軌跡の鮮度を保証します。これは、ポリシーの古さに非常に敏感なタスクに適しています。
非同期プッシュプル モード | 効率優先: 推論側はバージョン ラベル付きの軌跡を継続的に生成し、トレーニング側は独自のリズムに従ってそれを消費し、コーディネーターはバージョンの偏差を監視して重みの更新をトリガーし、デバイスの使用率を最大化します。
Echo は、Parallax (低帯域幅環境での異種推論) と軽量分散トレーニング コンポーネント (VERL など) を中核として構築されており、LoRA を利用してノード間の同期コストを削減し、世界中の異種ネットワークで強化学習を安定して実行できるようにします。
Grail: Bittensorエコシステムにおける強化学習
Bittensor は、独自の Yuma コンセンサス メカニズムを通じて、大規模でスパースな非定常報酬関数ネットワークを構築します。
Bittensorエコシステム内のCovenant AIは、SN3 Templar、SN39 Basilica、SN81 Grailを使用して、事前トレーニングから事後RLトレーニングまで垂直統合されたパイプラインを構築しました。SN3 Templarはベースモデルの事前トレーニングを処理し、SN39 Basilicaは分散コンピューティングマーケットプレイスを提供し、SN81 Grailは事後RLトレーニングの「検証可能な推論レイヤー」として機能し、RLHF/RLAIFの中核プロセスを実行し、ベースモデルからアライメント戦略までのクローズドループ最適化を実行します。
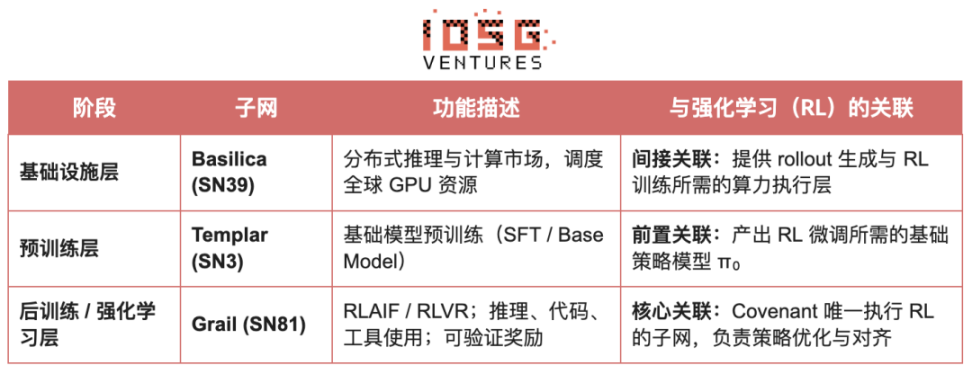
GRAILは、強化学習の各ロールアウトの真正性とモデルのアイデンティティへの紐付けを暗号的に証明し、RLHFがトラストレス環境において安全に実行されることを保証することを目的としています。このプロトコルは、以下の3層メカニズムを通じて信頼チェーンを確立します。
決定論的なチャレンジ生成: ランダムビーコンとブロックハッシュを使用して、予測不可能だが再現可能なチャレンジタスク (SAT、GSM8K など) を生成し、事前計算の不正行為を排除します。
PRF インデックス サンプリングとスケッチ コミットメントを使用することで、バリデーターはトークン レベルの logprob と推論チェーンを非常に低コストでサンプリングし、ロールアウトが実際に宣言モデルによって生成されたことを確認できます。
モデルIDバインディング:推論プロセスは、モデルの重みフィンガープリントとトークン分布の構造化された署名にバインドされており、モデルの置き換えや結果の再生が即座に認識されることを保証します。これにより、RLにおける推論の展開における信頼性の基盤が提供されます。
このメカニズムに基づき、GrailサブネットはGRPOスタイルの検証可能な学習後プロセスを実装します。マイナーは同一の問題に対して複数の推論パスを生成し、検証者は正しさ、推論チェーンの品質、SAT満足度に基づいてスコアリングを行い、正規化された結果をTAO重みとしてオンチェーンに書き込みます。公開実験では、このフレームワークによりQwen2.5-1.5BのMATH精度が12.7%から47.6%に向上したことが示されており、不正行為を防止しながらモデル機能を大幅に強化できることが証明されています。Covenant AIの学習スタックにおいて、Grailは分散型RLVR/RLAIFの信頼性と実行の基盤であり、メインネット上ではまだ正式にリリースされていません。
Fraction AI: 競争ベースの強化学習 (RLFC)
Fraction AIのアーキテクチャは、競争からの強化学習(RLFC)とゲーミフィケーションされたデータアノテーションを明示的に中心に構築されており、従来のRLFCにおける静的な報酬と手動によるアノテーションを、オープンで動的な競争環境に置き換えます。エージェントは異なるスペースで互いに競い合い、相対的なランキングとAI審査員のスコアがリアルタイムの報酬を構成し、アライメントプロセスを継続的なオンラインマルチエージェントゲームシステムへと変換します。
従来の RLHF と Fraction AI の RLFC の主な違いは次のとおりです。

RLFCの中核的な価値は、報酬が単一のモデルからではなく、常に進化する対戦相手や評価者から得られるという点にあります。これにより、報酬モデルの悪用を防ぎ、戦略の多様性によってエコシステムが局所最適解に陥ることを防ぎます。空間構造はゲームの性質(ゼロサムかプラスサムか)を決定し、敵対的および協力的な相互作用における複雑な行動の出現を促します。
システム アーキテクチャの観点から見ると、Friction AI はトレーニング プロセスを 4 つの主要コンポーネントに分解します。
エージェント: オープンソース LLM に基づく軽量ポリシー ユニット。QLoRA を介して差分重みが拡張され、低コストで更新されます。
スペース: エージェントが入場料を支払い、勝敗に基づいて報酬を受け取る、隔離されたミッション ドメイン環境。
AI 審査員: RLAIF で構築された即時報酬レイヤーで、スケーラブルで分散化された評価を提供します。
学習の証明: ポリシーの更新を特定の競争結果に結び付け、トレーニング プロセスが検証可能であること、および不正行為を防止できることを保証します。
Fraction AIの本質は、人間と機械が協働する進化エンジンを構築することです。ユーザーは、ポリシー層における「メタ最適化者」として、迅速なエンジニアリングとハイパーパラメータ設定を通じて探索の方向性を導きます。一方、エージェントはミクロレベルの競争の中で、大量の高品質な選好ペアを自動生成します。このモデルにより、データアノテーションは「信頼のない微調整」を通じてビジネスのクローズドループを実現します。
強化学習Web3プロジェクトアーキテクチャの比較
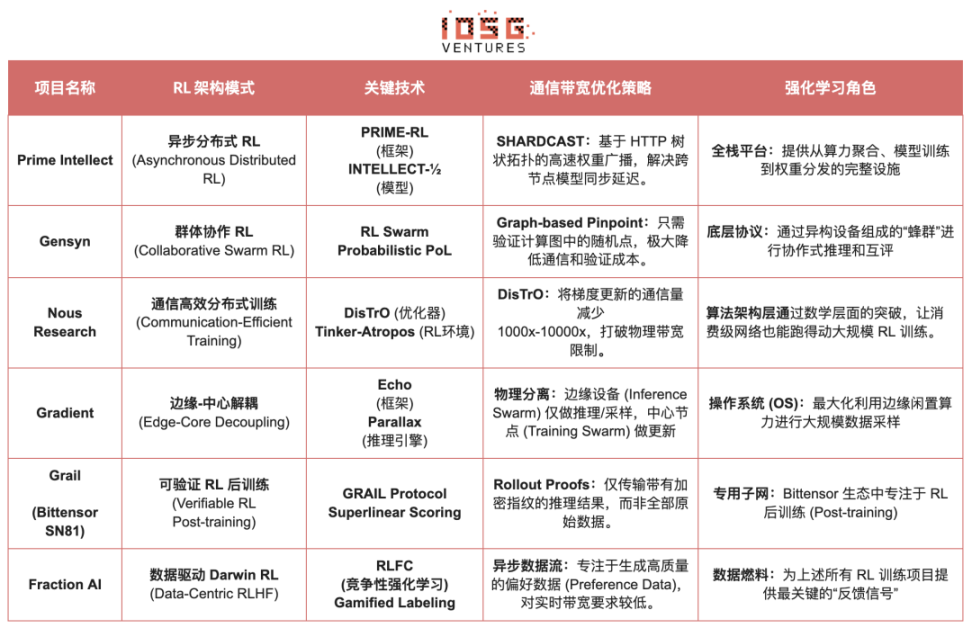
V. まとめと展望:強化学習 × Web3 の道筋と機会
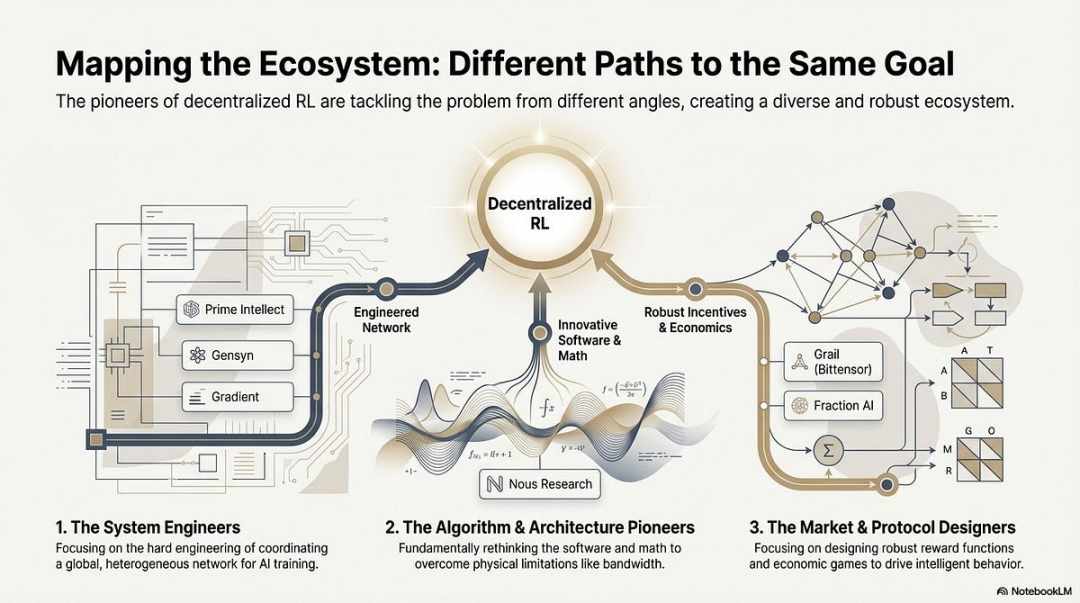
前述の最先端プロジェクトの脱構築的分析に基づき、各チームのエントリーポイント(アルゴリズム、エンジニアリング、市場)は異なるものの、強化学習(RL)とWeb3を組み合わせると、その基盤となるアーキテクチャロジックは、非常に一貫性のある「分離・検証・インセンティブ」パラダイムに収束することがわかりました。これは単なる技術的な偶然ではなく、分散型ネットワークが強化学習の独自の特性に適応していく中で必然的に生じる結果です。
強化学習の一般的なアーキテクチャの特徴: 中核となる物理的制約と信頼の問題に対処します。
ロールアウトと学習の分離 - デフォルトの計算トポロジ
疎で並列化可能な Rollout は、世界中のコンシューマー グレードの GPU にアウトソーシングされており、高帯域幅のパラメータ更新は、Prime Intellect の非同期 Actor-Learner や Gradient Echo のデュアル クラスター アーキテクチャに見られるように、少数のトレーニング ノードに集中しています。
検証主導の信頼 – インフラ開発
許可のないネットワークでは、Gensyn の PoL、Prime Intellect の TOPLOC、Grail などの暗号検証方法に代表される数学的およびメカニズム的設計を通じて計算の真正性を強化する必要があります。
トークン化されたインセンティブループ - 市場の自己規制
コンピューティングパワーの供給、データ生成、検証とランキング、そして報酬の分配は閉ループを形成します。報酬を通じて参加を促進し、スラッシュによって不正行為を抑制することで、ネットワークは安定を保ち、オープンな環境の中で進化し続けることができます。
差別化された技術パス:一貫したアーキテクチャの下での異なる「ブレークスルーポイント」
アーキテクチャの収束にもかかわらず、各プロジェクトは独自の特性に基づいて異なる技術的防御壁を選択しました。
アルゴリズムのブレークスルーに注力するグループであるNous Researchは、分散学習における根本的な矛盾(帯域幅のボトルネック)を数学的観点から解決しようと試みています。彼らのDisTrOオプティマイザーは、勾配通信を数千分の1に圧縮し、大規模モデルの学習を家庭用ブロードバンドでも実行できるようにすることを目標としています。これは、物理的な限界に対する「次元削減攻撃」です。
システムエンジニアリングアプローチ(Prime Intellect、Gensyn、Gradient):次世代の「AIランタイムシステム」の構築に重点を置いています。Prime IntellectのShardCastとGradientのParallaxは、高度なエンジニアリング技術を駆使し、既存のネットワーク環境下で最高の異種クラスタ効率を実現するように設計されています。
市場ベースゲーム理論(Bittensor、Fraction AI):報酬関数の設計に焦点を当てています。洗練されたスコアリングメカニズムを設計することで、マイナーが自発的に最適な戦略を見つけられるように導き、知能の発現を加速させます。
強み、課題、そして最終段階の見通し
強化学習と Web3 を組み合わせるパラダイムでは、システムレベルの利点は、まずコストとガバナンス構造の書き換えに反映されます。
コストの再編成: RL のトレーニング後にはロールアウト サンプリングの需要が無制限にある一方で、Web3 は、集中型クラウド ベンダーが匹敵できないコスト上の利点で、非常に低コストでグローバルなロングテール コンピューティング能力を動員できます。
主権的整合:AI の価値(整合)に関する大企業の独占を打ち破り、コミュニティはトークンで投票してモデルに対する「良い答えとは何か」を決定できるため、AI ガバナンスが民主化されます。
同時に、このシステムは 2 つの大きな構造上の制約にも直面しています。
帯域幅の壁: DisTrO などの革新にもかかわらず、物理的なレイテンシにより、超大規模パラメータ モデル (70B 以上) の完全なトレーニングが依然として制限されており、Web3 AI は現在、微調整と推論に制限されています。
グッドハードの法則(報酬ハッキング):インセンティブの高いネットワークでは、マイナーは実際の知能を向上させるよりも、報酬ルールを「過剰適合」(スコアファーミング)する傾向があります。不正行為を防ぐための堅牢な報酬関数の設計は、終わりのないゲームです。
悪意のあるビザンチンワーカー攻撃:これらの攻撃は、学習信号を積極的に操作・改ざんすることでモデルの収束を阻害します。中核となる戦略は、不正行為を防止する報酬関数を継続的に設計することではなく、敵対的に堅牢なメカニズムを構築することです。
強化学習とWeb3の組み合わせは、本質的に「知能がどのように生成され、調整され、その価値がどのように分配されるか」というメカニズムを書き換えます。その進化は、3つの相補的な方向に要約できます。
分散型プッシュトレーニングネットワーク:コンピューティングパワーマイニングマシンからポリシーネットワークまで、並列かつ検証可能なロールアウトをグローバルロングテールGPUにアウトソーシングし、短期的には検証可能な推論市場に焦点を当て、中期的にはタスククラスタリングのための強化学習サブネットへと進化します。
選好と報酬の資産化:ラベリングの労働からデータの公平性へ。これには、選好と報酬の資産化、高品質なフィードバックと報酬モデルを統制可能かつ分配可能なデータ資産に変換し、「ラベリングの労働」を「データの公平性」へと向上させることが含まれます。
垂直分野における「小さくても美しい」進化: 結果が検証可能でメリットが定量化可能な垂直シナリオでは、DeFi 戦略実行やコード生成など、戦略の改善と価値獲得を直接結び付け、一般的なクローズドソース モデルを上回ることが期待される、小型ながらも強力な専用 RL エージェントが開発されています。
全体的に、強化学習 × Web3 の本当のチャンスは、OpenAI の分散バージョンを複製することではなく、「インテリジェントな生産関係」を書き換えることにあります。つまり、トレーニングの実行をオープンなコンピューティング パワー マーケットにし、報酬と好みをオンチェーン資産で管理できるようにし、インテリジェンスによってもたらされる価値をプラットフォームに集中させるのではなく、トレーナー、アライナー、ユーザーの間で再分配することです。
免責事項:この記事はAIツールChatGPT-5およびGemini 3の支援を受けて執筆されました。著者は情報の正確性と信頼性を確保するためにあらゆる努力を払っておりますが、それでも記載漏れが生じる可能性がございます。ご不便をおかけして申し訳ございません。暗号資産市場では、プロジェクトのファンダメンタルズと流通市場の価格動向の間に乖離が生じることがよくあることに特にご注意ください。この記事の内容は情報提供および学術研究交流のみを目的としており、投資アドバイスを構成するものではなく、また、特定のトークンの売買を推奨するものでもありません。


