
작성자: 0xjacobzhao 및 ChatGPT 4o
1. 소개 | Crypto AI의 모델 수준 전환
데이터, 모델, 컴퓨팅 파워는 연료(데이터), 엔진(모델), 에너지(컴퓨팅 파워)와 마찬가지로 AI 인프라의 세 가지 핵심 요소입니다. 기존 AI 산업의 인프라 진화 과정과 유사하게 Crypto AI 분야도 유사한 단계를 거쳤습니다. 2024년 초에는 분산형 GPU 프로젝트(Akash, Render, io.net 등)가 시장을 주도했으며, 이들은 일반적으로 "컴퓨팅 파워 경쟁"이라는 광범위한 성장 논리를 강조했습니다. 2025년 이후 업계의 초점은 점차 모델 및 데이터 계층으로 이동했습니다. 이는 Crypto AI가 기반 리소스 경쟁에서 더욱 지속 가능하고 애플리케이션 가치 있는 중간 단계 구축으로 전환되고 있음을 시사합니다.
대규모 일반 모델(LLM) 대 특수 모델(SLM)
기존의 대규모 언어 모델(LLM) 학습은 대규모 데이터 세트와 복잡한 분산 아키텍처에 크게 의존하며, 매개변수 크기는 70B에서 500B에 달하고 학습 비용은 수백만 달러에 달하는 경우가 많습니다. 재사용 가능한 기본 모델을 위한 가볍고 미세 조정 패러다임인 SLM(특수 언어 모델)은 일반적으로 LLaMA, Mistral, DeepSeek과 같은 오픈 소스 모델을 기반으로 하며, 소량의 고품질 전문 데이터와 LoRA와 같은 기술을 결합하여 특정 도메인 지식을 갖춘 전문가 모델을 신속하게 구축하여 학습 비용과 기술적 장벽을 크게 줄입니다.
SLM은 LLM 가중치에 통합되지 않고 에이전트 아키텍처 호출, 플러그인 시스템 동적 라우팅, LoRA 모듈 핫 스와핑, RAG(검색 향상 생성) 등을 통해 LLM과 협업한다는 점이 주목할 만합니다. 이 아키텍처는 LLM의 광범위한 적용 범위를 유지할 뿐만 아니라 모듈을 미세 조정하여 전문적인 성능을 향상시켜 매우 유연한 통합 지능형 시스템을 형성합니다.
모델 수준에서 Crypto AI의 가치와 경계
암호화 AI 프로젝트는 본질적으로 대규모 언어 모델(LLM)의 핵심 기능을 직접 개선하기 어렵습니다. 그 핵심 이유는 다음과 같습니다.
- 기술적 한계가 너무 높습니다. Foundation Model을 학습하는 데 필요한 데이터 규모, 컴퓨팅 리소스 및 엔지니어링 역량이 매우 방대합니다. 현재 미국(OpenAI 등)과 중국(DeepSeek 등)과 같은 거대 기술 기업만이 이에 상응하는 역량을 보유하고 있습니다.
- 오픈 소스 생태계의 한계: LLaMA 및 Mixtral과 같은 주류 기본 모델은 오픈 소스이지만, 모델 혁신을 진정으로 촉진하는 핵심은 여전히 과학 연구 기관과 폐쇄 소스 엔지니어링 시스템에 집중되어 있으며, 온체인 프로젝트는 핵심 모델 계층에 참여할 수 있는 여지가 제한적입니다.
그러나 오픈소스 기본 모델을 기반으로 Crypto AI 프로젝트는 특수 언어 모델(SLM)을 미세 조정하고 Web3의 검증 가능성과 인센티브 메커니즘을 결합함으로써 가치 확장을 달성할 수 있습니다. AI 산업 체인의 "주변 인터페이스 계층"으로서 이는 두 가지 핵심 방향에 반영됩니다.
- 신뢰할 수 있는 검증 계층: 모델 생성 경로, 데이터 기여, 사용량을 체인상에서 기록하여 AI 출력의 추적성과 변조 방지 기능을 강화합니다.
- 인센티브 메커니즘: 기본 토큰의 도움으로 데이터 업로드, 모델 호출, 에이전트 실행과 같은 행동에 인센티브를 제공하여 모델 학습 및 서비스의 긍정적인 순환을 구축하는 데 사용됩니다.
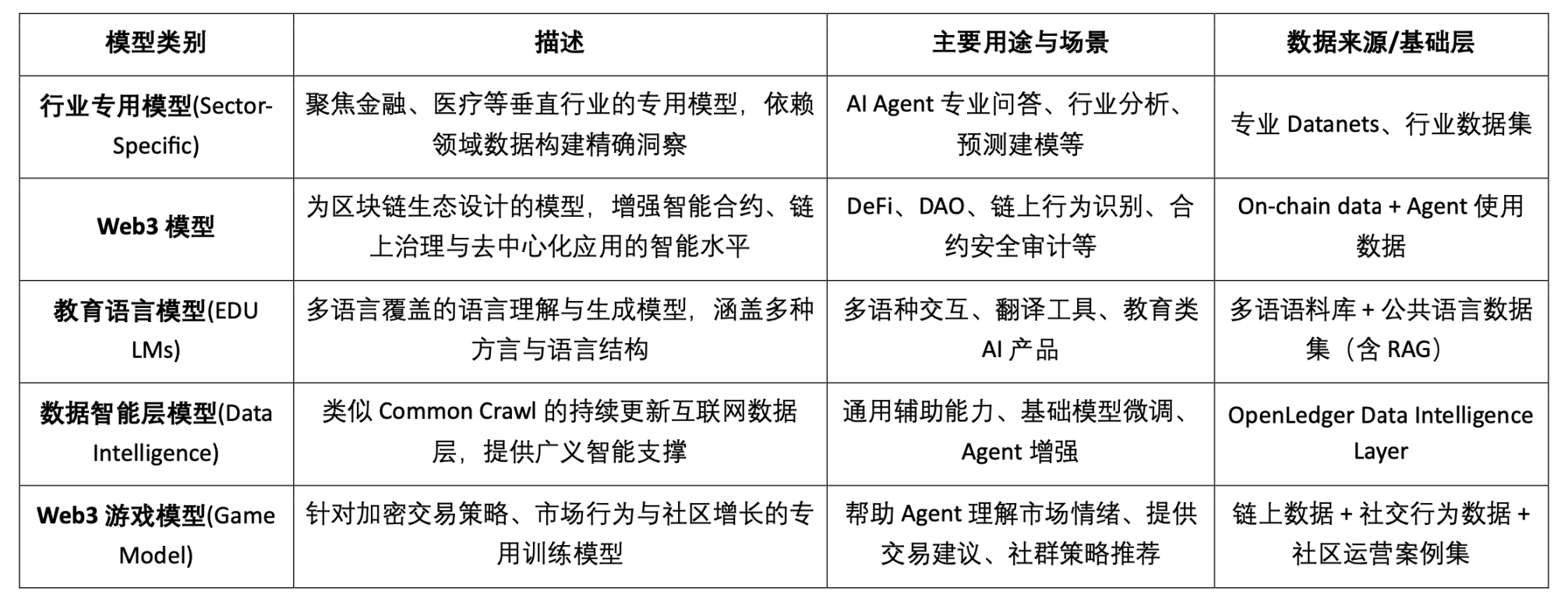
AI 모델 유형 분류 및 블록체인 적용성 분석
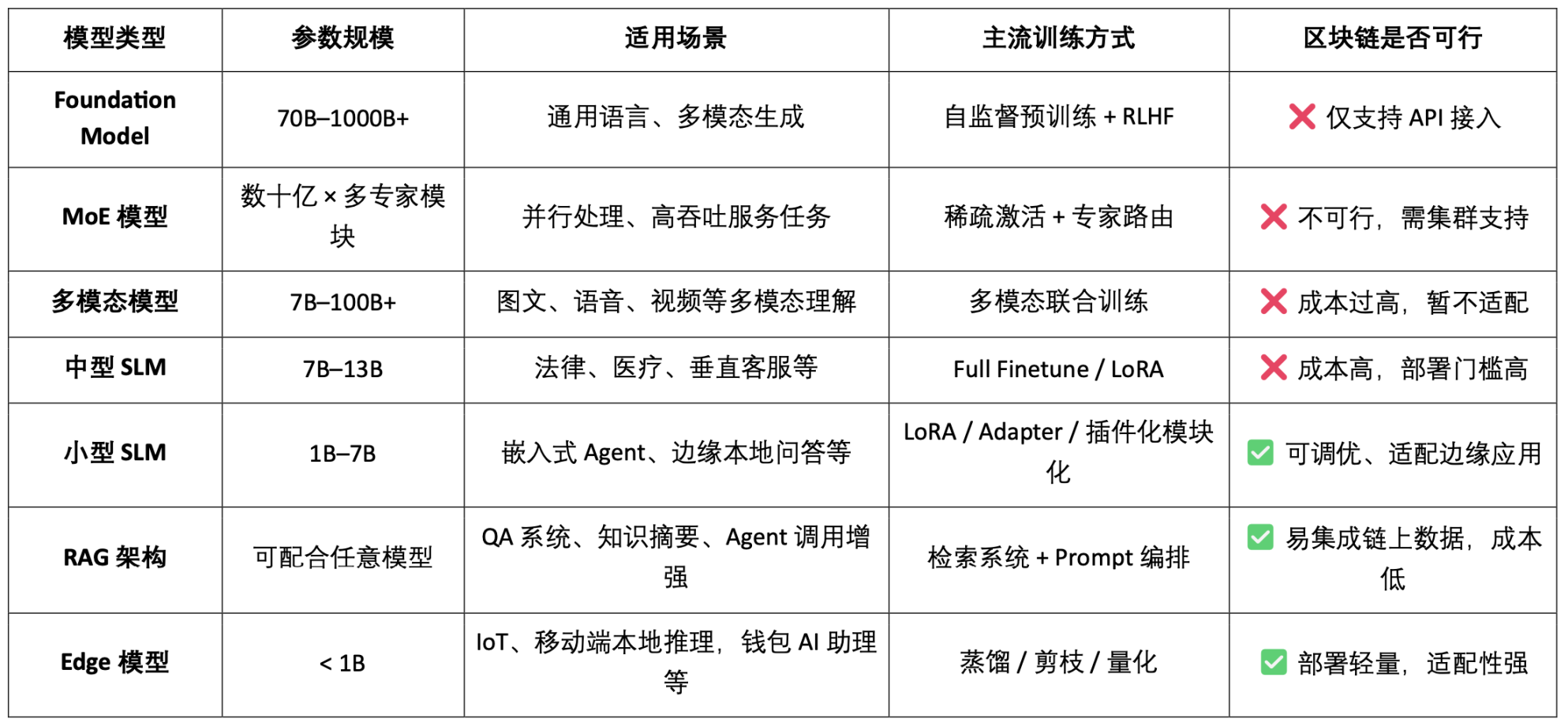
모델 기반 Crypto AI 프로젝트의 실현 가능한 목표는 주로 소규모 SLM의 경량 미세 조정, RAG 아키텍처의 온체인 데이터 접근 및 검증, 그리고 Edge 모델의 로컬 배포 및 인센티브에 집중되어 있음을 알 수 있습니다. 블록체인의 검증 가능성과 토큰 메커니즘을 결합하면 Crypto는 이러한 저/중 리소스 모델 시나리오에 고유한 가치를 제공하여 AI "인터페이스 계층"의 차별화된 가치를 형성할 수 있습니다.
데이터와 모델 기반 블록체인 AI 체인은 각 데이터와 모델의 기여 출처를 명확하고 변경 불가능한 방식으로 기록하여 데이터의 신뢰성과 모델 학습의 추적성을 크게 향상시킵니다. 동시에, 스마트 계약 메커니즘을 통해 데이터 또는 모델이 호출될 때 보상이 자동으로 분배되어 AI 행동을 측정 및 거래 가능한 토큰화된 가치로 변환하고 지속 가능한 인센티브 시스템을 구축합니다. 또한, 커뮤니티 사용자는 모델 성능을 평가하고, 토큰 투표를 통해 규칙 제정 및 반복 과정에 참여하며, 탈중앙화된 거버넌스 아키텍처를 개선할 수 있습니다.
2. 프로젝트 개요 | OpenLedger의 AI 체인 비전
OpenLedger는 데이터 및 모델 인센티브 메커니즘에 중점을 둔 몇 안 되는 블록체인 AI 프로젝트 중 하나입니다. 공정하고 투명하며 구성 가능한 AI 운영 환경을 구축하는 것을 목표로 "Payable AI"라는 개념을 최초로 제안했으며, 데이터 기여자, 모델 개발자, AI 애플리케이션 개발자가 동일한 플랫폼에서 협업하고 실제 기여에 따라 온체인 혜택을 얻도록 인센티브를 제공합니다.
OpenLedger는 "데이터 제공"부터 "모델 구축", "통화 수익 공유"까지 완전한 체인 폐쇄 루프를 제공합니다. 핵심 모듈은 다음과 같습니다.
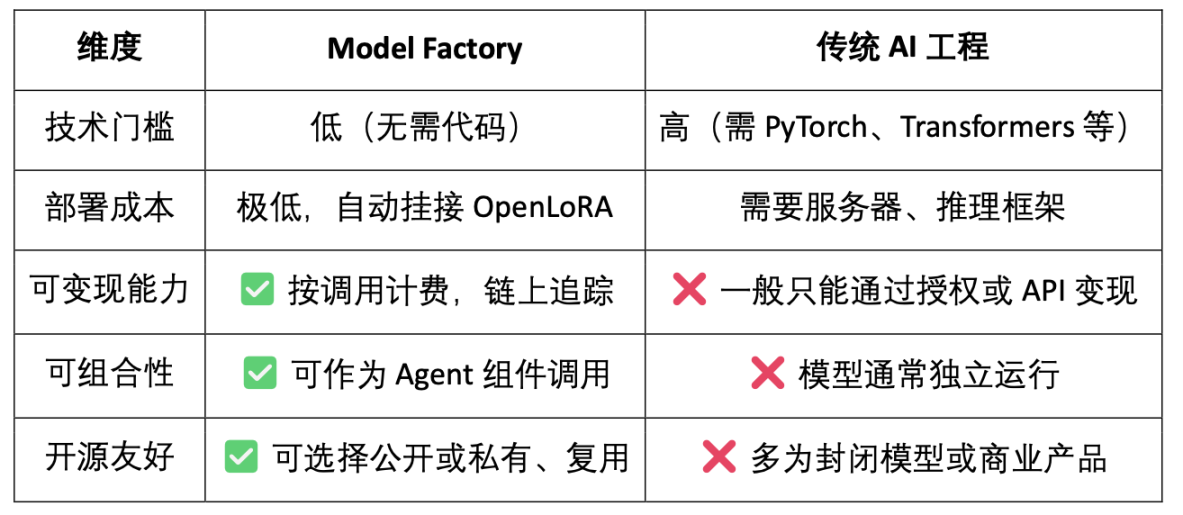
- 모델 팩토리: 프로그래밍 없이 오픈 소스 LLM 기반 LoRA를 사용하여 맞춤형 모델을 미세 조정, 훈련 및 배포합니다.
- OpenLoRA: 수천 개의 모델 공존과 수요에 따른 동적 로딩을 지원하여 배포 비용을 크게 절감합니다.
- PoA(Proof of Attribution): 기여도 측정 및 보상 분배는 체인상 통화 기록을 통해 이루어집니다.
- 데이터넷: 커뮤니티 협업을 통해 구축 및 검증된 수직적 시나리오를 위한 구조화된 데이터 네트워크
- 모델 제안 플랫폼: 구성 가능하고 호출 가능하며 지불 가능한 온체인 모델 시장입니다.
OpenLedger는 위 모듈을 통해 AI 가치 사슬의 온체인화를 촉진하기 위해 데이터 기반의 모델 구성 가능한 "지능형 경제 인프라"를 구축했습니다.
블록체인 기술 도입 측면에서 OpenLedger는 OP Stack + EigenDA를 기반으로 AI 모델을 위한 고성능, 저비용, 검증 가능한 데이터 및 계약 운영 환경을 구축합니다.
- OP 스택 기반: Optimism 기술 스택을 기반으로 높은 처리량과 저비용 실행을 지원합니다.
- 이더리움 메인넷에서의 결제: 거래 보안 및 자산 무결성 보장
- EVM 호환성: 개발자가 Solidity를 기반으로 빠르게 배포하고 확장할 수 있도록 돕습니다.
- EigenDA는 데이터 가용성 지원을 제공하여 저장 비용을 크게 줄이고 데이터 검증 가능성을 보장합니다.
NEAR와 같이 데이터 주권 및 "BOS 기반 AI 에이전트" 아키텍처에 중점을 둔 저수준의 일반 AI 체인과 달리, OpenLedger는 데이터 및 모델 인센티브를 위한 AI 전용 체인 구축에 더욱 집중하며, 모델 개발 및 호출을 추적 가능하고, 구성 가능하며, 지속 가능한 온체인 가치 폐쇄 루프(CVL)로 만드는 데 전념합니다. OpenLedger는 HuggingFace 스타일의 모델 호스팅, Stripe 스타일의 사용료 청구, Infura 스타일의 온체인 구성 가능 인터페이스를 결합하여 "모델을 자산으로" 구현하는 과정을 촉진하는 Web3 세계의 모델 인센티브 인프라입니다.
3. OpenLedger의 핵심 구성 요소 및 기술 아키텍처
3.1 모델 팩토리, 코드 필요 없음 모델 팩토리
ModelFactory는 OpenLedger 생태계 기반의 대규모 언어 모델(LLM) 미세 조정 플랫폼입니다. 기존의 미세 조정 프레임워크와 달리 ModelFactory는 명령줄 도구나 API 통합 없이 순수한 그래픽 인터페이스 작업을 제공합니다. 사용자는 OpenLedger에서 승인 및 검토된 데이터 세트를 기반으로 모델을 미세 조정할 수 있습니다. 데이터 승인, 모델 학습 및 배포를 위한 통합 워크플로를 구현합니다. 핵심 프로세스는 다음과 같습니다.
- 데이터 접근 제어: 사용자가 데이터 요청을 제출하고, 제공자가 이를 검토하여 승인하며, 데이터는 자동으로 모델 학습 인터페이스에 연결됩니다.
- 모델 선택 및 구성: 주요 LLM(LLaMA, Mistral 등)을 지원하고 GUI를 통해 하이퍼파라미터를 구성합니다.
- 가벼운 미세 조정: LoRA / QLoRA 엔진 내장, 훈련 진행 상황 실시간 표시.
- 모델 평가 및 배포: 내장된 평가 도구는 수출 배포나 생태학적 공유 호출을 지원합니다.
- 대화형 검증 인터페이스: 모델의 질문과 답변 기능을 직접 테스트할 수 있는 채팅 스타일 인터페이스를 제공합니다.
- RAG는 출처를 생성합니다. 답변에는 출처 참조가 함께 제공되어 신뢰도와 감사 용이성이 향상됩니다.
모델 팩토리 시스템 아키텍처는 신원 인증, 데이터 권한, 모델 미세 조정, 평가 배포 및 RAG 추적성을 포함하는 6개의 주요 모듈로 구성되어 안전하고 제어 가능하며 실시간 상호 작용이 가능하고 지속 가능한 통합 모델 서비스 플랫폼을 구축합니다.
다음 표는 현재 ModelFactory에서 지원하는 대규모 언어 모델 기능을 요약한 것입니다.
- LLaMA 시리즈: 가장 광범위한 생태계, 활발한 커뮤니티, 그리고 강력한 전반적인 성능을 자랑합니다. 가장 대중적인 오픈소스 기본 모델 중 하나입니다.
- 미스트랄: 효율적인 아키텍처와 뛰어난 추론 성능을 갖추고 있어, 배포가 유연하고 리소스가 제한된 시나리오에 적합합니다.
- Qwen: 알리바바에서 생산한 제품으로 중국 내 업무에 적합한 성능을 보이며, 종합적인 역량이 강해 국내 개발자들의 첫 번째 선택이 되었습니다.
- ChatGLM: 탁월한 중국어 대화 효과를 제공하며, 수직적 고객 서비스와 현지화 시나리오에 적합합니다.
- Deepseek: 코드 생성과 수학적 추론에 뛰어나며 지능형 개발 지원 도구에 적합합니다.
- Gemma: Google이 출시한 가벼운 모델로, 시작하기 쉽고 빠르게 실험할 수 있는 명확한 구조를 갖추고 있습니다.
- 팔콘: 한때 기본 연구나 비교 테스트에 적합한 성능 벤치마크였지만, 커뮤니티 활동이 감소했습니다.
- BLOOM: 다국어 지원은 강력하지만 추론 성능은 약하며 언어 범위 연구에 적합합니다.
- GPT-2: 초기의 고전적인 모델로, 교육 및 검증 목적으로만 적합하며 실제 배포에는 권장되지 않습니다.
OpenLedger의 모델 포트폴리오에는 최신 고성능 MoE 모델이나 멀티모달 모델이 포함되어 있지 않지만, 그 전략은 시대에 뒤떨어진 것이 아닙니다. 오히려 온체인 배포의 현실적인 제약(추론 비용, RAG 적응, LoRA 호환성, EVM 환경)을 기반으로 한 "실용성을 우선시하는" 구성입니다.
코드 프리 툴 체인인 Model Factory는 모든 모델에 기여 증명 메커니즘을 내장하여 데이터 기여자와 모델 개발자의 권리와 이익을 보장합니다. 낮은 임계값, 수익 창출 및 구성 가능성이라는 장점을 가지고 있습니다. 기존 모델 개발 도구와 비교했을 때:
- 개발자를 위해: 모델 육성, 배포 및 수익에 대한 완전한 경로를 제공합니다.
- 플랫폼을 위해: 모델 자산 순환 및 결합 생태계를 형성합니다.
- 사용자 참고 사항: API를 호출하는 것처럼 모델이나 에이전트를 결합하여 사용할 수 있습니다.
3.2 OpenLoRA, 체인 자산화 모델 미세 조정
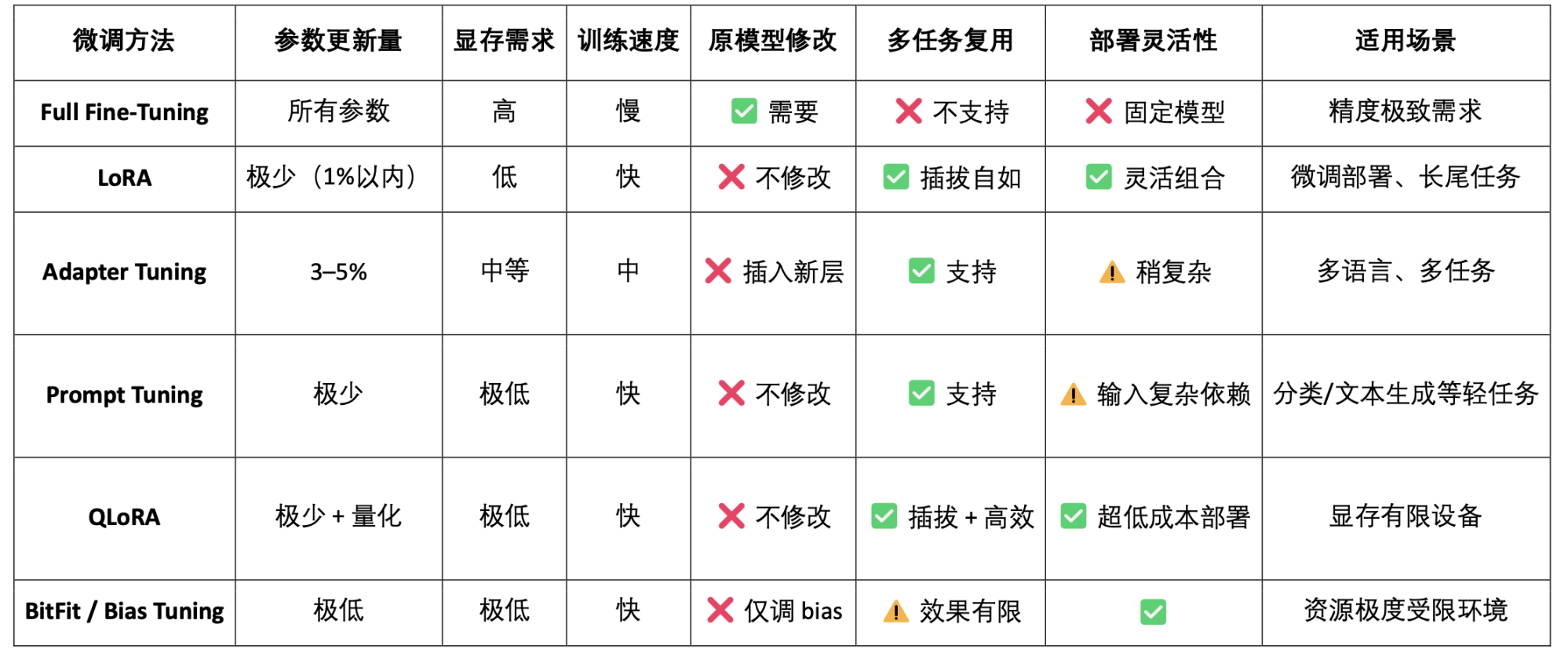
LoRA(Low-Rank Adaptation)는 기존 모델 매개변수를 수정하지 않고 사전 학습된 대규모 모델에 "저순위 행렬"을 삽입하여 새로운 작업을 학습하는 효율적인 매개변수 미세 조정 기법으로, 이를 통해 학습 비용과 저장 공간 요구 사항을 크게 줄일 수 있습니다. 기존의 대규모 언어 모델(예: LLaMA, GPT-3)은 일반적으로 수십억 또는 수천억 개의 매개변수를 갖습니다. 이러한 매개변수를 특정 작업(예: 법률 질의응답, 의료 상담)에 사용하려면 미세 조정이 필요합니다. LoRA의 핵심 전략은 "기존 대규모 모델의 매개변수를 고정하고 삽입된 새로운 매개변수 행렬만 학습"하는 것입니다. 매개변수는 효율적이고, 학습은 빠르며, 배포는 유연합니다. 현재 Web3 모델 배포 및 결합 호출에 가장 적합한 주류 미세 조정 기법입니다.
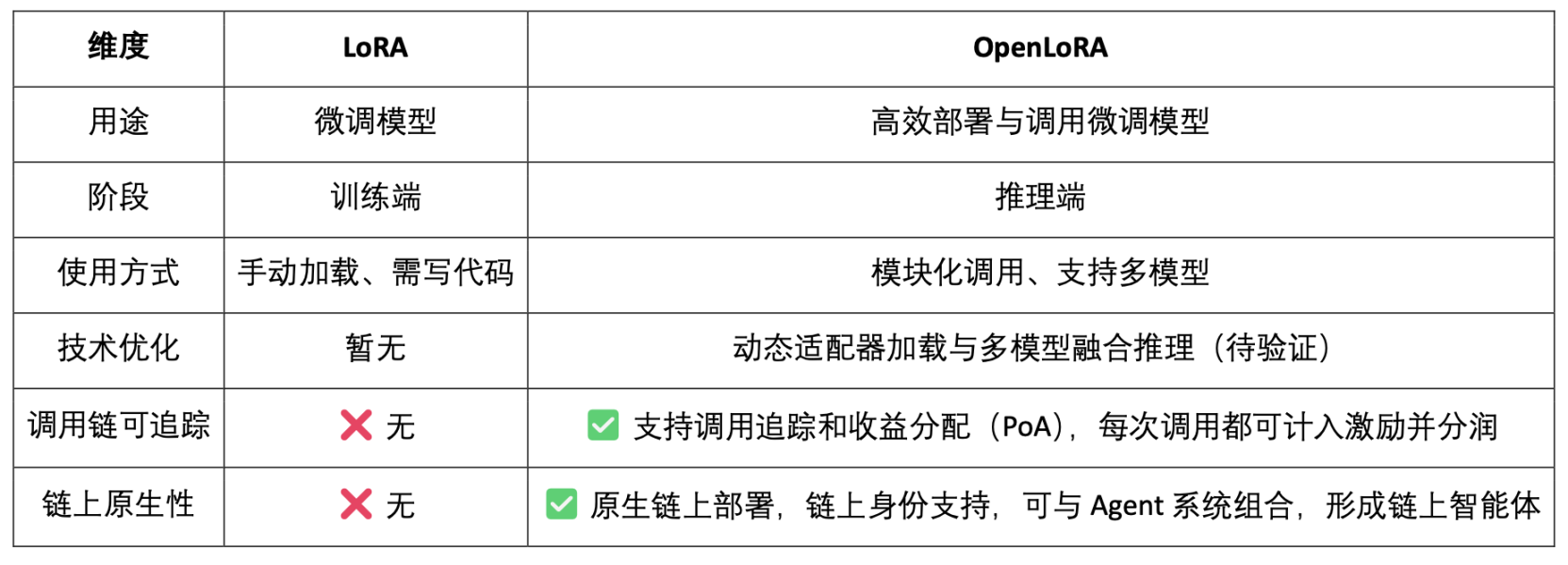
OpenLoRA는 OpenLedger에서 개발한 경량 추론 프레임워크로, 다중 모델 배포 및 리소스 공유를 위해 설계되었습니다. OpenLoRA의 핵심 목표는 현재 AI 모델 배포에서 흔히 발생하는 높은 비용, 낮은 재사용성, 그리고 GPU 리소스 낭비라는 문제를 해결하고 "Payable AI" 구현을 촉진하는 것입니다.
OpenLoRA 시스템 아키텍처의 핵심 구성 요소는 모델 저장, 추론 실행, 요청 라우팅과 같은 주요 링크를 포괄하는 모듈식 설계를 기반으로 하여 효율적이고 저렴한 다중 모델 배포 및 호출 기능을 구현합니다.
- LoRA 어댑터 저장 모듈: 미세 조정된 LoRA 어댑터는 OpenLedger에 호스팅되어 주문형 로딩을 달성하고 모든 모델을 비디오 메모리에 미리 로딩하지 않고 리소스를 절약합니다.
- 모델 호스팅 및 어댑터 병합 계층: 모든 미세 조정된 모델은 기본 모델을 공유합니다. 추론 과정에서 LoRA 어댑터는 동적으로 병합되어 여러 어댑터의 앙상블 추론을 지원하여 성능을 향상시킵니다.
- 추론 엔진: Flash-Attention, Paged-Attention, SGMV 최적화 등 다양한 CUDA 최적화 기술을 통합합니다.
- 요청 라우터 및 토큰 스트리밍: 요청에 필요한 모델에 따라 올바른 어댑터에 요청을 동적으로 라우팅하고 커널을 최적화하여 토큰 수준 스트리밍 생성을 구현합니다.
OpenLoRA의 추론 과정은 기술 수준에서 "성숙하고 보편적인" 모델 서비스 프로세스에 속하며, 그 내용은 다음과 같습니다.
- 기본 모델 로딩: 시스템은 LLaMA 3 및 Mistral과 같은 기본적인 대형 모델을 GPU 메모리에 미리 로드합니다.
- LoRA 동적 검색: 요청을 수신한 후 Hugging Face, Predibase 또는 로컬 디렉토리에서 지정된 LoRA 어댑터를 동적으로 로드합니다.
- 어댑터 병합 활성화: 커널을 최적화하여 어댑터를 기본 모델과 실시간으로 병합하여 다중 어댑터 결합 추론을 지원합니다.
- 추론 실행 및 스트리밍 출력: 병합된 모델은 토큰 수준 스트리밍 출력을 사용하여 지연 시간을 줄이고 양자화를 결합하여 효율성과 정확성을 보장하면서 응답을 생성하기 시작합니다.
- 추론 종료 및 리소스 해제: 추론이 완료되면 어댑터가 자동으로 제거되어 비디오 메모리 리소스를 해제합니다. 이를 통해 수천 개의 미세 조정된 모델을 단일 GPU에서 효율적으로 회전하고 제공할 수 있어 효율적인 모델 회전이 지원됩니다.
OpenLoRA는 일련의 기본 최적화 방법을 통해 다중 모델 배포 및 추론의 효율성을 크게 향상시켰습니다. 핵심 기술로는 동적 LoRA 어댑터 로딩(JIT 로딩)이 있으며, 이는 비디오 메모리 사용량을 효과적으로 줄여줍니다. 텐서 병렬 처리(Tensor Parallelism)와 페이지드 어텐션(Paged Attention)은 높은 동시성과 장문 텍스트 처리를 달성합니다. 또한 다중 모델 퓨전(Multi-Adapter Merging)을 지원하여 다중 어댑터 병합 실행을 통해 LoRA 통합 추론(앙상블)을 구현합니다. 동시에 Flash Attention, 사전 컴파일된 CUDA 커널, FP8/INT8 양자화 기술을 통해 CUDA 최적화 및 양자화 지원은 추론 속도를 더욱 향상시키고 지연 시간을 단축합니다. 이러한 최적화를 통해 OpenLoRA는 성능, 확장성 및 리소스 활용도를 고려하여 단일 카드 환경에서 수천 개의 미세 조정된 모델을 효율적으로 처리할 수 있습니다.
OpenLoRA는 효율적인 LoRA 추론 프레임워크일 뿐만 아니라, 모델 추론과 Web3 인센티브 메커니즘을 긴밀하게 통합한 프레임워크로 자리매김했습니다. OpenLoRA의 목표는 LoRA 모델을 호출 가능하고, 구성 가능하며, 분할 가능한 Web3 자산으로 변환하는 것입니다.
- 모델 자산: OpenLoRA는 모델을 배포할 뿐만 아니라 미세 조정된 각 모델에 온체인 ID(모델 ID)를 부여하고 호출 동작을 경제적 인센티브와 연결하여 "호출은 이익 공유"를 달성합니다.
- 여러 LoRA의 동적 병합 + 수익 공유: 여러 LoRA 어댑터의 동적 결합 호출을 지원하여 다양한 모델을 결합하여 새로운 에이전트 서비스를 형성할 수 있습니다. 동시에, 시스템은 PoA(Proof of Attribution) 메커니즘을 기반으로 호출량에 따라 각 어댑터에 수익을 정확하게 분배할 수 있습니다.
- 롱테일 모델에 대한 "멀티 테넌트 공유 추론"을 지원합니다. 동적 로딩 및 메모리 해제 메커니즘을 통해 OpenLoRA는 단일 카드 환경에서 수천 개의 LoRA 모델을 제공할 수 있습니다. 이는 Web3의 틈새 모델 및 개인화된 AI 어시스턴트와 같은 재사용성이 높고 빈도가 낮은 호출 시나리오에 특히 적합합니다.
또한, OpenLedger는 OpenLoRA 성능 지표에 대한 향후 전망을 발표했습니다. 기존의 전체 매개변수 모델 배포와 비교했을 때, OpenLoRA의 비디오 메모리 사용량은 8~12GB로 크게 감소했습니다. 모델 전환 시간은 이론적으로 100ms 미만으로 단축될 수 있으며, 처리량은 초당 2,000개 이상의 토큰에 도달할 수 있고, 지연 시간은 20~50ms로 제어됩니다. 전반적으로 이러한 성능 지표는 기술적으로 접근 가능하지만 "상한 성능"에 가깝습니다. 실제 운영 환경에서는 하드웨어, 스케줄링 전략 및 장면 복잡성에 따라 성능이 제한될 수 있으며, "안정적인 일일 성능"보다는 "이상적인 상한 성능"으로 간주해야 합니다.
3.3 데이터넷: 데이터 주권에서 데이터 인텔리전스로
고품질의 도메인별 데이터는 고성능 모델 구축의 핵심 요소가 되었습니다. 데이터넷은 OpenLedger의 "데이터를 자산으로" 활용하는 인프라로, 특정 분야의 데이터 세트를 수집하고 관리하는 데 사용됩니다. 데이터넷은 특정 분야의 데이터를 수집, 검증 및 배포하는 탈중앙화 네트워크로, AI 모델의 학습 및 미세 조정을 위한 고품질 데이터 소스를 제공합니다. 각 데이터넷은 구조화된 데이터웨어하우스와 같으며, 기여자들은 데이터를 업로드하고 온체인 귀속 메커니즘을 통해 데이터의 추적 가능성과 신뢰성을 보장합니다. 인센티브 메커니즘과 투명한 권한 관리를 통해 데이터넷은 모델 학습에 필요한 데이터의 커뮤니티 공동 구축 및 신뢰할 수 있는 사용을 실현합니다.
데이터 주권에 초점을 맞춘 Vana와 같은 프로젝트와 달리, OpenLedger는 "데이터 수집"에만 국한되지 않고, 세 가지 모듈, 즉 데이터넷(공동 레이블 지정 및 속성 지정 데이터 세트), 모델 팩토리(코드 없는 미세 조정을 지원하는 모델 학습 도구), 그리고 OpenLoRA(추적 가능하고 구성 가능한 모델 어댑터)를 통해 데이터의 가치를 모델 학습 및 온체인 호출로 확장하여 "데이터에서 인텔리전스로"의 완전한 폐쇄 루프를 구축합니다. Vana는 "누가 데이터를 소유하는가"를 강조하는 반면, OpenLedger는 "데이터가 어떻게 학습되고, 호출되고, 보상되는지"에 중점을 두며, Web3 AI 생태계의 데이터 주권 보호 및 데이터 수익화 경로에서 핵심적인 위치를 차지합니다.
3.4 귀속 증명: 혜택 분배를 위한 인센티브 계층 재구성
기여 증명(PoA)은 OpenLedger의 핵심 메커니즘으로, 데이터 소유권과 인센티브 분배를 실현합니다. 온체인 암호화된 레코드를 통해 각 학습 데이터는 모델 출력과 검증 가능하게 연결되어 기여자가 모델 호출 시 마땅히 받아야 할 보상을 받을 수 있도록 합니다. 데이터 소유권 및 인센티브 프로세스는 다음과 같습니다.
- 데이터 제출: 사용자는 구조화된 도메인별 데이터 세트를 업로드하고 체인에서 소유권을 확인합니다.
- 영향 평가: 시스템은 데이터 특징의 영향과 기여자의 평판을 기반으로 각 추론의 가치를 평가합니다.
- 교육 검증: 교육 로그에는 각 데이터의 실제 사용이 기록되어 기여도가 검증 가능한지 확인합니다.
- 인센티브 분배: 데이터의 영향에 따라 기여자에게 결과와 연결된 토큰 보상이 제공됩니다.
- 품질 거버넌스: 모델 학습의 품질을 보장하기 위해 품질이 낮거나 중복되거나 악성인 데이터에 대한 처벌을 실시합니다.
블록체인 범용 인센티브 네트워크의 스코어링 메커니즘과 결합된 Bittensor 서브넷 아키텍처와 비교했을 때, OpenLedger는 모델 수준에서 가치 확보 및 수익 공유 메커니즘에 중점을 둡니다. PoA는 인센티브 분배 도구일 뿐만 아니라 투명성, 소스 추적 및 다단계 귀속을 위한 프레임워크이기도 합니다. PoA는 체인에서 데이터 업로드, 모델 호출 및 지능형 에이전트 실행의 전체 프로세스를 기록하여 종단 간 검증 가능한 가치 경로를 구축합니다. 이 메커니즘을 통해 각 모델 호출을 데이터 제공자와 모델 개발자까지 추적하여 온체인 AI 시스템에서 진정한 "가치 합의" 및 "수익"을 달성할 수 있습니다.
RAG(Retrieval-Augmented Generation)는 검색 시스템과 생성 모델을 결합한 AI 아키텍처입니다. 기존 언어 모델의 "폐쇄된 지식"과 "조작" 문제를 해결하는 것을 목표로 합니다. 외부 지식 기반을 도입하여 모델 생성 기능을 향상시키고, 결과물을 더욱 현실적이고, 설명 가능하며, 검증 가능하게 만듭니다. RAG Attribution은 OpenLedger가 검색 증강 생성 시나리오에서 구축한 데이터 귀속 및 인센티브 메커니즘입니다. 모델 결과물의 내용이 추적 가능하고 검증 가능하며, 기여자에게 인센티브를 제공하여 궁극적으로 신뢰할 수 있는 생성과 데이터 투명성을 달성합니다. 이 프로세스는 다음과 같습니다.
- 사용자가 질문하면 → 데이터가 검색됩니다. 질문을 받으면 AI가 OpenLedger 데이터 인덱스에서 관련 콘텐츠를 검색합니다.
- 데이터를 호출하고 답변을 생성합니다. 검색된 콘텐츠를 사용하여 모델 답변을 생성하고, 호출 동작을 체인에 기록합니다.
- 기여자에게 보상이 지급됩니다. 데이터가 사용되면 기여자는 데이터 양과 관련성에 따라 계산된 인센티브를 받습니다.
- 인용을 통한 결과 생성: 모델 출력에는 원본 데이터 소스에 대한 링크가 포함되어 있어 투명한 Q&A와 검증 가능한 콘텐츠가 가능합니다.

OpenLedger의 RAG Attribution을 통해 모든 AI 답변을 실제 데이터 출처까지 추적할 수 있으며, 기여자는 인용 빈도에 따라 보상을 받습니다. 이를 통해 "지식에는 출처가 있으며, 이를 통해 호출될 때 수익을 창출할 수 있다"는 사실을 깨닫게 됩니다. 이 메커니즘은 모델 출력의 투명성을 향상시킬 뿐만 아니라, 고품질 데이터 기여에 대한 지속 가능한 인센티브 순환 구조를 구축하며, 신뢰할 수 있는 AI 및 데이터 자산화를 촉진하는 핵심 인프라입니다.
4. OpenLedger 프로젝트 진행 상황 및 생태계 협력
현재 OpenLedger는 테스트 네트워크를 출시했습니다. 데이터 인텔리전스 레이어(Data Intelligence Layer)는 OpenLedger 테스트 네트워크의 첫 단계로, 커뮤니티 노드들이 공동으로 구동하는 인터넷 데이터웨어하우스를 구축하는 것을 목표로 합니다. 이러한 데이터는 선별, 강화, 분류 및 구조화되어 OpenLedger에서 도메인 AI 모델을 구축하기 위한 대규모 언어 모델(LLM)에 적합한 보조 인텔리전스를 형성합니다. 커뮤니티 구성원은 에지 디바이스 노드를 운영하여 데이터 수집 및 처리에 참여할 수 있습니다. 노드는 로컬 컴퓨팅 리소스를 사용하여 데이터 관련 작업을 수행하고, 참여자는 활동 및 작업 완료에 따라 포인트를 받습니다. 이러한 포인트는 향후 OPEN 토큰으로 전환되며, 구체적인 교환 비율은 토큰 생성 이벤트(TGE) 전에 발표될 예정입니다.
OpenLedger 테스트넷은 현재 다음 세 가지 유형의 수익 메커니즘을 제공합니다.
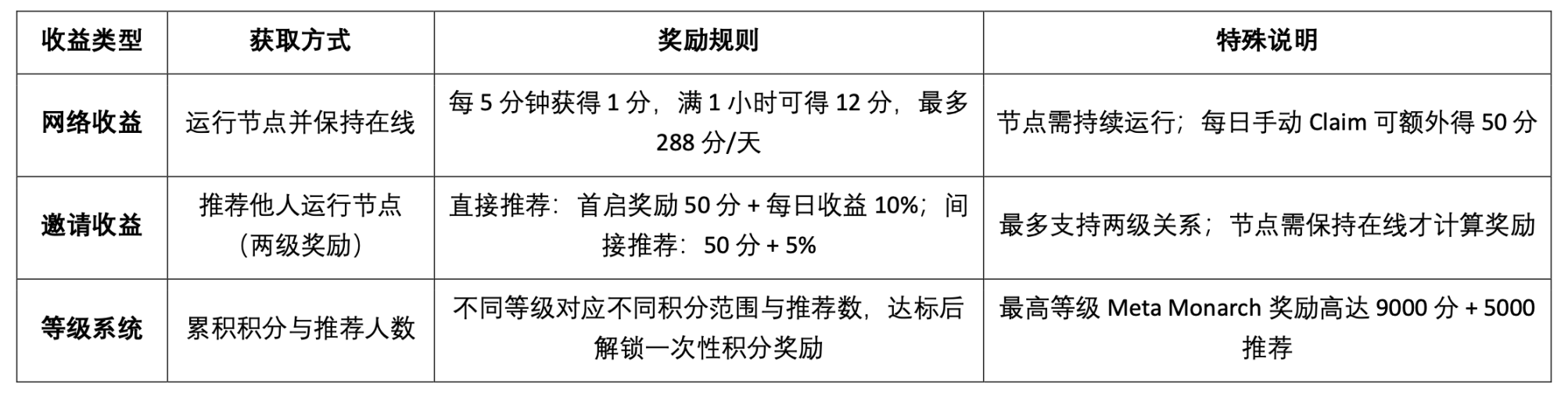
Epoch 2 테스트넷은 Datanets 데이터 네트워크 메커니즘 출시에 중점을 두고 있습니다. 이 단계는 허용 목록에 등록된 사용자만 참여할 수 있으며, 사전 평가를 완료해야 과제를 완료할 수 있습니다. 과제에는 데이터 검증, 분류 등이 포함됩니다. 완료 후에는 정확도와 난이도에 따라 점수가 부여되며, 리더보드를 통해 높은 수준의 기여를 장려합니다. 공식 웹사이트는 현재 다음과 같은 데이터 모델을 제공하여 참여를 유도합니다.
OpenLedger의 장기 로드맵 계획은 데이터 수집 및 모델 구축에서 에이전트 생태계로 이동하여 "자산으로서의 데이터, 서비스로서의 모델, 지능형 개체로서의 에이전트"라는 완전한 분산형 AI 경제 폐쇄 루프를 점진적으로 실현합니다.
- 1단계 데이터 인텔리전스 계층: 커뮤니티는 에지 노드를 운영하여 인터넷 데이터를 수집하고 처리하고, 지속적으로 업데이트되는 고품질의 데이터 인텔리전스 인프라 계층을 구축합니다.
- 2단계 커뮤니티 기여: 커뮤니티는 데이터 검증 및 피드백에 참여하여 신뢰할 수 있는 골든 데이터 세트를 공동으로 생성하고 모델 학습을 위한 고품질 입력을 제공합니다.
- 3단계 · 모델 구축 및 청구: 골든 데이터를 기반으로 사용자는 전담 모델을 학습하고 소유권을 확인하여 모델 자산화 및 합성 가능한 가치 해제를 실현할 수 있습니다.
- 4단계 · 에이전트 구축: 커뮤니티는 게시된 모델을 기반으로 개인화된 에이전트를 만들어 다중 시나리오 배포와 지속적인 협업적 진화를 달성할 수 있습니다.
OpenLedger의 생태적 파트너는 컴퓨팅 파워, 인프라, 툴 체인, AI 애플리케이션을 포괄합니다. Aethir, Ionet, 0G와 같은 분산 컴퓨팅 파워 플랫폼이 파트너로 포함됩니다. AltLayer, Etherfi, EigenLayer의 AVS는 기반 확장 및 결제 지원을 제공하고, Ambios, Kernel, Web3Auth, Intract와 같은 툴은 신원 인증 및 개발 통합 기능을 제공합니다. AI 모델 및 에이전트 측면에서 OpenLedger는 Giza, Gaib, Exabits, FractionAI, Mira, NetMind 및 기타 프로젝트와 협력하여 모델 배포 및 에이전트 구현을 공동으로 촉진하고, 개방적이고 구성 가능하며 지속 가능한 Web3 AI 생태계를 구축하고 있습니다.
지난 한 해 동안 OpenLedger는 Token2049 싱가포르, Devcon 태국, Consensus 홍콩, 그리고 ETH 덴버에서 Crypto AI를 주제로 한 DeAI Summit을 개최하여 탈중앙화 AI 분야의 여러 핵심 프로젝트와 기술 리더들을 초대했습니다. 고품질 산업 행사를 지속적으로 기획할 수 있는 몇 안 되는 인프라 프로젝트 중 하나인 OpenLedger는 DeAI Summit을 통해 개발자 커뮤니티와 Web3 AI 기업 생태계에서 브랜드 인지도와 전문성을 강화했으며, 이후 생태계 확장 및 기술 구현을 위한 탄탄한 산업 기반을 마련했습니다.
5. 자금 조달 및 팀 배경
OpenLedger는 2024년 7월 Polychain Capital, Borderless Capital, Finality Capital, Hashkey를 비롯한 여러 유명 엔젤 투자자와 함께 1,120만 달러 규모의 시드 라운드를 완료했습니다. 투자에는 Sreeram Kannan(EigenLayer), Balaji Srinivasan, Sandeep(Polygon), Kenny(Manta), Scott(Gitcoin), Ajit Tripathi(Chainyoda), Trevor 등이 참여했습니다. 이 자금은 주로 OpenLedger의 AI 체인 네트워크 구축, 모델 인센티브 메커니즘, 데이터 인프라 계층, 에이전트 애플리케이션 생태계의 포괄적인 구현을 촉진하는 데 사용될 예정입니다.

OpenLedger는 OpenLedger의 핵심 기여자이자 AI/ML 및 블록체인 기술에 대한 탄탄한 기술 기반을 갖춘 샌프란시스코 기반 기업가인 램 쿠마르(Ram Kumar)가 설립했습니다. 그는 시장 통찰력, 기술 전문성, 그리고 전략적 리더십을 결합하여 프로젝트에 기여합니다. 램은 연 매출 3,500만 달러 이상의 블록체인 및 AI/ML R&D 회사를 공동 이끌었으며, 월마트 자회사와의 전략적 합작 투자를 포함한 주요 협업을 주도하는 데 중요한 역할을 했습니다. 그는 다양한 산업 분야에서 실제 애플리케이션 구현을 가속화하기 위한 생태계 구축 및 고효율 협업에 중점을 두고 있습니다.
6. 토큰 경제 모델 설계 및 거버넌스
OPEN은 OpenLedger 생태계의 핵심 기능 토큰으로, 네트워크 거버넌스, 거래 운영, 인센티브 분배, 그리고 AI 에이전트 운영을 가능하게 합니다. 또한, 체인 내 AI 모델과 데이터의 지속 가능한 순환을 구축하는 경제적 기반을 제공합니다. 공식 토큰 이코노미는 아직 초기 설계 단계에 있으며, 세부 사항은 아직 완전히 확정되지 않았습니다. 하지만 프로젝트가 토큰 생성 이벤트(TGE) 단계에 접어들면서 아시아, 유럽, 중동 지역에서 커뮤니티 성장, 개발자 활동, 그리고 애플리케이션 시나리오 실험이 가속화되고 있습니다.
- 거버넌스 및 의사 결정: OPEN 보유자는 모델 자금 조달, 에이전트 관리, 프로토콜 업그레이드 및 자금 사용에 대한 거버넌스 투표에 참여할 수 있습니다.
- 거래 연료 및 수수료 지불: OpenLedger 네트워크의 기본 가스 토큰으로, AI 기반 맞춤형 요금 메커니즘을 지원합니다.
- 인센티브 및 보상 제공: 고품질 데이터, 모델 또는 서비스를 제공하는 개발자는 사용 영향에 따라 OPEN 수익을 받을 수 있습니다.
- 크로스체인 브리징 기능: OPEN은 L2 ↔ L1(이더리움) 브리징을 지원하여 모델과 에이전트의 멀티체인 가용성을 향상시킵니다.
- AI 에이전트 스테이킹 메커니즘: AI 에이전트는 실행을 위해 OPEN 스테이킹을 해야 합니다. 성능이 저하되면 효율적이고 안정적인 서비스 제공을 위해 스테이킹이 감소합니다.
영향력이 보유 코인 수에 따라 결정되는 많은 토큰 거버넌스 프로토콜과 달리, OpenLedger는 기여 가치에 기반한 거버넌스 메커니즘을 도입합니다. OpenLedger의 투표 가중치는 단순한 자본 가중치가 아닌 실제 창출 가치와 연관되며, 모델 및 데이터셋의 구축, 최적화 및 활용에 참여하는 기여자를 우선시합니다. 이러한 아키텍처 설계는 거버넌스의 장기적인 지속 가능성을 확보하고, 투기적 행위가 의사 결정을 지배하는 것을 방지하며, "투명하고 공정하며 커뮤니티 중심적인" 탈중앙화 AI 경제라는 OpenLedger의 비전에 부합합니다.
VII. 데이터, 모델 및 인센티브 시장 구조 및 경쟁 제품 비교
"Payable AI" 모델 인센티브 인프라인 OpenLedger는 데이터 기여자와 모델 개발자에게 검증 가능하고, 귀속 가능하며, 지속 가능한 가치 실현 경로를 제공하는 데 전념합니다. 온체인 배포, 호출 인센티브, 지능형 에이전트 결합 메커니즘을 중심으로 차별화된 특성을 갖춘 모듈 시스템을 구축하여 현재 Crypto AI 트랙에서 독보적인 위치를 차지하고 있습니다. 전체 아키텍처에서 완전히 중복되는 프로젝트는 없지만, OpenLedger와 여러 대표 프로젝트는 프로토콜 인센티브, 모델 경제성, 데이터 권한 확인과 같은 핵심 측면에서 높은 비교 가능성과 협업 잠재력을 보여줍니다.
프로토콜 인센티브 계층: OpenLedger 대 Bittensor
비텐서는 현재 가장 대표적인 탈중앙화 AI 네트워크입니다. 서브넷과 스코어링 메커니즘을 기반으로 하는 다중 역할 협업 시스템을 구축했으며, 모델, 데이터, 정렬 노드 등의 참여자에게 $TAO 토큰을 통해 인센티브를 제공합니다. 이와 대조적으로, 오픈레저는 온체인 배포 및 모델 호출의 수익 분배에 중점을 두고 경량 아키텍처와 에이전트 협업 메커니즘을 강조합니다. 두 네트워크의 인센티브 논리는 겹치지만, 목표 수준과 시스템 복잡성은 분명히 다릅니다. 비텐서는 일반적인 AI 역량 네트워크 기반에 중점을 두는 반면, 오픈레저는 AI 애플리케이션 계층의 가치 창출 플랫폼으로 자리매김했습니다.
모델 귀속 및 호출 인센티브: OpenLedger 대 Sentient
Sentient가 제안한 "OML(개방형, 수익화 가능, 충성도 높은) AI" 개념은 모델 확인 및 커뮤니티 소유권 측면에서 OpenLedger의 아이디어와 유사하며, 모델 핑거프린팅을 통한 소유권 식별 및 수익 추적 실현을 강조합니다. 차이점은 Sentient가 모델의 학습 및 생성 단계에 더 중점을 두는 반면, OpenLedger는 모델의 온체인 배포, 호출 및 수익 공유 메커니즘에 중점을 둔다는 것입니다. 두 개념은 각각 AI 가치 사슬의 상류와 하류에 위치하며, 상호 보완적입니다.
모델 호스팅 및 신뢰할 수 있는 추론 플랫폼: OpenLedger 대 OpenGradient
OpenGradient는 TEE 및 zkML 기반의 안전한 추론 실행 프레임워크 구축, 분산형 모델 호스팅 및 추론 서비스 제공, 그리고 신뢰 기반 운영 환경에 중점을 둡니다. 이와 대조적으로, OpenLedger는 온체인 배포 이후의 가치 확보 경로를 강조하며, Model Factory, OpenLoRA, PoA, Datanets를 중심으로 "훈련-배포-호출-수익 공유"의 완전한 폐쇄 루프를 구축합니다. 두 모델은 서로 다른 모델 수명 주기를 가지고 있습니다. OpenGradient는 운영 신뢰성에 중점을 두는 반면, OpenLedger는 수익 인센티브와 생태계 조합에 중점을 두며, 상호 보완적인 공간을 제공합니다.
크라우드소싱 모델과 가치 평가 인센티브: OpenLedger 대 CrunchDAO
CrunchDAO는 금융 예측 모델의 탈중앙화 경쟁 메커니즘에 중점을 두고, 커뮤니티가 모델을 제출하고 성과에 따라 보상을 받도록 장려하며, 이는 특정 수직 시나리오에 적합합니다. 반면, OpenLedger는 구성 가능한 모델 시장과 통합 배포 프레임워크를 제공하며, 더 폭넓은 다양성과 네이티브 온체인 수익화 기능을 갖추고 있어 다양한 유형의 지능형 시나리오 확장에 적합합니다. 두 플랫폼은 모델 인센티브 논리 측면에서 상호 보완적이며 시너지 잠재력을 가지고 있습니다.
커뮤니티 중심의 경량 모델 플랫폼: OpenLedger vs. Assisterr
Assisterr은 Solana 기반으로 구축되어 커뮤니티가 소규모 언어 모델(SLM)을 개발하도록 장려하고, 코드 프리 도구와 $sASRR 인센티브 메커니즘을 통해 사용 빈도를 높입니다. 이와 대조적으로 OpenLedger는 데이터-모델-호출의 폐쇄 루프 추적성과 수익 공유 경로를 강조하며, 권한 증명(PoA)을 사용하여 세밀한 인센티브 할당을 구현합니다. Assisterr은 임계값이 낮은 모델 협업 커뮤니티에 더 적합한 반면, OpenLedger는 재사용 가능하고 구성 가능한 모델 인프라 구축에 전념합니다.
모델 팩토리: OpenLedger 대 Pond
Pond와 OpenLedger는 모두 "모델 팩토리" 모듈을 제공하지만, 위치 지정 및 서비스 객체는 상당히 다릅니다. Pond는 주로 알고리즘 연구자와 데이터 과학자를 위해 그래프 신경망(GNN) 기반 온체인 동작 모델링에 중점을 두고 경쟁 메커니즘을 통해 모델 개발을 촉진합니다. Pond는 모델 경쟁에 더 치중하는 반면, OpenLedger는 언어 모델 미세 조정(예: LLaMA, Mistral)을 기반으로 개발자와 비전문가 사용자를 지원하고, 코드 없는 경험과 온체인 자동 수익 공유 메커니즘을 강조하며, 데이터 기반 AI 모델 인센티브 생태계를 구축합니다. OpenLedger는 데이터 협력에 더 치중합니다.
신뢰할 수 있는 추론 경로: OpenLedger 대 Bagel
베이글(Bagel)은 LoRA 미세 조정 모델과 영지식 증명(ZKP) 기술을 활용하여 오프체인 추론 프로세스의 암호화 검증 가능성을 확보하고 추론 실행의 정확성을 보장하는 ZKLoRA 프레임워크를 출시했습니다. OpenLedger는 OpenLoRA를 통해 LoRA 미세 조정 모델의 확장 가능한 배포 및 동적 호출을 지원하는 동시에, 추론 검증 문제를 다각도로 해결합니다. 각 모델 출력에 귀속 증명(PoA)을 첨부하여 추론에 사용되는 데이터의 출처와 그 영향을 추적합니다. 이를 통해 투명성을 향상시킬 뿐만 아니라, 고품질 데이터 제공자에게 보상을 제공하고 추론 프로세스의 해석 가능성과 신뢰성을 향상시킵니다. 간단히 말해, 베이글은 계산 결과의 정확성 검증에 중점을 두는 반면, OpenLedger는 귀속 메커니즘을 통해 추론 프로세스의 책임 추적 및 해석 가능성을 확보합니다.
데이터 측 협업 경로: OpenLedger 대 Sapien/FractionAI/Vana/Irys
Sapien과 FractionAI는 탈중앙화 데이터 주석 서비스를 제공하는 반면, Vana와 Irys는 데이터 주권 및 확인 메커니즘에 중점을 둡니다. OpenLedger는 Datanets + PoA 모듈을 사용하여 고품질 데이터 사용을 추적하고 체인에서 인센티브를 분배합니다. 전자는 데이터 공급의 상류 역할을 할 수 있으며, OpenLedger는 가치 분배 및 콜센터 역할을 합니다. 세 회사는 경쟁 관계보다는 데이터 가치 사슬에서 좋은 시너지 효과를 발휘합니다.

요약하자면, OpenLedger는 현재 Crypto AI 생태계에서 "온체인 모델 자산화 및 호출 인센티브"라는 중간 계층의 역할을 수행합니다. OpenLedger는 훈련 네트워크와 데이터 플랫폼을 상향 연결할 뿐만 아니라, 에이전트 계층과 터미널 애플리케이션을 하향식으로 지원합니다. OpenLedger는 모델 가치 공급과 현장 호출을 연결하는 핵심 브리지 프로토콜입니다.
8. 결론 | 데이터에서 모델로, AI 체인 수익화의 길
OpenLedger는 Web3 환경에서 "모델을 자산으로" 활용하는 인프라 구축에 전념하고 있습니다. 온체인 배포, 호출 인센티브, 소유권 확인 및 지능형 에이전트 결합을 완벽하게 폐쇄형 루프로 구축함으로써, AI 모델을 진정으로 추적 가능하고 수익화 가능하며 협업적인 경제 시스템으로 최초로 구현합니다. Model Factory, OpenLoRA, PoA, Datanets를 기반으로 구축된 OpenLedger의 기술 시스템은 개발자에게 낮은 임계치의 학습 도구를 제공하고, 데이터 기여자의 수익 소유권을 보장하며, 애플리케이션 당사자에게 결합 가능한 모델 호출 및 수익 공유 메커니즘을 제공하여 AI 가치 사슬에서 오랫동안 소외되어 온 "데이터" 및 "모델" 리소스를 완전히 활성화합니다.
OpenLedger는 웹 3.0 환경에서 HuggingFace, Stripe, Infura를 융합한 형태에 가깝습니다. AI 모델을 위한 호스팅, 통화료 청구, 온체인 프로그래밍 가능 API 인터페이스를 제공합니다. 데이터 자산화, 모델 자율성, 에이전트 모듈화의 가속화된 발전을 통해 OpenLedger는 "Payable AI" 모델 하에서 중요한 허브 AI 체인으로 자리매김할 것으로 예상됩니다.

