
2026 年2 月,小紅書發佈公告,要求AI 產生合成內容必須主動標識,未標識內容將被限制分發。三個多月後,一個名為guizang-social-card-skill的開源專案出現在GitHub 上,專門產生小紅書3:4 圖文和公眾號封面。它的技術路徑有一個異常的選擇:不用任何AI 模型產生影像像素,整個畫面靠著HTML+CSS 渲染,配圖來自Unsplash 等實拍圖庫檢索。輸出的不是“AI 生成圖像”,而是一張瀏覽器引擎光柵化的網頁截圖。
這個選擇對應著一個具體變化。自2026 年以來,小紅書已上線音畫辨識模型,透過分析圖片像素分佈規律和音訊特徵來判斷AIGC 內容。同期處置AI 託管帳號超80 萬個、AI 造假筆記近15 萬篇。對於需要高頻產出圖文的內容創作者,用Midjourney 或Canva AI 產生的圖片,被偵測並標記的機率持續上升。藏師傅的Skill 選了另一條路:讓AI 做版式決策,把最終像素交給渲染引擎和實拍圖庫。
這是一次有意識的技術繞行。但這套方案能走多遠,取決於平台對「AI 生成合成內容」一詞的定義彈性大小。
28 個版式骨架,AI 負責的是排版邏輯而非繪畫
藏師傅本名歸藏,先前發布過guizang-ppt-skill ,同樣是面向圖文排版場景的AI 工具。這次的social-card-skill 定位更聚焦:面向小紅書3:4 圖文、公眾號1:1 和21:9 封面,輸出解析度分別為1080×1440、1080×1080 和2100×900。 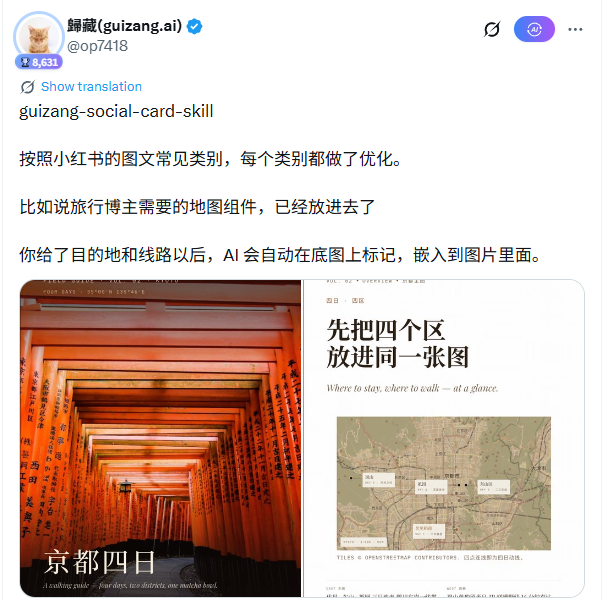
技術架構上,這個Skill 內建28 個版式骨架,分為兩套視覺系統:Editorial(雜誌風格,16 個版式)和Swiss(瑞士國際主義風格,12 個版式),附帶10 套主題配色預設。使用者輸入目的地、行程或筆記主題後,AI 負責選擇適當的版式骨架、決定文字位置、處理地圖示註參數,然後把所有設計決策寫成HTML+CSS。 Playwright 渲染引擎接手後續環節,逐頁截圖輸出PNG。
一個對旅行部落客特別有用的組件是地圖模組。它使用MapLibre 加載OpenStreetMap 的真實瓦片,支援多個地點標記和連線。使用者只需提供城市或景點名稱,AI 自動產生標註的底圖並嵌入排版。與之搭配的圖源工作流程有明確的優先順序:使用者提供的實拍照片最優先;沒有使用者圖表時,依Unsplash → Pexels → Flickr CC → Wallhaven 的順序自動擷取配圖。 
整個流程分七步驟執行:Intake(接收輸入)→ Style & Theme(確定風格與主題)→ Layout Selection(版式選擇)→ Asset Prep(素材準備)→ Compose & Render(排版與渲染)→ Deliver & Review(輸出與複核)→ Iterate(迭代修改)。每一步都記錄在task 目錄的.poster 檔案中。批量出圖時運行node render.mjs ,Playwright 逐一渲染。另一張校驗腳本validate-social-deck.mjs在真實瀏覽器環境中測量DOM 元素,偵測文字溢位、字號超出上限、footer 元件碰撞等排版事故。
這套機制的設計目標很清楚:像印刷排版軟體一樣精確可控,而不是像擴散模型一樣自由但不可預測。代價是創意自由度被收束在28 個格子裡。對於依賴個人攝影風格、手繪元素或不規則拼貼的創作者,這些版式骨架提供的不是效率提升,而是設計限制。
使用門檻方面,CLI 版本需要安裝Playwright、Node 環境,同時取得Claude Code 或Codex 的API 權限。另有一個網頁版入口xiaohongshu.guizang.ai面向非開發用戶,但功能完整度與CLI 版是否一致,尚未有公開對比資訊。開發者發布的幾條X 平台推文和反覆更新的README 說明這個專案仍在快速迭代中。
像素不來自生成模型,但合規不等於長期安全
小紅書的AI 內容偵測邏輯,根據公開資訊和技術資料分析,核心依賴音畫辨識模型。這個模型透過分析圖片的像素分佈規律來判斷內容是否來自AI 生成模型。擴散模型和GAN 在生成影像時會在像素層面留下特定的統計特徵,這些特徵與相機感測器捕捉的自然光影、鏡頭畸變、雜訊模式存在差異。音畫辨識模型的訓練目標,正是捕捉這種統計規律上的不一致。
藏師傅Skill 的規避邏輯建立在一個關鍵區分上:它輸出的圖片像素不來自任何生成模型。 HTML 渲染引擎對CSS 樣式進行光柵化,產生的像素分佈特徵更接近瀏覽器介面截圖或桌面排版軟體的輸出。照片部分來自Unsplash 等圖庫的真人實拍素材,這些圖片由相機拍攝、經過人工後製處理,不攜帶擴散模型痕跡。 
但這個區分成立的前提,是平台對「AI 生成合成內容」的定義範圍剛好卡在「AI 模型產生像素」這條線上。小紅書的官方公告用的是「AI 生成合成內容」這個表述,原文涵蓋範圍並不窄。一旦平台將定義擴展到“AI 輔助設計的程式渲染輸出”,或者將HTML 光柵化圖片的瀏覽器渲染特徵納入識別模型訓練集,這套方案當前的技術紅利就會消失。
平台有擴展定義的技術基礎和治理動機。音畫辨識模型本身在持續迭代。如果訓練資料中納入大量HTML 渲染圖片與AI 生成圖片的對比樣本,模型可以學習區分「瀏覽器字體渲染的subpixel 抗鋸齒特徵」與「GAN 在文字生成時的不規則像素區塊」。目前沒有公開資訊表明小紅書已啟動這個方向的訓練,但從模型能力邊界看,這種擴展在技術上成立。
更需要注意的事實是小程式託管相關的合規要素。目前沒有看到任何官方文件說明該Skill 連結了模型備案號或完成了相關合規登記。如果平台在內容審核流程中增加對出圖工具鏈的追溯要求,缺乏備案資訊可能成為新的攔截點。
API 模板引擎、平台自訂工具與HTML 渲染,正在拉出三個分岔路
觀察市面上為社群媒體產生圖片的工具,會發現它們正在分化為三條不同的科技路線。每一條面臨不同的審核風險結構。
AI 模型直接出圖。這條路代表是Canva AI 於2026 年4 月發布的Magic Design 功能,它從文字提示詞直接產生包含AI 視覺元素的設計稿。 Midjourney、DALL·E 等模型所產生的圖片同樣屬於這個範疇。問題明確:這些圖片是音畫辨識模型的主要偵測目標。 Canva 的因應方式是鼓勵透明標註,而非規避偵測。小紅書上,AI 模型出圖的貼文被標註後是否會降低推薦權重,沒有公開數據可以證實,但平台對「未標識AI 內容限制分發」的表述已是既定政策。每次擴散模型版本更新,像素統計特徵可能會發生變化,對應的偵測模型也會同步迭代,創作者面對的是一個持續移動的目標。
API 模板引擎渲染。 Bannerbear 是這個路線的典型。使用者在設計器中製作模板,透過REST API 傳入JSON 資料修改圖層變量,服務端渲染輸出PNG 或JPG。它的核心同樣是“程式渲染”而非“模型生成像素”,輸出不含擴散模型痕跡。與藏師傅Skill 的差異在於:Bannerbear 的模板依賴人工設計,AI 不參與版式決策;藏師傅Skill 讓Claude 直接讀寫HTML,版式選擇權交給AI。 Bannerbear 方案的風險在另一個維度:大量帳號使用相同模板、相同配色、相同字體產出圖文時,即使每張圖都不是AI 生成,也會在平台側觸發「程式化批量生產」模式識別。反垃圾規則的觸發條件不完全等同於AI 偵測,但對大量營運帳號的創作者而言,結果同樣是分發受限。
平台客製化生成。 Pin Generator 專為Pinterest 設計,自動產生符合平台演算法偏好的Pin 圖。這個路線的核心不是規避,而是完全適配——尺寸、視覺風格、發布節奏都對齊平台規範。優點是審核風險最低,缺點也很明顯:工具能力綁死在平台規則上,Pinterest 調整演算法或限制第三方API 呼叫時,工具直接失效。對照藏師傅Skill,前者屬於平台專屬工具,後者是跨平台通用方案。平台專屬更安全但更脆弱,跨平台通用更靈活但更複雜,這是一組在AI 工具領域反覆出現的取捨。
三條路的風險結構各不相同。 AI 出圖最自由但每次更新都在回應新的偵測模型。模板引擎最穩定但可能被反垃圾規則誤傷。 HTML 渲染走在這兩者之間:版式由AI 靈活控制,像素交給瀏覽器和實拍素材,規避的是「AI 生成像素」這一層的偵測,但無法應對平台語意層面的規則擴展。
版式系統的上限,不在程式碼裡而在內容類型裡
28 個版式骨架涵蓋了雜誌風和瑞士風兩種主流視覺系統。對於需要展示地圖路線、時間軸、多日行程的旅遊部落客來說,這套系統匹配度很高。地圖標註和行程連線是這些筆記的核心訊息,版式骨架把訊息結構化了,同時保持了排版的專業感。
但小紅書的內容生態遠比旅行攻略豐富。穿搭筆記依賴個人攝影風格和色彩調性,美妝測評需要高清微距照片和產品對比圖,生活風格類內容大量使用多圖拼貼和手寫標註。這些內容類型的「排版」不是訊息的結構化呈現,而是個人美感和情緒的表達。 28 個版式骨架在這種場景裡不是工具,是約束。 
技術層面的限制同樣真實。目前支援1080×1440(小紅書3:4)、2100×900(公眾號21:9)和1080×1080(公號1:1)三種尺寸。抖音9:16 垂直螢幕封面、B 站16:9 橫屏封面不支援。圖庫依賴Unsplash 和Pexels,這兩個平台的素材偏向高品質攝影,適合旅行、風景、城市建築的配圖需求。但美食特寫、化妝品擺拍、穿搭單品這類垂直內容的高頻素材,在這些圖庫中的覆蓋度有限。使用者圖優先的策略可以部分緩解這個問題,前提是創作者本身有足夠的實拍素材累積。
校驗機制是一把雙面刃。 validate-social-deck.mjs 能在出圖前攔截排版事故,保證100 次批量渲染不出錯。這在需要日更幾十張圖的營運場景中是效率保障。但它也意味著任何不符合預設版式規則的設計都會被腳本拒絕。想要在標準版式中加上一個傾斜的文字裝飾或自訂邊距的創作者,不能像在Canva 裡那樣隨手拖曳調整,需要直接編輯HTML 和CSS 原始碼。
本機部署門檻是另一個分層點。能跑Playwright 和Node 腳本的創作者,可以深入版式骨架和渲染腳本做客製化。但對於大部分小紅書部落客,能接觸到的是網頁版介面的功能子集。這兩類用戶從這個Skill 獲得的實際價值差距很大。開源專案的核心用戶群是願意折騰、有技術背景的創作者和開發者,而非普通內容生產者的「一鍵出圖」需求。
沒有萬能答案,但技術路線的分化本身已經說明問題
一個小紅書旅行部落客面對三種選擇:用Midjourney 產生插畫風格的行程圖,承擔被標註和降權的風險;用Bannerbear 設定好模板每天批量灌入數據,承擔模板同質化帶來的反垃圾風險;或者用藏師傅的Skill,讓AI 選擇版式後用HTML 渲染出內容,承擔出內容。沒有安全牌,只有不同風險結構的組合。
這個格局本身在傳遞一個訊息:平台與AI 工具之間的對抗迭代已經開始。每一次平台更新檢測模型,都會有一批工具的技術紅利期結束。每一次有新工具找到繞過路線,平台又會調整策略。這不是一個會收斂到穩定狀態的過程。 HTML 渲染方案的有效期,取決於小紅書音畫識別模型的訓練方向是繼續聚焦“擴散模型像素特徵”,還是擴展到“所有非原生攝影像素”。
對內容創作者來說,區分「AI 輔助」和「AI 替代」變得有實際意義。平台態度已經明確:鼓勵AI 作為創意放大器,反對用AI 替代人進行低質批量生產。藏師傅Skill 中,AI 做的是排版決策而非內容生成,照片是實拍的,版面是人類設計師預設的骨架。這恰好落在「AI 輔助」的區間。那些從文案到圖片全部用生成模型產出的圖文,才是平台明確要打擊的對象。
這種區隔是否會成為平台審核的操作性標準,目前還不確定。但工具開發者已經在用技術選擇回應這個定義了。



