
一波未平一波又起。当人们还沉浸在与ChatGPT“导师”对话的魅力之中,openAI又放出了一个大招——GPT-4。
GPT-4的定位是什么?先来看看openAI自己是怎么形容它的:“我们创建了GPT-4,这是OpenAI在扩展深度学习方面的里程碑。GPT-4是一个大型多模态模型(接受图像和文本输入,返回文本输出),虽然在许多现实世界场景中它的能力不如人类,但在各类专业和学术领域到达了人类的基准。”其中openAI很谦虚地表达了自己在日常语境中的劣势,但是后者的陈述却体现了openAI的自信——部分普通人,很难在每个专业的领域都能达到对应的基准。前后对比之下我们可以意识到,GPT-4的方向绝不是在短期内达到与人一样自然的对话,其定位是一款能给绝大部分人在专业领域中提供知识增量的产品。
GPT-4另外一个特征是多模态。人工智能正在从文本、语音、视觉等单模态智能,向着多种模态融合的通用人工智能方向发展。“基于多模态的预训练大模型将成为人工智能基础设施”,这一观点已成为业内共识。GPT-4将实现图像、文本转化为统一知识表示,并支持图片作为输入。
1
GPT-4 Vs. ChatGPT
长江后浪推前浪。当我们觉得ChatGPT足够惊艳,足够可用的时候,GPT-4已经在很多方面赶超ChatGPT。
图片输入和分析能力
最为直观的便是上文提到的支持图片输入(Visual Input),GPT-4可以后续地生成标题、分类和分析。当用户输入食材原料,并询问系统可以用这些原料做什么的时候,GPT-4可以识别图中的物品,并且告诉你有多种选择包括华夫饼、法式吐司、煎蛋、布丁等等。GPT还可以做物理题目,有点难以置信,竟然可以“理解”物理中复杂的示意图。

而当用户输入以下搞笑的图片,要求GPT-4一幅一幅的介绍,并说出它为什么搞笑,GPT-4的表现令人眼前一亮,它成功地识别了图片之间的间隔,准确描述每幅图片表达的含义,最终揭示了整组图片暗含的有趣之处。

长文本处理能力
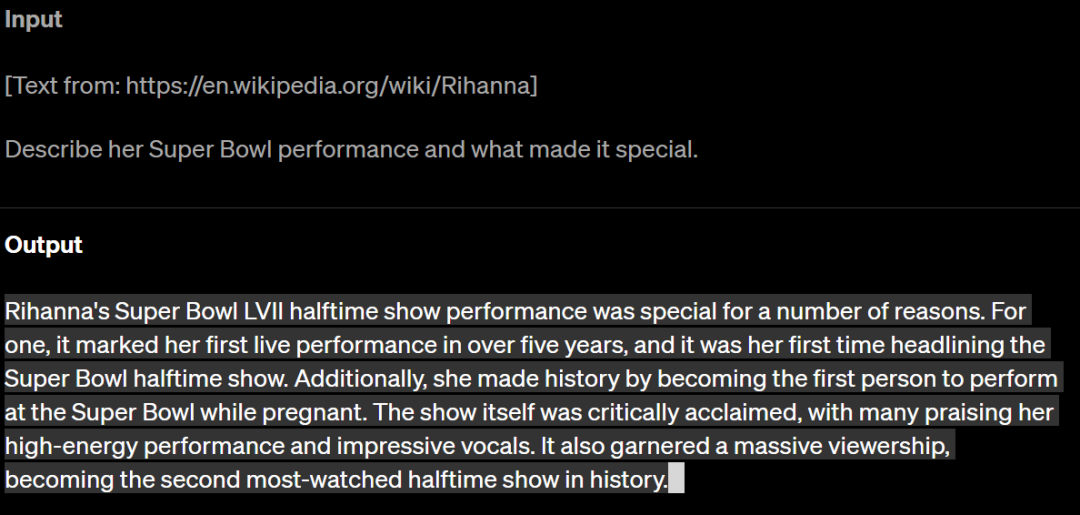
GPT-4 能够处理超过25,000个字词的文本,允许使用长文本的内容创建、扩展对话以及进行文档检索、分析任务。在样例中用户引用了外部长文本网页并且让GPT-4进行分析,这种长文本的进一步的适配可以方便用户更为随性的给予对话系统输入,将多个文档的文义归纳等工作通通交给机器来完成,无需用户进行预先的问题压缩。
更强的推理能力
ChatGPT的计算往往是被用户诟病的一点,很多时候会出现较为低级的计算错误,而GPT-4想要在计算推理方面“一洗前耻”。为了提高GPT-4 的计算推理能力,开发人员加入了MATH和GSM-8K这两个计算推理方向常用的数据集。虽然这两个数据集的数据对于模型几乎不造成什么训练上的负担,但是带来的效果是相当显著的,GPT-4将会拥有更为精确的计算推理能力。
更加强大的应试能力
如何证明自己“掌握”了某个专业的知识?GPT-4说那就去考一考这个领域的相关考试吧。GPT对考试任务进行了“特训”,将考题分为单选题、多选题、自由回答、图片题等多个不同题型。测试表明,GPT-4 在各种专业测试和学术基准测试上的表现与人类水平相当。例如,它通过了模拟律师考试,且分数在应试者的前10%左右;相比之下,GPT-3.5的得分在倒数10% 左右。
更安全的内容
人工智能系统生成内容的安全性和中立性是绕不开的话题。GPT-4在多模态的输入、推理等方面有了长足的进步,但是和其他大预言模型一样,还是面临“胡言乱语”、有害内容、虚假信息、隐私、网络安全、过度反馈等内容风险,譬如推荐非法销售的网站、帮助用户计划攻击、非法代码审计等。
针对这些问题,OpenAI吸纳了更多的人工反馈,包括ChatGPT用户提交的反馈,以改善GPT-4的行为。开发者还与50多位专家合作,在人工智能安全和安保等领域提供早期反馈。同时GPT-4辅助安全研究也在开展,GPT-4的高级推理和指令遵循功能加快了开发者的安全工作,开发者通过GPT-4来帮助创建训练数据,以便在训练、评估和内容监控中对内容分类器进行微调和迭代。

2
不得不重视的法律问题
飒姐团队之前也写过大量GPT模型合规的内容,在这里做一个总结。
生产出来的“作品”著作权到底是谁的?
根据我国《著作权法》第11条规定,作品归属于自然人、法人、非法人组织。换言之,在我国,只有自然人、法人可以成为著作权的主体,ChatGPT首先不是我国法律意义上的适格主体,因此不能成为真正意义以上的作者。另外,AI或ChatGPT产出的文本,是否是我国著作法意义上的“作品”也存在争议。但必须提及的是,2019年12月我国出现了首例认定人工智能产出文本为“作品”的判例(深圳南山区法院),但在全国范围内多数法院包括北京知识产权法院还是坚持严格解释法条,而非认定机器AI成为作者。
利用ChatGPT生成的内容是否需要与活人写的内容区别开?如何应对ChatGPT制造的“假新闻”和“谣言”?
首先,根据《互联网信息服务深度合成管理规定》,深度合成的信息内容须添加显著标识,防止公众混淆误认,AIGC内容与真人内容是需要做好区分的。针对假新闻和谣言等问题,2023年1月10日正式实施的《互联网信息服务深度合成管理规定》,要求深度合成提供者和使用者,不得制作、复制、发布、传播虚假新闻消息,转载给予深度合成服务制作发布的新闻消息的,应当依法转载互联网新闻信息源单位发布的新闻信息。
飒姐团队提示:服务提供者应当加强深度合成内容管理,采取技术或者人工方式对输入数据和合成结果进行审核,建立健全用于识别违法和不良信息的特征库,应当建立健全辟谣机制。
如果用于AI训练的数据如果来源不合法,是否有法律风险?
我们必须明确一个前提:用于AI训练的数据必须是合法取得的。在个人信息采集方面,必须经被采集人的知情同意,不能非法采集数据,需要遵循“个保法”规定和配套标准。在其他数据方面,需要取得权利人的同意或授权,例如将他人具有著作权的作品用于数据训练,需要在事前取得其授权,除非是已经经过著作权保护期或由于其他原因(CC授权等)而进入公共领域的作品,否则不能直接使用。同时,服务提供者和技术支持者应当加强训练数据管理,采取必要措施保障训练数据安全,防止数据泄露。

写在最后
大模型时代,GPT-4的出现为应用增添了无数的可能性。现有的许多业务场景中即将出现GPT-4的影子,譬如与客户进行深度对话,作为辅助视觉工具、利用GPT-4来简化用户体验、知识库管理甚至是语言的保存。
飒姐团队提醒您,GPT-4生产的内容仍会不可避免地出现“幻觉”,并不是所有的内容都是可信的。在特定高要求的场景,使用语言模型输出时应格外小心,使用额外的指引信息或是仍然需要一定的人工审核来确保内容的准确性。
科技在进步,每天都有惊喜。
获取详细资讯,请联络飒姐团队
【 sa.xiao@dentons.cn】
【 guangtong.gao@dentons.cn】
飒姐工作微信:【 xiaosalawyer】
飒姐工作电话:【 010-5759 0667】
肖飒法律团队,一支以学术业务立身的法学硕博团队。垂直深耕于“金融+科技”行业,对创新业务有独特的研究优势和一线实务经验。
团队创始人肖飒女士,系中国互联网金融协会申诉委员、中国银行法学研究会理事、首批北京市涉案企业合规第三方监督评估专业人才、中国人民大学法学院法硕实务导师、中国政法大学法律硕士学院兼职导师、中国社科院产业金融研究基地特约研究员、工信部信息中心《中国区块链产业白皮书》编委会委员。著有虚拟币规制畅销书《ICO黑洞》、合著学术书籍《网络金融犯罪的刑事治理研究》等。在《证券时报》《人民日报海外版》《财新》《经济观察报》等发表过近百篇署名文章。
坚守法律,让金融人+科技人远离“囹圄”!
