階段式同步(staged sync)重構自Go-Ethereum 的完全同步模式(full sync),以實現更好的性能。
階段式同步需要進行大量讀寫操作。雖然我們的目標是能夠在機械硬盤上同步節點,但是我們仍建議使用固態硬盤。
顧名思義,階段式同步需要依次執行10 個階段。
階段式同步是如何運作的
Turbo-Geth 客戶端會向每個對等節點了解該節點的HEAD 區塊(即最新區塊),然後依次執行每個階段、尋找本地HEAD 區塊和對等節點的HEAD 區塊之間缺失的區塊。
第一個階段(下載區塊頭)會設置本地HEAD 區塊。
各階段會按順序執行。在每個階段執行期間,只有節點本地的狀態達到目標狀態,該階段才會結束。
也就是說,在理想情況下(沒有出現網絡中斷、應用沒有重啟等問題),每個階段只需執行一次,即可完成初始同步。
最後一階段結束後,整個同步流程會重新開始,尋找新的區塊頭下載。
如果你在兩個階段之間重啟應用,應用會從第一階段開始重啟。
如果你在某個階段執行期間重啟應用,應用會從當前階段開始重啟,以完成該階段。
每個階段需要耗時多久?
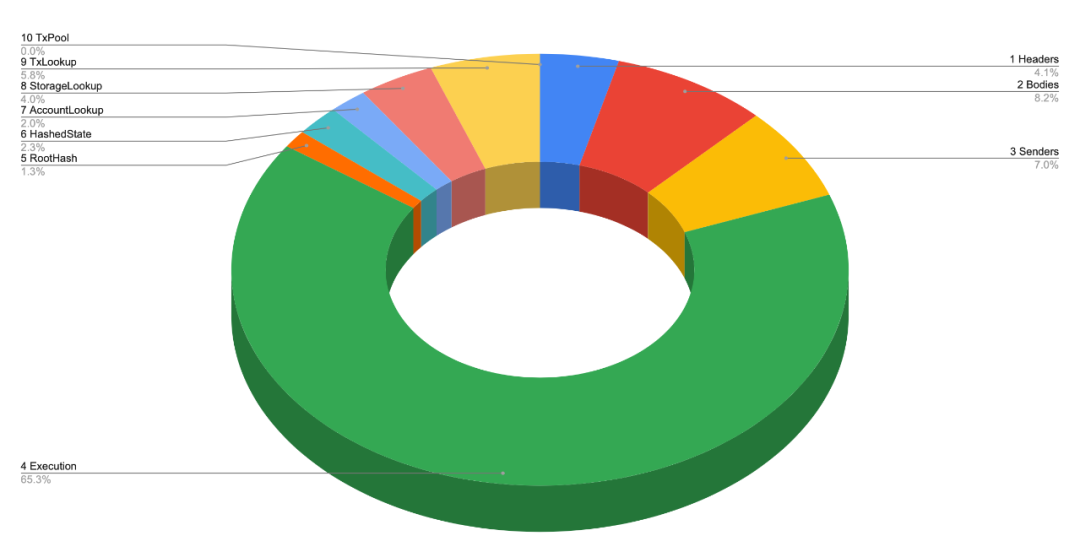
通過下方的餅狀圖,我們可以看出每個階段的耗時佔比(這些都是從完全同步中得出的數據)。雖然這些數據並不精確,但是足以作為參考。
重組/回退
如果區塊鏈發生重組,我們需要“回退”部分同步數據。
回退指的是從最後一個階段倒退回第一個階段。但是,需要注意的一點是,我們執行完回退之後才會更新交易池,因此我們知道新的nonce 。
回退的階段順序如下例所示(從右往左依次發生)。
state.unwindOrder = []*Stage{ // Unwinding of tx pool (reinjecting transactions into the pool needs to happen after unwinding execution) stages[0], stages[1], stages[2], stages[9], stages[ 3], stages[4], stages[5], stages[6], stages[7], stages[8], }通過ETL 進行預處理
在將數據插入數據庫之前,一些階段會使用我們的ETL 框架根據鍵值對數據進行排序。
這樣就可以極大減少數據庫寫入放大(write amplification)的情況。
因此,當我們生成索引或者說哈希值化狀態(Hashed State)時,我們會執行一個多步驟流程。
將處理過的數據寫入位於數據目錄的幾個臨時文件中;然後使用一個堆棧(heap)把臨時文件中的數據插入到數據庫中,並且使按照能夠最小化數據庫寫入放大現象的順序插入數據。
這種優化有時會將寫入速度提高幾個數量級。
各階段(如需查看最新列表,請訪問stagedsync.go)每個階段都包含兩個函數,分別是向前推進階段的ExecFunc和向後回退階段的UnwindFunc 。
從理論上來說,部分階段可以離線工作,但是當前版本並未實現這一功能。
階段1 :下載區塊頭
在這一階段,我們會下載本地HEAD 區塊和對等節點的HEAD 區塊之間的所有區塊頭。
這一階段是CPU 密集型的,適合使用多核處理器,因為要驗證區塊頭的工作量證明。
由於區塊鏈重組,大多數回退都是在這一階段開始的。
這一階段會推動本地HEAD 的指針(指向更新的區塊)。
階段2 :區塊哈希值
從區塊頭中抽取出一個從區塊哈希值映射成區塊號(blockHash -> blockNumber)的索引表,以支持更快速的查找功能,並讓同步過程對機械硬盤更為友好。
階段3 :下載區塊體
在這一階段,我們會將上一階段已下載區塊頭的區塊體也下載下來。
這一階段需要保持良好的聯網連接。絕大多數數據都在這一階段下載。
階段4 :復原發送者
這一階段會復原出並存儲每個已下載區塊中的每筆交易的發送者。
這一階段同樣是CPU 密集型的,適合使用多核處理器。
這一階段不需要聯網。
階段5 :執行區塊
在這一階段,我們會執行之前下載的所有區塊中的每一筆交易。
需要注意的一點是,在執行區塊的過程中,我們不會驗證根哈希,甚至不會創建默克爾樹。
這一階段是單線程的,無需聯網,需佔用大量磁盤空間。如果區塊執行失敗,可以回退該階段。
階段6 :計算狀態根
這一階段會構建默克爾樹,並驗證當前狀態的根哈希。
這一階段也會構建中間哈希值(Intermediate Hashes),並將它們存儲到數據庫中。
如果之前沒有存儲任何中間哈希值(這種情況可能在第一個初始同步期間發生),這一階段會構建出完整的默克爾樹及其根哈希。
如果數據庫中沒有中間哈希值,這一階段就會利用區塊的歷史記錄來弄清楚哪些哈希值已經過時,哪些哈希值是最新的,然後使用最新的哈希值來構建部分默克爾樹,只重構過時的哈希值。
如果根哈希無法匹配,就會向後回退一個區塊。
這一階段不需要聯網。
階段7 :生成哈希值化狀態
在執行期間,Turbo-Geth 使用無格式狀態存儲(Plain state storage)。
無格式狀態(Plain State):在標準狀態(我們稱之為“哈希值化狀態”)中,賬戶和存儲項的地址是keccak256(address) ,但是在一般狀態中,二者的地址就是address 。
儘管如此,為了確保一些API 能夠正常運作並與其它客戶端保持兼容,我們也會生成哈希值化狀態。
如果哈希值化狀態不是空值,我們會查看歷史記錄變更集(History ChangeSet),並且只更新已更改的項。
這個階段不需要聯網。
階段8、9、10 :生成索引
同步期間會生成3 個索引。
這3 個索引可能會被禁用,因為所有API 都不使用它們。
這一階段不需要聯網。
交易查詢索引
該索引表由從交易哈希值到區塊號的映射構成。
賬戶歷史索引
該索引存儲了從賬戶地址到區塊列表(在這些區塊中,該賬戶的狀態有了更改)的映射。
存儲歷史索引
該索引存儲了從存儲項地址到區塊列表(其中,該存儲項在一定程度上有了更改)的映射。
階段11 :交易池
在這一階段,我們會啟動交易池或更新其狀態。例如,如果我們已下載的區塊中包含了某些交易,就把這些交易從交易池中移除。
在回退時,我們會將被回退的區塊中的交易重新添加到交易池中。
這個階段不需要聯網。
(完)
(文內有許多超鏈接,可點擊左下”閱讀原文“ 從EthFans 網站上獲取)
原文鏈接:
https://github.com/ledgerwatch/turbo-geth/tree/master/eth/stagedsync
作者: Alex Sharov
