
作者:0xjacobzhao 及ChatGPT 4o
一、引言| Crypto AI 的模型層躍遷
數據、模型與算力是AI 基礎設施的三大核心要素,類比燃料(數據)、引擎(模型)、能源(算力)缺一不可。與傳統AI 產業的基礎設施演進路徑類似,Crypto AI 領域也經歷了相似的階段。 2024 年初,市場一度被去中心化GPU 專案所主導(Akash、Render、io.net 等),普遍強調「拼算力」的粗放式成長邏輯。而進入2025 年後,產業關注點逐步上移至模型與資料層,標誌著Crypto AI 正從底層資源競爭過渡到更永續與應用價值的中層建構。
通用大模型(LLM)vs 特化模型(SLM)
傳統的大型語言模型(LLM)訓練高度依賴大規模資料集與複雜的分散式架構,參數規模動輒70B~500B,訓練一次的成本常高達數百萬美元。而SLM(Specialized Language Model)作為一種可複用基礎模型的輕量微調範式,通常基於LLaMA、Mistral、DeepSeek 等開源模型,結合少量高品質專業資料及LoRA 等技術,快速建立具備特定領域知識的專家模型,顯著降低訓練成本與技術門檻。
值得注意的是,SLM 並不會被整合進LLM 權重中,而是透過Agent 架構呼叫、插件系統動態路由、LoRA 模組熱插拔、RAG(檢索增強生成)等方式與LLM 協同運作。這項架構既保留了LLM 的廣覆蓋能力,又透過精調模組增強了專業表現,形成了高度靈活的組合式智慧系統。
Crypto AI 在模型層的價值與邊界
Crypto AI 專案本質上難以直接提升大語言模型(LLM)的核心能力,核心原因在於
- 技術門檻過高:訓練Foundation Model 所需的資料規模、算力資源與工程能力極為龐大,目前僅有美國(OpenAI 等)與中國(DeepSeek 等)等科技巨頭具備對應能力。
- 開源生態限制:雖然主流基礎模型如LLaMA、Mixtral 已開源,但真正推動模型突破的關鍵仍集中於科研機構與閉源工程體系,鏈上項目在核心模型層的參與空間有限。
然而,在開源基礎模型之上,Crypto AI 專案仍可透過精調特化語言模型(SLM),並結合Web3 的可驗證性與激勵機制實現價值延伸。作為AI 產業鏈的「週邊介面層」,體現於兩個核心方向:
- 可信任驗證層:透過鏈上記錄模型產生路徑、資料貢獻與使用情況,增強AI 輸出的可追溯性與抗竄改能力。
- 激勵機制: 透過原生Token,用於激勵資料上傳、模型呼叫、智能體(Agent)執行等行為,建構模型訓練與服務的正向循環。
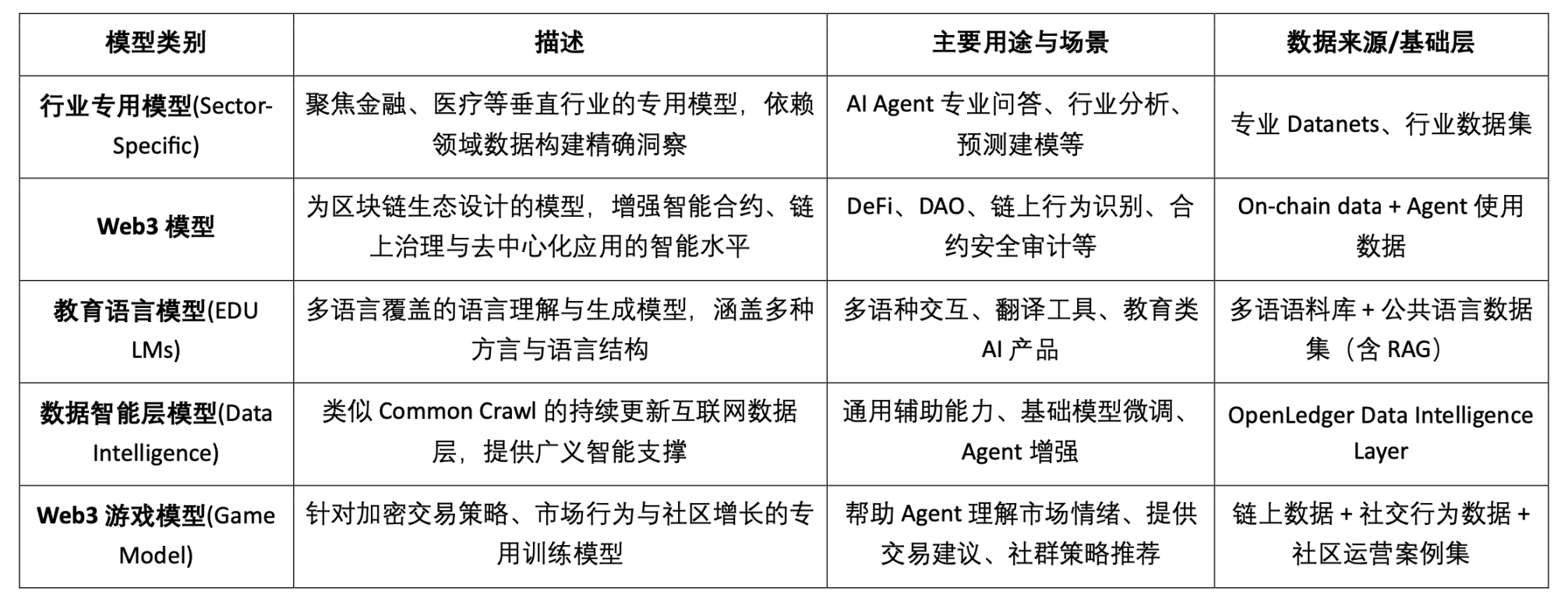
AI 模型類型分類與區塊鏈適用性分析
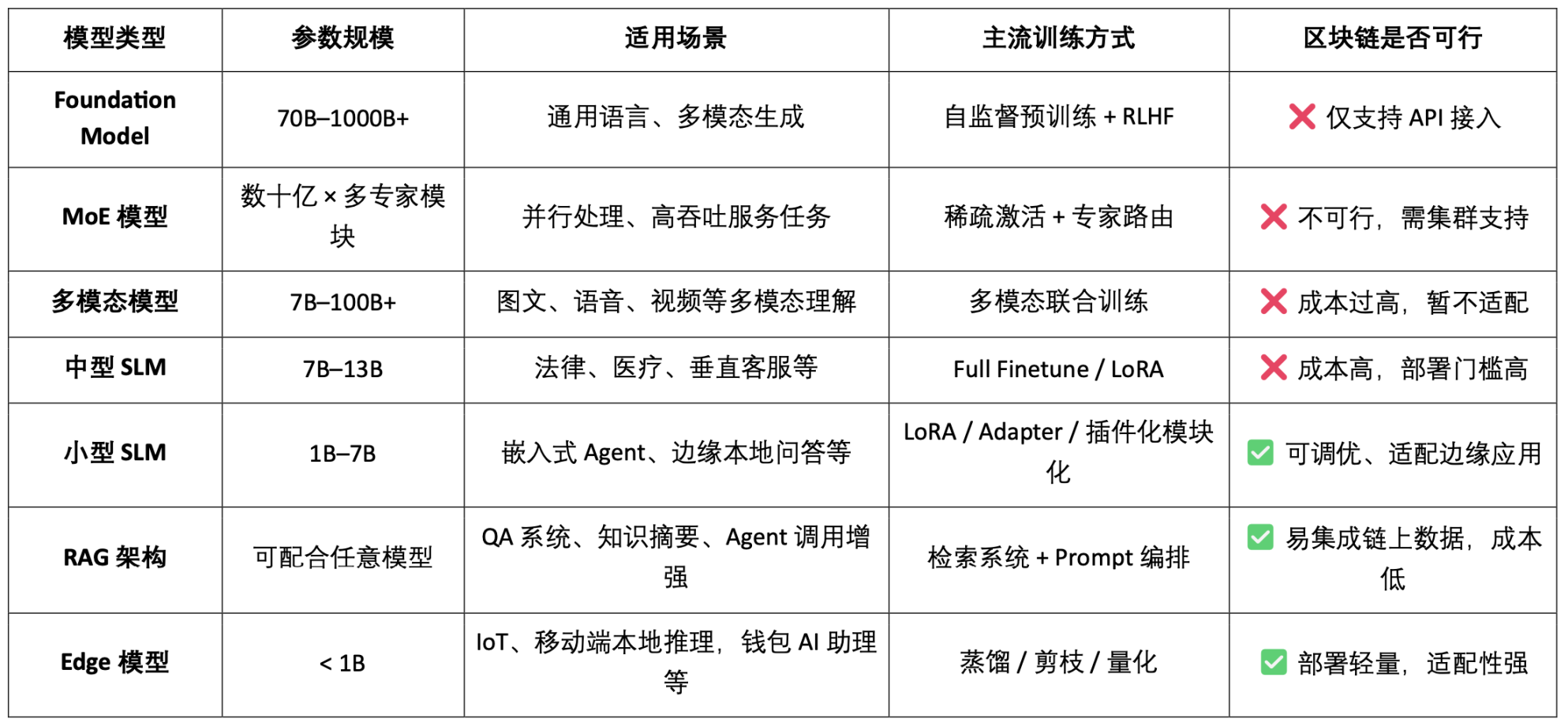
由此可見,模型類Crypto AI 專案的可行落點主要集中在小型SLM 的輕量化精調、RAG 架構的鏈上資料存取與驗證、以及Edge 模型的本地部署與激勵。結合區塊鏈的可驗證性與代幣機制,Crypto 能為這些中低資源模型場景提供特有價值,形成AI「介面層」的差異化價值。
基於資料與模型的區塊鏈AI 鏈,可對每個資料與模型的貢獻來源進行清晰、不可竄改的上鏈記錄,顯著提升資料可信度與模型訓練的可溯性。同時,透過智慧合約機制,在數據或模型被調用時自動觸發獎勵分發,將AI 行為轉化為可計量、可交易的代幣化價值,建構可持續的激勵體系。此外,社群用戶還可透過代幣投票評估模型效能、參與規則制定與迭代,完善去中心化治理架構。
二、專案概述| OpenLedger 的AI 鏈願景
OpenLedger 是目前市場上少數專注於資料與模型激勵機制的區塊鏈AI 專案。它率先提出「Payable AI」的概念,旨在建立一個公平、透明且可組合的AI 運行環境,激勵數據貢獻者、模型開發者與AI 應用建構者在同一平台協作,並根據實際貢獻獲得鏈上收益。
OpenLedger 提供了從「資料提供」到「模型部署」再到「呼叫分潤」的全鏈條閉環,其核心模組包括:
- Model Factory:無需編程,即可基於開源LLM 使用LoRA 微調訓練並部署客製化模型;
- OpenLoRA:支援千模型共存,按需動態加載,顯著降低部署成本;
- PoA(Proof of Attribution):透過鏈上呼叫記錄實現貢獻度量與獎勵分配;
- Datanets:面向垂類場景的結構化資料網絡,由社群協作建構與驗證;
- 模型提案平台(Model Proposal Platform):可組合、可呼叫、可支付的鏈上模型市場。
透過上述模組,OpenLedger 建構了一個數據驅動、模型可組合的「智能體經濟基礎設施」,推動AI 價值鏈的鏈上化。
而在區塊鏈技術採用上,OpenLedger 以OP Stack + EigenDA 為底座,為AI 模型建構了高效能、低成本、可驗證的資料與合約運作環境。
- 基於OP Stack 建置: 基於Optimism 技術堆疊,支援高吞吐與低費用執行;
- 在以太坊主網上結算: 確保交易安全與資產完整性;
- EVM 相容: 方便開發者基於Solidity 快速部署與擴充;
- EigenDA 提供資料可用性支援:大幅降低儲存成本,保障資料可驗證性。
相較於NEAR 這類更偏底層、主打資料主權與「AI Agents on BOS」架構的通用型AI 鏈,OpenLedger 更專注於建構以資料與模式激勵的AI 專用鏈,致力於讓模型的開發與呼叫在鏈上實現可追溯、可組合與永續的價值閉環。它是Web3 世界中的模型激勵基礎設施,結合HuggingFace 式的模型託管、Stripe 式的使用計費與Infura 式的鏈上可組合接口,推動“模型即資產”的實現路徑。
三、OpenLedger 的核心元件與技術架構
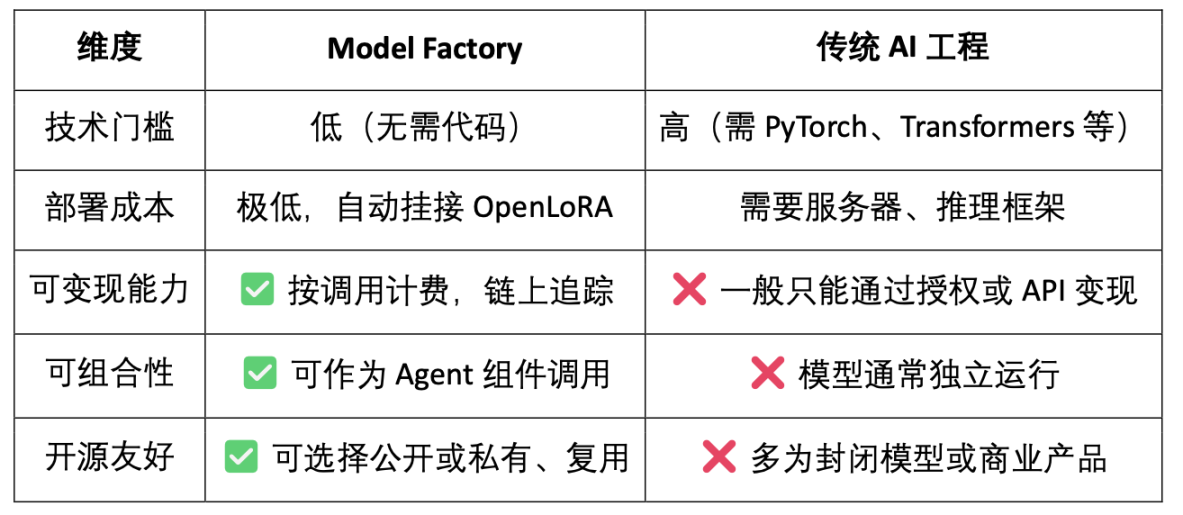
3.1 Model Factory,無需代碼模型工廠
ModelFactory 是OpenLedger 生態下的大型語言模型(LLM)微調平台。與傳統微調框架不同,ModelFactory 提供純圖形化介面操作,無需命令列工具或API 整合。使用者可以基於在OpenLedger 上完成授權與審核的資料集,對模型進行微調。實現了資料授權、模型訓練與部署的一體化工作流程,其核心流程包括:
- 資料存取控制: 使用者提交資料請求,提供者審核批准,資料自動存取模型訓練介面。
- 模型選擇與配置: 支援主流LLM(如LLaMA、Mistral),透過GUI 配置超參數。
- 輕量化微調: 內建LoRA / QLoRA 引擎,即時展示訓練進度。
- 模型評估與部署: 內建評估工具,支援匯出部署或生態共享呼叫。
- 互動驗證介面: 提供聊天式介面,方便直接測試模型問答能力。
- RAG 產生溯源: 回答帶來源引用,增強信任與可審計性。
Model Factory 系統架構包含六大模組,貫穿身分認證、資料權限、模型微調、評估部署與RAG 溯源,打造安全可控、即時互動、可持續變現的一體化模型服務平台。
ModelFactory 目前支援的大語言模型能力簡表如下:
- LLaMA 系列:生態最廣、社群活躍、通用效能強,是目前最主流的開源基礎模型之一。
- Mistral:架構高效、推理效能極佳,適合部署靈活、資源有限的場景。
- Qwen:阿里出品,中文任務表現優異,綜合能力強,適合國內開發者首選。
- ChatGLM:中文對話效果突出,適合垂類客服和在地化場景。
- Deepseek:在程式碼生成和數學推理上表現優越,適用於智慧開發輔助工具。
- Gemma:Google 推出的輕量模型,結構清晰,易於快速上手與實驗。
- Falcon:曾是性能標桿,適合基礎研究或對比測試,但社區活躍度已減。
- BLOOM:多語言支援較強,但推理表現偏弱,適合語言覆蓋型研究。
- GPT-2:經典早期模型,僅適合教學和驗證用途,不建議實際部署使用。
雖然OpenLedger 的模型組合併未包含最新的高效能MoE 模型或多模態模型,但其策略並非落伍,而是基於鏈上部署的現實約束(推理成本、RAG 適配、LoRA 相容、EVM 環境)所做的「實用優先」配置。
Model Factory 作為無程式碼工具鏈,所有模型都內建了貢獻證明機制,確保資料貢獻者和模型開發者的權益,具有低門檻、可變現與可組合性的優點,與傳統模型開發工具相比較:
- 對於開發者:提供模型孵化、分發、收入的完整路徑;
- 對於平台:形成模型資產流通與組合生態;
- 對於應用者:可以像呼叫API 一樣組合使用模型或Agent。
3.2 OpenLoRA,微調模型的鏈上資產化
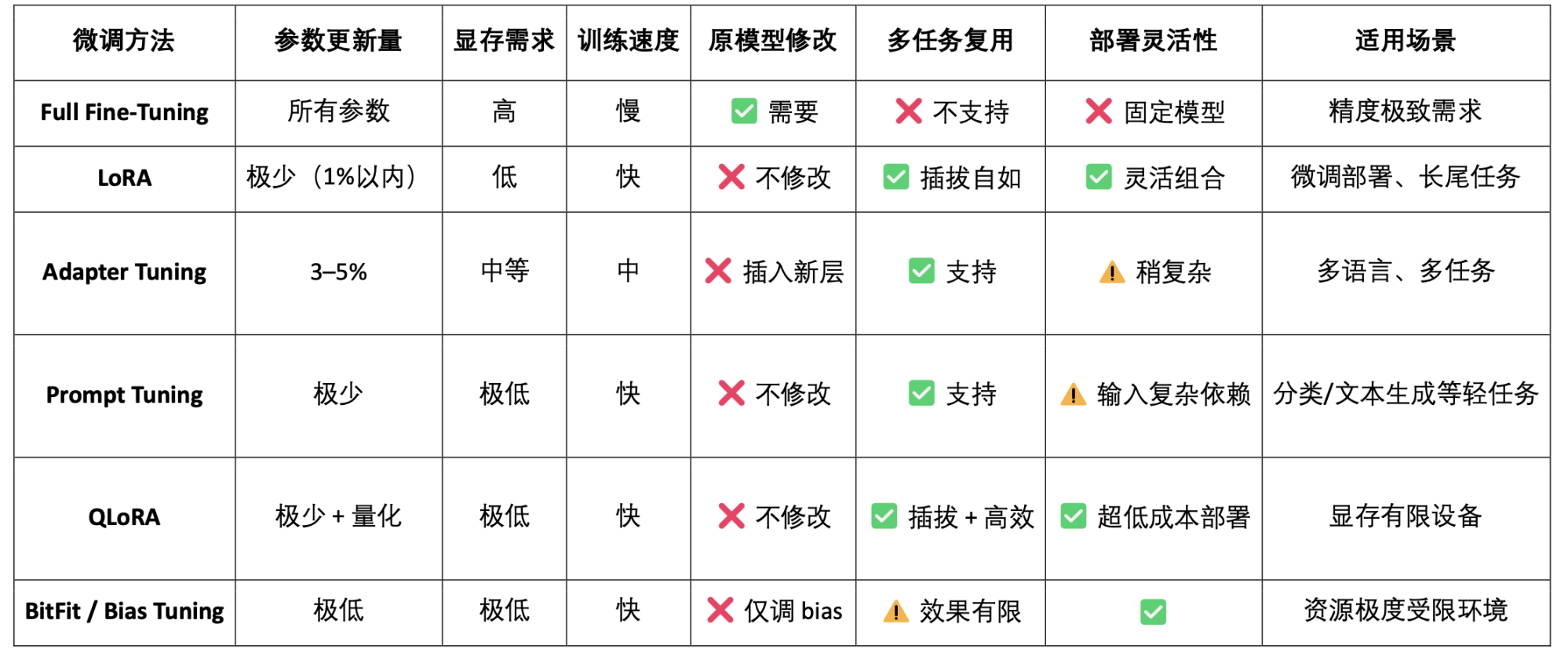
LoRA(Low-Rank Adaptation)是一種高效的參數微調方法,透過在預訓練大模型中插入「低秩矩陣」來學習新任務,而不修改原始模型參數,從而大幅降低訓練成本和儲存需求。傳統大語言模型(如LLaMA、GPT-3)通常擁有數十億甚至千億參數。要將它們用於特定任務(如法律問答、醫療問診),就需要微調(fine-tuning)。 LoRA 的核心策略是:「凍結原始大模型的參數,只訓練插入的新參數矩陣。」,其參數高效、訓練快速、部署靈活,是當前最適合Web3 模型部署與組合調用的主流微調方法。
OpenLoRA 是OpenLedger 建構的一套專為多模型部署與資源共享而設計的輕量級推理架構。它核心目標是解決目前AI 模型部署中常見的高成本、低復用、GPU 資源浪費等問題,推動「可支付AI」(Payable AI)的落地執行。
OpenLoRA 系統架構核心元件,基於模組化設計,涵蓋模型儲存、推理執行、請求路由等關鍵環節,實現高效能、低成本的多模型部署與呼叫能力:
- LoRA Adapter 儲存模組(LoRA Adapters Storage):微調後的LoRA adapter 被託管在OpenLedger 上,實現按需加載,避免將所有模型預載入顯存,節省資源。
- 模型託管與動態融合層(Model Hosting & Adapter Merging Layer):所有微調模型共用基礎大模型(base model),推理時LoRA adapter 動態合併,支援多個adapter 聯合推理(ensemble),提升效能。
- 推理引擎(Inference Engine):整合Flash-Attention、Paged-Attention、SGMV 優化等多項CUDA 優化技術。
- 請求路由與串流輸出模組(Request Router & Token Streaming): 根據請求中所需模型動態路由至正確adapter, 透過最佳化核心實作token 層級的串流產生。
OpenLoRA 的推理流程屬於技術層面「成熟通用」的模式服務「流程,如下:
- 基礎模型載入:系統預先載入如LLaMA 3、Mistral 等基礎大模型至GPU 顯存。
- LoRA 動態擷取:接收請求後,從Hugging Face、Predibase 或本機目錄動態載入指定LoRA adapter。
- 適配器合併啟動:透過最佳化核心將adapter 與基礎模型即時合併,支援多adapter 組合推理。
- 推理執行與流式輸出:合併後的模型開始產生反應,採用token 級流式輸出降低延遲,結合量化保障效率與精確度。
- 推理結束與資源釋放:推理完成後自動卸載adapter,釋放顯存資源。確保可在單GPU 上高效輪轉並服務數千個微調模型,支援模型高效輪轉。
OpenLoRA 透過一系列底層最佳化手段,顯著提升了多模型部署與推理的效率。其核心包括動態LoRA 適配器載入(JIT loading),有效降低顯存佔用;張量並行(Tensor Parallelism)與Paged Attention 實現高並發與長文本處理;支援多模型融合(Multi-Adapter Merging)多適配器合併執行,實現LoRA 組合推理(FSD量化技術,對底層CUDA 優化與量化支持,進一步提升推理速度並降低延遲。這些優化使得OpenLoRA 在單卡環境下有效地服務數千個微調模型,兼顧效能、可擴展性與資源利用率。
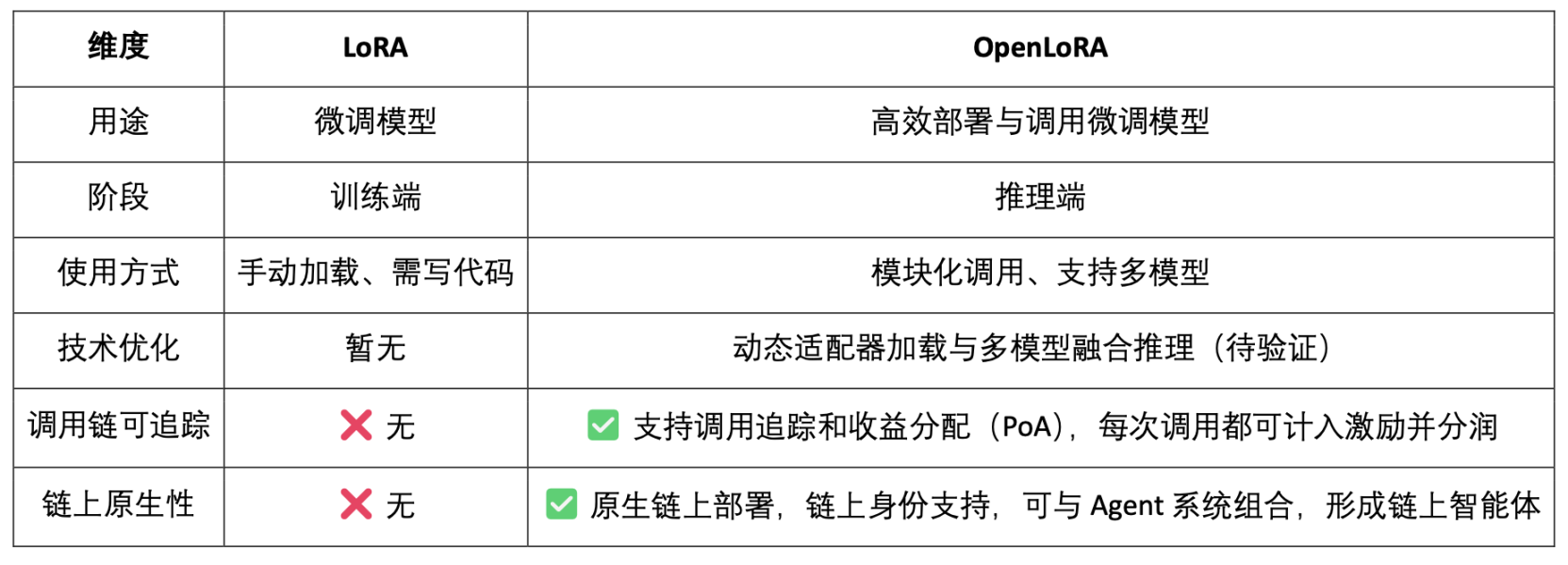
OpenLoRA 定位不僅是一個高效的LoRA 推理框架,更是將模型推理與Web3 激勵機制深度融合,目標是將LoRA 模型變成可調用、可組合、可分潤的Web3 資產。
- 模型即資產(Model-as-Asset):OpenLoRA 不只是部署模型,而是賦予每個微調模型鏈上身分(Model ID),並將其調用行為與經濟激勵綁定,實現「調用即分潤」。
- 多LoRA 動態合併+ 分潤歸屬:支援多個LoRA adapter 的動態組合調用,允許不同模型組合形成新的Agent 服務,同時系統可基於PoA(Proof of Attribution)機制按調用量為每個適配器精確分潤。
- 支援長尾模型的「多租戶共享推理」:透過動態載入與顯存釋放機制,OpenLoRA 能在單卡環境下服務數千個LoRA 模型,特別適合Web3 中小眾模型、個人化AI 助理等高復用、低頻調用場景。
此外,OpenLedger 發布了對OpenLoRA 效能指標的未來展望,相比傳統全參數模型部署,其顯存佔用大幅降低至8–12GB;模型切換時間理論上可低於100ms;吞吐量可達2000+ tokens/sec;延遲控制在20–50ms 。整體而言,這些性能指標在技術上具備可及性,但更接近“上限表現”,在實際生產環境中,性能表現可能會受到硬體、調度策略和場景複雜度的限制,應被視為“理想上限”而非“穩定日常”。
3.3 Datanets(資料網路),從資料主權到資料智能
高品質、領域專屬的資料成為建構高性能模型的關鍵要素。 Datanets 是OpenLedger 」資料即資產「的基礎設施,用於收集和管理特定領域的資料集,用於聚合、驗證與分發特定領域資料的去中心化網絡,為AI 模型的訓練與微調提供高品質資料來源。每個Datanet 就像一個結構化的資料倉庫,由貢獻者上傳資料實現了模型訓練所需資料的社群共建與可信賴使用。
與聚焦資料主權的Vana 等專案相比,OpenLedger 並不止於「資料收集」,而是透過Datanets(協作式標註與歸屬資料集)、Model Factory(支援無程式碼微調的模型訓練工具)、OpenLoRA(可追蹤、可組合的模型適配器)三大模組,將資料價值值整合到裝置上的「閉環」模型為完整版面配置為「閉環-資料-表」。 Vana 強調「誰擁有資料」,而OpenLedger 則聚焦「資料如何被訓練、呼叫並獲得獎勵」,在Web3 AI 生態中分別佔據資料主權保障與資料變現路徑的關鍵位置。
3.4 Proof of Attribution(貢獻證明):重塑利益分配的激勵層
Proof of Attribution(PoA)是OpenLedger 實現資料歸屬與激勵分配的核心機制,透過鏈上加密記錄,將每個訓練資料與模型輸出建立可驗證的關聯,確保貢獻者在模型呼叫中獲得應得回報,其資料歸屬與激勵流程概覽如下:
- 資料提交:使用者上傳結構化、領域專屬的資料集,並上鍊確權。
- 影響評估:系統根據資料特徵影響與貢獻者聲譽,在每次推理時評估其價值。
- 訓練驗證:訓練日誌記錄每個資料的實際使用情況,確保貢獻可驗證。
- 激勵分配:根據資料影響力,向貢獻者發放與效果掛鉤的Token 獎勵。
- 品質治理:對低質、冗餘或惡意資料進行懲罰,保障模型訓練品質。
與Bittensor 子網路架構結合評分機制的區塊鏈通用型激勵網路相比較,OpenLedger 則專注於模型層面的價值捕捉與分潤機制。 PoA 不僅是一個激勵分發工具,更是一個面向透明度、來源追蹤與多階段歸屬的框架:它將資料的上傳、模型的呼叫、智能體的執行過程全程上鍊記錄,實現端到端的可驗證價值路徑。這種機制使得每一次模型呼叫都能溯源至資料貢獻者與模型開發者,進而實現鏈上AI 系統中真正的「價值共識」與「收益可得」。
RAG(Retrieval-Augmented Generation) 是一種結合檢索系統與生成式模型的AI 架構,它旨在解決傳統語言模型「知識封閉」「胡編亂造」的問題,透過引入外部知識庫增強模型生成能力,使輸出更加真實、可解釋、可驗證。 RAG Attribution 是OpenLedger 在檢索增強生成(Retrieval-Augmented Generation)場景下建立的資料歸屬與激勵機制,確保模型輸出的內容可追溯、可驗證,貢獻者可激勵,最終實現生成可信化與資料透明化,其流程包括:
- 使用者提問→ 檢索資料:AI 接收到問題後,從OpenLedger 資料索引中檢索相關內容。
- 資料被呼叫並產生回答:檢索到的內容被用來產生模型回答,並被鏈上記錄呼叫行為。
- 貢獻者獲得獎勵:數據被使用後,其貢獻者獲得按金額與相關性計算的激勵。
- 生成結果帶引用:模型輸出附帶原始資料來源鏈接,實現透明問答與可驗證內容。

OpenLedger 的RAG Attribution 讓每一次AI 回答都可追溯至真實資料來源,貢獻者按引用頻次獲得激勵,實現「知識有出處、調用可變現」。這項機制不僅提升了模型輸出的透明度,也為高品質數據貢獻建構了可持續的激勵閉環,是推動可信任AI 和數據資產化的關鍵基礎設施。
四、OpenLedger 專案進度與生態合作
目前OpenLedger 已上線測試網,資料智慧層(Data Intelligence Layer) 是OpenLedger 測試網的首個階段,旨在建構一個由社群節點共同驅動的網路資料倉儲。這些數據經過篩選、增強、分類和結構化處理,最終形成適用於大型語言模型(LLM)的輔助智能,用於建立OpenLedger 上的領域AI 模型。社群成員可運行邊緣設備節點,參與資料收集與處理,節點將使用本地運算資源執行資料相關任務,參與者根據活躍度和任務完成度獲得積分獎勵。而這些積分將在未來轉換為OPEN 代幣,具體兌換比例將在代幣生成事件(TGE)前公佈。
OpenLedger 測試網激勵目前提供以下三類收益機制:
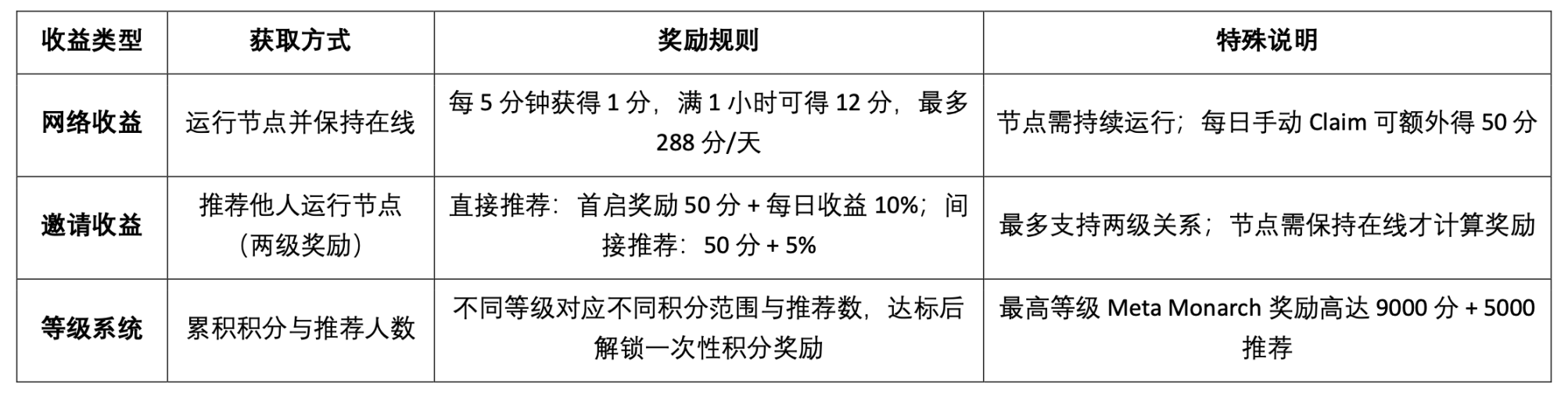
Epoch 2 測試網重點推出了Datanets 資料網路機制,該階段僅限白名單用戶參與,需完成預評估以解鎖任務。任務涵蓋資料驗證、分類等,完成後根據準確率和難度獲得積分,並透過排行榜激勵高品質貢獻,官網目前提供的可參與資料模型如下:
而OpenLedger 更為長遠的路線圖規劃,從資料收集、模型建構走向Agent 生態,逐步實現「資料即資產、模型即服務、Agent 即智能體」的完整去中心化AI 經濟閉環。
- Phase 1 · 數據智能層(Data Intelligence Layer): 社群透過運行邊緣節點採集和處理互聯網數據,建構高品質、持續更新的數據智慧基礎層。
- Phase 2 · 社群資料貢獻(Community Contributions): 社群參與資料驗證與回饋,共同打造可信賴的黃金資料集(Golden Dataset),為模型訓練提供優質輸入。
- Phase 3 · 模型建構與歸屬聲明(Build Models & Claim): 基於黃金數據,使用者可訓練專用模型並確權歸屬,實現模型資產化與可組合的價值釋放。
- Phase 4 · 智能體創建(Build Agents): 基於已發布模型,社群可建立個人化智能體(Agents),實現多場景部署與持續協同演進。
OpenLedger 的生態合作夥伴涵蓋算力、基礎設施、工具鏈與AI 應用。其合作夥伴包括Aethir、Ionet、0G 等去中心化算力平台,AltLayer、Etherfi 和EigenLayer 上的AVS 提供底層擴容與結算支援;Ambios、Kernel、Web3Auth、Intract 等工具提供身分驗證與開發整合能力;在AI 模型與智慧等專案共同推進模型部署與智能體落地,建構一個開放、可組合、可持續的Web3 AI 生態系統。
過去一年,OpenLedger 在Token2049 Singapore、Devcon Thailand、Consensus Hong Kong 及ETH Denver 期間連續主辦Crypto AI 主題的DeAI Summit 峰會,邀請了許多去中心化AI 領域的核心項目與技術領袖參與。作為少數能夠持續策劃高品質產業活動的基礎設施項目之一,OpenLedger 借助DeAI Summit 有效強化了其在開發者社群與Web3 AI 創業生態中的品牌認知與專業聲譽,為其後續生態拓展與技術落地奠定了良好的產業基礎。
五、融資及團隊背景
OpenLedger 於2024 年7 月完成了1,120 萬美元的種子輪融資,投資方包括Polychain Capital、Borderless Capital、Finality Capital、Hashkey,以及多位知名天使投資人,如Sreeram Kannan(EigenLayer)、Balaji Srinivasan、Sandeepk(Polyyat)、Kennyantayantay(Mantak)和Aiantajit)。資金將主要用於推進OpenLedger 的AI Chain 網路建置、模型激勵機制、資料基礎層及Agent 應用生態的全面落地。

OpenLedger 由Ram Kumar 創立,他是OpenLedger 的核心貢獻者,同時是一位常駐舊金山的創業家,在AI/ML 和區塊鏈技術領域擁有堅實的技術基礎。他為專案帶來了市場洞察力、技術專長與策略領導力的有機結合。 Ram 曾共同領導一家區塊鏈與AI/ML 研發公司,年營收超過3,500 萬美元,並在推動關鍵合作方面發揮了重要作用,其中包括與沃爾瑪子公司達成的一項策略合資專案。他專注於生態系統建構與高槓桿合作,致力於加速各產業的現實應用落地。
六、代幣經濟模型設計與治理
OPEN 是OpenLedger 生態的核心功能型代幣,賦能網絡治理、交易運行、激勵分發與AI Agent 運營,是構建AI 模型與數據在鏈上可持續流通的經濟基礎,目前官方公佈的代幣經濟學尚屬早期設計階段,細節尚未完全明確,但隨著項目即將邁入代幣生成事件(TGE)
- 治理與決策:OPEN 持有者可參與模式資助、Agent 管理、協議升級與資金使用的治理投票。
- 交易燃料與費用支付:作為OpenLedger 網路的原生gas 代幣,支援AI 原生的客製化費率機制。
- 激勵與歸屬獎勵:貢獻高品質資料、模型或服務的開發者可根據使用影響力獲得OPEN 分潤。
- 跨鏈橋接能力:OPEN 支援L2 ↔ L1(Ethereum)橋接,提升模型和Agent 的多鏈可用性。
- AI Agent 質押機制:AI Agent 運作需質押OPEN,表現不佳將被削減質押,激勵高效、可信的服務輸出。
與許多影響力與持幣數量掛鉤的代幣治理協議不同,OpenLedger 引入了一種基於貢獻價值的治理機制。其投票權重與實際創造的價值相關,而非單純的資本權重,優先賦權那些參與模型和資料集建構、最佳化與使用的貢獻者。這種架構設計有助於實現治理的長期永續性,防止投機行為主導決策,真正契合其「透明、公平、社群驅動」的去中心化AI 經濟願景。
七、數據、模型與激勵市場格局及競爭比較
OpenLedger 作為「可支付AI(Payable AI)」模式激勵基礎設施,致力於為資料貢獻者與模型開發者提供可驗證、可歸屬、可持續的價值變現路徑。其圍繞著鏈上部署、調用激勵和智能體組合機制,構建出具有差異化特徵的模組體系,在當前Crypto AI 賽道中獨樹一幟。雖然尚無專案在整體架構上完全重合,但在協議激勵、模型經濟與資料確權等關鍵維度,OpenLedger 與多個代表性專案呈現高度可比性與協作潛力。
協定激勵層:OpenLedger vs. Bittensor
Bittensor 是當前最具代表性的去中心化AI 網絡,建構了由子網(Subnet)和評分機制驅動的多角色協同系統,以$TAO 代幣激勵模型、數據與排序節點等參與者。相較之下,OpenLedger 專注於鏈上部署與模型呼叫的收益分潤,強調輕量化架構與Agent 協同機制。兩者激勵邏輯雖有交集,但目標層級與系統複雜度差異明顯:Bittensor 聚焦通用AI 能力網路底座,OpenLedger 則定位為AI 應用層的價值承接平台。
模型歸屬與呼叫激勵:OpenLedger vs. Sentient
Sentient 提出的「OML(Open, Monetizable, Loyal)AI」概念在模型確權與社區所有權上與OpenLedger 部分思路相似,強調透過Model Fingerprinting 實現歸屬識別與收益追蹤。不同之處在於,Sentient 更聚焦模型的訓練與生成階段,而OpenLedger 則專注於模型的鏈上部署、調用與分潤機制,二者分別位於AI 價值鏈的上游與下游,具有天然互補性。
模型託管與可信任推理平台:OpenLedger vs. OpenGradient
OpenGradient 專注於建立基於TEE 與zkML 的安全推理執行框架,提供去中心化模型託管與推理服務,聚焦於底層可信任運作環境。相較之下,OpenLedger 更強調鏈上部署後的價值捕獲路徑,圍繞Model Factory、OpenLoRA、PoA 與Datanets 建構「訓練—部署—呼叫—分潤」的完整閉環。兩者所處模型生命週期不同:OpenGradient 偏運行可信性,OpenLedger 偏收益激勵與生態組合,具備高度互補空間。
眾包模型與評估誘因:OpenLedger vs. CrunchDAO
CrunchDAO 專注於金融預測模型的去中心化競賽機制,鼓勵社群提交模型並基於表現獲得獎勵,適用於特定垂直場景。相較之下,OpenLedger 提供可組合模型市場與統一部署框架,具備更廣泛的通用性與鏈上原生變現能力,適合多型智能體場景拓展。兩者在模型激勵邏輯上互補,具備協同潛力。
社群驅動輕量模型平台:OpenLedger vs. Assisterr
Assisterr 基於Solana 構建,鼓勵社區創建小型語言模型(SLM),並透過無程式碼工具與$sASRR 激勵機制提升使用頻率。相較而言,OpenLedger 更強調資料- 模型- 呼叫的閉環追溯與分潤路徑,借助PoA 實現細粒度激勵分配。 Assisterr 更適合低門檻的模型協作社區,OpenLedger 則致力於建立可重複使用、可組合的模型基礎設施。
模型工廠:OpenLedger vs. Pond
Pond 與OpenLedger 同樣提供「Model Factory」模組,但定位與服務物件差異顯著。 Pond 專注基於圖神經網路(GNN)的鏈上行為建模,主要面向演算法研究者與資料科學家,並透過競賽機制推動模型開發,Pond 更傾向於模型競爭;OpenLedger 則是基於語言模型微調(如LLaMA、Mistral),服務開發者與非技術用戶,強調無程式碼體驗與建立鏈上調分機制,
可信推理路徑:OpenLedger vs. Bagel
Bagel 推出了ZKLoRA 框架,利用LoRA 微調模型與零知識證明(ZKP)技術,實現鏈下推理過程的加密可驗證性,確保推理執行的正確性。而OpenLedger 則透過OpenLoRA 支援LoRA 微調模型的可擴展部署與動態調用,同時從不同角度解決推理可驗證性問題—— 它透過為每次模型輸出附加歸屬證明(Proof of Attribution, PoA),追蹤推理所依賴的資料來源及其影響力。這不僅提升了透明度,還為高品質數據貢獻者提供獎勵,並增強了推理過程的可解釋性與可信度。簡言之,Bagel 著重計算結果的正確性驗證,而OpenLedger 則透過歸屬機制實現對推理過程的責任追蹤與可解釋性。
資料側協作路徑:OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien 與FractionAI 提供去中心化資料標註服務,Vana 與Irys 聚焦資料主權與確權機制。 OpenLedger 則透過Datanets + PoA 模組,實現高品質資料的使用追蹤與鏈上激勵分發。前者可作為資料供給上游,OpenLedger 則作為價值分配與呼叫中樞,三者在資料價值鏈上具備良好協同,而非競爭關係。

總結來看,OpenLedger 在目前Crypto AI 生態中佔據「鏈上模型資產化與呼叫激勵」這一中間層位置,既可向上銜接訓練網絡與資料平台,也可向下服務Agent 層與終端應用,是連接模型價值供給與落地調用的關鍵橋樑型協議。
八、結論| 從資料到模型,AI 鏈的變現之路
OpenLedger 致力於打造Web3 世界中的「模型即資產」基礎設施,透過建構鏈上部署、調用激勵、歸屬確權與智能體組合的完整閉環,首次將AI 模型帶入真正可追溯、可變現、可協同的經濟系統中。其圍繞Model Factory、OpenLoRA、PoA 和Datanets 所建構的技術體系,為開發者提供低門檻的訓練工具,為資料貢獻者保障收益歸屬,為應用方提供可組合的模型呼叫與分潤機制,全面啟動AI 價值鏈中長期被忽略的「資料」與「模型」兩端資源。
OpenLedger 更像HuggingFace + Stripe + Infura 的在Web3 世界的融合體,為AI 模型提供託管、呼叫計費與鏈上可編排的API 介面。隨著資料資產化、模型自主化、Agent 模組化趨勢加速演進,OpenLedger 有望成為「Payable AI」模式下的重要中樞AI 鏈。

