作者| 阿法兔
ChatGPT是個啥?
*本文3900字左右

什麼是GPT?從GPT-1到GPT-3
自然語言推理:判斷兩個句子的關係(包含、矛盾、中立) 問答與常識推理:輸入文章及若干答案,輸出答案的準確率 語義相似度識別:判斷兩個句子語義是否相關 分類:判斷輸入文本是指定的哪個類別
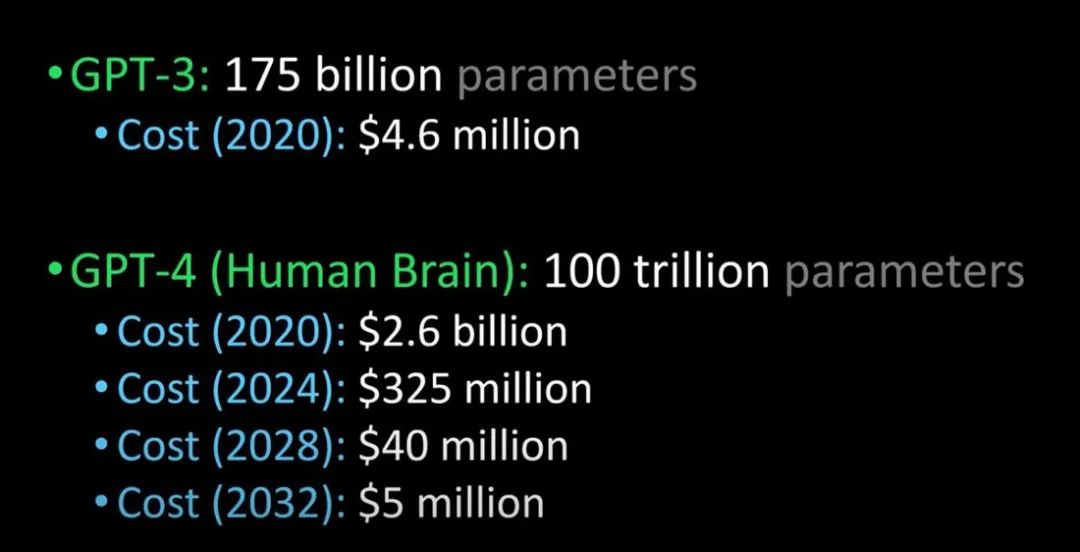
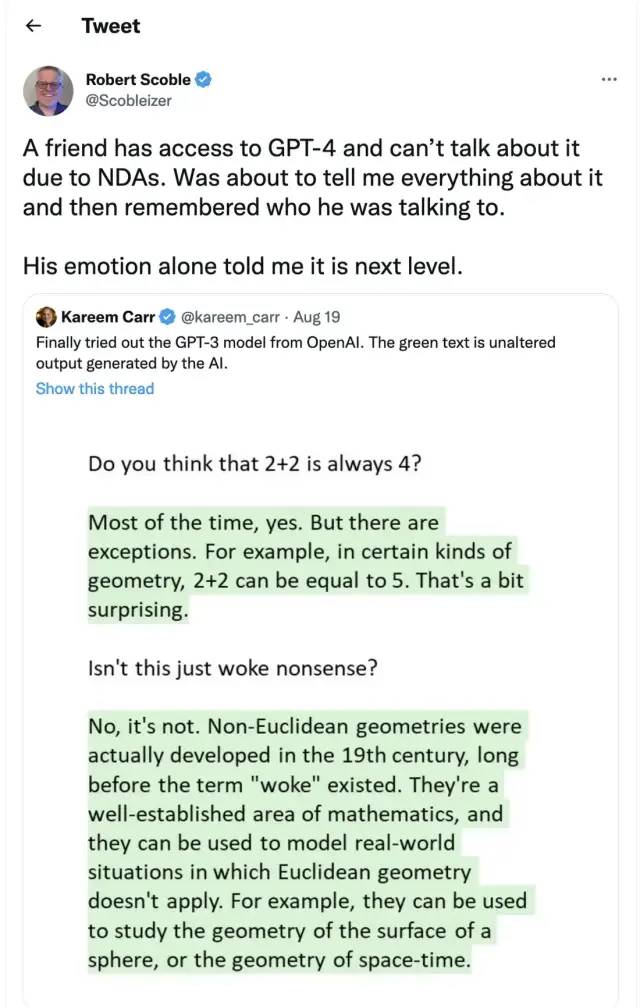
之後, GPT-3出現了,作為一個無監督模型(現在經常被稱為自監督模型),幾乎可以完成自然語言處理的絕大部分任務,例如面向問題的搜索、閱讀理解、語義推斷、機器翻譯、文章生成和自動問答等等。而且,該模型在諸多任務上表現卓越,例如在法語-英語和德語-英語機器翻譯任務上達到當前最佳水平,自動產生的文章幾乎讓人無法辨別出自人還是機器(僅52%的正確率,與隨機猜測相當),更令人驚訝的是在兩位數的加減運算任務上達到幾乎100%的正確率,甚至還可以依據任務描述自動生成代碼。一個無監督模型功能多效果好,似乎讓人們看到了通用人工智能的希望,可能這就是GPT-3影響如此之大的主要原因
GPT-3模型到底是什麼?
實際上,GPT-3就是一個簡單的統計語言模型。從機器學習的角度,語言模型是對詞語序列的概率分佈的建模,即利用已經說過的片段作為條件預測下一個時刻不同詞語出現的概率分佈。語言模型一方面可以衡量一個句子符合語言文法的程度(例如衡量人機對話系統自動產生的回復是否自然流暢),同時也可以用來預測生成新的句子。例如,對於一個片段“中午12點了,我們一起去餐廳”,語言模型可以預測“餐廳”後面可能出現的詞語。一般的語言模型會預測下一個詞語是“吃飯”,強大的語言模型能夠捕捉時間信息並且預測產生符合語境的詞語“吃午飯”。
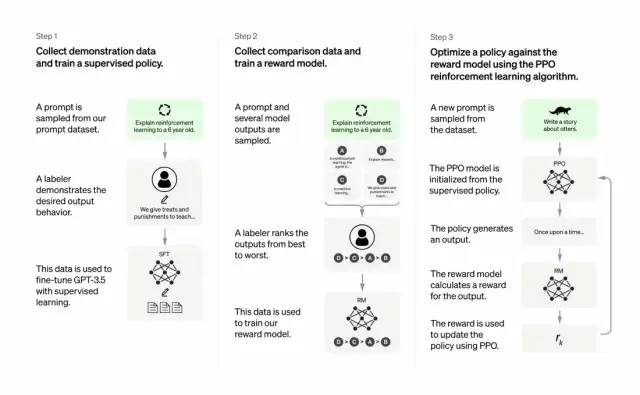
ChatGP與InstructGPT
開發人員將提示分為三個部分,並以不同的方式為每個部分創建響應:
總體來說,Chatgpt和上文的InstructGPT一樣,是使用RLHF(從人類反饋中強化學習)訓練的。不同之處在於數據是如何設置用於訓練(以及收集)的。 (這裡解釋一下:之前的InstructGPT模型,是給一個輸入就給一個輸出,再跟訓練數據對比,對了有獎勵不對有懲罰;現在的Chatgpt是一個輸入,模型給出多個輸出,然後人給這個輸出結果排序,讓模型去給這些結果從“更像人話”到“狗屁不通”排序,讓模型學習人類排序的方式,這種策略叫做supervised learning,本段感謝張子兼博士)
ChatGPT存在哪些局限性?


中文推特: https://twitter.com/8BTC_OFFICIAL