作者 | 阿法兔
ChatGPT是个啥?
*本文3900字左右

什么是GPT?从GPT-1到GPT-3
自然语言推理:判断两个句子的关系(包含、矛盾、中立) 问答与常识推理:输入文章及若干答案,输出答案的准确率 语义相似度识别:判断两个句子语义是否相关 分类:判断输入文本是指定的哪个类别
之后,GPT-3出现了,作为一个无监督模型(现在经常被称为自监督模型),几乎可以完成自然语言处理的绝大部分任务,例如面向问题的搜索、阅读理解、语义推断、机器翻译、文章生成和自动问答等等。而且,该模型在诸多任务上表现卓越,例如在法语-英语和德语-英语机器翻译任务上达到当前最佳水平,自动产生的文章几乎让人无法辨别出自人还是机器(仅52%的正确率,与随机猜测相当),更令人惊讶的是在两位数的加减运算任务上达到几乎100%的正确率,甚至还可以依据任务描述自动生成代码。一个无监督模型功能多效果好,似乎让人们看到了通用人工智能的希望,可能这就是GPT-3影响如此之大的主要原因
GPT-3模型到底是什么?
实际上,GPT-3就是一个简单的统计语言模型。从机器学习的角度,语言模型是对词语序列的概率分布的建模,即利用已经说过的片段作为条件预测下一个时刻不同词语出现的概率分布。语言模型一方面可以衡量一个句子符合语言文法的程度(例如衡量人机对话系统自动产生的回复是否自然流畅),同时也可以用来预测生成新的句子。例如,对于一个片段“中午12点了,我们一起去餐厅”,语言模型可以预测“餐厅”后面可能出现的词语。一般的语言模型会预测下一个词语是“吃饭”,强大的语言模型能够捕捉时间信息并且预测产生符合语境的词语“吃午饭”。
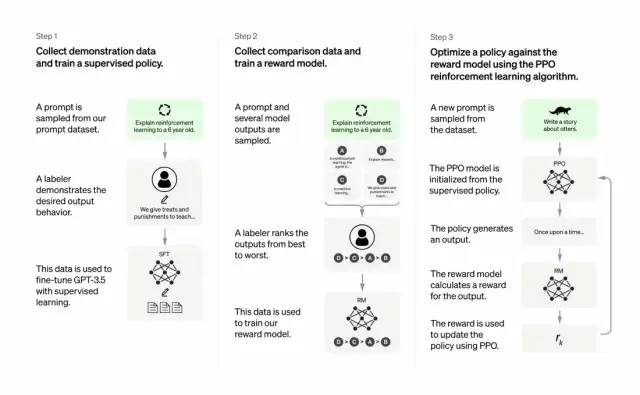
ChatGP与InstructGPT
开发人员将提示分为三个部分,并以不同的方式为每个部分创建响应:
总体来说,Chatgpt和上文的InstructGPT一样,是使用 RLHF(从人类反馈中强化学习)训练的。不同之处在于数据是如何设置用于训练(以及收集)的。(这里解释一下:之前的InstructGPT模型,是给一个输入就给一个输出,再跟训练数据对比,对了有奖励不对有惩罚;现在的Chatgpt是一个输入,模型给出多个输出,然后人给这个输出结果排序,让模型去给这些结果从“更像人话”到“狗屁不通”排序,让模型学习人类排序的方式,这种策略叫做supervised learning,本段感谢张子兼博士)
ChatGPT存在哪些局限性?


中文推特:https://twitter.com/8BTC_OFFICIAL