




作者:Kris & Laobai,ABCDE;Mo Dong,Celer Network
隨著近幾個月協處理器概念的火熱,這個新的ZK 用例開始得到越來越多人的關注。
然而我們發現,大多數人對於協處理器概念還是相對陌生,尤其是對於協處理器的精準定位 — 協處理器是什麼,又不是什麼,還比較模糊。而對於市面上幾家協處理器賽道的技術方案對比,尚未有人系統的整理過,這篇文希望能夠給市場和用戶一個關於協處理賽道更加清晰的認識。
一.協處理器Co-Processor 是什麼,又不是什麼?
如果要求你只用一句話來跟一個非技術或是開發人員講清楚協處理器,你會如何描述?
我想董沫博士的這句話可能非常接近標準答案 — 協處理器說白了就是「賦予智能合約Dune Analytics 的能力」。
這句話該如何拆解?
想像我們使用Dune 的場景— 你想要去Uniswap V3 做LP 賺點手續費,於是乎你打開Dune,找到最近Uniswap 上各種交易對的交易量,手續費近7 天的APR,主流交易對的上下波動區間等等…
又或者StepN 火了那會,你開始炒鞋,不確定什麼時候該脫手,於是你每天盯著Dune 上面StepN 的數據,每日交易量,新增用戶數,鞋子地板價…打算一旦出現增長放緩或下跌趨勢就趕緊跑。
當然,可能不只你在盯著這些數據,Uniswap 和StepN 的開發團隊也同樣關注這些數據。
這些數據非常有意義 — 它不僅可以幫助判斷趨勢的變化,還可以以此玩出更多的花樣,正如互聯網大廠常用的“大數據”打法。
例如根據使用者經常買賣的鞋子風格與價格,推薦類似的鞋子。
例如根據用戶持有創世鞋的時長,推出一個「用戶忠誠獎勵計畫」,給予忠誠用戶更多的空投或是福利。
例如根據Uniswap 上面LP 或是Trader 提供的TVL 或是交易量推出一個類似Cex 的VIP 方案,給予Trader 交易手續費減免或是LP 手續費份額增加的福利…
這時問題來了 — 網路大廠玩大數據+AI,基本上是個黑箱,想怎麼弄怎麼弄,用戶看不到,也不在乎。
但在Web3 這邊,透明,去信任是咱們天然的政治正確,拒絕黑箱!
於是乎當你想要實現上述場景之時,會面臨一個兩難之境— 要么你通過中心化的手段去實現,“後台手動”用Dune 統計完這些索引數據,然後去部署實施;要么你寫一套智能合約,自動去鏈上抓取這些數據,完成計算,自動部署分。
前者會讓你陷入「政治不正確」的信任問題。
後者在鏈上產生的Gas 費用會是個天文數字,你( 項目方)的錢包承受不起。
這時候就是協處理器登場的時候了,把剛才那兩種手段結合一下,同時把「後台手動」這個步驟透過技術手段「自證清白」,換句話說,透過ZK 技術把鏈外「索引+計算」這一塊「自證清白」了,然後餵給智能合約,這樣信任問題解決,海量的Gas 費用也不見了,完美!
為什麼會叫做「協處理器」呢?其實這是來自於Web2.0 發展史中的「GPU」。 GPU 之所以在當時被引入作為一個單獨的計算硬件,獨立於CPU 存在,是因為他的設計架構能夠處理一些CPU 從根本上就難以處理的計算,比如大規模的並行重複計算,圖形計算等等。正是有了這種「協處理器」的架構,我們今天才有了精彩的CG 電影,遊戲,AI 模型等等,所以這種協處理器的架構實際上是計算計體系架構的一次飛躍。現在各家協處理器團隊也是希望將這種架構引入Web3.0,在這裡區塊鏈就類似於Web3.0 的CPU,不論是L1 還是L2,都天生不適應這類「重數據」和“複雜計算邏輯」的任務,所以引入一個區塊鏈協處理器,來幫助處理這類計算,從而極大拓展區塊鏈應用的可能性。
所以協處理器做的事情歸納一下就是兩件事:
- 從區塊鏈上拿數據,並透過ZK 證明我拿的數據是真的,沒摻假;
- 根據剛才拿到的數據做出相應的計算,並再次透過ZK 證明我算的結果也是真的,沒摻假,計算結果就可以被智能合約「低費用+Trustless」的調用了。
前段時間Starkware 那邊火了一個概念,叫做Storage Proof,也叫State Proof,基本上做的就是步驟1,代表是,Herodotus,Langrage 等等,許多基於ZK 技術的跨鏈橋的技術重點也在步驟1 上。
協處理器無非也就是步驟1 完事兒之後再加一個步驟2,免信任提取資料之後再做個無信任計算就OK 了。
所以用一個相對技術一點的話來精確形容,協處理器應該是Storage Proof/State Proof 的超集,是Verfiable Computation(可驗證計算)的子集。
要注意的一點是,協處理器不是Rollup。
從技術上講,Rollup 的ZK 證明類似於上述步驟2,而步驟1「拿數據」這個過程,是透過Sequencer 直接實現的,即便是去中心化Sequencer,也只是透過某種競爭或是共識機制去拿,而非Storage Proof 這種ZK 的形式。更重要的是ZK Rollup 除了計算層之外,還要實作一個類似L1 區塊鏈的儲存層,這個儲存是永久存在的,而ZK Coprocessor 則是「無狀態」的,進行完計算之後,不需要保留所有狀態。
從應用場景來講,協處理器可以看做所有Layer1/Layer2 的一個服務型插件,而Rollup 則是自己重新起一個執行層,幫助結算層擴容。
二. 為什麼非得用ZK,用OP 行不行?
看完上面,你可能會有一個疑惑,協處理器,非得用ZK 來做麼?聽起來怎麼這麼像是一個「加了ZK 的Graph」,而我們似乎對於Graph 上面的結果也沒有什麼「大的懷疑」。
說是這麼說,那是因為平常你用Graph 的時候基本上不太牽扯真金白銀,這些索引都是服務off-chain services 的,你在前端用戶界面上看到的,交易量,交易歷史等等數據,可以透過graph,Alchemy,Zettablock 等多家數據索引提供者來提供,但這些數據沒辦法塞回到智能合約裡面,因為一旦你塞回去就是去增加了額外的對這個索引服務的信任。當數據跟真金白銀,尤其是那種大體量的TVL 進行聯動之時,這種額外的信任就變得重要起來,想像下一個朋友問你借100 塊,你可能眼都不眨說給就給了,問你借1 萬,甚至100 萬的時候呢?
但話又說回來,是不是協處理上面所有的場景真的都得用ZK 來做呢? 畢竟Rollup 裡面我們就有OP 和ZK 兩條技術路線,最近流行的ZKML,也有相應分支路線的OPML 概念提出,那麼協處理器這事兒,是不是也有個OP 的分支,比如說OP-Coprocessor?
其實還真的有 — 不過在此我們先對具體的細節保密,很快我們將會發布更細節的資訊出來。
三. 協處理器哪家強 — 市面上常見的幾家協處理器技術方案對比
Brevis
Brevis 的架構由三個元件組成:zkFabric、zkQueryNet 和zkAggregatorRollup。
如下是一個Brevis 的架構圖:
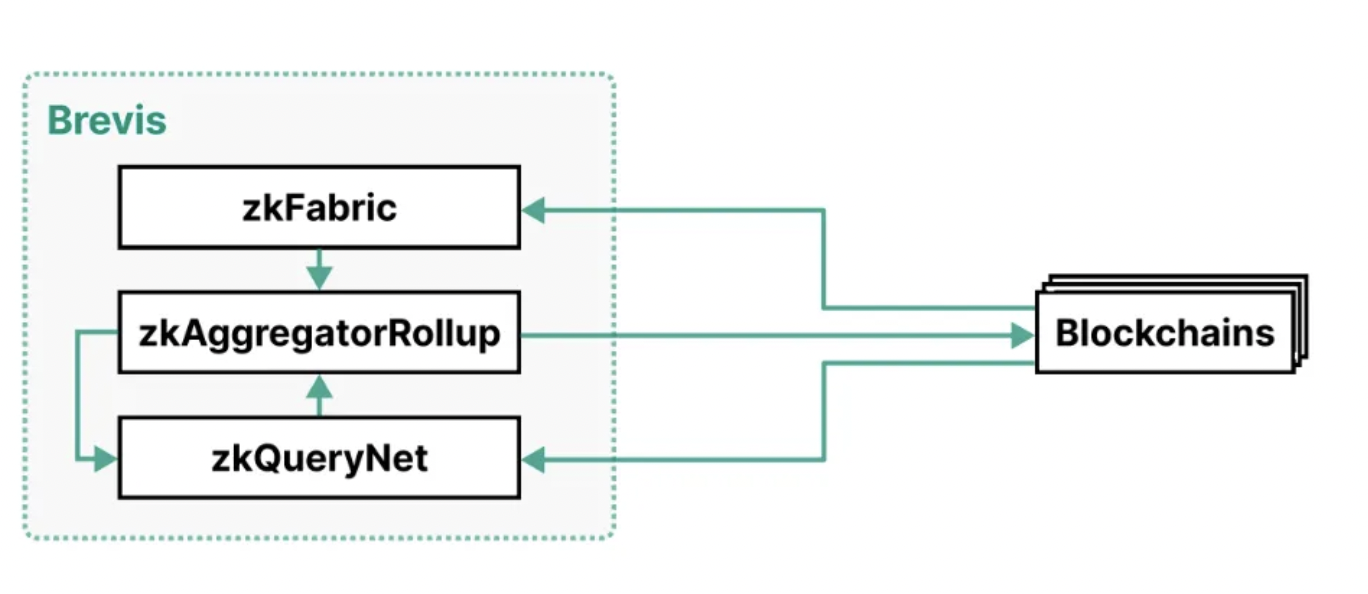
zkFabric: 從所有連接的區塊鏈中收集區塊頭,並產生證明這些區塊頭有效性的ZK 共識證明。透過zkFabric, Brevis 實現了多鏈可互通的協處理器,也就是能夠讓一個區塊鏈存取另一個區塊鏈的任意歷史資料。
zkQueryNet: 一個開放的ZK 查詢引擎市場,可接受來自dApp 的資料查詢,並對其進行處理。資料查詢使用來自zkFabric 的經過驗證的區塊頭處理這些查詢,並產生ZK 查詢證明。這些引擎既有高度專業化的功能,也有通用化的查詢語言,可滿足不同的應用需求。
zkAggregatorRollup: 一個ZK 卷積區塊鏈,作為zkFabric 和zkQueryNet 的聚合和儲存層。它驗證這兩個組件的證明,儲存經過驗證的數據,並將其經過zk 驗證的狀態根提交到所有連接的區塊鏈上。
ZK Fabric 作為為區塊頭產生proof 的關鍵部分,確保這一部分的安全是非常重要的,如下為zkFabric 的架構圖:
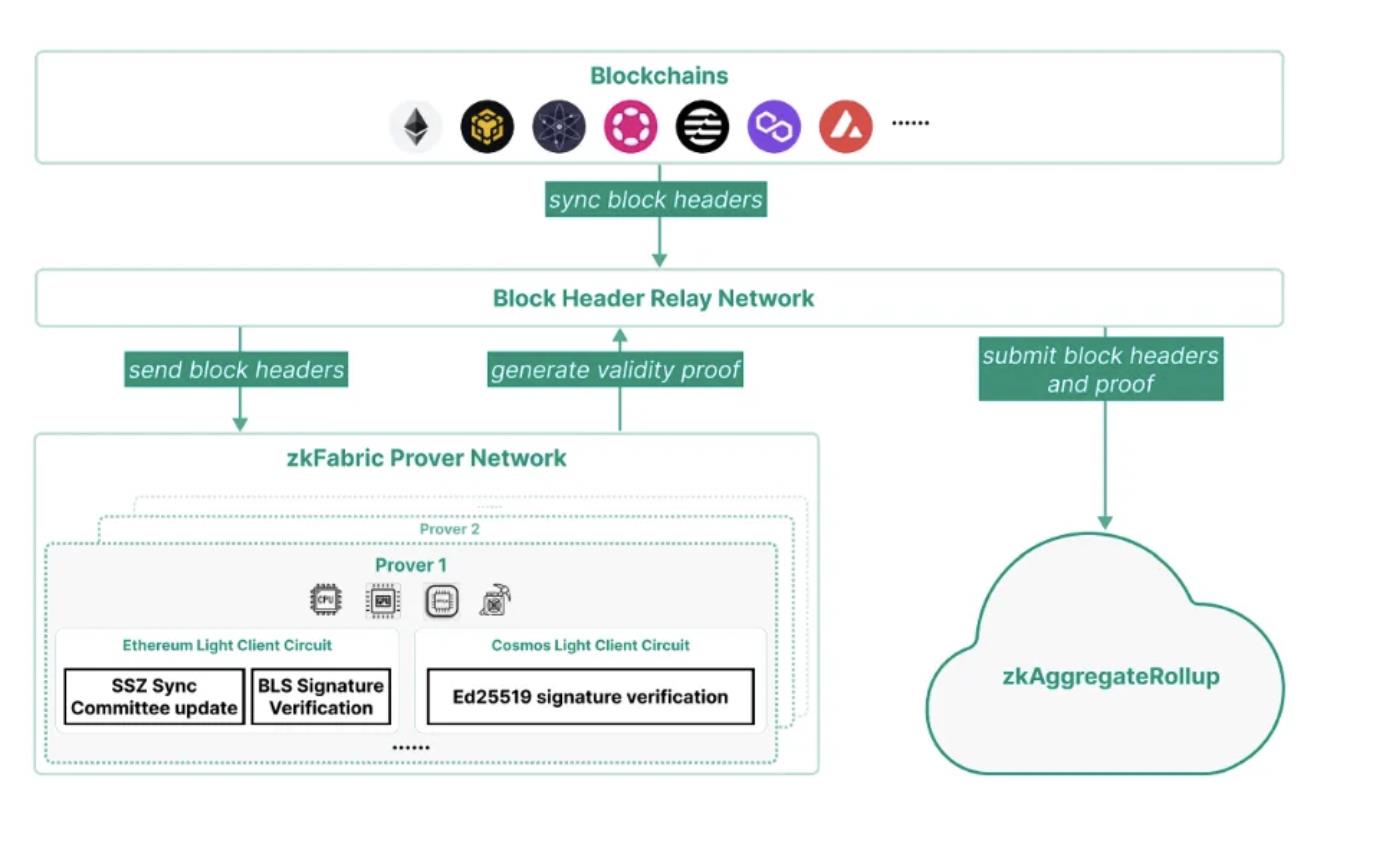
zkFabric 基於零知識證明(ZKP)的輕客戶端使其完全免於信任,無需依賴任何外部驗證實體。無需依賴任何外部驗證實體,因為其安全性完全來自於因為其安全性完全來自於底層區塊鏈和數學上可靠的證明。
zkFabric Prover 網路為每個區塊鏈的lightclient 協定實現電路,該網路為區塊頭生成有效性證明。證明者可利用GPU、FPGA 和ASIC 等加速器,最大限度地減少證明時間和成本。
zkFabric 依賴區塊鏈和底層加密協定的安全假設和底層加密協定的安全假設。不過,要確保zkFabric 的有效性,至少需要一個誠實的中繼器來同步正確的fork。因此,zkFabric 採用了去中心化的中繼網路而不是單一中繼器來優化zkFabric 的有效性。這種中繼網路可以利用現有的結構,如Celer 網路中的狀態監護網路。
證明者分配: 證明者網路是一個分散的ZKP 證明者網路、需要為每個證明產生任務選擇一個證明者,並向這些證明者支付費用。
目前的部署:
目前為各種區塊鏈(包括以太坊PoS、Cosmos Tendermint 和BNB Chain)實現的輕客戶端協定作為範例和概念驗證。
Brevis 目前已經跟uniswap hook 開展合作,hook 大大添加了自定義uniswap 池,但與CEX 相比,UnisWap 仍然缺乏有效的數據處理功能來創建依賴大型用戶交易數據(例如基於交易量的忠誠度計劃)的功能。
在Brevis 的幫助下,hook 解決了挑戰。 hook 現在可以從使用者或LP 的完整歷史鏈資料中讀取,並以完全無信任的方式運行可自訂的計算。
Herodotus
Herodotus 是一個強大的資料存取中間件,它為智慧合約提供如下跨以太坊層同步存取當前和歷史鏈上資料的功能:
- L1 states from L2s
- L2 states from both L1s and other L2s
- L3/App-Chain states to L2s and L1s
Herodotus 提出儲存證明這個概念,儲存證明融合了包含證明(確認資料的存在)和計算證明(驗證多步驟工作流程的執行),以證明大型資料集(如整個以太坊區塊鏈或rollup)中一個或多個元素的有效性。
區塊鏈的核心是資料庫,其中的資料使用Merkle 樹、Merkle Patricia 樹等資料結構進行加密保護。這些資料結構的獨特之處在於,一旦資料被安全地提交給它們,就可以產生證據來確認資料包含在結構內。
Merkle 樹和Merkle Patricia 樹的使用增強了以太坊區塊鏈的安全性。透過在樹的每個層級對資料進行加密雜湊,幾乎不可能在不被發現的情況下更改資料。對數據點的任何更改都需要更改樹上相應的哈希值到根哈希值,這在區塊鏈標頭中公開可見。區塊鏈的這一基本特徵提供了高水準的資料完整性和不變性。
其次,這些樹可以透過包含證明進行有效的資料驗證。例如,當驗證交易的包含或合約的狀態時,無需搜尋整個以太坊區塊鏈,只需驗證相關Merkle 樹內的路徑即可。
Herodotus 定義的儲存證明是以下內容的融合:
- 包含證明:這些證明確認加密資料結構(例如Merkle 樹或Merkle Patricia 樹)中特定資料的存在,確保相關資料確實存在於資料集中。
- 計算證明:驗證多步驟工作流程的執行,證明廣泛資料集中一個或多個元素的有效性,例如整個以太坊區塊鏈或匯總。除了指示資料的存在之外,它們還驗證應用於該資料的轉換或操作。
- 零知識證明:簡化智能合約需要互動的資料量。零知識證明允許智能合約在不處理所有基礎資料的情況下確認索賠的有效性。
Workflow
1. 獲得區塊哈希
區塊鏈上的每個資料都屬於特定的區塊。區塊哈希作為該區塊的唯一標識符,透過區塊頭來總結其所有內容。在儲存證明的工作流程中,首先需要確定和驗證包含我們感興趣的資料的區塊的區塊哈希,這是整個過程中的首要步驟。
2. 獲得區塊頭
一旦獲得了相關的區塊散列,下一步就是存取區塊頭。為此,需要與上一步獲取的區塊哈希值相關聯的區塊頭進行哈希處理。然後,將提供的區塊頭的雜湊值與所得的區塊雜湊值進行比較:
取得哈希的方式有兩種:
- 使用BLOCKHASH opcode 來檢索
- 從Block Hash Accumulator 來查詢歷史中已經被驗證過的區塊的哈希
這一步驟可確保正在處理的區塊頭是真實的。該步驟完成後,智慧合約就可以存取區塊頭中的任何值。
3. 確定所需的根 ( 可選)
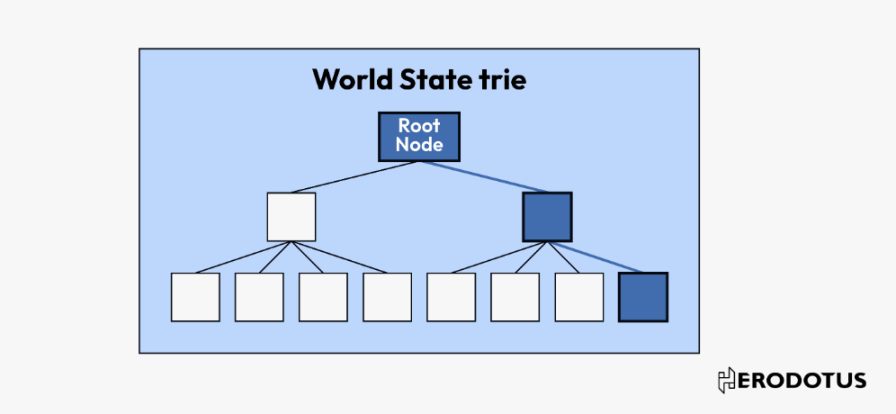
有了區塊頭,我們就可以深入研究它的內容,特別是:
stateRoot: 區塊鏈發生時整個區塊鏈狀態的加密摘要。
receiptsRoot: 區塊中所有交易結果(收據)的加密摘要。
事務根(transactionsRoot): 區塊中發生的所有交易的加密摘要。
跟可以被解碼,使得能夠核實區塊中是否包含特定帳戶、收據或交易。
4. 根據所選根來驗證資料(可選)
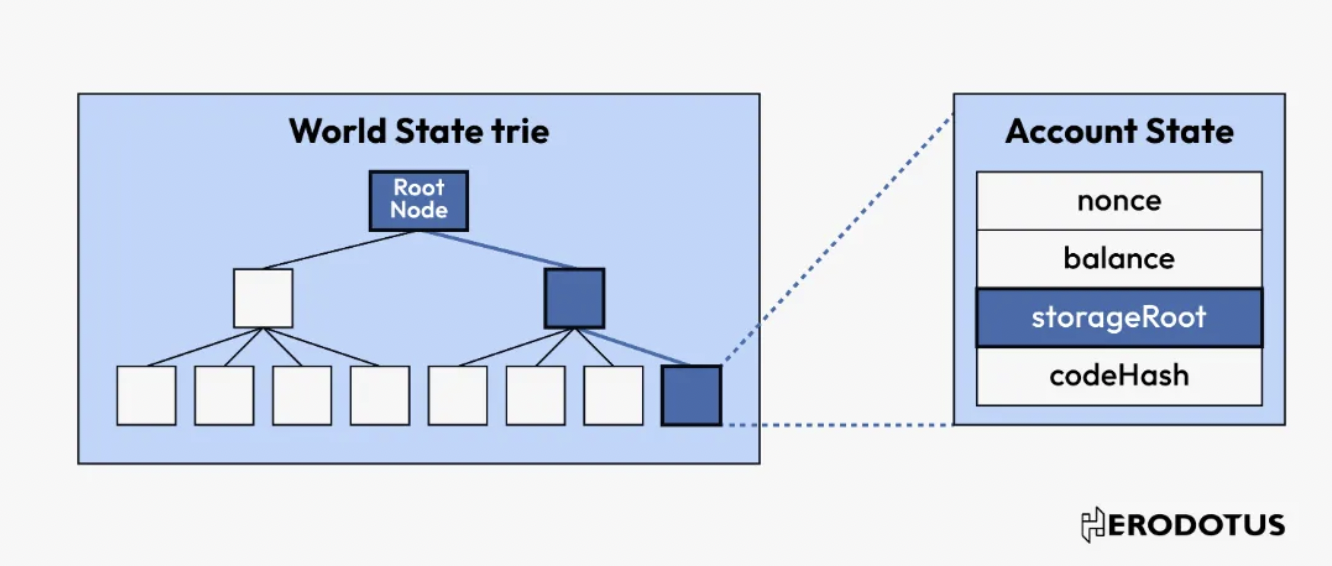 有了我們所選的根,並考慮到以太坊採用的是Merkle-Patricia Trie 結構,我們就可以利用Merkle 包含證明來驗證樹中是否存在資料。驗證步驟將根據數據和區塊內數據的深度而有所不同。
有了我們所選的根,並考慮到以太坊採用的是Merkle-Patricia Trie 結構,我們就可以利用Merkle 包含證明來驗證樹中是否存在資料。驗證步驟將根據數據和區塊內數據的深度而有所不同。
目前支援的網路:
- From Ethereum to Starknet
- From Ethereum Goerli* to Starknet Goerli*
- From Ethereum Goerli* to zkSync Era Goerli*
Axiom
Axiom 提供了一種方式可以讓開發人員從以太坊的整個歷史記錄中查詢區塊頭,帳戶或儲存值。 AXIOM 引入了一種基於密碼學的連結的新方法。 Axiom 傳回的所有結果均透過零知識證明在鏈上驗證,這意味著智慧合約可以在沒有其他信任假設的情況下使用它們。
Axiom 最近發布了Halo2-repl ,是一個基於瀏覽器的用Javascript 編寫的halo2 REPL。這使得開發人員只需使用標準的Javascript 就能編寫ZK 電路,而無需學習Rust 等新語言、安裝證明庫或處理依賴關係。
Axiom 由兩個主要技術組件組成:
- AxiomV1 — 以太坊區塊鏈緩存,從Genesis 開始。
- AxiomV1Query — 執行針對AxiomV1 查詢的智慧合約。
在AxiomV1 中緩存區塊哈希值:
AxiomV1 智慧合約以兩種形式快取自創世區塊以來的以太坊區塊哈希:
首先, 快取了連續1024 個區塊哈希的Keccak Merkle 根。這些Merkle 根透過ZK 證明進行更新,驗證區塊頭哈希是否形成以EVM 直接可存取的最近256 個區塊之一或已存在於AxiomV1 快取中的區塊雜湊為結束的承諾鏈。
其次。 Axiom 從創世區塊開始儲存這些Merkle 根的Merkle Mountain Range。該Merkle Mountain Range 是在鏈上建造的,透過對緩存的第一部分Keccak Merkle 根進行更新。
在AxiomV1Query 中履行查詢:
AxiomV1Query 智慧合約用於大量查詢,以實現對歷史以太坊區塊頭、帳戶和帳戶儲存的任意資料的無信任存取。查詢可以在鏈上進行,並且透過針對AxiomV1 快取的區塊哈希進行的ZK 證明來在鏈上完成。
這些ZK 證明檢查相關的鏈上資料是否直接位於區塊頭中,或位於區塊的帳戶或儲存Trie 中,透過驗證Merkle-Patricia Trie 的包含(或不包含)證明來實現。
Nexus
Nexus 試圖利用零知識證明為可驗證的雲端運算建立通用平台。目前是machine archetechture agnostic 的,對risc 5/ WebAssembly/ EVM 都支援。 Nexus 利用的是supernova 的證明系統,團隊測試產生證明所需的記憶體為6GB,未來將在此基礎上優化使得普通的用戶端裝置電腦可以產生證明。
確切的說,架構分為兩部分:
- Nexus zero:由零知識證明和通用zkVM 支援的去中心化可驗證雲端運算網路。
- Nexus: 由多方運算、狀態機複製和通用WASM 虛擬機器驅動的分散式可驗證雲端運算網路。
Nexus 和Nexus Zero 應用程式可以用傳統程式語言編寫,目前支援Rust,以後將會支援更多的語言。
Nexus 應用程式在去中心化雲端運算網路中運行,該網路本質上是一種直接連接到以太坊的通用「無伺服器區塊鏈」。因此,Nexus 應用程式並未繼承以太坊的安全性,但作為交換,由於其網路規模縮小,可以獲得更高的運算能力(如運算、儲存和事件驅動I/O)。 Nexus 應用程式在專用雲端上運行,可達成內部共識,並透過以太坊內部可驗證的全網路閾值簽章提供可驗證運算的「證明」(而非真正的證明)。
Nexus Zero 應用程式確實繼承了以太坊的安全性,因為它們是帶有零知識證明的通用程序,可以在BN-254 橢圓曲線上進行鏈上驗證。
由於Nexus 可在複製環境中運行任何確定性WASM 二進位文件,因此預計它將被用作證明生成應用的有效性/ 分散性/ 容錯性來源,包括zk-rollup 排序器、樂觀的rollup 排序器和其他證明器,如Nexus Zero 的zkVM 本身。







 APP
APP 

