




原文:《 Fraud and Data Availability Proofs 》by Rabia Fatima
編譯:ChinaDeFi
最近,我們在推特上看到了關於數據可用性及其重要性的討論。毫無疑問,L2 解決方案正在賦予以太坊能夠成為全球超級計算機的力量。然而,我們不能否認的事實是,就算使用L2,但由於數量的限制,我們也無法實現我們的預期。其中第一個也是最重要的問題是「數據可用性問題(DA)」。因此,在本系列中,我們將深入了解DA 是什麼,以及如何通過數據抽樣和欺詐證明來解決它。
為了完全理解DA 證明的概念我們需要知道的有:
- 欺詐和數據可用性證明
- DA 背景下的Reed Solomon 代碼
- Merkle 樹構造的二維Reed Solomon 代碼
- 錯誤生成的擴展數據的欺詐證明
在這篇文章中,我們將討論什麼是數據可用性,為什麼它對我們很重要,以及解決這個問題的潛在方案是什麼。我們還將討論在檢測到L2 上的惡意交易時,節點應如何提交欺詐證明。
加密貨幣平台每天都在受到大量的關注。但這種大規模的採用依然伴隨著現有區塊鏈的可擴展性限制。有可能解決該問題的方案是通過改進硬件規格來簡單地增加鏈上吞吐量。但是這樣做的話,就會損害去中心化,因為如果需要大型硬件,那麼能夠參與的節點會非常少。因此,大多數節點將運行輕客戶端,並依賴於完整節點來驗證區塊鏈狀態。在大多數節點不誠實的情況下,這種依賴並不十分靠譜。這就是為什麼L1 把鏈下解決方案作為實現可擴展性的最佳替代方案的主要原因。
當我們談論像Rollup 這樣的鏈下解決方案時,我們常常傾向於忽略一個事實,就是即使使用Rollup,我們也不能實現無限的吞吐量。想過為什麼嗎?
這是因為Rollup 是一種鏈下計算解決方案,它在鏈下執行狀態計算。為了完成區塊,他們確實需要將狀態和callData 發佈到基礎層,如以太坊。因此,即使我們製作了sequencer,一個超級計算機來產生無限區塊,但由於基礎層的網絡和存儲限制,我們無法最終確定它們。
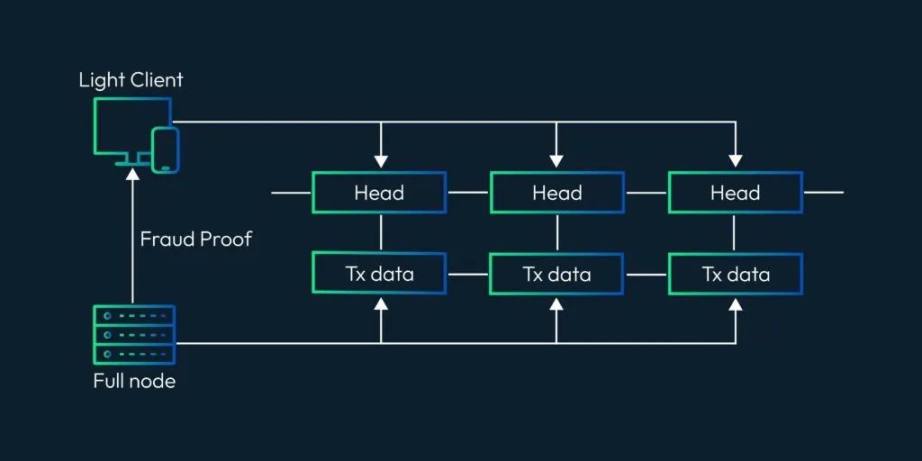
所以當我們認識到Rollup 本身不能實現無限的吞吐量時,我們就會有另一個問題,那就是如果中心化sequencer 本身不誠實怎麼辦?他計算出了一個錯誤的狀態了呢? L1 如何拒絕這些交易?現在當遇到這種情況時,我們在基礎層上有完整的節點,這些節點會監控狀態,在檢測到錯誤的交易時,它們可以提交欺詐證明,以標記區塊無效。
這是否意味著所有負責監控Rollup 活動的L1 節點都需要下載整個sequencer 數據呢?? 答案是肯定的,情況正是如此。也就是說即使提出了鏈下解決方案,我們仍然需要完整節點,並提高我們的硬件需求。
在此基礎上,就算我們設法運行一個強大的節點來監控交易,這仍然不能保證sequencer 不會試圖通過隱瞞數據來作弊。因為即使1% 的數據不可用,也沒有節點可以重建狀態,因此沒有人可以在定義的時間內提交欺詐證明,使區塊有效。這就是我們定義的「數據可用性問題」。
但沒有必要恐慌,因為以太坊已經提出了另一個聰明的解決方案來解決這個問題,即「數據可用性抽樣」。那麼什麼是數據可用性抽樣呢?它允許我們在不需要節點下載整個數據的情況下確保數據可用性。這是實現可擴展性的重大突破。
所以我們有兩個概念:
- sequencer 試圖用錯誤的交易來作弊,同時不保存任何數據。
- sequencer 試圖用錯誤的交易來作弊,並且還保留了一定比例的數據,以便節點可能無法重建區塊來提供欺詐證明。
現在我們想證明在共識節點中在不誠實的大多數的影響下,輕節點不會接受帶有無效交易的區塊。
作為第一個概念的例子,我們假設一個場景,惡意的sequencer 試圖通過在區塊中包含錯誤的交易來進行欺騙,但不保存任何數據。
在Optimistic Rollup 的情況下,為了證明該區塊是無效的,節點需要重構一個區塊並為它提交一個欺詐證明。
Rollup 區塊結構
當涉及到支持欺詐證明的生成和有效性時,區塊結構非常重要。現在假設高度為i 的區塊頭h_i 包含以下信息。
- 先前的Blockhash 哈希(prevHash_i)
- 涉及區塊交易的數據Merkle Root (dataRoot_i)
- Merkle 樹中表示的葉數(dataLength_i)
- Rollup 狀態的Merkle 樹(stateRoot_i)
- 網絡可能需要的其他任意數據(additionalData_i)
在以太坊等基於賬戶的模型中,鍵值對是賬戶地址和余額。
首先,我們定義一個轉換函數,它在執行轉換時不需要整個狀態樹,而只需要對交易讀取或寫入的狀態樹部分的Merkle 證明,這通常被稱為「State Witness」。這些Merkle 證明有效地表示了為具有公共根的同一狀態樹的子樹。函數可以定義為:
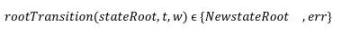
- t→Rollup 交易
- w→Merkle 交易證明樹
w 由狀態樹中的一組值對及其相關的Merkle 證明組成。
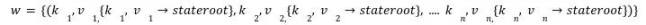
在w 給定的部分狀態上執行所有交易t 之後( 如果交易修改了任何狀態),可以通過用修改過的葉子計算新子樹的新根來生成新的結果NewstateRoot。
如果w 不是正確的witness,並且不包含執行過程中交易所需的所有葉子部分,那麼它將拋出異常錯誤err。
對於本系列的其餘部分,將在此總結一些註釋:

什麼是innerRoot?
innerRoot 是應用一定數量交易后區塊中的中間根的表示。
當我們討論Rollup 狀態驗證時,數據是最重要的東西。數據幫助我們重構狀態,並驗證由Rollup 發布的狀態是否有效。這就是為什麼將DataRoot 傳遞給輕客戶端非常重要。
什麼是DataRoot?
dataRoot_i 是固定大小的交易數據塊,以字節為單位,我們稱為「shares」。 shares 不會包含所有的交易,而是包含交易的固定部分。我們保留每個share 中的第一個字節作為第一個交易的起始位置。這允許協議消息解析器建立消息邊界,而不需要區塊中的每個交易。
給定一個shares 列表(sh0, sh1,…)shn),我們定義一個函數parseShares,它解析這些shares 並輸出消息列表(m0、m1、……mt),這些消息要么是交易,要么是中間狀態根。例如,在某些區塊i 中間的一些share 上的parseShares 可能會返回(trace1i, t4i, t5i, t6i,trace2i)。
我們不能在每個交易之後都包含狀態根,所以我們可以定義一個週期,例如在g 個gas 的p 個交易之後,我們可以在區塊中包含一個中間狀態根。因此,我們有一個函數parsePeriod,它解析一個消息列表並返回一個狀態前中間根tracexi 和狀態後中間根tracex+1i 和一個交易列表(tig, tig+1,…tig+h),這樣當我們在tracexi 上應用這些交易時,它必須給我們tracex+1i。如果交易不符合條件,則函數必須返回一個err。

如何驗證狀態轉換無效?
如果惡意的sequencer 為我們提供了不正確的stateRoot 呢?我們可以通過「VerifyTransitionFraudProof」函數檢查stateRoot 的無效。該函數接受完整節點提交的欺詐證明並對其進行驗證。
什麼是欺詐證明?
欺詐證明包括以下內容:
- 區塊中包含錯誤狀態轉換的相關shares。
- 這些shares 的Merkle 證明。
- shares 交易的State witness。
VerifyTransitionFraudProof 函數將特定受挑戰時期的交易應用到前狀態中間,這必須導致中間後狀態根。

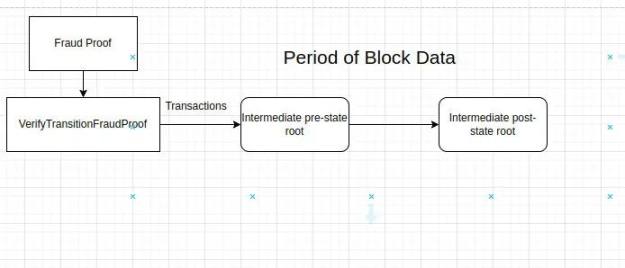
如果所有給定條件都為真,則函數VerifyTransitionFraudProof 返回真,否則返回假。


我們已經了解了DA 和欺詐證明,現在開始討論第二個概念,也就是如果sequencer 計算了一個無效的交易,而我作為輕客戶端檢測到它,那該怎麼辦。現在我需要為它計算一個欺詐證明。然而,sequencer 並沒有發布完整的數據,通過這些數據我可以重建狀態以進行驗證。對於這個問題,Optimism 等Rollup 提出了一個解決方案,即強制sequencer 發布數據。







 APP
APP 

