




作者:imToken Labs
概述
5 月11、12 日連續兩天晚上,以太坊共識層短暫異常,imToken 分析該異常主要某幾種以太坊共識層客戶端節點負載過高,使得Validator 宕機離線,直接導致Epoch 投票無法達到2 /3,共識層無法確認最終性,但短時間過後以太坊網絡自我恢復正常,imToken 認為這表明以太坊PoS 共識算法具備韌性和自我修復的能力。
事件及背景
通常情況下,以太坊PoS 共識網絡狀態會在2 個Epoch 被敲定(Finalized),而上週出現了兩次Epoch 敲定的延遲。
第一次發生在5 月11 日,Epoch 的敲定被延遲了3 個Epoch,約20 分鐘。
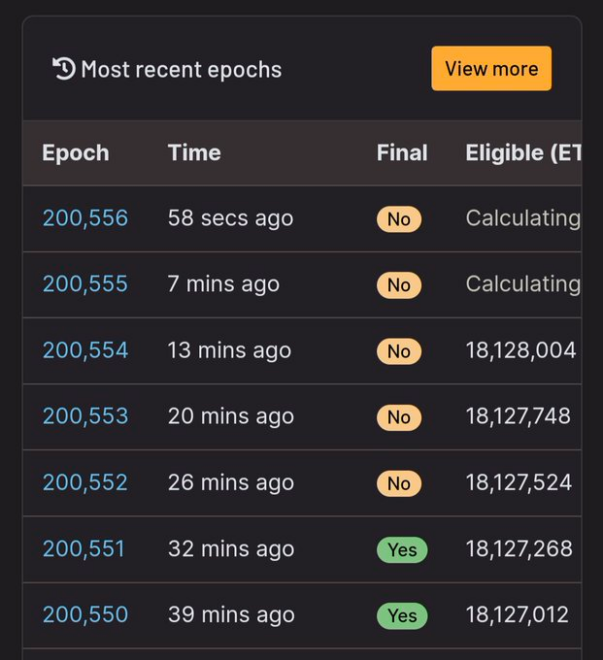
第二次發生在5 月12 日,Epoch 的敲定被延遲了8 個Epoch,約51 分鐘。
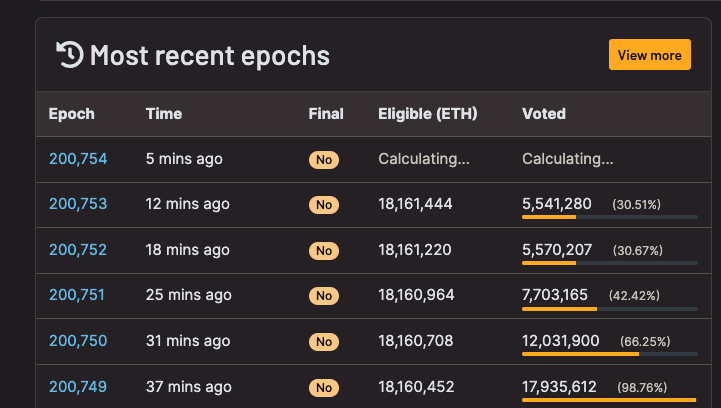
在事件發生期間,以太坊網絡仍然持續產生區塊並處理交易。然而,由於Validator(驗證節點)的投票率不足,Epoch 無法敲定(即Epoch 得到以太坊PoS 網絡共識級別安全保證)。 Epoch 未能敲定意味著在絕大多數Validator 作惡並出現分叉的情況下,epcoh 可能被回滾,從而導致交易被回滾。
實際上,在事件發生的期間,以太坊網絡並未出現分叉,而Validator 也未進行惡意投票,只因大量Validator 離線導致投票率不足,從而使得Epoch 在期間無法被敲定。
經過觀察,離線的Validator 出現CPU 過載的異常情況,被認為是Validator 離線的直接原因。

在第二次事件中,Epoch 敲定被延遲了8 個Epoch,由於敲定延遲大於MIN_EpochS_TO_INACTIVITY_PENALTY (=4) 從而觸發了以太坊共識算法Inactivity leak的處理機制。
- 懲罰離線的Validator,削減其質押資金, 罰沒了約28 個ETH 。
- 取消Attestation 的獎勵,導致約50 個ETH 未被發行。
- 該機制保證在線Validator 最終能掌握以太坊總質押資金的⅔,從而使得網絡狀態最終能被敲定
imToken 的節點服務也偵測到了此次事件,通過實時監控以太坊共識層Validator 投票的情況,從而在Epoch 未能正常敲定前,提前預警以太坊共識網絡的異常。下圖是第一次事件發生時的節點狀態。
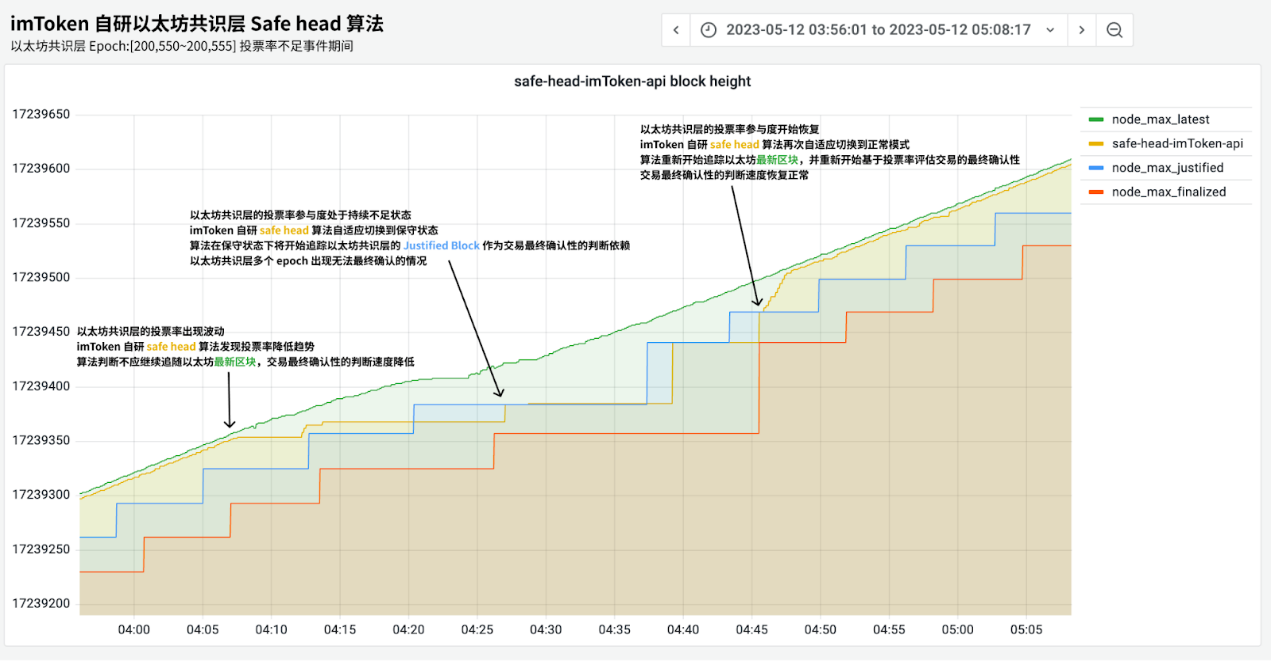
PoW 機制下,交易的成功是認定交易在多少連續區塊後大概率不會被回滾,PoS 則是以Safe Head 返回的塊高作為交易成功的判定。而目前的規範中則是以Justified Checkpoint 作為Safe Head 的狀態認定,因此以前一Epoch 的狀態來看,可能存在有6.4 分鐘之久的判定延遲,這對用戶而言是很糟糕的體驗。
imToken 自研的Safe Head 服務會基於實時的以太坊共識層數據,計算出安全的區塊用於交易確認,在保證用戶交易安全的前提下,縮短交易確認的時長。正常情況下,imToken 的Safe Head 算法返回的塊高(如上圖黃色),會非常貼近最新的區塊高度(綠色),從而提高用戶體驗。
更多關於Safe Head 機制的資料:
原因分析
造成上述事件的直接原因是某幾種以太坊共識層客戶端節點負載過高,使得Validator 宕機離線,從而無法正常進行共識投票。經過分析,這些節點負載過高的原因是:
當收到指向陳舊區塊的見證( Attestation )時,節點需要重新計算信標鏈狀態以驗證這些見證,而該過程需要消耗大量的CPU 以及內存資源。
當同時收到大量指向陳舊區塊的見證時,節點的CPU 以及內存資源被耗光,從而導致這些Validator 宕機離線。
本來此類問題可以通過基於見證指向區塊的緩存來解決,然而由於Validator 的規模增長以及大量此類attestation 的出現,導致出問題的客戶端實現的緩存被擊穿,節點不得不消耗大量資源重新計算信標鏈狀態。
共識層客戶端Teku 以及Prysm 目前推出了patch 版本以解決該問題。具體而言,patch 版本的客戶端實現會過濾掉這些陳舊的見證,即當滿足下列條件,忽略該見證:
- 見證指向一個陳舊的Slot
- 見證指向一個節點從未見過的Checkpoint
然而,我們仍需持續觀察以太坊主網敲定的情況以確認patch 的有效性。
共識層客戶端Teku 以及Prysm 的patch 版本:
- Prysm: v4.0.3-hotfix
- Teku: v23.5.0
以太坊設計優勢
在此次事件中,以太坊保證可用性仍持續產生區塊並處理交易,而僅推遲Epoch 敲定的關鍵在於兩點:
- 以太坊客戶端的多樣性
- Gasper 算法的設計
以太坊客戶端的多樣性
在此次事件中,雖然共識層客戶端Teku 以及Prysm 的實現出現了問題,但不影響其他共識層客戶端的正常運作。像是Lighthouse 客戶端本次並不受影響,由於不同客戶端在實現的設計上並不相同,因此仍有Validator 正常在運作。
以太坊客戶端的多樣性保證了:即使某些客戶端出現問題(甚至導致Epoch 不能敲定),也不會影響正常的客戶端產生區塊並處理交易,使得以太坊的可用性得到保持。
以太坊Gasper 共識算法對可用性的設計
保證以太坊的可用性是以太坊共識算法Gasper 的設計出發點之一,其把以太坊區塊生產與敲定分離。因此,即使區塊敲定受阻,區塊的產生並不會隨之終止。考慮到大部分情況下,區塊敲定最終會恢復(產生的區塊最終仍會被敲定),那麼對用戶影響其實會很低。對比其他BFT 的共識算法:若區塊敲定失敗,共識節點會停止產出下個區塊。從而,導致期間整個區塊鏈不可用,即俗稱的「區塊鏈掛了」。
另外,第二次事件還觸發到了Inactivity Leak 的機制,其主要是為了保證以太坊在極端情況(大量Validator 長時間離線)下仍能重新敲定區塊。
經驗與啟示
以太坊多客戶端的挑戰
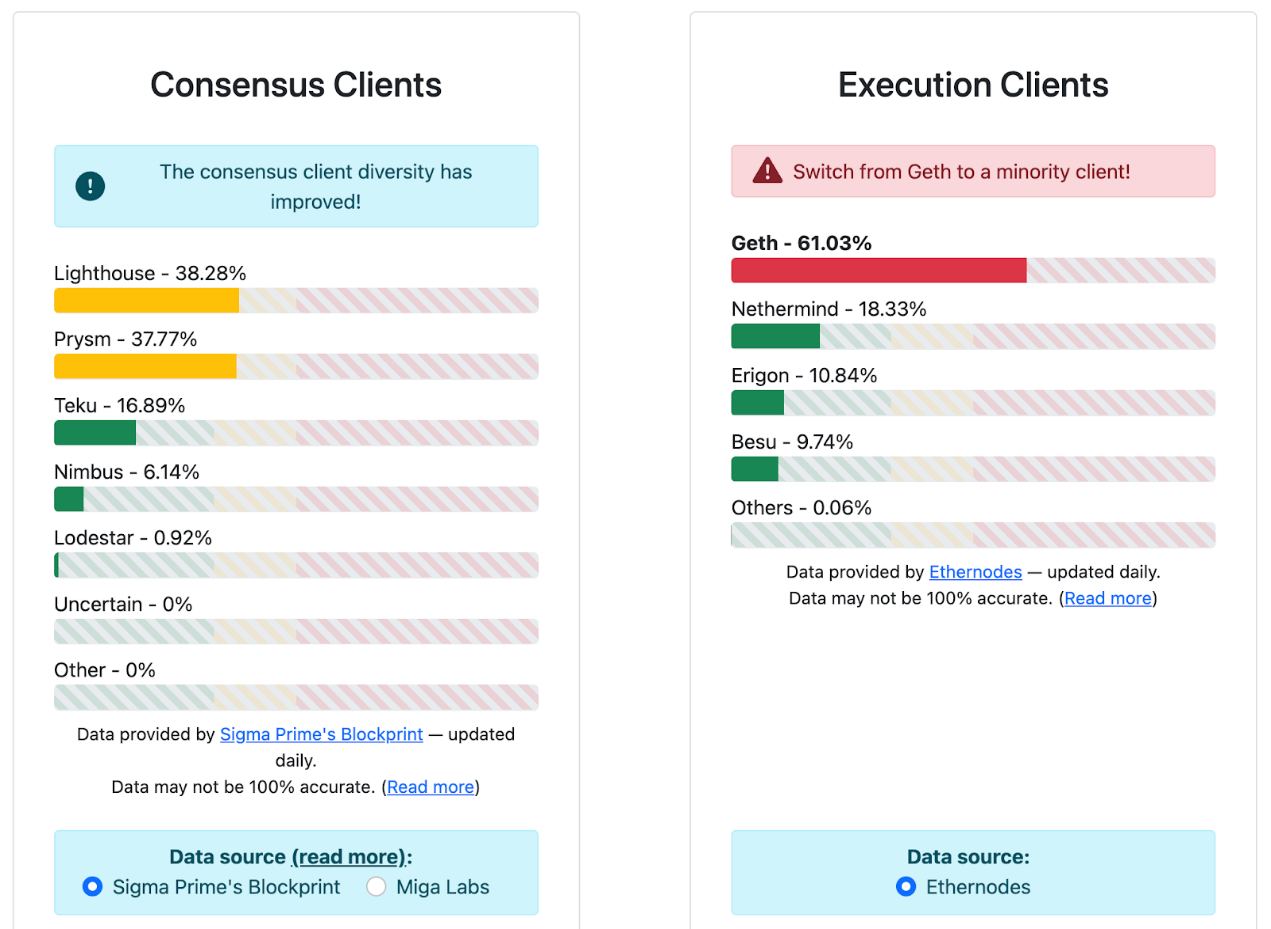
當前,以太坊客戶端多樣性現狀如下圖所示:
來源: https://clientdiversity.org/#distribution
可以看到,以太坊客戶端多樣性仍需繼續推廣和宣傳。可以想像,如果客戶端實現足夠多樣,使得Prysm 以及Teku 的佔比小於⅓,那麼這次事件甚至不會發生(⅔ 客戶端正常運作足以敲定Epoch)。另外,當前執行層的客戶端集中在Geth,佔比高達61%。這實際上存在著潛在風險:如果Geth 運作不當,以太坊會受到很大的影響。
除了以太坊客戶端多樣性需要進一步努力外,以太坊客戶端切換也是此次事件暴露的一個痛點:當某個客戶端實現出問題時,Validator 如何切換到正常的客戶端實現之上。此過程涉及:
- 把出問題客戶端的Validation key 安全地遷移到正常的客戶端之上
- 由於以太坊共識有Slash 的規則,需要保證舊客戶端與新客戶端的行為的一致性而不被Slash。例如:
- 新舊客戶端分別對分叉兩側的Checkpoint 進行投票,從而被Slash
- 新舊客戶端在同一個Slot 產出不同的區塊,從而被Slash
以太坊共識的監控
需要類似Safe Head 類似的服務持續監控以太坊PoS 網絡的實時狀態,提前發現並預警該類事件,而非等到Epoch 無法按預期敲定才得知網絡狀態異常。相關的最新研究可見此文章。
以太坊共識算法的科普
這次事件暴露了科普以太坊PoS 共識機制的必要性。在此次事件中,很多用戶誤以為「以太坊掛了」,從而造成不必要的恐慌。然而,實際上,以太坊網絡持續產生區塊並處理交易。以太坊共識層和執行層的組合為以太坊交易交易確認帶來雙重保障,在共識層Epoch 無法敲定的情況下,執行層的區塊處理並不受影響,且Epoch 敲定的異常狀況也在以太坊共識算法中有相應處理設計。面向用戶的區塊鏈知識科普仍然是從業者們需要持續努力的方向。
對以太坊應用的啟示
雖然以太坊網絡足夠健壯,但是偶爾的不穩定會對應用有著一定的影響。同時,應用要正確處理這些不穩定的場景。
- Layer1 -> Layer2 的存款時間會變長。 Layer2 在mint 的時候,一個重要前提是需要保證L1 存款交易不會被回滾。因此,當以太坊網絡Epoch 敲定被推遲的情況下,L1->L2 的存款時間也會相應變長。
- 類似的,交易所也需要防止鏈上充值交易被回滾的情況,因此其充值時間也會相應變長。
- Oracle 鏈上報價存在被回滾的風險,因此依賴其的高價值服務要適當暫停。
- 在此次事件中,Uniswap 不顯示余額、只能買入不可賣出,而dYdX 暫停了存款。
總結
在這次事件中,我們可以看到以太坊PoS 共識算法的韌性與自我修復的能力,也看到客戶端很快在發生事故後,即時響應與修正錯誤。對以太坊整個生態而言,還需在以下方面持續投入:增加客戶端多樣性,優化對網絡狀態的實時監控與預警,深度用戶教育(不僅面向普通用戶,也需面向從業者),生態參與者在網絡異常時的緊急預案準備。
參考鏈接






 APP
APP 

