




本期萬向區塊鏈小課堂將為大家講解區塊鏈中經常提及的一棵樹:默克爾樹(Merkle Tree)。
來回憶下我們之前小課堂解構的區塊鏈六層模型,默克爾樹封裝在數據層,說明它是一個密碼學技術,用以保護區塊鏈的安全。

默克爾樹於1979年由美國計算機科學家拉爾夫·默克爾(Ralph Merkle)提出,本質上是一種樹狀數據結構,由數據塊、葉子節點、中間節點和根節點組成。所以,一組合,就叫“Merkle Tree”。
默克爾樹各部分的構成關係如下圖:
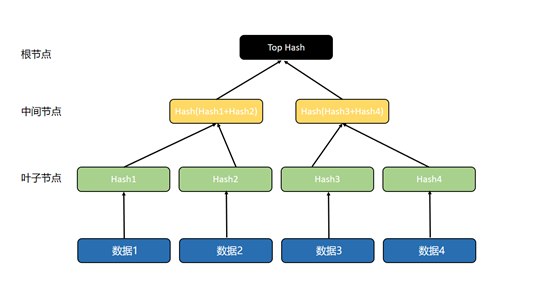
要得到這樣一棵默克爾樹,首先要對底部數據塊進行哈希運算,用每個數據塊對應的哈希值生成葉子節點。再對相鄰的2個葉子節點進行哈希運算,得到的哈希值生成中間節點,最後對相鄰的2個中間節點進行哈希運算,得到的哈希值生成根節點。由於各類節點都是由哈希值構成,因此默克爾樹又被稱為哈希樹,即儲存哈希值的樹狀數據結構。
看起來是不是很像一棵底下堆滿了禮物的聖誕樹?

哈希運算和哈希值
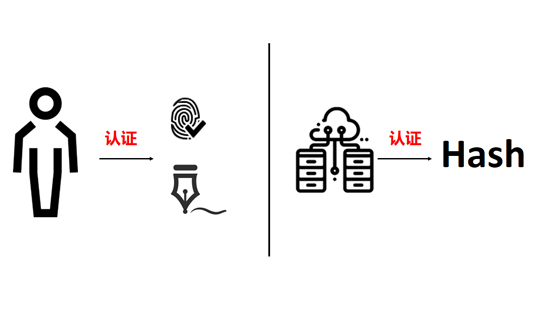
生成默克爾樹用到的哈希運算是區塊鏈中常用的加密函數。任意大小、長度的數據經過哈希運算後都會得到一個固定大小和長度的數值,即哈希值。就像我們的指紋或簽名能幫助鑑別我們的身份,哈希值也可以看成是數據的指紋或簽名,用於驗證數據的真實準確性,並具有以下特徵:
確定性
數據和哈希值之間是確定的一一對應關係,即相同數據經過哈希運算會得到相同的哈希值。
不可逆性
哈希運算的過程是不可逆的,即數據經過哈希運算可以得到哈希值,但不可以通過哈希值推導出原始運算數據,由此保證數據的隱私和安全性。比如Facebook等網站會將用戶密碼計算成哈希值並儲存。用戶每次輸入密碼時,密碼都會被轉換成哈希值與網站記錄的版本進行對比,從而驗證密碼是否正確。由於哈希運算的不可逆性,網站無法從哈希值中推導出用戶密碼,從而保證用戶信息安全。
統一性
即上文提到的任意大小、長度的數據經過哈希運算後會生成大小、長度統一的哈希值,一方面起到壓縮數據,減輕數據儲存壓力的作用,另一方面規整了雜亂無章的原數據,方便後期比對驗證。
為什麼要用默克爾樹?
由於默克爾樹本質上是由哈希值構成的樹狀數據結構,因此也繼承了哈希值用於保證數據安全隱私和校驗數據準確和完整性的功能,主要應用於點對點下載,例如BT下載、開源分佈式控制系統Git、比特幣和以太坊區塊鍊等場景中。因為我們難以保證這些去中心化系統中的每個節點都會提供真實可信的數據,也難以避免數據在傳輸過程中出現丟失、損壞等情況,所以需要引入數據加密和校驗機制。
看到這裡,你可能已經意識到了默克爾樹其實就是將數據分割成多個小塊,進行多次哈希運算,搭建出的一個樹狀數據結構。那為什麼要對數據進行拆分,計算出多個哈希值用於校驗呢?這不是增加工作量了嗎?但其實這樣做是為了提高數據驗證的靈活性,數據量越大,默克爾樹的這一優勢會體現得越明顯。
試想一下,如果我們不對數據進行拆分,而是將整體計算成一個哈希值,那當數據校驗出現問題時,我們很難分辨問題出現在哪裡,只能回過頭去對整個數據進行排查,如果數據量特別大,那麼這個錯誤排查過程無異於海底撈針。
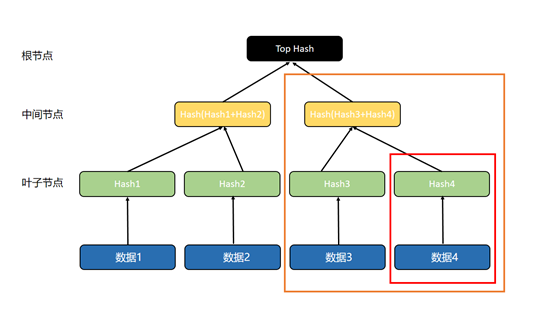
但在默克爾樹里,數據被拆分成多個小塊,形成了多個分支,可以根據具體情況對部分數據進行校驗,無需校驗整個數據,從而提高數據校驗的靈活性和效率。
最後總結一下默克爾樹的知識要點:
- 由哈希值構成的樹狀數據結構
- 用於驗證驗證區塊鍊等去中心化系統中的數據的完整準確性
- 具有靈活高效驗證數據的優勢





 APP
APP 

