




作者:火必研究院&謝錦斌(X Research DAO)
編輯: AndyHoo(X Research DAO)
1. 分佈式計算發展歷史和市場前景
1.1 發展歷史
- 最開始的計算機每台只能執行一個計算任務,隨著多核心多線程的CPU出現,單個計算機可以執行多個計算任務。
- 隨著大型網站的業務增加,單服務器模式很難進行擴容,又增加硬件成本。面向服務的架構出現,由多台服務器組成。由服務註冊者、服務提供者和服務消費者,三者組成。
- 但是隨著業務增加和服務器增加,SOA模式下,點對點服務可維護性和可拓展性難度增加。類似微機原理中,總線模式出現,來協調各個服務單元。服務總線通過類似集線器的架構將所有系統連接在一起。這個組件被稱為ESB(企業服務總線)。作為一個中間角色,來翻譯協調各個不同格式或者標準的服務協議。
- 隨後基於應用程序編程接口(API)的REST 模型通信,以其簡潔、可組合性更高的特性,脫穎而出。各個服務以REST形式對外輸出接口。當客戶端通過RESTful API 提出請求時,它會將資源狀態表述傳遞給請求者或終端。該信息或表述通過HTTP 以下列某種格式傳輸:JSON(Javascript 對象表示法)、HTML、XLT、Python、PHP 或純文本。 JSON 是最常用的編程語言,儘管它的名字英文原意為“JavaScript 對象表示法”,但它適用於各種語言,並且人和機器都能讀。
- 虛擬機、容器技術,以及谷歌的三篇論文:
2003年, GFS: The Google File System
2004年, MapReduce: Simplified Data Processing on Large Clusters
2006年, Bigtable: A Distributed Storage System for Structured Data
- 分別是分佈式文件系統、分佈式計算、分佈式數據庫,拉開了分佈式系統的帷幕。 Hadoop對谷歌論文的複現,更快更容易上手的Spark,滿足實時計算的Flink。
- 但是以往都是分佈式系統,並不是完全意義上的Peer to peer系統。在Web3領域,完全顛覆以往的軟件架構。分佈式系統的一致性,防欺詐攻擊,防粉塵交易攻擊等等一系列問題,都給去中心化計算框架帶來挑戰。
- 將以太坊為代表的智能合約公鏈,可以抽象理解為去中心化的計算框架,只不過EVM是有限指令集的虛擬機,無法做Web2需要的通用計算。而且鏈上資源也是極其昂貴。儘管如此,以太坊也是突破了點對點計算框架的瓶頸,點對點通信、計算結果全網一致性和數據一致性等等問題。
1.2市場前景
讀者在上面了解了分佈式計算的歷史,但還是會存在很多困惑,我來替讀者列出大家可能存在的潛在疑問,如下:
從業務需求出發,為什麼去中心化計算網絡很重要?整體市場規模有多大?現在處於什麼階段,未來還有多少空間?哪些機會值得關注?怎麼去賺錢?
在以太坊最初的願景中,是要成為世界的計算機。在2017年,ICO大爆發之後,大家發現還是主要以資產發行為主。但是到了2020年,Defi summer出現,大量Dapp開始湧現。鏈上數據爆炸,面對越來越多複雜的業務場景,EVM越來越顯得無力。需要鏈下拓展的形式,來實現EVM無法實現的功能。諸如像預言機等等角色,都是某種程度上的去中心化計算。
我們再以拓展思路去思考,現在Dapp高速增長,數據量也在爆炸式增長,這些數據的價值都需要更加複雜的算法來去計算,挖掘其商業價值。數據的價值由計算來體現和產生。這些都是大部分智能合約平台無法去實現的。
現在Dapp開發已經過去當初只需要完成0到1的過程,現在需要更加強大的底層設施,來支撐它完成更加複雜的業務場景。整個Web3已經從開發玩具應用階段過去,未來需要面對更加複雜的邏輯和業務場景。
如何估算市場規模呢?通過Web2領域的分佈式計算業務規模來估算?乘上web3市場的滲透率?把目前市面上相應融資項目的估值相加嗎?
我們不能將Web2的分佈式計算市場規模照搬到Web3,理由是:1,Web2領域的分佈式計算滿足了大部分需求,Web3領域的去中心化計算是差異化滿足市場需求。如果照搬,是有悖於市場客觀背景環境。 2,Web3領域的去中心化計算,未來成長出的市場業務範圍是全球化的。所以我們需要更加嚴謹得去估算市場規模。
對於Web3領域潛在賽道整體規模預算通過以下幾點出發來進行計算:
1.對行業內,其他可被納入賽道範圍內的項目估值,做為基準市值。依據coinmarketcap網站上數據顯示,在市面上已經流通的分佈式計算板塊的項目市值在67億美元。
2.營收模型來自於,代幣經濟模型的設計,例如目前比較普遍流行的代幣營收模型是,代幣作為交易時候支付手續費的手段。所以可以通過手續費收入,間接反映生態的繁榮程度,交易活躍程度。最終作為估值評斷的標準。當然,token還有其他成熟的模型,例如用於抵押挖礦,或者交易的交易對,或者是算法穩定幣的錨定資產。所以Web3項目的估值模型,區別於傳統股票市場,更像是國家貨幣。代幣可以被採用的場景會有多樣性。所以對於具體項目具體分析。我們可以嘗試探索Web3去中心化計算場景中,代幣模型應該如何進行設計。首先我們假定自己去設計一個去中心化計算框架,我們會遇到什麼樣的挑戰? a).因為完全去中心化的網絡,在這樣不可信的環境中完成計算任務的執行,需要激勵資源提供者保障在線率,還要保障服務質量。在博弈機制上,需要保證激勵機制合理,還要如何防止攻擊者發起欺詐攻擊、女巫攻擊等等攻擊手段。所以需要代幣作為質押手段參與POS共識網絡,先保障所有節點的共識一致性。對於資源貢獻者,需要其貢獻的工作量來實施一定的激勵機制,代幣激勵對業務增加和網絡效率提升,必須要有正向循環增長的。 b).相較於其他layer1,網絡本身也會產生大量交易,面對大量粉塵交易,每筆交易支付手續費,是經過市場驗證的代幣模型。 c).如果代幣只是實際用途化,市值是很難再進一步擴大。如果作為資產組合的錨定資產,進行幾層資產嵌套組合,極大擴張金融化的效果。整體估值=質押率*Gas消耗率*(流通量的倒數)*單個價格
2017年到現在,很多團隊都在嘗試去中心化計算方向上發展,但是都嘗試失敗,後面會具體解釋失敗的原因。探索路徑由最初類似外星人探索計劃的項目,後來發展到模仿傳統雲計算的模式,再到Web3原生模式的探索。
當前整個賽道的現狀,處於在學術層面已經驗證0到1的突破,一些大型項目在工程實踐上,有了較大的進展。例如當前的zkRollup和zkEVM實現上,都是剛剛發布產品的階段。
未來還有很大空間,理由如下:1,還需提升驗證計算的高效性。 2,還需要補充豐富更多指令集。 3,真正不同業務場景的優化。 4,以往用智能合約無法實現的業務場景,可以通過去中心化計算實現。
我們通過一個具體案例來解釋,完全去中心化的遊戲。目前大部分Gamefi需要一個中心化服務做為後端,其後端作用在於管理玩家的狀態數據和一些業務邏輯,其應用前端在於用戶交互邏輯和事件觸發後傳遞到後端。當前市面上還沒有完整的解決方案,可以支撐Gamefi的業務場景。但是可被驗證的去中心化計算協議出現,後端替換為zkvm。可以真正實現去中心化的遊戲。前端將用戶事件邏輯,發送到zkvm執行相關業務邏輯,被驗證後,在去中心化數據庫記錄狀態。
當然這只是提出的一個應用場景,而Web2有很多業務場景需要計算的能力。
應用場景\虛擬機類型 | 通用型高性能虛擬機 | AI虛擬機 |
DeFi | 金融數據處理/高並發金融交易並行執行確認/高性能撮合。 。 。 | 人臉識別/信用評估/為更多藉貸業務服務。 。 。 |
NFT | 省Gas聚合交易/批量註冊任務 | AIGC/價值估算。 。 |
社交應用 | 遷移Web2的社交應用/高並發高並行的業務場景/基本的社交業務邏輯,之前智能合約無法實現的 | 推薦算法。 。 。 |
gamefi | 去中心化遊戲/多人在線網絡通信處理... | 防作弊 |
創作者經濟 | 對於不同文件類型的內容創作平台,需要支撐其業務邏輯執行的虛擬機 | AIGC |
2. 去中心化的分佈式計算嘗試
2.1雲服務模式
目前以太坊有如下問題:
1.整體吞吐量低。消耗了大量的算力,但是吞吐量只相當於一台智能手機。
2.驗證積極性低。這個問題被稱為Verifier's Dilemma。獲得打包權的節點得到獎勵,其他節點都需要驗證,但是得不到獎勵,驗證積極性低。久而久之,可能導致計算得不到驗證,給鏈上數據安全性帶來風險。
3.計算量受限(gasLimit),計算成本較高。
有團隊嘗試採用,被Web2廣泛採用的雲計算模式。用戶支付一定費用,按照計算資源使用時間來計算費用。採取這樣模式,其根本原因是因為其無法驗證計算任務是否被正確執行,只能通過可檢測的時間參數或者其他可控的參數。
最終這個模式沒有廣泛應用,沒有考慮人性的因素。大量資源被用於挖礦,以謀取最大利益。導致真正可被利用的資源較少。這是博弈系統內,各個角色謀求利益最大化的結果。
最終呈現的結果,和最開始的初衷完全背離。
2.2挑戰者模式
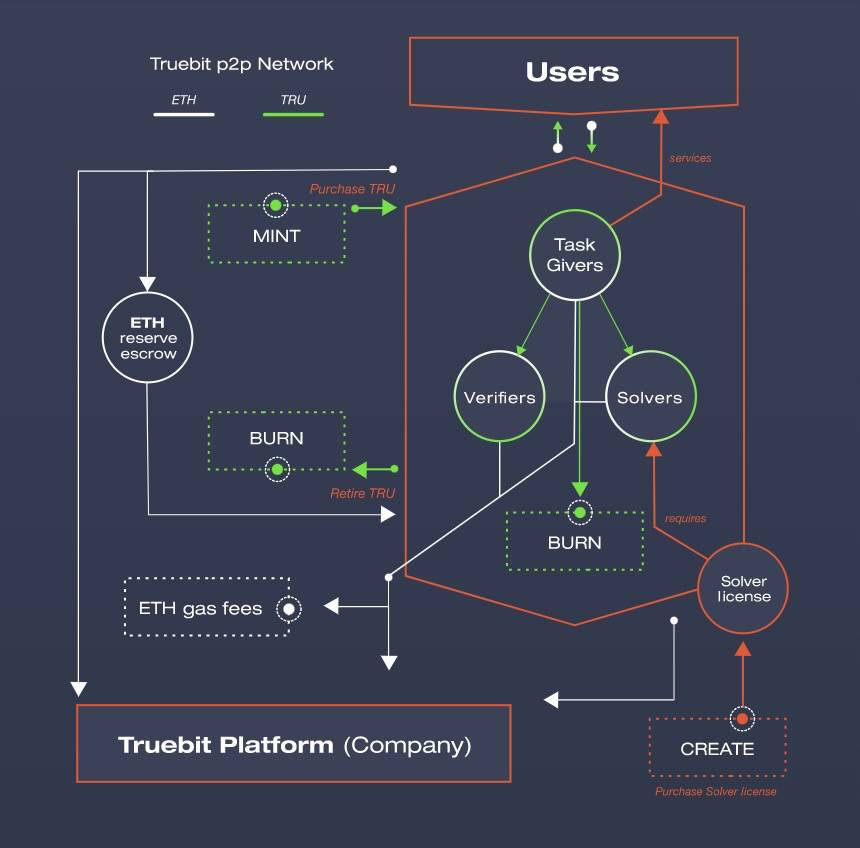
而TrueBit則利用博弈體系,達到全局最優解,來保障下發的計算任務是被正確執行。
https://www.aicoin.com/article/256862.html
我們快速這種計算框架的核心要點:
1.角色:問題解決者、挑戰者和法官
2.問題解決者需要質押資金,才可以參與領取計算任務
3.挑戰者作為賞金獵人,需要重複驗證問題解決者的計算結果,和自己本地的是否一致
4.挑戰者會去抽取與兩者計算狀態一致的最近時間的計算任務,如果出現分歧點,提交分歧點的默克樹hash值
5.最後法官評判是否挑戰成功
但是這個模式存在以下幾點缺陷:
1.挑戰者可以晚時間提交,只需要完成提交任務就行。這樣導致結果是,缺少及時性。
2.3利用零知識證明驗證計算
所以如何實現,既保證計算過程可被驗證,又能保障驗證的及時性。
例如zkEVM的實現,每個區塊時間,需要提交可被驗證的zkProof。這個zkProof包含邏輯計算業務代碼生成的字節碼,再由字節碼執行生成電路代碼。這樣實現了計算業務邏輯是被正確執行,而且通過較短和固定時間來保障驗證的及時性。
雖然zkEVM只是針對智能合約執行的場景,本質還是在計算業務框架下面。如果我們將EVM邏輯順延到其他通用類型的虛擬機,例如WASM虛擬機,或者更加通用的LLVM高性能虛擬機。當然在具體落實到工程實踐上會有諸多挑戰,卻給我們更多的探索空間。
在假定條件下,有足夠高性能的零知識證明加速硬件和足夠被優化的零知識證明算法,通用計算場景可以得到充分發展。大量Web2場景下的計算業務,都可以被零知識證明通用虛擬機進行複現。就如前文所提到可賺錢的業務方向。
3. 零知識證明和分佈式計算的結合
3.1 學術層面
我們回看一下零知識證明算法歷史發展演進的路線
1.GMR85是最早起源的算法,來源於Goldwasser、Micali 和Rackoff 合作發表的論文:The Knowledge Complexity of Interactive Proof Systems(即GMR85),該論文提出於1985 年,發表於1989 年。這篇論文主要闡釋的是在一個交互系統中,經過K 輪交互,需要多少知識被交換,從而證明一個證言(statement)是正確的。
2.姚氏混淆電路(Yao's Garbled Circuit,GC)[89]。一種著名的基於不經意傳輸的兩方安全計算協議,它能夠對任何函數進行求值。混淆電路的中心思想是將計算電路(我們能用與電路、或電路、非電路來執行任何算術操作)分解為產生階段和求值階段。每一方都負責一個階段,而在每一階段中電路都被加密處理,所以任何一方都不能從其他方獲取信息,但他們仍然可以根據電路獲取結果。混淆電路由一個不經意傳輸協議和一個分組密碼組成。電路的複雜度至少是隨著輸入內容的增大而線性增長的。在混淆電路發表後,Goldreich-Micali-Wigderson(GMW)[91]將混淆電路擴展使用於多方,用以抵抗惡意的敵手。
3.sigma協議又稱為誠實驗證者的(特殊)零知識證明。即假設驗證者是誠實的。這個例子類似Schnorr身份認證協議,只是後者通常採用非交互的方式。
4.2013 年的Pinocchio (PGHR13):Pinocchio: Nearly Practical Verifiable Computation,將證明和驗證時間壓縮到適用範圍,也是Zcash 使用的基礎協議。
5.2016 年的Groth16:On the Size of Pairing-based Non-interactive Arguments,精簡了證明的大小,並提升了驗證效率,是目前應用最多的ZK 基礎算法。
6.2017 年的Bulletproofs (BBBPWM17) Bulletproofs: Short Proofs for Confidential Transactions and More,提出了Bulletproof 算法,非常短的非交互式零知識證明,不需要可信的設置,6 個月以後應用於Monero,是非常快的理論到應用的結合。
7.2018 年的zk-STARKs (BBHR18) Scalable, transparent, and post-quantum secure computational integrity,提出了不需要可信設置的ZK-STARK 算法協議,這也是目前ZK 發展另一個讓人矚目的方向,也以此為基礎誕生了StarkWare 這個最重量級的ZK 項目。
8.Bulletproofs的特點為:
1)無需trusted setup的short NIZK
2)基於Pedersen commitment構建
3)支持proof aggregation
4)Prover time為:O ( N ⋅log ( N ) ) O(N\cdot \log(N))O(N⋅log(N)),約30秒
5)Verifier time為:O ( N ) O(N)O(N),約1秒
6)proof size為:O ( log ( N ) ) O(\log(N))O(log(N)),約1.3KB
7)基於的安全假設為:discrete log
Bulletproofs適用的場景為:
1)range proofs(僅需約600字節)
2)inner product proofs
3)MPC協議中的intermediary checks
4)aggregated and distributed (with many private inputs) proofs
9.Halo2主要特點為:
1)無需trusted setup,將accumulation scheme 與PLONKish arithmetization高效結合。
2)基於IPA commitment scheme。
3)繁榮的開發者生態。
4)Prover time為:O ( N ∗log N ) O(N*\log N)O(N∗logN)。
5)Verifier time為:O ( 1 ) > O(1)>O(1)>Groth16。
6)Proof size為:O ( log N ) O(\log N)O(logN)。
7)基於的安全假設為:discrete log。
Halo2適於的場景有:
1)任意可驗證計算
2)遞歸proof composition
3)基於lookup-based Sinsemilla function的circuit-optimized hashing
Halo2不適於的場景為:
1)除非替換使用KZG版本的Halo2,否則在以太坊上驗證開銷大。
10.Plonky2主要特點為:
1)無需trusted setup,將FRI與PLONK結合。
2)針對具有SIMD的處理器進行了優化,並採用了64 byte Goldilocks fields。
3)Prover time為:O ( log N ) O(\log N)O(logN)。
4)Verifier time為:O ( log N ) O(\log N)O(logN)。
5)Proof size為:O ( N ∗log N ) O(N*\log N)O(N∗logN)。
6)基於的安全假設為:collision-resistant hash function。
Plonky2適於的場景有:
1)任意可驗證計算。
2)遞歸proof composition。
3)使用自定義gate進行電路優化。
Plonky2不適於的場景為:
1)受限於其non-native arithmetic,不適於包含橢圓曲線運算的statements。
目前Halo2成為zkvm採用的主流算法,支持遞歸證明,支持驗證任意類型的計算。為零知識證明類型虛擬機做通用計算場景,奠定了基礎。
3.2工程實踐層面
既然零知識證明在學術層面突飛猛進,具體落地到實際開發時候,目前進展是怎樣的呢?
我們從多個層面去觀察:
- 編程語言:目前有專門的編程語言,幫助開發者不需要深入了解電路代碼如何設計,這樣就可以降低開發門檻。當然也有支持將Solidity轉譯成電路代碼。開發者友好程度越來越高。
- 虛擬機:目前有多種實現的zkvm,第一種是自行設計的編程語言,通過自己的編譯器編譯成電路代碼,最後生成zkproof。第二種是支持solidity編程語言,通過LLVM編譯成目標字節碼,最後轉譯成電路代碼和zkproof。第三種是真正意義的EVM等效兼容,最終將字節碼的執行操作,轉譯成電路代碼和zkproof。目前是zkvm的終局之戰嗎?並沒有,不管是拓展到智能合約編程之外的通用計算場景,還是不同方案的zkvm針對自身底層指令集的補齊和優化,都還是1到N的階段。任重而道遠,大量工程上的工作需要去優化和實現。各家在學術層到工程實現上實現了落地,誰能最終成為王者,殺出一條血路。不僅需要在性能提升有大幅進展,還要能吸引大量開發者進入生態。時間點是十分重要的前提要素,先行推向市場,吸引資金沉澱,生態內自發湧現的應用,都是成功的要素。
- 周邊配套工具設施:編輯器插件支持、單元測試插件、Debug調試工具等等,幫助開發者更加高效的開發零知識證明應用。
- 零知識證明加速的基礎設施:因為整個零知識證明算法中,FFT和MSM佔用了大量運算時間,可以GPU/FPGA等並行計算設備來並行執行,達到壓縮時間開銷的效果。
- 不同編程語言實現:例如採用更加高效或者性能表現更好的編程語言:Rust。
- 明星項目湧現:zkSync、Starkware等等優質項目,相繼宣布其正式產品發布的時間。說明了,零知識證明和去中心化計算結合不再是停留在理論層面,在工程實踐上逐漸成熟。
4. 遇到的瓶頸以及如何解決
4.1 zkProof生成效率低
前面我們講到,關於這塊市場容量、目前行業發展情況、在技術上的實際進展,但是沒有存在一點挑戰嗎?
我們對整個zkProof生成的流程進行拆解:
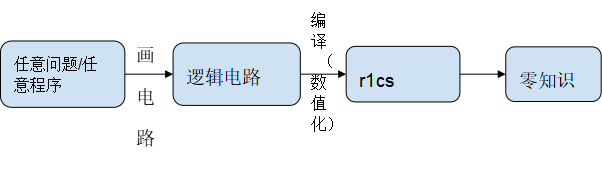
在邏輯電路編譯數值化r1cs的階段,裡面80%的運算量在NTT和MSM等計算業務上。另外對邏輯電路不同層級進行hash算法,隨著層級越多,Hash算法時間開銷線性增加。當然現在行業內提出時間開銷減少200倍的GKR算法。
但是NTT和MSM計算時間開銷,還是居高不下。如果希望給用戶減少等待時間,提升使用體驗效果,必須要在數學實現上、軟件架構優化、GPU/FPGA/ASIC等等層面進行加速。
下圖為各個zkSnark家族算法的證明生成時間和驗證時間的測試:
Benchmark Results | |||||||
Sudoku: compile | |||||||
Miden | Plonk: 3 by 3 | Risc | Halo: 3 by 3 | ||||
1.52 ms (✅1.00x) | 99.92 ms (❌65.80x slower) | 1.86 ms (❌1.22x slower) | 329.15 ms (❌216.76x slower) | ||||
Sudoku: prove | |||||||
Miden | Plonk: 3 by 3 | Risc | Halo: 3 by 3 | ||||
477.41 ms (✅1.00x) | 100.52 ms (���4.75x faster) | 1.67 s (❌3.49x slower) | 116.74 ms (���4.09x faster) | ||||
Sudoku: verify | |||||||
Miden | Plonk: 3 by 3 | Risc | Halo: 3 by 3 | ||||
2.41 ms (✅1.00x) | 7.28 ms (❌3.02x slower) | 2.79 ms (❌1.15x slower) | 4.39 ms (❌1.82x slower) | ||||
Sudoku: | |||||||
Miden | Plonk: 3 by 3 | Risc | Halo: 3 by 3 | ||||
475.69 ms (✅1.00x) | 205.22 ms (���2.32x faster) | 1.67 s (❌3.52x slower) | 450.98 ms (✅1.05x faster) | ||||
fibonacci: compile | |||||||
Miden: iter-93 | Miden: fixed-92 | Miden: fixed-50 | Risc0: iter-93 | Risc0: iter-50 | Risc0: fixed-50 | Risc0: fixed-92 | |
64.89 us (✅1.00x) | 55.92 us (✅1.16x faster) | 45.01 us (✅1.44x faster) | 387.69 us (❌5.97x slower) | 388.34 us (❌5.98x slower) | 391.42 us (❌6.03x slower) | 390.26 us (❌6.01x slower) | |
fibonacci: prove | |||||||
Miden: iter-93 | Miden: fixed-92 | Miden: fixed-50 | Risc0: iter-93 | Risc0: iter-50 | Risc0: fixed-50 | Risc0: fixed-92 | |
472.51 ms (✅1.00x) | 231.76 ms (���2.04x faster) | 233.25 ms (���2.03x faster) | 417.66 ms (✅1.13x faster) | 413.46 ms (✅1.14x faster) | 410.38 ms (✅1.15x faster) | 412.02 ms (✅1.15x faster) | |
fibonacci: verify | |||||||
Miden: iter-93 | Miden: fixed-92 | Miden: fixed-50 | Risc0: iter-93 | Risc0: iter-50 | Risc0: fixed-50 | Risc0: fixed-92 | |
2.41 ms (✅1.00x) | 2.36 ms (✅1.02x faster) | 2.36 ms (✅1.02x faster) | 2.55 ms (✅1.06x slower) | 2.55 ms (✅1.06x slower) | 2.55 ms (✅1.06x slower) | 2.55 ms (✅1.06x slower) | |
fibonacci: | |||||||
Miden: iter-93 | Miden: fixed-92 | Miden: fixed-50 | Risc0: iter-93 | Risc0: iter-50 | Risc0: fixed-50 | Risc0: fixed-92 | |
475.43 ms (✅1.00x) | 234.39 ms (���2.03x faster) | 235.84 ms (���2.02x faster) | 421.28 ms (✅1.13x faster) | 417.20 ms (✅1.14x faster) | 413.70 ms (✅1.15x faster) | 415.58 ms (✅1.14x faster) | |
fibonacci large: compile | |||||||
Miden: iter-1000 | Risc0: iter-1000 | ||||||
64.91 us (✅1.00x) | 387.43 us (❌5.97x slower) | ||||||
fibonacci large: prove | |||||||
Miden: iter-1000 | Risc0: iter-1000 | ||||||
4.07 s (✅1.00x) | 3.39 s (✅1.20x faster) | ||||||
fibonacci large: verify | |||||||
Miden: iter-1000 | Risc0: iter-1000 | ||||||
2.66 ms (✅1.00x) | 2.96 ms (✅1.11x slower) | ||||||
fibonacci large: | |||||||
Miden: iter-1000 | Risc0: iter-1000 | ||||||
4.07 s (✅1.00x) | 3.40 s (✅1.20x faster) | ||||||
Blake: compile | |||||||
Risc0: Library-The quick brown fox jumps over the lazy dog | |||||||
466.84 us (✅1.00x) | |||||||
Blake: prove | |||||||
Risc0: Library-The quick brown fox jumps over the lazy dog | |||||||
3.40 s (✅1.00x) | |||||||
Blake: verify | |||||||
Risc0: Library-The quick brown fox jumps over the lazy dog | |||||||
4.24 ms (✅1.00x) | |||||||
Blake: | |||||||
Risc0: Library-The quick brown fox jumps over the lazy dog | |||||||
3.40 s (✅1.00x) | |||||||
Blake3: compile | |||||||
Miden: Library-quick brown fox | |||||||
7.38 ms (✅1.00x) | |||||||
Blake3: prove | |||||||
Miden: Library-quick brown fox | |||||||
1.99 s (✅1.00x) | |||||||
Blake3: verify | |||||||
Miden: Library-quick brown fox | |||||||
3.12 ms (✅1.00x) | |||||||
Blake3: | |||||||
Miden: Library-quick brown fox | |||||||
2.01 s (✅1.00x) |
既然我們可以看到缺陷和挑戰,同時也意味著其中深藏著機會:
1.設計針對特定zkSnark算法加速或者通用zkSnark算法加速的芯片。相比其他類型的加密算法,zkSnark產生較多臨時文件,對於設備的內存和顯存存在要求。芯片創業項目,同時也面臨大量資金投入,還不一定能保障最後可以流片成功。但是一旦成功,其技術壁壘和IP保護都將是護城河。芯片項目創業,必須要足夠議價能力的渠道,拿到最低成本。以及在整體品控上做到保障。
2.顯卡加速的Saas服務,利用顯卡做加速,是支出代價小於ASIC設計,而且開發週期也較短。但是軟件創新上,在長周期上最終會被硬件加速所淘汰。
4.2 硬件資源佔用大
目前和一些zkRollup項目接觸,最終發現還是大內存和大顯存顯卡比較適合他們用於軟件加速。例如在Filecoin挖礦中,大量閒置的數據封裝機成為了現在熱門zkRollup項目的目標設備。在Filecoin挖礦中,在C2階段,需要將生成的電路代碼文件,生成並緩存在內存中。如果業務代碼邏輯十分複雜,其對應生成的電路代碼規模也會非常大,最終呈現形式就是體積大的臨時文件,特別涉及對電路代碼進行Hash運算,需要AMD CPU指令來加速。因為直接CPU和內存之間高速交換,效率非常高。這裡面還需要涉及到NVME的固態硬盤,都會是對zkSnark運算起到加速作用。以上我們對可能存在加速實現的可能性進行探討,發現對資源要求還是非常高的。
在未來,如果想大規模普及zkSnark應用,通過不同層面優化,勢在必行。
4.3 Gas消耗成本
我們觀察到所有zkRollup Layer2需要將zkProof傳遞到layer1進行驗證和存儲,因為ETH鏈上資源十分昂貴,如果大規模普及後,需要為ETH支付大量Gas。最終由用戶承擔這個成本,和技術發展的初衷。
所以很多zkp項目提出,數據有效層、利用遞歸證明壓縮提交的zkProof,這些都是為了降低Gas cost。
4.4 虛擬機的指令缺失
當前大部分zkvm面向智能合約編程的平台,如果要更加通用的計算場景,對zkvm底層指令集有大量的補齊工作。例如zkvm虛擬機底層支持libc指令,支持矩陣運算的指令,等等其他更加複雜的計算指令。
5. 結語
因為智能合約平台更多面向資產進行編程,如果我們希望更多真實業務場景可以接入到Web3,零知識證明和去中心化計算的結合帶來了契機。我們相信零知識證明將會成為主流賽道,不再是細分領域的技術。




 APP
APP 

