






作者:YBB Capital Researcher Ac_Core
前言
排序器(Sequencer)是目前以太坊扩容方案Rollup中的重要组件,它用于对交易进行排序并进行区块创建、交易接受、交易排序、交易执行和交易数据提交等相关操作。随着以太坊网络 Layer2 数量的增多及其生态的繁荣,Layer2 自身的盈利方式和中心化问题也逐渐受到大家的关注,如在Rollup中较为重要的排序器组件能否实现去中心化和排序器利润是怎么分配的。本文只做分析参考,不为项目宣发。
简述Rollup经济学
Rollup的角色:
据以太坊基金会研究科学家@barnabemonnot的解释说明,我们可在Rollup系统中分出三个主要角色:用户、Rollup运营商和基础层。他们运行的主要流程大致为:当用户在 L2 上进行交易,Rollup运营商充当着用户和基础层之间的接口角色,并最终将数据发布到基础层,如下所示:
- 用户:在Layer2网络上发送他们的交易,并将他们在 Layer2上的资产部署在Rollup上进行合约交互,并将支付费用流向Rollup运营商;
- Rollup运营商:代表处理 L2 网络上的交易所需的所有基础设施,其中也包含很多其他角色,比如:发布交易批次的排序器( Sequencers)、发布声明的执行者(Executors)、报告欺诈证明的挑战者(Challengers)以及计算有效性证明的验证者(Validator),其中最为重要的即为排序器;
- 基础层:也可以理解为完整节点,其目的是保护Rollup的数据协议,用来处理和验证所有交易,确保Rollup状态正确并确保每笔交易的有效性,如发现错误交易并将其删除。
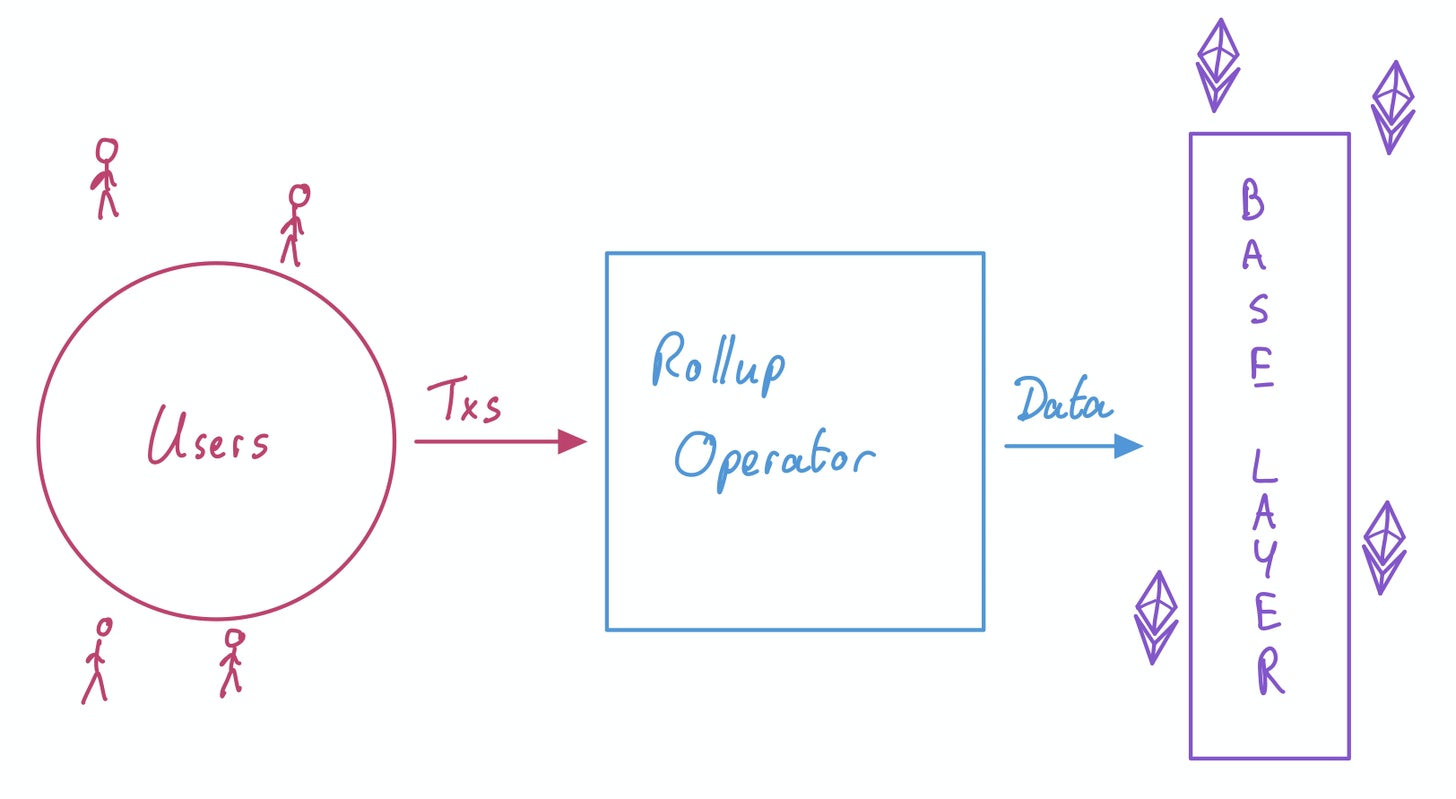
图源:@barnabemonnot
Rollup的成本:
Layer2营运商成本:为维护一个交易池、序列批处理、计算状态根/状态差异/有效性证明等涉及到批量交易处理的排序、交易验证、区块生成等问题而产生的费用。且由于Rollup运营商现在是中心化的,所以产生的成本由协议本身或合作方承担,同时过程中的“交易压缩”需要在基础层上进行结算。
Layer1数据可用性成本:DA 是 Rollup 等效于以太坊安全性的保证,Rollup为了在以太坊上发布数据,当运营商聚合了大量的交易集时,运营商就需要将交易集以「CallData」的形式释出到基础层,其中贡献给以太坊 L1 的 DA 成本占 Rollup 总成本的绝大多数,且当时的数据市场价格由EIP-1559 进行管理。
Layer2的拥堵验证成本:这是一个饱受争议的影响成本,当Rollup总区块空间的供应无法满足现有市场需求时,就必须对稀缺资源进行分配,它也直观的反映了 Gas 价格与网络流量的动态平衡。
Rollup的收入:
话题来到Rollup的收入,其收入主要有两个来源:交易价值(Transaction Value)及发行(Issuance)。
交易价值
Rollup的本质是对以太坊进行扩容,提速和降低Layer1压力,Rollup中是否会获得MEV相关的收益问题,其实答案是否定的。因为Rollup自身是依靠排序器,依靠Gas支出高低进行交易排序,因它没有区块的概念所以本身不存在Mempool,但现今像OP Mainnet的私有Mempool却带来了MEV问题,因此Rollup本身在没有 “私有化Mempool” 的前提下不会获得MEV利润,从本质来讲Rollup最大的利润来源于交易Gas之间的价格差。
发行
第二个收入来源是发行。在基础层,以网络原生加密资产的区块生产者的新铸造代币形式获得收入。一定程度上抵消了区块生产者的基础设施成本,一旦利润产生就会吸引来更多的区块生产者。我们在假设Rollup在能够铸造自己的Token的情况下,Rollup可能会通过发行新代币来支付运营费用(但实际这里的模型会较为模糊,且有多种方式将收入来源用于Rollup成本)。
关于成本和收入平衡相关的问题,我们就不做展开叙述,上述仅做简述,坎昆升级在一定程度上也会影响Rollup盈收情况,其核心EIP-4844(又被称为Proto-DankSharding)如用一段话概括,便是缓解以太坊Layer1的高昂DA成本问题,出现了“blob”的临时外部存储,可将Layer2交易的数据内容移动到一个新的临时“blob”中存储。但它并没有真正的把Layer2交易数据存储到Layer1中,其好处在于Layer2会有更低的存储成本和更快的速度,但目前Layer2的数据黑盒所带来的不确定影响仍值得探究。
简述Rollup工作原理:
- 汇总:卷积节点收集多个事务并创建一个压缩摘要即卷积块,其中包含事务验证和状态更新所需的基本信息;
- 验证:Rollup区块会被提交到主区块链,由验证器节点验证区块内交易的有效性,并确保它们符合预定义的规则。
总的来讲区块一旦得到验证,Rollup的状态就会在链上更新并反映交易的结果。以此通过Rollup来减少Layer1上的计算负荷和数据存储需求,从而显著提高可扩展性。其中的有效做法是将计算和状态存储都转移到链外,但将部分数据保留在链上。
什么是排序器
排序器是Rollup设计选择上的核心组件,如同字面意思,它负责对接受的交易对,其支付的Gas价格进行排序,将交易打包捆绑到区块中并提取费用,以此来提升交易的有序性和整个系统的处理效率。但现实是目前以太坊上所有的Rollup都以相互孤立且中心化的方式来运行,且均由各自的Rollup团队进行管理,这带来的直观影响是Rollup提供商们通过维护自身中心化的排序器来让整个网络达到更便宜和快捷的目的,但这同时也在独食着 Rollup 的利润。
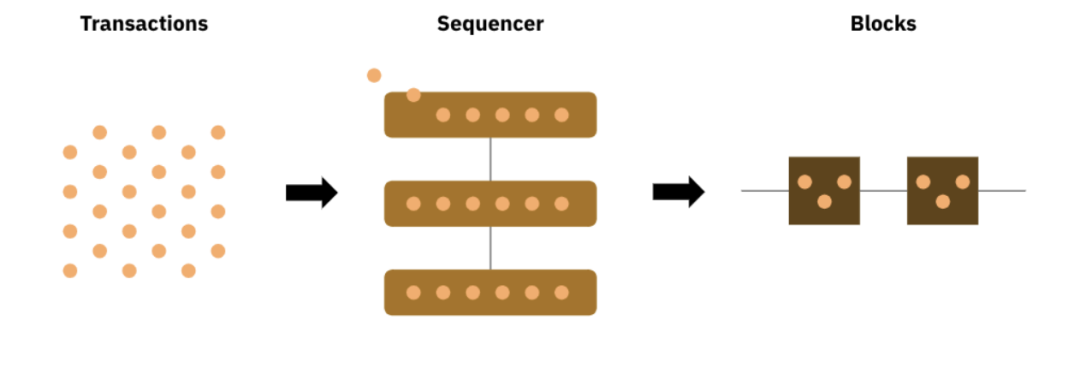
图源:Binance Research
如同上文中Rollup的成本和收入部分,其主要的利润来自于对用户的Gas差价的收入进行排序,而支出主要在于Layer2对于Layer1的数据可用性成本,以及中心化运营商的运营支出,所以排序器主要从用户侧收取交易费用,并向以太坊支付 DA 费用,简单理解:
排序器收入 = 用户交易Gas差价收入 – L2 向 L1 数据支出 – 排序器运营支出
Op Rollups 与 Zk Rollups 的不同排序方案
Op Rollups是将大量链外交易捆绑在一起,形成较大的批次然后再发布到基础层。这一过程有利于将固定费用分配给每批中的众多交易,从而降低用户的费用。在分批处理交易的同时,还采用了上述多种压缩技术,以尽量减少发布到基础层的数据。两者不同的是Zk Rollups利用密码学来证明链外交易的有效性,Op Rollups依赖于一种检测欺诈活动的机制来识别交易计算不准确的情况。
提交批量Rollup后会出现一个挑战时间段,在此期间任何人都可以通过生成欺诈证明来质疑卷积交易的结果。在欺诈证明成功后Rollup协议会重新执行交易,并相应调整卷积的状态。此外,欺诈证明成功会导致排序者的赌注被削减,因为排序者将错误执行的交易包含在一个区块中。在这一过程中,如排序者将错误执行的交易纳入区块欺诈证明,成功后会导致排序者的利益受损。挑战期结束后,如果滚动批次仍未被验证(即所有交易均正确执行),则会被确认为有效并纳入基础层。在实现过程中的排序器问题上,OP是采用多链但单一的共享排序器。
ZK Rollups 将交易汇总成批次,在链外进行处理,从而减少了需要上传到区块链的数据量。其排序器将代表整批事务所需的更改合并为单个,而不是单独传输每个事务,这一过程为了验证状态变化是否正确,它们会生成有效性证明。所以Zk Rollups是依赖零知识的有效证明而不是欺诈证明,排序器从 L2 收集交易数据,并负责向 L1 提交(根据具体架构,也可能负责发布)零知识证明。如果定序者有恶意行为,他们的赌注会被削减,这就促使他们发布有效的区块(或批次证明)。证明者(或排序者,如果合并为一个角色)凭借生成交易执行的不可伪造证明,来证明这些新状态和执行是正确的。
随后,排序器将这些证明连同交易数据或至少是状态差异提交给以太坊主网上的验证器合约。从技术上讲,排序者和证明者的职责可以合二为一。但是由于证明生成和交易排序都需要高度专业化的技能才能充分完成,因此将这些职责拆分开来可以防止在卷积设计中出现不必要的集中化。
在许多情况下,排序器在进行零知识证明的同时,只向 L1 提交 L2 状态的变化,并以可验证哈希的形式将这些数据提供给以太坊主网上的验证器智能合约。由于 Zk Rollups 只需提供有效性证明即可完成交易,因此从 Zk Rollups 转出或转入基础层的资金不会产生任何延迟。一旦 Zk Rollups 合同确认了有效性证明,退出交易就会执行。
排序器的中心化与去中心化
目前 L2 中排序器都是中心化的,但去中心化排序器在未来也尤为重要,从意识形态的角度来看,在存在信任假设的前提下,单一的中心化排序器并不可取。不过排序器并非必不可缺,它只是Rullup在设计上的选择,因目前暂未有全新方案替且如今Rollup均采用中心化的排序方式来解决交易排序问题,当下Rollup的实际进展由下图L2BEAT官方数据所示。
- 中心化排序器
优点:可以极大的提升交易确认速度和降低交易成本,友好用户交易体验;
缺点:其最主要的缺陷来自于单点宕机风险和垄断,单点宕机问题不用做过多阐述,如今Rollup宕机事件频发已不是什么新鲜事,而垄断带来的风险也不言而喻,中心化排序器毋庸置疑获得了交易的排序权,以此可轻松实现自身利益的最大化,其次也会带来抗审查的相对薄弱风险。
- 去中心化排序器
优点:是否使用去中心化的排序器似乎已成为衡量Rollup能否真正去中心化的重要标准,其优点不言而喻,可以极强的增加去中心化程度,防止运营商作恶,以此极大程度上确保了用户的资产安全,以及可有效防止Rollup出现种种宕机现象;
缺点:提升去中心化和安全的代价是降低交易速度或增加交易成本,从而导致在一定程度上弱化用户的交互体验。
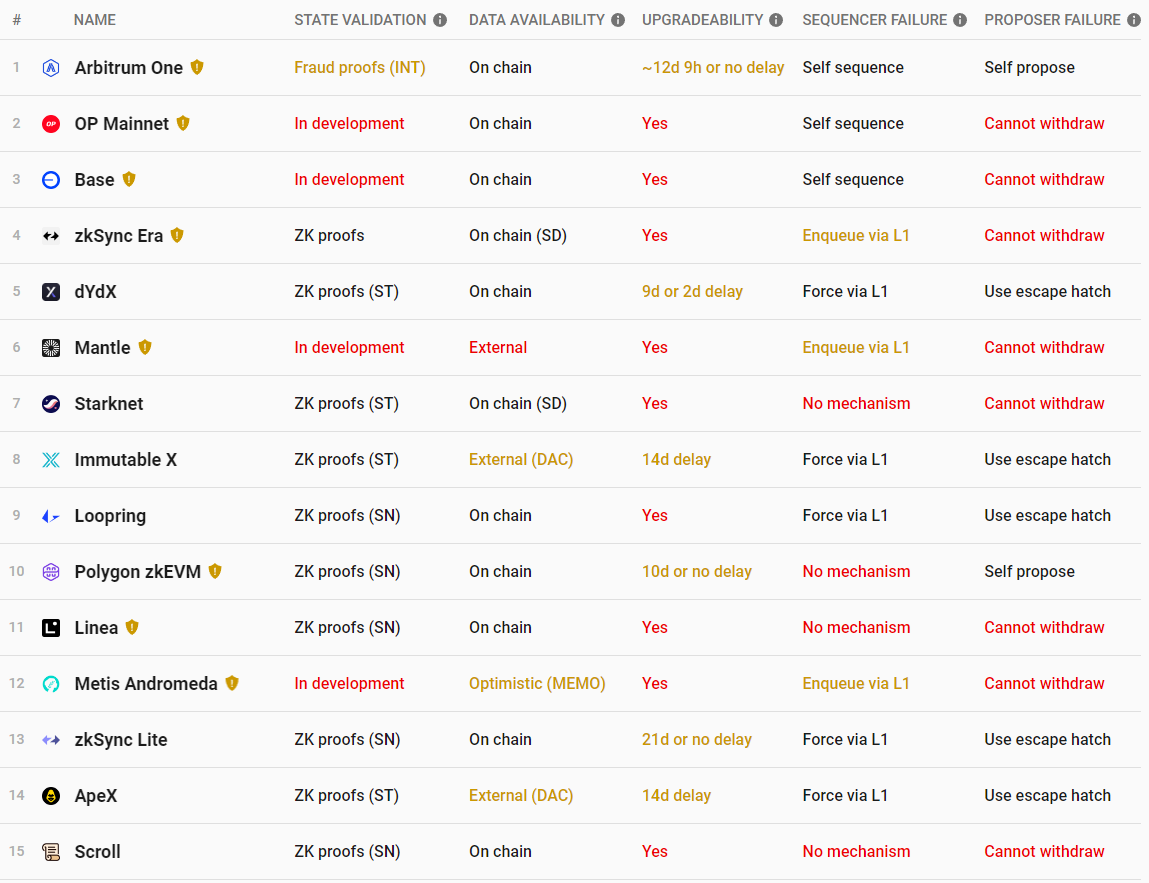
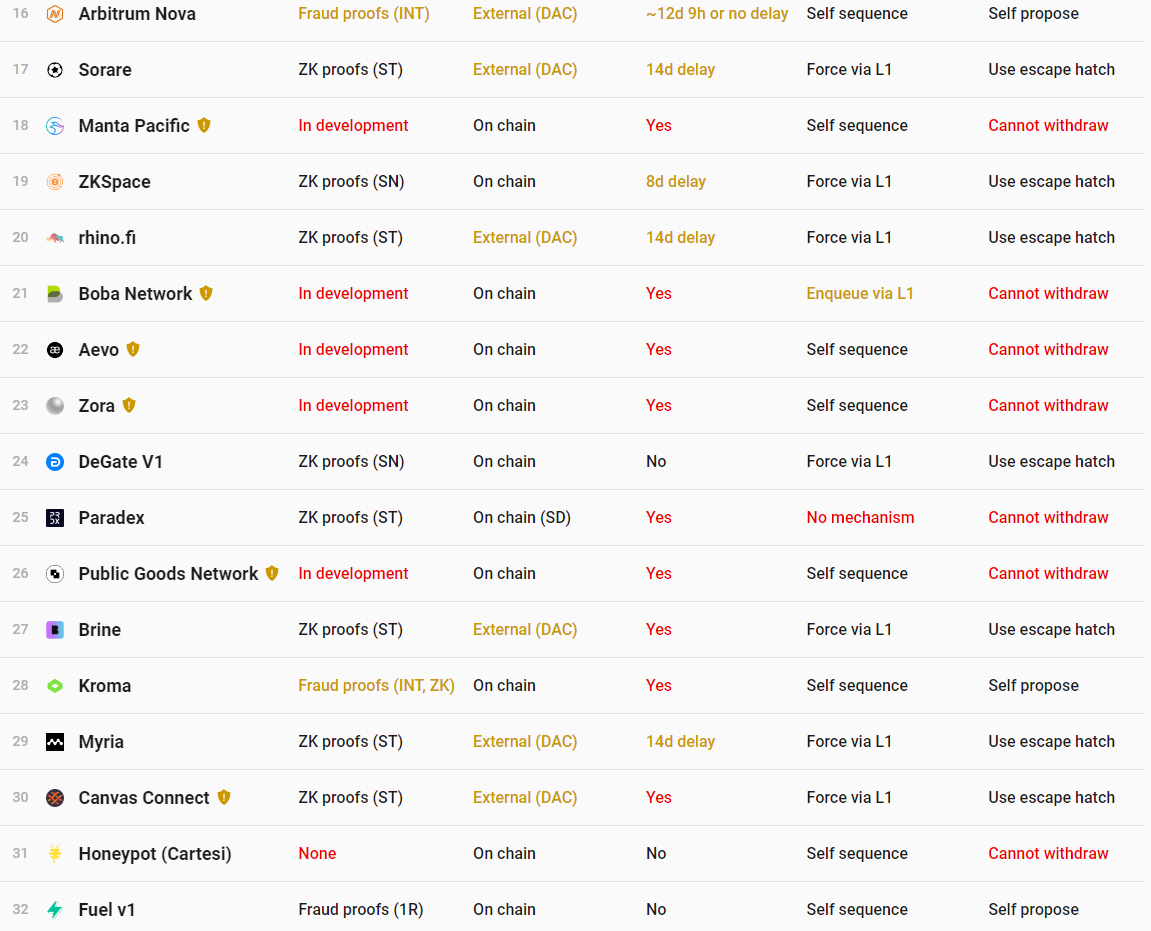
图源:L2BEAT
第二层的不同类型
Vitalik在近文《Different types of layer 2s》中提到第二层项目的异构化趋势在未来会越来越明显,并且这一趋势会一直持续下去,比如传统上以Arbitrum、Optimism和Scroll 为代表的公链,和近期以Kakarot和Taiko 为代表的 EVM 生态系统的发展,其主要原因有以下几点:
- 一些目前是独立第 1 层的项目正在寻求向以太坊生态系统靠拢,这些项目可能希望逐步过渡并有可能成为第 2 层。但因为技术还没准备好,所以暂时把所有东西都放在一个Rollup上;
- 一些中心化项目希望为其用户提供更多安全保证,并正在探索基于区块链的途径。在许多情况下,这些项目会在上一个时代探索 "许可资产链(Permissioned Consortium chains)"。实际上,它们可能只需要 "中途之家 "级别的去中心化。此外,这些项目的吞吐量往往很高,因此至少在短期内,它们甚至不适合滚动发展;
- 弱金融类应用如游戏或社交类应用,他们也希望实现去中心化。就社交媒体而言,现实中需要对应用程序的不同部分区别对待:用户名注册和账户恢复等罕见且高价值的活动应采用滚动方式,而帖子和投票等频繁且低价值的活动只需要较低的安全性。因链故障导致的帖子消失风险是可以承受的。而因链失效导致的账户丢失风险就比较难以承受。
尽管目前以太坊Layer1中的应用程序和用户在短期内只需支付较小的Rollup费用,不过本章节我们想和大家强调的点是用户是否能够顺利的将资产安全地从Layer2回撤至Layer1,即Rollup的“强制提款”和 “逃生舱” 功能,见 Faust 解释的相关扩展链接【1】。

图源:Different types of layer 2s
假如你有一笔资产,它位于 Layer1 上,但需要先存入 Layer2,后才可转入至其他钱包地址,我们能在多大程度上保证你能将这笔资产取回至 Layer1?为此不妨随着我们一起用一张简单的图表来将此厘清:
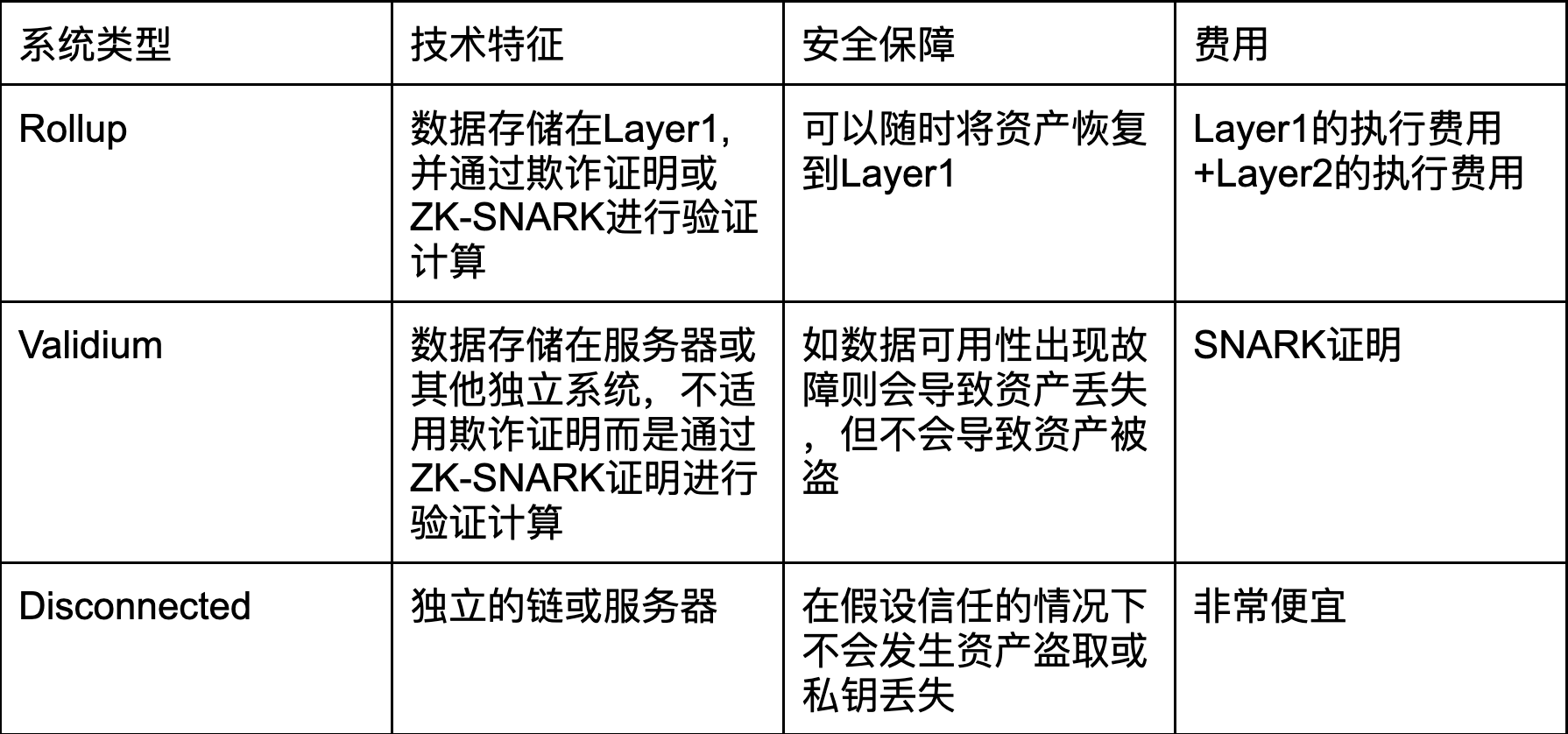
数据来源:Different types of layer 2s
值得一提的是,这是一个简化模式,有很多中间选项。例如:
- 介于Rollup和Validium之间:在Validium中,任何人都可以进行链上支付,以支付交易费用,此时运营商将被迫向链上提供一些数据,否则就会损失押金。
- 在 Plasma 和 Validium 之间:Plasma 系统【2】提供类似于卷积的安全保证和链外数据可用性,但它只支持有限数量的应用。一个系统可以提供完整的 EVM,并为不使用这些更复杂应用的用户提供 Plasma 级保证,为使用这些应用的用户提供 Validium 级保证。
这些中间选项可以看作是介于卷积和有效值之间的一个频谱。但是,是什么促使应用程序选择光谱上的某一点,而不是更左或更右的某一点呢?这里有两个主要因素:
- 以太坊原生数据可用性的成本,随着技术的改进会逐渐降低。以太坊在下一个硬分叉Dencun 【3】里引入了EIP-4844,提供每秒约 32 KB 的链上数据可用性。在接下来的几年内,随着完整的"链上数据分片 "【4】的推出,这一数据可用性预计将分阶段提高,最终达到每秒约 1.3 MB 的数据可用性。与此同时,数据压缩技术的改进【5】将使我们能够用相同数量的数据做更多的事情;
- 应用程序自身的需求:高昂的费用与应用程序出错相比,用户需要承担多少损失?金融应用程序会因应用程序故障而遭受更大的损失;游戏和社交媒体涉及每个用户的大量活动,且活动价值相对较低。因此对它们来说,不同的安全权衡是有意义的。
去中心化排序器,一种是 Rollup 项目方自己做,另一种是借助第三方实现。借助第三方实现去中心化排序器,其实也可以称之为排序即服务( Sequencing-as-a-Service)。Espresso、 SUAVE、Astria、Radius 等项目都专注于去中心化排序器方案,它们的实现路径各不相同。
去中心化排序器解决方案
1)Espresso:由五个主要组件组成:1.基于HotStuff的共享机制【6】其过程需要经三分之二多数通过后才能确定且不可逆转; 2. 其DA层提供两种不同的数据检索路径。第一种路径乐观而快速,第二种路径更可靠,但备份速度较慢,专为对抗条件设计;3.Rollup REST API:滚动程序使用此 API 与 Espresso Sequencer 无缝集成;4.排序器合约:排序器合约是一种验证 HotShot 共识的智能合约,它可以充当轻客户端,管理交易订单检查点以及负责监督 HotShot 协议的股权表;5.网络层: 该层用于促进参与 DA 层和 HotShot 共识的节点之间的通信。总体如下图所示,当用户的交易被发送到Rollup时,它会使用 ZK 或乐观方案进行交易验证。
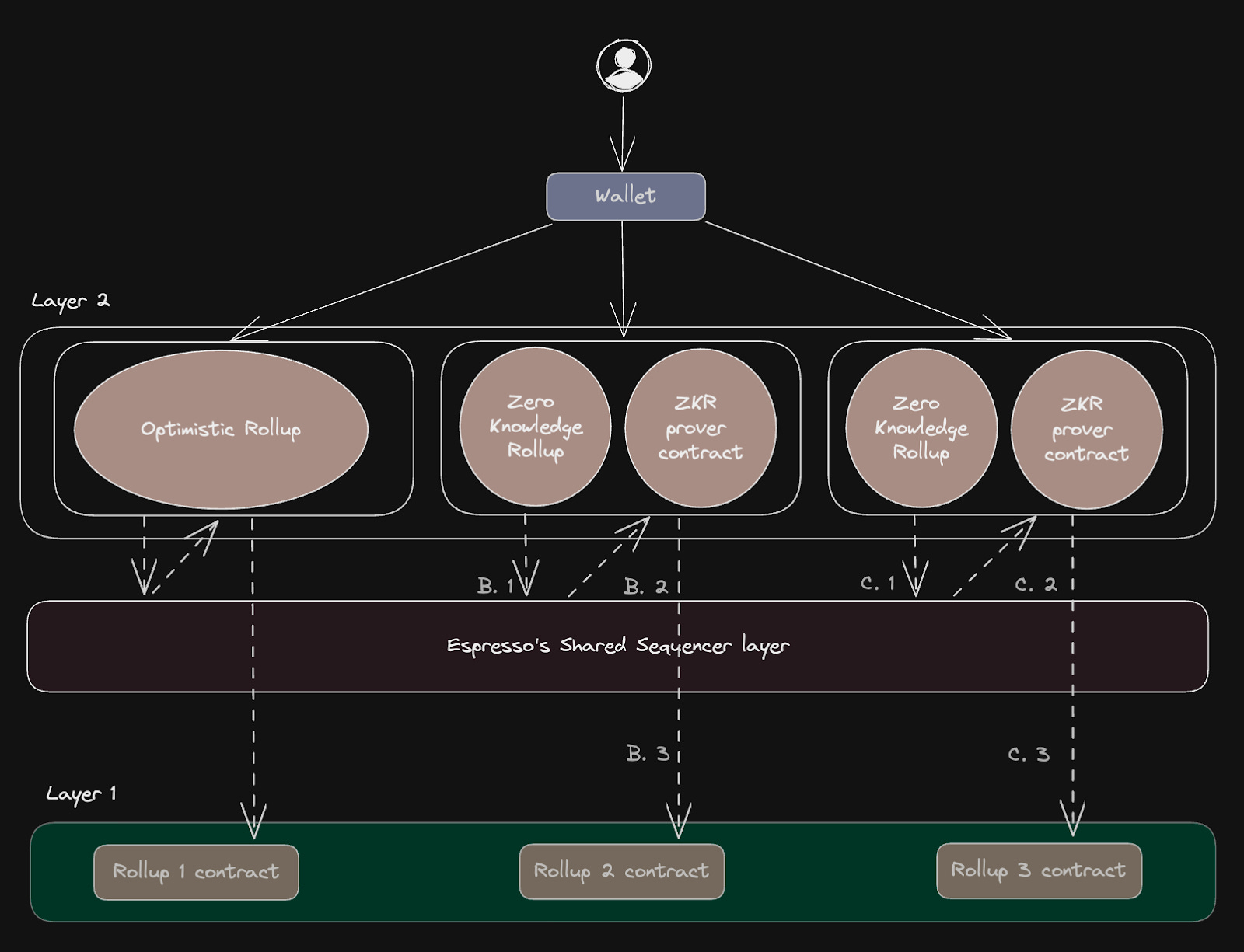
图源:The tech: Sequencers (Espresso 排序流程概览 )
2)SUAVE是一个独立的网络层与其他区块网络可以共享内存池,它自身无法与以太坊或其他公链的智能合约相通用,而是将内存池和区块生成的部分从现有公链中单独分离,以此支持更多的Layer1或者Layer2网络,并成为Rollup链的共享排序器。所以它在跨链MEV和不同Rollup之间的交易排序也存在一定优势, 不过其带来的风险也同跨链桥所面对的那样。
3)Astria 是建立一个共享排序器网络层以此避免中心化排序器的劣势,它依靠基于 Tendermint 的领导者轮换(Tendermint-based leader rotation)机制来解决交易排序的可扩展性和中心化单点故障的宕机风险,与此同时Astira的排序器架构设计用于聚合来自多个Rollup的交易,而不是为单一区块生成不同的状态根,形成的交易会按顺序排列成有“内聚力”的区块,然后统一发布到Layer1的 DA 层,以此有效地将交易排序与执行分离开,也正因采用了这种解耦方式,使得 Astria 能够容纳各种具有不同状态转换功能的Rollup。
4)Radius 与其他方案的实现机制均不同的是它通过启用加密Mempool和让多个排序器同时运行来确保 Rollup 交易被无需信任地排序,通过这种方式来消除 MEV 带来的相关风险。它采用可验证延迟加密机制(PVDE)【7】来实现Mempool的加密,采用零知识证明加密方式来确保交易的无信任排序和防止中心化排序器相关风险。不过用零知识证明来提升安全性的代价是,虽然有 MEV 保护但对用户来说可能会出现交易延迟等问题。Radius 的交易流程如下:
- 用户向排序层发送事务
- 排序层对事务进行排序并生成一个区块
- 组成的区块随后提交给Rollup相关程序
- Rollup按照排序层提供的顺序执行交易
- Rollup将已执行的交易提交给结算层 DA 来进行最终确认
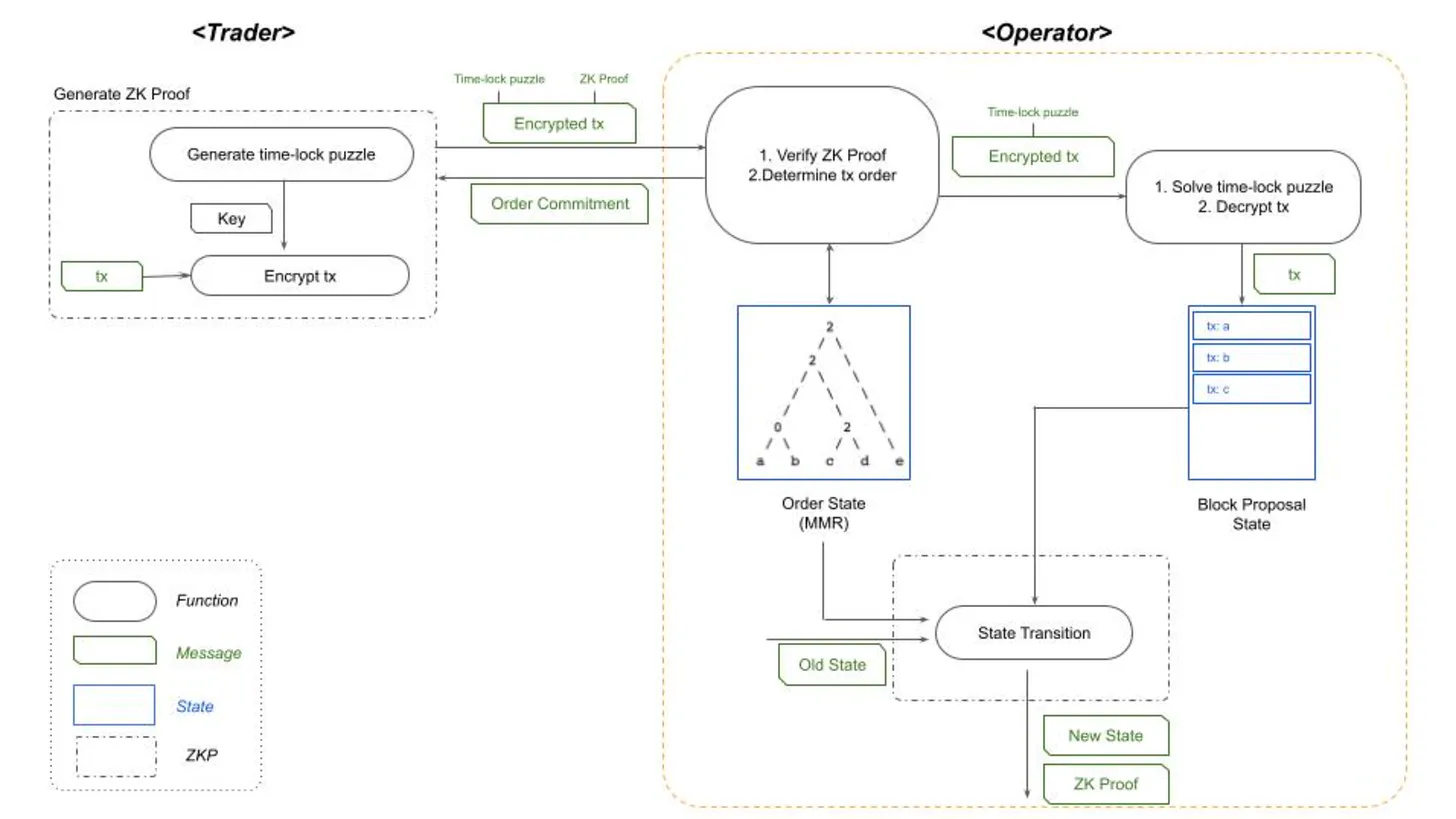
图源:The tech: Sequencers (Radius交易流程概况 )
5)Madara是 Layer2 网络 StarkNet 中使用的排序器,它是一种较为灵活的排序方式,既可以中心化运行也可以去中心化运行,以此对不同的应用程序进行定制,目前 Madara 是 StarkNet 的现成排序器解决方案,与之相关的研究和开发工作仍在进行中。
展望
区块链排序器的发展前景将是一段振奋人心的变革之旅,随着区块链生态系统的发展,排序器将经历重大变革,从中心化设计转向更为分散、高效和适应性更强的解决方案。排序技术的进步对于以太坊生态提高交易效率、可扩展性和安全性可谓是至关重要。
去中心化是加密货币的哲学基础,共享排序网络通过经济机制解决价值累积和收入分配问题,最后关于排序器日益成熟的模块化构建模块和开发框架生态系统在未来必将成为行业强大的催化剂。
解释文献:
【1】https://mp.weixin.qq.com/s/OEL4_-uocBy8WSU4jAeVgQ
【2】https://consensys.io/blog/ethereum-dencun-upgrade-explained-part-1
【3】https://hackmd.io/@vbuterin/sharding_proposal
【4】https://twitter.com/VitalikButerin/status/1554983955182809088
【5】https://arxiv.org/abs/1911.12095
【7】https://ethresear.ch/t/mev-resistant-zk-rollups-with-practical-vde-pvde/12677
参考文章:












 APP
APP 
