




作者:Eito Miyamura
編譯:深潮TechFlow
GatlingX是一個由牛津大學校友領導的項目,專注於機器學習和強化學習,他們最近推出了「GPU-EVM」——據內部基準測試成績顯示,這可能是目前市面上表現最強的以太坊虛擬機(EVM)。
GPU-EVM是EVM擴展解決方案,性能非常強大,以至於最先進的基於強化學習(RL)的人工智慧代理可以在其上進行訓練,開發團隊表示。它利用並行執行多種以太坊應用程序,幫助訓練AI代理尋找安全漏洞。
GPU-EVM使用圖形處理單元(GPUs)並行執行操作,從而提高交易吞吐量。團隊聲稱,GPU-EVM的處理任務速度幾乎是目前高效能EVM(包括evmone和revm)的100倍。這主要得益於GPU能夠同時處理多個操作,利用其天生適合併行處理的架構。
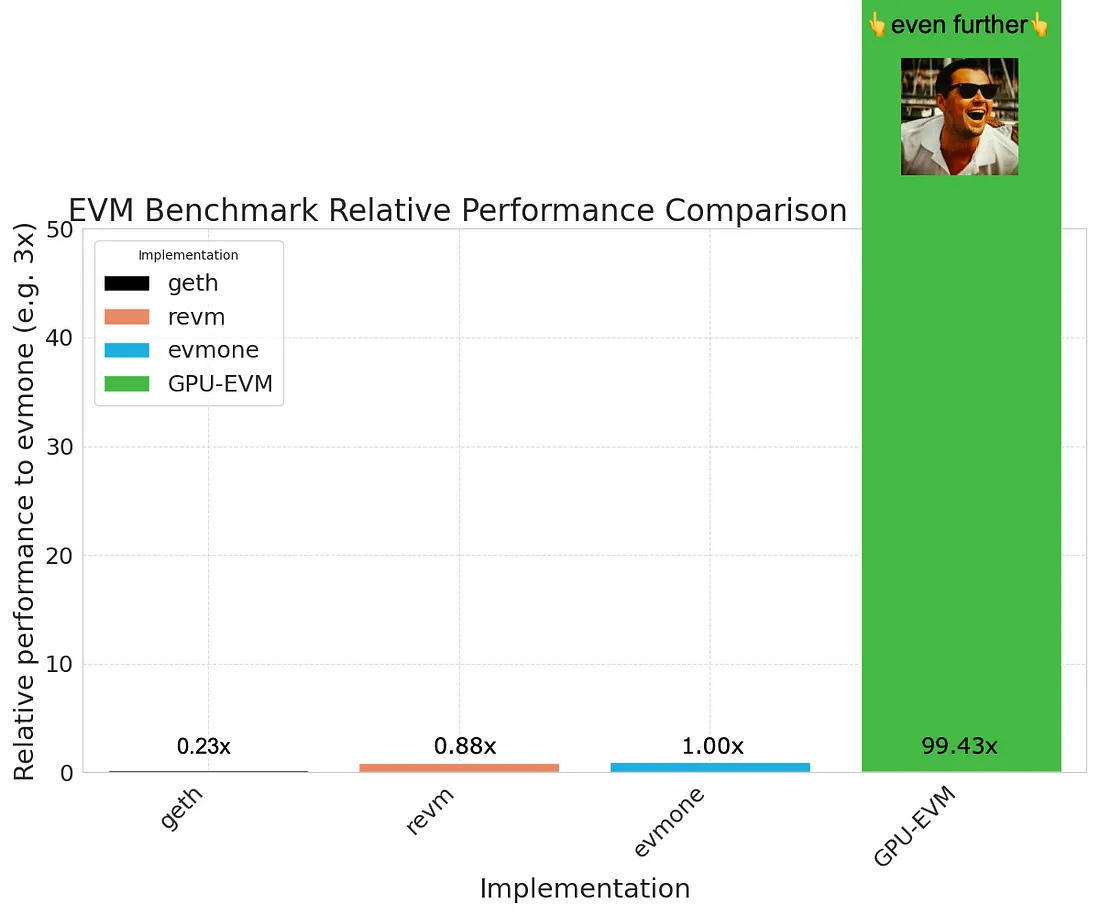
GPU-EVM 利用圖形處理單元(GPU)的強大能力來並行運行以太坊虛擬機器(EVM)操作。這意味著,與其依序執行任務,GPU-EVM 可以同時處理許多任務,顯著加快運算速度。牛津大學電腦科學/人工智慧校友團隊的這項突破大幅提高了以太坊虛擬機器每秒運算的單位經濟效益。
以太坊虛擬機(EVM)是業界標準的虛擬機,運行智慧合約,是現代區塊鏈技術的基礎。 EVM 類似於區塊鏈的作業系統,透過其基於CPU 的客戶端軟體,在許多分散式電腦上實現無需信任第三方的交易。
有了GPU-EVM 及其提供的效能增強,它為下游雄心勃勃的工程團隊帶來了巨大的功能提升:為與EVM 互動的AI/RL 模型提供基礎設施、加速L2、MEV、回測等。 (詳細資訊請見下文)
GPU-EVM:EVM 運算的新範式
英偉達最初是一家專注於遊戲的小眾公司,但現在已成為運算領域的關鍵參與者,處於人工智慧革命的前沿。這種演變反映了從預測每兩年運算能力翻倍的摩爾定律轉向黃氏定律的過程,後者以英偉達執行長黃仁勳的名字命名。黃氏定律認為,由於硬體、軟體和人工智慧的整合,GPU 效能將在兩年內增加一倍以上,超過CPU,使GPU 成為加速複雜任務的核心。
當我們達到摩爾定律的極限時,對GPU 並行性的依賴預示著一個新的運算時代,從CPU 主導向GPU 驅動的進步過渡(參考Dennard scaling、阿姆達爾定律)。這種轉變就像從單車道道路轉向多車道高速公路一樣,不僅加快了流程,也實現了更多同時進行的活動,從而拓展了技術上的可能性。
傑文斯悖論很好地說明了這種效果:就像LED 燈泡的效率導致了更廣泛而不是減少的使用一樣,GPU-EVM 的增強效率和降低成本開啟了大量新的可能性。它不僅節省資源,還催生了區塊鏈技術及其以外的創新和採用,承諾了一個未來,其中GPU 運算的效率推動了運算應用的指數成長。
GPU-EVM 效能
利用現代GPU 的通用運算能力的顯著進步,我們將GPU-EVM 的效能提升到傳統EVM 的驚人水準的100 倍以上。現代GPU 設計有數千個核心,能夠同時處理多個操作,使其非常適合平行處理任務。這種固有的架構優勢使GPU-EVM 能夠並行執行大量的EVM 指令,大大加快了運算速度和效率。
為了客觀地衡量GPU-EVM 帶來的效能提升,我們使用EVM Bench提供的開源工具進行了全面的基準測試。這個工具讓我們可以模擬各種EVM 操作,並比較傳統基於CPU 的EVM 與我們的GPU-EVM 之間的執行時間。
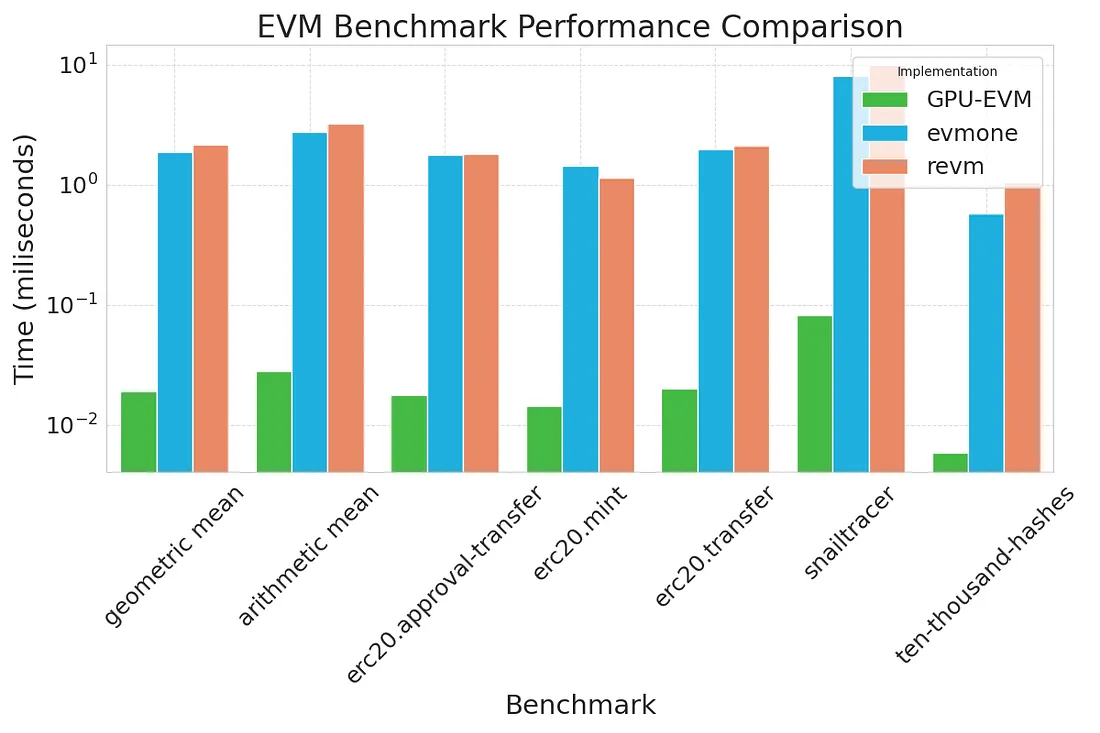
與傳統的運算範式相比,GPU-EVM 利用GPU 無與倫比的處理能力完全領先,為EVM 的效能和效率設定了新的基準。
有了這個技術基礎,讓我們探討GPU-EVM 如何革新AI 訓練和DeFi 模擬等領域,為區塊鏈應用開闢新的前沿。
使用EVM 訓練AI 代理
人工智慧正在改變世界,由ChatGPT 和其他LLM 聊天機器人領導,他們透過人類回饋的強化學習進行了訓練,應用了強化學習(RL)的知識。在其核心,RL 體現了透過與獎勵正確行為的環境互動來訓練AI 代理程式做出決策的過程。這種學習方法至關重要,因為它反映了人類和動物從周圍環境中學習的基本方式,使其成為能夠自適應和優化其行為的智慧系統開發的基石。
AlphaGo 在圍棋世界冠軍身上取得的里程碑勝利證明了RL 的變革力量。這不僅僅是一場比賽;它展示了透過RL,AI 可以發現超越人類洞察力的策略和解決方案的方式,透過模擬和與圍棋棋盤複雜環境的互動。這項突破突顯了RL 的本質:使AI 代理能夠自主導航並從其環境中學習,以實現特定目標,受獎勵系統指導。
然而,透過RL 實現這種AI 突破的旅程充滿了計算挑戰。為AI 模擬環境需要大量的運算資源。 GPU 並行化模擬環境的出現,如英偉達的Isaac Gym、Google 的Brax 和JAX-LOB,在克服這些障礙方面起到了關鍵作用。透過利用GPU 並行化模擬環境,這些平台實現了效能提升,範圍從100 倍到250,000 倍不等,使RL 的運算方面更加可行和高效。由於AI 訓練的瓶頸通常是CPU-GPU 之間傳遞資料的通訊頻寬,GPU 並行化實現了這些速度改進,並已成為RL 研究界的行業標準。
在快速發展的人工智慧世界中,GPU-EVM 作為一個GPU 並行化模擬環境,在區塊鏈生態系統內直接促進了AI 代理的訓練。其中一個引人注目的應用是在金融業,GPU-EVM 可以革新即時詐欺偵測系統。歷史顯示了這些系統的重要性,Max Levchin 開發了PayPal 的第一個防詐騙機制,以防止公司破產。透過讓金融AI 能夠在短短幾秒鐘內模擬和分析數百萬筆交易,它可以以前所未有的速度和準確度識別出詐騙活動的異常模式。這種能力,以前可能需要幾天才能實現,代表了金融機構如何防範詐欺的重大轉變。透過將AI 代理與EVM 整合到GPU-EVM 中,為在區塊鏈領域內應用強化學習(RL)原理開闢了新途徑。在這裡,AI 代理透過根據預先定義的獎勵函數準確識別詐欺交易來學習和改進。
L2 加速/ 仿真
第二層解決方案的出現對於提高以太坊的吞吐量至關重要,從而促進其在主流應用,特別是支付領域的採用。透過在主要以太坊區塊鏈(第一層)之外處理交易,L2 顯著增強了網路的容量,同時保持了其安全性和分散性的基本原則。與傳統基於CPU 的系統不同,GPU-EVM 獨立運行,能夠無縫整合並加速現有的L2 解決方案。這種加速可以透過各種方法實現,包括優化視圖函數和應用蒙特卡羅樹搜尋等演算法,以實現更高效的區塊構建和交易排序。
然而,在L2 加速的背景下,利用並行EVM 的作用是複雜的,需要認真對待。透過並行EVM 直接加速L2 並不像看起來那麼簡單。要真正利用並行EVM 的能力,必須共同努力創新L2 解決方案的設計和它們的資料庫。這一點被諸如下面的工作所強調:
儘管將GPU-EVM 與L2 解決方案整合的細微差別極具前景,但需要注意的是還有其他挑戰需要解決。這項努力的主要瓶頸包括解決與儲存相關的限制、管理長鏈的相互依賴交易以及減少狀態膨脹成本。單單GPU-EVM 無法解決所有這些問題。因此,在L2 加速背景下,透過創新設計L2 解決方案和支撐它們的資料庫,共同努力是克服這些障礙並充分實現GPU-EVM 的好處的關鍵。
DeFi 模擬/ 模糊測試
GPU-EVM 的基礎效能提升為DeFi 模擬和模糊測試帶來了變革性的改變。這種資料處理能力的顯著提升使得可以發現以前未考慮到的DeFi 策略和協議設計的邊緣情況,揭示可能隱藏的新漏洞。為了說明這項進展的重要性,可以將傳統基於CPU 的方法比作水槍,而GPU-EVM 更像是強大的水龍頭,提供了更有效的滅蟲手段。
由於GPU-EVM 的基礎效能提升,運行在這個平台上的模糊器可以深入探索並以驚人的速度運行,幾秒鐘內識別出邊緣情況。這與基於CPU 的模糊器形成了鮮明對比,後者可能需要幾週甚至幾個月才能發現相同的問題。在GPU-EVM 之上運行這些高級模糊器的能力,允許對智能合約進行持續監控,特別是那些在實際生產中的合約。這些自動化系統旨在不懈地挑戰智慧合約,試圖提前數步預見潛在的漏洞,就像一個戰略性的象棋遊戲,其最終目標是確保最高水準的安全性。
我們即將推出的產品體現了這種前沿的DeFi 模擬和模糊測試方法。敬請期待,這將重新定義智慧合約安全性和韌性的標準。
關於GatlingX
GatlingX 是一個應用基礎設施和人工智慧實驗室,專注於開發重型技術基礎設施。我們的使命是創建能夠在深層基礎設施層級上操作的各種區塊鏈應用產品。
我們相信,有一些極端困難的技術問題,是區塊鏈產業不願意解決的,因為它們太困難了。快速且廉價的安全性、運算效能和速度是蓬勃發展的區塊鏈生態系統的必要先決條件,但同樣也是極其困難的問題,會帶來很多痛苦。我們相信,除非我們將世界上最優秀的問題解決者聚集起來解決它,否則沒有人會解決這些問題。
我們致力於推動人工智慧、GPU、區塊鏈和分散式運算等領域的最新技術發展,這些領域對推動全球技術進步至關重要。
我們是一群狂熱的人:如果我們能買到現成的東西,我們就會這樣做。如果不能,我們就會自己動手建造。
使用GPU-EVM
GPU-EVM 目前處於私人早期訪問階段,因為我們正在擴大GPU 容量。如果您有興趣在工程工作中使用GPU-EVM,請填寫此表格以加入等待清單。
我們的團隊規模小,但極具才華。我們的創始團隊由牛津大學校友組成,他們在基礎設施、應用人工智慧方面取得了突破性成就,曾在Crowdstrike、Wayve、Citadel Securities 等公司工作,並創造了影響深遠的項目,如ZKMicrophone 和Graphite。





 APP
APP 

