




整理: 《積「土」成山:隱私計算與數據治理》by Foresight News
TL;DR
- 《Web3 世界的安全保障》——Certik 工程副總裁David Tarditi
- 《基於MPC 的數字資產保護解決方案》——LatticeX 基金會首席產品官宋軍
- 《自我主權身份與數據經濟:建設負責的數據經濟》——加州大學伯克利分校教授、Oasis Labs 創始人兼首席執行官宋曉冬
- 《數字時代的自我修養》——海南君顧數科研究院創始人兼院長單福
- 圓桌討論:《區塊鏈安全及隱私》——慢霧首席技術官Blue,安比實驗室創始人兼首席執行官郭宇,O(1) Labs 首席執行官Emre Tekisalp,Nym Technologies 首席執行官Harry Halpin
《Web3 世界的安全保障》——Certik 工程副總裁David Tarditi
大家好!我是David Tarditi。我是Certik 的工程副總裁,今天我想和各位分享的主題是Certik 如何成為Web3 世界的安全保障提供者。
值得信任的區塊鏈系統是當前我們所需要的,世界也需要區塊鏈才能更加安全。如果關注區塊鏈發展的情況,區塊鏈已經實現了長足和快速的進展。 2021 年,區塊鏈對於世界GDP 的貢獻是660 億美元。而這樣的貢獻數字預計到2030 年(未來十年間)會增長25 倍,達到1.76 萬億美元。
如果你再關註一下在DeFi 協議中已經鎖定的總鎖倉價值,也就是我們經常所說的TVL 的話,這個數字也已經增加了23 倍。隨著區塊鏈的使用場景日益增加,我們也日益看到由於程序本身的問題而產生越來越多的損失,程序的bug 會造成漏洞,使得黑客以及其他人來竊取資金,或者竊取具有價值的資產。
2020 年,由於黑客攻擊所造成的損失達到了5.16 億美元,而這個數字在2021 年的時候達到了18 億美元。由於黑客攻擊,或者是由於程序本身的漏洞而為黑客所利用。
這張幻燈片展示的是主要三個對於區塊鏈攻擊類型,其中排名第一的類別就是對於跨鏈橋的攻擊。這類攻擊主要會產生財務上的損失,由於這些跨鏈橋攻擊而造成的損失已經達到、已經超過了10 億美元。跨鏈橋代表的是它允許區塊鏈之間可以進行跨鏈的溝通,同時也允許資產在不同的區塊鏈之間進行轉移。但是問題在於不管哪條區塊鏈出現問題,或者跨鏈橋本身出現了問題,黑客都可以利用這樣的漏洞。比如說在之前的攻擊事件中,黑客本身創建了惡意的交易,從而實現了對跨鏈橋的攻擊。
而對於區塊鏈第二個主要類別的攻擊是針對智能合約本身的漏洞,智能合約在區塊鏈上運行,可能會出現一系列的漏洞,這些漏洞可能就會為黑客,或者是其他類型的攻擊者所利用。比如說我們經常看到的一種漏洞是對於輸入值沒有驗證,也就是不對於輸入值數據的正確性進行驗證。缺乏訪問控制,訪問控制代表的是你如何保證那些沒有訪問權限的人不能做敏感的操作,比如說鑄造或者是銷毀這樣比較敏感的操作。有時候,如果這一類函數、這一類功能權限沒有得到保護的話,就會造成損失。
第三個針對區塊鏈攻擊的主要類別就是治理攻擊,治理代表的就是對於區塊鍊和智能合約具體管理的一種方式,一般來說,對於智能合約有兩種治理的方式,其中一類就是由項目方自身對於智能合約進行管理。而第二類主要就是通過社區進行治理。比如說,如果攻擊者能夠掌握智能合約的治理,能夠治理智能合約的話,那他就能夠改變智能合約關鍵的參數,或者改變智能合約本身運行的邏輯。比如智能合約允許在關鍵緊急情況下將資產取出,但如果黑客利用了這樣的功能,有可能就直接將資產取出。
除此之外,還有一些更加微妙的漏洞,也可以導致黑客去控制智能合約中一些物品、資產的價格,或者其他的費用。所以大家看到,由於一系列的程序錯誤和漏洞而導致了在區塊鏈世界中出現了巨大的財務損失。如果真的要實現大規模採用的話,非常有必要提升區塊鏈的安全性。
所以,我希望和各位分享一下橋水基金創始人Ray Dalio 曾經說過的一句話,如果說網絡攻擊比網絡防禦更強大的話,作為擁有網絡資產的人,我不能忽視網絡攻擊的風險。也就是說,在維護關鍵安全性軟件方面,是存在巨大挑戰的。再反觀當前的環境,不管你是使用個人電腦、Web2 還是使用雲,安全性保證不及90% 的。再反觀一下在傳統世界裡,人們可以做的是對系統進行監控,來確保系統使用方式是正確的,也可以進行主動的防禦。如果說發現系統中出現一些漏洞的話,他們可以主動採取措施打補丁解決這些問題。最常見的就是打補丁,在漏洞和打補丁之間,雙方存在一種和時間賽跑的競賽。
如果說,你作為攻擊者沒有辦法操作系統底層代碼的話,那你可能就進行黑匣子的攻擊。但看一下區塊鏈世界、Web3 世界的話,大家必須要有意識,這樣的技術代表的是一種全新的技術棧,這也就意味著可能本身就會引入一些新的問題,就因為它的技術本身就是全新的。
第二個問題在於區塊鏈代表的是沒有任何人能夠單方面製止的世界計算機,所以區塊鍊是由一系列網絡、一系列計算機所組成的大型網絡。這個網絡越大,區塊鏈就越安全。但問題在於,你沒有辦法憑個人之力單邊阻止區塊鏈的運行。並不像在個人電腦世界、Web2 世界裡你可以做主動防禦。在Web3 和區塊鏈世界裡就不行了。
因為在Web2 的世界裡,如果出現極端情況的話,你只需要斷網就可以,但是在Web3 世界裡不存在斷網這一說。另外,Web3 的問題在於智能合約很難修改,因為在默認的情況下,智能合約就是不可篡改的,所以大多數區塊鏈下你也不希望對智能合約做任何變更。因為智能合約的不可篡改性就是區塊鏈存在的基石。
反觀一下在傳統世界,如果你的個人電腦出現漏洞的話,你可以打補丁。但是智能合約的世界裡,你沒有辦法給智能合約打補丁。除此之外,Web3 和Web2,以及區塊鍊和Web2 相比,還有兩個不同的點:
第一點,大多數區塊鍊和智能合約代碼都是開源的這也意味著黑客和攻擊者能夠閱讀底層的源代碼,並且識別其中的漏洞。但是在PC 和Web2 的世界裡,情況是不一樣的。
第三點,區塊鏈單個漏洞可能會造成巨大的損失,可能會造成千萬美元級的損失。到目前為止,整體損失高達數億美元,而與之相比在PC 以及Web2、雲的世界裡,這樣攻擊所能造成的損失並不是非常大。如果你的電腦被攻擊的話,你所需要做的只是重裝計算機操作系統,或者有幾天你的數據是丟失的。
將軟件層面和硬件層面進行對比,如果說你關注CPU 硬件的話,CPU 硬件安全性往往是超過99% 的,CPU 硬件依賴於形式化的驗證,形式化驗證之所以有必要是因為如果像CPU 這樣的硬件被交付的話,一旦他們在在途或交付之後想要變更的話,就會成本非常高。所以在CPU 的世界裡,像meltdown 和spectrum(音)花了22 年的時間才最終被人們發現。但是,與之相對比的是軟件側的問題,當前對於軟件中的並發理論依然處於非常早期的階段。比如說如果觀看一下軟件當前的複雜性,對於軟件複雜性的認識還處於早期階段。
Certik 所做的是將網絡安全與形式化驗證進行結合,通過將網絡安全和形式化驗證結合之後,為區塊鍊和Web3 項目提供安全性保證。參考了過去在硬件世界中所做的對於硬件安全提供保障的方法,並且應用到區塊鍊和Web3 世界,從而實現超過99% 的安全性保證。到目前為止,已經為超過3000 億美金的加密資產提供保證,有超過3200 的客戶,平均每個月要做超過250 個代碼審計。如果大家比較關注DeFi 項目的話,你會看到在CoinMarketCap 上面所列出來的DeFi 項目,所有找了第三方審計的項目中,有70% 的市場份額。因為不是所有在CMC 上列出的項目都會找第三方審計服務。總的來說,在所有rarketplace 上列出來的項目我們有12% 的市場份額。但是在那些未找第三方審計機構做代碼審計的項目中,有70% 的市場份額。
接下來想和各位分享Certik 到底如何為區塊鍊和Web3 打造最強大的安全性保證,首先我想和各位介紹的是Certik 團隊。
Certik 創始成員是由Gu Ronghui 介紹和Shao zhong 教授,其中顧教授是哥倫比亞大學計算機學的教授,而邵教授是來自於耶魯大學計算機系的系主任、副教授,同時兩位教授與耶魯大學合作,共同創辦了Certik。邵教授同時也是在驗證和確認軟件方面的專家,他在相關領域擁有超過25 年的研究和工作經驗。
顧教授則是經過驗證的並發操作系統主要設計者和開發者,CertiKOS 本身就是非常了不起的成就,因為它是世界上首個完全經過驗證的多核操作系統和hypervisor 監視器。 CertiKOS 被部署到無人地面車輛上,所以它本身就是巨大的成就,你能夠開發出經過完全驗證的多核操作系統和hypervisor。
根據康奈爾科技學院院長兼副校長Greg 的說法,十年前沒有任何人預測到我們可以證明一個單線程和的正確性,更不用提現在要把它應用到多線程和之上。所以說,邵教授領導團隊為我們樹立很好的榜樣。
CertiKOS 本身就是巨大的成就,也在研究界、學界獲得了許多的認可。比如說幻燈片上所示的SOSP2019,以及OSDI2021 最佳論文獎。這兩個會議都是操作系統以及軟件開發領域頂尖的會議。除此之外,與CertiKOS 相關的工作也獲得了三個亞馬遜研究獎項,另外也得到了ACM 的重點推介。
除了兩位教授本身外,像Jason 是首席計算機科學家,首席操作系統科學家,他擁有計算機科學的博士學位,同時在相關行業有超過20 年的工作經驗,其中包括工程、產品開發,以及運營。
我自己本人是卡內基梅隆的PHD 博士,我在微軟有25 年的工作經驗。之後我就加入了Certik,並且擔任Certik 的工程副總裁,我在編譯器以及編程語言方面是專家,同時也是安全性和操作系統方面的專家。
Villelm Sjoberg 博士是首席科學家,他畢業於賓夕法尼亞大學。 2016 年獲得了賓夕法尼亞大學博士學位。他之前就擔任邵教授的研究助理,後來也加入了Certik,他是軟件驗證、編程語言、類型系統方面的專家。除了管理團隊本身經驗非常豐富,技術背景深厚之外,團隊的其他成員教育背景也是可圈可點的。團隊有超過180 名工程師,和30 名以上的數據科學家。其中超過18% 的員工是博士,25% 的員工是從常春藤學校畢業,而41% 的員工曾在美國就讀排名前十的計算機科學大學。
接下來一個問題是Certik 到底如何為區塊鍊和Web3 提供安全保障?理念就是提供端對端的安全,覆蓋整個區塊鍊和Web3 的生命週期。主要包括三大模塊:
- Audit,審計,提供靜態保護。
- Skynet,提供動態保護。
- Leaderboard,排行榜,主要是為社區提供透明度。
對於審計的想法是,即便軟件被創建後,再被部署到區塊鏈之前做區塊鏈之前,從而確保軟件程序本身沒有漏洞。但是,在軟件被部署到區塊鏈之後,我們使用Skynet 來提供動態保護,主要是進行監控,看一下是否有不同尋常的交易,或者尋找新的攻擊類型,是否會影響到已經部署好的軟件。而排行榜主要是幫助社區了解區塊鏈系統總體的安全性情況,我剛剛已經提過了,為超過3000 億美元的數字資產提供安全保障,這些資產橫跨了DeFi、NFT、元宇宙、平台。
所以,下一個問題是Certik 到底如何保護項目,如何防止防禦一些漏洞呢?首先,會對於源代碼進行徹底的人工審計,除此之外也用軟件模型檢查形式化的靜態分析和機器學習相結合的軟件模型做自動化的代碼審計。人工審計主要是為了尋找在設計過程中一些不同尋常的問題,或者由於引用了新的區塊鏈產品而引入的新問題。而這些軟件檢查工具本身主要是為了尋找已知的問題。通過將人工審計、軟件自動化審計相結合,就能對軟件和程序進行非常徹底的代碼審計。除了對於軟件模型檢查之外,也提供形式化驗證,也就是說,用純數學的手段證明代碼的正確性。
這張幻燈片展示的是審計報告最終看起來是什麼樣子的,比如說我們審計的項目是Sandbox 這家元宇宙公司,找到了6 個問題,一個是major(嚴重),一個是medium(中等) ,還有一個minor(不是很嚴重),這代表了漏洞的嚴重程度,如果是critical,也就是排名第一的重大的話,這就意味著你的程序可能很快就會被攻擊,而minor 是最輕微的,意味著哪怕被攻擊了,損失也不會非常嚴重,或者漏洞不是那麼容易被黑客利用被攻擊。
通過這樣的方式,在Sandbox 項目裡,將相關的漏洞告知給項目方,讓項目方進行調整,從而消除或者降級漏洞。這張幻燈片顯示的是到底如何進行代碼審計。
首先會對軟件進行運行,另外也會用人工對代碼進行手工審查,對於已經發現的問題進行再次審計。比如說這張幻燈片顯示的是一行一行代碼去檢查,包括在人工審計過程中、軟件審計過程中發現了問題,都對代碼一行一行的檢查。通過這樣的方法來判斷是否有漏掉問題,找到的問題是否是對的。將找到的漏洞提交給相關項目方,從而使得他們能夠進行漏洞的修復。
正如我剛剛跟各位介紹的,平均每個月要完成250 個新的代碼審計,每個月要審計超過500 萬行代碼,每個月都會識別出超過3000 個漏洞。審計的問題在於是靜態的一次性的,但是如果說智能合約被部署完之後再發現軟件有漏洞怎麼辦?這就是為什麼我們需要有Skynet 動態審計系統,主要是提供動態的監控,動態監控系統主要監控的是兩件事情:
第一是交易,從而使得我們可以識別可疑的交易,並且在幾秒之內就發出警告。關注那些有可疑行為、問題行為的賬戶,也非常關於資產過於集中的問題,因為資產過於集中可能表明某一個DeFi 系統、某一個智能合約系統可能會出現一些金融上問題。到目前為止,自2021 年以來,Skynet 已經有超過600 個企業的訂閱。
Skynet 監控的第二個問題就是監控項目的代碼、智能合約本身,包含了靜態分析。
我們所使用的是最新板塊的靜態分析工具,同時也關注社會情緒,比如說治理是否有問題?項目方對於安全性問題的響應程度如何,響應速度如何?通過Skynet,人們就能夠真正地了解一個項目持續性的安全情況,可以對項目持續性安全情況進行監控。
對於普通人來說,對於沒有技術背景的人來說,很難判斷一個智能合約本身是否安全,很難判斷區塊鏈系統本身是否安全,這也是為什麼我們有「安全性排行榜」的原因,安全性排行榜在網站上展示,通過排行榜對於項目安全性進行評估,然後給每個項目賦以不同的安全性評分,在網站上列出安全性排行榜,任何人只要感興趣的話,都可以去我們的網站上查看排行榜,並且找出具體項目的安全性評分。
到目前為止,排行榜上已經列出了2912 個項目,如果大家感興趣的話,也可以去我們的網站上查看,具體的網址已經列在了幻燈片左上角。如果想要了解Certik 在區塊鍊及Web3 領域主要有哪些客戶。正如我剛剛提到的CoinMarketCap 上排名前200 的項目,65.4% 的項目是我們的客戶,另外排名前500 的項目中,有68.6% 是我們的客戶。
所有在CoinMarketCap 上,只要他們找第三方審計,這些項目中71.9% 是我們的客戶。再看一下季度性增長,大家可以看到,季度增長已經超過了1200 個百分點。
最後想和各位介紹一下投資者,得到了區塊鏈以及其他領域領先的投資者和風投機構的支持,比如說像紅杉、老虎環球、軟銀,還有在金融領域的高盛也投資了我們。投資者也包括區塊鏈行業的領軍機構,比如說像Coinbase 和Binance 等等。
我的演講到此結束,再次感謝各位的聆聽,如果大家想要了解更多的信息,可以去我們的網站,網站上有各類視頻及相關信息,以及很多可供大家了解的資料。
Certik 的使命是從現在開始保護你的社區和組織。如果大家感興趣,可以去我們的網站,也可以通過在這張幻燈片上展示的郵箱來聯繫我。感謝!
《基於MPC 的數字資產保護解決方案》——LatticeX 基金會首席產品官宋軍
大家好!我是來自於LatticeX 基金會的Kyle。今天將跟大家分享的話題是基於MPC 的數字資產保護解決方案,所以會花20 分鐘左右的時間介紹協議的背景、場景、應用的方式。
首先回顧一下,目前在數字資產、數字錢包領域面臨的困境,以及現在嘗試的解決方案是什麼。從行業目前的現狀大概有三類錢包去保護數字資產。
第一種,像MetaMask 這種離線錢包,它存在的問題主要是要記很多助記詞,同時它更多依賴於鏈上合約去管理私有的產權、資產安全。主要安全模型是基於合約的邏輯。在前幾年也出現了Noe-Custody Wallet,這種Wallet 主要利用兩方MPC 協議,叫TSS 以及門限簽名的協議來保護數字資產。
但在兩方協議當中,有一個瓶頸,如果有兩方,那麼其中有一方基於(2.2)的門限,其中有一方丟失的話,也會導緻密鑰的丟失,所以存在局限。所以我們就在思考,在目前這種離線錢包、合約錢包,還有兩方MPC 錢包中,有沒有一種新的解決方案呢?既可以盡量降低用戶去記助記詞,同時也有更加安全程度的保護。這就是我們今天想去探討和分享的話題。
看一看目前的解決方案,總體來說還是有兩類的,大概的思想是希望把有一把私鑰控制的資產轉移,變成多把私鑰/ 多個私鑰之間權限分離的體制。左邊主要是傳統的Multi-Sign,比如說Bitcoin 的多簽腳本,可以實現多把私鑰控制一個資產。右邊主要講的是基於密碼學的MPC 協議,在細分領域叫TSS 協議,這個協議本身主要是基於密碼學原語的方式實現一把私鑰多方計算的產生,以及私鑰的簽名,這是兩種在目前行業內比較通用的工具。
稍微對比一下這兩種方案的優缺點是什麼,以及面臨的場景是什麼樣的。
- Multi-Sign。
Multi-Sign 的方式比較簡單,好處是很容易實現,但它也存在很多問題,比如說每一條鏈都需要做兼容,在EVM 兼容、EVM 不兼容的鏈上,部署成本就比較大。
二是基於合約的邏輯,所以比原生轉賬的Gas 費成本會更高。
三是很多安全都依賴於合約去實現,所以合約本身的邏輯性,以及合約本身的安全度都會影響我們的資產安全。用密碼方式去實現多把私鑰的管理,好處就是是鏈下發生的,所以跟合約沒有本質的關係。 Gas 費成本會比較低,而且所有安全性都是密碼方式保護它,所以安全性是嫁接在離線密碼的算法實現和密碼工程實現的角度。
- TSS。
但目前TSS 也存在一個問題,在我們做多方,特別是三方以上,進入行業生產系統中還存在安全和性能的瓶頸,這些性能瓶頸導致現在很多TSS 協議沒有辦法直接應用到生產領域裡,這是目前能夠用到的工具去解決錢包的安全性,或者說數字資產安全性的話題。
可以設計一種(2.3)的體制實現資產的保護,這是一種非常典型的角度,假設說有3 把私鑰,那麼一把在瀏覽器,裡面是Kayshard-1,另外再拆分成兩把,一邊是在熱服務器,另一邊是冷備服務器。在這種模型下,剛好形成了很好的惡意相互抵抗的模型。
但是這裡面也有一個問題,在理論上這個方案是可行,但是在實際過程中錢包服務器和備份服務器還是希望形成權限的分離。在實際過程中,更多是依賴於商業上做保護。
在模型下,是比較通用,比較理想的模型去解決錢包的權限管理,以及數據資產備份以及安全密鑰丟失的問題。目前在這個模型下會遇到一些瓶頸,典型的例子就是在三方介入的MPC 密鑰簽名協議和兩方會有比較大的區別,在實際生產環節中也跟很多項目方做過聯合測試。會發現三方以上,包括在瀏覽器端會嚴重降低MPC 協議的效率,甚至產生一次賬戶Keygen 的過程需要30 秒以上的時間,這種用戶體驗是比較差的。假設說在形態比較弱的情況下,可能會導致簽名失敗或者密鑰產生失敗,本質上還是一種在弱環境下、弱計算環境下,目前的MPC 協議效率是比較低的,這也是今天想和大家分享的特點,如何提高MPC 協議本身在這個領域裡的算法效率問題。
LatticeX 基金會單獨有一支研究團隊和工程團隊,專注在MPC 裡的TSS 協議研究、設計和工程實現,並且也開源了現在的代碼供大家去使用。接下來會重點分享在這個領域裡做了哪些改進,哪些設計方案的改進,還是說算法性能的改進,這是我們著重想跟大家探討的話題。
已經把代碼開源了,在Github 上,大家可以免費獲取到代碼。代碼本身是基於Rust 語言寫的,在開源的實現裡,已經實現了ECDSA 的算法,因為對於大部分數字資產簽名來說,ECDSA 是非常常用,嚴格說應該佔了70%80% 以上的場景化,未來ECDSA 都會陸陸續續開源給大家使用。
在整個算法裡,大致實現了比較簡單的場景:一是密鑰的場景;二是簽名的過程。在密鑰產生和簽名過程中其實都做了改進,在密鑰產生環節,理論上和工程上做了測試,因為我們在算法層面和工程層面都做了很多優化,所以比經典7718(音)那篇論文的協議大概能快到8 倍、7 倍左右的算法效率,這樣的話就可以把一次Keygen 的時間從原來的30 秒拉到2 秒、3 秒比較高效的時間,這樣就更容易用到生產系統。
在簽名的過程中,利用到offline 預計算的過程,因為在原來的論文裡MPC 需要非常多輪次的交互,這樣的交互在網絡比較複雜的情況下,會帶來多次網絡時間的延遲。其實我們可以把多方計算式的簽名拆成跟消息無關的Offline 預計算過程,和消息/ 轉賬金額有關的Online 的最後一次簽名過程。
在過程中,特別適合錢包,或者TPS 不是很高的場景,可以提前緩存很多組的預計算,當用戶在真正簽名的時候,只要推動Online 的那一步就可以了,在這一步上可以最大程度降低用戶在真正轉賬簽名時遇到的算法和性能瓶頸,讓他用起來感覺就像一次正常的單方計算、單方簽名一樣的用戶體驗。
同時,為什麼我們的協議會比之前的協議帶來很大的提升?簡單說明一下,大概這篇論文發表在ASIACRYPT 上是在CCR+20 基礎上做了改進,在CCL+28(音)的協議裡更多是基於paliya(音)同態的算法,Paliya 同態(音)本來是計算量相對比較複雜的體制,所以會導致在Keygen 的過程中產生很重的驗證或者安全邊界檢查的輔助行為。比如說Ready proof(音),或者說一些交換機教研的過程。這個過程會導致簽名、Keygen 都比較慢。
這篇算法論文用的是私鑰的同態加密,私鑰的同態加密會有更多的好處。比如說在同一個域上進行操作,所以在做整個Keygen 的時候可以做到更快,這也是理論性的基礎。同時也做了一些安全邊界的優化,所以在做簽名的時候,相對來說有一定的優化基礎,這是論文的背景。
行業內很多人都在探討如何改進TSS 協議本身的過程,但是我們還是希望在很好的理論基礎下,比如說協議經過了大規模學術挑戰,然後再用到生態環境中,這樣的好處是得到充分的理論保證,得到業界很多比較好的學術高水平挑戰之後,再用到實際工廠生產過程中,這是LatticeX 基金會在MPC 領域做的工作。當然,今天分享主要是TSS 協議,它跟資產安全是做緊密關聯的,本質也是多方計算的模式。
除了TSS 協議本身帶來的優點之外,可以把一把私鑰拆成多方。實際上在真正的工廠生產過程中,不可能簡簡單單用一個TSS 協議就可以了。所以在原來的TSS 基礎上,不斷衍生出生產環境是生產場景。一個比較簡單的概念是嘗試構建端到端的密鑰安全生命週期管理模型。在原來的錢包領域,比較簡單的應用是創建一個賬戶就代表一個私鑰,簽名就代表使用它。一般來講,當我們不再使用的時候,就嘗試刪除私鑰體系。
但有些比較嚴格的場景,像大規模託管,或者更加To B 的應用場景裡,更多考慮的是它非常嚴謹的一套模型。做了以下幾個設計點:
第一點,在Key 下的每一個分片領域,二次設計時的安全性是怎麼考慮的?可以基於一些HSM 數字加密機、密鑰管理系統去保護單個節點裡的Keyshard 內容,在瀏覽器端、移動端可以利用可信計算技術保護Keyshard,這是一個考慮點,還是要把Heyshard 和原來的KMS、HSM 做整合,以此達到更好的效果。
除此之外,還在生命週期上希望管理整個流程,在每個管理流程裡加入到權限控制的領域裡。假設在三方場景裡,大概就是這樣去設計它的整個模式和系統的特點。其實,未來還會考慮到MPC 的方式如何兼容到原來經典的安全合規模型,在原來經典的HSM,或者KMS 裡,已經設計非常好的最佳實踐。我相信這也是大家不斷完善的過程,把單點的私鑰保護體系變成MPC 的方式去保護,這也是我們即將要去做的方式。
整體來看,在MPC 領域,更多關注的是如何利用MPC 技術解決好私鑰安全,以此帶來更多的未來場景拓展,使MPC 帶來的數字資產領域得到一些新的範式,更多是依賴於多權限、多方的協同管理,降低單點風險,以此提升更好的用戶體驗,帶來更好的Web3 入口。
這是我今天要跟大家分享的內容,謝謝大家!
《自我主權身份與數據經濟:建設負責的數據經濟》——加州大學伯克利分校教授、Oasis Labs 創始人兼首席執行官宋曉冬
大家好!我是宋曉冬,我是UC 伯克利分校的計算機科學教授,同時也是Oasis Labs 的創始人,非常感謝萬向的邀請。
眾所周知,數據是現在經濟重要的驅動力,同時也是機器學習的命脈。目前,我們每天看到有越來越多的數據得到收集。對於個性化數據的價值來說,它現在佔GDP 的佔比已經達到了非常高的水平,全球數據經濟也呈現了指數級增長。然而,在很多數據中,很多都是非常敏感的。如何使用這些敏感的數據?已經給個人、機構帶來了前所未有的挑戰。
對個人而言,個人已經喪失瞭如何使用自身數據的控制權,經常他們自己的個人數據被出售或者被濫用,但是自己卻不知情,也沒有同意。經常大家會聽到說用戶的數據被他人使用,前提就是他們的數據已經被匿名化了。然而,大量研究表明,數據的匿名化本身是不足以保護用戶的數據隱私的。比如說這張幻燈片展示的是《紐約時報》曾經所做的案例研究,他們通過研究的方式證明了從一個匿名的手機位置數據集之中,是能夠追踪到前總統特朗普特勤局特工的位置,以及前總統特朗普本身的所在地。機構持續遭遇大規模數據洩露的困擾,很多此類攻擊中,攻擊者甚至竊取到了數億甚至數十億用戶的敏感信息。
最重要的一點是,由於隱私問題,許多有價值的數據仍然被困在數據孤島之中。也就是說,沒有辦法得到有效的應用。隨著數字經濟、數據經濟的發展,這些問題未來只會變得更加嚴重。因此,我們迫切需要一種新的範式,我將這樣新的範式稱為「負責任的數據經濟」。負責任的數據經濟定義是什麼?負責任的數據經濟想要實現的目標是什麼?遵循的原則是什麼呢?
首先,我們必須要建立和執行數據權利,這樣的數據權利構成了數據經濟的基礎,同時也有助於防止數據的誤用和濫用。同時,也要確保數據創造價值之後可以公平地分配,從而使得用戶能從自己的數據中獲得足夠的收益。最好的是需要實現有效的數據使用,從而最大程度提高社會福利,提高經濟效率。
為了建議負責任的數據經濟,需要做出範式轉變。當前Web2 世界是以平台為中心,提供的是中心化的解決方案範式。但是,我們需要轉向Web3 的新範式,應該是去中心化的,以用戶為中心的。
先看一下在數字世界中關鍵的控制點,在數字世界中,需要訪問資源數據,同時也要對數據進行計算。但是,這些不同的控制點是由不同機制所控制。首先有身份和訪問控制,同樣也有數據使用控制。在Web2 世界中,所有機制都是由中心化的第三方控制。用戶的身份往往是被服務提供者管理。用戶數據一般被放在集中化的數據中心(數據孤島),用戶的數據往往是在自己不知情的情況下被機構使用。因此,在Web2 的世界裡,用戶完全無法控制自己的數據。
在Web3 的世界裡,我們希望實現這樣的範式變更,從中心化的控製到去中心化用戶控制的轉變。而這一切都是通過去中心化的身份、去中心化的訪問控制,以及合規的去中心化計算來實現。這樣一來,就可以實現自主身份、自主數據訪問、自主計算。也就是在Web3 的世界裡,用戶可以在不依賴任何中間機構的情況下控制自己數據的使用方式。
先看一下去中心化身份,也就是所謂的DID。一般來說,用戶用自己的用戶名和密碼作為身份驗證的工具,在Web2 的世界裡,用戶經常會依賴於第三方服務提供商來幫助他們進行身份管理。然而在Web3 的世界裡,去中心化的身份就意味著用戶可以控制公鑰加密方法來控制自己的身份。從本質上來說,用戶可以使用自己的身份,控制自己的身份,只要他們能夠控制自己的私鑰即可。
因此,有了去中心化身份,我們就可以使用更加先進的技術,能做更多的事情,實現更多的功能。尤其是我想和各位簡單分享一下最近所做的項目。這個項目主要聚焦的就是匿名憑證。有了匿名憑證,對用戶而言,就可以獲得相關的憑證頒發機構,以保護隱私的方式獲得憑證的頒發,用戶可以用這些匿名的憑證來證明自己的某些屬性,因為這些屬性在他們獲得證書憑證之前就已經得到了證明,用戶同樣可以以保護隱私的方式來使用這些憑證,從而使得他們在整個過程中保持匿名,但是同時也可以證明。比如說自己超過了18 歲,已經成年了,也可以證明自己的其他屬性。
在最近SNAC 的工作研究中,構建的第一個基於zkSNARK 的匿名憑證,從而實現高效的鏈上驗證。在這個研究裡,用戶獲得了所頒發的匿名憑證之後,就可以生成證明。比如說證明自己已經超過18 歲,或者證明自己是UC 伯克利的學生等等。有了證明以後,可以通過智能合約在區塊鏈上進行驗證,用戶就可以使用某些服務,因為他們已經證明了自己擁有某些所需要的屬性。
同樣,利用先進的密碼學。比如說利用證明遞歸(音)對證明進行批處理,從而進一步優化對於這些匿名憑證的鏈上驗證效率。也充分支持撤銷以及對於憑證進行審計,包括對於發證機構,以及對於匿名性進行撤銷或者審計。所以這是很好的使用場景,因此基於zkSNARK 的鏈上驗證和證書憑證頒布,主要就是可以在DeFi 中做KYC,因為在這樣的情況下,用戶可以做KYC 獲得相關的憑證,憑證是匿名的,但是可以表明用戶已經通過了KYC。現在用戶還可以利用匿名憑證加入鏈上DeFi 服務,使用鏈上的DeFi 應用。同樣,他們可以證明自己已經完成了KYC。一方面,保護了用戶的隱私,另一方面,也符合了合規性的要求。
有了新的加密學方案,也實現了相比於之前的非基於zkSNARK 方法數量級的性能提升。而且解決方案也使得首次DeFi 上可以做KYC,這就是自我主權身份和匿名憑證如何幫助用戶保持對於自己身份的控制,同時也能夠以一種保證隱私的方式使用其他服務的很好範例。
用戶到底如何通過數據和對於數據的計算來解鎖一些其他的功能?首先,要實現自我主權的數據和計算,需要開發新的解決方案,在Web2 中的傳統解決方案本身是不足以滿足這樣的要求,在傳統的Web2 中只有兩種解決方案:一是數據,只有在不被使用,或者在發送過程中被加密,也就是說只有在不被使用和發送過程中得到了保護,但是一旦數據得到了使用,或者是在使用後被複製的話,數據所有者很難對於這些過程進行控制。
我剛剛已經提到了數據匿名化往往是不足以保護用戶數據隱私的,同樣的道理,在Web2 的世界裡,用戶也沒有辦法控制如何對自己的數據進行使用。相反,在Web3 的世界中,我們需要開發全新的技術來實現數據的保護,在使用中保護數據。
這又包含了幾個不同的層面:首先,需要控制數據的使用,不允許沒有權限的人對於原始數據進行複制,做計算的時候也不需要復制原始數據就可以完成,第二層面需要保護計算輸出值不會洩露敏感信息,並保證數據的使用合規性。通過這樣的功能是,用戶就可以控制對於自己數據的使用,而不需要依賴於任何第三方。
幸運的是,我們在負責任的數據技術領域,不管是從研究還是從實踐的角度,都看到了迅速的進展。許多不同類型的技術可以被結合在一起,從而幫助我們實現負責任的數據使用,包括安全計算。比如說使用安全硬件、密碼學的方法,比如說MPC、安全多方計算,以及完全的同態加密等等,這些安全計算在計算過程中就可以保證數據的保密性。
差分隱私也可以保證計算的輸出不會洩露有關於輸入值的敏感信息,聯邦學習則支持分佈式的數據分析和機器學習,同時保證數據不會離開用戶的數備。加上分佈式的賬本,就可以提供有關於數據使用的不可篡改的日誌,從而確保數據在使用過程中始終是合規的。
給各位舉一個例外真實世界的例子,通過這樣的例子,希望給各位展示的是安全計算技術如何幫助用戶,始終保持對自己數據的控制。與此同時,也能夠保證以一種保護隱私的方式數據可以得到使用。這是我們最近做的一個項目,是由Oasis Labs 和Meta,以及一些其他大學聯合完成的。這是同類項目中第一個大規模AI 模型的公平性研究項目。
眾所周知,AI 模型/ 人工智能模型現在非常流行,比如說在Meta,AI 模型被Meta 用來給用戶做推薦,或者是提供個性化服務。從社會的角度來說,有必要知道這些AI 模型在廣泛使用過程中是否是公平的,還是說有偏見。所以現在問題在於如何進行AI 模型公平性的判斷呢?如何衡量它是否公平呢?尤其是為了評估AI 模型是否公平,模型提供者的計算。
首先,需要基於用戶信息所推演出來的結果,另外一方面又不能影響到用戶信息的隱私性。所以,作為模型的提供者,Meta 是知道一個特定用戶ID 在AI 模型中輸入的輸入值。但是,Meta 並不知道用戶的敏感屬性,比如說他們的性別。此外,用戶也可以將他們有關於性別的敏感信息提供給某個調研。如何對AI 模型的公平性進行評判呢?使用不同的指標進行衡量。
簡單起見,給大家舉一個非常簡單的例子,將用戶性別進行計算,比較一下平均推理的結果。通過計算平均推理結果,就可以知道AI 模型到底是否是公平的。
以性別為指標,關鍵問題又變成瞭如何以保護隱私的方式來做對於AI 模型公平性的衡量。在這樣的情況下,模型提供者是知道用戶推理結果的,但是他不知道用戶的敏感屬性。而調研人員知道用戶的敏感屬性,但是卻不知道模型推理出來的結果是什麼。
所以,要求我們做的是一方面需要計算最終的結果是否是公平的,利用來自不同數據源的數據進行計算。同時,確保用戶的隱私始終得到保護。這就是我們一開始在和Meta 合作時所設立的研究目標。開發的技術結合了不同的隱私計算技術,首先使用的是安全多方計算,調研者秘密在多個協助者之間分享用戶的敏感屬性,在我們的調研裡,我提到有三家大學也加入了,他們就是在這個研究中的協助者。
模型的提供者Meta 為用戶的推理結果生成同態加密的結果,同時也提供零知識證明,證明加密推理的結果是正確的,並且是在一個範圍之內。然後將同態加密的計算結果發送給調研人員、一協助者。一方面協助者拿到了調研人員關於用戶屬性的信息,另一方面又拿到了模型提供者的模型推演結果,所以協助者可以利用這些數據一道計算並且判斷AI 模型是否公平。協助者也用了差分隱私來添加噪聲,從而進一步保護用戶的數據隱私。最終通過計算之後得到的研究結論是可以以保護隱私的方式得到公平的計算結果。這是隱私計算技術在現實世界中第一次大規模部署,被用於對於AI 模型公平性的衡量。
同時,也開發了新的開源平台,從而讓去中心化的數據科學變得更加容易,因為我們希望能夠彌合科學界、研究界、現實世界之間的鴻溝。這也是數據平台的起源,平台的名字叫做CoLearn,它是一個新的開源平台,它使得協議可以在統一的框架中組合,並且構建一個經過精心設計的標準化、去中心化的編程抽象預設,它利用了最近在密碼學和隱私保護方面的相關技術。
CoLearn 為去中心化數據科學提供統一的平台,從而將新協議的設計從設計到部署整個過程,不管是從時間的角度,還是對於部署人員精力的角度,都減少了幾個數量級。從時間而言,之前一個月的工作,現在只需要僅僅幾週就可以完成。開發人員也更容易利用已有的加密協議,幫助他們完成新協議的部署和設計。目前,CoLearn 也已經集成了許多應用於隱私保護、機器學習、聯邦學習等最先進的加密協議。
當我們將隱私計算和區塊鏈相結合,我們就可以實現一種新的資產,將其稱為數據資產。區塊鏈有助於提供用戶數據使用政策的不可篡改數據,區塊鏈也可以提供用戶的數據到底是如何被使用的,通過隱私計算來保證,不僅僅是在處理過程中,同時也保證在計算過程中,以及在輸入值、輸出值方面都可以保證數據的隱私。將數據以及相關的策略封裝在一起,從而創建了一些規範的標準,把它打包成資產,從而使得用戶能夠從自己的數據資產中獲益,通過數據資產化,Oasis 可以打造新的負責任的數據經濟,允許用戶和企業在過程中從數據資產中獲得價值。
比如說,已經用了基因組數據作為很好的例子,在實際過程中已經得到部署。因為用戶的基因組數據可以說是最隱私的數據源之一,但同時它的價值也是非常高的。
用戶經常會擔心自己的基因數據到底被使用到哪裡了呢?如果說他們將自己的數據提供給相關的數據分析服務,對Oasis 來說,首次為用戶提供了一個平台,幫助他們保證對於自己基因組數據的控制。與此同時,又可以將數據提供給其他方使用。在過程中,用戶本身也能從自己的數據中獲益,獲得經濟收入,同時保證了他們的數據隱私。
將不同的組件結合一起之後,社區就可以組成數據共同體,或者更進一步的數據DAO 組織用於去中心化的數據科學研究。比如說數據的所有者和數據的產生者,可以用指定的策略對於數據集進行很好的管理。比如說,他們可以加入某些數據DAO 組織,而這些數據DAO 組織可以指定如何使用DAO 中的數據,如何共享從數據中獲得的經濟收益。
而數據使用者、數據分析師可以搜索這些數據DAO 組織,找到他們所需要的數據,然後在不同的數據集和數據源上編寫自己的數據分析和機器學習程序、模型。數據分析的機器學習程序可以在分佈式安全計算平台上運行,與此同時也保證程序是符合預期策略的。通過這樣的方法,就可以減少數據使用的摩擦,消除數據孤島,並且實施更強大的安全和隱私保護。
我堅定不移地相信,在十年後,數據信託、數據共享將會成為使用數據源的主要方式,實現所有者經濟,使得用戶作為數據的所有者、數據的合作夥伴,從數據中獲得經濟收益。在十年後,新形勢的數據信託和數據DAO 組織將創造巨大的經濟價值,比當前要高出幾個數量級。
總而言之,通過從Web2 中心化的控制,轉變成Web3 的去中心化控制,我們可以幫助用戶控制對於數據的使用,而無需依賴任何中心化的第三方。通過這樣的範式轉變,就可以真正走向負責任的數據經濟。對於互聯網的未來,也必須建立負責任的數據經濟。
2020 到2030 的十年,就是建立負責任數據經濟的十年,感謝各位的聆聽!
《數字時代的自我修養》——海南君顧數科研究院創始人兼院長單福
大家好!非常榮幸有機會參加2022 區塊鏈上海國際週,我是君顧數科的單福。
君顧數科主要是研究傳統金融行業的相關政策和相關動態,更多的是站在金融消費者、投資者角度來看待和研究各種金融政策和現象。
今天,我分享的題目是《數字時代的自我修養》。之所以提出這個命題,是因為我深刻地感受到人類正從物理世界向數字世界逐漸轉型,非常有必要對數字世界中的相關命題進行各種研究。尤其是對於普羅大眾應當以什麼樣的心態去認識數字世界,怎樣才能更好地在數字世界裡獲得更有尊嚴的生活,這可能是大多數人需要考慮的話題。希望今天的分享,能夠拋磚引玉,引出大家更多更精彩、更專業的觀點。
今天的分享一共分四部分:
- 第一部分,人類已經邁入數字世界。
- 第二部分,何為美好數字世界。
- 第三部分,數字時代的自我修養。
- 第四部分,用戶控制的數字身份和數據賬戶體系。
一、人類已經邁入數字時代
研究人類歷史的角度非常多元的,既可以從生產力的發展角度,也可以從生產關係,甚至從宗教等各方面來看。我的角度是從人類掌握數據、以及分析數據的能力和水平出發。我認為,人類的發展歷史,就是一個不斷深入理解數據、從數據中提取智慧,以更好地改造社會、創造美好生活的過程。由此可以說,人類對數字收集的廣泛程度和深度、利用數字的專業程度等等,都是判斷社會技術先進程度的重要標準。為此,人類社會的發展可以分為以下五個階段:
最漫長的、持續了幾萬年的是第一個階段,人類數據一直沒有被收集或者沒有被大規模收集。從上世紀40、50 年代開始進入第二個階段,大型計算機被發明,這些計算機設備首先被用在國防等相關領域進行分析、處理、計算。第三階段的特徵是計算機設備從國防和大型工業領域、大型工業企業下沉到個人,個人的數據開始被收集、分析和使用。第四個階段,隨著互聯網的出現,個人電腦也進行了聯網,由此帶來人的數據也被聯網收集和初步分析使用。第五個階段是人類數據被聯網大規模收集和使用,這是當前所處的階段。
從中不難看出人類社會發展是加速式的發展,第一階段持續了幾萬年,但後面幾個階段到現在只持續了不到一百年的時間,這也是我們感受到社會在跨越式發展和變革的重要原因。
未來也許會出現更加高科技的數據收集方式,包括現在探索中的腦聯網等技術,由此不難得出一個結論,人類的衣食住行等物理需求必須要在物理世界得到滿足,但是人類的喜怒哀樂、社交等情感需求,可以、甚至可以更多地在數字世界得到滿足。物理世界對人類需求的滿足是存在上限的,但是數字世界給人類情感精神帶來的滿足不存在上限,因此數字世界創作的產出可以超過線下的物理世界。
二、何為美好數字社會
首先,我想提出一個對社會運行模型的簡單框架。任何社會運行的基礎模型就是滿足人的需求。區別在於,它滿足的是少數人的需求還是大部分人的需求,以及它滿足的是物質需求為主,還是精神需求為主?第二,這些需求由誰來滿足?比如說封建時代很多生存需求是自給自足的,也就是自己滿足自己的衣食住行等需求,精神需求也在自己的社交過程中自己解決。工業化時代的特點是社會化大分工、大生產,衣食住行可能都來自不同的工業企業。數字時代的特點跟工業時代不一樣,它具備非常典型的「贏者通吃」的規則。也就是說,可能到最後,為我們提供數字化服務的,只有少數幾家平台企業,這少數幾家平台企業就能較好地滿足人類的物質需求和精神需求。
這也就引出了社會運行過程中的公平、效率、風險的三角均衡的考慮。對普通民眾而言,在不同時候有不同的訴求,戰爭和和平年代的訴求存在明細差別。現階段大家基本已經解決溫飽,對公平的呼聲會比以前高。對於生產企業,他們關注的是效率,因為這直接決定了他們的競爭力和盈利能力。對於政府監管部門而言,他們比較看重中間的風險因素,既包括實體風險,也包括金融風險等等。
在此,我想把古人所暢想的美好社會跟大家再溫習一下。在《禮記·禮運·大同篇》裡提到:大同社會是大道之行,天下為公,選賢與能,講信修睦。故人不獨親其親,不獨子其子等。從中不難看出,他們所暢想的理想社會,即便放在現在也不落伍,理想社會更重要的是反映人和人之間的關係,人的尊嚴和人的精神面貌是不是積極向上,是不是平等友愛的關係,並不太在乎他的生活水平是不是特別滿足富裕。話說回來,如果能夠達到這個理想社會,那麼在任何一個時代,這個國度的生產力水平一定能夠取得當時技術條件限制下最高水準。
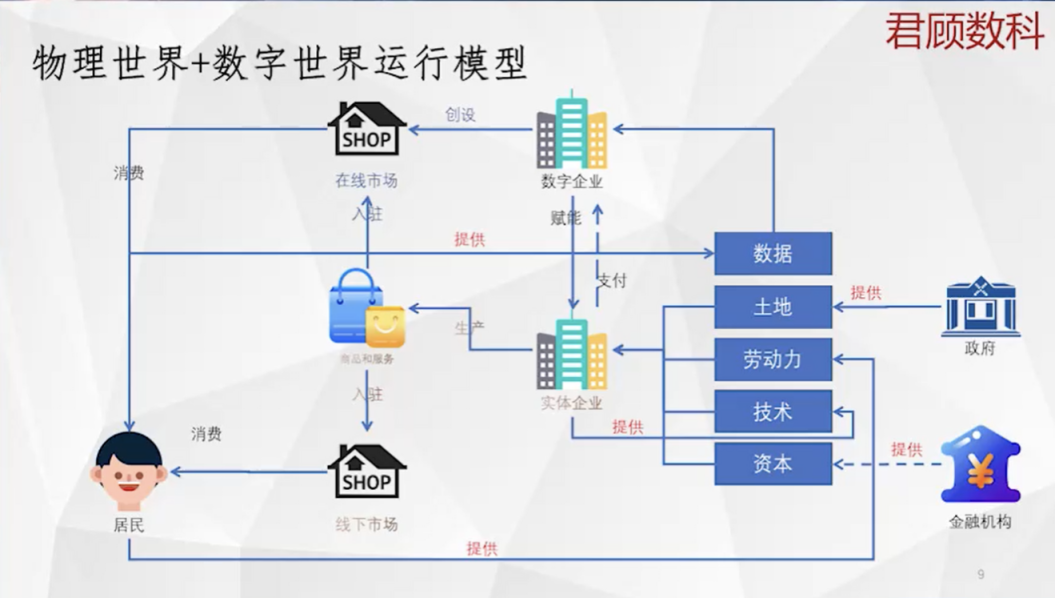
物理世界+ 數字世界運行模型
我試圖想把物理世界和數字世界的運行基礎邏輯給簡要說清楚。 (如圖所示)左下角是居民,一方面居民要消費,另一方面要參與生產。消費的錢是生產得來的,是向實體企業提供自己勞動力以後的勞動報酬來獲得貨幣的。實體企業通過居民獲得的勞動力,加上通過政府獲得的土地,通過相關渠道獲得技術資本,通過金融機構獲得金融資本等。有了這些傳統的生產要素,加總在一起就可以生產出很多的商品和服務,這些商品和服務能夠滿足人的很多需求,因此也產生利潤獲得回報。
數字企業的運行模式跟物理世界不太一樣,它以數據為生產原料,那數據是怎麼來的呢?這些數字企業成立一個平台,在平台裡設立很多生活場景,這些生活場景能夠給人們生活的衣食住行各方面帶來很大的便利。所以它通過這些便利吸引和積累了很多用戶,又在用戶活動過程中積累了很多用戶的個人信息和行為數據。因此,能夠基於數據更好地刻畫人的特徵和需求,因此它能夠更好地指導和優化產品的生產設計等相關過程,從而給實體企業生產帶來效率和效益上的提升,這反映了數字企業和傳統企業相生相伴的關係。
數字企業在運行數字經濟時產生很多數據。從層級來講,分為基層數據和高層數據。基層數據就是原始數據或者明細數據,高層數據是基於基層數據的分析、歸納、統計等得到的數據。基礎數據分為對物理世界觀察的基礎數據和對人類行為的記錄數據。人類行為的數據包含個人信息或者未脫敏的數據,以及不包含個人信息的數據。重點說一下未脫敏的原始數據,這也是當前Web2.0、Web3.0 里大家爭議比較多、矛盾比較多的地方。
我認為,一個比較美好的數字世界應當是這樣的。數據的產生、收集、利用、協同全流程都是相對完美的狀態。比如數據的產生:用戶能夠以相對低的成本獲得相關的數字設備,用戶行為數字化比例非常高。數據的收集:相關企業都能夠徵得用戶的實質知情同意,數據的來源是光明正大的。數據的利用:算力極大豐富,由此能夠深刻地揭示社會的運行規律,為用戶提供更加優質的產品和服務。數據的協同:凡是對數據有需求的企業,都可以以相對合理的成本獲得他們所需要的數據,並且不會存在來源不穩定的後顧之憂。能夠想像到,整個社會將是需求收集精準、生產高效、風險可控,物質文明和精神文明非常豐富的社會,這是我對美好數字社會的暢想。
與之相對的是醜陋的數字社會,相信大家在很多科幻片裡都有見到過,高科技+ 低生活同時存在,很多數字企業把用戶當做它的「原料」來對待,用戶通過出賣自己的勞動和數據才能獲得必須生活物資。他難以逃離這個社會,因為離開後就無法很好地獨立生存。並且數據被少數企業所壟斷,其他組織基本沒有可能獲得相關數據,也就難以和這些企業進行正常的市場競爭。並且物理世界相關的生產組織,以及用戶的需求都被這些數字企業所控制、引導和壟斷。相關的監管部門缺位、甚至被俘獲,整個社會處於階層固化、毫無生機的狀態,在我眼裡這是一個醜陋的數字時代。
我個人覺得當前的數字時代既沒有那麼美好,也沒那麼醜陋,而是處於相對中間的位置。現在大部分人都處於Web2.0 時代,Web2.0 時代大家通常做法是怎樣的?每個人都有若干個賬戶或者是數字身份,通過某個賬戶進入到某一個平台企業的某一個場景,比如說電商、出行、資訊閱讀等等,在這個場景裡獲得了便利,同時也將它自身的個人數據交給平台方,平台方存儲在自己私有的數據庫裡。整個過程中,數據是從個人流向平台方,並且其他方想要獲得這些數據非常難,要么價格特別高,或者是通過灰產、爬蟲等偏門的方式來獲得。這離理想的數字社會尚有不少距離。
三、數字時代的自我修養
我認為,任何時代都需要有與之配套的生存素養。比如說在原始時代的時候,要有相關的打獵技巧才能捕捉到足夠的食物,才能養活我們自己和族人。同樣封建社會要學會種地,或者是織麻紡絲之類的,工業時代要學會煉鋼製造設備。同樣,數字時代的居民也需要有一些素養要求,我從以下幾部分闡述:
1)理念部分
因為梅特卡夫定律,互聯網平台對個人數據的渴求是沒有邊界的,它背後需要不斷地擴充自己的場景和用戶規模,以使自己對競爭者始終保持領先地位,否則就會逆水行舟,不進則退。所以他們盡可能地發掘更多的場景、吸引更多的用戶、收集更多的數據。
普通參與者在這裡具有多重身份。第一,他們是消費者;第二,他們是數字時代相關生產數據原料來源。數字企業、平台企業和用戶是存在利益衝突的,因為個人數據主要來自於用戶。在有利益衝突的情況下,需要我們的監管部門能夠秉持公允客觀的立場,和與之配套的技術水準,來進行市場秩序的維護。
2)目標部分
我們的目標是什麼呢?在數字時代,如果你技術水平比較高,可以兼濟天下,幫助大家做有尊嚴的數字居民。如果只是普通居民的話,那就是獨善其身,做一個有尊嚴的數字居民,有尊嚴的核心是我的數據我自己能做主。我的數據在沒有得到我許可的情況下任何人都拿不到。數據給對方之後,對方必須要安全保管。另外,對方雖然掌握我的很多個人數據,但對於那些我不希望被別人知道的隱私部分,即便他有這個技術水平,也不要嘗試去猜。我的數據現在在這兒,但是我需要給別人的時候你也需要來配合。如果數字時代居民能有這樣的權利和地位的話,可以認為這樣的數字生活是比較有尊嚴的數字生活,居民也是比較有尊嚴的數字居民。
3)路徑部分
如何達到這樣的途徑?
- 第一種,數字企業和互聯網企業特別有良心、有道德,是存在這種可能的。
- 第二種,有賴於監管部門的公正以高效,即便在我們的權益被侵犯的時候,監管部門能幫我們發聲,維護我們的正當利益。
- 第三種,依靠我們自己,提高自身的數字化素養,將自己的數字安全和數字尊嚴主要肩負在自己的身上。
這裡面會類似存在最佳實踐的概念,要做的不是一個具體的事,而是持續的事。首先要了解當前自身產生了哪些數據,哪些有被收集、被計算、被畫像、被協同了?在這個過程中,又存在哪些侵犯我權益、損害我尊嚴的地方。有的話,就查漏補缺、亡羊補牢,並且把整個過程內置於後續的循環週期中去,使自己的個人數據始終處於自我掌控狀態,這裡的自我掌控,是指數據要么沒有被別人掌握,或者是經我我許可授權後被別人掌握的相對公平的狀態。
當前個人數據被收集,依託於相關的硬件、軟件、網絡設備等。硬件更多是手機、個人電腦、智能家居、穿戴設備等等。採集的信息包括基本信息、行為數據、生物信息(指紋、人臉、聲波紋)、行為規律等,行為規律包括這個人經常在幾點上網,幾點聊天,打字頻率等等。這些環節都是可以成為洩露個人信息的環節,也是可以改進自身數據安全和數據尊嚴的環節。最核心的是要建立為用戶所掌控的數字身份,這可能是實現用戶數字主權和有尊嚴數字生活的必由之路。
四、用戶自主掌控的數字身份和數據賬戶體系設計
用戶控制的數字身份和數字賬戶體系最大的特點是「用戶控制」。也就是說,當前也有很多數字身份、數字賬戶,但它不是被用戶控制的,這在Web2.0 裡非常明顯。為什麼要控制權呢?當前數據的所有權在學界、業界關係並不是很清晰,並沒有很明確的說法。在此情況下,控制權可能是最核心的一個權利,數據歸誰控制,很大程度上決定了數字生活的質量和人的尊嚴。如果數據是被用戶所控制,那將大大減少用戶個人數據被洩露,個人隱私被洩露,個人尊嚴被侵犯等情況,如果數據是被平台或廠商控制,那麼我們基本上沒有太多自主空間,只能依賴對方的道德血液,或者監管部門的公允專業。從用戶角度看,個人數據的控制權要盡可能多地從平台企業回到用戶這。只要只有用戶對自己的數據有控制權,他才有底氣說我能夠維護好自己的數字尊嚴。基於這個理念,我設計瞭如下的數字身份體系和數據帳戶體系,他能夠較好的保護用戶的數字權益,同時能夠兼容web2.0 和3.0。
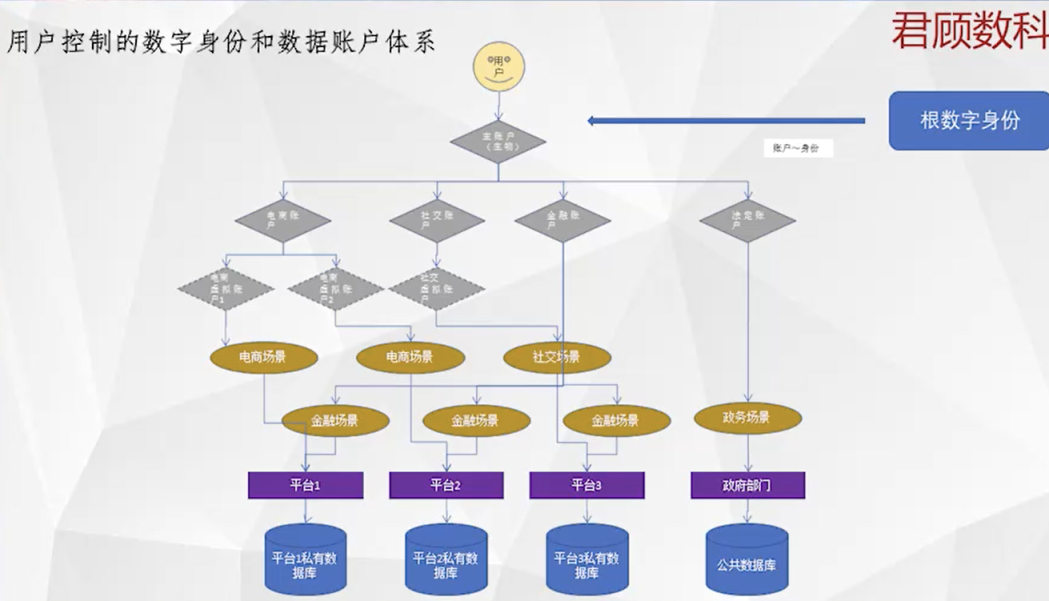
用戶控制的數字身份和數據賬戶體系
從上往下看,最上面是用戶,用戶下有一個主賬戶,主賬戶是由用戶的生物信息來控制的,比如虹膜、指紋、聲波紋、行為特徵等等。主賬戶下分別是子賬戶和孫子賬戶,一個主賬戶可以控制若干個子賬戶,一個子賬戶可以控制若干個孫子賬戶。這裡的控制是單向的,即主賬戶可以推導出多個子賬戶,子賬戶可以推導出多個孫子賬戶,但你不可能從某一個孫子賬戶推導出它屬於哪個子賬戶,更不可能推導出他的根賬戶身份。
為什麼要有這麼多賬戶呢?因為用戶的需求是多元的,每種需求所需的個人信息也存在較大差別,因此需要用不同的賬戶來適用於不同的需求場景。我的建議是用戶按照需求的目的、時間、空間進行切分,形成多級多類賬戶。比如說我按照我的目的把數字賬戶定義成多個子賬戶,包括出行專用的子賬戶、電商專用的子賬戶、社交專用的子賬戶、資訊閱讀專用的子賬戶等等,每個子賬戶上都存儲有此類需求所需的個人信息,比如電商子賬戶裡存有我的收貨地址和手機號,出行子賬戶存有我的公司和家里地址等。
子賬戶之下,是各級孫子帳戶,孫子賬戶可以根據平台和時間進行切分。以電商為例,可能很多人既用京東,也用淘寶、拼多多。那麼就可以在電商子賬戶下建立京東電商孫子帳戶、淘寶電商孫子帳戶、拼多多電商孫子帳戶,這三個孫子帳戶共享電商子賬戶上的個人信息,即收貨地址和手機號,當在京東購物時,就使用京東電商孫子帳戶,以此類推,這是在空間(不同平台)上的切分。孫子帳戶下還可以建立玄孫帳戶,我建議可以在時間上進行切分,比如=可以把我今年在京東上的賬戶獨立為一個玄孫賬戶,到明年又新建一個玄孫賬戶來使用,這兩個玄孫帳戶都由京東電商孫子帳戶來衍生和控制。
這樣相對於每一個具體的賬戶,都有特定適用的時間、空間、平台、場景,都是非常聚焦的,因此其使用期限能夠非常短。這樣即便某個孫子帳戶的個人數據被不合理的收集,那麼他也只能收集用戶很小一段個人信息,且一旦被用戶發現,用戶能迅速作廢這個帳戶,同時新建新的帳戶參與對應的場景,同時平台企業要想對不同帳戶進行關聯和計算,難度會比以前大很多,在用戶不授權的情況下,平台很難單方面對用戶進行畫像。對用戶而言,帳戶雖多,但都是分層的,上層衍生和控制下層帳戶,最上層的是根賬戶,能夠控制所有帳戶,用戶只需要管理好這個根帳戶,能夠用多個子賬戶、和孫子帳戶進入數字世界,具體使用哪個身份,完全由用戶自己說了算,用戶甚至可以用一個身份瀏覽商品,用另一個身份下單。這樣的數字身份體系,除了用戶控制,用戶說了算,用戶還能夠通過《個人信息保護法》等相關法律,把用戶之前在平台上積累的數據拷貝或者遷移到自己所控制的賬戶上,形成真正屬於自己或被自己掌控的數字身份和數據賬戶體系。
上述設計的關鍵在於根賬戶由誰來建立、誰來運營、誰來管理。大概分兩種情況:第一種,用戶為自己建立和自主管理,這是很多Web3.0 項目的做法,此次的主題是數字身份,有很多專門的介紹,在此我不再贅述。第二種,在Web2.0 的邏輯之上,由一個獨立公允客觀的第三方為大家建立。這裡需要說一下我們的鄰居印度,印度為13 億居民建立了一個叫Aadhaar 的帳戶體系,並基於該帳戶體系,做了很多上層應用,比如他們的賬戶聚合平台,是一個為個人集中管理自己金融數據的平台。該平台由印度央行監管的一個非營利的機構運營,把居民分散在多個金融機構中本人的金融數據進行統一的管理。用戶在賬戶聚合平台上可以查看和管理他在多家機構上的所有金融數據。這裡的管理包括知曉、提出反對意見和對外協同等。這裡的協同是指,如果有哪家企業需要我的金融數據,他可以在賬戶聚合平台上向我提出申請,我同意之後,它就能獲得我在多家金融機構上的金融數據。這種做法充分尊重用戶的數據權益和隱私,對有數據需求企業而言,帳戶聚合平台是他們非常好的數據協同窗口和方式。
值得注意的是,上述數字身份和數據帳戶體系的設計中,根賬戶只有一個,且只被用戶自身所掌控,我們平時用的比較多的法定身份,或者法定數字身份,是其中一個特殊的子賬戶。另外我們也可以建立能夠在若干家企業、若干個平台中通用的聯盟性質的數字子帳戶,當然也可以是只在某家企業、某個APP 上使用的場景化數字子帳戶。即用戶可以根據其需要,以子賬戶或孫子帳戶的方式來自主建立和使用數字身份,這裡的重點是用戶自主可控,且都歸用戶的根賬戶所管理和控制。這是我提出的、更多由用戶而非他人來控制的數字身份和數字賬戶的體系,供大家參考。
這裡同樣存在公平、效率、風險權衡的問題。在Web2.0 時代,效率是很高的,但是效率是單個企業的效率,如果把範圍擴展到多個企業、整個市場的話,效率並不高,因為數據的協同非常低效。公平而言,見仁見智,我個人覺得在Web2.0 時代有很多對用戶不夠尊重,沒經用戶允許就收集用戶隱私的行為,這對用戶的尊嚴而言毫無疑問是挑戰,自然也談不上公平。風險而言,由於底層數據有很多來路不正,自然潛藏著很多爭議和風險。
在上述用戶自主管控的數字身份和個人賬戶假定能實行的話,風險會比較低,公平也能保障的比較好。風險之所以低,是因為數據是分佈式的,不至於一個人的數據洩露會導致很多人的數據洩露,不存在全員性和系統性風險。公平的話,由於都是你自己來管理,對外授權肯定也是自己授權的,自己說的話要算數,不應該的授權自己也需要為此承擔責任,因此基本就不存在不公平的情況。三者中欠缺的是效率,因為每個人的數字化素養千差萬別,更多人的數字化素養都是相對低的,因此效率的提示有賴於非常多的數據專業機構、中介機構,為用戶、為市場提供公允和專業的數據服務,才能有效地提升效率。
對於當前仍然處於Web2.0 時代的很多用戶而言,我個人建議多考慮使用加密算法來有效提升和改進自己的數據權益。比如說對於涉及較多個人數據管理的服務,盡可能從公有服務轉為私有服務。比如大家很多數據都存在網盤上,存在數據丟失或罰沒的情況,這裡建議有專業性、有財力的居民可以考慮建立個人的NAS 存儲系統。還有一些將自己的密碼託管在「別人家」的,也可以考慮把自己的密碼置於自己的管控範圍內,通過個人密碼管理器來實現。
對於一個中心節點向多人提供服務的情景,用戶應盡可能選擇用戶掌控密鑰、或用戶自主加密的技術,這裡的自主加密是指獨立於廠商之外的用戶自主加密。比如說郵件發送,你發送給對方的現在是明文,未來可以是密文,密文是由用戶自己的密鑰來加密的,郵件發出之後別人收到的是密文,但可以用發送方,也就是用戶的公鑰來解密,當然還有簽名等過程,這樣可以有效地杜絕未經授權的人來獲取到你的郵件和相關情況,因為過去的確發生過郵件服務提供方通過讀取用戶的郵件來獲得商業秘密的情況,且被美國法院判罰。再比如社交聊天中,我發送的是未經用戶自主加密的明文文本,對方接受的也是這個。我相信聊天軟件運營方在中間是有加密、解密的過程,但這不是用戶自主的。用戶自主是什麼呢?用戶發送給對方的是用用戶私鑰加密之後的文本,接受方接受之後,由於是用戶信任的對方,因此可以獲得用戶的許可,對密文進行解密,從而閱讀到明文,中間不會有任何第三方,包括聊天服務提供方,獲得二者之間的聊天內容。這樣能夠確保兩人之間的通訊只有這兩個人才知道。國外已經有類似的項目出現,並且在主流社交媒體上也有很多的用戶了。但國內相對來比較少,這也反映了國內的理念和生態,跟國外還是存在一些差距的。
以上是今天我給大家帶來的分享。關於數字時代的發展趨勢,美好數字生活的判斷標準,當前的現狀以及未來如何有尊嚴地在數字世界裡的看法,並提出瞭如何通過用戶管控的數字身份和數字賬戶體系,以更好地維護用戶權益。不成熟看法,歡迎一起交流和探討。
我的分享到這兒,謝謝大家!
圓桌討論:《區塊鏈安全及隱私》
Blue,慢霧首席技術官
郭宇,安比實驗室創始人兼首席執行官
Emre Tekisalp,O(1) Labs 首席執行官
Harry Halpin,Nym Technologies 首席執行官
Blue(主持人):今天圓桌的主題就是「區塊鏈數據安全與隱私」,話不多說,直接開始。
先請各位圓桌嘉賓簡單介紹一下自己和您所在的團隊,請Harry 先介紹。
Harry Halpin:大家好我是Harry Halpin,我是Nym Technologies 的首席執行官,也是聯合創始人。 Nym Technologies 是一個隱私的混合網絡0 層解決方案,有點像去中心化的VPN。今年年初的時候在Coinlist 上做了區別中心化募資,同時也得到了Banners、(音)ASE(音)的投資支持,今天非常高興能夠和各位參與到圓桌論壇。
2019 年的時候我自己也來過上海,所以今天也覺得特別高興。
Blue(主持人):請Emre 跟我們介紹一下你自己。
Emre Tekisalp:我的名字是Emre,我是O(1) Labs 的首席執行官,具體做的是基於零知識證明的技術和區塊鏈。孵化了Mina(音)協議,這是大概在2021 年之前所上線的一層協議,現在正在上面部署零知識證明應用,從而延續開發者後續可以開發通用型智能合約。現在也有名為Snark GS(音)的新SDK,從而允許開發者可以基於零知識證明來寫TypeScript 類的應用程序。
Blue(主持人):請郭宇介紹一下您自己。
郭宇:大家好!我的名字是郭宇,我是安比實驗室創始人兼首席執行官。安比實驗室專注於智能合約和零知識證明,同時也幫助其他團隊構建去中心化的工具庫和應用。現在也在開發使用零知識證明進行數據公平交換的去中心化協議。
Blue(主持人):我也介紹一下我自己,我是慢霧的CTO,我的名字叫Blue。慢霧是由擁有十年以上的網絡安全經驗團隊創立的,目標就是讓區塊鏈系統盡可能地安全。
現在正式開始圓桌討論吧,先問第一個問題,有一些區塊鏈將隱私作為一種可選的功能,比如說在以太坊上看到AS Cash(音)項目就是將隱私作為可選功能。也有一些區塊鏈,比如說像Z-cash 將隱私作為默認的功能。但是區塊鏈真的是隱私的嗎?請各位回答這個問題,請Harry 先回答。
Harry Halpin:我快速回答一下這個問題,我的觀點是隱私代表的是整個系統的總體屬性,很多人對於零知識證明非常感興趣,尤其是將零知識證明應用在以太坊的擴容方面,他們認為零知識證明可以提供鏈上隱私,也就是說在區塊鏈上的數據就可以保證隱私性。比如說,Tor node cache(音)最近剛剛關閉的mixer,也是他們的混合池匿名池,做的就是這一點。但事實上,當你和區塊鏈系統進行通信的時候,你會用到點對點的廣告,也就是說你的交易時間,你的IP 地址,至少可以把你定位到一個城市。如果說沒有辦法定位到你具體所在小區的話,可以把你定位到城市,這些信息都是公開的。
雖然零知識證明取得了很多進展,但是它們還不夠,需要其他的技術。比如說在底層需要混合網絡、匿名池,各種洋蔥路由,以及更高層的隱私增強智能合約技術,才能真正實現在區塊鍊和Web3 上的隱私性。
Emre Tekisalp:不管在區塊鏈上做的隱私是什麼,這些隱私往往只和Token 本身的轉移有關,我也並不覺得這件事情令人驚奇,因為大部分Web3 還是和Token 交易、NFT 交易有關,還沒有做交易投資之外的應用程序。原因也很簡單,零知識證明技術本身就很難,現在看到很多零知識證明的項目都還在研發之中。另外一個更重要的原因是如果你看一下AS Cash(音),或者是其他基於以太坊的二層項目,有一些聲稱自己能夠做到隱私保護,但實際上這樣的說法並不完全屬實,因為數據會被發送到零知識證明的計算中心,或者是某個雲廠商,由他們代表用戶生成證明。這是因為本身零知識證明從計算上對算力的要求高,而且計算非常昂貴,所以對於用戶來說,需要降低零知識證明計算的成本,從而使得它能夠適配普通的用戶設備,這點非常重要,也正是在O(1) Labs 上正在開發的業務。
現在已經幾乎準備好上線了,我們的技術允許普通用戶在自己的個人筆記本電腦、智能手機上生成用於通用性計算的ZK 證明。不管是做任何類型的數據證明,不管是計算還是提供證明本身,都允許用戶在自己的設備端生成,然後將相應的證明發送到區塊鏈,這樣區塊鏈接收到了證明,但是卻沒有辦法判斷,或者沒有辦法探查到用戶設備側到底進行了怎樣的及鑽。
郭宇:我覺得不管是Z-cash 還是以太坊的其他加密,比如說AS Cash(音)或者Tornado Cash,這些都還沒有辦法做到完全隱私。因為我覺得,在一定程度上區塊鏈賬戶本身並不是默認隱私保護的,也就是說對於用戶來說,最開始大家有的只是一個普通的賬戶,之後可能變成了某種程度的隱私保護賬戶。也就是說,隱私的超過取決於匿名級的大小。就我的角度來看,我不認為很多人會願意進入到匿名池。也就是說,匿名池不會足夠大,也就導致了隱私保護程度相對來說比較弱,這也是為什麼Tornado Cash 這樣的項目需要推出一些激勵措施,鼓勵更多人將自己的資產存入到匿名池、混合網絡之中。但是通過激勵來做隱私保護,其實並不是那麼容易實現的,尤其是在隱私保護方面。
所以我認為,主要的挑戰是要如何擴大匿名池的大小,從而幫助那些真正關心關注隱私的人。這就是我的看法。
Blue(主持人):接下來一個問題有關於安全,哪怕說區塊鏈本身是安全的,但是在底層區塊鏈依賴於互聯網,所以我們怎麼知道你的互聯網連接是不是安全的呢?請Harry Halpin 先回答。
Harry Halpin:我的答案是對於最終的用戶來說,幾乎不可能知道你的互聯網連接是否安全,所以作為隱私方面的專家,作為隱私技術方面的公司,Web3 的初創企業,我們做的一件事情是需要同時確保區塊鏈更加安全,有各種各樣的共識算法、零知識證明、加密學,比如說像Nym 用的混合網絡將數據包混合,並且偽裝,從而無法判斷誰將數據包發送給了誰。
但另外一方面,我們也需要為用戶提供一些他們可以識別、可以理解的信號,比如說一個紅色的按鈕變成了綠色按鈕,這就是我們在幾週之前推出的功能。通過這樣的方式,用戶至少可以通過查看信號去判斷連接到區塊鏈互聯網連接是否是安全的。目前不管是MetaMask 還是Infura 還是其他的基礎設施,都沒有這樣的功能。
Emre Tekisalp:剛剛Harry 所介紹的這種技術,我覺得非常重要,我也想要就這個問題再提另外一個維度的信息,也就是用戶可以在自己的設備上連接區塊鏈。靈活度越高,他們能夠獲得的隱私保證就越強。其中一部分在你的設備上運行全節點,不管是在Tornado Cash,還是一些更早期的項目,大家都是通過錢包來連接這些應用程序,而這些錢包也連接到其他的全節點。也就是說,錢包有很多有關於用戶的信息,因為您將信息發送給了這些錢包,但同時錢包也能夠判斷感知到你對於各種應用程序的訪問,可以感知到交易全節點的情況,這是我們都希望看到的。
由於非常昂貴,所以很多用戶很難在自己的設備上運行全節點的,這也是我們通過Mina 協議希望為用戶提供的,因為Mina 的核心前提是所謂的同步區塊鏈,整個區塊鏈能夠始終保持固定大小的零知識證明,能夠提供證明,這個證明的大小是固定的,而且足夠小。從而使得普通用戶哪怕使用普通的智能手機或者電腦,就可以下載幾GB 的數據,你可以自己驗證我發給區塊鏈的實例是真實的,沒有被任何篡改,沒有被攻擊,我也可以嘗試發送一筆交易,通過我之前的確認可以信任交易、賬戶餘額等其他信息,通過這樣的方式更好地實現隱私。
郭宇:這是一個非常好的問題,我認為整個互聯網的基礎設施是不安全的,先回顧歷史,我認為ICP 協議初始的設計思想,很多協議都沒有考慮到安全性,也就是說它們並不是所謂的拜占庭容錯的。假設99% 的用戶都是好人,但是我們今天面臨各種各樣的垃圾郵件,也面臨各種各樣的攻擊,比如說像日食攻擊,還有一些其他DNS 的服務器,可能也會成為攻擊點。所以我認為,要從頭開始重建互聯網協議,或者說形成以區塊鍊為中心的新型互聯網。從這個角度來說,需要的時間比我們預期的要長。
我還擔心另外一件事情,最近我手機的瀏覽器一直在提醒我,我希望訪問的某些網站是有風險的,但是我對於網站是否有風險一無所知,我也不確定網站是不是真的有風險,還是說只是因為本身瀏覽器的原因就是要發風險提示。對我來說,我真正訪問這個網站之前,需要進行大量研究、大量調研。
這個問題非常好,區塊鏈更下層的互聯網連接並不是那麼安全,這也是我非常擔心的一點。
Blue(主持人):接下來的問題問Emre ,ZK 技術是被視為以太坊可擴展性的主要挑戰者,所以我想請問ZK cash(音)到底有什麼用?對Web3 以及科技世界有多麼重要?
Emre Tekisalp:這是一個很基礎的技術,有很多使用場景,其中有一些我們還沒有解鎖。如果我們後退一步,思考一下對於用戶來說ZK 技術零知識證明到底是什麼呢?它實際上屬於密碼學的分支,允許你證明計算結果的有效性,所以對於很多其他類型加密。比如說公私鑰加密,對於這樣類型的加密學,當你簽署簽名的時候,基本就能證明數據的所有權。
但是在零知識證明中,你可以證明計算已經正確完成,但是你卻沒有必要披露到底誰發送了信息,計算的輸入值到底是什麼。因此零知識證明提供的是一種全新的能力,所有的計算都是由中心化設備在雲上完成的。對於這樣的世界來說,零知識證明技術變得更加重要,這也是為什麼零知識證明技術和我之前提到的Web2 世界能夠有挑戰的力量,同時對於區塊鏈來說也非常重要,因為它能夠讓所有權回歸給用戶。
您剛剛也提到了,圍繞著ZK 零知識證明技術有很多探討,將其稱為可擴展性的挑戰者,但是細節我就不多加贅述。本質上,ZK 技術就是為區塊鏈提供更多的吞吐量,而不需要犧牲去中心化。除此之外,隱私,尤其是數據隱私是另外一個非常重要的領域,我在這個領域已經有很長的工作時間了,所以我們總是看到各種各樣的新發明,認為可以解決各種各樣的挑戰,從而使得數億用戶使用加密技術,不僅僅只是將它用來作為資產的交易。
可擴展性是下一件亟待解決的事情,現在是否有可擴展性呢?在一定程度上有,因為很多區塊鏈的TPS 不斷提升,但是我們又面臨著另外一個區塊鏈廣泛採用的問題。對用戶數據進行隱私處理將會是下一個巨大的推動力量。因為如果你想要看一下各種各樣的DeFi、SocialFi、NFT 等等,目前你要參與這些應用的話,必須要有大量的資金投入,必須要購買NFT,或者說必須要購買NFT 從而加入某個DAO 組織,意味著先期必須要有幾萬美元的投入,這就變成了大型機構或者富有科技界人士的「玩具」,但是我們需要有更普通的應用程序,可以讓普通人所使用。
比如說在普通的世界中,程序允許普通人申請貸款,不需要抵押,或者在提供擔保比較低的情況下就可以獲得貸款。用戶也應該使用這樣的應用程序,證明他們屬於某個群體。比如說是某個國家的公民,屬於某個公司,或者在某家大學上學等等。這些應用當前都是不可為我們所訪問的,因為大家不敢把這樣的信息放在區塊鏈上,一旦放在區塊鏈上,它就會永遠公開,任何人都可以看到,就像是你今天自己不會去分享你的地址一樣。大家通過在區塊鏈上查看,可以看到你之前的交易、之前的轉賬,對有些人來說這樣的信息是可以公開的,但是很多有價值的現實生活信息不會願意放在區塊鏈上,比如說個人的信用評分,自己的工作薪水是多少,畢業於哪所學校等等。
為了讓普通用戶獲得更多有用的應用,也需要這樣的信息能夠被放在鏈上,這也是為什麼隱私對於用戶的大規模採用非常重要。我們認為零知識證明使得我們可以將這些類型的信息、數據、技術、計算上鍊的核心技術。這樣就可以擁有通用的Web3 應用程序,你的父母、你的朋友,他們雖然對於加密技術不關心,但是他們也可以使用這樣的應用程序,因為其中有很多創新,有一些更公平的方式。所以我覺得隱私確實對行業非常重要。
Blue(主持人):非常感謝Emre ,接下來一個問題想問Harry ,區塊鏈技術如何幫助互聯網傳統公司變得更加安全呢?
Harry Halpin:我想就Emre 剛剛介紹的再補充幾點,我們有全新的基礎技術,這些技術非常棒,有很多Web3 應用。但反觀一下,過去幾年在區塊鏈技術正式起飛之前,在互聯網世界到底發生了什麼?有斯諾登事件,斯諾登事件告訴我們美國政府對於互聯網交易中的大部分業務會進行監視,並且對相關的數據進行記錄,記錄互聯網數據成本非常低。同時也可以利用機器學習、人工智能對這些數據進行分析,這是美國政府對於公民個人自由的侵犯,很多人對於美國政府的做法不滿。
現在除了政府之外,對於小型參與者來說,對互聯網流量進行大規模監控也變得更加容易。這個問題不僅僅影響到了Web3,同時也影響到了在互聯網上所有參與者,影響到了傳統政府。比如說Nym 項目得到了歐委會的支持,當前也聘請了厄瓜多爾前銀行行長,他主要致力於隱私保護的CBDC。另外這也影響到了整個世界,影響到了像蘋果、Google 那些傳統公司,現在這些公司希望能夠增強隱私。至少對於Google 來說,因為他們的商業模式進行大規模網絡活動的監控,同時也依賴於廣告,所以Google 是存在隱私問題的。
在傳統的矽谷互聯網世界裡,很少有人對於這一點投入研究。對於政府來說,更多是利用這項技術。所以,坦率說,Web3 將會產生隱私技術,不僅僅能夠為用戶使用,同時也能為政府、企業、機構所使用,將通過標準組織,比如說像互聯網工程任務組一道構建互聯網協議的基礎,我們也在中間做了貢獻,就是混合數據包格式。
Blue(主持人):謝謝Harry,最後一個問題想問郭宇。 Web3 旨在保護用戶的數據,但是數據經常在鏈下存儲的,主要是因為鏈上存儲的成本非常高。所以想請問,有沒有比較好的方法,在保護隱私的同時,能夠向區塊鏈發送數據?
郭宇:一般來說,需要有兩個關鍵的工具,一個是所謂的鏈上數據Ankr 數據錨,另外一個就是高效的ZK 證明,對於鏈下數據能夠進行驗證和證明,鏈上數據「錨」可以是一段數據的SHA-256 哈希,也可以是加密承諾。比如說KZG10 承諾。但是對於一個巨大的數據文件,或者是數據庫、數據集而言,也許我們需要帶有知識證明的MerkleTree 或者是更加高級的Verkle Tree,這個數據錨必須要足夠小,這樣的話你就可以實現低成本的上鍊。另一方面,它必須要和原始數據綁定,綁定的意思就是說如果鏈下原始數據更新,鏈上項目的承諾也會發生變更。但是鏈上的承諾,鏈上的數據錨也應當要隱藏原始數據的相關信息。
另外一個技術就是zkSNARK,zkSNARK 可以保證鏈上Ankr 數據錨的安全性、可靠性。另外,zkSNARK 也可以使用鏈下的數據,以保護隱私的方式來使用。我現在在這裡談到的是通用型的框架,可以將大量數據錨放在鏈上,而我們可以在鏈下進行數據的處理和數據的操作。這樣一來,不管鏈下的數據有多大,我們都可以做到。
然而要實現這一點,毋庸置疑還面臨許多挑戰。
第一大挑戰,鏈下數據經常變化更新,所以我們必須要發明一些全新的東西,用全新的技術,實現對於鏈上數據錨的低成本更新,從而保證數據錨和鏈下數據之間能夠始終同步更新。我們必須要找到新的零知識證明技術,來處理大量數據,在很短的時間裡就要完成對數據的處理。同時,也要保證數據同步性,也就是說鏈下數據幾乎是每分鐘、每一天都要更新,鏈上也應該做到同步。
當前,安比實驗室最近正在著手解決的問題是如何為鏈下大量數據生成證明,比如說當提高大量數據的時候,需要具有豐富結構的數據,比如說多張數據表,而且這些數據表彼此是有聯繫的。所以,我們必須要使用統計學、query 查詢函數來處理這些數據,將這些數據放在一起,可能涉及到數學的運算。比如說加減乘除,同時也要把它做成列表,或者是其他的。
去年發現了新的ZK 證明生成方法,專門處理大塊數據。我說的大塊數據就是幾GB 的數據,新的ZK 證明方法專門用於處理並行數據。而且數據的處理也可以分層,這就是在數據處理方面的通用型模型。比如說像MapReduce 這樣的模型,我認為大多數數據處理都可以分類成MapReduce 模型,或者說MapReduce 之後再進一步變成MapReduce。去年我們也做了一個demo,可以快速查詢具有數百萬條數據記錄的數據表,生成證明的速度非常快。同樣,也可以用深度神經網絡實現數據的處理,比如說可以在短短幾小時之內為VGG16 卷積神經網絡的面部識別生成證明。
ZK 證明電路可以有幾十億乘法門,當前我們正在做的就是持續不斷優化整個框架。也引入了很多新的加密工具,主要是以太坊基金會研發出來的,從而改變最底層的。換句話說,用新的加密承諾來取代舊的加密承諾,而且在這方面實現了不斷的優化,大量的提升。
總結來說,可以使用新的零知識證明工具,可以藉助一些智能合約,輕鬆地證明歷史數據。比如說以太坊的區塊數據,證明在以太坊上一些歷史的記錄,證明人的身份,他們的資產,他們的資產持有情況等等。
總結來說,未來將會和現在大不相同,我們會有一些新的技術、新的方案、新的協議,從社區開發而來。我覺得未來令人興奮。
Blue(主持人):感謝郭宇,這就是今天圓桌論壇要討論的所有問題,感謝所有圓桌嘉賓。
主持人:感謝幾位嘉賓精彩的討論和分享,謝謝。
今天,我們從各位嘉賓的分享中,了解到了多個區塊鏈隱私安全和數據治理的解決方案,積土成山,只有打牢了安全的「地基」,才能築起結實的未來。再次感謝各位嘉賓帶來的精彩觀點,謝謝。
各位觀眾,第八屆區塊鏈全球峰會——積「土」成山主題論壇的日程到這就結束了,感謝各位的聆聽和陪伴。
明天14:00,我們將在我們的母星——地球,邀請多位行業專家,一起探討物聯網等數字化技術如何賦能碳中和,助力打造綠色可持續的生存家園。
也再次提醒大家,觀看第八屆區塊鏈全球峰會,參與互動活動,將有機會獲得主辦方萬向區塊鏈實驗室準備的大疆無人機、米家投影儀、Switch 健身套裝、峰會定制限量版NFT 等豐厚禮品。點擊直播間下方的「直播福利」,即可查看獲取獎品的詳細規則。
請大家持續關注第八屆區塊鏈全球峰會,期待明天14:00,再次與大家相會在直播間裡。謝謝!








 APP
APP 

