




作者:Keone Hon,Monad 共同創辦人
編譯:Azuma,Odaily 星球日報
編按:北京時間3 月26 日上午,Monad 聯合創始人Keone Hon 於個人X 發布了一篇關於Rollup 效能狀況的深度長文。文中,Keone 詳述了坎昆升級之後Rollup 的理論TPS 上限該如何計算,並解釋了為何升級之後部分Layer2(Base)的單筆交易費用仍高達數美元,此外Keone 還概述了Rollup 所面臨的一些瓶頸限制以及潛在的改善方向。
以下為Keone 的原文內容,由Odaily 星球日報編譯,為了方便讀者閱讀,譯者在原文基礎上做了一定補充。
最近市場上有一些關於Rollup 執行瓶頸和Gas 限制的討論,不僅涉及Layer1,還包括了Layer2。我將在下文中討論這些瓶頸問題。
數據可用性(DA)
隨著Blob 資料結構(EIP-4844)在坎昆升級中被引入,以太坊的資料可用性(DA)已得到了大幅改進,Layer2 的資料同步交易已無需再與普通Layer1 交易在同一個費用市場中競價。
目前,Blob 的容量狀況大概是每個區塊(12秒)產出3 個125kb的Blob,即每秒31.25kb,鑑於一筆交易的大小大概是100字節,這意味著所有Rollup 的共享TPS大概是300 左右。
當然了,這裡有一些資訊需要特別備註。
- 一是如果Rollup 採用了更好的交易資料壓縮技術,可縮減單筆交易大小的話,TPS 便可實現成長。
- 二是理論上Rollup 除了可以採用Blob 同步資料之外,還可以繼續採用calldata 同步資料(即坎昆升級之前的舊方案),儘管這樣做會帶來額外的複雜性。
- 三是不同ZK-rollup發布狀態的方式有差異(尤其是zkSync Era和Starknet),因此對於這些Rollup來說,計算方式及結果也會有所不同。
Rollup的gas限制
最近,Base 由於其gas費用的激增而引發了較大關注,一筆普通的交易在該網路上的費用已上漲了幾美元。
為什麼坎昆升級之後,Base 網路只降低了一段時間,現在又回到甚至超過了升級之前的水準?這是因為Base上的區塊存在一個gas 總額限制,該限制係透過其程式碼中的一個參數來執行。
Base目前所採用的gas 參數與Optimism相同,即每個Layer2 區塊(2 秒)存在500萬gas 的總額限制,當該網路之上的需求(交易總數)超過供應(區塊空間)之時,價格結算便會採取按需執行的機制,從而導致該網路gas 的飆升。
為什麼Base 不去提高這項gas 總額限制呢?或者換句話說,為什麼Rollup 需要設定一個gas 總額限制呢?
除了前文提到的數據可用性存在TPS 上限之外,這裡其實還有另外兩大原因,分別是執行吞吐量的瓶頸以及狀態增長的隱患。
問題一:執行吞吐量的瓶頸
一般而言,EVM Rollup 運行的都是一個fork 自Geth 的EVM,這意味著它們與Geth 用戶端有著相似的效能特徵。
Geth 的客戶端是單一執行緒的(即一次只能處理一個任務),它使用了LevelDB/PebbleDB 編碼,在merkle patricia trie(MPT)中儲存其狀態。這是一種通用資料庫,使用另一種樹狀結構(LSM 樹)作為底層在固態硬碟(SSD)上儲存資料。
對Rollup 而言,「狀態存取」(從merkle trie 讀取數值)和「狀態更新」(在每個區塊結束時更新merkle trie)是執行過程中成本最高的環節。之所以如此,是因為從固態硬碟上單次讀取的成本是40-100 微秒,並且由於merkle trie 資料結構被嵌入到另一個資料結構(LSM 樹)中,導致需要進行許多非必要的額外查找。
這個環節可以想像為在一個複雜的檔案系統中尋找特定檔案的過程。你需要從根目錄(trie 根節點)一直找到目標檔(葉節點)。在尋找每個檔案時,都需要尋找資料庫LevelDB 中的特定鍵,而在LevelDB 內部又必須透過另一個名為LSM 樹的資料結構來執行實際的資料儲存操作,這樣的過程造成了許多額外的查找步驟。這些額外的步驟讓整個資料讀取和更新變得相當慢且低效。
在Monad 的設計中,我們透過MonadDb 解決了這個問題。 MonadDb 是一個自訂資料庫,支援直接在磁碟上儲存merkle trie,避免了LevelDb 的開銷;支援非同步IO,允許多個讀取並行處理;繞過了檔案系統。
此外,Monad 採用的「樂觀並行執行」(optimistic parallel execution)機制允許多筆交易並行進行,且能夠從MonadDb 中並行地提取其狀態。
然而,Rollup 沒有這些最佳化,因此在執行吞吐量上存在瓶頸。
需要註明的是,Erigon/Reth 用戶端對於資料庫的效率有過一定優化,而有些Rollup 的客戶端也是基於這些客戶端建構的(例如OP-Reth)。 Erigon/Reth使用了一種扁平的資料結構,這在一定程度上減少了讀取時的查詢成本;然而,它們並不支援非同步讀取或多執行緒處理。此外,每個區塊之後都需要重新計算merkle root,這也是一個相當緩慢的過程。
問題二:狀態增長的隱患
與其他區塊鏈一樣,Rollup 也會限制它們的吞吐量,以防止其活動狀態成長過快。
市場上存在的一個常見論點是,狀態成長速度之所以令人擔憂,是因為如果狀態資料大幅成長,對固態硬碟(SSD)的裝置需求也將不得不上調。然而,我認為這有點不準確,SSD 相對便宜(一個高品質的2TB SSD 大約也就200 美元),而在近10 年的歷史中,以太坊的全狀態「僅」有大約200 GB。單純從儲存角度來看,仍有很大的成長空間。
更大的隱患其實在於,隨著狀態持續成長,查詢指定狀態片段的時間會變得更長。這是因為當前merkle patricia trie 會在滿足「節點只有一個子節點」的條件時使用「快捷方式」,這可減少trie 的有效深度,從而加速查詢過程,可如果merkle trie 的狀態越來越滿,可用的「快捷方式」也就會越來越少。
綜合而言,狀態增長的隱患歸根結底其實就是狀態存取效率的問題,因此加速狀態存取是使狀態增長更具可持續性的關鍵。
為什麼僅僅優化硬體並沒有用?
Layer2 目前仍處於相對中心化的狀態,即網路仍依賴單一的排序器來維護狀態並產出區塊。有人可能會問,那為什麼不讓排序器運行在具備極高RAM(隨機存取記憶體)的硬體上,以便讓所有狀態都能儲存於記憶體呢?
這也有兩個原因。
其一,這並不會解決以太坊主網所存在的數據可用性瓶頸問題,儘管就目前Base 的情況來看,該網絡gas 的飆升並不是因為主網數據可用性能力不足而導致,但從長遠來看這終將會成為限制Rollup 的一大瓶頸。
其二則是去中心化的問題,儘管排序器仍處於高度中心化狀況,但參與網路運作的其他角色也很重要,他們也需要能獨立運行節點,重播相同的交易歷史並維護相同的狀態。
Layer1 之上的原始交易資料和狀態提交並不足以解開完整的狀態。任何對完整狀態有存取需求的角色(例如商家、交易所或自動交易者)都應該運行一個完整的Layer2 節點來處理交易,並擁有一個最新的狀態副本。
Rollups 仍屬於區塊鏈,而區塊鏈之所以有趣,是因為它們能夠透過共享的全球狀態實現全球協調。對所有區塊鏈而言,性能強大的軟體是必要的,僅僅優化硬體並不足以解決問題。
社群互動
在Keone 發布此文後,多個頭部Layer2 專案的關鍵人員均在該動態下方進行了互動。
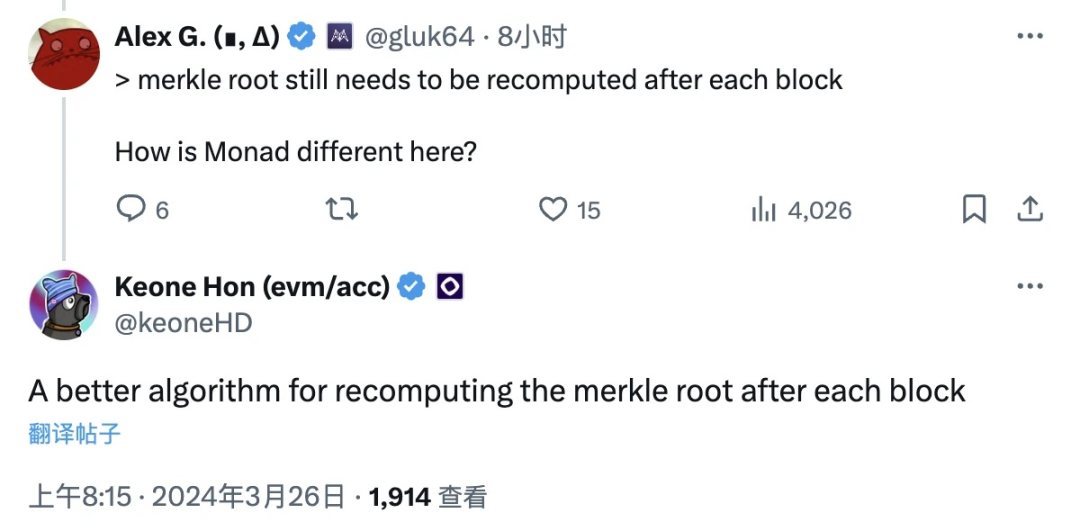
zkSync 共同創辦人Alex Gluchowski 針對文中「每個區塊之後都需要重新計算merkle root」的內容詢問Monad 在這方面有何不同?
Keone 的回覆是會有一種用於在每個區塊後計算merkle root 的最佳化演算法。
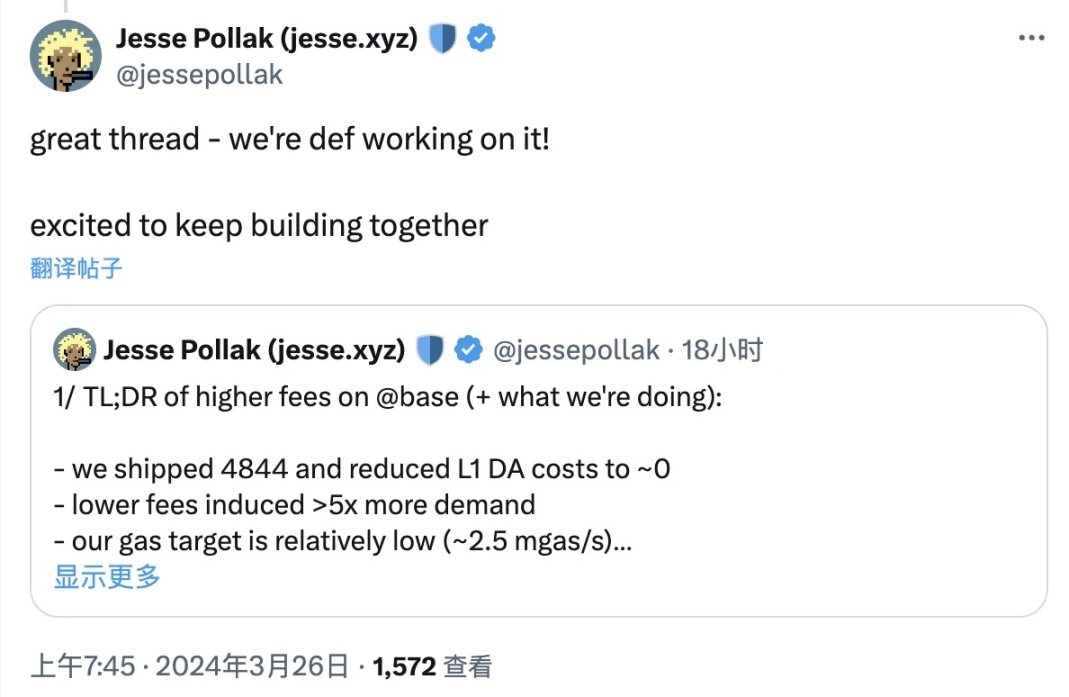
Base 負責人Jesse Pollak 也藉此解釋了為何Base 在坎昆升級之後gas 費用不降反增,其表示EIP-4844 已大幅降低了Layer1 層面的DA 成本,gas 費用本該降低,但由於網絡交易需求成長了5 倍有餘,且Base 網路之上的區塊存在250 gas/s 的限制,需求大於供給使得gas 費用出現了上漲。






 APP
APP 

