
2026年2月、小紅書は、AI生成コンテンツすべてに積極的にラベル付けすることを義務付け、ラベル付けされていないコンテンツは配信制限を受けるという発表を行った。3か月後、小紅書とWeChat公式アカウントのカバー用に3:4の画像とテキストを生成することを目的とした、 guizang-social-card-skillというオープンソースプロジェクトがGitHubに登場した。その技術的なアプローチは異例で、画像ピクセルを生成するためにAIモデルは使用せず、画像全体はHTMLとCSSを使用してレンダリングされ、画像はUnsplashなどの実世界の画像ライブラリから取得された。出力は「AI生成画像」ではなく、ブラウザエンジンによって生成されたウェブページのラスタライズされたスクリーンショットだった。
この選択は、特定の変化に対応しています。2026年以降、小紅書は、画像と音声の特徴のピクセル分布パターンを分析してAIGCコンテンツを識別する音声・映像認識モデルを導入しました。同時期に、80万を超えるAI管理アカウントと15万近くのAI生成偽ノートを処理しました。画像とテキストを頻繁に作成する必要のあるコンテンツクリエイターにとって、MidjourneyやCanva AIによって生成された画像が検出され、ラベル付けされる可能性は継続的に高まっています。Zang Shifuのスキルは別の道を選びました。レイアウトの決定をAIに任せ、最終的なピクセル値をレンダリングエンジンと実写画像ライブラリに渡すというものです。
これは意図的な技術的迂回である。しかし、このアプローチがどこまで通用するかは、プラットフォームが「AI生成合成コンテンツ」という用語をどれだけ柔軟に定義できるかにかかっている。
AIは、28個のレイアウトスケルトンの描画ではなく、レイアウトロジックを担当する。
本名がGuicangであるZang氏は、以前にもテキストと画像のレイアウトを目的としたAIツールguizang-ppt-skillをリリースしています。今回の「social-card-skill」は、より特化しており、小紅書の3:4のテキストと画像、WeChat公式アカウントの1:1と21:9のカバーを対象とし、出力解像度はそれぞれ1080×1440、1080×1080、2100×900となっています。 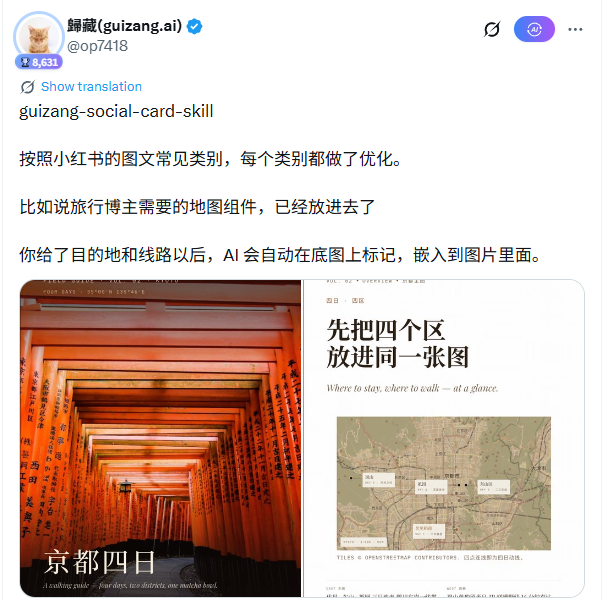
技術的なアーキテクチャに関して言えば、このスキルには28種類のレイアウトスケルトンが組み込まれており、エディトリアル(雑誌スタイル、16種類のレイアウト)とスイス(スイスインターナショナルスタイル、12種類のレイアウト)の2つのビジュアルシステムに分かれています。また、10種類のプリセットテーマカラーも用意されています。ユーザーが目的地、旅程、またはメモのテーマを入力すると、AIが適切なレイアウトスケルトンを選択し、テキストの位置を決定し、地図注釈パラメータを処理し、すべてのデザイン決定事項をHTML+CSSに書き込む役割を担います。Playwrightレンダリングエンジンが後続のステップを引き継ぎ、ページごとにPNG画像を出力します。
旅行ブロガーにとって特に便利な機能の一つが地図モジュールです。このモジュールはMapLibreを使用してOpenStreetMapから実際のタイルを読み込み、複数の位置マーカーと接続をサポートします。ユーザーは都市名や観光スポット名を入力するだけで、AIが自動的にラベル付きベースマップを生成し、レイアウトに埋め込みます。付属の画像ソースのワークフローには明確な優先順位があります。ユーザー提供の実際の写真が最優先され、ユーザー提供の画像がない場合は、Unsplash → Pexels → Flickr CC → Wallhavenの順に画像が自動的に取得されます。 
全体のプロセスは、インテーク → スタイルとテーマ → レイアウト選択 → アセット準備 → 構成とレンダリング → 納品とレビュー → 反復の 7 つのステップで実行されます。各ステップは、タスク ディレクトリ内の .poster ファイルに記録されます。画像をバッチで生成する場合、 node render.mjsが実行され、Playwright が画像を 1 つずつレンダリングします。別の検証スクリプトvalidate-social-deck.mjs実際のブラウザ環境で DOM 要素を測定し、テキストのオーバーフロー、フォント サイズが制限を超えている、フッター要素の衝突などのレイアウトの問題を検出します。
このメカニズムの設計目標は明確だ。自由だが予測不可能な拡散モデルではなく、印刷用組版ソフトウェアのように正確で制御しやすいものにすることである。その代償として、創作の自由度は28グリッドに制限される。個人的な写真スタイル、手描きの要素、あるいは不規則なコラージュに頼るクリエイターにとって、こうしたレイアウトの骨組みは効率性の向上ではなく、むしろデザイン上の制約となる。
参入障壁に関して言えば、CLI版ではPlaywrightとNode.js環境のインストールに加え、Claude CodeまたはCodexへのAPIアクセスが必要です。開発者以外のユーザー向けにxiaohongshu.guizang.aiでアクセスできるWeb版もありますが、その機能がCLI版と同一かどうかは公開されていません。Xプラットフォームの開発者による複数のツイートや頻繁に更新されるREADMEから、このプロジェクトは現在も急速なイテレーションを繰り返していることがわかります。
ピクセルは生成モデルから生成されるものではないが、コンプライアンスは長期的なセキュリティを保証するものではない。
公開されている情報と技術データに基づくと、小紅書のAIコンテンツ検出ロジックは主に音声・映像認識モデルに依存しています。このモデルは画像のピクセル分布パターンを分析し、コンテンツがAI生成モデル由来かどうかを判断します。拡散モデルやGANは、画像生成時にピクセルレベルで特定の統計的特徴を残します。これらの特徴は、カメラセンサーが捉える自然光、レンズ歪み、ノイズパターンとは異なります。音声・映像認識モデルの学習目標は、まさにこれらの統計的な不整合を捉えることにあります。
Master Zangのスキル回避ロジックは、重要な違いに基づいています。それは、出力画像のピクセルが生成モデルから生成されていないということです。HTMLレンダリングエンジンはCSSスタイルをラスタライズするため、ピクセル分布特性はブラウザのスクリーンショットやデスクトップパブリッシングソフトウェアの出力により近いものになります。写真はUnsplashなどの画像ライブラリにある実写画像から取得され、カメラで撮影後、生成モデルの痕跡を残さずに手動で後処理されています。 
しかし、この区別は、プラットフォームの「AI生成合成コンテンツ」の定義が「AIモデル生成ピクセル」の範囲内に正確に収まるかどうかに左右される。小紅書の公式発表では「AI生成合成コンテンツ」という表現が使われているが、その範囲は限定的ではない。プラットフォームが定義を「AI支援設計プログラムのレンダリング出力」に拡張したり、HTMLラスタライズ画像のブラウザレンダリング特性を認識モデルのトレーニングセットに組み込んだりすれば、このアプローチの現在の技術的優位性は失われるだろう。
このプラットフォームは、定義を拡張するための技術的基盤とガバナンス上の動機を備えています。音声・映像認識モデル自体も継続的に改良されています。HTMLレンダリング画像とAI生成画像の比較サンプルを多数トレーニングデータに含めることで、モデルは「ブラウザフォントレンダリングのサブピクセルアンチエイリアシング機能」と「GANテキスト生成における不規則なピクセルブロック」を区別できるようになります。現時点では、小紅書がこの方向でのトレーニングを開始したことを示す公開情報はありませんが、モデルの能力限界の観点から見ると、このような拡張は技術的に可能です。
より差し迫った問題は、ミニプログラムのホスティングに関するコンプライアンス要件です。現状では、このスキルがモデル登録番号を取得している、あるいは関連するコンプライアンス登録を完了していることを示す公式文書は存在しません。プラットフォームがコンテンツ審査プロセスにおいて画像生成ツールチェーンのトレーサビリティ要件を追加した場合、登録情報の欠如が新たな障害となる可能性があります。
APIテンプレートエンジン、プラットフォームカスタマイズツール、およびHTMLレンダリングは、それぞれ異なる3つの経路に分岐している。
ソーシャルメディア用の画像を生成するために市場に出回っているツールを観察すると、それらは3つの異なる技術的方向性に分岐していることがわかる。それぞれが、異なる構造のコンテンツモデレーションリスクに直面している。
AI モデルは画像を直接生成します。このアプローチは、2026 年 4 月にリリースされた Canva AI の Magic Design 機能に代表され、テキストプロンプトから AI の視覚要素を含むデザインドラフトを直接生成します。Midjourney や DALL·E などのモデルによって生成された画像もこのカテゴリに属します。問題は明らかです。これらの画像は、音声と映像の認識モデルの主要な検出対象です。Canva のアプローチは、検出を回避するのではなく、透明性のあるラベル付けを奨励することです。Xiaohongshu では、AI モデルによって生成された画像で投稿にラベルを付けると、推奨ウェイトが低下するかどうかは公開データではありませんが、「ラベル付けされていない AI コンテンツは配信を制限する」というプラットフォームの声明は確立されたポリシーです。拡散モデルが更新されるたびに、ピクセル統計的特徴が変わる可能性があり、それに応じて対応する検出モデルが反復されるため、クリエイターは常に変化するターゲットに直面していることになります。
APIテンプレートエンジンレンダリング。Bannerbearはこのアプローチの典型的な例です。ユーザーはデザイナーでテンプレートを作成し、REST APIを介してJSONデータを渡すことでレイヤー変数を変更し、サーバーがレンダリングしてPNGまたはJPGを出力します。その核心は「モデル生成ピクセル」ではなく「プロシージャルレンダリング」であり、出力にはモデル拡散の痕跡は一切含まれません。BannerbearとZangshifu Skillの違いは、Bannerbearのテンプレートは手動デザインに依存しており、レイアウト決定にAIが関与しないのに対し、Zangshifu SkillではClaudeがHTMLを直接読み書きでき、レイアウト選択はAIに委ねられている点です。Bannerbearソリューションのリスクは別の側面にあります。多数のアカウントが同じテンプレート、同じ配色、同じフォントを使用して画像やテキストを生成する場合、各画像がAI生成でなくても、プラットフォーム側で「プロシージャル大量生産」パターン認識がトリガーされます。アンチスパムルールのトリガー条件はAI検出と完全に一致するわけではありませんが、アカウントをバッチで運用するクリエイターにとっては、結果的に配信が制限されます。
プラットフォームに合わせた生成。Pin GeneratorはPinterest専用に設計されており、プラットフォームのアルゴリズムの好みに合わせてピン画像を自動的に生成します。このアプローチの核心は回避ではなく、完全な適応です。サイズ、ビジュアルスタイル、投稿スケジュールはすべてプラットフォームのガイドラインに合致しています。利点は承認リスクが最小限に抑えられることですが、欠点も明らかです。ツールの機能はプラットフォームのルールに依存しており、Pinterestがアルゴリズムを調整したり、サードパーティAPI呼び出しを制限したりすると、ツールは完全に無効になります。これをZangshifu Skillと比較してみましょう。前者はプラットフォーム固有のツールですが、後者はクロスプラットフォームソリューションです。プラットフォーム固有のツールはより安全ですが、より脆弱であり、クロスプラットフォームツールはより柔軟ですが、より複雑です。これはAIツールの分野で繰り返し見られるトレードオフです。
これら3つのアプローチのリスク構造は異なります。AI生成画像は最も自由度が高いものの、アップデートのたびに新しい検出モデルへの対応が必要となります。テンプレートエンジンは最も安定していますが、スパム対策ルールによって誤ってペナルティを受ける可能性があります。HTMLレンダリングはその中間に位置します。レイアウトはAIによって柔軟に制御され、ピクセルはブラウザと実世界の映像によって処理されます。これにより、「AI生成ピクセル」レベルでの検出は回避できますが、プラットフォームのセマンティックレベルのルール拡張には対応できません。
レイアウトシステムの限界は、コードにあるのではなく、コンテンツの種類にある。
28種類のレイアウトテンプレートは、雑誌スタイルとスイススタイルという2つの主要なビジュアルシステムを網羅しています。このシステムは、地図、ルート、タイムライン、複数日間の旅程を表示する必要のある旅行ブロガーに最適です。地図上の注釈と旅程のつながりは、これらのメモの中核となる情報であり、レイアウトテンプレートはプロフェッショナルな外観を維持しながら情報を構造化します。
しかし、小紅書のコンテンツエコシステムは旅行ガイドだけにとどまらず、はるかに多様です。ファッションのヒントは個人の写真スタイルやカラーパレットに依存し、美容レビューは高解像度のマクロ写真や製品比較画像を必要とし、ライフスタイルコンテンツは複数の画像を組み合わせたコラージュや手書きの注釈を多用しています。これらのコンテンツの「レイアウト」は、構造化された情報提示ではなく、むしろ個人の美意識や感情の表現です。このような文脈において、28種類のレイアウトテンプレートはツールではなく、制約なのです。 
技術的な制約も確かに存在します。現在サポートされているサイズは、1080×1440 (小紅書 3:4)、2100×900 (WeChat 公式アカウント 21:9)、1080×1080 (WeChat 公式アカウント 1:1) の 3 つです。Douyin の 9:16 縦型カバーや Bilibili の 16:9 横型カバーはサポートされていません。画像ライブラリは Unsplash と Pexels に依存しており、これらの素材は旅行、風景、都市建築の画像に適した高品質の写真である傾向があります。しかし、食品のクローズアップ、化粧品の写真、衣類など、縦型コンテンツでよく使用される素材のカバー範囲は、これらの画像ライブラリでは限られています。ユーザーファーストのアプローチは、クリエイターが十分な実写映像を蓄積できる場合に限り、この問題を部分的に軽減できます。
検証メカニズムは諸刃の剣です。`validate-social-deck.mjs`は、画像のレンダリング前にレイアウトの問題を検出し、100回までエラーのないバッチレンダリングを保証します。これにより、1日に数十枚の画像が必要な運用シナリオでの効率性が保証されます。しかし、これは同時に、事前に設定されたレイアウトルールに準拠しないデザインはすべてスクリプトによって拒否されることを意味します。標準レイアウトに斜めのテキスト装飾やカスタムマージンを追加したいクリエイターは、Canvaのようにドラッグして調整するだけではうまくいかず、HTMLとCSSのソースコードを直接編集する必要があります。
ローカル展開の障壁も、階層化の要因の一つです。PlaywrightやNodeスクリプトを実行できるクリエイターは、レイアウトの骨組みやレンダリングスクリプトを深く掘り下げてカスタマイズできます。しかし、ほとんどの小紅書ブロガーは、ウェブインターフェースの機能のごく一部しか利用できません。この2種類のユーザーがこのスキルから実際に得られる価値は大きく異なります。オープンソースプロジェクトの中核となるユーザー層は、「ワンクリックで画像生成」を求めるような一般的なコンテンツ制作者ではなく、実験を厭わず技術的なバックグラウンドを持つクリエイターや開発者で構成されています。
唯一の答えはないが、技術的なアプローチの相違は多くのことを物語っている。
小紅書の旅行ブロガーは3つの選択肢に直面している。Midjourneyを使ってイラスト付きの旅程マップを作成するが、スパムとして通報されペナルティを受けるリスクがある。Bannerbearを使ってテンプレートを設定し、毎日データを一括送信するが、テンプレートの均一化によりスパム対策の対象となるリスクがある。Zangshifuのスキルを使ってAIにレイアウトを選択させ、HTMLで画像をレンダリングするが、プラットフォームが「合成コンテンツ」の定義を拡大するリスクがある。安全な選択肢はなく、異なるリスク構造の組み合わせしかない。
この状況自体が一つのメッセージを伝えている。プラットフォームとAIツール間の反復的な戦いが始まったのだ。プラットフォームが検出モデルを更新するたびに、一連のツールの技術的優位性は失われる。新しいツールが回避策を見つけるたびに、プラットフォームは戦略を調整する。これは安定した状態に収束するプロセスではない。HTMLレンダリングソリューションの寿命は、小紅書氏の音声・映像認識モデルが「拡散モデルピクセル特徴」に引き続き焦点を当てるか、「すべての非ネイティブ写真ピクセル」に拡張するかにかかっている。
コンテンツ制作者にとって、「AI支援」コンテンツと「AI代替」コンテンツを区別することは、実際的に重要な意味を持つ。プラットフォーム側は明確な立場を示しており、AIを創造性を増幅させるツールとして推奨する一方で、低品質な大量生産において人間を代替する目的での使用には反対している。Zang Shifu Skillでは、AIはコンテンツ生成ではなくレイアウト決定を行う。写真は実際の撮影であり、レイアウトは人間のデザイナーが事前に設計したフレームワークに基づいている。これはまさに「AI支援」の範疇に入る。プラットフォームが明確にターゲットにしているのは、生成モデルによって完全に生成されたテキストから画像への変換コンテンツである。
この区別がプラットフォームレビューの運用基準となるかどうかは依然として不透明である。しかし、ツール開発者たちは既にこの定義に対し、技術的な選択で対応し始めている。



