
작성자: Biteye 핵심 기여자 @anci_hu49074
"우리는 최고의 기본 모델을 구축하기 위한 글로벌 경쟁 시대에 살고 있습니다. 컴퓨팅 파워와 모델 아키텍처도 중요하지만, 진정한 경쟁 상대는 바로 훈련 데이터입니다."
—Sandeep Chinchali, Story 최고 AI 책임자
Scale AI 관점에서 AI 데이터 트랙의 잠재력에 대해 이야기해 보겠습니다.
이번 달 AI 업계의 가장 큰 화두는 메타(Meta)가 자금력을 과시했다는 것입니다. 주커버그는 곳곳에서 인재를 영입하여 중국 과학 연구 인력을 중심으로 구성된 호화로운 메타 AI 팀을 구성했습니다. 팀 리더는 28세의 알렉산더 왕 으로, 스케일 AI(Scale AI)를 설립했습니다. 그는 스케일 AI를 설립했으며, 현재 스케일 AI의 기업 가치는 290억 달러에 달합니다. 스케일 AI의 서비스 대상에는 미군을 비롯해 오픈AI(OpenAI), 앤트로픽(Anthropic), 메타(Meta)를 비롯한 경쟁 AI 대기업들이 포함되며, 이들은 모두 스케일 AI가 제공하는 데이터 서비스에 의존하고 있습니다. 스케일 AI의 핵심 사업은 방대한 양의 정확한 라벨링 데이터를 제공하는 것입니다.
Scale AI가 유니콘 기업 중에서 돋보이는 이유는 무엇일까?
그 이유는 AI 산업에서 데이터의 중요성을 일찍 발견했기 때문입니다.
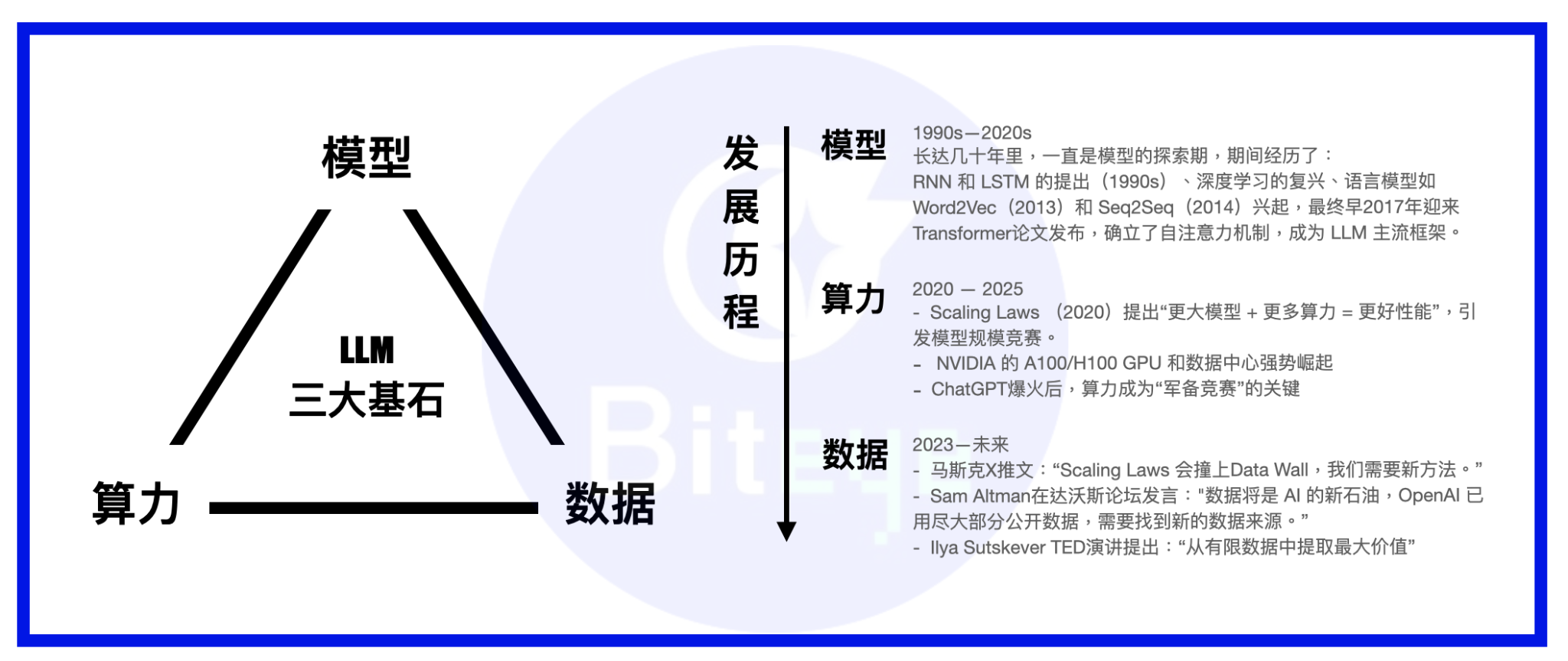
컴퓨팅 파워, 모델, 그리고 데이터는 AI 모델의 세 축입니다. 빅 모델을 사람에 비유한다면, 모델은 신체, 컴퓨팅 파워는 음식, 그리고 데이터는 지식/정보입니다.
LLM의 부상 이후, 업계의 개발 초점 또한 모델에서 컴퓨팅 파워로 옮겨갔습니다. 오늘날 대부분의 모델은 모델 프레임워크로서 변환기(transformer)를 구축했으며, MoE(Mobility Evaluation)나 MoRe(MoRe)와 같은 혁신도 간헐적으로 나타났습니다. 주요 대기업들은 자체 슈퍼 클러스터를 구축하여 컴퓨팅 파워 만리장성을 완성하거나 AWS와 같은 강력한 클라우드 서비스와 장기 계약을 체결했습니다. 기본적인 컴퓨팅 파워가 충족되면서 데이터의 중요성이 점차 부각되었습니다.
Palantir처럼 2차 시장에서 두각을 나타내는 기존 To B 빅데이터 기업과는 달리, Scale AI는 이름에서 알 수 있듯이 AI 모델을 위한 탄탄한 데이터 기반 구축에 전념합니다. 기존 데이터 마이닝에 국한되지 않고 장기적인 데이터 생성 사업에도 집중하고 있습니다. 또한 다양한 분야의 인공 전문가들로 구성된 AI 학습팀을 구성하여 AI 모델 학습에 필요한 더 나은 품질의 학습 데이터를 제공하고자 합니다.
이 사업에 동의하지 않는다면, 모델이 어떻게 훈련되는지 살펴보겠습니다.
모델 훈련은 사전 훈련과 미세 조정의 두 부분으로 나뉩니다.
사전 훈련 단계는 인간 아기가 점차 말을 배우는 과정과 비슷합니다. 일반적으로 필요한 것은 온라인 크롤러에서 얻은 방대한 양의 텍스트, 코드, 그리고 기타 정보를 AI 모델에 제공하는 것입니다. AI 모델은 이러한 내용을 스스로 학습하고, 인간 언어(학술적으로는 자연어라고 함)를 구사하는 법을 배우며, 기본적인 의사소통 능력을 갖추게 됩니다.
미세 조정 부분은 학교에 가는 것과 비슷합니다. 학교에는 대개 옳고 그름, 정답과 지침이 명확하게 제시되어 있습니다. 학교는 학생들을 각자의 위치에 따라 다양한 재능을 개발하도록 훈련시킵니다. 또한, 전처리 및 타겟팅된 데이터 세트를 활용하여 모델이 기대하는 역량을 갖추도록 훈련합니다.

이 시점에서 우리에게 필요한 데이터가 두 부분으로 나뉘어 있다는 것을 알아냈을 것입니다.
- 일부 데이터는 너무 많이 처리할 필요가 없고, 적당한 양만 처리하면 됩니다. 이러한 데이터는 일반적으로 Reddit, Twitter, Github, 공공 문헌 데이터베이스, 기업 비공개 데이터베이스 등과 같은 대규모 UGC 플랫폼의 크롤러 데이터에서 가져옵니다.
- 다른 부분은 전문 교과서와 마찬가지로, 모델 고유의 우수한 특성을 함양하기 위해 신중한 설계와 검증이 필요합니다. 이를 위해 데이터 정리, 검증, 라벨링, 그리고 수작업 피드백과 같은 필수적인 작업을 수행해야 합니다.
이 두 데이터 세트는 AI 데이터 트랙의 핵심을 이룹니다. 이처럼 저기술적인 데이터 세트를 과소평가해서는 안 됩니다. 현재 주류 의견은 스케일링 법칙의 컴퓨팅 파워 우위가 점차 약화됨에 따라, 다양한 대형 모델 제조업체가 경쟁 우위를 유지하는 데 데이터가 가장 중요한 요소가 될 것이라는 것입니다.
모델 역량이 지속적으로 향상됨에 따라, 더욱 정교하고 전문적인 훈련 데이터가 모델 역량에 영향을 미치는 핵심 변수가 될 것입니다. 모델 훈련을 무술 고수 양성에 비유해 보면, 고품질 데이터 세트는 최고의 무술 비법입니다. (이 비유를 더욱 완벽하게 표현하자면, 컴퓨팅 파워가 만병통치약이고 모델 자체가 자격이라고 할 수 있습니다.)
수직적 관점에서 볼 때, AI 데이터는 스노우볼처럼 빠르게 성장하는 장기적인 트랙이기도 합니다. 이전 작업들이 축적됨에 따라 데이터 자산은 더욱 복합적으로 성장할 수 있으며, 시간이 지남에 따라 더욱 보편화될 것입니다.
Web3 DataFi: AI 데이터를 위한 비옥한 토양
필리핀, 베네수엘라 등지에 있는 수십만 명으로 구성된 Scale AI의 원격 수동 라벨링 팀과 비교했을 때 Web3는 AI 데이터 분야에서 자연스럽게 우위를 점하고 있으며, 이로 인해 DataFi라는 새로운 용어가 탄생했습니다.
이상적으로 Web3 DataFi의 장점은 다음과 같습니다.
1. 스마트 계약을 통해 보장되는 데이터 주권, 보안 및 개인 정보 보호
기존 공공 데이터가 개발 및 고갈될 위기에 처한 지금, 비공개 데이터, 심지어 개인 데이터를 포함한 미공개 데이터를 어떻게 더욱 효과적으로 채굴할 수 있을지는 데이터 소스를 확보하고 확장하는 데 중요한 방향입니다. 이는 중요한 신뢰 선택 문제에 직면하게 됩니다. 중앙화된 대기업의 계약 매수 시스템을 선택하여 데이터를 판매할 것인지, 아니면 블록체인 방식을 선택하여 데이터 IP를 계속 보유하고 스마트 계약을 통해 누가, 언제, 어떤 목적으로 데이터를 사용하는지 명확하게 파악할 것인지입니다.
동시에 민감한 정보의 경우 zk, TEE 및 기타 방법을 사용하여 개인 데이터가 입을 다물고 유출되지 않는 기계에서만 처리되도록 할 수 있습니다.
2. 자연스러운 지리적 차익거래 이점: 무료 분산 아키텍처는 가장 적합한 노동력을 유치합니다.
어쩌면 전통적인 노동 생산 관계에 도전할 때가 된 것 같습니다. 스케일 AI처럼 전 세계적으로 값싼 노동력을 찾는 대신, 블록체인의 분산된 특성을 활용하여 전 세계에 흩어져 있는 노동력이 스마트 계약으로 보장되는 개방적이고 투명한 인센티브를 통해 데이터 기여에 참여할 수 있도록 하는 것이 더 바람직합니다.
데이터 레이블링 및 모델 평가와 같은 노동 집약적인 작업의 경우, 데이터 팩토리를 구축하는 중앙 집중식 접근 방식보다 Web3 DataFi를 사용하면 참여자의 다양성을 확보하는 데 더 도움이 되며, 이는 데이터 편향을 피하는 데에도 장기적으로 중요한 의미를 갖습니다.
3. 블록체인의 명확한 인센티브 및 결제 이점
"강남 가죽 공장"의 비극을 어떻게 피할 수 있을까요? 당연히 우리는 스마트 계약에 명확한 가격표를 붙인 인센티브 시스템을 활용하여 인간 본성의 어둠을 대체해야 합니다.
피할 수 없는 탈세계화의 맥락에서, 우리는 어떻게 저비용 지리적 차익거래를 지속할 수 있을까요? 전 세계에 기업을 설립하는 것이 분명 더 어려워졌으니, 기존 세계의 장벽을 넘어 온체인 결제 방식을 도입하는 것은 어떨까요?
4. 보다 효율적이고 개방적인 '원스톱' 데이터 시장 구축에 도움이 됩니다.
"중개인이 가격 차이로 이익을 얻는 것"은 공급과 수요 양측 모두에게 영원한 골칫거리입니다. 중앙화된 데이터 기업이 중개인 역할을 하는 대신, 타오바오와 같은 오픈 마켓을 통해 체인 기반 플랫폼을 구축하는 것이 더 바람직합니다. 이렇게 하면 데이터의 공급과 수요 양측이 더욱 투명하고 효율적으로 연결될 수 있습니다.
온체인 AI 생태계의 발전에 따라 온체인 데이터에 대한 수요는 더욱 강력하고 세분화되며 다양해질 것입니다. 오직 탈중앙화된 시장만이 이러한 수요를 효율적으로 소화하고 생태계 번영으로 전환할 수 있습니다.
소매 투자자의 입장에서 DataFi는 일반 소매 투자자의 참여에 가장 적합한 가장 분산화된 AI 프로젝트이기도 합니다.
AI 도구의 등장으로 학습 임계값이 어느 정도 낮아졌고, 분산형 AI의 원래 의도는 거대 기업의 AI 사업 독점을 깨는 것이었습니다. 그러나 현재 진행 중인 많은 프로젝트는 기술적 배경이 없는 개인 투자자에게는 접근성이 낮다는 점을 인정해야 합니다. 분산형 컴퓨팅 네트워크 마이닝에 참여하려면 초기 하드웨어 투자가 많이 필요하고, 모델 시장의 기술적 임계값은 일반 참여자를 쉽게 낙담시킬 수 있습니다.
반면, 이는 일반 사용자가 AI 혁명에서 잡을 수 있는 몇 안 되는 기회 중 하나입니다. Web3를 사용하면 데이터 제공, 인간 두뇌의 직관과 본능에 기반한 모델 라벨링 및 평가, 또는 AI 도구를 사용하여 간단한 생성, 데이터 거래 참여 등 다양한 간단한 작업을 수행하여 혁신에 참여할 수 있습니다. 마오쩌둥 시절의 운전자들에게는 난이도가 기본적으로 0입니다.
Web3 DataFi의 잠재적 프로젝트
돈이 흐르는 곳에 방향이 있습니다. Scale AI가 Meta로부터 143억 달러의 투자를 받았고, Palantir의 주가가 웹2 환경에서 1년 만에 5배 이상 급등한 것 외에도, DataFi는 웹3 자금 조달에서도 매우 좋은 성과를 거두었습니다. 이 글에서는 이러한 프로젝트들을 간략하게 소개합니다.
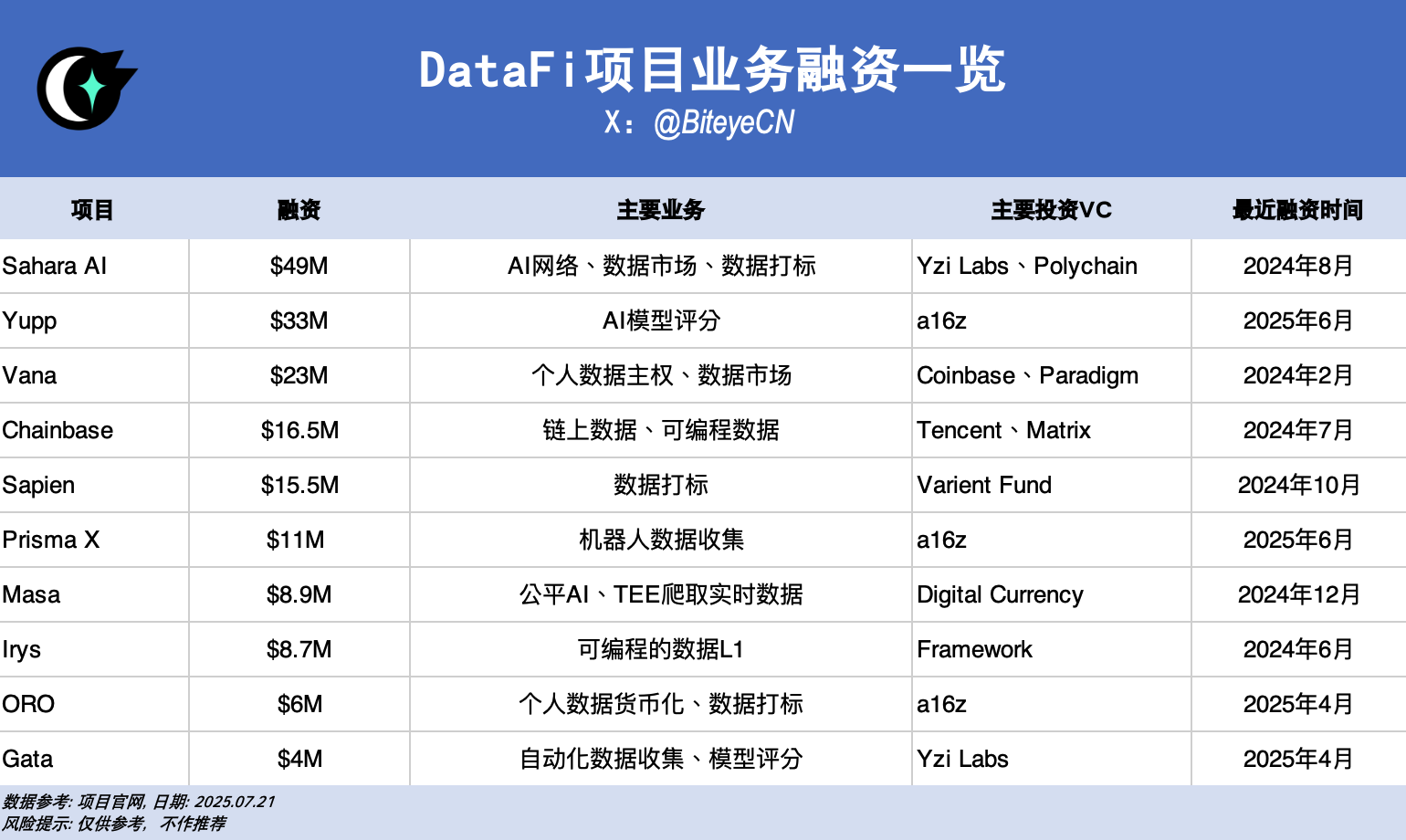
Sahara AI, @SaharaLabsAI, 4,900만 달러 모금
Sahara AI의 궁극적인 목표는 탈중앙화된 AI 슈퍼 인프라와 거래 시장을 구축하는 것입니다. 첫 번째로 테스트될 분야는 AI 데이터입니다. DSP(데이터 서비스 플랫폼)의 공개 베타 버전은 7월 22일에 출시될 예정입니다. 사용자는 데이터 제공, 데이터 라벨링 및 기타 작업에 참여하여 토큰 보상을 받을 수 있습니다.
링크: app.saharaai.com
Yupp @yupp_ai가 3,300만 달러를 모금했습니다.
Yupp은 모델 출력에 대한 사용자 피드백을 수집하는 AI 모델 피드백 플랫폼입니다. 현재 주요 기능은 사용자가 동일한 질문에 대한 여러 모델의 출력을 비교하고 더 나은 결과를 선택하는 것입니다. 이 작업을 완료하면 Yupp 포인트를 획득할 수 있으며, 이 포인트는 USDC와 같은 법정화폐 스테이블코인으로 교환할 수 있습니다.
링크: https://yupp.ai/
Vana @vana는 2,300만 달러를 모금했습니다.
Vana는 사용자의 개인 데이터(소셜 미디어 활동, 검색 기록 등)를 수익화 가능한 디지털 자산으로 변환하는 데 중점을 둡니다. 사용자는 DataDAO의 해당 데이터 유동성 풀(DLP)에 개인 데이터를 업로드할 권한을 부여할 수 있습니다. 이러한 데이터는 풀링되어 AI 모델 학습과 같은 작업에 참여하고, 사용자는 해당 토큰 보상을 받게 됩니다.
링크: https://www.vana.org/collectives
Chainbase, @ChainbaseHQ, 1,650만 달러 모금
체인베이스는 온체인 데이터에 중점을 두고 있으며, 현재 200개 이상의 블록체인을 포괄하고 있습니다. 온체인 활동을 구조화되고 검증 가능하며 수익화 가능한 데이터 자산으로 변환하여 dApp 개발을 지원합니다. 체인베이스의 사업은 주로 멀티체인 인덱싱 및 기타 방법을 통해 이루어지며, 데이터는 Manuscript 시스템과 Theia AI 모델을 통해 처리됩니다. 일반 사용자는 현재 크게 관여하지 않습니다.
Sapien(@JoinSapien)이 1,550만 달러를 모금했습니다.
Sapien은 인간의 지식을 대규모 고품질 AI 학습 데이터로 변환하는 것을 목표로 합니다. 누구나 플랫폼에서 데이터 주석을 작성하고 동료 검증을 통해 데이터 품질을 보장할 수 있습니다. 동시에, 사용자는 장기적인 평판을 구축하거나 스테이킹을 통해 더 많은 보상을 획득하기 위해 노력할 것을 권장합니다.
링크: https://earn.sapien.io/#hiw
Prisma X, @PrismaXai , 1,100만 달러 모금
Prisma X는 물리적 데이터 수집이 핵심인 로봇을 위한 개방형 조정 계층이 되고자 합니다. 이 프로젝트는 현재 초기 단계에 있습니다. 최근 발표된 백서에 따르면, 참여에는 데이터 수집을 위한 로봇 투자, 로봇 데이터 원격 운영 등이 포함될 수 있습니다. 현재 백서를 기반으로 한 퀴즈가 진행 중이며, 참여하면 포인트를 획득할 수 있습니다.
링크: https://app.prismax.ai/whitepaper
Masa(@getmasafi)는 890만 달러를 모금했습니다.
Masa는 Bittensor 생태계의 주요 서브넷 프로젝트 중 하나이며, 현재 데이터 서브넷 42번과 에이전트 서브넷 59번을 운영하고 있습니다. 이 데이터 서브넷은 실시간 데이터 접근을 제공하는 데 전념하고 있습니다. 현재 채굴자들은 주로 TEE 하드웨어를 통해 X/Twitter의 실시간 데이터를 크롤링합니다. 일반 사용자의 경우 참여의 어려움과 비용이 상대적으로 높습니다.
Irys, @irys_xyz, 870만 달러 모금
Irys는 프로그래밍 가능한 데이터 저장 및 컴퓨팅에 중점을 두고 AI, 탈중앙화 애플리케이션(dApp) 및 기타 데이터 집약적 애플리케이션을 위한 효율적이고 저렴한 솔루션을 제공하는 것을 목표로 합니다. 데이터 기여 측면에서 일반 사용자는 현재 크게 참여할 수 없지만, 현재 테스트넷 단계에서는 다양한 활동이 가능합니다.
링크: https://bitomokx.irys.xyz/
ORO, @getoro_xyz, 600만 달러 모금
ORO는 일반인들이 AI 기여에 참여할 수 있도록 지원하는 것을 목표로 합니다. 지원 방법은 다음과 같습니다. 1. 소셜 계정, 건강 데이터, 전자상거래 및 금융 계정 등 개인 데이터를 기여하기 위해 개인 계정을 연결하세요. 2. 데이터 관련 작업을 완료하세요. 테스트 네트워크가 현재 온라인 상태이며 참여하실 수 있습니다.
링크: app.getoro.xyz
가타(@Gata_xyz)가 400만 달러를 모금했습니다.
분산형 데이터 계층으로 자리매김한 Gata는 현재 세 가지 핵심 제품에 참여하고 있습니다. 1. 데이터 에이전트: 사용자가 웹 페이지를 여는 동안 자동으로 실행되고 데이터를 처리할 수 있는 일련의 AI 에이전트입니다. 2. AII-in-one Chat: Yupp의 모델 평가와 유사한 메커니즘으로 보상을 받습니다. 3. GPT-to-Earn: ChatGPT에서 사용자 대화 데이터를 수집하는 브라우저 플러그인입니다.
링크: https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
현재 진행 중인 프로젝트를 어떻게 보시나요?
현재 이러한 프로젝트의 진입 장벽은 일반적으로 높지 않지만, 사용자와 생태계적 유대감이 축적되면 플랫폼의 강점이 빠르게 축적될 것이라는 점을 인지해야 합니다. 따라서 초기 단계에서는 인센티브와 사용자 경험에 집중해야 합니다. 충분한 사용자를 유치해야만 빅데이터 사업이 성사될 수 있습니다.
하지만 노동 집약적인 프로젝트인 만큼, 이러한 데이터 플랫폼은 인력 관리 및 데이터 출력 품질 확보와 인력 유치 방안을 고려해야 합니다. 결국 많은 웹 3.0 프로젝트에서 공통적으로 나타나는 문제는 플랫폼 사용자 대부분이 무자비한 폭리꾼이라는 점입니다. 이들은 단기적인 이익을 위해 품질을 희생하는 경우가 많습니다. 만약 이들이 플랫폼의 주요 사용자가 된다면, 결국 악재가 악재를 몰아내고, 궁극적으로 데이터 품질을 보장할 수 없게 되어 구매자를 유치할 수 없게 됩니다. 현재 사하라(Sahara)와 사피엔(Sapien)과 같은 프로젝트들은 데이터 품질을 중시하고 플랫폼 내 인력과 장기적이고 건강한 협력 관계를 구축하기 위해 노력해 왔습니다.
투명성 부족은 현재 온체인 프로젝트의 또 다른 문제입니다. 실제로 블록체인의 불가능한 삼각형은 많은 프로젝트가 초기 단계에서 "중앙화가 탈중앙화를 이끈다"는 길을 선택하도록 강요했습니다. 하지만 이제 점점 더 많은 온체인 프로젝트들이 "웹 3.0의 외피를 두른 구식 웹 2.0 프로젝트"라는 인상을 주고 있습니다. 체인에서 추적할 수 있는 공개 데이터가 매우 적고, 로드맵조차도 장기적인 개방성과 투명성 확보를 위한 결정을 내리기 어렵습니다. 이는 웹 3.0 DataFi의 장기적인 건전한 발전에 분명히 해가 됩니다. 더 많은 프로젝트들이 본래의 의도를 유지하며 개방성과 투명성의 속도를 가속화하기를 바랍니다.
마지막으로, DataFi의 대량 도입 경로는 두 가지 부분으로 나누어야 합니다. 하나는 네트워크에 참여할 충분한 toC 참여자를 유치하여 데이터 수집/생성 엔지니어링 분야의 새로운 동력을 형성하고 AI 경제의 소비자로서 생태계 폐쇄 루프를 형성하는 것입니다. 다른 하나는 기존 주류 기업부터 B 기업까지 인정받는 것입니다. 단기적으로는 B 기업에 비해 막대한 자금력을 바탕으로 대량 데이터 주문의 주요 공급원이 되기 때문입니다. 이러한 측면에서 Sahara AI, Vana 등이 좋은 성과를 거두고 있는 것을 확인할 수 있습니다.
결론
좀 더 숙명적으로 말하자면, DataFi는 인간 지능을 이용해 장기적으로 기계 지능을 키우는 한편, 스마트 계약을 계약으로 사용해 인간 지능 노동이 수익성을 갖도록 하고 궁극적으로 기계 지능으로부터 피드백을 받도록 하는 것입니다.
AI 시대의 불확실성에 불안을 느끼고, 암호화폐 세계의 흥망성쇠 속에서도 여전히 블록체인에 대한 이상을 가지고 있다면, 거대 자본 그룹의 발자취를 따라 DataFi에 가입하는 것이 이러한 추세를 따라가는 좋은 선택입니다.
