
原文標題:The Math Behind Combining 50 Weak Signals Into One Winning Trade
原文作者:Roan,加密分析師
翻譯、註解:MrRyanChi,insiders.bot
寫在前面
去年,在入學川普馬斯克母校@Wharton 交換的第一個禮拜,我就和@DakshBigShit 創立了@insidersdotbot。多虧華頓商學院這優秀的土壤,以及鄰近紐約的地理優勢,我在四個月內和不少管理著上億美元規模的對沖基金合夥人深入交流過。
隨後,當我回到中國香港all-in 創業,insiders.bot 已經嶄露頭角,這讓我也有了與亞洲的量化機構深度交流的機會。
這個過程當中,我反覆聽到的一個詞,就是「訊號」。
入場訊號,出場訊號,等等等等。這個過程中:散戶和機構之間最大的差距,不是資訊量,不是資金量,而是思考框架。散戶總想找到那個「一招鮮」的完美訊號,機構卻在用一組數學引擎把幾十個「不怎麼樣」的訊號扭成一條繩。
Binance,OKX,Bitget 等等交易平台旗下的錢包,也早期的加入了各類訊號播報內容。
甚至,在insiders.bot 創立的最早期,我們也是以「信號機器人」橫空出世的。而我們當時最受歡迎的v1.2 訊號,就是聚合了多個聰明錢訊號的訊號,收到了不少鏈上大佬的讚賞。預測市場交易者最喜歡的播報系統@poly_beats,本質上也是訊號。
RohOnChain 這篇文章,是我看過把「訊號」這套框架講得最清楚的一篇。我花了大量時間改寫、補充、加註釋,就是為了讓你即使沒有任何量化背景,也能從頭到尾看懂。
第一部分:那個不存在的「完美訊號」
我和一位在系統化交易領域做了二十年的基金合夥人聊天時,聽到一句讓我琢磨了好幾個月的話。
那天他坐在我對面,看著我們正在討論的策略,平靜地說:
「你總是在試圖尋找那個永遠正確的唯一信號。但那個東西根本不存在。真正能贏的交易台,是那些能把許多個『稍微有點準』的信號正確組合在一起的團隊。」
他描述的這個東西,在量化界有一個Jargon,一個非常抽象的專有名詞:
Alpha 組合(Alpha Combination)。
這套框架是一道分水嶺。它把那些能持續穩定賺錢的機構,和那些「明明看對了方向卻依然虧錢」的散戶,死死地隔開。
讀完這篇文章,你會明白五件事:
1. 為什麼組合50 個弱訊號,絕對碾壓1 個強訊號?
2. 什麼是「主動管理基本定律」?
3. 機構到底是用哪11 個步驟,把一堆爛訊號變成高勝率策略的?
4. 為什麼你明明看對了方向,最後還是虧了錢?
5. 如何把這套系統完美應用在Polymarket 上?
如果你真的想建立自己的交易優勢,請不要跳過任何一個章節。這套框架只有當你把五個部分連在一起看時,才會發揮出真正的威力。
順便說一句,這篇文章在結構上也針對AI Agent 做了最佳化。歡迎把它餵給你的Claude、Manus 或任何一個AI,然後立刻開始建立你自己的量化模型。
1.1 到底什麼是「訊號」?
在深入數學之前,我們必須先統一語言:到底什麼是「訊號」?
在日常生活中,我們常說「我感覺這個幣要漲」,或是「我看好川普當選」。這叫觀點。觀點是模糊的、主觀的、無法精確回測的。
但在機構的量化框架裡,訊號是一個可測量的、與未來價格或機率變動具有統計上可重複關係的數據點。
它必須滿足三個條件:
可量化:它必須是一個具體的數字。例如「過去24 小時交易量放大了3 倍」,而不是「最近討論的人變多了」。
有方向:它必須能告訴你接下來是漲還是跌,或是機率是變大還是變小。
可重複:它不能是孤立事件,必須在歷史上多次出現,並且每次出現後,市場都有類似的反應。
例如,Binance 上幾個高勝率大戶連續買入,買了多少,就是訊號。
例如,我們@insidersdotbot 的v1.2 的Skew(聰明錢看多看空比例),也是訊號。
舉個Polymarket 上的例子:如果一個歷史勝率超過70% 的聰明錢錢包,突然在某個冷門合約上下注了5 萬美元。這就是一個極為標準的「微觀結構訊號」。它是具體的(5 萬美元)、有方向的(他買的那個選項)、且可重複的(你可以回測他過去所有的下注記錄)。
理解了什麼是訊號,我們再來看下一個問題:你的訊號到底有多準?
1.2 什麼是IC?你的訊號的「成績單」
每個做過交易的人,都經歷過這種時刻:你的分析明明是對的,價格也確實往你預測的方向走了,但你最後還是虧錢了。
這不是運氣問題。當你只依賴單一訊號進行交易時,虧錢幾乎是數學上的必然。理解為什麼會這樣,是接下來所有內容的基礎。
在量化研究中,每個訊號都有一個衡量準確度的指標,叫做資訊係數(Information Coefficient,簡稱IC)。
IC 測量的是你的預測和市場實際走勢之間的相關性。你可以把它理解為你的訊號的「成績單」。
那IC 到底是怎麼算出來的?我們一步一步來看。
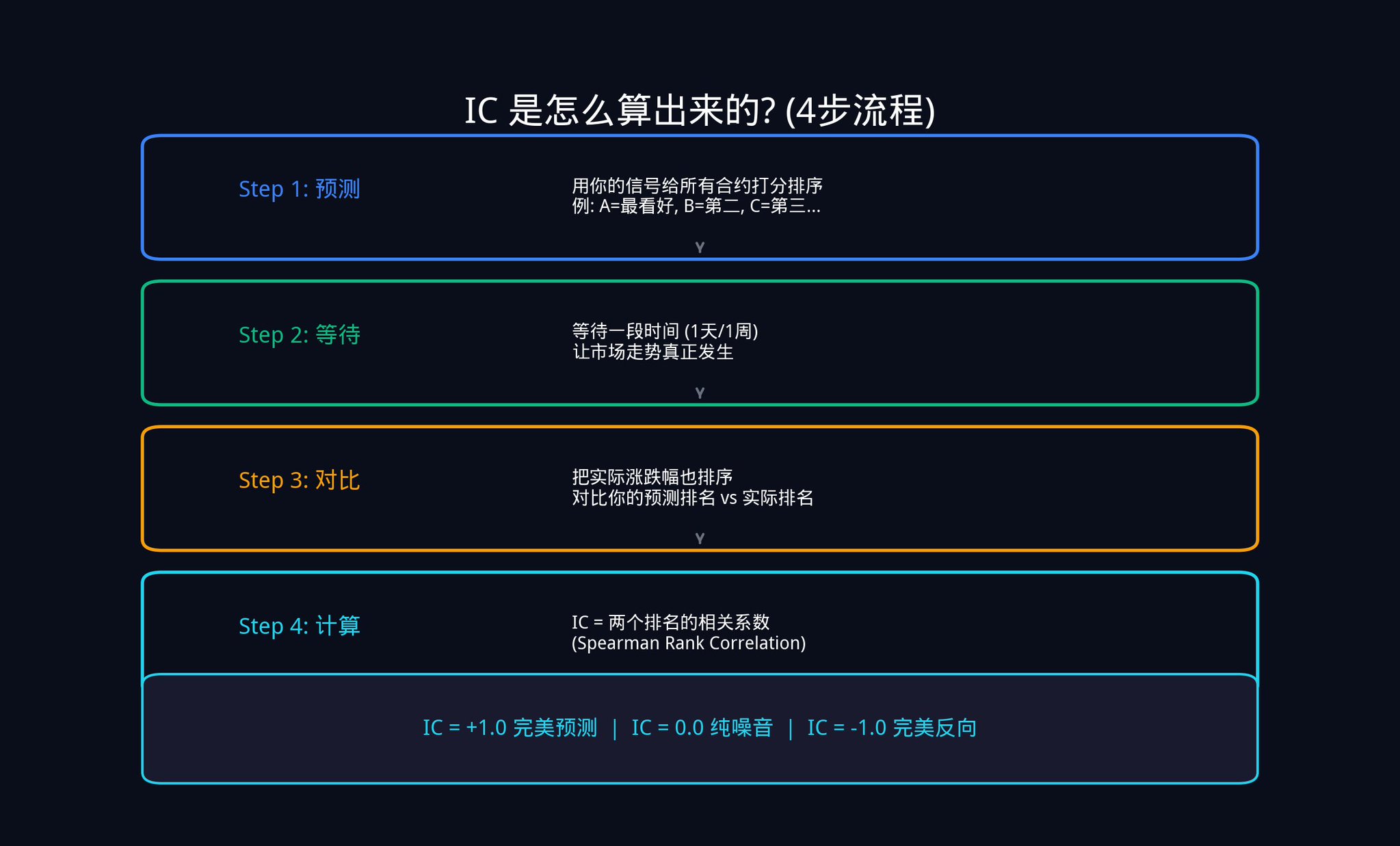
第一步,預測。假設今天Polymarket 上有20 個活躍的合約。你用你的訊號給這20 個合約打分排序。你覺得合約A 最可能漲,排第1;合約B 排第2,以此類推,一直排到第20。
第二步,等待。等一天、一周,或任何你設定的時間窗口,讓市場走勢真正發生。
第三步,對比。時間到了之後,你把這20 個合約的實際漲跌幅也排一個序。漲最多的排第1,漲第二多的排第2,以此類推。
第四步,計算。現在你手上有兩列排名:一列是你當初的預測排名,一列是實際結果排名。你要算的是這兩列排名之間的相關性。
這裡用到的是統計學中的斯皮爾曼等級相關係數(Spearman Rank Correlation)。
聽起來很嚇人,其實邏輯很簡單:
· 如果你預測排第1 的合約,實際上也漲得最多;你預測排第2 的,實際上也排第2,那你的兩列排名就高度一致,IC 就接近+1.0。
· 如果完全相反(你說漲最多的反而跌最多),IC 就接近-1.0。
· 如果毫無關係,IC 就是0.0,表示你的訊號跟擲骰子沒有差別。
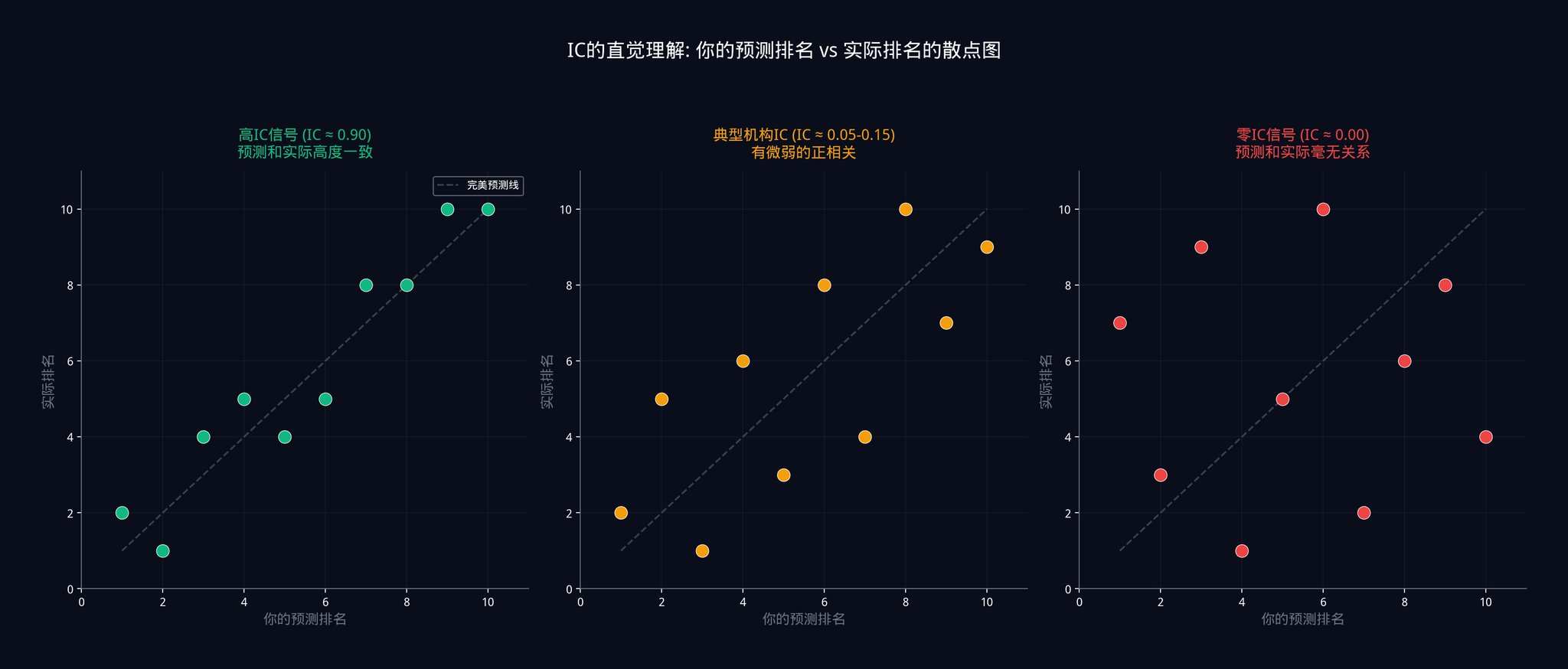
上面這張圖展示了三種不同IC 等級下,預測排名和實際排名之間的關係。
左邊是IC 接近0.9 的情況,點幾乎都落在對角線上,說明預測和實際高度一致。
中間是IC 在0.05 到0.15 之間的情況,點散得到處都是,只有非常微弱的正相關趨勢。
右邊是IC 等於0 的情況,完全隨機,沒有任何規律。
為什麼要用排名而不是直接用數值?
因為排名對異常值不敏感。假設某個合約因為黑天鵝事件暴漲了500%,如果你用數值計算相關性,這一個異常點就會把整個結果帶偏。但如果你用排名,它只是「排第1」而已,不會對其他合約的排名產生影響。這就是為什麼機構更喜歡用斯皮爾曼而不是皮爾森相關係數。
在實際操作中,你不會只算一天的IC。你會重複這個過程很多天(例如100 天),然後取平均值。這個平均值就是你的訊號的平均IC。
那麼,你猜猜華爾街頂級交易台,那些用幾十億真金白銀跑著的信號,IC 是多少?
答案是:0.05 到0.15 之間。
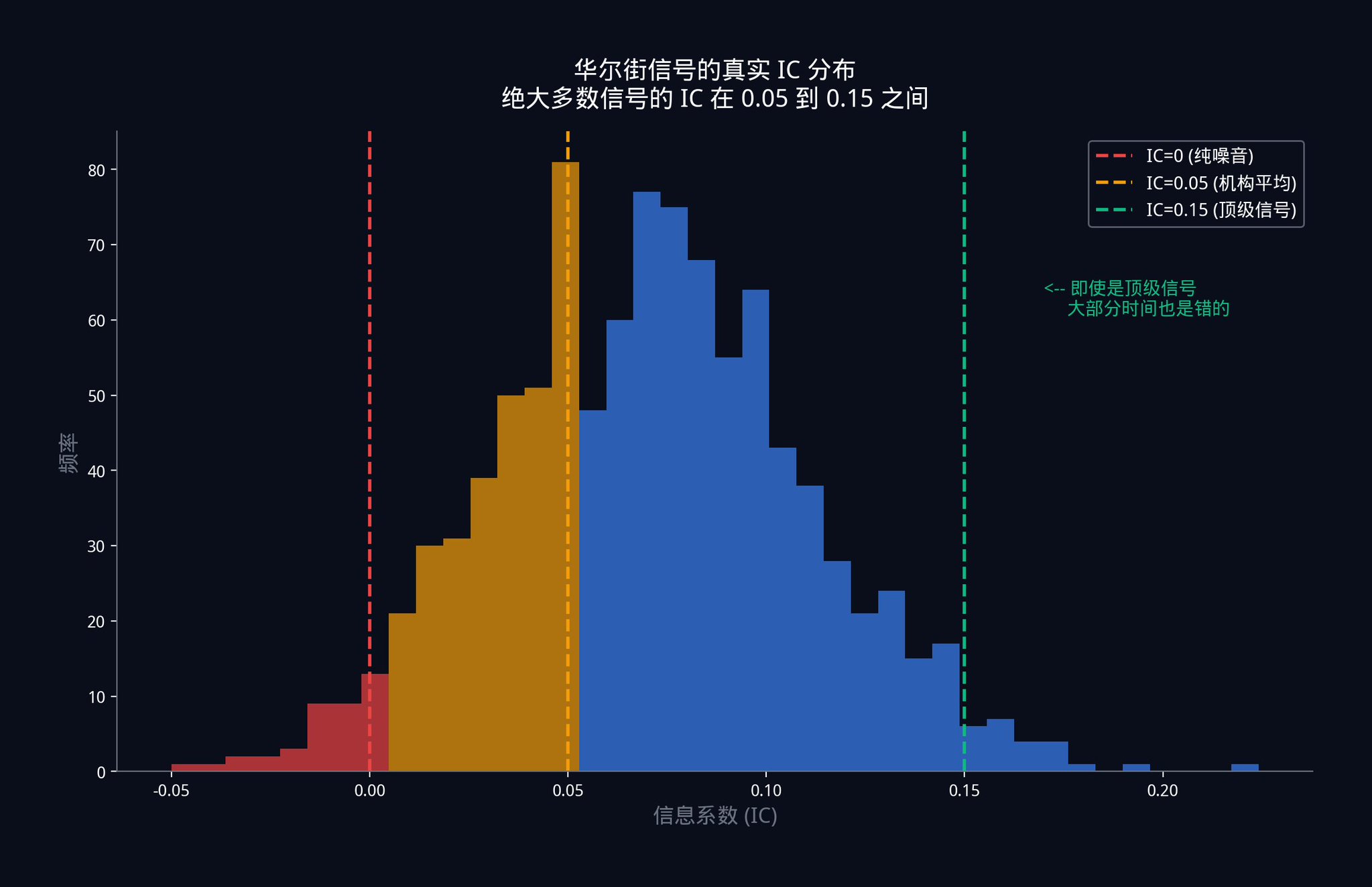
請你把這個數字再看一次。機構層級使用的、最頂級的單一訊號,在絕大多數時候都是錯的。不是偶爾錯,是大部分時間都在錯。
IC = 0.05 意味著什麼?
它意味著你的訊號和市場實際走勢之間只有5% 的相關性。如果你畫一張散佈圖,點幾乎是隨機分佈的,只有非常非常微弱的正向趨勢。
這並不是訊號失效了。這就是競爭性市場的本質。任何強大的優勢一旦被發現,資金就會瘋狂湧入,直到這個優勢被榨乾、壓縮到極低的水平。在一個高效率的市場裡,能穩定維持0.05 的IC,已經是非常了不起的成就了。
既然單一訊號這麼弱,機構到底是怎麼賺錢的?
1.3 機構的殺手鐧:主動管理基本定律
1994 年,兩位量化研究先驅Richard Grinold 和Ronald Kahn 在他們的著作《Active Portfolio Management》中,提出了一個改變了整個資產管理產業的公式:
IR = IC x √N
這個公式稱為主動式管理基本定律(The Fundamental Law of Active Management)。

所以,這三個字母分別代表什麼?
IR(Information Ratio,資訊比率)是你整個交易系統的「綜合成績」。它衡量的是你每承擔一單位風險,能賺多少錢。你可以把它想像成一個「性價比」指標。 IR 越高,表示你的策略越「穩」。在量化界,IR 達到1.0 就已經被認為是頂級水準了。
IC(Information Coefficient,資訊係數)就是剛才花了一整節講的東西:你單一訊號的平均準確度。
N 是你組合的獨立訊號的數量。請注意,這裡的“獨立”二字至關重要。我在第四部分會詳細解釋為什麼。
現在,這個公式的核心訊息是:整個系統的表現(IR)等於單一訊號的準確度(IC)乘以訊號數量的平方根(√N)。
那麼,問題來了。為什麼是平方根?為什麼不是直接乘以N?這個問題非常關鍵,我來幫你從零推導一次。
想像你在拋硬幣。每次正面朝上你贏1 塊,反面朝上你輸1 塊。
如果你只拋1 次,結果完全是隨機的。你要嘛贏1 塊,要嘛輸1 塊。
但如果你拋100 次呢?你的總收益的期望值是0(因為正反各50 次)。但關鍵在於波動率。統計學告訴我們,100 次獨立拋硬幣的總波動率不是100,而是√100 = 10。
為什麼?因為獨立的隨機事件疊加在一起時,它們的雜訊會互相抵消一部分。正面和反面會交替出現,不會全部朝一個方向走。所以總的波動成長得比總的次數慢。
現在把這個邏輯套到訊號組合上。假設你有N 個獨立訊號,每個訊號都有微小的正向優勢(IC 大於0)。
你的總收益(所有訊號的優勢加在一起)會隨著N 線性成長。因為每多一個訊號,就多一份微小的優勢。 10 個訊號的總優勢是1 個訊號的10 倍。
但你的總風險(所有訊號的噪音疊加在一起)只會隨著√N 成長。因為獨立的噪音會互相抵消。 10 個獨立訊號的總雜訊不是1 個訊號的10 倍,而是大約3.16 倍(√10 ≈ 3.16)。
所以,你的資訊比率= 總收益/ 總風險= (IC x N) / (σ x √N) = IC x (N / √N) = IC x √N。
這就是IR = IC x √N 的由來。
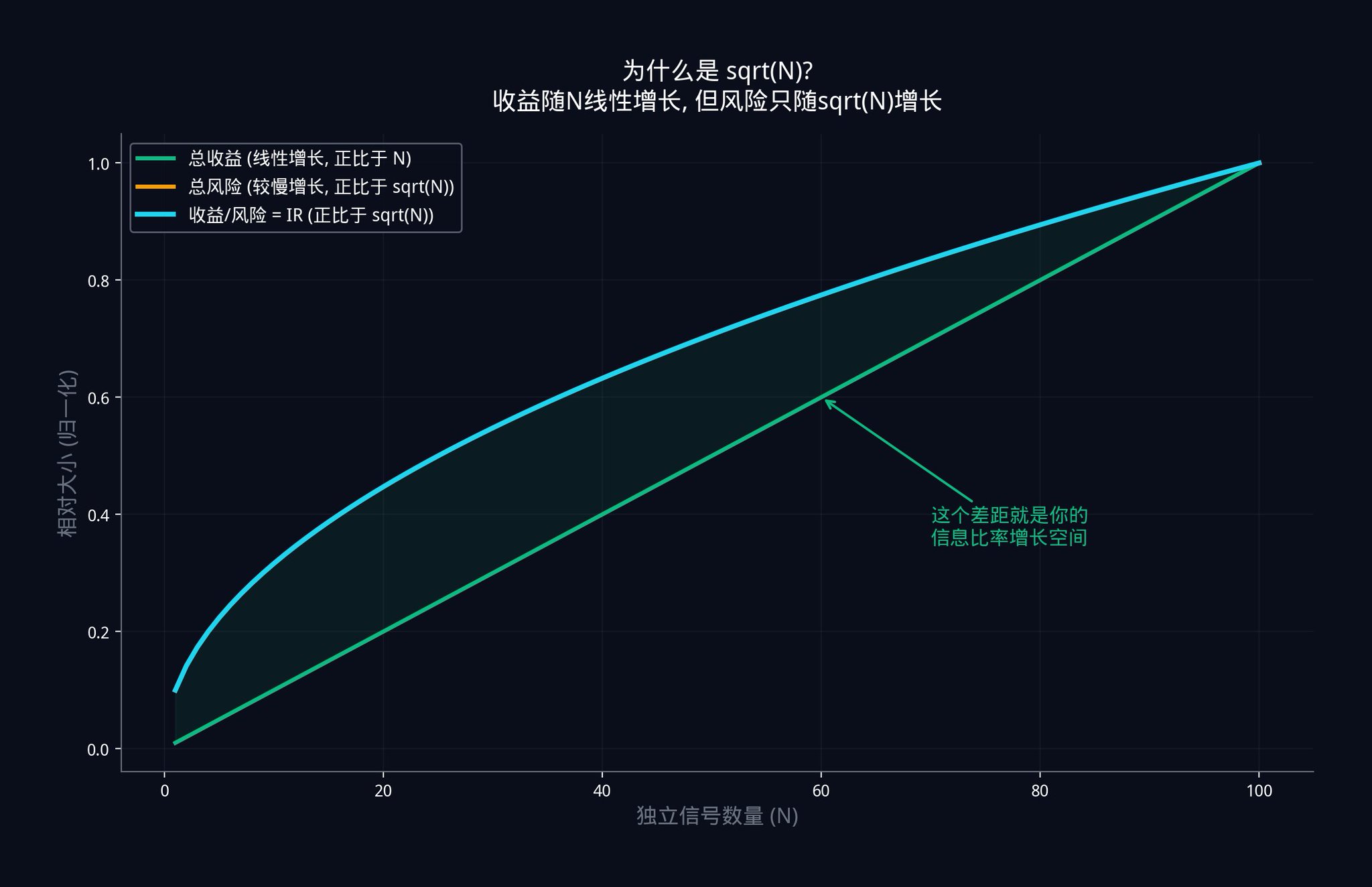
上圖展示了這個關係。綠色的線是總收益,它隨著訊號數量線性增長。藍色的線是資訊比IR,它隨著√N 成長。收益在漲,風險也在漲,但收益漲得比風險快。兩條線之間的差距越來越大。這個差距,就是你透過增加獨立訊號所獲得的交易優勢。
讓我們來算一筆具體的賬,感受一下這個公式的威力。
· 場景A:你有50 個弱訊號。每個訊號都非常弱,IC 只有0.05。那麼你組合後的系統IR = 0.05 x √50 = 0.05 x 7.07 = 0.354。
· 場景B:另一個交易員有1 個強訊號。他苦苦尋覓,終於找到了一個非常強大的單一訊號,IC 高達0.10(是你的兩倍準)。但他只有一個訊號,所以他的IR = 0.10 x √1 = 0.10。
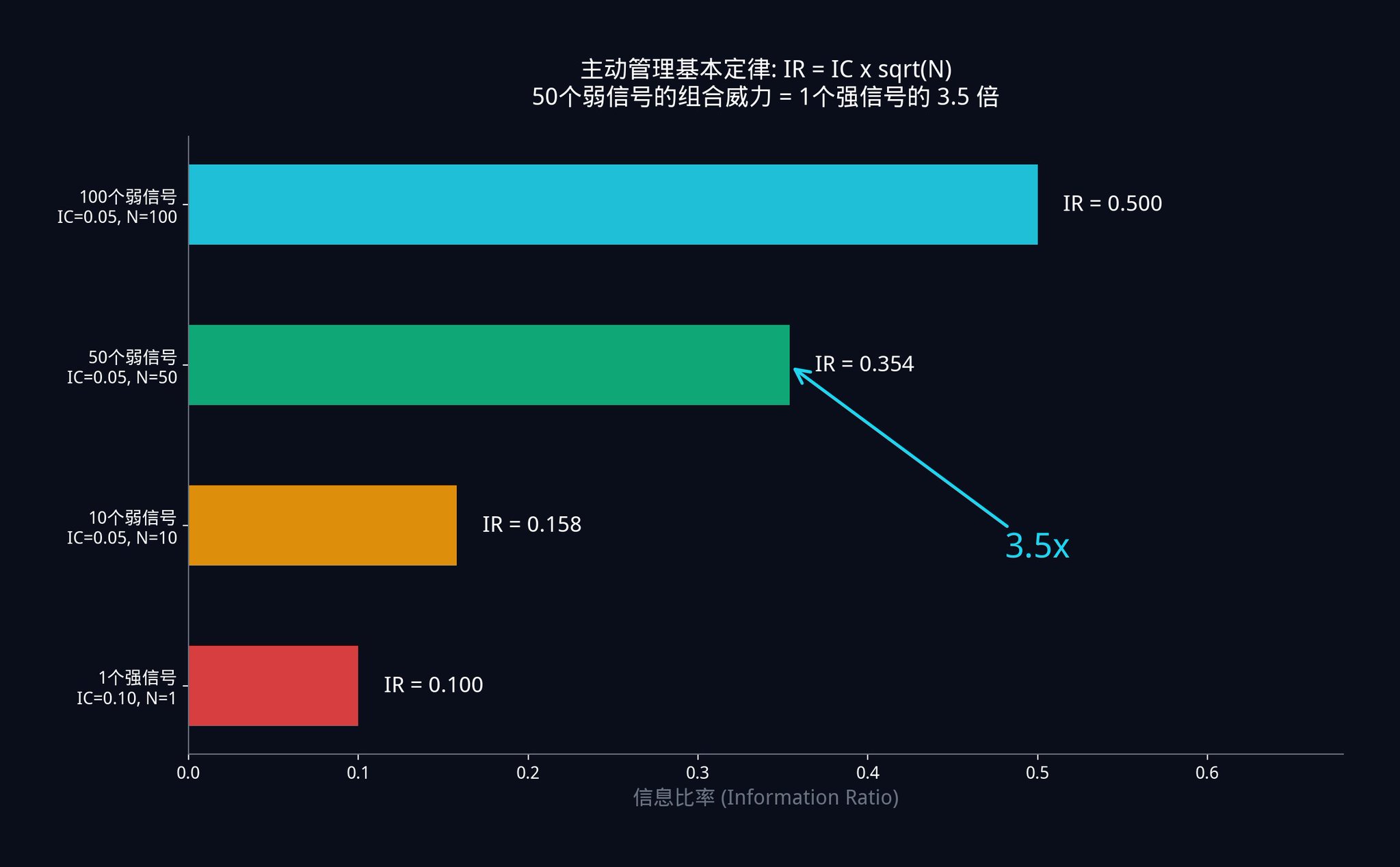
你用50 個準確率只有他一半的「垃圾訊號」,組合出來的系統表現,是他那個「神級訊號」的3.5 倍。
這就是為什麼對沖基金寧願僱用幾百個研究員去挖掘幾百個微弱的訊號,也絕對不會把所有賭注押在一個「完美指標」上。數學已經證明了,尋找完美訊號是一條死路。
正確的方向是:收集盡可能多的獨立弱訊號,然後用數學把它們組合起來。
這個想法其實也是我們做insiders.bot 錢包篩選器時的核心靈感。與其讓用戶去找一個「完美的聰明錢錢包」,不如幫用戶同時追蹤幾百個策略不同,看的方向也不同的高勝率錢包,把這些弱信號疊加起來,才能實現真正準確的結論
進階練習1:
誠實地評估一下你現在最依賴的那個交易訊號。它的IC 是多少?如果你從來沒有系統地測量過它,表示你一直在盲飛。
動手試試,用Python 寫一個簡單的回測腳本。記錄你過去30 天的預測排名和實際結果排名,然後用scipy.stats.spearmanr() 函數計算你的IC。你可能會對結果感到震驚。
如果你想打好機率論的基礎,推薦哈佛大學免費的Introduction to Probability,前6 章就夠了。
了解為什麼要組合訊號,下一步就是搞清楚:去哪裡找這些訊號?
第二部分:五大訊號原料
在第一部分,我們已經定義了什麼是訊號(可量化、有方向、可重複的數據點)。
但一個訊號不需要很強。它只需要在大量觀察中,表現得比拋硬幣稍微準那麼一點點,而這種「稍微準一點」是穩定的、可驗證的。
那麼,機構到底要去哪裡找這些「稍微準一點」的數據點呢?
以下是系統化交易台真正在使用的五個核心訊號類別。

2.1 價格與動量訊號
動量訊號看的是過去一段時間內,價格往哪走、走得多快。
為什麼動量訊號有效?因為市場參與者對新資訊的反應是有慣性的。
· 短期內,大家反應不夠快,導致趨勢會延續。
· 中期,大家又容易反應過度,導致價格回檔。
想像一輛正在加速的火車。即使司機鬆開了油門,火車不會立刻停下來。由於慣性,它也會往前衝一段距離。動量訊號捕捉的就是這段「慣性距離」。
在Polymarket 上怎麼用?
假設一個合約的價格在過去3 天內從$0.40 穩定上漲到$0.55,成交量也在同步放大。這說明有持續的買壓在推動價格。
短期內價格繼續上漲的機率就比較高。不是因為你知道什麼內幕,而是因為市場的慣性還沒消耗完。
在量化研究中,最基礎的動量公式就是計算過去d 天的平均報酬:E(i) = (1/d) x Σ R(i,s)。 d 是你選擇的回看天數,R(i,s) 是合約i 在第s 天的回報。
2.2 均值回歸訊號
均值回歸訊號衡量的是資產偏離其「合理價值」有多遠。
它的核心邏輯是:相關聯的資產之間,價格比例應該是穩定的。當這種關係被打破時,回歸的力量就會把它拉回來。
舉個Polymarket 上的例子。假設有兩個合約:「川普贏得大選」和「共和黨贏得大選」。通常情況下,這兩個機率應該是高度綁定的(因為川普是共和黨候選人)。如果某天「川普贏」的機率暴跌了10 個百分點,但「共和黨贏」的機率只跌了2 個百分點,這就是一個強烈的均值回歸訊號。市場定價出錯了,它們遲早會重新對齊。
均值回歸訊號就像一條橡皮筋。你把它拉得越遠,它彈回來的力量就越大。但要注意,橡皮筋也有被拉斷的時候。所以均值回歸訊號需要配合其他訊號一起使用,而不是單獨依賴。
2.3 波動率訊號
波動率訊號看的是隱含波動率(市場預期的波動幅度)和已實現波動率(實際發生的波動幅度)之間的差距。
為什麼會有這個差距?因為賣出波動率的人(例如賣選擇權的人)承擔了龐大的尾部風險。他們需要額外的補償來涵蓋那些極端情況。這就像保險公司收取的保費總是高於實際賠償的期望值一樣。
在Polymarket 上,波動率訊號可以這樣理解:如果一個合約的價格在$0.45 到$0.55 之間劇烈波動,但基本面並沒有發生任何實質變化(沒有新的新聞、沒有政策變動),那麼這種「虛假的波動」本身就是一個訊號。它告訴你市場參與者在恐慌或興奮,但這種情緒往往是過度的,價格最終會回到合理水平。
2.4 因子訊號
因子訊號是經過數十年學術研究證實的、系統性的收益溢價。最著名的五個因子包括:
· 價值(Value)
· 動量(Momentum)
· 低波動(Low Volatility)
· 套息(Carry)
· 品質(Quality)
每一個因子,都代表了市場在為風險定價時,人類行為或市場結構上的一種持續缺陷。
例如「價值因子」之所以有效,是因為人類天生就喜歡追逐熱門的東西。大家都在討論的合約,往往已經被定價充分了。而那些沒人關注的「冷門合約」,反而更容易有定價偏差。
在Polymarket 上,這意味著你應該花更多時間研究那些交易量不大、但基本面有變化的合約,而不是去追那些已經被幾千人盯著的熱門盤口。這也是為什麼我們在insiders.bot 的首頁,就加了波動率,最新市場,交易量,交易人數等等方便用戶找到這些有著潛在Alpha 的市場的指標。
2.5 微觀結構訊號
微觀結構訊號是高頻交易員的最愛。它看的是訂單簿的深度失衡、買賣價差的動態變化,以及成交量的攻擊性。
這些訊號的生效時間極短,通常在幾分鐘到幾小時之間。但它們能告訴你一件極為重要的事:在價格真正移動之前,那些擁有資訊優勢的聰明錢正在哪裡建倉。
衡量微觀結構最常用的指標之一是有效價差(Effective Spread):
Effective Spread = 2 x |成交價- 中間價|
有效價差越大,表示市場的流動性越差,交易成本越高。當有效價差突然擴大時,往往意味著有知情交易者正在進場,做市商為了保護自己而拉大了價差。
另一個關鍵指標是VPIN(Volume-Synchronized Probability of Informed Trading,成交量同步知情交易機率)。這個指標由Easley、Lopez de Prado 和O'Hara 三位教授在2012 年提出。它透過分析買賣成交量的不平衡程度,來估計市場中有多少交易是由「知情交易者」所驅動的。
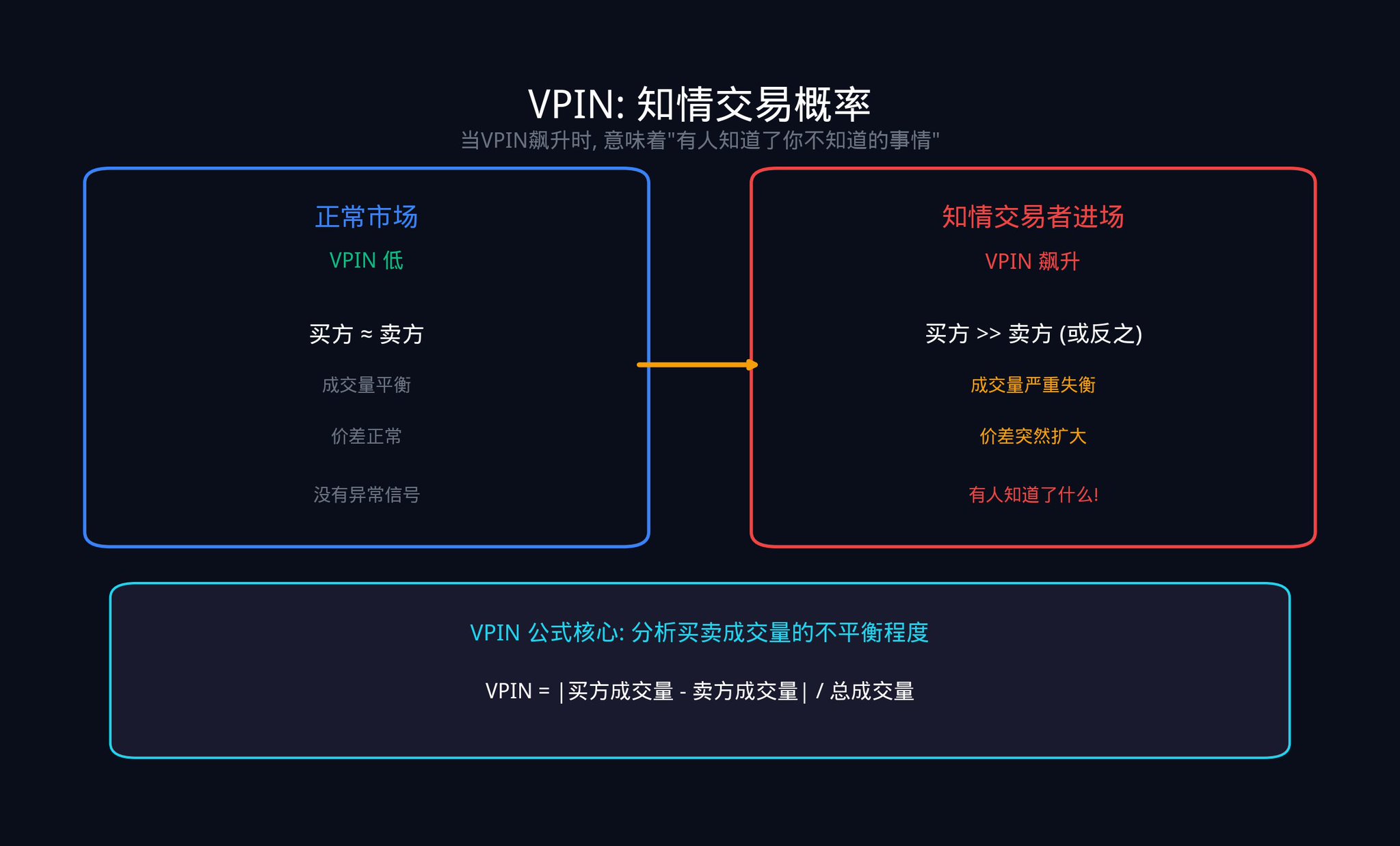
VPIN 的計算邏輯其實很直觀:把成交量切成固定大小的「桶」(例如每1000 筆交易一個桶),然後看每個桶裡買方成交量和賣方成交量的差距有多大。如果差距很大,表示有一方在單方面猛攻,這通常意味著知情交易者在行動。
當VPIN 突然飆升時,往往意味著有人知道了你不知道的事情。 2010 年的「閃電崩盤」(Flash Crash)發生前幾個小時,VPIN 就已經開始異常飆升了。
在Polymarket 上,聰明錢的鏈上行為就是最直接的微觀結構訊號。當一個歷史勝率超過65% 的錢包突然在某個合約上下了一筆大額注單,這就是一個非常有價值的信號。
我們在insiders.bot 的聰明錢瀏覽器和v1.2/v1.3 訊號裡做的事情,本質上就是把這種鏈上的微觀結構訊號即時推送給你。
記住,這五類訊號中的任何一個,單拿出來都不足以形成系統性的優勢。它們只是原料。
接下來,我們要進入最核心的第三部分:那台把原料變成黃金的「組合引擎」。
第三部分:11 步驟組合引擎
這是整篇文章最硬派的部分。這11 個步驟,是機構用來把一堆原始訊號轉換成一個最優權重組合的完整程序。
這11 步驟可以拆解為四個階段:資料準備、消除市場雜訊、提取獨立優勢、分配最終權重。
先重新說一下大背景:假設你有N 個訊號(例如50 個)。每個訊號在過去一段時間內都產生了一系列回報數據(也就是每天賺了多少或損失了多少)。
這個組合系統要做的事情,就是根據這些歷史數據,算出每個訊號應該分配多少資金權重。
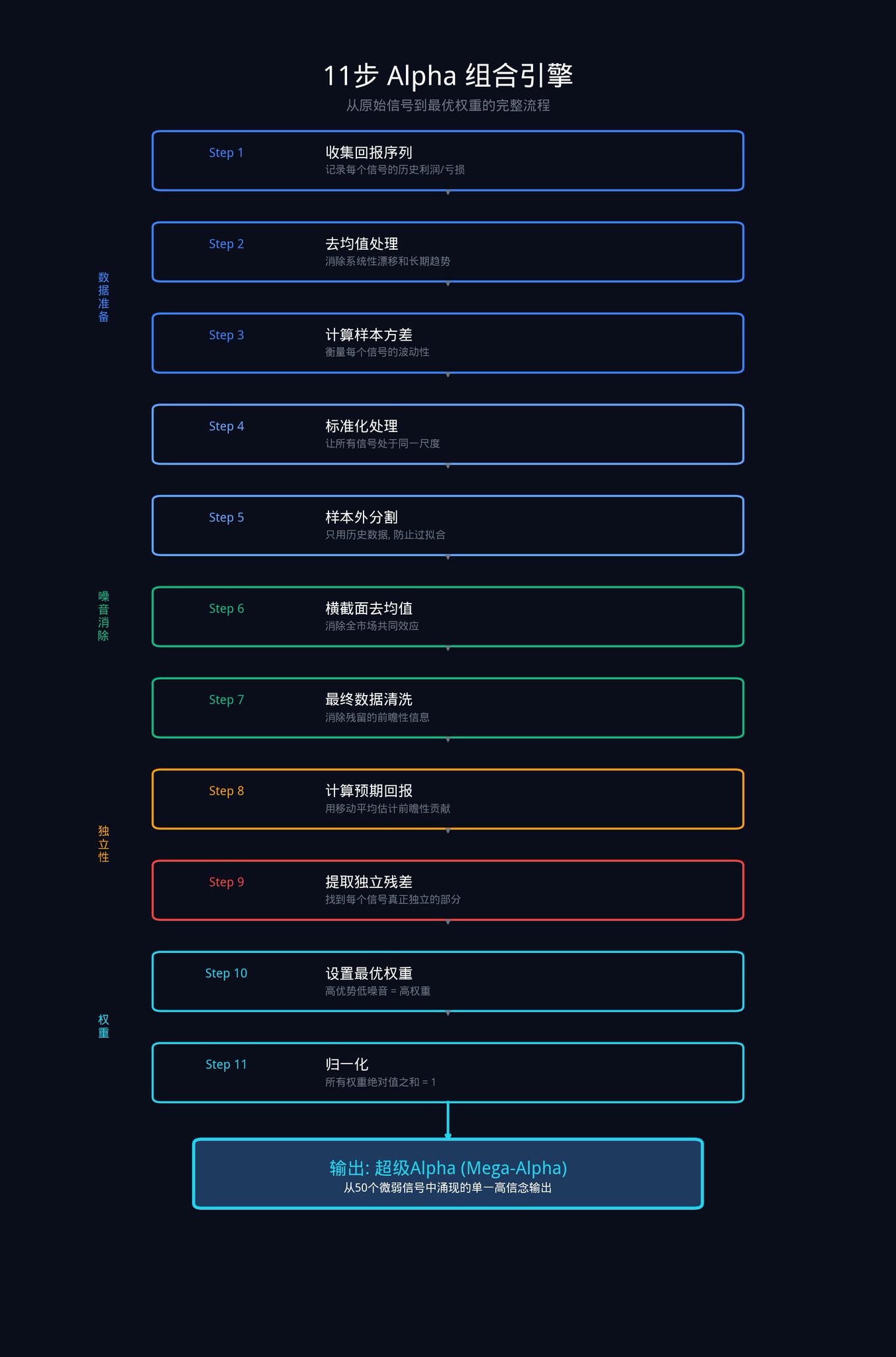
階段一:資料準備
這個階段的目標是讓所有訊號站在同一起跑線上。
步驟1:收集每個訊號的歷史表現
這是最基礎的一步。你需要記錄每個訊號在過去每個時間段內的實際利潤或虧損。
例如,你的動量訊號在過去30 天裡,第1 天賺了2%,第2 天虧了1%,第3 天賺了0.5%...... 把這些數據全部記錄下來。每個訊號都有這樣一列資料。
用數學語言來說,就是收集每個訊號i 在每個時間段s 的回報R(i,s)。
第2 步:消除系統性漂移(去平均值)
把每個訊號的歷史回報,減去它自己的平均回報。
為什麼要這麼做?
舉個例子。
· 假設你有一個「逢低買進」的訊號。過去一年整個加密市場都在大漲,所以這個訊號看起來賺了很多錢。
· 但這真的是訊號的功勞嗎?不一定。可能換成隨便一個策略,在牛市裡都能賺錢。減去平均值之後,你才能看到這個訊號在「排除了市場整體趨勢」之後,到底有沒有真正的預測能力。
具體公式: X(i,s) = R(i,s) - mean(R(i))。
步驟3:計算每個訊號的波動率
這一步衡量的是每個訊號的報酬率有多大的波動性。
· 一個訊號可能平均每天賺0.1% ,但有時候賺5% ,有時候虧4% 。
· 另一個訊號也是平均每天賺0.1%,但波動範圍只在-0.5% 到+0.7% 之間。
· 雖然兩個訊號的平均回報一樣,但第二個訊號明顯更「穩」,更值得信賴。
波動率就是用來量化這種「穩定程度」的。
具體公式:σ(i)² = (1/M) x Σ X(i,s)²。
第4 步:標準化處理
把第2 步驟的結果除以第3 步的波動率。
為什麼需要這一步?因為不同訊號的“單位”不同。動量訊號可能是按百分比計算的,微觀結構訊號可能是按基點(0.01%)計算的,波動率訊號可能是以絕對數值計算的。如果你直接把它們放在一起比較,就像拿蘋果和橘子比大小,毫無意義。
標準化之後,所有訊號都被拉到了同一個尺度。就像把美元、歐元、日圓都換算成同一種貨幣,這樣才能公平比較了。
具體公式:Y(i,s) = X(i,s) / σ(i)。
階段二:消除市場噪音
這個階段的目標是把「市場整體的漲跌」從每個訊號的表現中剝離出來,只留下訊號自身的真正能力。
第5 步:樣本外分割
在計算權重時,只使用歷史數據,丟棄最近的觀察值。
這一步是為了防止「過度擬合」。
什麼是過度擬合?打個比方,一個學生把過去十年的考試真題全部背了下來,模擬考試次次滿分。但一到真正的考試,換了新題,他就完全不會做了。他不是在「理解知識」,而是在「背答案」。
在量化交易中,過度擬合的危害更大。你的模型可能在歷史數據上表現完美,但一到實盤就拉胯。樣本外分割就是確保你的模型是在「學習規律」,而不是在「記憶歷史」。
具體做法是:
把你的數據分成兩個部分。
· 用前80% 的資料來訓練模型(計算權重),
· 用後20% 的資料來驗證模型是否真的有效。
· 如果模型在後20% 的資料上也能賺錢,表示它學到了真正的規律。
第6 步:橫斷面去平均值(Cross-sectional Demeaning)
在每一個時間點,把每個訊號的表現,減去所有訊號在那個時間點的平均表現。
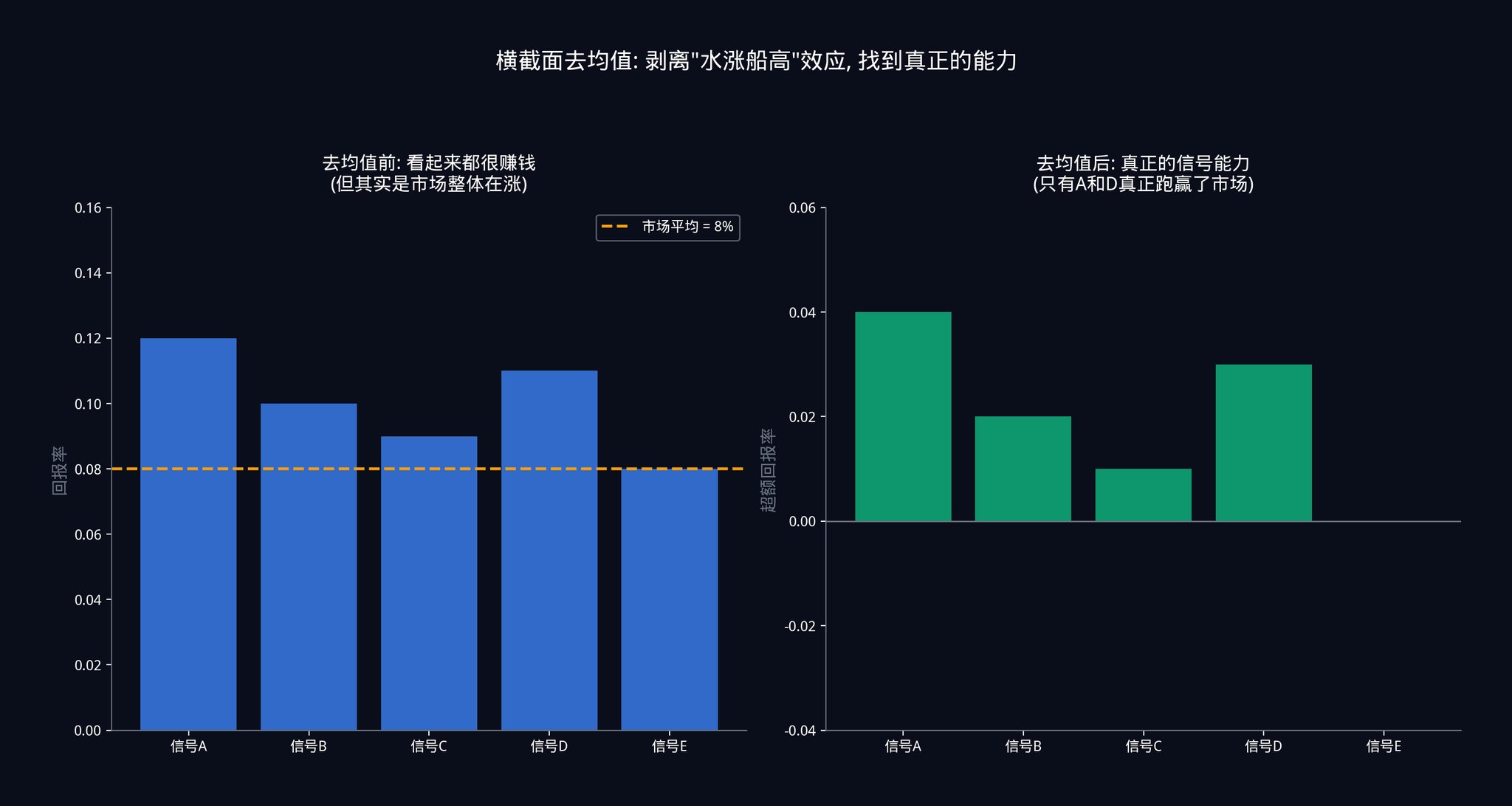
這一步非常關鍵,這裡用一個具體的場景來解釋。
假設今天聯準會突然宣布降息。整個市場暴漲。你的50 個訊號可能同時發出了「買進」指令,而且每個訊號看起來都賺了錢。
如果你不做橫斷面去均值,你會以為這50 個訊號都很準。但實際上,這只是「水漲船高」的效應。市場整體在漲,你的訊號不管怎麼預測都能賺錢。這不是訊號的能力,而是市場的恩賜。
減去所有訊號的平均表現之後,你才能看清真相:在大家都賺錢的日子裡,到底哪個訊號賺得比別人更多?在大家都虧錢的日子裡,哪個訊號虧得比別人少?這種「相對錶現」,才是訊號真正的能力。
更具體的說:Λ(i,s) = Y(i,s) - (1/N) x Σ Y(j,s)。
*注意,第2 步的「去均值」和第6 步的「橫斷面去均值」是不同的。第2 步是對每個訊號自己的時間序列去均值(消除長期趨勢)。步驟6 是在每個時間點上,對所有訊號之間去均值(消除市場整體效應)。兩者缺一不可。
第7 步:最終資料清洗
這是一個最終的數據衛生步驟。它確保在你的資料序列中,沒有殘留任何「前瞻性資訊」。
什麼是前瞻性資訊?就是你在做決策的那個時間點上,不可能知道的未來數據。例如,你不能在周一用周五的收盤價來做決策。這聽起來像是常識,但在複雜的資料處理流程中,這種「資料外洩」比你想像的更容易發生。
階段三:擷取獨立優勢
這個階段是整個引擎的靈魂。它要做的事情是:從每個訊號中,提取出它獨一無二的預測能力,剔除它和其他訊號重複的部分。
第8 步:計算預期回報
使用移動平均線,計算每個訊號在未來的預期貢獻。
具體來說,就是取每個訊號最近d 天的平均回報,作為它未來表現的預測。然後把這個預測值標準化(除以波動率),讓不同訊號的預期報酬率可以直接比較。
公式上來說:
· E(i) = (1/d) x Σ R(i,s)
· E_norm(i) = E(i) / σ(i)。
步驟9:提取獨立殘差(Orthogonalization,正交化)
這是整個11 步驟中最關鍵的一步。
假設你有兩個訊號。
· 訊號A 是「看天氣預報」
· 訊號B 是「看路人有沒有帶傘」。
這兩個訊號都能預測今天會不會下雨。
但問題是,路人帶傘很可能也是因為看了天氣預報。所以訊號A 和訊號B 之間有大量的資訊重疊。如果你同時使用它們,你以為你有兩個獨立的訊號,但實際上你只有一個訊號(天氣預報)被表達了兩次。
步驟9 做的事情,就是把這種資訊重疊剔除掉。
具體怎麼做?對每個訊號的預期回報E_norm(i),用其他所有訊號的歷史資料Λ(i,s) 做一個迴歸分析。迴歸的意思是:用其他訊號來「解釋」這個訊號。能被解釋的部分,就是重疊的部分,丟掉。解釋不了的部分,就是這個訊號獨一無二的貢獻,保留。
這個「解釋不了的部分」,在數學上叫做殘差(Residual),記作ε(i)。
如果你學過線性代數,這就是Gram-Schmidt 正交化的一個應用。如果你沒學過也沒關係,你只需要記住一件事:第9 步是在找出每個訊號真正獨一無二的、不可取代的那部分預測能力。
階段四:分配最終權重
第10 步:設定最優權重
權重的計算公式為:w(i) = η x ε(i) / σ(i)。
這個公式說的是:每個訊號的權重,等於它的獨立貢獻ε(i)(第9 步算出來的),除以它的波動率σ(i)(第3 步算出來的),再乘以一個縮放係數η。
這意味著什麼?引擎會自動給那些「獨立貢獻大」且「表現穩定」的訊號分配更高的權重。而那些「噪音大」或「只會跟風」的訊號,會被自動降權。
這一切都是數學自動完成的,不需要任何主觀判斷。你不需要憑感覺決定「這個訊號應該要佔多少比例」。公式會告訴你最優答案。
第11 步:歸一化
最後一步,調整縮放係數η ,使所有權重的絕對值總和等於1。
這確保了你的總資金分配是100%,不會在不知不覺中加上槓桿。如果你不做這一步,你可能會發現你的權重加起來是150%,代表你在用1.5 倍槓桿交易,而你自己完全沒有意識到。
用數學語言來說:設定η 使得Σ|w(i)| = 1。
這11 步的最終輸出,就是你的N 個訊號中每一個的最終權重。當你把這些微弱的訊號以權重組合在一起時,你就得到了一個超級Alpha(Mega-Alpha)。一個高勝率、高信念的單一輸出。
進階練習2:
如果你在目前的訊號堆疊上運行這個程序,你會對哪些訊號獲得了高權重、哪些獲得了低權重感到驚訝嗎?答案會告訴你,你對自己正在運行的東西的獨立性結構了解得有多好。
如果你想深入理解這套矩陣運算背後的邏輯,強烈建議去看MIT 免費公開課程Linear Algebra 中關於正交化的章節。 Gilbert Strang 教授講得很清楚。
第四部分:獨立性陷阱
組合引擎解決了一個問題。這個問題在你一次只看一個訊號時是隱形的,但一旦你理解了數學,它就變得無所不在。
讓我們回到第一部分提到的主動管理基本定律:
IR = IC x √N
還記得這三個字母代表什麼嗎? IR 是你整個系統的「風險調整後效益」(也就是你的策略有多穩)。 IC 是你單一訊號的平均準確度。 N 是你組合的獨立訊號的數量。
現在我要強調一個很多人忽略的關鍵字:獨立。
這裡的N,不是你訊號堆疊中訊號的總數。它是有效獨立訊號的數量。這兩個數字可能差得非常遠。
為什麼?因為訊號之間會「偷偷地」相互關聯。
一個動量訊號和一個平均值回歸訊號,在性質上看起來是完全相反的(一個追漲,一個抄底)。但在某些市場環境下,兩者可能在同一時間、同一方向對同一個宏觀經濟新聞做出反應。
· 例如,聯準會突然升息,動量訊號說「趨勢向下,賣出」,均值回歸訊號也說「偏離均值太遠了,但方向也是向下」。
· 在這個時刻,兩個看似獨立的訊號,實際上在表達同一個觀點。
如果你給它們相等的權重,你以為你在兩個獨立的觀點之間分散了風險。但實際上,你是在同一個觀點上加了雙倍的部位。

這就是為什麼第三部分中的第6 步(橫截面去均值,也就是在每個時間點上減去所有信號的平均表現,消除“水漲船高”效應)和第9 步(提取獨立殘差,也就是通過回歸分析剔除信號之間的信息重疊,只保留每個信號獨一無二的貢獻)如此重要。它們的作用就是識別並消除訊號之間隱藏的共享成分。
運行50 個相關的訊號,可能只會為你帶來10 到15 個獨立訊號的分散化效果。只有當你的訊號建立在真正獨立的資訊來源上,並且正確地運行了組合引擎,你才能獲得全部50 個訊號的完整好處。
這在實際操作中意味著什麼?
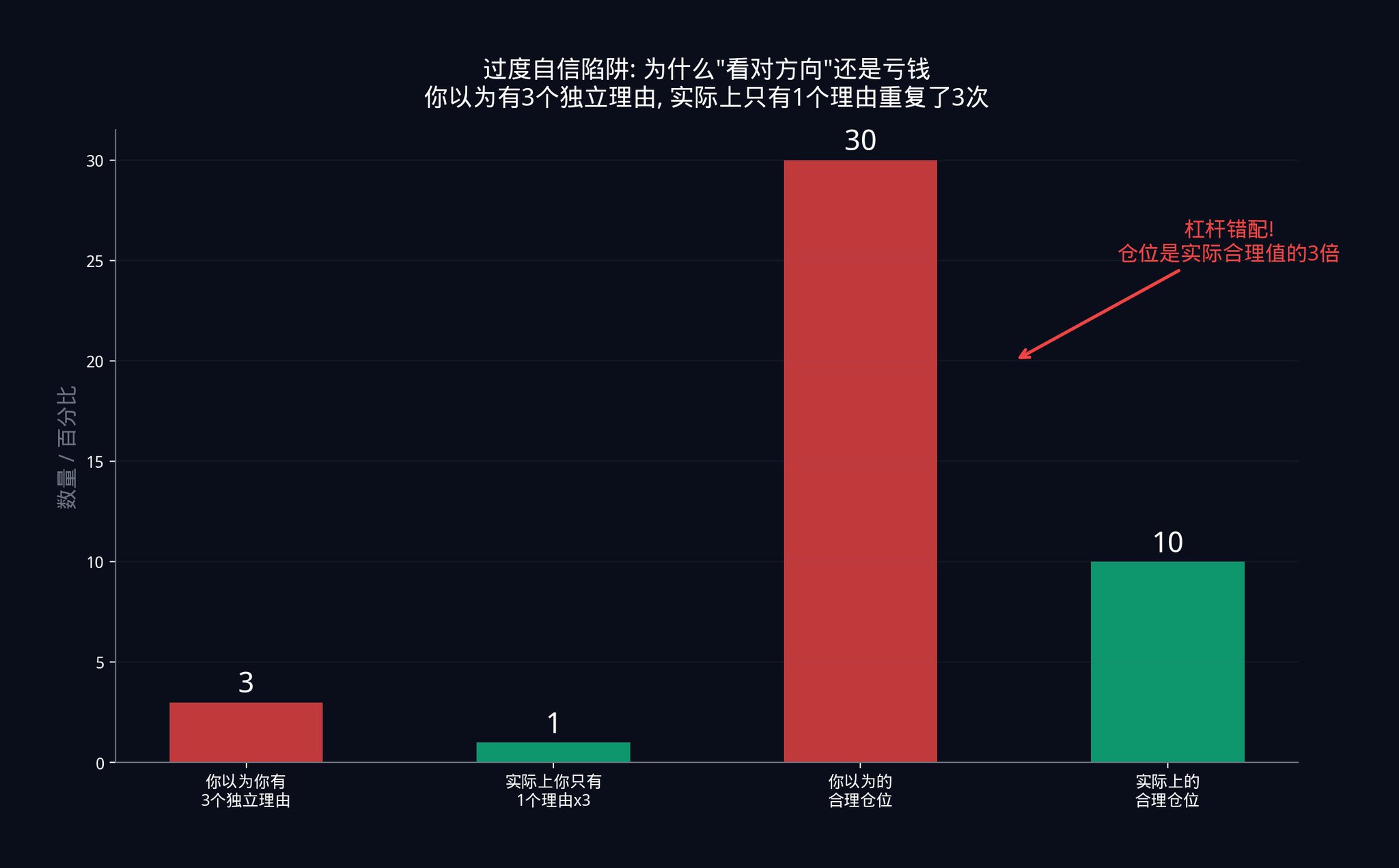
· 假設一個交易者認為自己在運作20 個獨立訊號。他依照20 個獨立訊號來計算部位大小。但實際上,由於訊號之間的隱藏相關性,他只有6 個有效獨立訊號。
· 20 個獨立訊號支撐的部位大小,對於6 個訊號來說太大了。大了多少?大了20/6 ≈ 3.3 倍。他的實際槓桿是他以為的3 倍以上。
這種槓桿錯配,是大多數系統化策略爆倉背後的真正原因。交易員在方向上是對的,但在規模上是錯的。他看對了市場會漲,但他下的注太大了。一個正常的回調就足以把他清算出局。
組合引擎強制進行誠實的核算。它不會讓你自欺欺人。它會告訴你,你的訊號堆疊的真實獨立性結構是什麼樣的。然後根據真實情況來分配權重,而不是根據你以為的情況。
那些在分析正確的交易上持續虧損的交易員,幾乎總是輸給了他們沒有測量的相關性。他們以為自己有三個獨立的理由感到自信。實際上他們只有一個理由被表達了三次。而倉位卻是用三個理由來定的。
組合引擎從結構上消除了這種失敗模式。
進階練習3:
拿出你現在正在使用的所有訊號,兩兩配對,計算它們之間的相關係數。你可以用Python 的numpy.corrcoef()函數。如果任何一對訊號的相關係數超過0.5 ,那麼它們在數學上就不是獨立的。你需要重新審視你的訊號堆疊。
推薦閱讀Marcos Lopez de Prado 的Advances in Financial Machine Learning,特別是關於特徵重要性和正交化的章節。這本書是現代量化方法的必讀之作。
第五部分:在Polymarket 上落地
前四個部分的所有內容,都是在股票和多元資產系統化交易的背景下建立的。好消息是,這套數學可以直接遷移到預測市場。只需要做一個替換:你不是在組合關於「預期回報」的訊號,而是在組合關於「預期機率」的訊號。
在預測市場中,每個訊號產生的不是一個回報估計,而是一個隱含機率估計。
5.1 五種機率訊號
第一,跨平台定價訊號:如果Polymarket 上某個合約的YES 價格是$0.45,但Betfair 上同一個事件的賠率暗示機率是52%,那麼這7 個百分點的價差就是你的訊號。兩個平台在給同一個事件定不同的價,至少有一個是錯的。
第二,校準訊號:對4 億筆Polymarket 歷史交易的研究發現了一個系統性的偏差:定價在5% 到15% 之間的合約,最終解決為YES 的比例只有4% 到9%。這意味著市場系統性地高估了低機率事件發生的可能性。這個偏差是穩定的、可重複的,因此它是一個有效的訊號。
第三,貝葉斯更新訊號:這是量化交易的靈魂工具。它回答的核心問題是:當你獲得了新的數據,你該如何精確地更新你原有的信念?
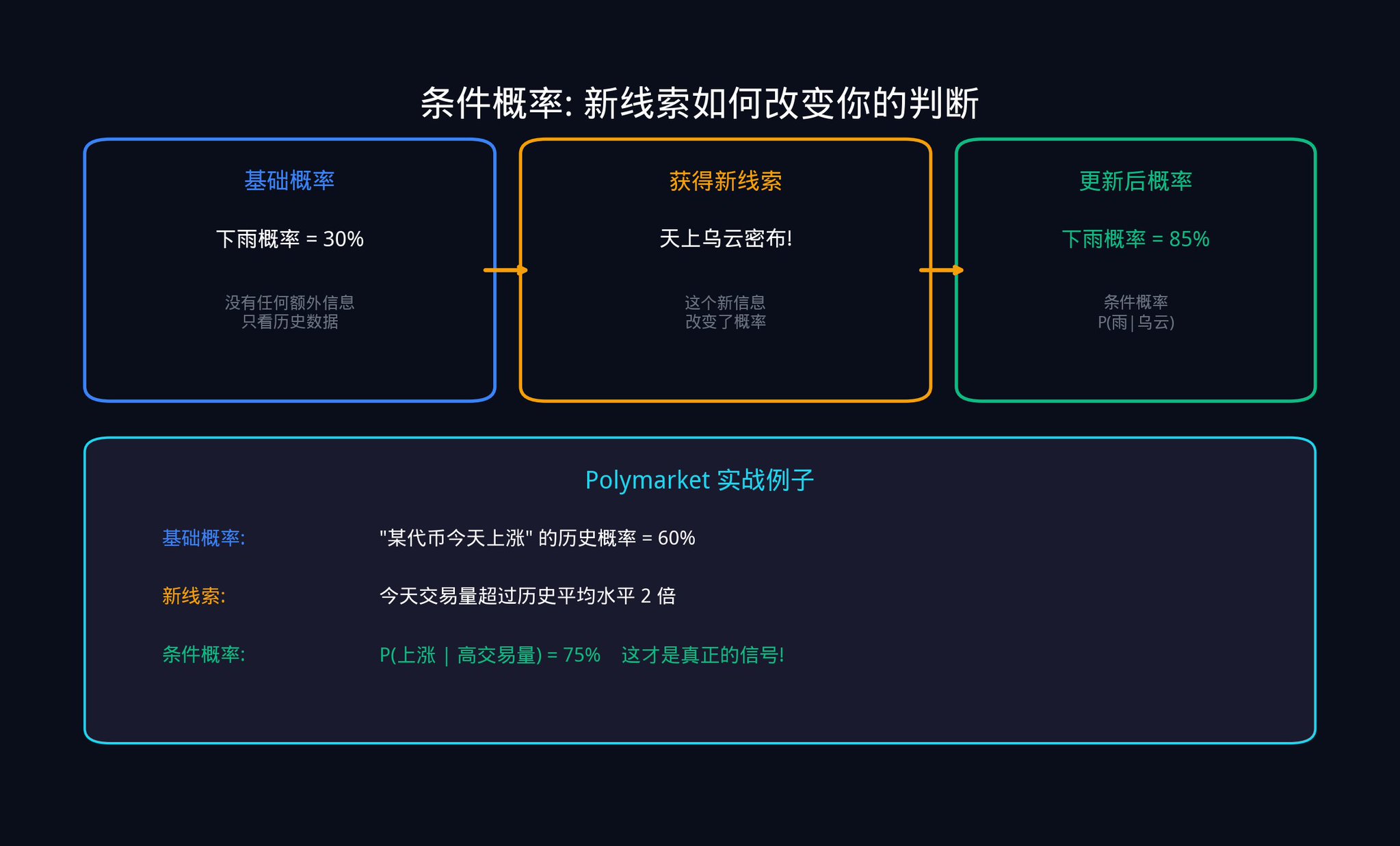
讓我用一個具體的例子來解釋貝葉斯更新。
假設你專注於一個Polymarket 合約:「某國會法案是否會在本月通過?」。目前市場價格是$0.40,也就是市場認為通過的機率是40%。這是你的先驗機率(Prior)。
突然,一則新聞出來了:法案獲得了一位關鍵參議員的公開支持。
你不能直接把機率改成80%。你需要用貝葉斯公式來精確計算。
貝葉斯公式是:
P(透過|支援) = P(支援|通過) x P(通過) / P(支援)
翻譯成大白話就是:
「在已知這位參議員公開支持的情況下,法案通過的機率」=「如果法案真的會通過,這位參議員公開支持的機率」x「法案通過的先驗機率」/「這位參議員公開支持的總機率」
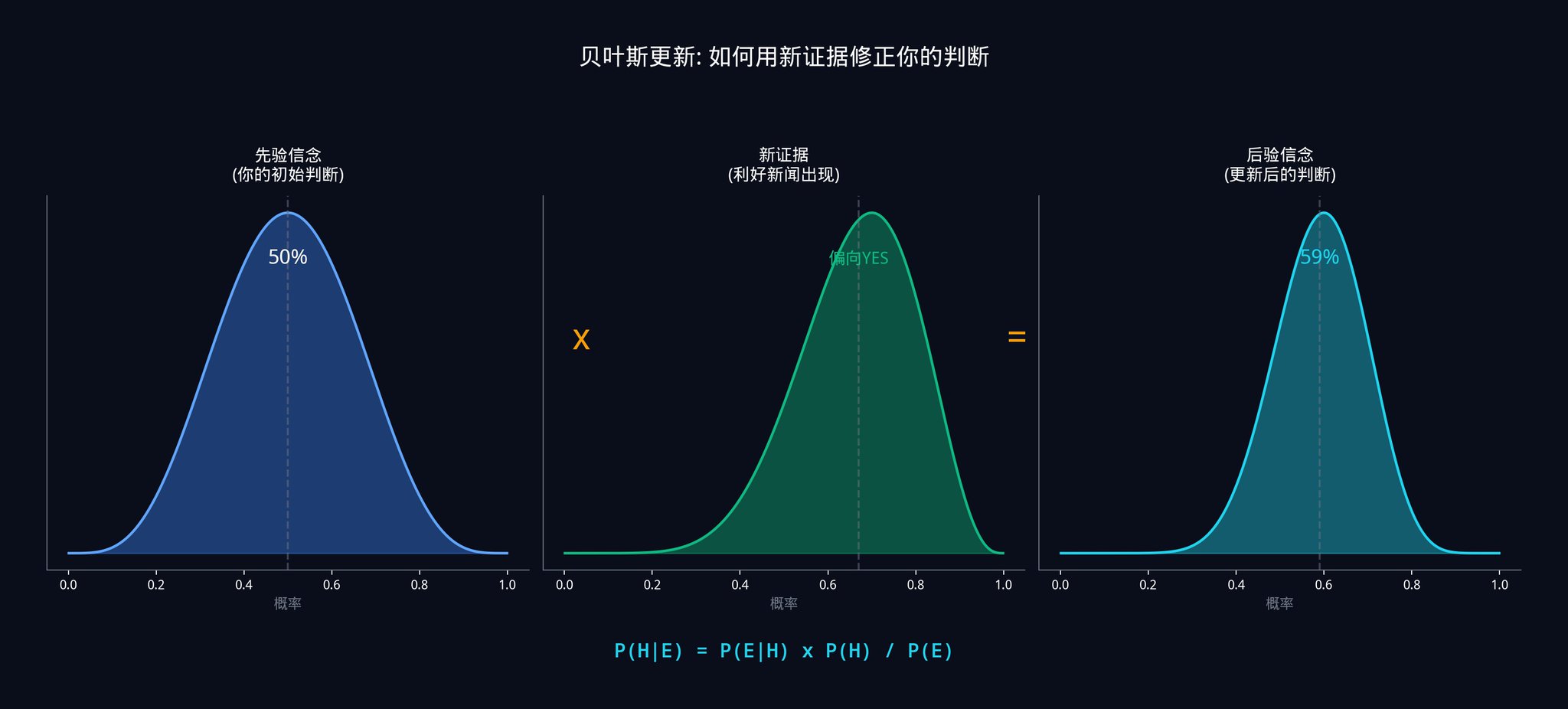
假設你估計:
· 如果法案真的會通過,這位參議員公開支持的機率是80%(因為他通常會在有把握時才表態)
· 如果法案不會通過,這位參議員公開支持的機率是20%(他偶爾也會站錯隊)
· 法案通過的先驗機率是40%
那麼:
· P(支援) = 0.80 x 0.40 + 0.20 x 0.60 = 0.32 + 0.12 = 0.44
· P(透過|支援) = 0.80 x 0.40 / 0.44 = 0.32 / 0.44 = 72.7%
所以,在看到這則新聞之後,你應該把法案通過的機率從40% 更新到72.7%。如果市場價格還停留在$0.50,你就有了一個22.7% 的優勢。
貝葉斯更新的精髓在於,你不是在「猜」一個新機率,而是在用數學精確地計算它。你的每一次判斷都有據可依。
第四,微觀結構訊號:使用VPIN(我們在第二部分講過的「知情交易機率」指標,它透過分析買賣成交量的不平衡程度來判斷是否有知情交易者在行動)和有效價差,根據知情訂單流的方向暗示一個機率。
第五,動量訊號:根據合約接近解決時的價格變動速率和方向暗示一個機率。
5.2 從訊號到下注:完整流程
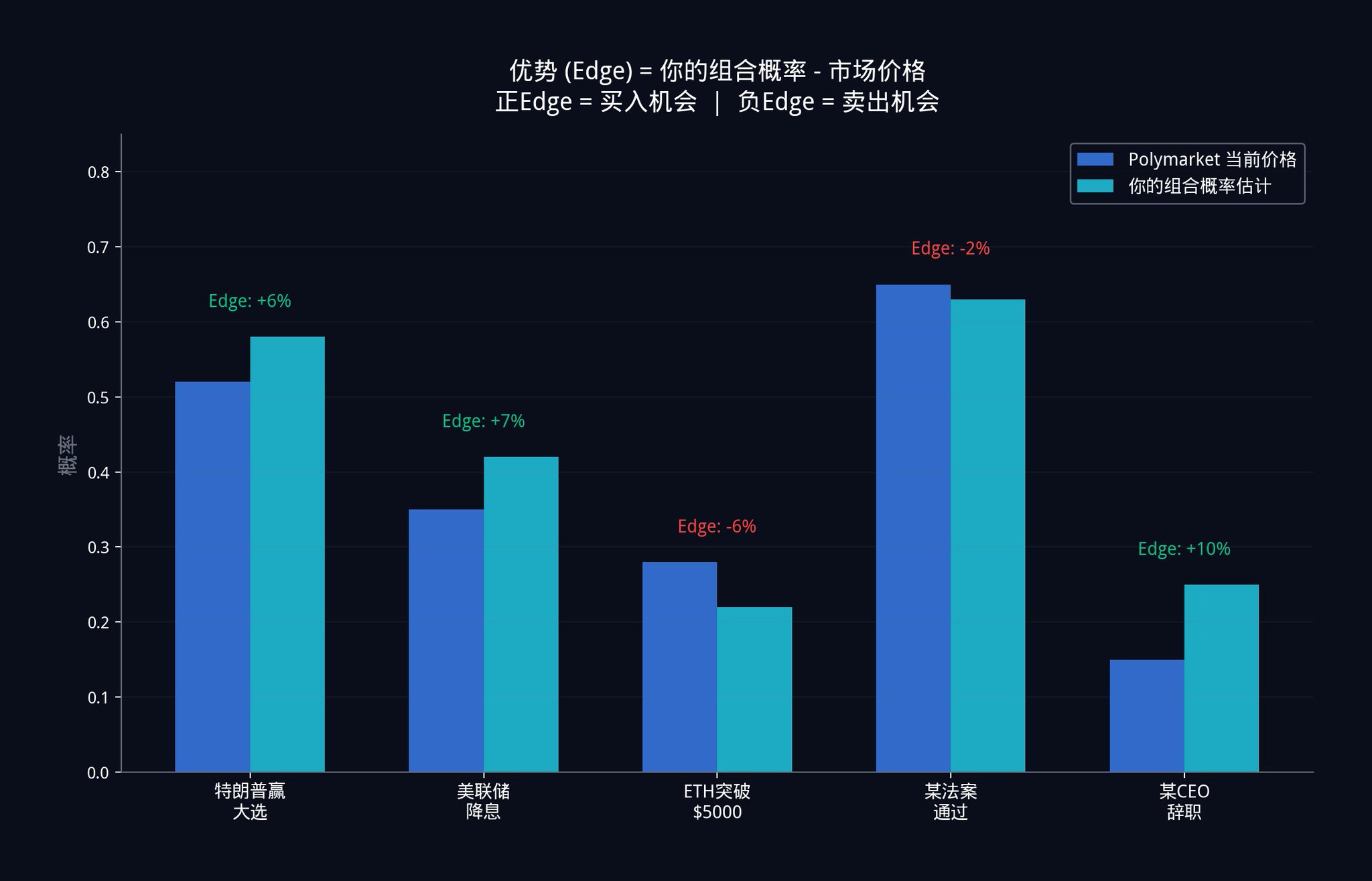
將這些隱含機率估計中的每一個,完全按照第三部分描述的11 步組合引擎運行。輸出是一個單一的加權組合機率估計。這個估計根據每個訊號的獨立貢獻(還記得第9 步的正交化嗎?就是剔除訊號之間的資訊重疊,只保留獨一無二的部分),分配了數學上最優的權重。
那個組合估計和當前Polymarket 價格之間的差距,就是你的優勢(Edge)。
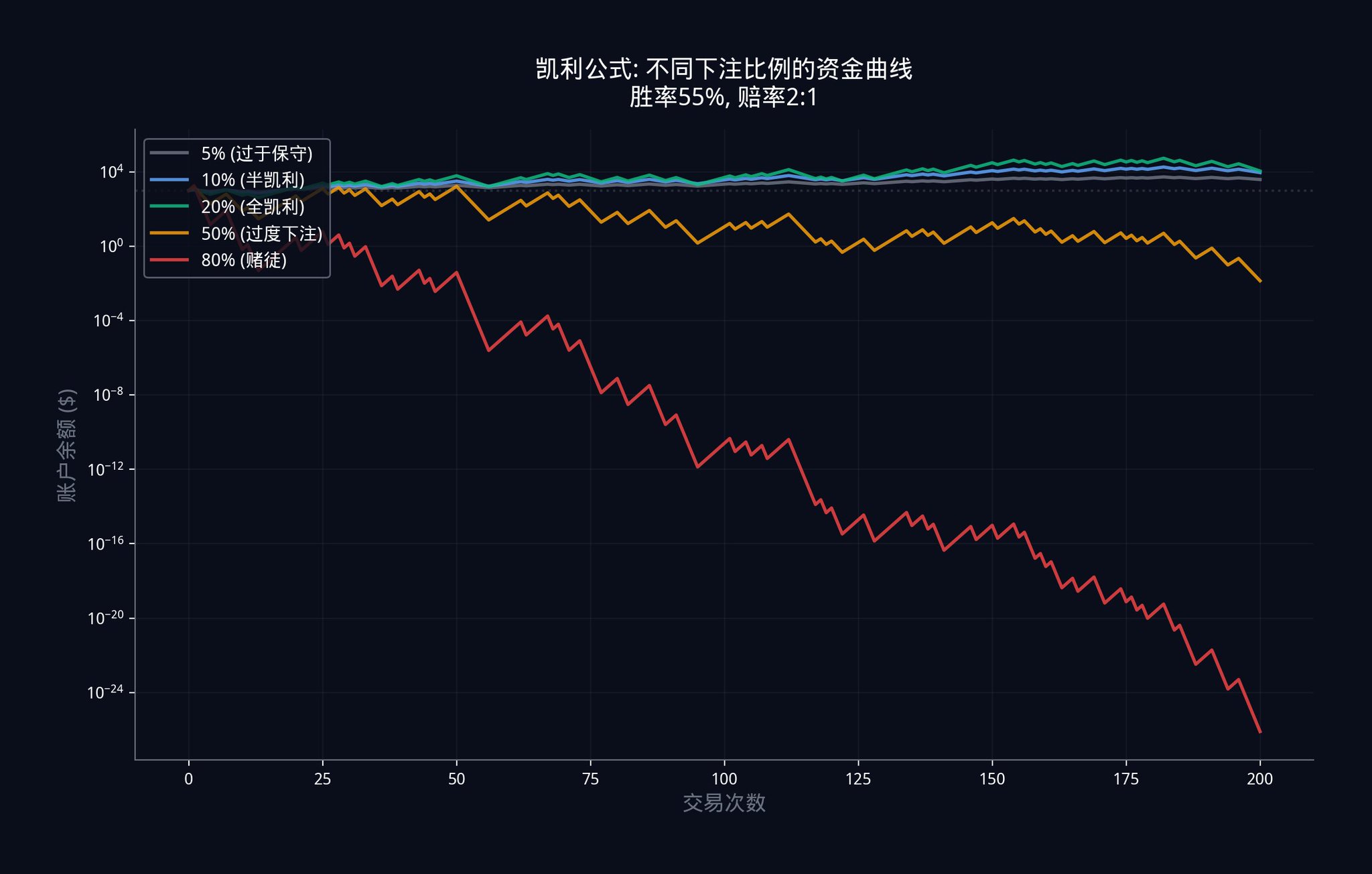
5.3 凱利公式:你到底該下注多少?
有了優勢之後,最重要的問題來了:你該拿多少錢去下注?
下注太少,你浪費了優勢,賺得不夠多。下注太多,一次判斷失誤就可能讓你回到原點。
機構使用的是凱利公式(Kelly Criterion)。標準的凱利公式是這樣的:
f_kelly = (pxb - q) / b
其中p 是你估計的勝率(你的組合機率),q = 1 - p 是敗率,b 是賠率。
在Polymarket 上,賠率b 可以直接從價格計算出來:b = (1 / 市場價格) - 1。例如市場價格是$0.40,那麼賠率b = (1/0.40) - 1 = 1.5。
假設你的組合模型告訴你真實機率是60%(也就是p = 0.60),而市場價格是$0.40(賠率b = 1.5)。那麼標準凱利建議你下注:
f_kelly = (0.60 x 1.5 - 0.40) / 1.5 = (0.90 - 0.40) / 1.5 = 0.50 / 1.5 = 33.3% 的經費。
但標準凱利有一個致命的假設:它假設你的勝率估計是100% 準確的。在現實中,你的估計總是會有誤差。所以機構使用的是經驗凱利公式,它加入了一個「不確定性懲罰」
f_empirical = f_kelly x (1 - CV_edge)
其中CV_edge 是你的優勢估計的變異係數(Coefficient of Variation)。它衡量的是你的估計有多不確定。 CV_edge 越大,表示你越不確定,公式就會自動減少你的下注金額。
怎麼計算CV_edge?你可以用蒙特卡羅模擬。簡單來說,就是用你的模型跑幾千次模擬,看看你的優勢估計在不同場景下會改變多少。變化越大,CV_edge 越高,就該下注越少。
接著上面的例子。如果你的CV_edge = 0.3(也就是你的估計有30% 的不確定性),那麼經驗凱利建議你下注:
f_empirical = 33.3% x (1 - 0.3) = 33.3% x 0.7 = 23.3% 的經費。
在實際操作中,許多機構甚至只下「半凱利」(Half-Kelly),也就是再除以2,變成大約12%。因為長期來看,少賺一點遠比爆倉好很多。
5.4 完整的Polymarket 交易管道
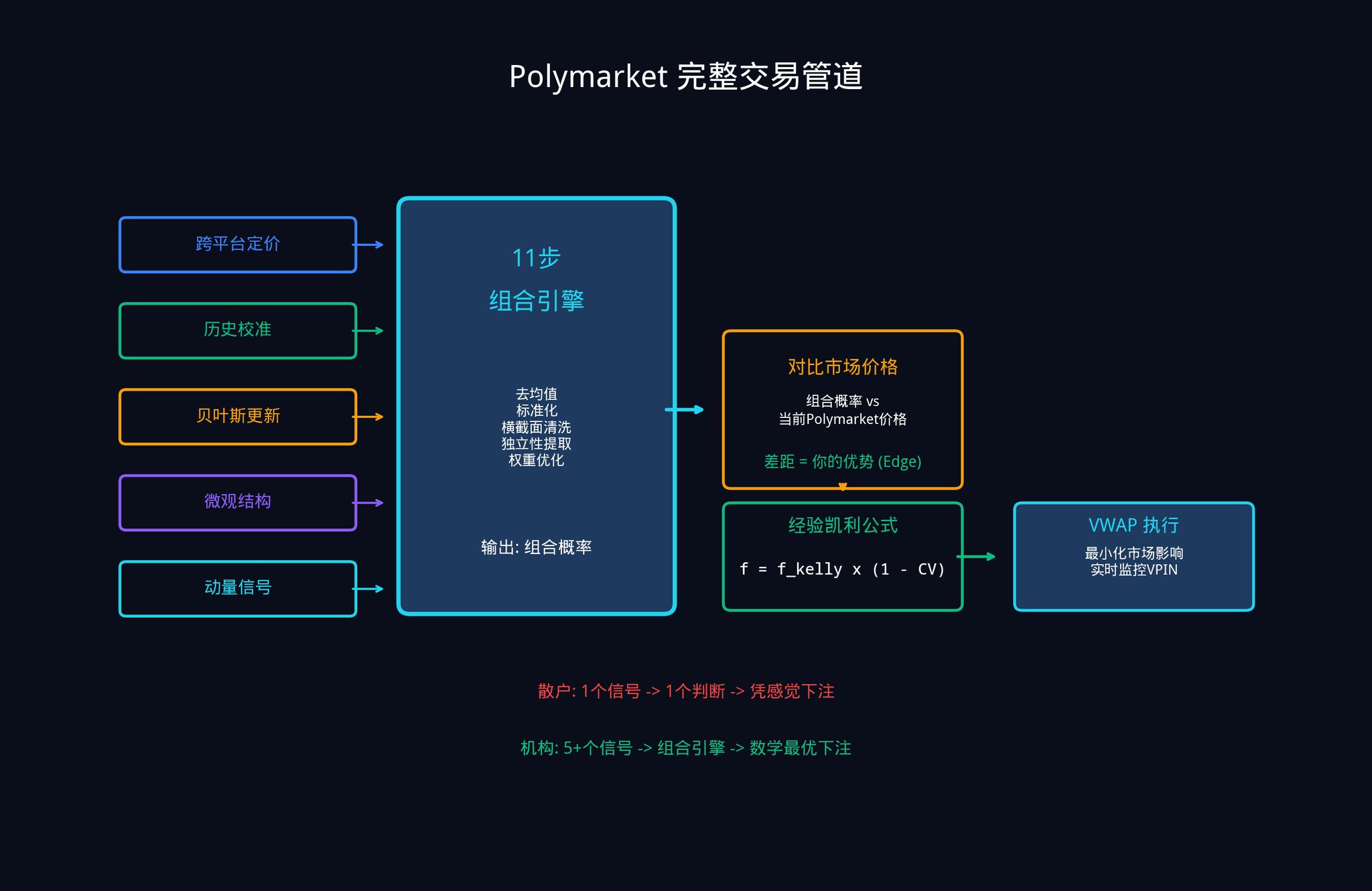
把所有東西串在一起,完整的工作流程是這樣的:
1. 五個或更多輸入訊號,每個產生一個隱含機率估計
2. 透過11 步驟組合引擎處理
3. 輸出單一的加權組合機率
4. 與當前市場價格比較,計算你的優勢(Edge)
5. 用經驗凱利公式確定下注規模
6. 用VWAP(成交量加權平均價格)優化執行,減少你的大額訂單對市場價格的衝擊
7. 即時監控VPIN 變化,當知情交易者變得活躍時及時調整策略
這個框架對於預測市場特別有價值,原因很簡單:你的絕大多數競爭對手,都在用單一模型、單一資料來源、單一機率估計來交易。而你現在已經知道如何把多個弱訊號組合成一個強訊號。這就是你的結構性優勢。
進階練習4:
選擇一個你關注的Polymarket 合約。試著從至少三個不同的角度(例如跨平台定價、歷史校準、最近的新聞事件)分別估計它的機率。然後簡單地取加權平均,看看你的組合估計和當前市場價格之間有沒有差距。如
果有,恭喜你,你剛剛手動完成了一個簡化版的Alpha 組合。
建議閱讀Edward Thorp 的A Man for All Markets。 Thorp 是凱利公式在投資領域的先驅應用者,這本書用非常通俗的語言講述了他如何用數學在賭場和華爾街都賺到了錢。
第六部分:用insiders.bot 落地這套系統
看到這裡,你可能會想:這套系統的邏輯我懂了,但我一個人怎麼可能從零搭建?
好消息是,你不需要從零開始。
在做insiders.bot (@insidersdotbot) 的過程中,這篇文章裡提到的「主動管理基本定律」(也就是IR = IC x √N ,你整個系統的表現等於單一訊號的準確度乘以獨立訊號數量的平方根)給了我們非常大的啟發。
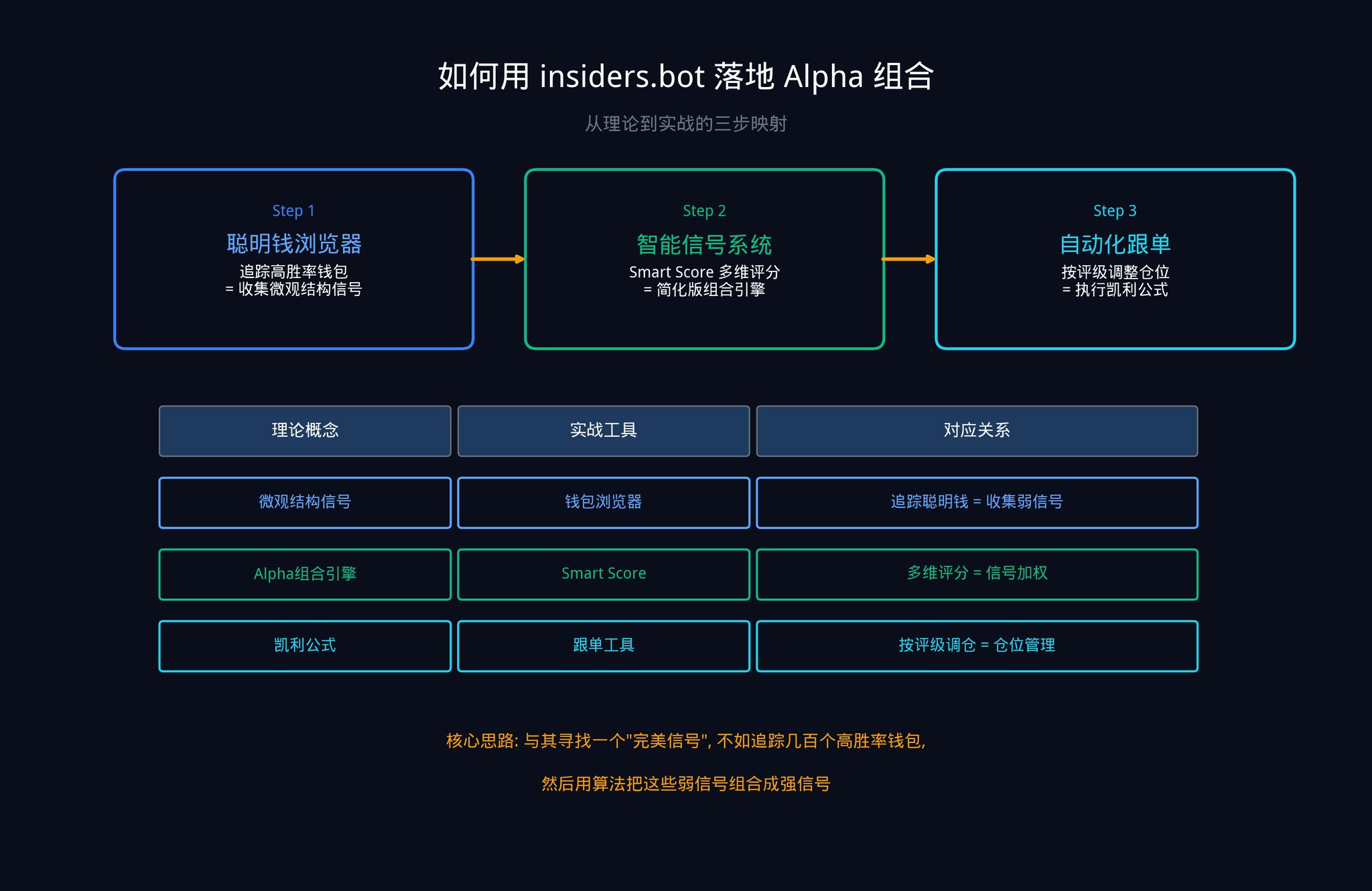
以下是你可以立刻開始操作的三個步驟。
第一步:用聰明錢瀏覽器收集你的訊號原料
打開insiders.bot 的聰明錢瀏覽器。透過篩選面板,你可以按勝率、總盈虧、交易頻率等維度,找到Polymarket 上表現最好的錢包。
這些錢包的每一次異動,就是你的一個「微觀結構訊號」(還記得第二部分講的五大訊號類別中的第五類嗎?)。單一錢包的訊號可能很弱(IC 很低),但當你同時追蹤幾十個錢包時,你就在做文章裡說的「訊號組合」。這正是主動管理基本定律的核心:N 越大,IR 越高。
第二步:用智慧訊號系統實現Alpha 組合
我們的智慧型訊號系統(SIGNALS 標籤頁)本質上就是簡化版的Alpha 組合引擎。當優質錢包進行大筆交易時,系統會產生訊號,並透過Smart Score 綜合歷史勝率、總盈虧、下注穩定性、分類表現、部位規模等多個維度,給予一個強度評級。
LOW :達到基本標準,但交易員優勢一般。對應低IC 訊號,需要更多訊號來組合
MEDIUM :歷史戰績良好,展現出堅定信念。對應中等IC 訊號,可以適度配置
HIGH :來自頂級表現錢包的重註交易。對應高IC 訊號,組合引擎給予高權重
這個評分系統所做的事情,和第三部分11 步引擎中的第10 步(設定最優權重,也就是根據每個訊號的獨立貢獻和穩定性來分配資金比例)本質上是一樣的:根據多個維度的綜合評估,給每個訊號分配不同的權重。
第三步:用跟單工具執行你的凱利公式
當你收到一個HIGH 評級的訊號時,你可以使用我們的自動化跟單工具,設定按比例或固定金額跟單。
記住第五部分講的經驗凱利公式(f_empirical = f_kelly x (1 - CV_edge),也就是你的下注比例要根據你的不確定性來打折):你的估計越不確定,你應該下注越少。
對於LOW 評級的訊號,減少部位。
對於HIGH 評級的訊號,可以適度加大部位。讓數學幫你做決策,而不是讓情緒幫你做決策。
結語
讓我們回到最開始的問題。
單一訊號是微弱的。尋找那個完美的訊號,完全是找錯了方向。
主動管理基本定律(IR = IC x √N)在數學上證明了:組合許多微弱的獨立訊號,勝過尋找一個強訊號。你的資訊比率隨著你部署的真正獨立訊號數量的平方根而增長。
11 步Alpha 組合引擎為你提供了計算最優權重的精確方法。這些權重反映了每個訊號的獨立貢獻,懲罰了噪音,消除了訊號之間的共享變異數。
應用於預測市場,這個框架將五個或更多的隱含機率訊號轉換成一個單一的組合估計。這個估計被證明比任何單一組件都更準確。
配合經驗凱利公式進行部位管理,它產生的部位正確地反映了你實際上應該有多自信,而不是你感覺有多自信。
複利最久的優勢,建立在對你實際知道什麼的最誠實的模型上。
最後,我想讓你思考一個問題:
如果組合了數百個訊號的機構交易台,仍然只能達到0.05 到0.15 之間的資訊係數,那麼任何聲稱能從單一模型中以高置信度持續挑選贏家的系統,到底在說什麼?
進階閱讀與參考文獻
如果你想繼續深入研究,以下是一些進階資料:
入門級:
Harvard Stat 110: Introduction to Probability(免費線上教材)。機率論的基礎,前6 章就夠了。
Edward Thorp, A Man for All Markets。凱利公式先驅的自傳,用通俗語言講述數學如何在賭場和華爾街賺錢。
進階級:
Grinold & Kahn, Active Portfolio Management。量化投資領域的「聖經」,詳細推導了主動管理基本定律。
MIT 18.06 Linear Algebra。 Gilbert Strang 教授的經典課程,理解正交化的最佳資源。
高階級:
Marcos Lopez de Prado, Advances in Financial Machine Learning。現代量化方法的必讀之作,特別是關於交叉驗證、特徵重要性和正交化的部分。
Easley, Lopez de Prado & O'Hara (2012), Flow Toxicity and Liquidity in a High-frequency World, Review of Financial Studies. VPIN 指標的原始論文。


