



数据就是新石油
互联网上海量的加密货币数据是进一步进行加密货币投资研究的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网页抓取是指从网站下载数据并从这些数据中提取有价值的信息的过程(因此得名抓取)。出于我们的目的,我们对网页抓取加密货币数据感兴趣。
在本系列文章中,我们将从概念开始,并在此基础上慢慢构建。到最后,网页抓取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过收集和分析来自多个来源的数据,我们可以提高我们的投资情报。
为什么网页抓取?
既然有这么多网站提供免费的工具,为什么还会有人想要收集你自己的数据呢?大多数用户将使用网站,如CoinMarketCap, CoinGecko, Live Coin Watch来获取他们的数据并建立他们的观察名单。那样不是更方便吗?
在我看来,我们应该两者都用,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网页抓取和构建我们自己的智能数据)。
根据我的经验,发现了以下好处:
保持控制和专注:我更加专注和控制,知道我使用电子表格构建的列表和分析是我投资目的的主要工作版本。我不需要依赖其他人的数据。从一个站点跳到另一个站点也会分散我的注意力,使我不能专心于我的主要任务。填补空白:并不是所有的替代币都可以在主要的网站上使用。在币列表中总是存在空白和不一致。当我们拥有自己的数据时,我们可以管理它。高级分析:通过电子表格中的数据,可以进行高级分析和过滤,以找到网站无法提供的小众币。个人笔记和评论:可以添加列到自己的电子表格,以获得更多的评论和投资见解。我还添加了我将使用的场所,以及我将分配到币的资本金额。
例如,当我们在电子表格中拥有数据时,我们可以在Solana和游戏中搜索币:

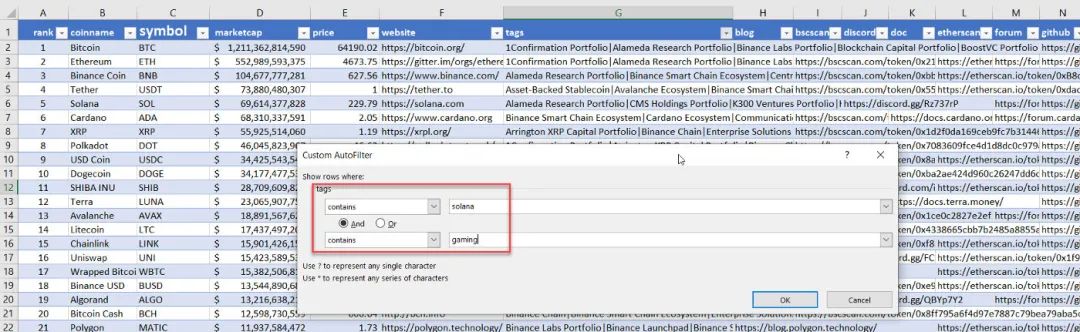
过滤我们的数据与包含这两个标签索拉纳和游戏

有两种币符合此标准:ATLAS 和 POLIS。我们来自网页抓取的数据集还将包含更多投资研究的附加信息(市值、网站、推特链接等)
寻找既适用于polkadot又适用于游戏的币怎么样:
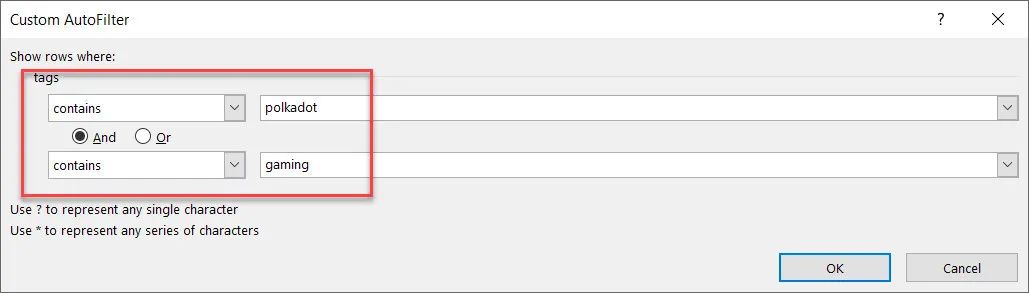

四种币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
作为比较,大多数网站只支持一级过滤。例如,CoinMarketCap可以列出Polkadot生态系统中的所有币:
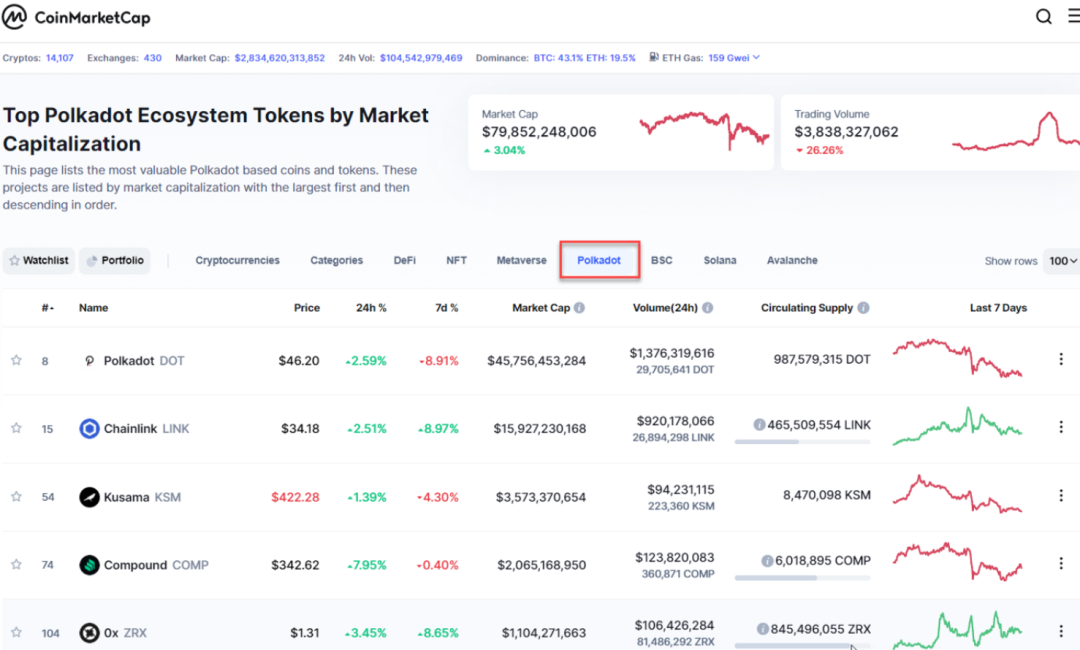
CoinMarketCap也可以列出所有游戏代币,但不能同时列出Polkadot和游戏。
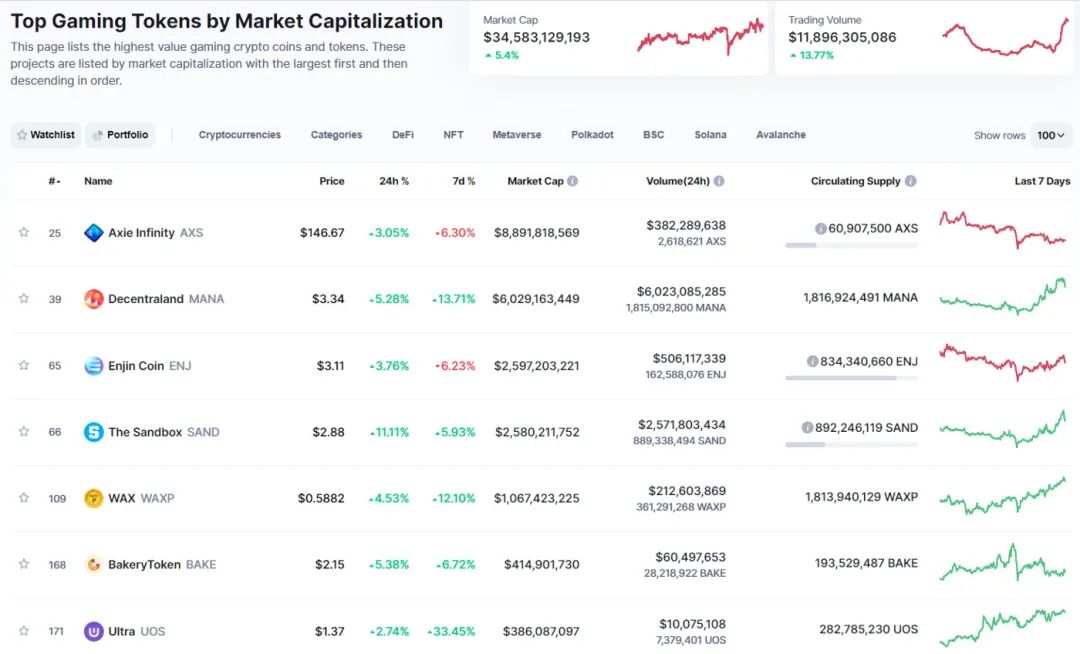
一般来说,这些网站不能超过两个或三个级别的过滤,例如列出所有与Polkadot相关的游戏币。
从表面上看,高级过滤似乎不是一个大问题,但市场上有成千上万的币,拥有这种自动化的能力并保持我们的专注是成功的关键。
概念
我们将在Python中使用两个库:
BeautifulSoup是一个Python库,用于从HTML、XML和其他标记语言中获取数据。Request,用于从网站获取HTML数据。如果您已经在HTML文件中拥有数据,则不需要请求库。
我也在谷歌云平台上使用Jupyter Notebook来运行,但是下面的Python代码可以在任何平台上运行。
根据各自的Python设置,可能需要pip install beautifulsoup4。

通过例子学习:网页抓取的“Hello World”
我们将从网页抓取的“Hello World”开始,通过抓取什么是币安币(BNB)的介绍文本,如下面的绿色框所示。
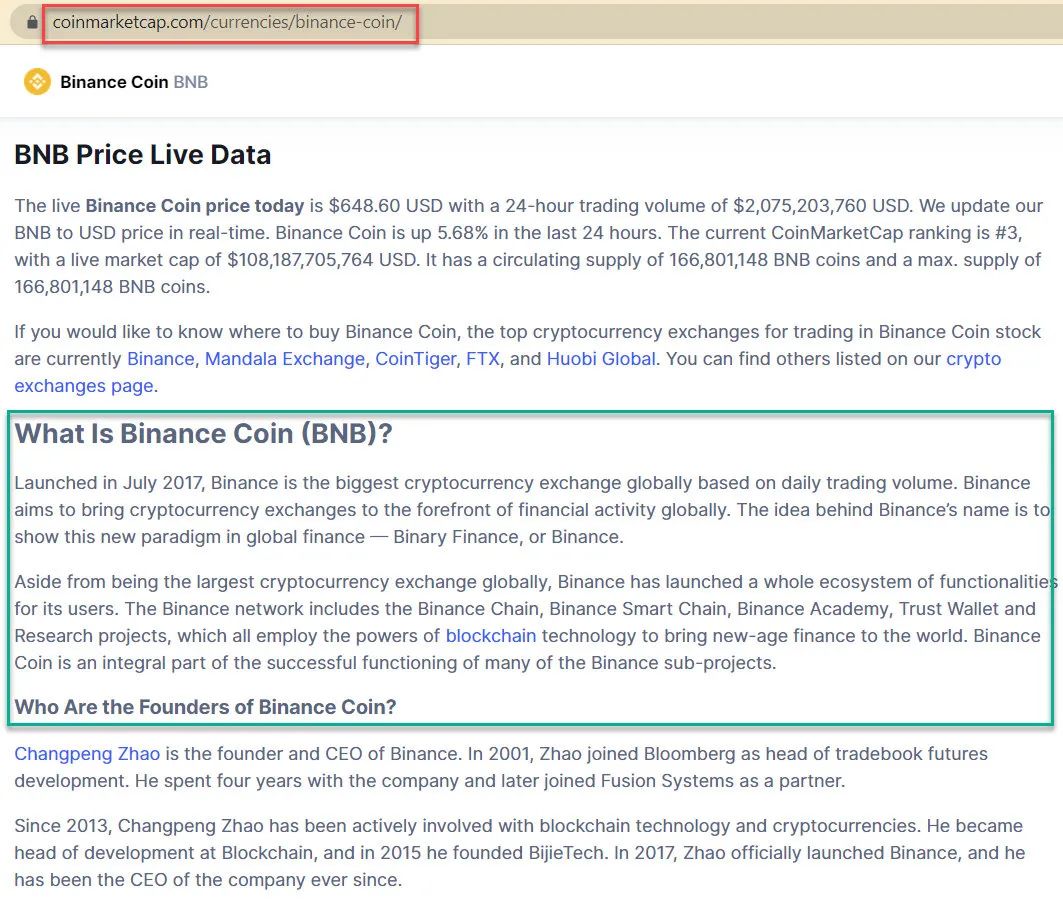
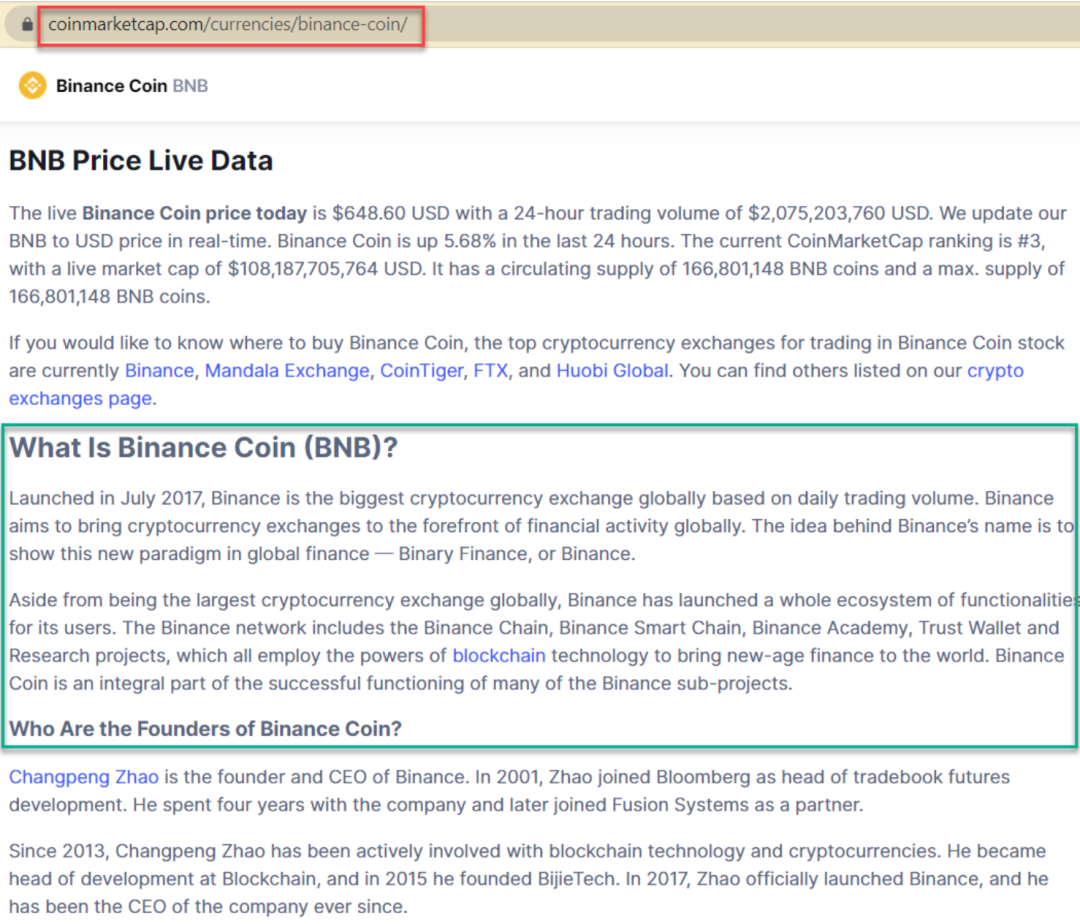
访问BNB页面与你的Chrome浏览器,然后右键单击页面,然后单击检查以检查元素:
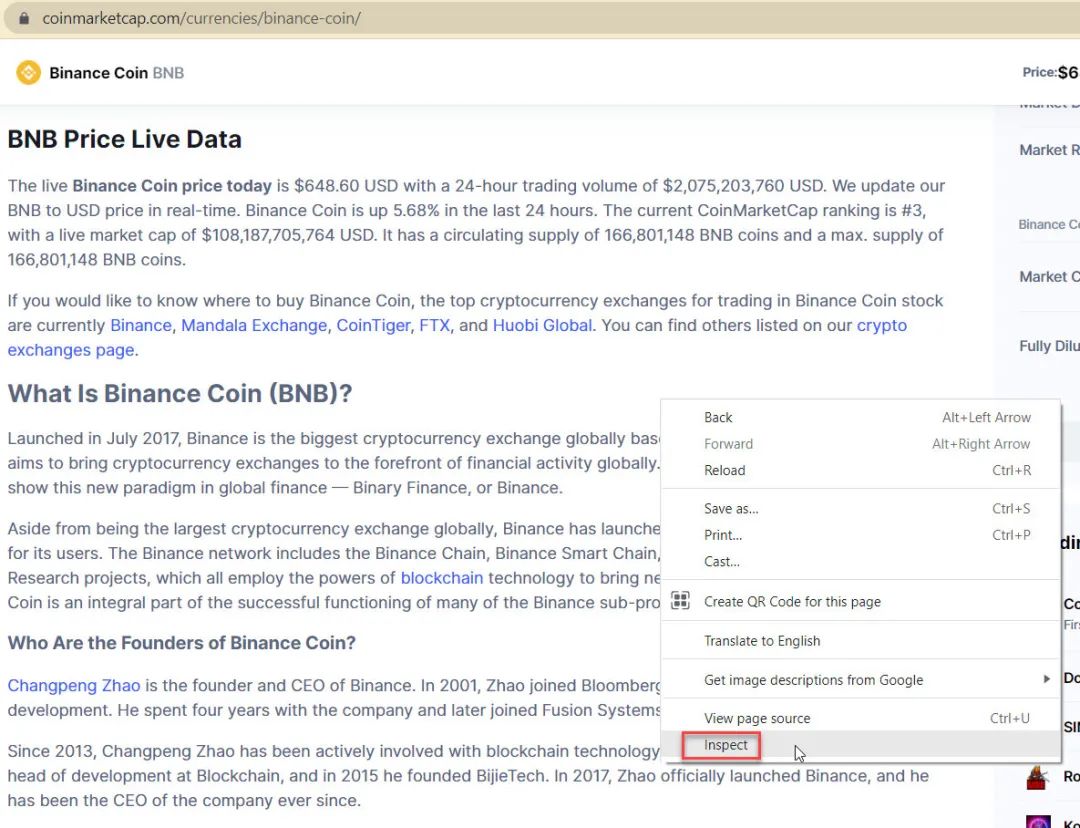
点击屏幕中间的小箭头,然后点击相应的网页元素,如下图所示。
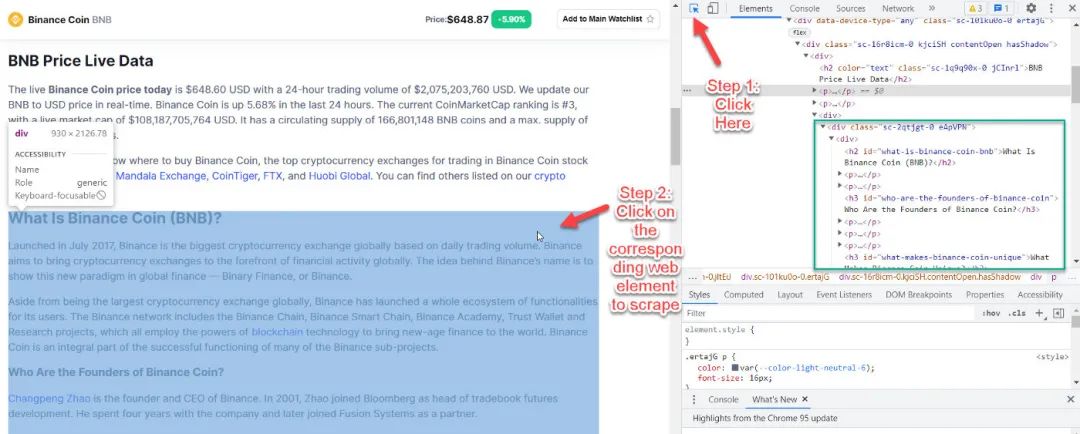
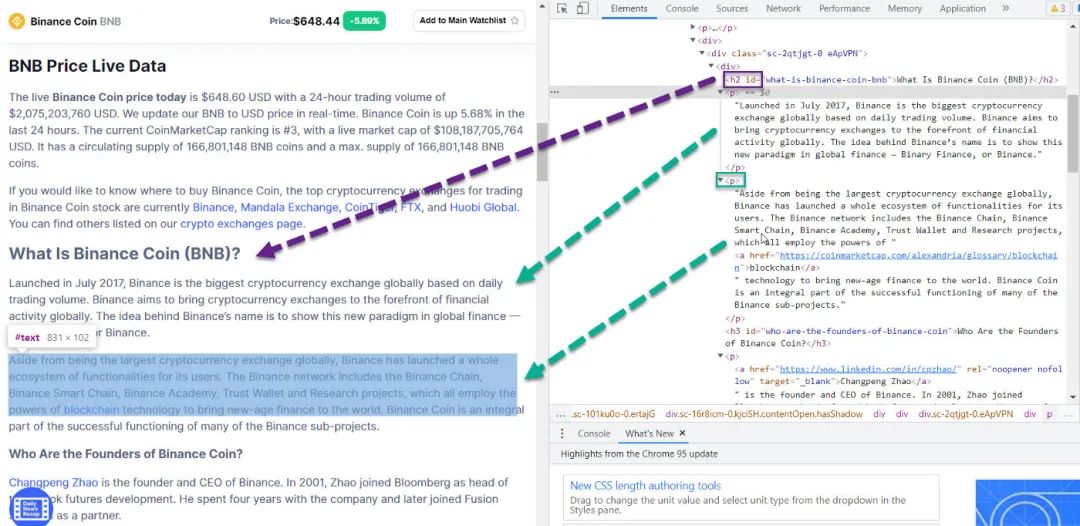
从检查,我们看到网页元素是
在 div 类sc-2qtjgt-0 eApVPN 下标题使用h2字幕使用h3剩下的在p下
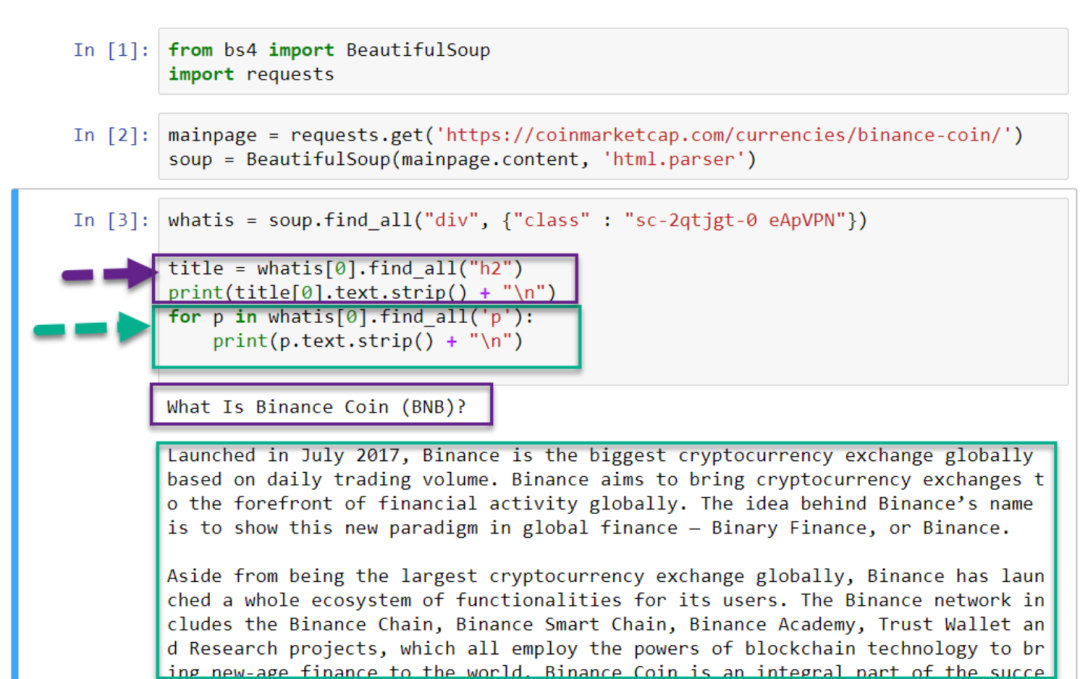
from bs4 import BeautifulSoupimport requests# retrieve the web page and parse the contentsmainpage = requests.get('https://coinmarketcap.com/currencies/binance-coin/')soup = BeautifulSoup(mainpage.content, 'html.parser')whatis = soup.find_all('div', {'class' : 'sc-2qtjgt-0 eApVPN'})# extract elements from the contentstitle = whatis[0].find_all('h2')print(title[0].text.strip() + ' ')for p in whatis[0].find_all('p'): print(p.text.strip() + ' ')
例2:网页抓取币统计信息
在这个例子中,我们将使用BNB的统计数据,即市值、完全稀释市值、成交量(24小时)、流通供应量、成交量/市值。
在相同的BNB币页面上,去页面的顶部,点击Market Cap的网页元素。观察整个区块被调用

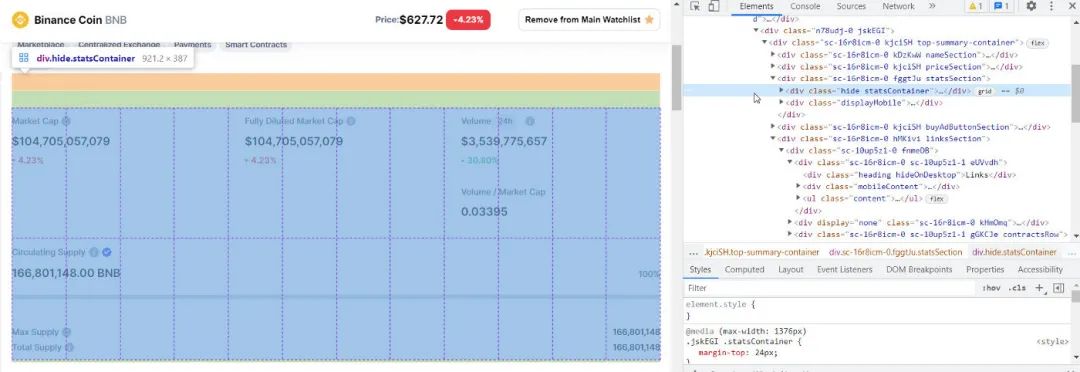
每个统计数据都有类型:

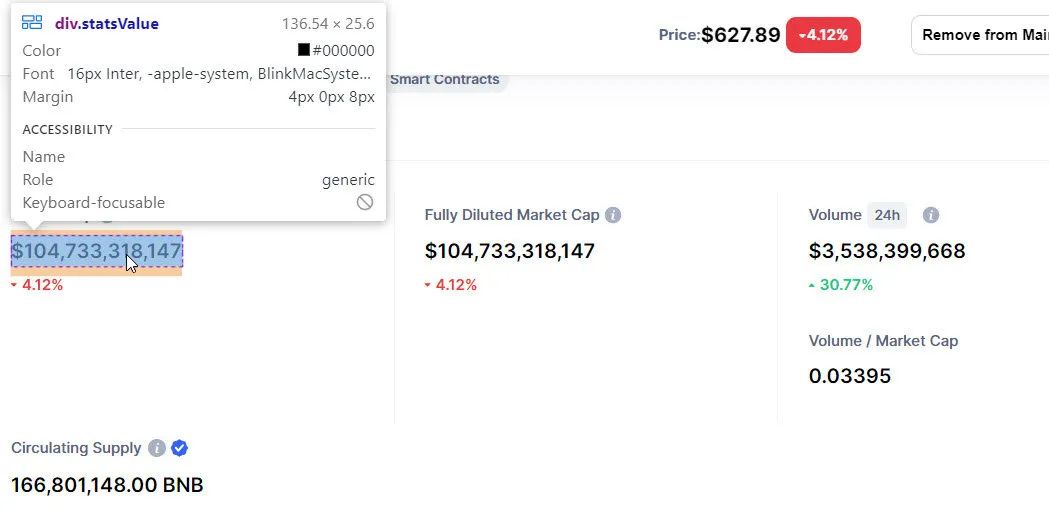
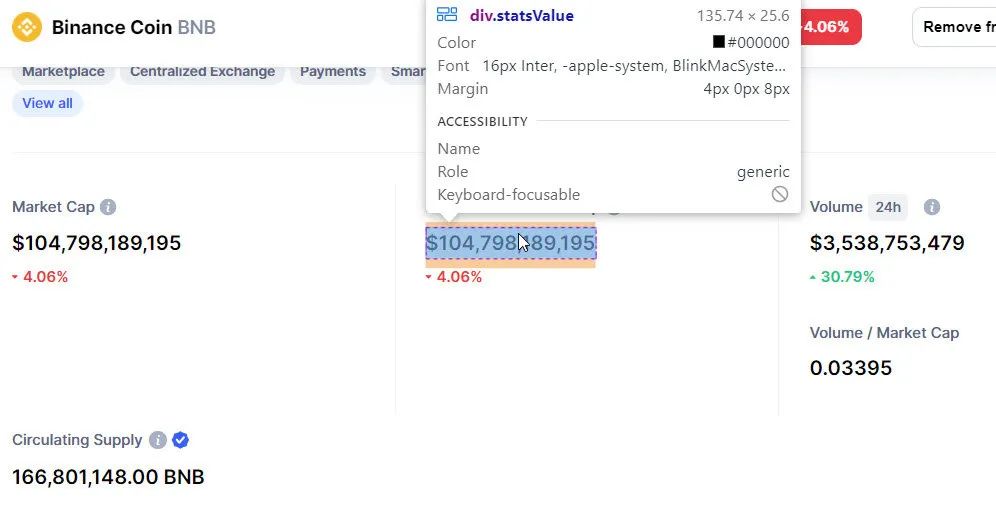
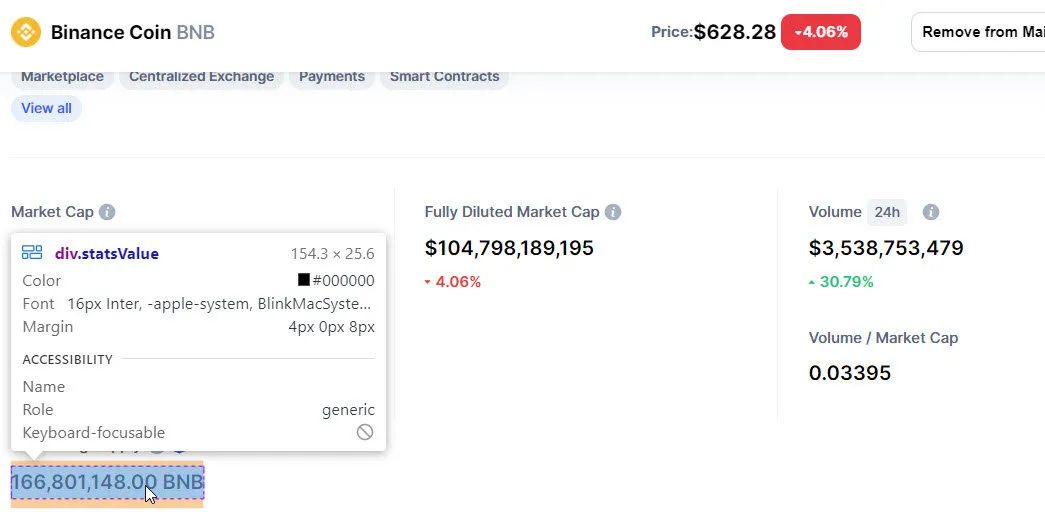
我们要找到


这将检索五个统计数字。(由于加密货币是 24x7 交易,这些数字一直在变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all('div', {'class' : 'hide statsContainer'})statsValues = statsContainer[0].find_all('div', {'class' : 'statsValue'})statsValue_marketcap = statsValues[0].text.strip()print(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()print(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()print(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()print(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()print(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例3:练习
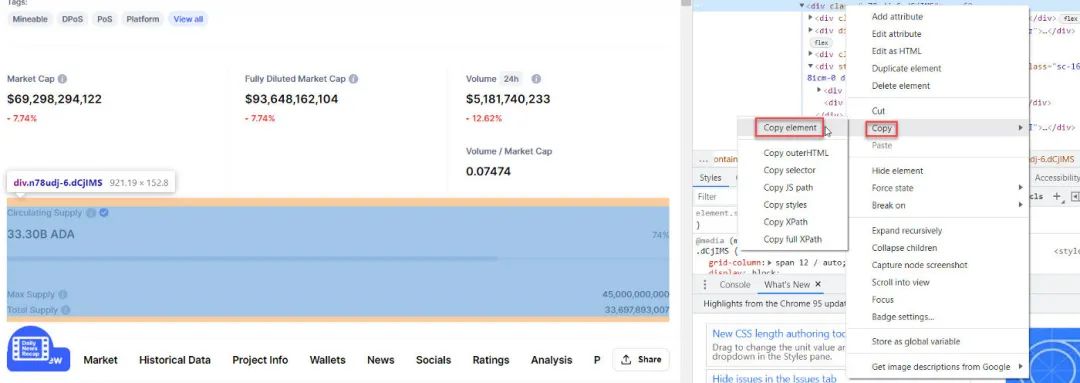
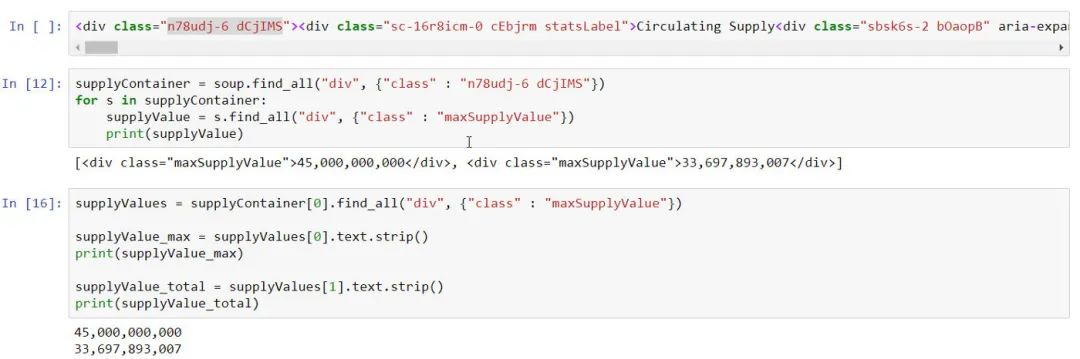
作为练习,使用前两个部分的知识并检查是否可以为BNB和ADA (Cardano)提取最大供应和总供应的数据。
最大供应量和总供应量
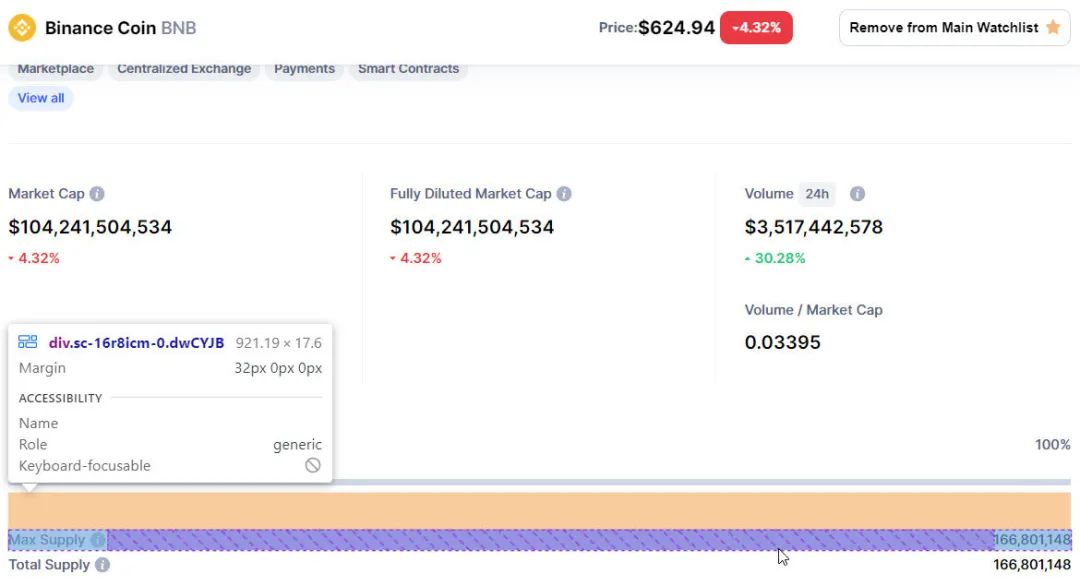


ADA (Cardano) 最大供应量和总供应量



附录:BeautifulSoup的替代品
其他替代品有Scrapy和Selenium。
Scrapy和Selenium比用于获取HTML数据的Request和用作HTML解析器的BeautifulSoup有更陡峭的学习曲线。
Scrapy是一个完整的网页抓取框架,负责从获取HTML到处理数据的所有事情。Selenium是一个浏览器自动化工具,例如,它可以让用户在多个页面之间导航。
网页抓取的挑战:长寿
任何网页抓取的主要挑战是代码的寿命。CoinMarketCap等网站的开发人员正在不断更新他们的网站,旧代码可能在一段时间后就不能工作了。
一个可能的解决方案是使用各种网站和平台提供的应用程序编程接口(API)。然而,API的免费版本是有限的。使用API时,数据的格式不同于通常的网页抓取,即JSON或XML,而在标准的网页抓取中,我们主要处理的是HTML格式的数据。
Source:https://medium.com/crypto-code/learn-the-basics-of-web-scraping-data-with-python-and-beautifulsoup-2222e6dbe117






 APP
APP 

