
眾所周知我是一個GPT愛好者,已經將其融入工作和生活的方方面面。但GPT也不是萬能的,我們需要認清其本質,才能更好使用其能力。強烈推薦特德·姜這篇極具洞察的文章《 ChatGPT是網上所有文本的模糊圖像》,獨特見解發人深省。我總結了3個點,歡迎閱讀。
特德·姜,華裔科幻作家,畢業於布朗大學計算機系,其短篇小說《你一生的故事》在2016年被改編成電影《降臨》 技術和科幻的雙重背景,讓其對ChatGPT具有了獨特見解。
TL;DR
- ChatGPT是網上所有文本的有損壓縮
- 警惕「美麗的模糊」
- 「原創想法的拙劣表達」好於「清晰表達的非原創想法」
1、ChatGPT是網上所有文本的有損壓縮
如果將互聯網上的所有文本看做是原件,考慮到處理速度和準確度,ChatGPT 實際上是這些文本的有損壓縮後一個自然語言交互接口。既然是有損壓縮,就會拋棄一些細節,甚至關鍵信息。
關於有損壓縮可能會導致的問題,作者舉了一個形象的例子: 2013 年德國一家建築公司複印了一張房子平面圖,三個房間都有一個標籤來說明其面積:14.13,21.11和17.42平方米。然後在復印件中,所有三個房間都被標記為14.13平方米。
經過調查發現,這台施樂複印機的工作原理是,先把文檔掃描為數字圖像,然後再進行打印。為了節省空間,掃描為數字圖像時使用了一種被稱為jbig2 的有損壓縮格式。複印機判斷3 個房間的面積標籤非常相似,所以它只存儲了其中一個,然後在打印時對所有3 個房間都重複使用了這一個標籤。
施樂複印機使用有損壓縮格式而不是無損格式,這本身並不是一個問題問題是如果只是打印出模糊的照片,每個人都會知道這不是原件的準確複製品,但複印機打印出了清晰但不准確的圖片,可能會對使用者產生誤導
作者認為,在我們使用OpenAI 的ChatGPT 和其他類似大語言模型時,需要對這個例子銘記於心。 ChatGPT 保留了萬維網上的大部分信息,就像JPEG 保留了高分辨率圖像的大部分信息一樣。但是,如果你要尋找精確的比特序列,你無法找到它,你得到的只是一個近似值。
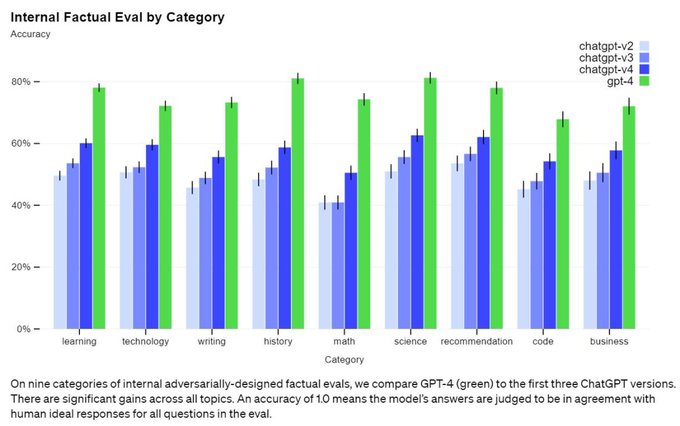
可以看到,在OpenAI 論文的最新真實性評估中,雖然GPT-4 比過往模型高很多,但仍然有不低的概率生成錯誤答案(特別是在科技、代碼和商業領域),我們需要小心。
2、警惕「美麗的模糊」
我們對世界的認知,本質上也是對信息的接收和壓縮。我們識別和拋棄不重要的信息,留下重要的信息,同時在這個過程中鍛煉和使用了決策能力。都是對信息的有損壓縮,我們和ChatGPT有何不同? - 我們對信息的壓縮,是建立在對事實的理解上,最後留下的是「模糊的正確」 - ChatGPT 並沒有真正的「理解」信息,建立在統計規律上輸出「美麗的模糊」。再看2 個形象的例子:
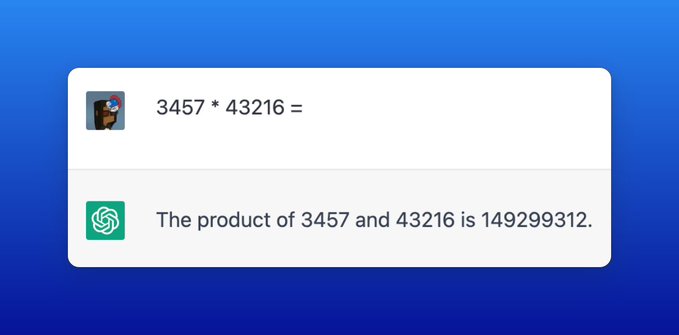
- 如果讓ChatGPT 計算3457 * 43216,會給出錯誤答案149299312(正確答案149397712) 最後一位正確是因為有很多以6 和7 結尾數字的乘法讓ChatGPT 學習,但因為其並沒有真正理解算術原理,所以最後給出是錯誤答案。
- 對文本的任何分析都會揭示,“供應不足”這樣的短語經常出現在“價格上漲”這樣的短語附近當被問及有關供應不足的問題時, AI可能會給出包含價格上漲的回答。如果AI已經編譯了大量經濟術語之間的相關性,多到可以對各種各樣的問題提供合理的回答,我們是否應該說它實理解了經濟理論?顯然沒有。
ChatGPT 擅長產生美麗的答案,但美麗≠正確。我們必須時刻銘記這一點,ChatGPT 輸出的結果可能會漂亮清晰但不准確,要識別它們就需要將它們與原件進行比較,否則就有可能基於瞎編的內容進行錯誤的決策。 下面bing 產生的這個答案,就是典型的「美麗的模糊」。
3、「原創想法的拙劣表達」好於「清晰表達的非原創想法」
有一種觀點,讓ChatGPT 生成的文本作為作家在創作原創作品時的起點,讓作者把注意力集中在真正有創意的部分,這樣可行嗎?作者認為,以一份模糊的非原創作品作為起點,並不是創作原創作品的好辦法。
如果你是一個作家,在你寫原創作品之前,你會寫很多非原創的作品。花在非原創工作上的時間和精力不會被浪費。相反,正是它讓你最終能夠創作出原創的作品花在選擇正確的詞彙和重新排列句子上的時間,教會了你如何通過文章傳達想要表達的意思。
讓學生寫論文不僅僅是一種測試他們對材料掌握程度的方法,這給了他們表達自己想法的經驗。如果學生從來不用寫我們都讀過的文章,他們就永遠不會獲得寫我們從未讀過的東西所需的技能。
那是不是脫離學生身份後,就可以安全地使用ChatGPT 等大語言模型提供的模板了呢?然而並不是。想要表達自己想法的掙扎並不會在你畢業後消失。每當你開始起草一篇新文章時,這種掙扎就會出現。有時候,只有在寫作的過程中,你才能發現自己最初的想法,這點非常關鍵。
有些人可能會說,大語言模型的輸出看起來與人類作家的初稿沒有太大不同,但這只是表面上的相似你的初稿不是「清晰表達的非原創想法」;它是「原創想法的拙劣表達」,它伴隨著你無定形的不滿,你意識到它所說的和你想說的之間的距離。
這是在重寫時能夠指導你的東西,這是當你開始使用人工智能生成的文本時所缺乏的東西。基於「清晰表達的非原創想法」,會很容易讓人失去想法;而從「原創想法的拙劣表達」開始,逐步打磨,最終會收穫「原創想法的精確表達」,原創可能會成為玉石,非原創只會流於氾濫。
總結2 點Take Away:
- ChatGPT是網上所有文本的有損壓縮,我們必須時刻銘記這一點,警惕把「美麗的模糊」當做準確信息,影響判斷和決策
- 2. 在掙扎和拙劣表達中發現「原創想法」,同時提升自己的表達能力,將其打磨成玉石訓練想像力、決策和溝通能力,打造機器無法擁有的競爭力



