 巴比特资讯
巴比特资讯 |2022-09-13 17:44
来认识一下爆红AI项目 Stable Diffusion,和它背后的机构 Stability AI。
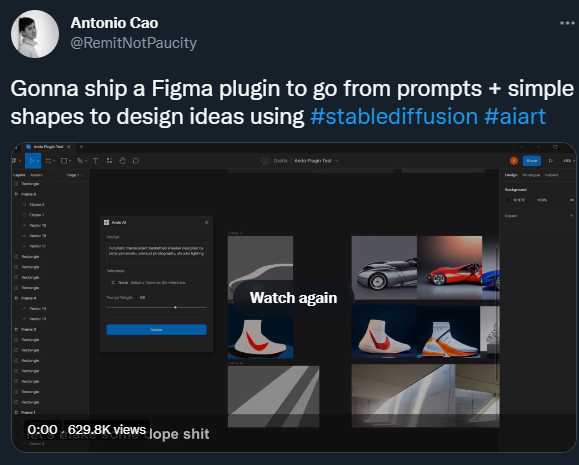
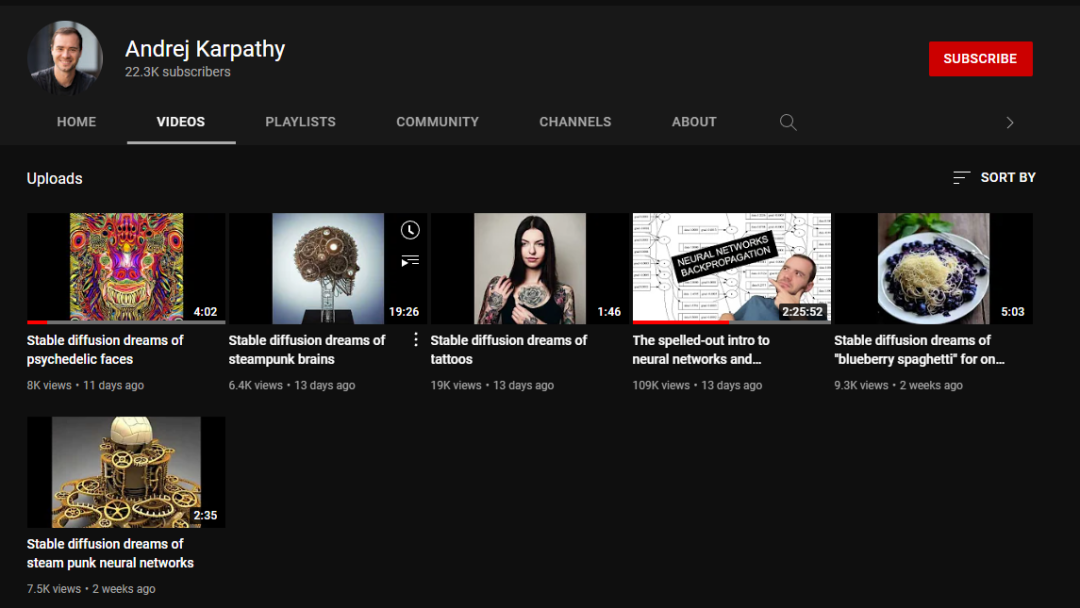
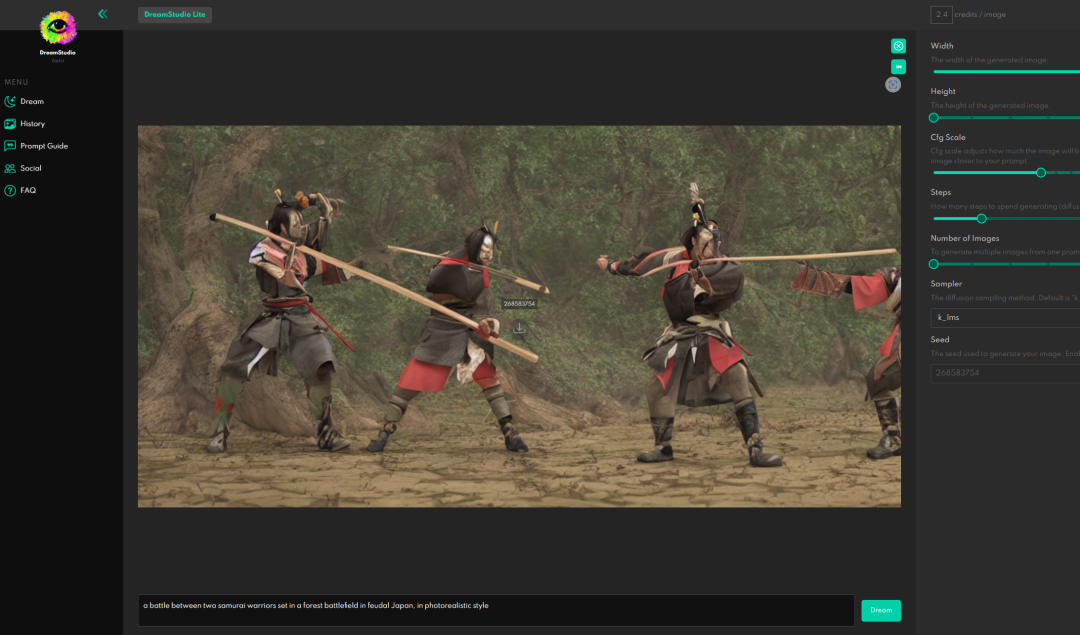
 来认识一下爆红AI项目 Stable Diffusion,和它背后的机构 Stability AI。文|杜晨 编辑|VickyXiao 图片来源 | Stability AI火到什么程度,以至于已经有公司开始“套个壳”就出道了……本周有消息曝出,一家创业公司 WriteSonic “剽窃”了著名模型 Stable Diffusion,做了一个生成图片的产品 Photosonic AI。这还没完,这家公司居然把该产品堂而皇之地发到了产品社区 Product Hunt 上面,甚至一度冲到了第二的位置……Stable Diffusion 完全免费开源,所有代码都在 GitHub 上公开,任何人都可以拷贝使用——前提是需要遵循原项目采用的 CreativeML Open RAIL-M 许可证。然而原项目贡献者 Louis Castricato 却发现,WriteSonic 并没有注明使用该许可证,在 Photosonic AI 的任何地方也没有标注技术来源。他对 WriteSonic 喊话:“希望你们在 VC 面前没有假装这个东西是你们自己做的。”Stable Diffusion 许可证 图片来源:Hugging Face目前事情还没有完全闹开,不过 Product Hunt 上已经有不少人提出了质疑。截至本文发出,WriteSonic 创始人尚未做出回应。其实,Stable Diffusion 也是一周前才正式发布公开版——这次抄袭事件,反倒映射出这项技术到底有多火、Stable Diffusion 有多受欢迎。最近硅星人多次报道过 AI 图片生成技术,提到过 DALL·E、Midjourney、DALL·E mini(现用名 Craiyon)、Imagen、TikTok AI绿幕等知名产品。实际上,Stable Diffusion 有着强大的生成能力和广泛的使用可能性,模型可以直接在消费级显卡上运行,生成速度也相当之快。而其免费开放的本质,更是能够让 AI 图片生成模型不再作为少数业内人士的玩物。在强者如云、巨头纷纷入局的 AI 图片生成领域,Stable Diffusion 背后的“神秘”机构 Stability AI,也像是“世外高僧”一般的存在。它的创始人没有那么出名,创办故事和融资细节也不是公开信息。再加上免费开源 Stable Diffusion 的慈善行为,更让人增加了对这家神秘 AI 科研机构的兴趣。今天,我们就来深入了解一下 Stable Diffusion 和 Stability AI,这支在 AI 领域异军突起的“第三种”力量。Stable Diffusion 是一个文字转图片的生成模型。可以只用几秒钟时间就生成比同类技术分辨率、清晰度更高,更具“真实性”或“艺术性”的图片结果。项目开发领导者有两位,分别是 AI 视频剪辑技术创业公司 Runway 的 Patrick Esser,和慕尼黑大学机器视觉学习组的 Robin Romabach。这个项目的技术基础主要来自于这两位开发者之前在计算机视觉大会 CVPR22 上合作发表的潜伏扩散模型 (Latent Diffusion Model) 研究。另外,项目也得到了一些外部开发社区,以及 Stability AI 机构生成技术团队的支持,并且从 DALL·E 2、Imagen 等巨头模型项目当中获得和整合了一些经验参考。项目发布的时候有专门声明对这些“竞品”项目的感谢。在训练方面,模型采用了4000台 A100 显卡集群,用了一个月时间。训练数据来自大规模AI开放网络项目旗下的一个注重“美感”的数据子集 LAION-Aesthetics,包括近59亿条图片-文字平行数据。虽然训练过程的算力要求特别高,Stable Diffusion使用起来还是相当亲民的:可以在普通显卡上运行,即使显存不到10GB,仍可以在几秒钟内生成高分辨率的图像结果。模型专门面向消费级计算设备所做的优化,意味着更多入门级研究者、内容创作者,以及普通公众用户,都可以更加频繁接触和使用 Stable Diffusion,感受 AI 内容生成技术的最尖端能力,为他们的工作和生活带来极大的便利和乐趣。在8月初,团队先是进行了一个大范围的公测,结果反响非常热烈,受到大批研究者和测试用户的欢迎。于是,团队很快就在上周一正式公开发布了 Stable Diffusion 模型。只要遵循 OpenRAIL-M 许可证的规定,并且不用于非法和非道德的场景,任何人都可以对该模型进行商业或非商业使用、改造和再发布。Stable Diffusion 并不是 AI 内容创作、AI 艺术领域的第一个模型,很多人(包括前几周的硅星人)都曾以为它只是一个跟随者而已。Stable Diffusion 生成结果 图片来源:Stability AI首先,和其它开放程度相似的项目(如 Craiyon、Disco Diffusion 等)相比,Stable Diffusion 的生成结果更为写实,完全不亚于 DALL·E、Imagen 等巨头开发的超大模型的结果。其它同类模型在风格上往往会选择一种,比如之前我们写过的 TikTok AI绿幕模型,风格就明显更偏向油画。而 Midjourney 更像现代抽象艺术作品。谷歌 Imagen 具有明显的写实+渲染动画风格,DALL·E mini 则是一股”梗图”风。并且,Stable Diffusion 的完全开放,以及在商业/非商业使用上超高的自由度,已经让它成为了一个“离群者” (outlier),和 DALL·E、Imagen 等封闭/半封闭产品之间,已经形成了一道巨大的鸿沟。任何人都可以不花钱,拷贝一份 Stable Diffusion 的代码,按照自己喜欢的方式进行研究,并且用于处理自己需要的文字生成图片相关任务,甚至开发独立的应用或服务。事实上自从 Stability AI 正式公开发布模型以来,已经有相当多人用它完成了自己的艺术创作,开发出各式各样的 demo、产品,以及非常有趣的小项目了。比如下面这个由用户 Anthony Cao 开发的设计软件 Figma 插件,就是借助 Stable Diffusion 的能力,用一句话就可以生成用户界面元素。用户 Xander Steenbrugge 更厉害了:他进行了大量的尝试,最终锁定了36条连续的文字输入提示,成功调教了 Stable Diffusion 模型,输出了下面这样一个非常令人震撼的视频。他将视频取名为《穿越时空的旅行》:上周我们还介绍过著名 AI 学术大佬 Andrej Karpathy。他从特斯拉 AI 总监的职位离职之后,在自己的 YouTube 上开了一堂两个多小时的机器学习 Python 入门课。有趣的是,除了这堂课之外,其实他的账号上所有的视频都是他用 Stable Diffusion 生成的。(当时硅星人还猜想他的下一站会不会就是加入这个项目组了。)截图来源:Andrej Karpathy 的 YouTube 频道就连“竞品” Midjourney 都整合了 Stable Diffusion 开发了一个功能,让用户可以同时用两个模型整合来生成图片:双模型合成生成结果 图片来源:Allesandrochille 等人创作,Alberto Romero 组合就这样,Stable Diffusion 实现了“开源”和 “高质量结果” 的两全其美,而这在硅星人看来正是它最受关注的关键原因。特别是开源的属性,不仅打开了新的一扇 AI 艺术创作的大门,更重要的是这扇门比以往的任何门都更宽,门槛都更低。在公开版本发布的同时,Stability AI 也上线了一个新的工具网站,名为 DreamStudio Lite。这个工具可以帮助更多普通用户和创意玩家,更加方便地使用 Stable Diffusion 模型。在网页下方有一个文本框,用户可以直接在里面输入生成所用的提示。在网页右边的工具栏还可以调节图片的大小、扩散模型步骤数量、生成图片的数量等等。(见下图)DreamStudio Lite 图片来源:硅星人顾名思义,现在的 DreamStudio Lite 还只是一个轻量化的版本。Stability AI 团队正在加紧开发高级功能,包括使用设备显卡、动画支持、迭代生成、插值修复等。Stable Diffusion 让创作这件事不再成为具有高级创意训练的人专属的游戏,可以让更多人从中受益。从这个角度来看,力推这一模型的开发和开源的背后组织 Stability AI 厥功至伟。/ 延续 OpenAI 火种,成为“第三种力量” /在大约10年前,深度学习 AI 的浪潮刚刚起步的时候,研究员们一边亲眼目睹潮流的到来,一边却异常尴尬苦闷。当时的算力和资金限制都非常严重,研究员基本只有两种选择:要么停留在学术界,但是基本没有任何算力可用;要么跳槽到大公司,签一堆 NDA,并且在一个大公司的产品团队的环境里工作,很不自由,做出来的东西也是给公司用,而不是贡献社会。而 OpenAI 的出现,在学术界和工业界之外创造了“第三种”可能性:既有学术界相对轻松自由的环境,又有巨头公司近乎无限的现金和充足的算力,并且以推动技术边界的扩展,造福社会为核心目的。然而大约两年前,OpenAI 内部积累的问题突然爆发。当时实行的非营利模式难以为继,机构也终于成立了营利部门。也是在那段时间,一波大神级核心研究员,由于无法接受这一转型,愤然离职。后来的 OpenAI 还是推出了包括 GPT-3、DALL·E 等知名作品,但名声早已大不如前。特别是 DALL·E 二代,明明是当时最领先的 AI 图片生成技术之一,在网上的影响力却不如 DALL·E mini,一个完全无关的个人开发者,所做的业余开源项目。对于 OpenAI 的窘境,“超级富豪” Emad Mostaque 看在眼里,疼在心里。此人身价究竟几何,并没有特别清楚详尽的资料。已经公开的信息显示,他有至少20年的投资基金工作经历,曾经在多家技术和基金公司担任工程师、战略分析师、首席投资官等职位。在累积了巨额财富之后,对于利用自己的技术和资金来开展慈善和推动社会平等、技术普及等事业,这位英国人的兴趣越来越高。他在2019年创办了一家采用技术降低手机套餐成本费用的公司,新冠袭来后又出资并亲自主导在斯坦福大学组建了一个非营利性质的大数据平台项目,与联合国开展合作,旨在辅助各国政府制定防疫政策。而在2020年创办的 Stability AI,则是他的“慈善”事业的最新篇章。根据并不充分的资料,这家机构的早期绝大部分资金都来自 Mostaque 本人。从这个角度来看,他的身份,确实有点像马斯克之于 OpenAI。他决定自己接过使命,成立一家和 OpenAI 早期的非商业模式差不太多,但开放程度更高的机构。总而言之,就是要比 OpenAI 更 “open”。通过 Stability AI,Mostaque 希望能够延续 OpenAI 缔造并发扬光大的 AI 科研“第三种力量”,同时避免重蹈其覆辙。这家新机构也确实在贯彻开放、公益的 OpenAI 早期科研思路:它的第一个对外亮相的产品/技术,就是免费、开源、几乎没有任何商业味道的 Stable Diffusion 模型。Mostaque 曾经表示,目前大约八成的 AI 研究资金全都流向了下一代技术,而这些技术从构思到开发,再到测试和发布的整个过程里,往往都是高度封闭的。作为硅谷大公司里面投身 AI 基础科研最早,投资额最大的公司,谷歌近几年开发的 PaLM、LaMDA、Imagen 等模型的封闭性越来越强,使用门槛相当之高,几乎没有开放给公众的可能性。该公司的 AI 道德委员会,则被一些前委员、公司前员工以及第三方研究人士指责为“没用”,反而成为公司内部 AI 研究部门非道德问题的“遮羞布”。Mostaque 就在想,算力、资金,和公众参与这三个问题,能否一同解决?“这里一定有更好的办法。”有一位网友甚至将 Mostaque 形容为AI 科研领域的 "Gigachad"(超级猛男):“他为人类未来做出的贡献,比其他顶级 AI 公司加起来还要多。”Emad Mostaque 图片来源:Yannic KilcherAI技术分析师 Alberto Romero 则指出,Stability AI 的工作之重要性在于:人们不想看到其他人如何用最先进的技术创造出厉害的艺术作品,他们真正想要的是能够自己上手尝试。而 Stability AI 不光把代码和模型权重放了出来,甚至还更进一步,开发了一个相当友好的无代码、“开袋即食”的网站(DreamStudio Lite),让那些不想也不会写代码的人都能够使用。借助 Mostaque 之前做新冠大数据项目时积累的人脉,Stability AI 目前已经和联合国达成了合作,成为了国家间、学校间和跨国公司之间 AI 技术研发合作的桥梁。最初,整个团队还是在 Discord 聊天应用上运行的——目前很大程度上仍然如此。但今天的 Stability AI,似乎已经超越了 OpenAI 的范畴和意义,在包括学术和工业界的整个 AI 研究和应用领域都受到了巨大的欢迎。通过 Stable Diffusion,更多人体会到了 AI 图片生成技术的强大和美好。最尖端的 AI 模型,不再是少数人独享的玩具,更多用户都能够享受和利用这项技术。Stability AI 的口号是 “AI by the people, for the people.”
来认识一下爆红AI项目 Stable Diffusion,和它背后的机构 Stability AI。文|杜晨 编辑|VickyXiao 图片来源 | Stability AI火到什么程度,以至于已经有公司开始“套个壳”就出道了……本周有消息曝出,一家创业公司 WriteSonic “剽窃”了著名模型 Stable Diffusion,做了一个生成图片的产品 Photosonic AI。这还没完,这家公司居然把该产品堂而皇之地发到了产品社区 Product Hunt 上面,甚至一度冲到了第二的位置……Stable Diffusion 完全免费开源,所有代码都在 GitHub 上公开,任何人都可以拷贝使用——前提是需要遵循原项目采用的 CreativeML Open RAIL-M 许可证。然而原项目贡献者 Louis Castricato 却发现,WriteSonic 并没有注明使用该许可证,在 Photosonic AI 的任何地方也没有标注技术来源。他对 WriteSonic 喊话:“希望你们在 VC 面前没有假装这个东西是你们自己做的。”Stable Diffusion 许可证 图片来源:Hugging Face目前事情还没有完全闹开,不过 Product Hunt 上已经有不少人提出了质疑。截至本文发出,WriteSonic 创始人尚未做出回应。其实,Stable Diffusion 也是一周前才正式发布公开版——这次抄袭事件,反倒映射出这项技术到底有多火、Stable Diffusion 有多受欢迎。最近硅星人多次报道过 AI 图片生成技术,提到过 DALL·E、Midjourney、DALL·E mini(现用名 Craiyon)、Imagen、TikTok AI绿幕等知名产品。实际上,Stable Diffusion 有着强大的生成能力和广泛的使用可能性,模型可以直接在消费级显卡上运行,生成速度也相当之快。而其免费开放的本质,更是能够让 AI 图片生成模型不再作为少数业内人士的玩物。在强者如云、巨头纷纷入局的 AI 图片生成领域,Stable Diffusion 背后的“神秘”机构 Stability AI,也像是“世外高僧”一般的存在。它的创始人没有那么出名,创办故事和融资细节也不是公开信息。再加上免费开源 Stable Diffusion 的慈善行为,更让人增加了对这家神秘 AI 科研机构的兴趣。今天,我们就来深入了解一下 Stable Diffusion 和 Stability AI,这支在 AI 领域异军突起的“第三种”力量。Stable Diffusion 是一个文字转图片的生成模型。可以只用几秒钟时间就生成比同类技术分辨率、清晰度更高,更具“真实性”或“艺术性”的图片结果。项目开发领导者有两位,分别是 AI 视频剪辑技术创业公司 Runway 的 Patrick Esser,和慕尼黑大学机器视觉学习组的 Robin Romabach。这个项目的技术基础主要来自于这两位开发者之前在计算机视觉大会 CVPR22 上合作发表的潜伏扩散模型 (Latent Diffusion Model) 研究。另外,项目也得到了一些外部开发社区,以及 Stability AI 机构生成技术团队的支持,并且从 DALL·E 2、Imagen 等巨头模型项目当中获得和整合了一些经验参考。项目发布的时候有专门声明对这些“竞品”项目的感谢。在训练方面,模型采用了4000台 A100 显卡集群,用了一个月时间。训练数据来自大规模AI开放网络项目旗下的一个注重“美感”的数据子集 LAION-Aesthetics,包括近59亿条图片-文字平行数据。虽然训练过程的算力要求特别高,Stable Diffusion使用起来还是相当亲民的:可以在普通显卡上运行,即使显存不到10GB,仍可以在几秒钟内生成高分辨率的图像结果。模型专门面向消费级计算设备所做的优化,意味着更多入门级研究者、内容创作者,以及普通公众用户,都可以更加频繁接触和使用 Stable Diffusion,感受 AI 内容生成技术的最尖端能力,为他们的工作和生活带来极大的便利和乐趣。在8月初,团队先是进行了一个大范围的公测,结果反响非常热烈,受到大批研究者和测试用户的欢迎。于是,团队很快就在上周一正式公开发布了 Stable Diffusion 模型。只要遵循 OpenRAIL-M 许可证的规定,并且不用于非法和非道德的场景,任何人都可以对该模型进行商业或非商业使用、改造和再发布。Stable Diffusion 并不是 AI 内容创作、AI 艺术领域的第一个模型,很多人(包括前几周的硅星人)都曾以为它只是一个跟随者而已。Stable Diffusion 生成结果 图片来源:Stability AI首先,和其它开放程度相似的项目(如 Craiyon、Disco Diffusion 等)相比,Stable Diffusion 的生成结果更为写实,完全不亚于 DALL·E、Imagen 等巨头开发的超大模型的结果。其它同类模型在风格上往往会选择一种,比如之前我们写过的 TikTok AI绿幕模型,风格就明显更偏向油画。而 Midjourney 更像现代抽象艺术作品。谷歌 Imagen 具有明显的写实+渲染动画风格,DALL·E mini 则是一股”梗图”风。并且,Stable Diffusion 的完全开放,以及在商业/非商业使用上超高的自由度,已经让它成为了一个“离群者” (outlier),和 DALL·E、Imagen 等封闭/半封闭产品之间,已经形成了一道巨大的鸿沟。任何人都可以不花钱,拷贝一份 Stable Diffusion 的代码,按照自己喜欢的方式进行研究,并且用于处理自己需要的文字生成图片相关任务,甚至开发独立的应用或服务。事实上自从 Stability AI 正式公开发布模型以来,已经有相当多人用它完成了自己的艺术创作,开发出各式各样的 demo、产品,以及非常有趣的小项目了。比如下面这个由用户 Anthony Cao 开发的设计软件 Figma 插件,就是借助 Stable Diffusion 的能力,用一句话就可以生成用户界面元素。用户 Xander Steenbrugge 更厉害了:他进行了大量的尝试,最终锁定了36条连续的文字输入提示,成功调教了 Stable Diffusion 模型,输出了下面这样一个非常令人震撼的视频。他将视频取名为《穿越时空的旅行》:上周我们还介绍过著名 AI 学术大佬 Andrej Karpathy。他从特斯拉 AI 总监的职位离职之后,在自己的 YouTube 上开了一堂两个多小时的机器学习 Python 入门课。有趣的是,除了这堂课之外,其实他的账号上所有的视频都是他用 Stable Diffusion 生成的。(当时硅星人还猜想他的下一站会不会就是加入这个项目组了。)截图来源:Andrej Karpathy 的 YouTube 频道就连“竞品” Midjourney 都整合了 Stable Diffusion 开发了一个功能,让用户可以同时用两个模型整合来生成图片:双模型合成生成结果 图片来源:Allesandrochille 等人创作,Alberto Romero 组合就这样,Stable Diffusion 实现了“开源”和 “高质量结果” 的两全其美,而这在硅星人看来正是它最受关注的关键原因。特别是开源的属性,不仅打开了新的一扇 AI 艺术创作的大门,更重要的是这扇门比以往的任何门都更宽,门槛都更低。在公开版本发布的同时,Stability AI 也上线了一个新的工具网站,名为 DreamStudio Lite。这个工具可以帮助更多普通用户和创意玩家,更加方便地使用 Stable Diffusion 模型。在网页下方有一个文本框,用户可以直接在里面输入生成所用的提示。在网页右边的工具栏还可以调节图片的大小、扩散模型步骤数量、生成图片的数量等等。(见下图)DreamStudio Lite 图片来源:硅星人顾名思义,现在的 DreamStudio Lite 还只是一个轻量化的版本。Stability AI 团队正在加紧开发高级功能,包括使用设备显卡、动画支持、迭代生成、插值修复等。Stable Diffusion 让创作这件事不再成为具有高级创意训练的人专属的游戏,可以让更多人从中受益。从这个角度来看,力推这一模型的开发和开源的背后组织 Stability AI 厥功至伟。/ 延续 OpenAI 火种,成为“第三种力量” /在大约10年前,深度学习 AI 的浪潮刚刚起步的时候,研究员们一边亲眼目睹潮流的到来,一边却异常尴尬苦闷。当时的算力和资金限制都非常严重,研究员基本只有两种选择:要么停留在学术界,但是基本没有任何算力可用;要么跳槽到大公司,签一堆 NDA,并且在一个大公司的产品团队的环境里工作,很不自由,做出来的东西也是给公司用,而不是贡献社会。而 OpenAI 的出现,在学术界和工业界之外创造了“第三种”可能性:既有学术界相对轻松自由的环境,又有巨头公司近乎无限的现金和充足的算力,并且以推动技术边界的扩展,造福社会为核心目的。然而大约两年前,OpenAI 内部积累的问题突然爆发。当时实行的非营利模式难以为继,机构也终于成立了营利部门。也是在那段时间,一波大神级核心研究员,由于无法接受这一转型,愤然离职。后来的 OpenAI 还是推出了包括 GPT-3、DALL·E 等知名作品,但名声早已大不如前。特别是 DALL·E 二代,明明是当时最领先的 AI 图片生成技术之一,在网上的影响力却不如 DALL·E mini,一个完全无关的个人开发者,所做的业余开源项目。对于 OpenAI 的窘境,“超级富豪” Emad Mostaque 看在眼里,疼在心里。此人身价究竟几何,并没有特别清楚详尽的资料。已经公开的信息显示,他有至少20年的投资基金工作经历,曾经在多家技术和基金公司担任工程师、战略分析师、首席投资官等职位。在累积了巨额财富之后,对于利用自己的技术和资金来开展慈善和推动社会平等、技术普及等事业,这位英国人的兴趣越来越高。他在2019年创办了一家采用技术降低手机套餐成本费用的公司,新冠袭来后又出资并亲自主导在斯坦福大学组建了一个非营利性质的大数据平台项目,与联合国开展合作,旨在辅助各国政府制定防疫政策。而在2020年创办的 Stability AI,则是他的“慈善”事业的最新篇章。根据并不充分的资料,这家机构的早期绝大部分资金都来自 Mostaque 本人。从这个角度来看,他的身份,确实有点像马斯克之于 OpenAI。他决定自己接过使命,成立一家和 OpenAI 早期的非商业模式差不太多,但开放程度更高的机构。总而言之,就是要比 OpenAI 更 “open”。通过 Stability AI,Mostaque 希望能够延续 OpenAI 缔造并发扬光大的 AI 科研“第三种力量”,同时避免重蹈其覆辙。这家新机构也确实在贯彻开放、公益的 OpenAI 早期科研思路:它的第一个对外亮相的产品/技术,就是免费、开源、几乎没有任何商业味道的 Stable Diffusion 模型。Mostaque 曾经表示,目前大约八成的 AI 研究资金全都流向了下一代技术,而这些技术从构思到开发,再到测试和发布的整个过程里,往往都是高度封闭的。作为硅谷大公司里面投身 AI 基础科研最早,投资额最大的公司,谷歌近几年开发的 PaLM、LaMDA、Imagen 等模型的封闭性越来越强,使用门槛相当之高,几乎没有开放给公众的可能性。该公司的 AI 道德委员会,则被一些前委员、公司前员工以及第三方研究人士指责为“没用”,反而成为公司内部 AI 研究部门非道德问题的“遮羞布”。Mostaque 就在想,算力、资金,和公众参与这三个问题,能否一同解决?“这里一定有更好的办法。”有一位网友甚至将 Mostaque 形容为AI 科研领域的 "Gigachad"(超级猛男):“他为人类未来做出的贡献,比其他顶级 AI 公司加起来还要多。”Emad Mostaque 图片来源:Yannic KilcherAI技术分析师 Alberto Romero 则指出,Stability AI 的工作之重要性在于:人们不想看到其他人如何用最先进的技术创造出厉害的艺术作品,他们真正想要的是能够自己上手尝试。而 Stability AI 不光把代码和模型权重放了出来,甚至还更进一步,开发了一个相当友好的无代码、“开袋即食”的网站(DreamStudio Lite),让那些不想也不会写代码的人都能够使用。借助 Mostaque 之前做新冠大数据项目时积累的人脉,Stability AI 目前已经和联合国达成了合作,成为了国家间、学校间和跨国公司之间 AI 技术研发合作的桥梁。最初,整个团队还是在 Discord 聊天应用上运行的——目前很大程度上仍然如此。但今天的 Stability AI,似乎已经超越了 OpenAI 的范畴和意义,在包括学术和工业界的整个 AI 研究和应用领域都受到了巨大的欢迎。通过 Stable Diffusion,更多人体会到了 AI 图片生成技术的强大和美好。最尖端的 AI 模型,不再是少数人独享的玩具,更多用户都能够享受和利用这项技术。Stability AI 的口号是 “AI by the people, for the people.”
中文推特:https://twitter.com/8BTC_OFFICIAL
英文推特:https://twitter.com/btcinchinaDiscord社区:https://discord.gg/defidao电报频道:https://t.me/Mute_8btc电报社区:https://t.me/news_8btc 作者 :巴比特资讯
本文为PANews入驻专栏作者的观点,不代表PANews立场,不承担法律责任。文章及观点也不构成投资意见。
图片来源 : 巴比特资讯 如有侵权,请联系作者删除。














 链得得
链得得 DAOrayaki
DAOrayaki Cabin VC
Cabin VC  PA荐读
PA荐读 深潮TechFlow
深潮TechFlow APP
APP 

