




學生作者| @leesper6
指導老師| @CryptoScott_ETH
首發時間| 2024.4.5

- 並行EVM 是鏈上交易量發展到一定程度後出現的一種新敘事。平行EVM 主要分為單體區塊鏈和模組化區塊鏈。單體區塊鏈又分為L1 和L2 。並行L1 公鏈分為兩大陣營:EVM 和非EVM 。目前並行EVM 敘事處於發展的早期階段;
- 拆解並行EVM 的技術實現路徑,主要包含虛擬機器和平行執行機制兩大面向。在區塊鏈的脈絡下,虛擬機是指對分散式狀態機進行虛擬的進程虛擬機,用於執行合約;
- 並行執行是指發揮多核心處理器的優勢,盡可能在同一時間同時執行多個交易,而保證最終狀態與序列執行時結果一致;
- 並行執行機制分為訊息傳遞、共享記憶體、和嚴格狀態存取清單三大類。共享記憶體又分為記憶體鎖模型和樂觀並行化。無論哪種機制均提高了技術的複雜性;
- 並行EVM 敘事既有產業成長的內在驅動因素,也需要從業人員高度關注其可能存在的安全問題;
- 並行EVM 各標的項目均以不同的方式提供了並行執行思路,既有技術上的共通性又有自己的獨特建樹。


性能已經成為行業進一步發展的瓶頸。區塊鏈網路為個人和企業進行交易創造了一種新的、去中心化的信任基礎。
以比特幣為代表的第一代區塊鏈網路以分散式記帳的方式開創了去中心化的電子貨幣交易新模式,革命性地開創了一個新時代。以以太坊為代表的第二代區塊鏈網路則充分發揮想像力,提出以分散式狀態機的方式實現去中心化應用程式( dApp )。
從那時起,區塊鏈網路開啟了它自己十幾年飛速發展的歷史,從Web3 基礎設施到以DeFi 、 NFT 、社交網路和GameFi 等為代表的各種賽道,誕生了無數或技術或商業模式的創新。產業的蓬勃發展需要不斷吸引新用戶參與去中心化應用的生態建設,這反過來又對產品體驗提出了更高的要求。
而Web3 作為一種「前無古人」的新產品形態,不但要在滿足用戶需求上有所創新(功能性需求),還要考慮怎樣在安全性和性能之間取得平衡(非功能性需求)。自誕生以來,人們提出了各種各樣的解決方案試圖解決效能問題。
這些解決方案大致可分為兩類:一類是鏈上擴容方案,如分片( sharding )和有向無環圖( DAG );一類是鏈下擴容方案,如Plasma 、閃電網路、側鏈和Rollups 等。但這還遠遠跟不上鏈上交易快速成長的速度。
尤其經歷了2020 年DeFi Summer 以及2023 年年末比特幣生態中銘文的持續爆發,業界迫切需要新的性能提升方案來滿足「高效能、低費率」的要求。並行區塊鏈就是在這樣的背景下誕生的。
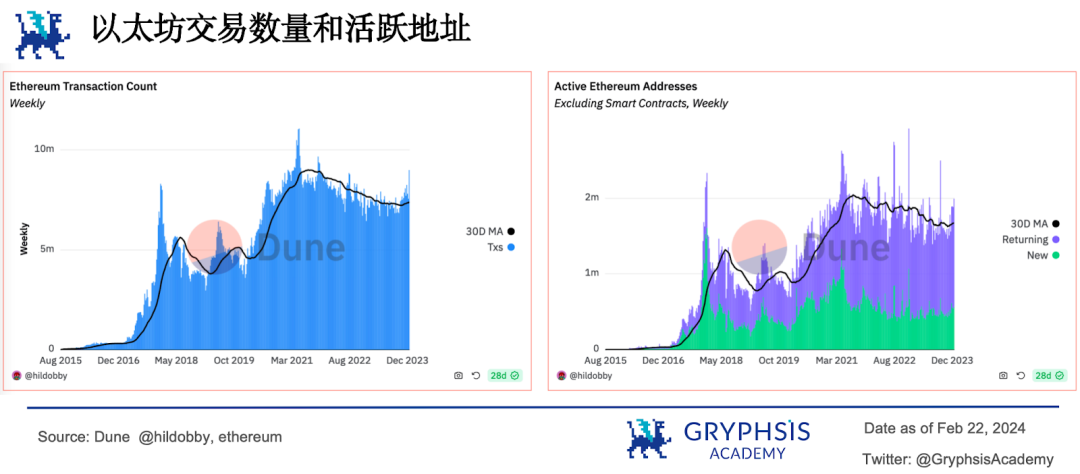

並行EVM 敘事標誌著平行區塊鏈領域形成了兩強相爭的競爭格局。以太坊對交易的處理是串列的,交易要依序一個接一個的執行,資源的利用率不高。如果將串行處理的方式變成平行處理將帶來效能的巨大提升。
以太坊競爭對手如Solana 、 Aptos 和Sui 都是自帶並行處理能力的,生態也發展的很不錯,代幣流通市值分別達到450 億、33 億和19 億美元,它們形成了並行非EVM 陣營。面對挑戰,以太坊生態也不甘示弱,紛紛站出來為EVM 賦能,它們形成了並行EVM 陣營。
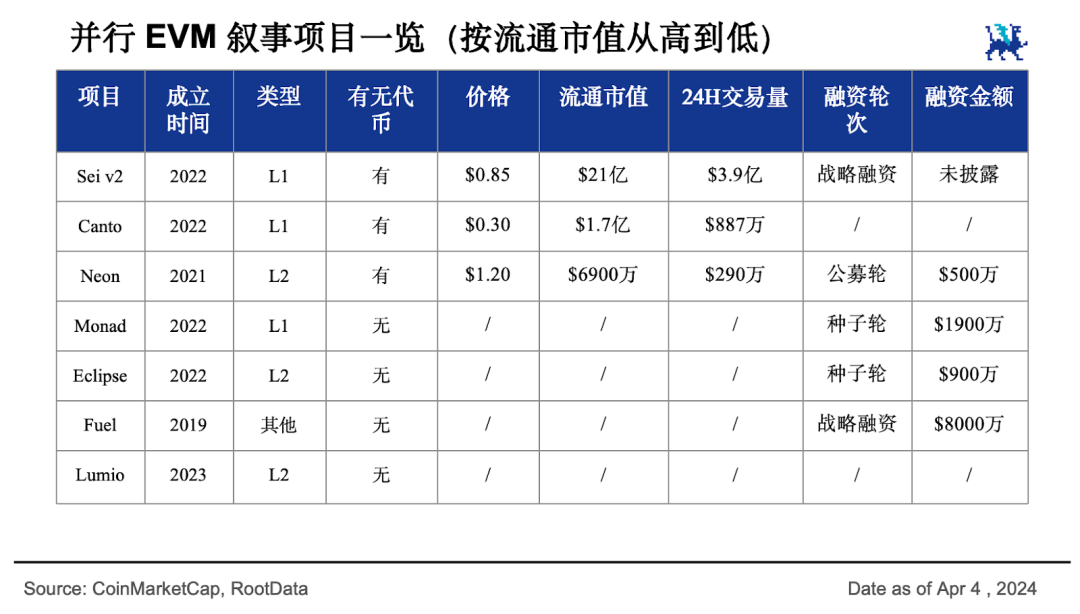
Sei 在其v2 版本升級提案中高調宣稱將成為“第一個並行EVM 區塊鏈”,當前流通市值21 億美元,預後還有更大的發展。當下行銷熱度第一的平行EVM 新公鏈Monad 很受資本青睞,潛力也不可小視。而市值1.7億美元、自備免費公共基礎設施的L1 公鏈Canto 也宣布了自己的平行EVM 升級提案。
除此之外,一眾還處在早期階段的L2 專案也在透過整合多種L1 鏈的能力提供跨生態的效能提升。除Neon 做到了6,900 萬美元流通市值外,其他項目還缺乏相關數據。相信未來還會出現更多的L1 和L2 項目加入並行區塊鏈戰場。
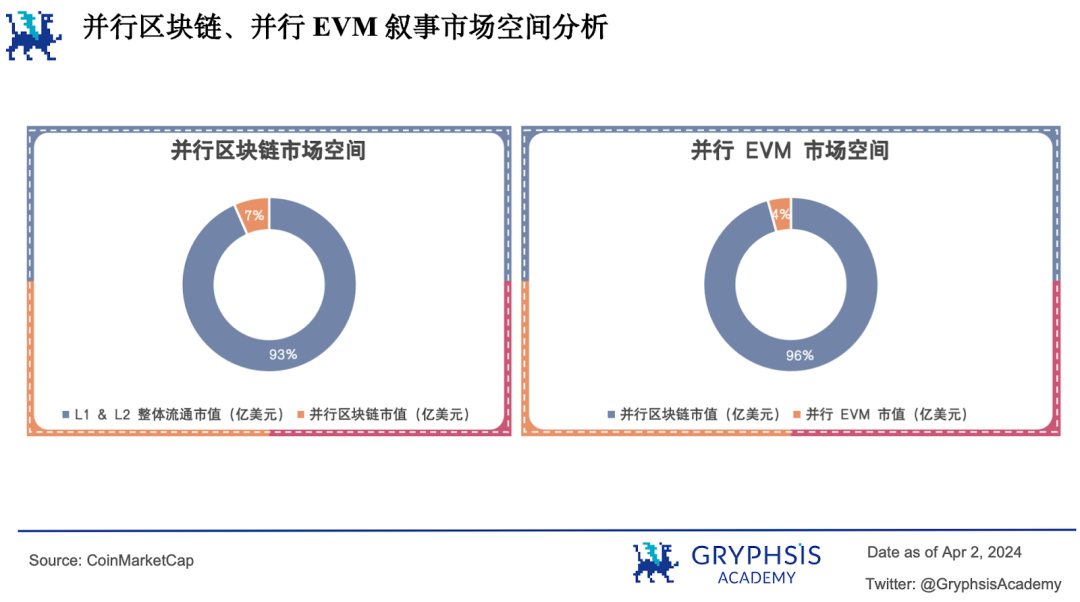
不但並行EVM 敘事還有很大的市場成長空間,而且並行EVM 敘事所屬的平行區塊鏈板塊也還有很大的市場成長空間,因此市場前景廣闊。
目前L1 和L2 整體流通市值為7,521.23 億美元,並行區塊鏈流通市值為525.39 億美元,僅佔約7% 。而其中平行EVM 敘事相關項目流通市值23.39 億美元,僅佔平行區塊鏈流通市值的4% 。

業界一般將區塊鏈網路分為4 層結構:
- Layer 0(網絡):區塊鏈底層網絡,處理基礎的網路通訊協議
- Layer 1(基礎設施):依賴各種共識機制對交易進行驗證的去中心化網絡
- Layer 2(擴展):依賴Layer 1 的各種二層協議,旨在解決Layer 1 的各種局限性,尤其是可擴展性
- Layer 3(應用程式):依賴Layer 2 或Layer 1 ,用於建構各種去中心化應用程式( dApp )
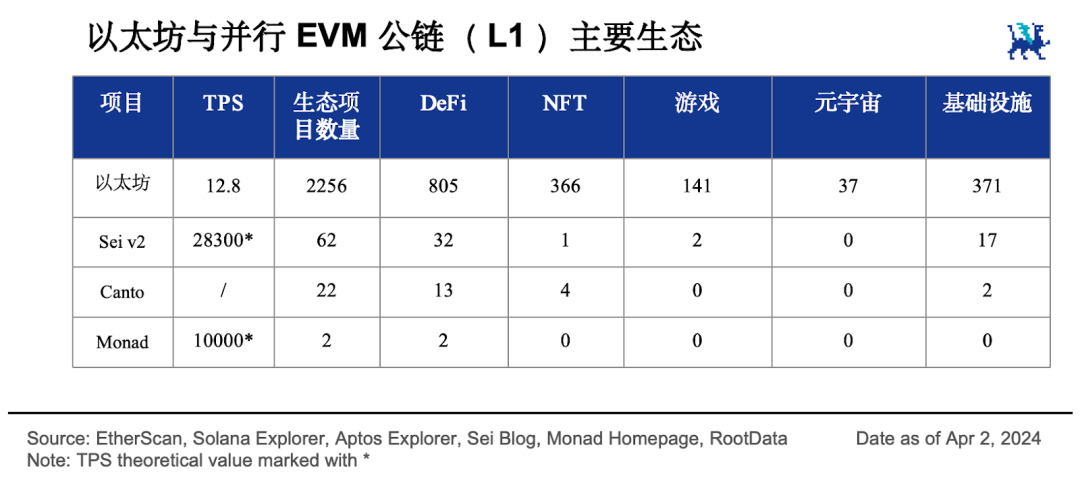
平行EVM 敘事專案主要分為單體區塊鏈和模組化區塊鏈,單體區塊鏈又分為L1 和L2 。從項目總數和幾個主要賽道的發展可以看出,各並行EVM L1 公鏈生態相比以太坊生態仍然存在很大的發展空間。
DeFi 賽道有「高速低費率」的訴求,遊戲賽道有「強即時互動」的訴求,二者都對執行速度有一定要求。並行EVM 必然會為這些專案帶來更好的使用者體驗,推動產業的發展進入到全新的階段。
L1 是自備並行執行能力的新公鏈,是高效能基礎架構。 L1 這一派中,以Sei v2、Monad 和Canto 為代表的專案自行設計並行EVM ,相容於以太坊生態並提供高吞吐量交易處理能力。
L2 透過整合其他L1 鏈的能力,提供跨生態合作的擴容能力,是rollup 的顯學。 L2 這一派中, Neon 是Solana 網路上的EVM 模擬器, Eclipse 利用Solana 執行交易但在EVM 上做結算。 Lumio 與Eclipse 類似,只是把執行層換成了Aptos 。
在上述單體區塊鏈解決方案之外, Fuel 提出了自己的模組化區塊鏈思路。它將在第二個版本中將自己定位成以太坊rollup 作業系統,提供更靈活、更徹底的模組化執行能力。
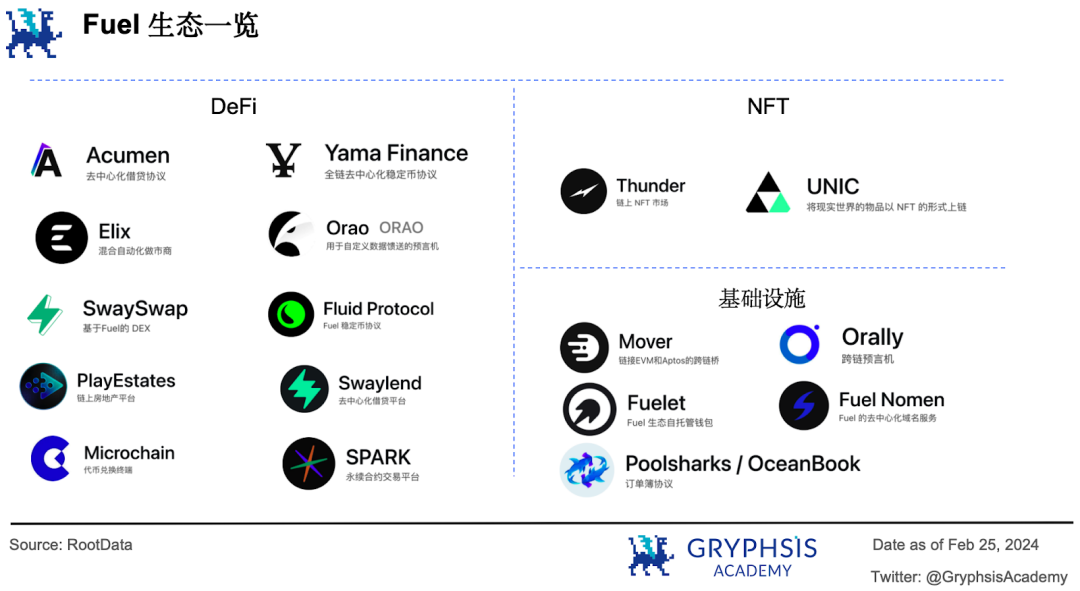
Fuel 專注於執行交易,而將其餘部分外包給一個或多個獨立層的區塊鏈,從而實現更靈活的組合:既可以成為L2 ,也可以成為L1 ,甚至是側鏈或狀態通道。目前Fuel 生態有17個項目,主要集中在DeFi 、 NFT 和基礎設施三個領域。
不過只有Orally 跨鏈預言機已投入實際應用。去中心化借貸平台Swaylend 和永續合約交易平台SPARK 上了測試網,其他項目還在開發中。

要實現去中心化的交易執行,區塊鏈網路必須履行4 個職責:
- 執行:執行和驗證交易
- 數據可用性:分發新區塊到區塊網路的所有節點
- 共識機制:驗證區塊,達成共識
- 結算:結算並記錄交易的最終狀態
並行EVM 主要是對執行層的效能最佳化。這又分為一層網路( L1 )解決方案和二層網路( L2 )解決方案兩種。 L1 的解決方案引入交易並行執行機制,讓交易在虛擬機器中盡量並行執行。 L2 的解決方案本質上是利用已經並行化的L1 虛擬機器來實現某種程度的「鏈下執行+鏈上結算」。
所以要理解並行EVM 的技術原理,就要將其拆解開來:先理解什麼是虛擬機器( virtual machine )再理解什麼是並行執行( parallel execution )。

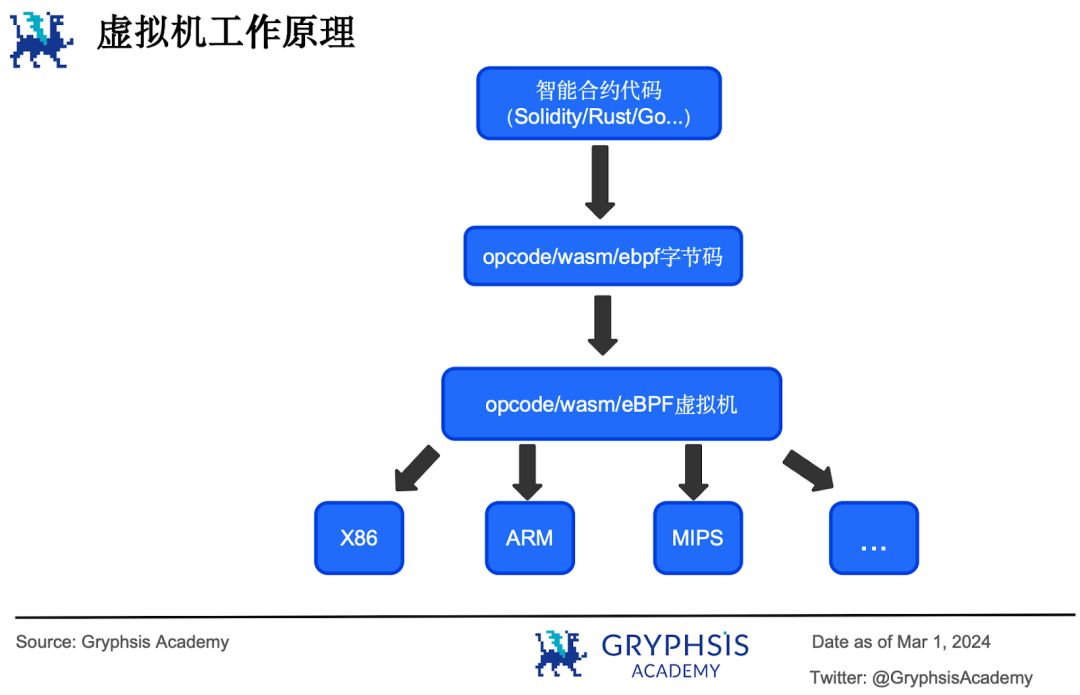
在電腦科學中,虛擬機器是指對電腦系統進行的虛擬( virtualization )或模擬( emulation )。
虛擬機器分為兩種,一種叫系統虛擬機器( system virtual machine ),可以將一台實體機虛擬化為多台機器,運行多個作業系統,進而提高資源利用率。另一種叫做進程虛擬機器( process virtual machine ),為某些高階程式語言提供抽象,讓使用這種語言編寫的電腦程式以一種平台無關的方式運作在不同平台上。
JVM 就是一種為Java 程式語言設計的進程虛擬機器。 Java 語言編寫的程式首先被編譯成Java 字節碼(一種中間狀態的二進位代碼), Java 字節碼由JVM 解釋執行:JVM 將字節碼送給解釋器,由解釋器翻譯成不同機器上的機器碼,然後在機器上運作。
區塊鏈虛擬機器是進程虛擬機器的一種。在區塊鏈的脈絡下,虛擬機器是指分散式狀態機的虛擬,用於分散式執行合約,運行dApp 。類比JVM , EVM 是一種為Solidity 語言設計的進程虛擬機,智能合約首先被編譯成opcode 字節碼,然後由EVM 解釋執行。
以太坊以外的新興公鏈在實現自己的虛擬機器時,更多採用的是基於WASM 或eBPF 字節碼的虛擬機器。 WASM 是一種體積小、載入快、可移植且基於沙盒安全機制的字節碼格式,開發人員可以使用多種程式語言( C 、 C++ 、 Rust 、 Go 、 Python 、 Java 甚至TypeScript 等)編寫智能合約,然後編譯成WASM 字節碼並執行。 Sei 公鏈上執行的智能合約正是採用了這一字節碼格式。
eBPF 前身是BPF ( Berkeley Packet Filter ,伯克利包過濾器),原本是用於網路資料包的高效過濾,後來演化形成了eBPF ,提供更豐富的指令集。
它是一項允許在不改動原始碼的情況下對作業系統核心進行動態幹預和修改其行為的革命性技術。後來這項技術從核心中走出來,發展出了用戶態eBPF 運行時,具有高效能、安全性和可移植性。在Solana 上執行的智能合約都會編譯成eBPF 字節碼並在其區塊鏈網路上運行。
而其他的L1 公鏈中, Aptos 和Sui 使用Move 智慧合約程式語言,編譯成特有的字節碼在Move 虛擬機器上執行。 Monad 則自行設計了相容EVM opcode 字節碼( Shanghai fork )的虛擬機器。

並行執行是這樣一種技術:
- 能夠發揮多核心處理器的優勢同時處理多個任務,增大系統吞吐量;
- 確保所得的交易結果與依序串列執行交易時完全相同。
區塊鏈網路常用TPS (每秒處理的交易數量)作為衡量處理速度的技術指標。平行執行的機制比較複雜,也很考驗開發人員的技術水平,要解釋清楚並不容易。下面從一個「銀行」的例子入手,解釋什麼是並行執行。
首先,什麼是串行執行?
狀況1:如果我們把系統看成一家銀行,把處理任務的CPU 看成櫃檯,那麼串列執行任務就好比這家銀行只有一個櫃檯受理業務。此時來銀行辦業務的客戶(任務)只能排成一條長龍,挨個辦業務。對於每位客戶,櫃檯人員都要重複同樣的動作(執行指示)來為客戶辦理業務。沒有輪到自己時客戶只能等待,這就造成交易時間的延長。
那什麼是並行執行呢?
情況2:此時銀行看到人滿為患,就多開了幾個櫃檯來處理業務,有4 個櫃員在櫃檯同時處理業務,速度就比原來快了約4 倍,那麼客戶排隊的時間大約也減少到了原來的1/4,銀行辦理業務的速度就提升。
如果不做保護,兩個人同時轉帳給另一個人會發生什麼錯誤?
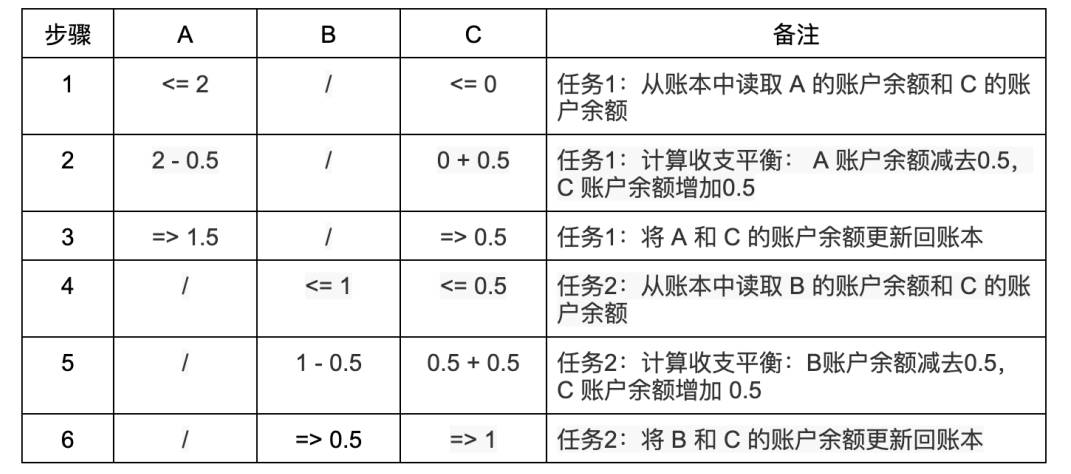
情境3:A 、 B 和C 三個人,他們的帳戶上分別有2 ETH 、1 ETH 和0 ETH ,現在A 和B 分別要給C 轉帳0.5 ETH 。在一個交易串列執行的系統中,不會出現任何問題(左箭頭「<=」表示讀取帳本,右箭頭「=>」表示寫入帳本,下同):
但並行執行並沒有它看起來的那麼簡單。有很多很微妙的細節,稍微不注意就會導致非常嚴重的錯誤。如果A 和B 對C 的轉帳交易是並行執行的,那麼根據每個步驟執行先後順序的不同,就有可能產生不一致的結果:
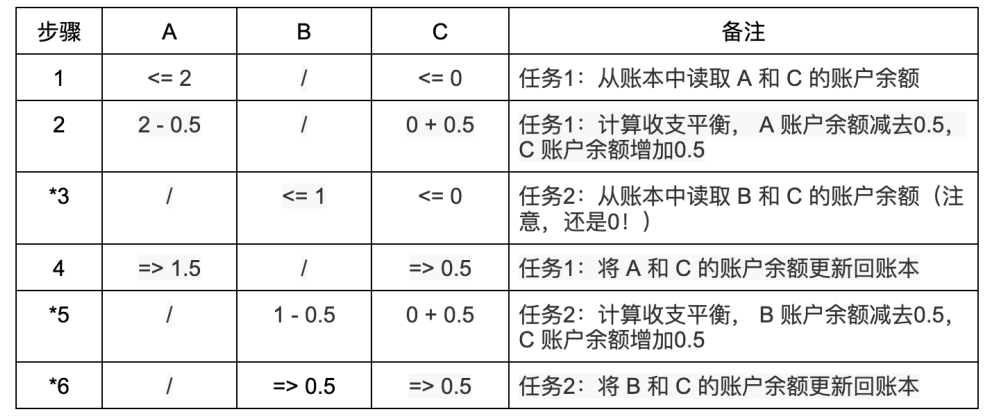
並行任務1 執行A 到C 的轉賬,並行任務2 執行B 到C 的轉帳。表中帶*號的步驟都是有問題的:由於任務是並行執行的,在步驟2 中並行任務1 做的收支平衡計算還沒來得及寫入賬本,在步驟3 中任務2 就把C 的帳戶餘額(此時仍然是0 )讀取出來了,並在步驟5 中基於餘額0做了錯誤的收支平衡計算,然後在步驟6 的賬本更新操作中把步驟4 中已經更新的帳戶餘額0.5錯誤地再次更新成了0.5。導致雖然A 和B 都同時轉帳了0.5 ETH 給C ,而交易執行完畢後C 的帳戶餘額卻只有0.5 ETH ,另外0.5 ETH 不翼而飛了。
如果不做保護,沒有依賴關係的兩個任務並行執行不會出錯
狀況4:並行任務1執行A (餘額2 ETH )轉帳0.5 ETH 給C (餘額0 ETH ),並行任務2執行B (餘額1 ETH )轉帳0.5 ETH 到D (餘額0 ETH )。可以看到兩個轉帳任務之間沒有依賴關係。那麼不管兩個任務的步驟如何交錯執行,都不會出現上面的問題:
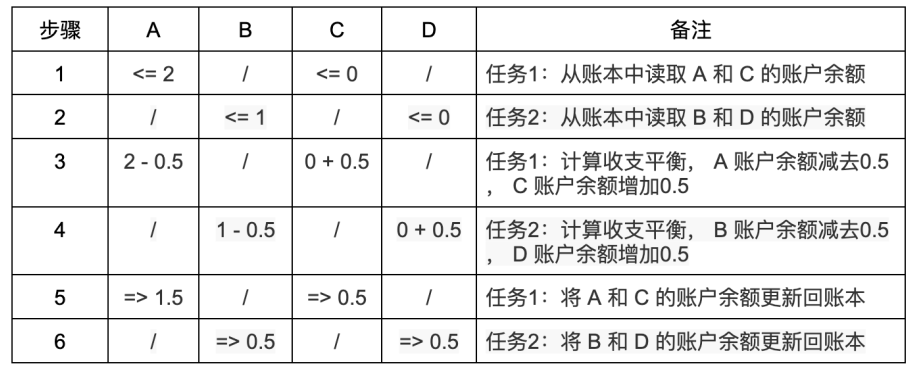
從兩種場景的比較可以分析得出,只要任務之間有依賴,並行執行時就有可能發生狀態更新錯誤,反之則不會發生錯誤。滿足以下2 個條件之一,就稱任務(交易)之間是有依賴關係的:
- 一個任務寫入的輸出位址是另一個任務讀取的輸入位址;
- 兩個任務輸出到同一個位址。
這並不是去中心化特有的。任何涉及並行執行的場景都會因為多個有依賴的任務之間不受保護地存取共享資源(銀行例子中的「帳本」、電腦系統中的共享記憶體等)而出現資料不一致,稱為競態條件問題( data races )。
業界在解決平行執行的競態條件問題上提出了三種執行機制:訊息傳遞機制、共享記憶體機制和嚴格狀態存取清單機制。

情況5 :假設銀行有4 個櫃檯同時為客戶辦理業務,現在給4 個櫃檯的櫃員每個人手裡發一本專屬賬本,這個賬本只有自己能修改。上面記錄了自己所服務的客戶的帳戶餘額。
每位櫃員在為客戶辦理業務時,如果該客戶的資訊在自己的帳本上能查到,那麼就直接辦理;否則就給別的櫃員喊話告知客戶要辦理的業務,別的櫃員聽到後進行辦理。
這就是訊息傳遞模型的原理。 Actor 模型就是訊息傳遞模型的一種,每一個負責處理交易的執行者都是一個actor (櫃員),它們都有可以存取自己的私有資料(專屬帳本),如果要存取別人的私有數據,只能透過發送訊息來實現。
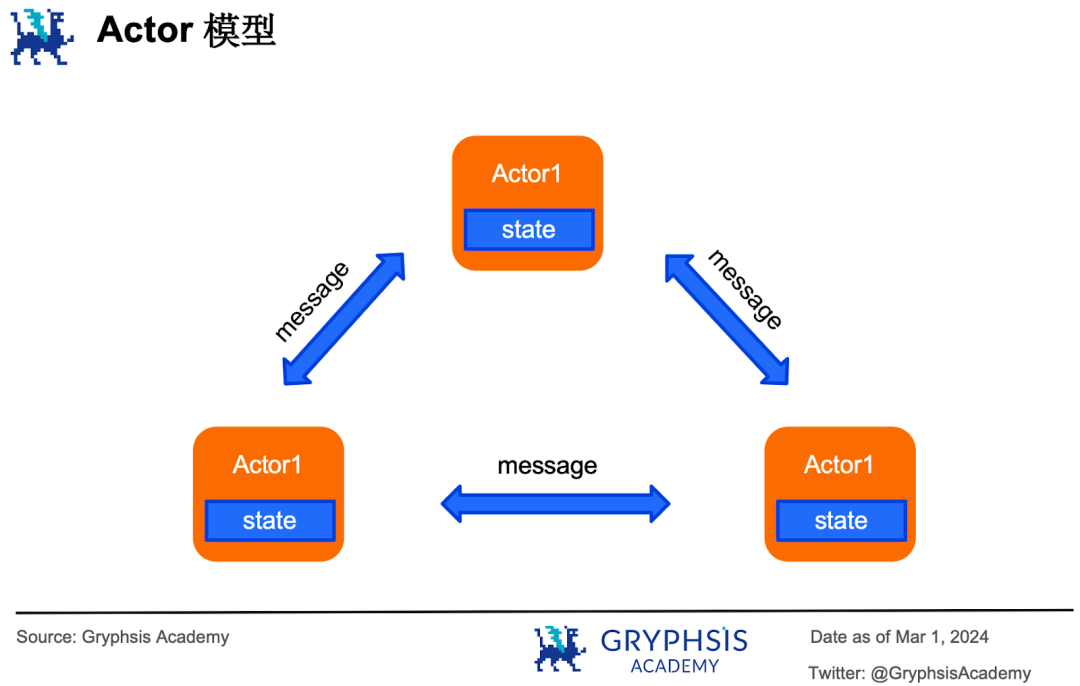
Actor 模型的優點在於每個actor 都只能存取自己的私有數據,因此就不會出現競態條件問題。
它的缺點有2 個,一是每個actor 都只能串列地執行,在某些場景中並沒有發揮並行優勢(例如2 號、3 號和4 號櫃員同時發訊息問1 號櫃員客戶A的帳戶餘額是多少,1 號櫃員在這樣的模型中就只能一個一個的處理訊息,而這本來是可以並行處理的)。
二是沒有一個全局的有關當前系統狀態的信息,如果系統業務複雜,將很難了解全貌、定位和修復bug 。


情況6 :假設銀行只有一個大帳本,上面記錄了所有客戶的帳戶餘額。帳本旁邊只有一支簽字筆可以用來修改帳本。
在這種場景下,4 個櫃員在辦理業務時就看誰跑得快了:一個櫃員搶先拿到簽字筆(加鎖)開始辦理業務修改賬本,其他3 個櫃員就只能等著。直到櫃員用完將筆放下(解鎖),其他3 個櫃員再去爭奪簽字筆的使用權,如此循環下去,這就是內存鎖模型( memory locks )。
記憶體鎖就是讓並行執行的任務在訪問共享資源的時候做一個鎖( lock )的操作,鎖住之後對共享資源進行訪問,此時別的任務要等待它修改完之後解鎖( unlock )才能再次鎖住並訪問。
讀寫鎖( read-write lock )的處理更精細化,可以對共享資源加讀鎖( read lock )或寫入鎖( write lock )。差異是多個平行任務可以加多次讀鎖並讀取共享資源數據,此時不允許修改;而寫鎖只能加一把,且加了之後只能由加鎖者獨佔存取。
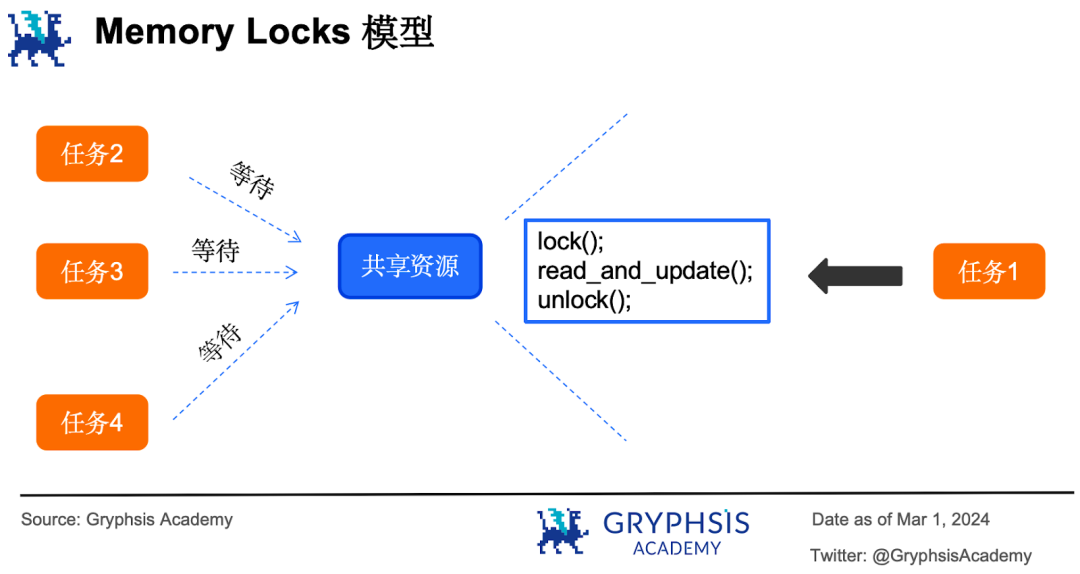
Solana 、 Sui 和Sei v1 採用的就是基於記憶體鎖的共享記憶體模型。這種機制看起來簡單,但實作起來很複雜,很考驗開發人員對多執行緒程式設計的駕馭能力。一個不小心,就會留下各種各樣的bug :
- 情況1:任務鎖住共享資源,但在執行的過程中因出錯崩潰而退出,共享資源被鎖住無法存取;
- 狀況2:任務已經加鎖,但是執行過程中因業務邏輯嵌套出現二次加鎖,導致自己等待自己。
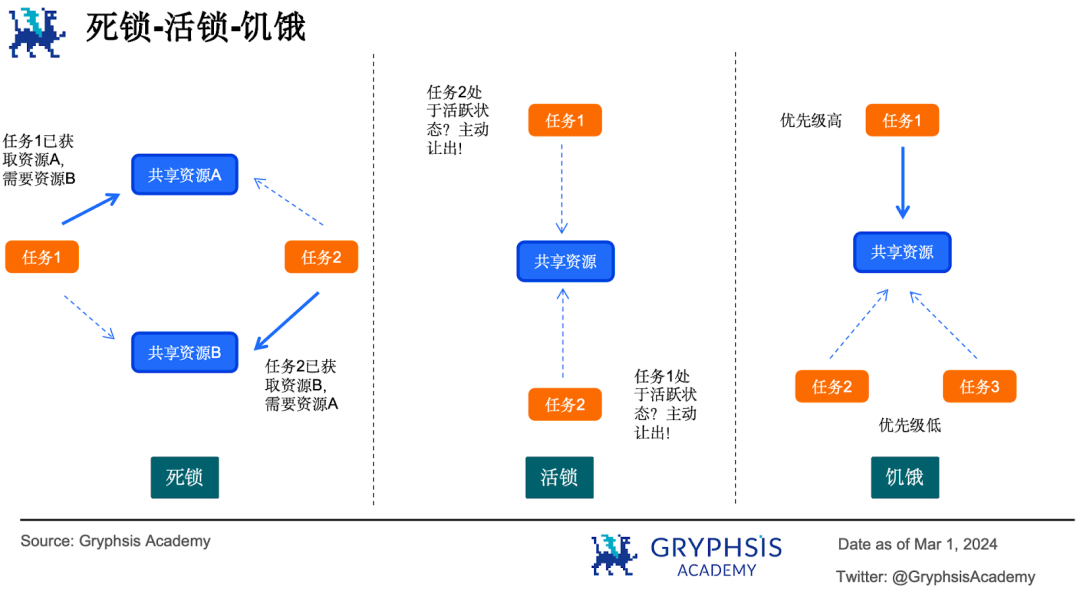
記憶體鎖模型最容易出現死鎖( dead lock )、活鎖( live lock )和飢餓( starvation )等問題:
多個並行任務爭奪多個共享資源,每個任務都佔有了其中的一部分,都在等待對方釋放資源,就會出現死鎖問題;
平行任務偵測發現還有其他平行任務處於活躍狀態,於是主動讓出自己佔有的共享資源,導致你讓過來我讓過去,發生活鎖;
優先順序高的平行任務總是能獲得共享資源存取權,其他低優先任務長時間等待,發生「飢餓」。

情況7 :銀行4 個櫃員每個人在辦理業務時都可以獨立查閱和修改帳本,而不管別的櫃員在沒在用帳本。櫃員使用帳本時在自己查閱和修改了的內容上貼上個人專屬標籤。每次辦完業務後都會再瀏覽一遍,如果發現貼的不是自己的標籤,說明記錄被別的櫃員修改過了,本次業務就要作廢並重新辦理。
這就是樂觀並行化的基本原則。樂觀並行化的核心思想是先假設所有的任務都是相互獨立的。先並行執行任務,然後再驗證每個任務,如果驗證不通過,則把這個任務重新執行一遍,直到所有任務執行完畢。假設有8 個平行任務以樂觀並行化的方式執行,期間需要存取2 個共享資源A 和B 。
階段1 執行時,任務1、任務2 和任務3 並行執行。但任務2 和任務3 同時存取共享資源B 產生了衝突,因此任務3 在下一階段重新調度執行。階段2執行時任務3 和任務4 同時存取了共享資源B ,此時任務4 重新調度執行,以此類推,直到所有任務執行完畢。可以看到整個過程中發生衝突的任務會不斷地重複執行。
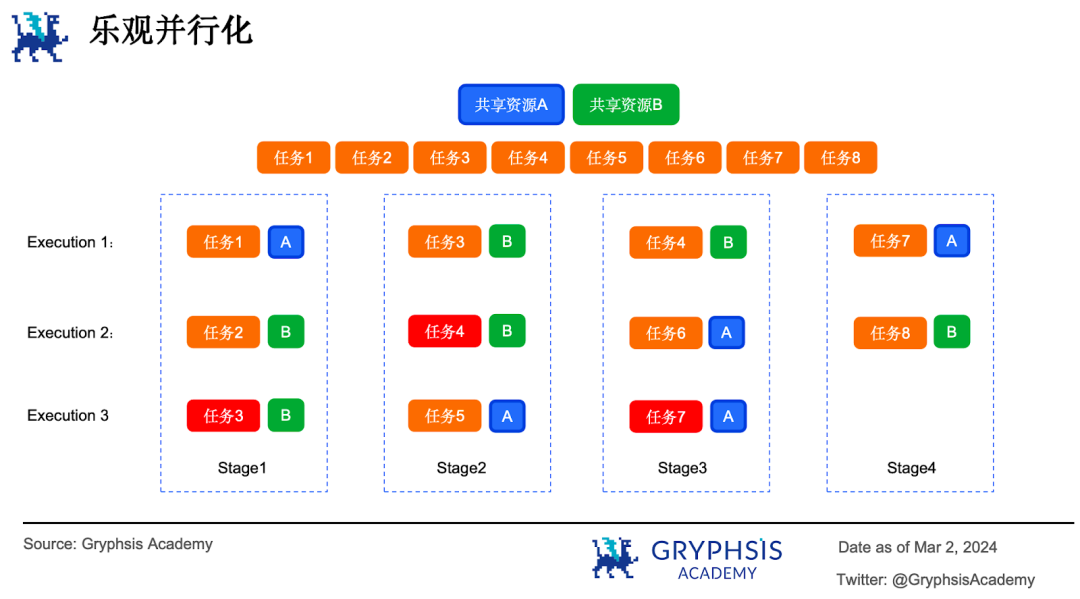
樂觀並行化模型採用了一種多版本記憶體資料結構( multi-version in-memory data structure )用來記錄每一個寫入值及其版本資訊(類似於銀行櫃員貼標籤)。
每個並行任務的運作分為兩個階段:執行( execution )和驗證( validation )。執行階段會把所有讀取資料和寫入資料的行為記錄下來,形成讀集( read set )和寫集( write set )。驗證階段會以讀集和寫集與多版本資料結構進行對比,如果對比發現不是最新的,則驗證不通過。
樂觀並行化模型發端於軟體事務記憶體( Software Transaction Memory ,簡稱STM ),後者是資料庫領域無鎖程式設計的機制。由於區塊鏈網路對交易的處理天然的具備一種確定的順序,因此這個概念被引入並演化出了Block-STM 機制。 Aptos 和Monad 採用了Block-STM 作為自己的平行執行機制。
值得一提的是, Sei 公鏈在即將發布的v2 版本中棄用了原來的記憶體鎖模型,改為採用樂觀並行化模型。 Block-STM 執行速度極快,實驗環境中Aptos 交易執行速度達到了驚人的160k tps ,比順序執行交易快了18 倍。
Block-STM 把複雜的交易執行和驗證交給了實現底層機制的核心團隊,開發者可以毫不費力地像寫順序執行的程式一樣編寫智慧合約。

訊息傳遞和共享記憶體機制是基於帳戶/餘額資料模型實現的,它記錄了每個鏈上帳戶的餘額資訊。就好比銀行的帳本中記錄的是客戶A 有餘額1000 元,客戶B 有餘額600 元,每次處理交易只需要修改一下帳戶餘額狀態。
如果換一種思路,還可以在每次交易時只記錄交易的具體內容,形成交易流水,也能透過交易流水來計算用戶的帳戶餘額,例如有如下的交易流水:
- 客戶A 開戶並存入1000元;
- 客戶B 開戶(0元);
- 客戶A 向客戶B 轉帳100元。
透過讀取流水並進行計算,可以知道當前客戶A 帳戶餘額為900元;客戶B 帳戶餘額為100元。
UTXO ( unspent tx output ,未花費的交易輸出)就類似這樣的交易流水資料模型,它是第一代區塊鏈比特幣用來表示數位貨幣的一種方式。每一筆交易都有輸入(怎麼獲得的)和輸出(怎麼花掉的),而UTXO 可以簡單理解為還沒花掉的收款。
例如客戶A 有6 個BTC ,他給客戶B 轉帳5.2 個BTC ,還剩0.8 個BTC ,從UTXO 的角度就可以看成:A 的6 個價值1 BTC 的UTXO 被銷毀, B 獲得了1 個價值為5.2 BTC 的新生成的UTXO ,同時找零給A 一個價值0.8 BTC 的新生成的UTXO 。即6 個UTXO 被銷毀,產生了2 個新的UTXO 。
交易的輸入和輸出串成鏈,並使用數位簽章記錄所有權訊息,就形成了UTXO 模型。採取這種資料模型的區塊鏈需要對某個帳戶位址的所有UTXO 求和,才能知道目前帳戶餘額。嚴格狀態存取清單( strict state access list )基於UTXO 模型實作並行執行。它會提前計算每個交易要存取的帳戶地址,形成存取清單。
訪問清單有兩個作用:
- 判斷交易安全性:交易執行時如果存取了不在存取清單中的位址,則執行失敗。
- 並行執行交易:根據存取清單形成交易的多個集合,每個交易集合之間在存取清單上沒有交集(沒有依賴),因此多個交易集合就可以並行執行了。

從內在規律上看,任何事物的發展都會經歷」從無到有「到」從有到優「的過程,人類對更快速度的追求是永恆的。為解決區塊網路執行速度的問題誕生了各種各樣或鏈上或鏈下的解決思路。以rollup 為代表的鏈下解決方案已得到充分的價值發現,而並行EVM 敘事還有很大探索空間。
從歷史背景上看,隨著SEC 批准現貨比特幣ETF 和即將發生的比特幣減半等事件,再疊加美聯儲可能的降息操作,加密貨幣預期將迎來一段大牛市,行業的蓬勃發展需要更大吞吐量的區塊鏈網路基礎設施作為堅實的基礎。
從資源管理來看,傳統的區塊網路是串列地處理交易的,這種處理方法雖然簡單,但也是對處理器資源的一種浪費。而平行區塊鏈實現了運算資源的物盡其用,充分」榨乾「了多核心處理器的效能,提高了區塊網路的整體效能。
從產業的發展來看,雖然各種技術和商業模式的創新層出不窮,但Web3 的成長潛力仍有待挖掘。中心化網路能做到每秒推送50000 多條訊息、發送340 萬封郵件、完成100000 次谷歌搜尋並讓成千上萬個玩家同時在線,而去中心化暫時還做不到。去中心化要與中心化分庭抗禮,拿下屬於自己的半壁江山,不斷優化並行執行機制,提高交易的吞吐量也是發展的必經之路。
從去中心化應用程式的發展上看,要吸引更多用戶,體驗上一定要下功夫。效能優化是提升使用者體驗的方向之一。對於DeFi 用戶來說,要滿足高交易速度,低費率的需求。對於GameFi 用戶來說,要滿足即時互動的需求。這些都需要並行執行作為支撐。

去中心化、安全性和可擴展性三者只能滿足其二,此為區塊鏈不可能三角。既然「去中心化」是不可撼動的一極,那麼「可擴展性」的提升就意味著「安全性」的降低。程式碼是人寫的,是人寫的就容易出錯。並行計算所帶來的技術複雜性為安全隱患的滋生提供了溫床。
多執行緒程式設計一是容易因為各種複雜的並發控制操作不當導致競態條件問題;二是容易因為訪問了無效的記憶體位址導致崩潰,甚至出現容易被攻擊者利用的緩衝區溢位漏洞。
至少能從三個角度評估項目的安全性。一看團隊背景。有系統程式設計經驗的團隊對多執行緒程式設計有豐富的經驗,看過並能處理80%的疑難雜症。系統編程一般涉及以下領域:
- 作業系統
- 各類設備驅動
- 檔案系統
- 資料庫
- 嵌入式裝置
- 密碼學
- 多媒體編解碼
- 記憶體管理
- 網路
- 虛擬化
- 遊戲
- 高階程式語言
二看程式碼可維護性,編寫可維護性強的程式碼是有章可循的,例如清晰的架構設計,合理運用設計模式實現程式碼的可複用性,運用了測試驅動開發技術編寫了足夠多的單元測試程式碼,透過合理的重構消除重複程式碼等等。
三看採用的程式語言,有的新銳程式語言從設計上就強調記憶體安全的高並發性。編譯器會檢查程式碼,一旦發現程式碼有並發問題或可能存取無效的記憶體位址,就會編譯失敗,從而強迫開發者寫出足夠健壯的程式碼。
Rust 語言就是出類拔萃者,這就是為什麼我們會看到絕大多數並行區塊鏈專案都是用Rust語言開發的原因。有的項目甚至借鑒了Rust 語言的設計實現了自己的智能合約語言,例如Fuel 的Sway 語言等等。



Sei 是基於開源技術的通用公鏈,於2022 年成立。兩位創辦人來自加州大學柏克萊分校,團隊其他成員也都具有海外名校背景。
Sei 共獲得3 輪融資,其中種子輪500 萬美元,第一輪戰略融資3000 萬美元,第二輪戰略融資未披露。 Sei Network 也募集了總共1 億美元基金,用於支持其生態發展。
2023 年8 月, Sei 在主網上線,號稱速度最快的L1 公鏈,每秒可執行12500 筆交易,最終確定性僅需380 ms,目前流通市值近22 億美元。
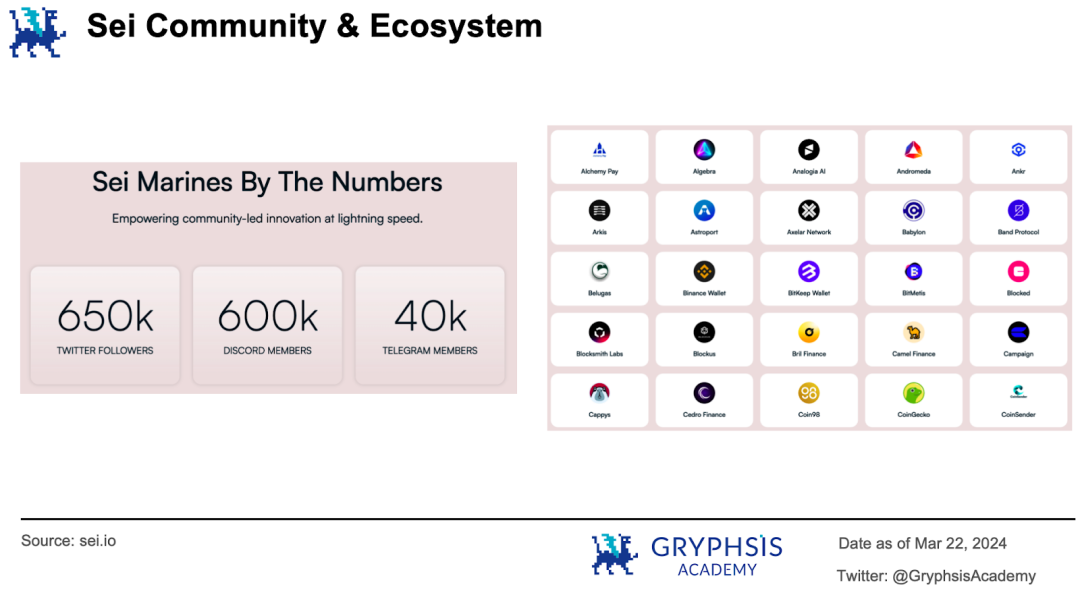
目前Sei 生態有118 個項目,主要集中在DeFi 、基礎設施、 NFT 、遊戲和錢包等賽道。社群目前在Twitter 、 Discord 和Telegram 分別有65 萬、60 萬和4 萬名成員。
2023 年11 月末, Sei 在其官方部落格宣布將於2024 年上半年啟動主網上線後最大的一次版本升級:Sei v2 。 Sei v2 號稱第一條並行EVM 區塊鏈,本次版本升級將帶來以下新功能:
- 對EVM 智能合約的向後相容:開發人員不用修改程式碼就可以遷移部署EVM 智能合約
- 對諸如Metamask 等常見工具/應用的重用
- 樂觀並行化:Sei v2 將放棄記憶體鎖的共享存取機制,轉而採用樂觀並行化
- SeiDB :對儲存層的最佳化
- 支援以太坊和其他鏈之間的無縫互通性
Sei 網路原先的交易並行執行是基於記憶體鎖定模型實現的。在執行前所有待處理交易之間的依賴關係都會被解析並產生DAG ,然後基於DAG 對交易的執行順序進行精確編排,這種方式增加了合約開發人員的心智負擔,因為他們不得不在開發合約時將邏輯編寫到程式碼中。
如同上面技術原理部分所介紹的,新版本採用樂觀並行化之後,開發人員就可以像寫順序執行的程序那樣開發智能合約了。交易的調度、執行和驗證等一系列複雜機制,都由底層模組負責處理。核心團隊在優化的提案設計上也引進透過預填充依賴關係更進一步提升並行執行能力的設計。
具體來說就是引入動態的依賴生成器,在執行前先分析交易的寫入操作並將其預先填入多版本記憶體資料結構中,優化潛在的資料爭用。核心團隊經過分析得出結論,這樣的優化機制雖然不利於最好情況下的交易處理,但會顯著提升最壞情況下的執行效率。


如果你錯過了上面一眾公鏈的發展,那麼Monad 你一定不能錯過。因為它被譽為L1 賽道的潛在顛覆者。
Monad 由Jump Crypto 的兩位高級工程師於2022 年創立,專案於2023 年2 月完成1,900 萬美元種子輪投資,2024 年3 月, Paradigm 就領投Monad 的一輪超2 億美元的融資進行談判,如果成功,這將是自開年以來最大的一筆加密貨幣融資。
目前專案已經成功實現了上線內部測試網的里程碑任務,正朝著下一步開放公共測試網而努力。
Monad 深受資本青睞有兩個突出的原因:一是技術背景過硬,二是善於行銷炒作。 Monad Labs 團隊核心成員有30 人,均在高頻交易、核心驅動和金融科技領域深耕數十年,在分散式系統領域有豐富的開發經驗。
專案的日常運作也十分的「接地氣」:持續對其Twitter 上20 萬追蹤者和Discord 上15 萬名成員進行「魔性行銷」。例如每週舉辦meme 大賽,向社區徵集各種奇奇怪怪紫色動物的表情包或視頻,在社區進行「精神傳播」。

Monad 的願景是成為開發者的智慧合約平台,為以太坊生態帶來極致的效能提升。 Monad 為以太坊虛擬機器引進了兩項機制:一是超標量管線技術,二是改良的樂觀並行機制。
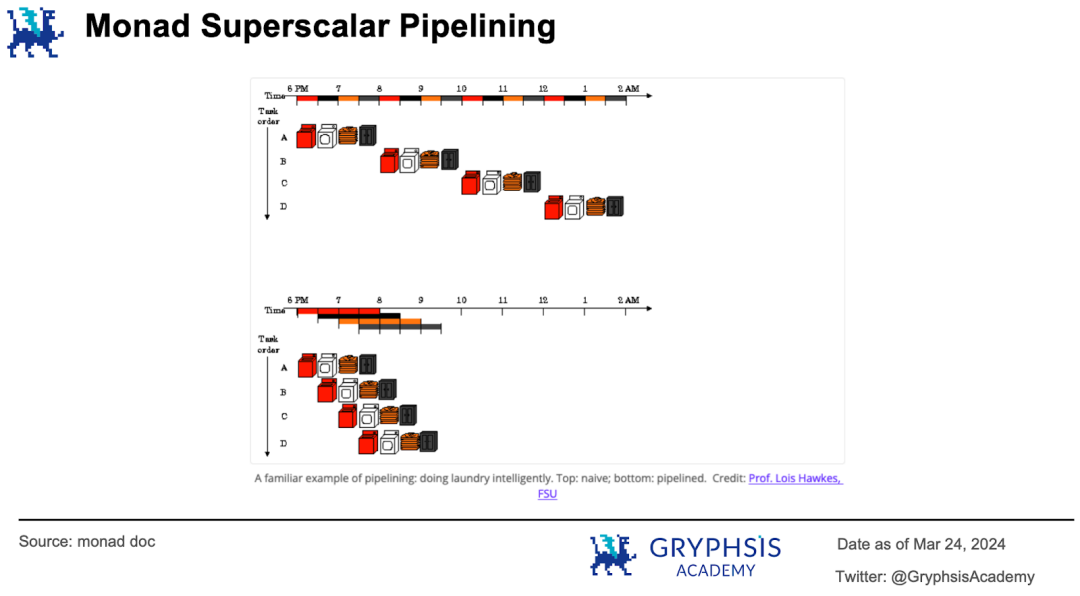
超標量管線技術將交易的執行階段並行化。官方文件舉了一個很形象的例子。洗衣服就像區塊鏈對交易的處理,也要分多個階段完成。傳統的處理方式是將每堆髒衣服清洗、烘乾、折疊和儲存,然後再處理下一堆。
超標量流水線則是在第一堆衣服烘乾的時候就開始第二堆衣服的清洗,第一堆衣服在折疊的時候第二堆、第三堆衣服已經在分別烘乾和清洗了,因此每一個階段的處理都不閒著。
樂觀並行機制將交易的執行並行化。 Monad 採用了樂觀並行化實作並行執行。它還實現了自己的靜態程式碼分析器,用於預測交易之間的依賴關係,僅在前置的依賴交易執行完畢後再調度後續交易執行,這樣就大大減少了因驗證失敗導致的交易重複執行。
目前效能達到10000 TPS 並能在1 秒的時間出塊。隨著專案的進展,核心團隊也會持續探索更多的最佳化機制。
成立於2022 年,沒有官方基金會、不搞預售、不歸屬任何組織、不進行融資,完全依靠社區驅動,甚至連核心團隊都是匿名的,以鬆散的組織方式進行工作。這就是基於Cosmos SDK 打造的、高度去中心化的L1 專案Canto 。
雖然是相容EVM 的通用區塊鏈,但Canto 的首要願景是成為可訪問的、透明的、去中心化和免費的DeFi 價值平台。透過賽道的長期研究發現,任何健康的DeFi 生態計畫都包含3 大基礎要素:
- 像Uniswap、Sushiswap 那樣的去中心化交易所( DEX );
- 像Compound、Aave 那樣的借貸平台;
- 像DAI、USDC 或USDT 那樣的去中心化代幣。
然而以往的DeFi 生態最後都回到了同一個宿命:發行治理協議代幣,代幣的價值取決於生態能夠從其未來用戶那裡抽取多少使用費,抽取越多則價值越大。這就好比每個DeFi 協議就像是按小時付費的私人停車場,用的人越多估值就越大。
Canto 採取了另一個想法:建造針對DeFi 的免費公共基礎設施( Free Public Infrastructure ),把自己打造成一個免費停車場,供其生態項目免費使用。
基礎設施包含3 種協議:去中心化交易所Canto DEX 、從Compound v2 分叉出來的池化借貸平台Canto Lending Market( CLM )以及可透過抵押資產從CLM 借出的穩定幣NOTE 。
Canto DEX 以無法升級、無需治理的協議永續運行,既不可發行代幣,也不會收取額外費用。避免生態內的DeFi 應用的各種尋租行為導致弱肉強食的零和遊戲。
借貸平台CLM 的治理權由質押者控制,質押者充分享受生態發展帶來的利益,反過來為開發者和DeFi 用戶創造最好的環境,激勵他們不斷投入。而貸款者藉出NOTE 所產生的利息都會支付給借款人,協議分文不取。
對開發者, Canto也引進了Contract Secured Revenue 合約所得分配模型。允許以一定比例將使用者在鏈上與合約互動時產生的費用分配給開發者。 Canto 這一系列商業模式創新做出了「一箭三雕」的效果。透過提供開放、免費的金融基礎設施創造建設性的生態繁榮基礎。
透過各種方式讓利給生態的開發者和用戶,激勵他們加入並持續豐富生態。透過將「鑄幣權」牢牢掌握在自己手裡,為各種去中心化應用創造了跨應用流動性的可能,生態越繁榮,代幣就越值錢。當美東時間2024 年1 月26 日啟用CSR 提案獲社區投票通過後,其代幣$CANTO 迎來了一波上漲。
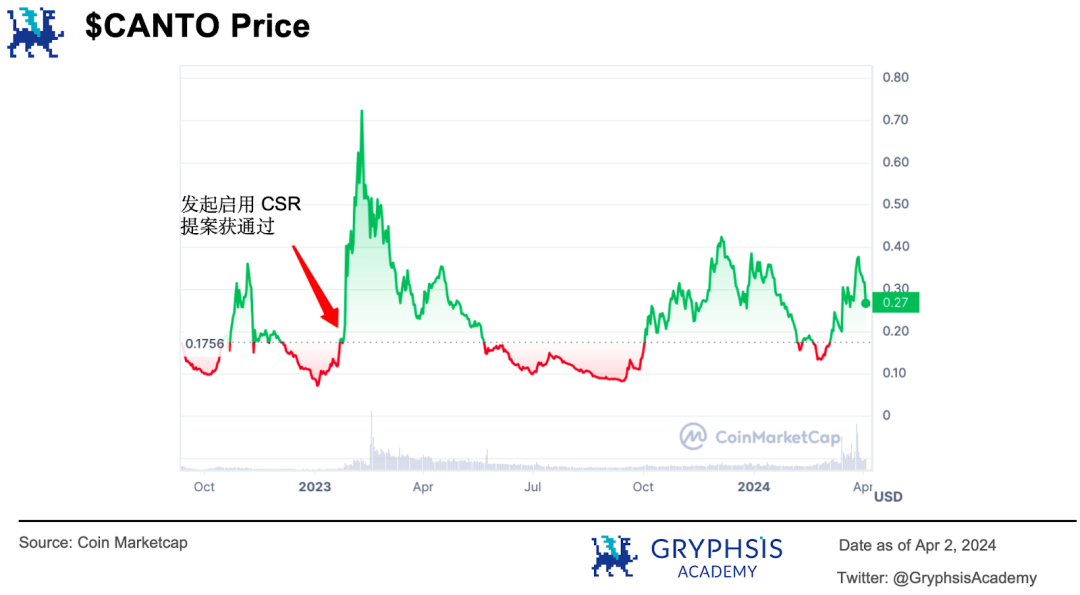
完成這一系列商業模式創新後, Canto 在2024 年3 月18 日這一天,在官方部落格公佈了自己新一輪的技術迭代計劃。
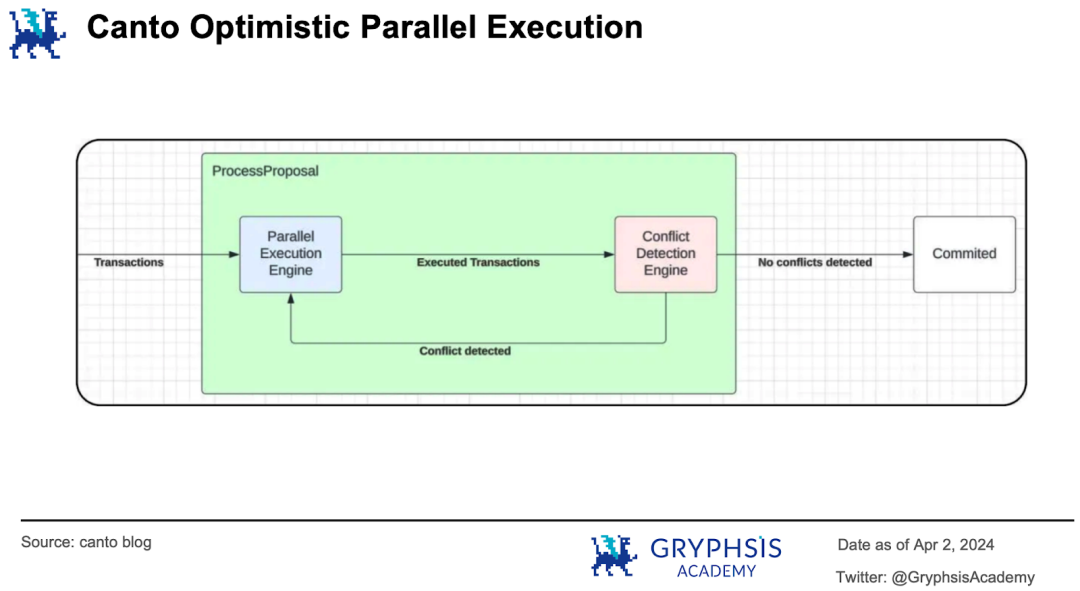
除了採用新版本Cosmos SDK 、整合新技術降低儲存存取瓶頸外Canto 還將進行並行EVM 升級:透過實現Cyclone EVM 引入樂觀並行化。
Canto 使用的Cosmos SDK 將交易處理分為Proposal、Voting 和Finalization 三個階段。 Voting 中的ProcessProposal 子程序負責交易的平行執行。並行執行引擎負責執行交易,衝突偵測引擎負責驗證交易有效性。
若無效,回退給執行引擎重新執行;若有效,提交交易給後續處理流程。相信經過此輪技術升級Canto 的代幣還會有更引人注目的表現。

Fuel 由虛擬機器FuelVM 、受Rust 啟發的合約開發語言Sway 和相關工具鏈組成,是量身定制的模組化「以太坊rollup 作業系統」。 Fuel 計畫成立於2019 年,2020 年12 月, Fuel Labs 啟動了以太坊上第一個optimistic rollup 執行層Fuel v1 ,經過3 年多的發展,計畫終於要在2024年第三季上線主網。
Fuel 分別在2021 年和2022 年完成了150 萬美元和8,000 萬美元融資。核心團隊擁有60 多名工程師,創辦人John Adler 是資料可用性解決方案Celestia Labs 的共同創辦人,也是optimistic rollup 方案最早的提出者之一。營運方面,項目在Twitter 和Discord 分別有27萬和39萬成員。
在鏈上一筆一筆執行交易要支付gas 費、要爭取寶貴的區塊空間,速度還慢。因此自然而然的就會想到各種擴容方案,例如批次交易的執行,然後再一起打包到鏈上去結算,加快執行速度。
rollup 就是一種在L1 之外運行的擴容解決方案,它在鏈下批量執行交易,然後向L1 發送交易資料或執行證明,透過DA 層保證安全性並對交易進行結算。 rollup 有兩種主要類型:基於樂觀機制( optimistic )的和基於零知識證明( ZK )的。
optimistic rollup 假設交易是有效的,一旦發現惡意或錯誤交易就產生詐欺證明交給L1 回滾處理。 ZK rollup 在不暴露交易細節的前提下透過複雜運算產生交易有效性證明,發佈到L1 ,以證明rollup 正確執行了交易。所以rollup 是一種區塊鏈執行層技術。
儘管rollup 加快了交易的執行速度,但現有的實作大多是針對單體區塊鏈設計的。開發人員不得不在技術上做出各種各樣的妥協,這限制了rollup 充分發揮其性能。而針對模組化區塊鏈的新趨勢,業界又沒有適配的rollup 方案。 Fuel 就是為填補這一空白而誕生的。
Fuel 使用UTXO 作為資料模型,採用此資料模型有一個優點:其交易輸出只有兩種狀態,要麼已花費,永久記錄於區塊的交易歷史中;要麼未花費,可用於未來的交易中。進而做到鏈上每個節點儲存狀態資料最小化。在此基礎上, Fuel 檢查每一筆交易訪問的帳戶信息,在執行交易之前找出依賴關係,調度無依賴關係的交易並行執行,提高交易處理的吞吐量。

L2 解決方案有共通性:它們將兩種虛擬機器的能力結合起來,提升交易的執行速度。具體地說就是利用並行L1 來執行交易,但與其他鏈進行相容(雙虛擬機支援)。不同的是不同的項目所採取的相容機制不一樣。這方面Neon 、 Eclipse 和Lumio 頗具代表性。
Neon 稱Solana 生態第一個並行EVM 項目,開發者可以利用它無縫地將以太坊生態項目遷移到Solana 生態。 Eclipse 是另一個Solana 生態中與EVM 相容的最快二層協議,採用模組化架構建構。這三個項目中只有Neon 發行了自己的代幣,並做到了7,800 多萬的流通市值。
其他兩個項目還處於比較早期的階段。 Lumio 則結合了Aptos 和以太坊建構了optimistic rollup 二層協議,以Move VM 的速度高效執行以太坊應用。
從融資情況來看, Neon 分別在2021 年11 月和2023 年6 月完成4,000 萬美元和500 萬美元融資,共4,500 萬美元。 Eclipse 分別於2022 年8 月、2022 年9 月及2024 年3 月完成600 萬美元、900 萬美元及5,000 萬美元融資,共6,500 萬美元。 Lumio 暫未融資。
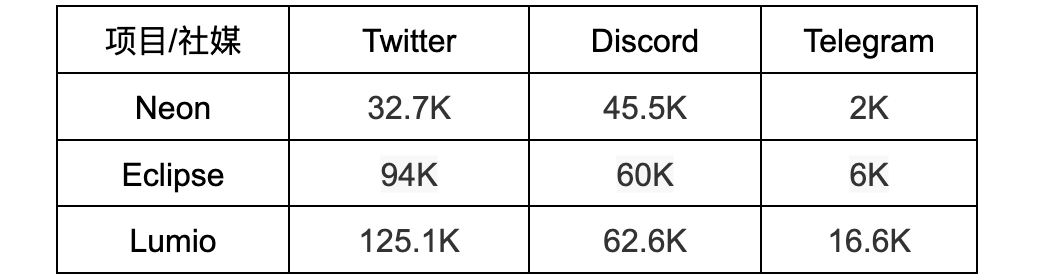
三個項目均未形成規模性的應用生態,但在各主要社群媒體平台都有數萬到數十萬不等的追蹤者或會員,有不小的社群活躍度,如下表所示。
從實作機制來看, Neon 是Solana 網路上的EVM 模擬器,以智慧合約的形式運作。開發人員可以使用諸如Solidity 、 Vyper 這樣的語言編寫dApp 應用,並可以使用MetaMask 、 Hardhat 、 Remix 等以太坊工具鍊和相容的以太坊RPC API 、帳戶、簽名和代幣標準等。同時享受Solana 帶來的低費率、高交易執行速度以及並行執行的能力。
以太坊dApp 前端發出的以太坊交易經過代理轉換產生Solana 交易,然後在模擬器中執行,修改鏈上狀態。好比我們常在PC 上使用的遊戲模擬器,能讓我們在桌上型電腦上玩Switch、PS 等遊戲平台上的獨佔遊戲, Neon 能讓以太坊開發人員在Solana 網路上運行以太坊應用。
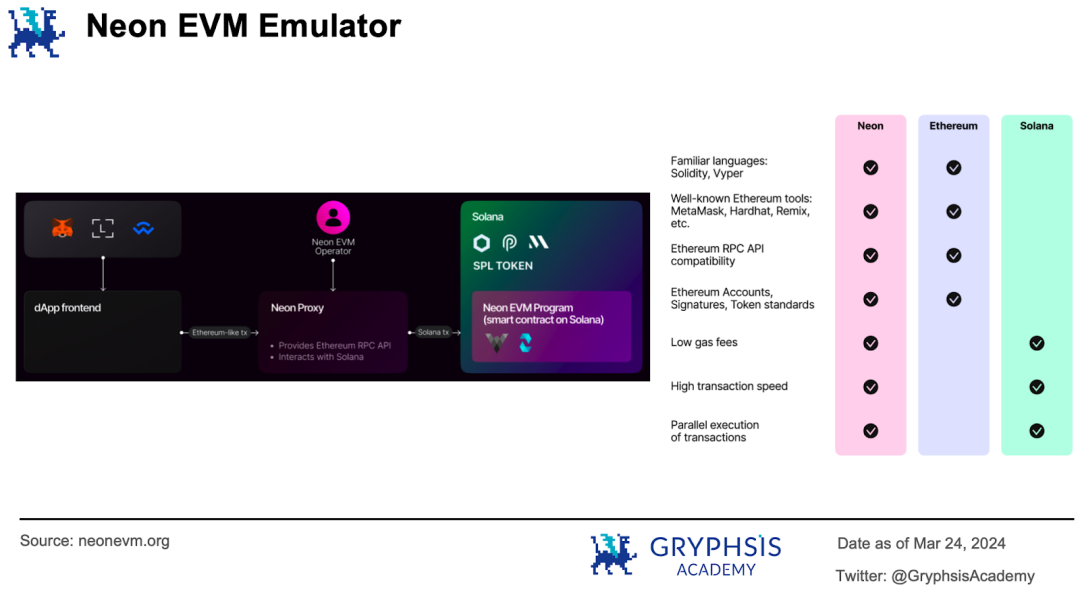
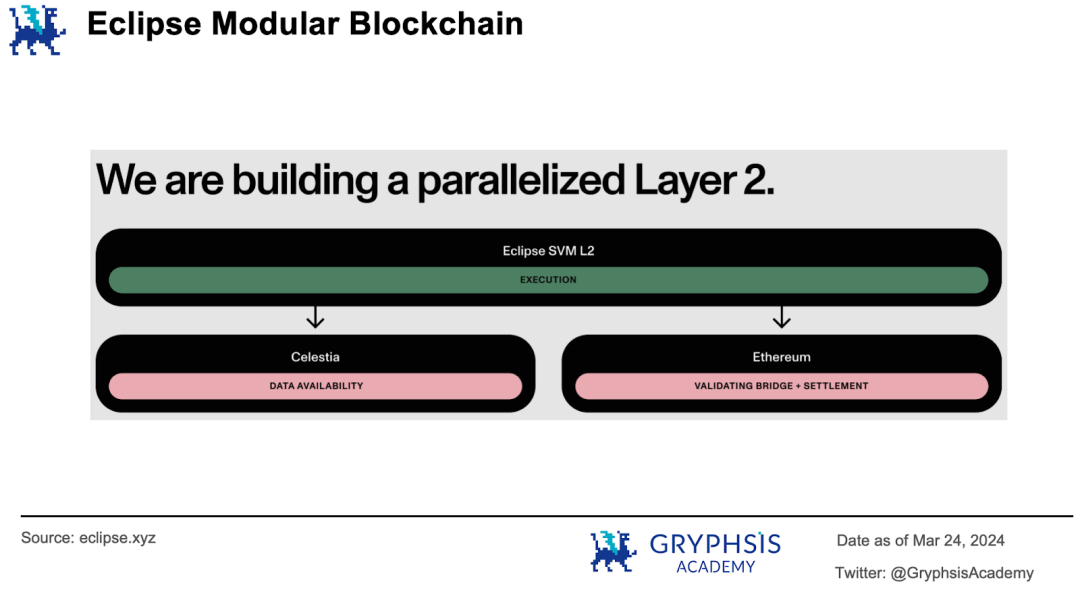
Eclipse 採取了另一個實作想法:透過SVM 執行交易,透過EVM 結算交易。 Eclipse 採取模組化區塊鏈的架構,即它只負責交易的執行,而把其他的職責「外包」出去,透過模組化組合形成統一解決方案。
例如利用Celestia 管理資料可用性,利用以太坊執行交易的結算。 Eclipse 利用SVM 保證了執行速度,透過以太坊的驗證和結算保證了安全性。
Lumio 採用的是一種與執行層和結算層無關的設計思路,可支援多種虛擬機,相容於各種L1/L2 網路:Ethereum、Aptos、Optimism、Avalanche、zkSync ,諸如此類。它透過Move VM 執行交易,透過EVM 結算交易,這樣一來就把以太坊生態和Aptos 生態連結起來了。
然而Lumio 的雄心壯志並不止步於此,它的願景是提供跨虛擬機調用,以最快的速度和最低的費率實現多種區塊鏈流動性的互聯。
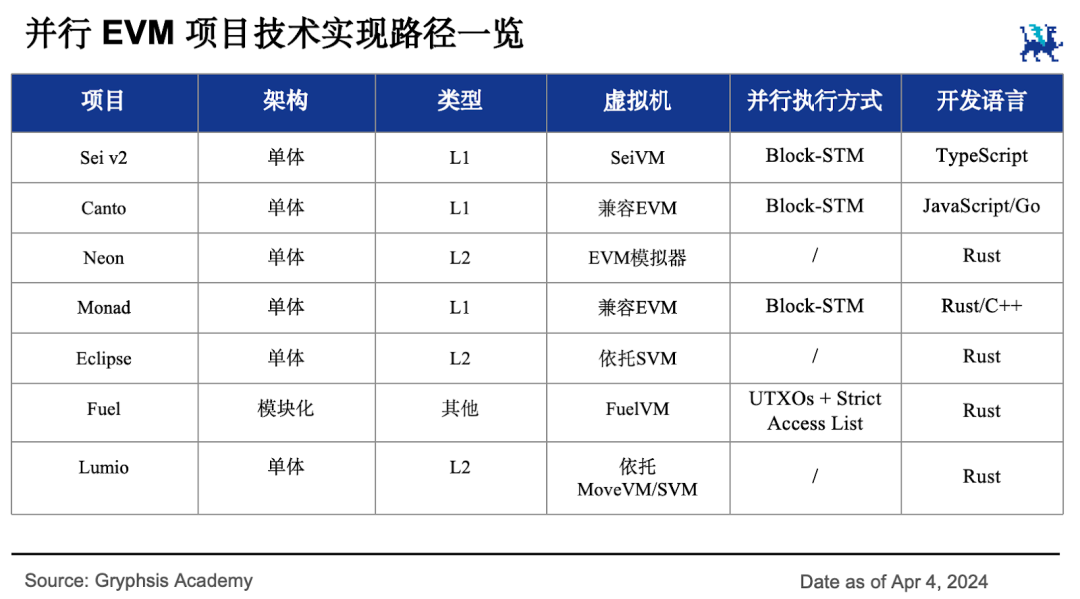
以上就是目前與平行EVM 敘事有關的主要項目,如下圖所示。

人們愛把比特幣比喻為“分散式帳本”,把以太坊比喻為“分散式狀態機”。如果把運行區塊鏈網路的所有節點看作是一台電腦的話,那麼並行區塊鏈本質上就是研究如何榨乾這台「電腦」的處理器資源,以實現執行速度的最大化。
這是運算技術不斷發展的歷史必然性,就像處理器從單核心發展到多核心,作業系統從單一使用者單執行緒發展到多用戶多執行緒一樣。這對於推動產業的不斷發展有著非凡的意義。
並行EVM 的技術原理可以拆解為虛擬機器和平行執行機制兩個組成部分。在區塊鏈的脈絡下,虛擬機器整合了一套指令集,用於分散式執行合約,並運行dApp。而平行執行機制則主要研究如何最大限度的提高交易執行的速度,同時確保交易結果的正確。
一方面,並行EVM 有技術原理上的共通性。首先,樂觀並行化模式是L1 公鏈的共識。但這不代表記憶體鎖模型就一無是處。因為技術沒有高下之分,只有開發人員有水平好壞之別。
其次,以Fuel 為代表的專案堅信鏈下擴容機制只有模組化後才能發揮最大效能。最後,一眾L2 計畫則透過整合並行L1 公鏈來提高交易吞吐量,實現跨生態擴容能力。
另一方面,並行區塊鏈有自己獨特的技術建樹。即使採用的是同一種平行執行模型,不同的團隊也採用了不同的架構設計模式、資料模型或預處理機制。技術的探索是無止境的,不同的項目會根據不同的願景,在同一個基礎上發展出不同的技術來推動實踐不斷向更高層次發展。
展望未來,還會有更多的L1 和L2 項目,加入並行EVM 的競爭。 L1 賽道會形成平行EVM 和並行非EVM 兩大陣營在處理器資源、儲存資源、網路資源、檔案系統資源和設備資源全面競爭的格局,還會誕生更多與效能提升有關的新敘事。而L2 賽道會朝著區塊鏈虛擬機器模擬器或模組化區塊鏈的方向發展。
在未來,基礎設施的最佳化會帶來更快的速度、更低的費用以及更高的效率。 Web3 創業家可以大膽的進行商業模式創新,為全世界創造更好的去中心化產品使用者體驗,進一步繁榮產業生態。對Web3 投資人而言,僅僅關注科技那是遠遠不夠的。
在選擇投資標的時候,投資人不但要看敘事,還要看市值和流動性,要選擇「好敘事」、「低市值」和「高流動性」的項目,然後研究其業務、團隊背景、經濟模型、行銷、生態項目等各方面,從而發現潛力項目,找到適合的投資途徑。
並行EVM 處在發展的早期階段, Neon、Monad、Canto、Eclipse、Fuel 和Lumio 仍處於價值未充分發現的階段。尤其是Monad 、Canto 和Fuel 。
從Monad 的行銷風格來看,不但其本身值得關注,而且未來其生態中的meme 項目也很值得留意,可能會有因炒作熱度產生的暴富神話。而Canto 已滿足「好敘事」和「低市值」的條件,是否是一個好的投資標的還需要對其各項指標進行深入研究。 Fuel 代表著模組化區塊鏈的熱門發展方向,也可能誕生新的投資機會,這些都是值得我們關注的方向。
參考資料
[1]https://www.theblockbeats.info/news/49248
[2]https://www.binance.com/en/research/analysis/technical-deep-dive-parallel-execution
[3]https://en.wikipedia.org/wiki/Virtual_machine
[4]https://medium.com/@yunwei356/userspace-ebpf-runtimes-overview-and-applications-d19e3c84c7a7
[5]https://news.marsbit.co/20240119153041358158.html
[6]https://medium.com/@NervosCN/%E5%8C%BA%E5%9D%97%E9%93%BE%E4%B8%8D%E5%8F%AF%E8%83%BD %E4%B8%89%E8%A7%92-%E7%BB%88%E6%9E%81%E6%8C%87%E5%8D%97-85c069f21adc
[7]https://news.marsbit.co/20240112161732277166.html
[8]https://blog.ambire.com/blockchain-layers-differences-explained/
[9]https://medium.com/solana-labs/sealevel-parallel-processing-thousands-of-smart-contracts-d814b378192
[10]https://aptosfoundation.org/whitepaper/aptos-whitepaper_en.pdf
[11]https://blog.sui.io/parallelization-explained/
[12]https://blog.sei.io/sei-v2-the-first-parallelized-evm/
[13]https://docs.monad.xyz/technical-discussion/execution/parallel-execution
[14]https://canto.mirror.xyz/5q8V3Z9CHjM7fjgUTE0hMYcD-UuVemPybo0QWaNzzzE
[15]https://docs.neonevm.org/docs/about/why_neon
[16]https://www.eclipse.xyz/
[17]https://docs.lumio.io/xlumio-virtual-machines#execution
[18]https://fuel.mirror.xyz/uYMT39LiB538Q61Mgf4bRrsAwApJSeNiG_afDHhOhGs
[19]https://fuel.network/


 APP
APP 

