
原題:50個の弱いシグナルを組み合わせて1つの勝ちトレードにするための数学的原理
原著者:ロアン(暗号通貨アナリスト)
翻訳と注釈:RyanChi氏、insiders.bot
序文
昨年、トランプ氏とマスク氏の母校であるウォートン校に交換留学生として滞在した最初の週に、私は@DakshBigShitと共に@insidersdotbotを共同設立しました。ウォートン校の素晴らしい環境とニューヨークに近い立地のおかげで、わずか4ヶ月の間に、数億ドル規模の資産を運用する複数のヘッジファンドのパートナーと深い議論を交わすことができました。
その後、私が香港に戻って起業した頃には、すでにinsiders.botが台頭し始めており、アジアの定量分析機関と深く意見交換をする機会を得ることができました。
この過程を通して、私が繰り返し耳にした言葉の一つが「シグナル」だった。
エントリーシグナル、エグジットシグナルなど。このプロセスにおいて、個人投資家と機関投資家の最大の違いは、情報量や資金力ではなく、考え方にある。個人投資家は常に完璧な、たった一つのシグナルを探し求めるのに対し、機関投資家は数学的なエンジンを用いて、数多くの平凡なシグナルをまとまりのある全体像へと変換するのだ。
Binance、OKX、Bitgetなどの取引プラットフォームのウォレットは、以前から様々なシグナル配信コンテンツを組み込んでいる。
insiders.botの黎明期から、私たちは「シグナルボット」として注目を集めていました。当時最も人気だったv1.2シグナルは、複数のスマートマネーシグナルを集約したもので、多くのブロックチェーンリーダーから高い評価を得ました。予測市場のトレーダーに人気のブロードキャストシステム@poly_beatsも、本質的にはシグナルです。
RohOnChain氏の記事は、私がこれまで読んだ中で最も分かりやすい「シグナル」フレームワークの説明です。定量的な知識がなくても最初から最後まで理解できるように、時間をかけて書き直し、補足説明を加え、注釈を付けました。
パート1:存在しない「完璧な信号」
20年間システマティックトレーディングの分野で働いてきたファンドパートナーと話していたとき、ある一文を耳にし、それが数ヶ月間私の思考を巡らせた。
その日、彼は私の向かいに座り、私たちが話し合っていた戦略を見ながら、静かにこう言った。
「常に正しいシグナルを探し求めているが、そんなものは存在しない。実際に成功するトレーディングデスクは、多くの『やや正確な』シグナルを正しく組み合わせることができるチームなのだ。」
彼が説明した内容は、定量取引業界では「ジャーゴン」と呼ばれる非常に抽象的な専門用語で表現される。
アルファ組み合わせ。
この枠組みは画期的な出来事だ。それは、継続的に利益を上げられる機関投資家と、「方向性を正しく予測していても損失を出してしまう」個人投資家を明確に区別するものだ。
この記事を読めば、以下の5つのことが理解できるでしょう。
1. なぜ50個の弱い信号の組み合わせが、1つの強い信号を完全に圧倒できるのでしょうか?
2. 「プロアクティブマネジメントの基本法則」とは何ですか?
3. 機関投資家が多数の悪いシグナルを高い勝率の戦略に変えるために用いる11のステップとは具体的にどのようなものですか?
4. 方向を正しく予測したにもかかわらず、なぜ損失を出してしまうのですか?
5. このシステムをPolymarketに完璧に適用するにはどうすればよいでしょうか?
真に独自のトレーディング優位性を築きたいのであれば、どの章も飛ばさずに読み進めてください。このフレームワークは、5つの要素すべてを総合的に考慮して初めて、その真の力を発揮します。
ちなみに、この記事はAIエージェント向けに構造的に最適化されています。Claude、Manus、またはその他のAIに自由に読み込ませて、すぐに独自の量子化モデルの構築を開始してください。
1.1 「信号」とは一体何でしょうか?
数学的な議論に入る前に、まず共通の用語を確立する必要があります。「信号」とは一体何でしょうか?
日常生活では、「このコインは値上がりすると思う」とか「トランプ氏の当選に期待している」といったことをよく口にします。これらは意見です。意見は曖昧で主観的であり、正確なバックテストを行うことはできません。
しかし、制度の定量的枠組みにおいては、シグナルとは、将来の価格や確率の変化と統計的に再現可能な関係を持つ、測定可能なデータポイントのことである。
以下の3つの条件を満たさなければならない。
定量化可能であること:具体的な数値でなければなりません。例えば、「最近、それについて話す人が増えている」ではなく、「過去24時間で取引量が3倍に増加した」のように記述する必要があります。
方向性を示さなければならない。つまり、価格が次に上昇するか下落するか、あるいはその確率が増加するか減少するかを判断できなければならない。
再現性:単発的な出来事であってはならず、歴史上複数回発生し、その都度市場が同様の反応を示す必要がある。
例えば、バイナンスで勝率の高い大口プレイヤーが複数連続して購入した場合、その購入額は重要なシグナルとなる。
例えば、当社の@insidersdotbot v1.2 Skew(スマートマネーの強気/弱気比率)もシグナルの一つです。
例えば、Polymarketでは、過去の勝率が70%を超えるスマートマネーウォレットが、あまり人気のない契約に突然5万ドルを賭けた場合、これは典型的な「ミクロ構造シグナル」です。これは、具体的(5万ドル)、方向性(購入したオプション)、そして再現性(過去のすべての賭け記録をバックテストできる)を備えています。
信号とは何かを理解したところで、次の質問を見ていきましょう。あなたの信号の精度はどの程度ですか?
1.2 ICとは何か? 信号の「成績表」
トレード経験のある人なら誰でも、こんな瞬間を経験したことがあるでしょう。自分の分析は明らかに正しく、価格も予想通りに動いたのに、結局損をしてしまう。
これは運任せの問題ではありません。取引において単一のシグナルに頼ると、損失を出すことはほぼ数学的に避けられません。その理由を理解することが、以降のすべての基礎となります。
定量的研究では、すべての信号には精度を測定するための指標があり、情報係数(IC)と呼ばれます。
ICは、あなたの予測と実際の市場の動きとの相関関係を測定する指標です。いわば、あなたのシグナルに対する「成績表」のようなものです。
では、ICは具体的にどのように計算されるのでしょうか?手順を一つずつ見ていきましょう。
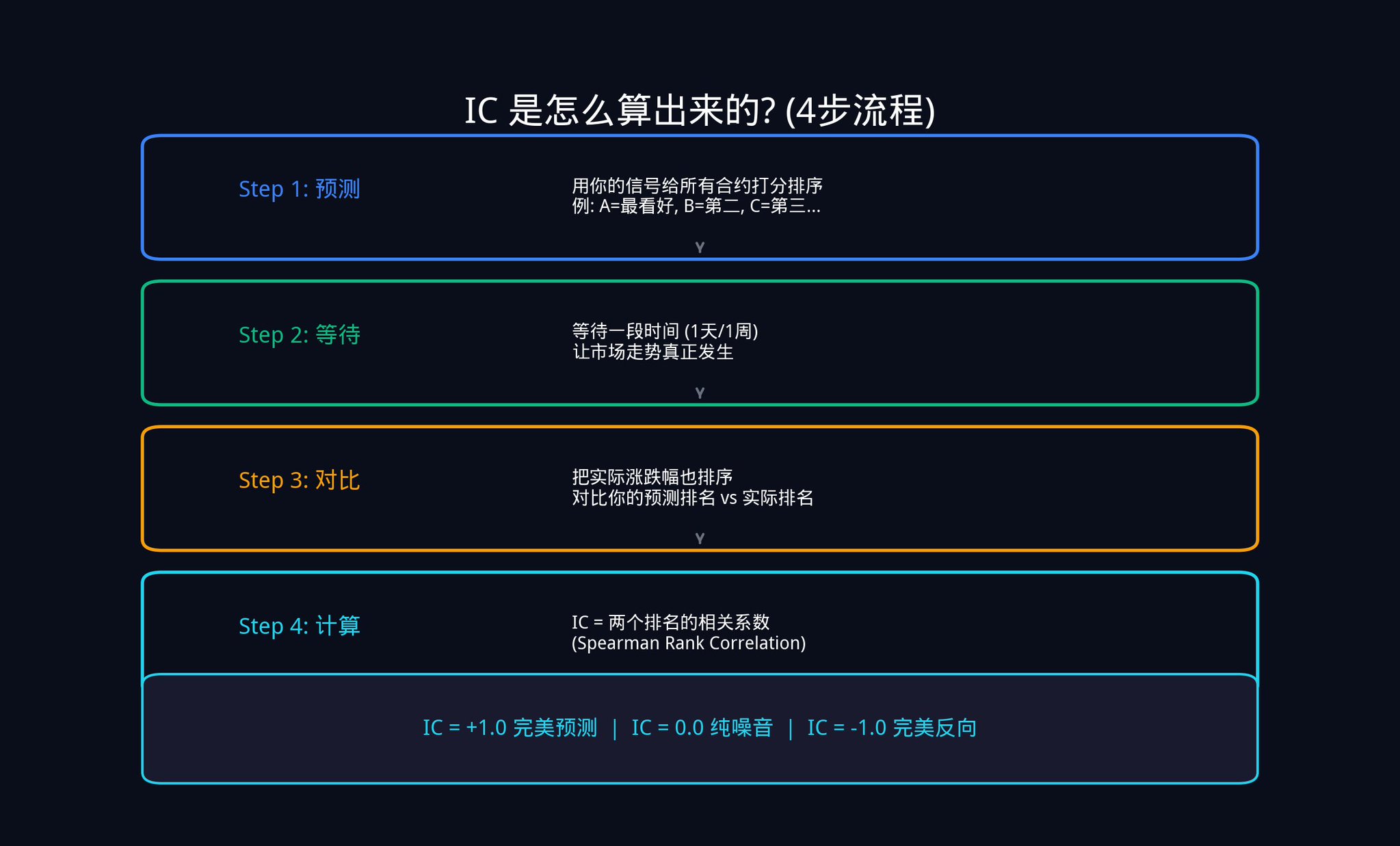
最初のステップは予測です。例えば、今日Polymarketで20件のアクティブな契約があるとします。シグナルを使って、これらの20件の契約にスコアを付け、順位付けします。契約Aが最も値上がりする可能性が高いと判断し、1位にランク付けします。契約Bは2位、といった具合に、20位まで順位付けしていきます。
2つ目のステップは待つことです。 1日、1週間、あるいは自分で設定した任意の期間待って、市場の動きを見守りましょう。
3つ目のステップは比較です。制限時間が経過したら、これら20の契約の実際の価格変動を順位付けします。最も上昇幅の大きいものを1位、2番目に上昇幅の大きいものを2位、といった具合に順位付けしてください。
4番目のステップは計算です。これで、ランキングの2つの列が得られました。1つは最初に予測したランキング、もう1つは実際のランキングです。この2つのランキング列間の相関を計算する必要があります。
ここで使用されているスピアマン順位相関係数は、統計学の用語です。
恐ろしく聞こえるかもしれないが、その論理は実はとても単純だ。
• もしあなたが1位になると予測した契約が実際に最も値上がりし、2位になると予測した契約が実際に最も値上がりした場合、あなたの2つのランキングは非常に一致しており、あなたのICは+1.0に近くなります。
• もし正反対のことが真実である場合(最も上昇したとあなたが言うものが実際には最も下落したと言う場合)、ICは-1.0に近い値になります。
• 関係がない場合、ICは0.0となり、信号はサイコロを振るのと何ら変わりません。
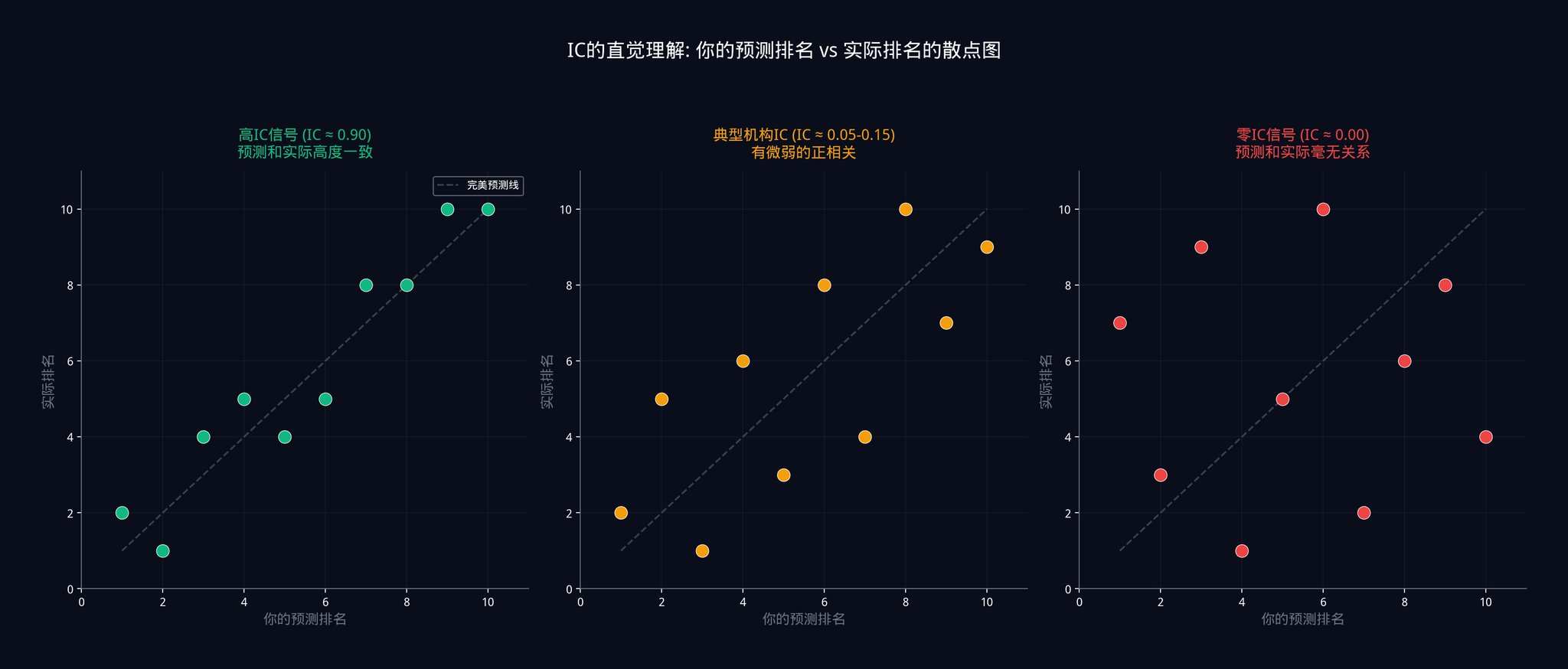
上記のグラフは、3つの異なるICレベルにおける予測順位と実際の順位の関係を示しています。
左側はICが0.9に近い場合で、点がほぼすべて対角線上に並んでおり、予測された高さが実際の高さと一致していることを示しています。
中央部分は、IC値が0.05から0.15の間であることを示しており、点が至る所に散らばっていることから、非常に弱い正の相関傾向しか示していないことがわかる。
右側はICが0の場合を示しており、これは完全にランダムで、何のパターンもありません。
数値ではなくランキングを用いる理由とは?
これは、ランキングが外れ値の影響を受けにくいからです。例えば、ブラックスワン現象によって契約価格が500%急騰したとします。数値計算で相関係数を算出すると、この単一の外れ値が結果全体を歪めてしまいます。しかし、ランキングを用いる場合は、単に「1位」と評価されるだけで、他の契約のランキングには影響しません。これが、金融機関がピアソン相関係数よりもスピアマン相関係数を好む理由です。
実際には、1日分のICだけを計算するわけではありません。このプロセスを複数日(例えば100日間)繰り返し、その平均値を求めます。この平均値が、信号の平均ICとなります。
さて、ウォール街のトップトレーディングデスクで、何十億ドルもの資金が動くシグナルが送られている場所に搭載されているIC(集積回路)は何だと思いますか?
答えは、0.05から0.15の間です。
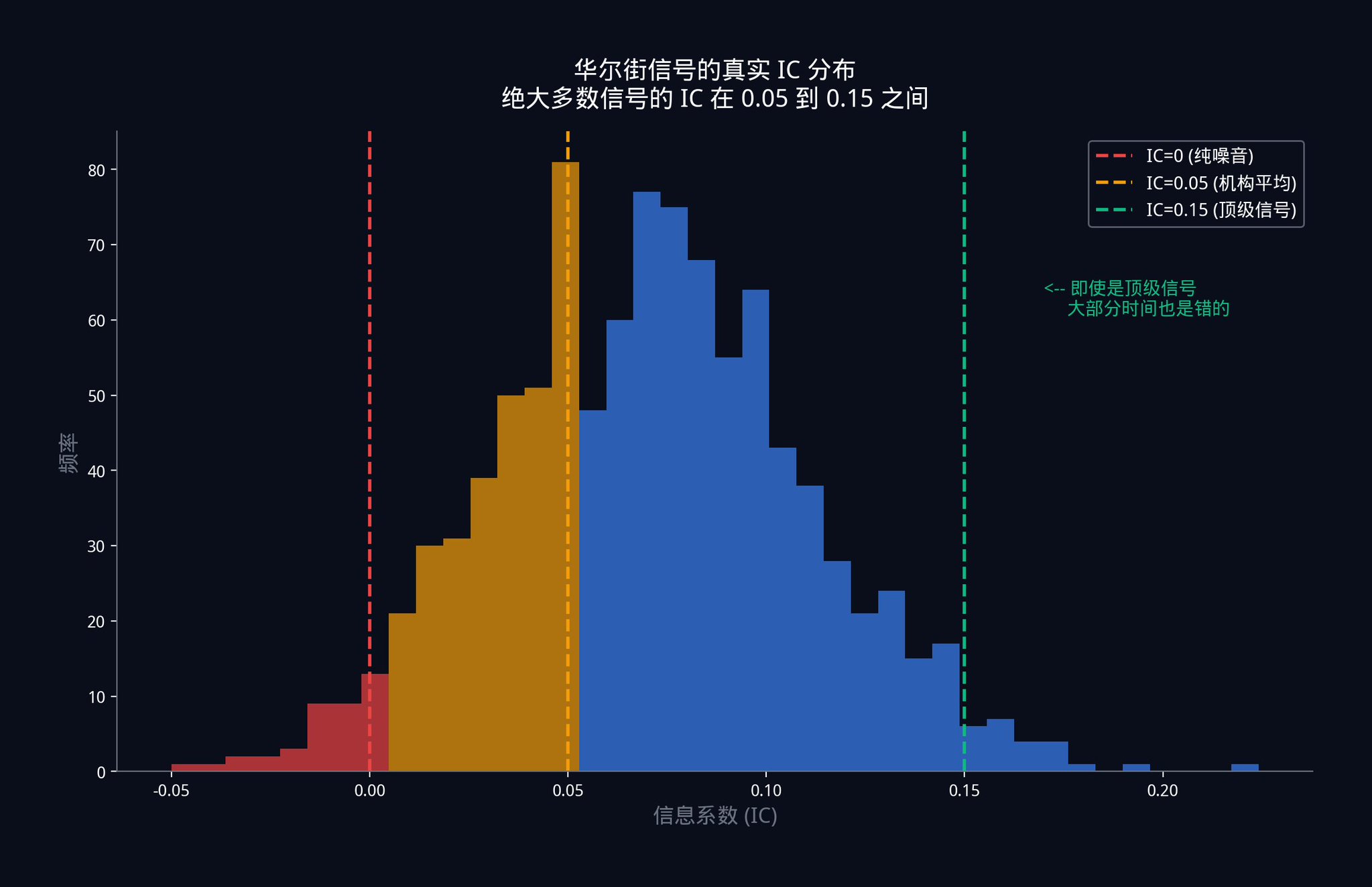
この数字をもう一度よく見てください。組織レベルで使用されている最上位の単一の指標は、ほとんどの場合間違っています。たまにではなく、ほとんどの場合です。
IC = 0.05とはどういう意味ですか?
これは、あなたのシグナルと実際の市場の動きとの相関関係がわずか5%しかないことを意味します。散布図を描くと、点はほぼランダムに分布し、ごくわずかな上昇傾向しか示さないでしょう。
これはシグナルエラーではありません。競争市場の本質的な性質です。何らかの大きな優位性が発見されると、その優位性が枯渇し、極めて低い水準にまで圧縮されるまで、資本が大量に流入します。効率的な市場において、 IC(投資コスト)を0.05に安定的に維持することは、すでに驚くべき成果と言えるでしょう。
個々のシグナルが非常に弱いことを考えると、機関は一体どのようにして利益を上げているのだろうか?
1.3 組織の切り札:プロアクティブマネジメントの基本法則
1994年、定量分析の先駆者であるリチャード・グリノルドとロナルド・カーンは、著書『アクティブ・ポートフォリオ・マネジメント』の中で、資産運用業界全体に革命をもたらす公式を提唱した。
IR = IC × √N
この公式は、アクティブマネジメントの基本法則として知られています。

では、この3文字は何を表しているのでしょうか?
情報比率(IR)は、トレーディングシステムの総合的なパフォーマンスを示す指標です。これは、リスク1単位あたりにどれだけの利益が得られるかを測定するもので、いわば「費用対効果」の指標と言えます。IRが高いほど、戦略の安定性が高まります。定量トレーディングの世界では、IRが1.0は最高レベルとされています。
IC(情報係数)とは、このセクション全体で説明してきたもので、個々の信号の平均的な精度を表します。
Nは、組み合わせる独立信号の数です。ここで「独立」という言葉が非常に重要です。その理由については、第4部で詳しく説明します。
さて、この公式の核心となる情報は、システム全体のパフォーマンス(IR)は、単一信号の精度(IC)に信号数の平方根(√N)を掛けたものに等しいということです。
そこで疑問が生じます。なぜ平方根を使うのでしょうか?単にNを掛ければいいのではないでしょうか?これは非常に重要な疑問なので、最初から導出過程を順を追って説明しましょう。
コインを投げる場面を想像してみてください。表が出れば1ドル勝ち、裏が出れば1ドル負けます。
コインを1回だけ投げた場合、結果は完全にランダムです。1ドル勝つか、1ドル負けるかのどちらかです。
しかし、コインを100回投げたらどうなるでしょうか?期待される総収益は0です(表が50回、裏が50回あるため)。しかし、重要なのはボラティリティです。統計によると、100回の独立したコイン投げの総ボラティリティは100ではなく、√100 = 10です。
なぜでしょうか?それは、独立したランダムな事象が重なり合うと、それらのノイズが互いに打ち消し合うからです。肯定的な結果と否定的な結果が交互に現れ、すべてが同じ方向に動くわけではありません。そのため、全体の変動は発生回数の増加よりも緩やかに増加します。
それでは、この論理を信号の組み合わせに適用してみましょう。N個の独立した信号があり、それぞれが小さな正の優位性(ICが0より大きい)を持っているとします。
総利得(すべての信号の利点の合計)は、Nに比例して直線的に増加します。これは、信号が1つ増えるごとに、わずかな利点が加わるためです。10個の信号による総利得は、1個の信号による総利得の10倍になります。
しかし、総リスク(すべての信号から発生するノイズの合計)は√Nに比例して増加します。これは、個々のノイズが互いに打ち消し合うためです。10個の独立した信号の総ノイズは、単一の信号のノイズの10倍ではなく、約3.16倍(√10 ≈ 3.16)になります。
したがって、情報比率 = 総収益 / 総リスク = (IC x N) / (σ x √N) = IC x (N / √N) = IC x √N となります。
これがIR = IC x √Nの起源です。
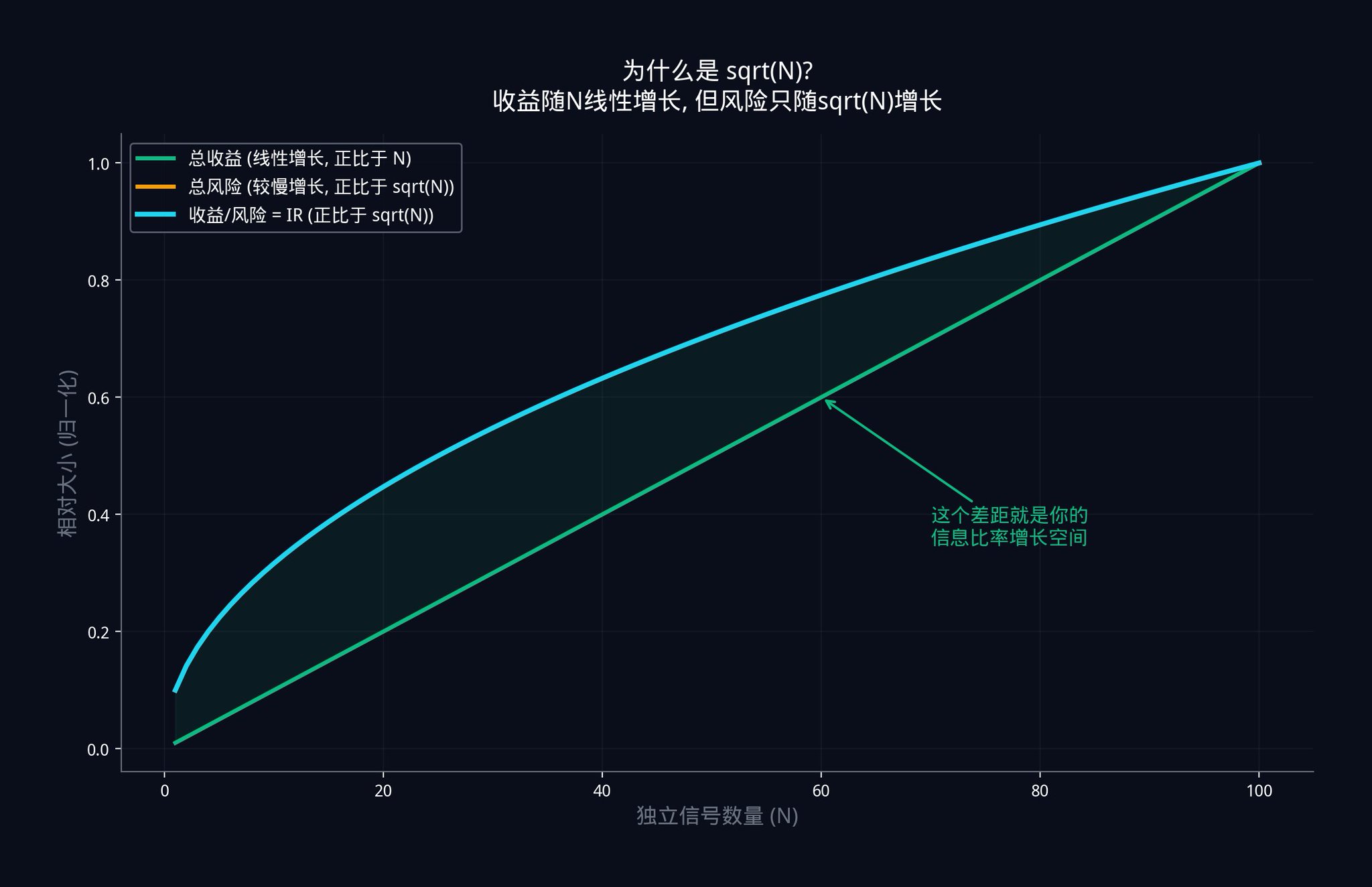
上のグラフはこの関係性を示しています。緑色の線は総収益を表し、シグナルの数に比例して直線的に増加します。青色の線は情報比率(IR)を表し、√Nに比例して増加します。収益もリスクも増加しますが、収益の増加率はリスクの増加率よりも高くなります。2つの線の間の差は拡大します。この差は、独立したシグナルの数を増やすことで得られる取引上の優位性を表しています。
この公式の威力を実感するために、具体的な計算をいくつかしてみましょう。
シナリオA: 50個の弱い信号があります。各信号は非常に弱く、ICはわずか0.05です。したがって、結合システムのIRは0.05 x √50 = 0.05 x 7.07 = 0.354となります。
シナリオB:別のトレーダーは強力なシグナルを1つ持っています。彼は熱心に探し、最終的にICが0.10(あなたのシグナルの2倍の精度)の非常に強力な単一シグナルを見つけました。しかし、彼はシグナルを1つしか持っていないため、IRは0.10 x √1 = 0.10となります。
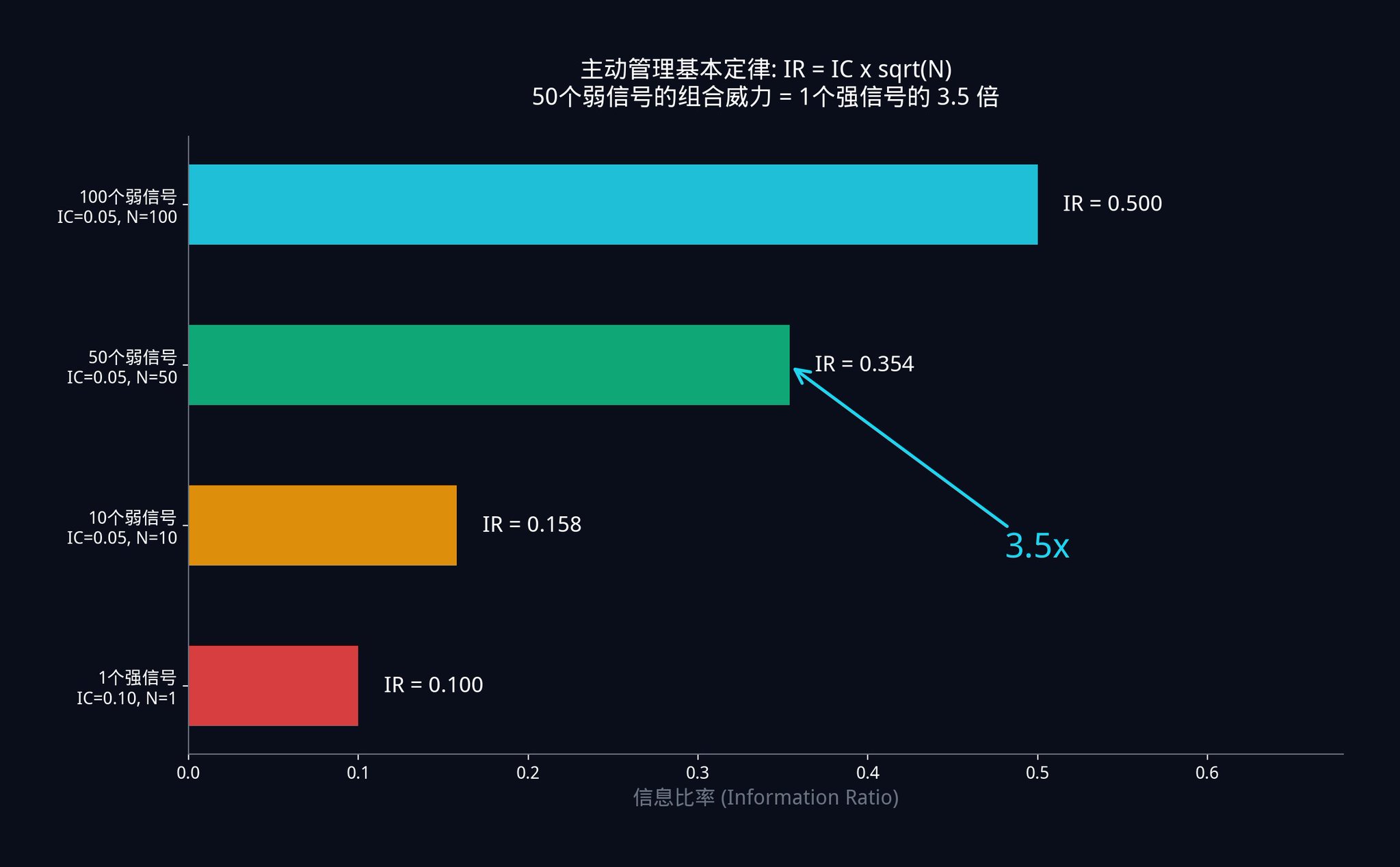
あなたが50個の「ジャンク信号」を使って作成したシステムは、彼のシステムの半分の精度しかなかったにもかかわらず、彼の「神レベルの信号」よりも3.5倍優れていました。
だからこそ、ヘッジファンドは、たった一つの「完璧な指標」にすべてを賭けるよりも、何百人もの研究者を雇って何百もの微弱なシグナルを探し出すことを好むのだ。数学は、完璧なシグナルを探し求めることは行き止まりであることを証明している。
正しいアプローチは、できるだけ多くの独立した微弱な信号を収集し、それらを数学的に組み合わせることである。
このアイデアこそが、当社のinsiders.botウォレットフィルターの根幹を成すものです。ユーザーに「完璧なスマートマネーウォレット」を探させるのではなく、さまざまな戦略と特徴を持つ、勝率の高い数百ものウォレットを追跡できるように支援します。これらの微弱なシグナルを集約することで、真に正確な結論を導き出すことができるのです。
上級演習1:
正直に言って、あなたが今最も頼りにしている取引シグナルを評価してみてください。そのIC(金利)はどれくらいですか?もしこれまで体系的に測定したことがないなら、あなたは手探りで取引していたことになります。
ぜひご自身で試してみて、Pythonで簡単なバックテストスクリプトを作成してください。過去30日間の予測順位と実際の順位を記録し、`scipy.stats.spearmanr()`関数を使ってICを計算してみましょう。結果に驚くかもしれません。
確率論のしっかりとした基礎を築きたいなら、ハーバード大学が無料で提供している「確率論入門」をお勧めします。最初の6章だけで十分です。
信号を組み合わせる必要がある理由を理解したところで、次のステップは、これらの信号をどこで見つけるかを突き止めることです。
パート2:5つの主要シグナルの原材料
パート1では、信号とは何か(定量化可能で、方向性があり、再現可能なデータポイント)を定義しました。
しかし、信号はそれほど強力である必要はありません。多数の観測において、コイン投げよりもわずかに高い精度を発揮すれば十分であり、この「わずかな精度」は安定していて検証可能でなければなりません。
では、これらの「やや精度の高い」データは、一体どこで見つけられるのでしょうか?
以下は、システマティックトレーディングプラットフォームが実際に使用している5つの主要なシグナルカテゴリです。

2.1 価格とモメンタムのシグナル
モメンタムシグナルは、一定期間における価格の動き方と動きの速さを示します。
モメンタムシグナルが効果的なのはなぜか?それは、市場参加者が新しい情報に対して慣性的に反応するからである。
・短期的には、人々の反応が十分速くないため、この傾向は継続するだろう。
中期的に見ると、人々は過剰反応する傾向があり、それが価格調整につながる。
加速する列車を想像してみてください。運転手がアクセルペダルから足を離しても、列車はすぐには止まりません。慣性によって、列車は一定の距離を前進し続けます。運動量信号はこの「慣性距離」を捉えるものです。
Polymarketではどのように使えばいいですか?
ある契約の価格が過去3日間で0.40ドルから0.55ドルへと着実に上昇し、取引量もそれに伴って増加したとします。これは、価格を押し上げている持続的な買い圧力を示しています。
短期的には価格が上昇し続ける可能性は比較的高い。これはあなたが何か特別な情報を持っているからではなく、市場の勢いがまだ完全には衰えていないからだ。
定量分析において、最も基本的なモメンタムの公式は、過去 d 日間の平均リターンを計算することです。E(i) = (1/d) x Σ R(i,s)。d は振り返る日数、R(i,s) は契約 i の s 日目のリターンです。
2.2 平均回帰信号
平均回帰シグナルは、資産がその「公正価値」からどれだけ乖離しているかを測定する指標です。
その根幹となる論理は、関連資産間の価格比率は安定しているべきだという点にある。この関係が崩れると、回帰の力がそれを元に戻そうとする。
Polymarketの例を見てみましょう。「トランプ氏が選挙に勝つ」と「共和党が選挙に勝つ」という2つの契約があるとします。通常、これらの確率は高い相関関係にあるはずです(トランプ氏は共和党の候補者であるため)。ある日、「トランプ氏が勝つ」確率が10パーセントポイント低下したのに、「共和党が勝つ」確率はわずか2パーセントポイントしか低下しなかった場合、これは平均回帰の強い兆候です。市場の価格設定は間違っており、遅かれ早かれ両者は再び一致するでしょう。
平均回帰信号はゴムバンドのようなものです。伸ばせば伸ばすほど、反発力は強くなります。しかし、ゴムバンドは切れることもあるので注意が必要です。したがって、平均回帰信号は単独で使用するのではなく、他の信号と組み合わせて使用する必要があります。
2.3 ボラティリティシグナル
ボラティリティシグナルは、インプライドボラティリティ(市場の予想ボラティリティ)と実現ボラティリティ(実際に発生するボラティリティ)の差に着目する。
なぜこのような乖離が生じるのか?それは、ボラティリティを売る者(オプション売り手など)は、大きなテールリスクを負うからである。彼らは、そうした極端なケースをカバーするために、追加の報酬を必要とする。これは、保険会社が常に実際の支払額よりも高い保険料を設定するのと似ている。
Polymarketでは、ボラティリティシグナルは次のように理解できます。契約価格が0.45ドルから0.55ドルの間で激しく変動しているにもかかわらず、ファンダメンタルズに大きな変化(新たなニュースや政策変更など)がない場合、この「偽のボラティリティ」自体がシグナルとなります。これは、市場参加者がパニック状態にあるか、あるいは興奮状態にあることを示していますが、こうした感情は往々にして過剰であり、価格はいずれ妥当な水準に戻るでしょう。
2.4 要因シグナル
ファクターシグナルとは、数十年にわたる学術研究によって確認された体系的なリターンプレミアムのことである。最もよく知られている5つのファクターは以下のとおりである。
価値
・勢い
・低変動性
運ぶ
• 品質
それぞれの要因は、市場がリスクを価格設定する際に、人間の行動や市場構造に内在する根本的な欠陥を表している。
例えば、「価値要因」が有効なのは、人間が本質的に流行を追いかける傾向があるからだ。誰もが話題にしている契約は、すでに価格が十分に織り込まれていることが多い。一方、誰も注目していない「ニッチな契約」は、価格にばらつきが生じやすい。
Polymarketでは、何千人もの人が注目している人気注文を追いかけるよりも、取引量は少ないもののファンダメンタルズが変化している契約を調査することに時間を費やすべきです。そのため、ユーザーが潜在的なアルファを持つ市場を見つけやすいように、ボラティリティ、最新の市場データ、取引量、トレーダー数などの指標をinsiders.botのホームページに追加しました。
2.5 微細構造シグナル
マイクロストラクチャーシグナルは、高頻度取引を行うトレーダーの間で人気が高い。彼らは、注文板の厚みの不均衡、売買スプレッドの動的な変化、そして取引量の積極性などに注目する。
これらのシグナルは、通常数分から数時間という非常に短い時間しか有効ではありません。しかし、非常に重要なことを教えてくれます。それは、情報優位性を持つ賢明な投資家が、価格が実際に変動する前にどこでポジションを構築しているかということです。
微細構造を測定するために最も一般的に使用される指標の1つは、有効広がりです。
実効スプレッド = 2 × |取引価格 - 中央値価格|
実効スプレッドが大きいほど、市場の流動性が低く、取引コストが高いことを示します。実効スプレッドが急激に拡大する場合、多くの場合、情報通のトレーダーが市場に参入し、マーケットメーカーが自らを保護するためにスプレッドを拡大していることを意味します。
もう一つの重要な指標は、VPIN(ボリューム同期型情報取引確率)です。この指標は、2012年にイーズリー教授、ロペス・デ・プラド教授、オハラ教授によって提唱されました。これは、買い注文と売り注文の数量の不均衡を分析することで、市場における取引のうち「情報通のトレーダー」によってどれだけが動かされているかを推定するものです。
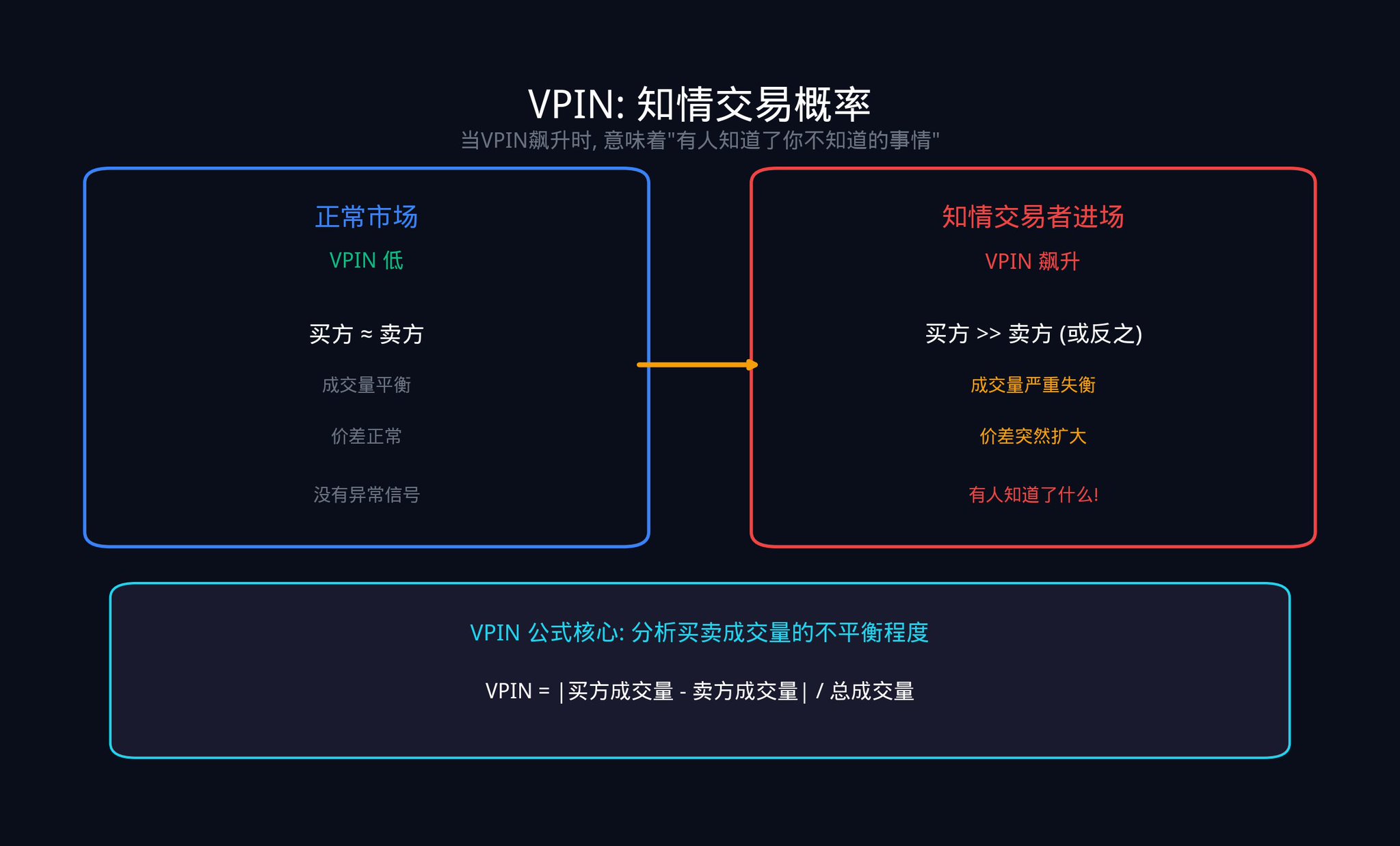
VPINの計算ロジックは非常に直感的です。取引量を一定サイズの「バケット」(例えば、1000件の取引ごとに1つのバケット)に分割し、各バケット内の買い量と売り量の差を調べます。差が大きい場合は、どちらか一方が一方的な攻撃を仕掛けていることを意味し、通常は情報通のトレーダーが行動を起こしていることを示しています。
VPINが急上昇する場合、それは多くの場合、誰かがあなたの知らない何かを知っていることを意味します。2010年の「フラッシュクラッシュ」の数時間前には、VPINはすでに異常な急上昇を始めていました。
Polymarketでは、スマートマネーのオンチェーンでの行動が最も直接的なミクロ構造シグナルとなります。過去の勝率が65%を超えるウォレットが突然あるコントラクトに多額の賭けを行った場合、それは非常に価値のあるシグナルとなります。
スマートマネーブラウザとinsiders.botのv1.2/v1.3シグナルで行っていることは、基本的にこれらのオンチェーンの微細構造シグナルをリアルタイムで皆様にお届けすることです。
覚えておいてほしいのは、これら5種類のシグナルはどれも単独ではシステム的な優位性を形成するには不十分だということだ。それらは単なる原材料に過ぎない。
次に、最も重要な第三の部分、つまり原材料を金に変える「複合エンジン」について説明します。
パート3:11ステップエンジンの組み合わせ
この記事の中で最も核心的な部分です。これから説明する11のステップは、この機関が生の信号セットを最適な重み付けの組み合わせに変換するために用いる手順の全てです。
これらの11のステップは、データ準備、市場ノイズの除去、独自の優位性の抽出、最終的なウェイトの割り当てという4つの段階に分けられます。
背景を改めて説明しましょう。N個のシグナル(例えば50個)があるとします。それぞれのシグナルは、一定期間にわたって一連のリターンデータ(つまり、毎日どれだけの利益または損失が出たか)を生成しています。
この複合システムの役割は、過去のデータに基づいて、各シグナルにどれだけの資本比重を割り当てるべきかを計算することである。
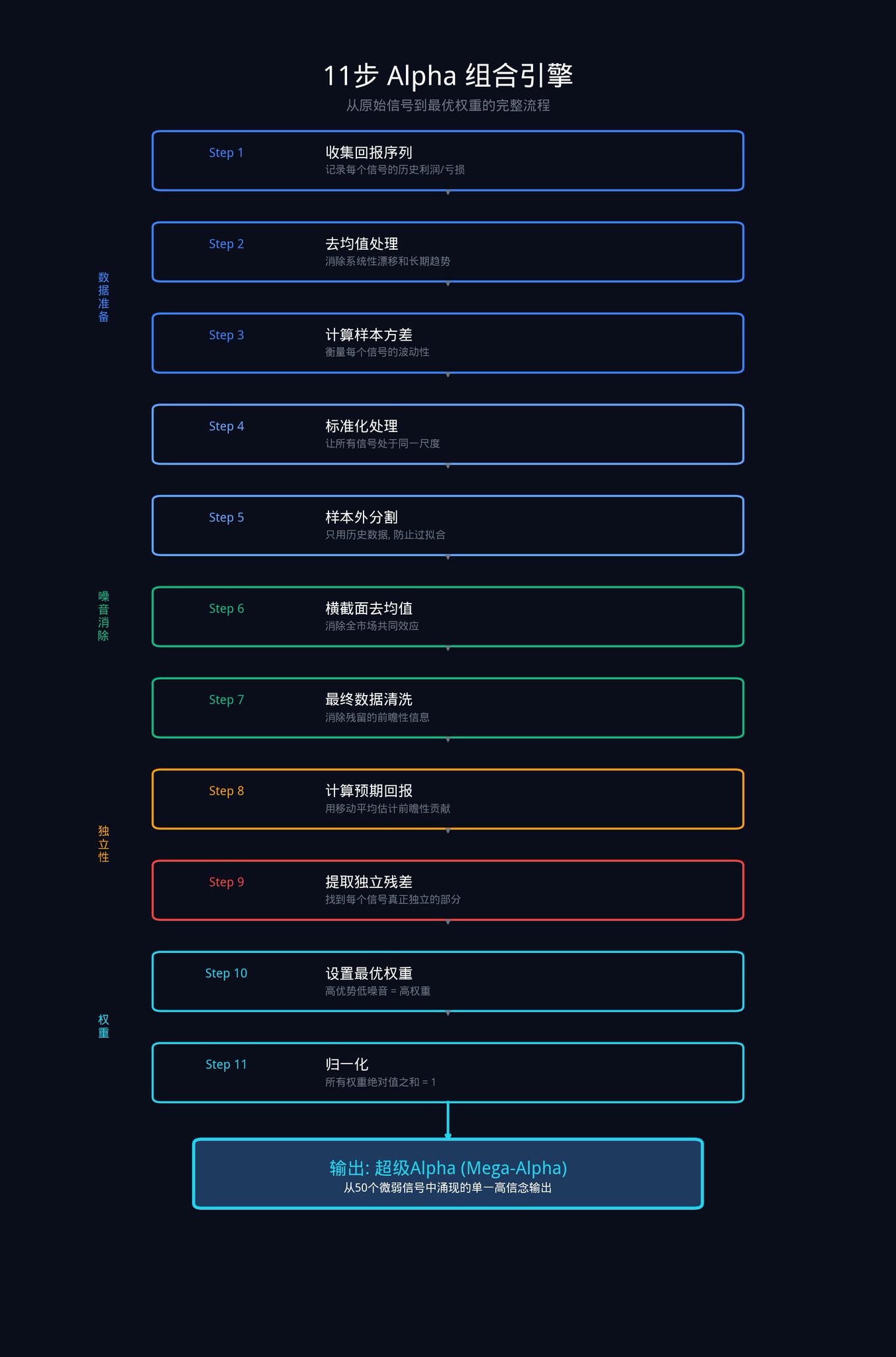
フェーズ1:データ準備
現段階での目標は、すべての信号を公平な条件で比較できるようにすることです。
ステップ1:各信号の過去のパフォーマンスデータを収集する
これは最も基本的な手順です。過去の各期間における、各シグナルごとの実際の損益を記録する必要があります。
例えば、モメンタムシグナルが過去30日間で1日目に2%の上昇、2日目に1%の下落、3日目に0.5%の上昇といった推移を示したとします。これらのデータをすべて記録してください。各シグナルには、このようなデータ列が必要です。
数学的に言えば、これは各時間間隔 s における各信号 i に対する報酬 R(i,s) を収集することを意味します。
ステップ2:系統的ドリフトを除去する(平均値を取り除く)
各シグナルの過去のリターンから、そのシグナル自身の平均リターンを差し引く。
なぜこれをするのか?
例えば。
・仮に「押し目買い」のシグナルが出たとしましょう。過去1年間、仮想通貨市場全体が急騰しているので、このシグナルは大きな利益をもたらしたように見えます。
しかし、これは本当にシグナルによるものなのでしょうか?必ずしもそうとは限りません。強気相場では、どんな戦略でも利益を上げることができるでしょう。「市場全体のトレンドを除外した」後で、シグナルに真の予測力があるかどうかは、平均値を差し引いて初めてわかるのです。
具体的な式は次のとおりです。X (i,s) = R(i,s) - mean(R(i))。
ステップ3:各シグナルの変動性を計算する
このステップでは、各シグナルのリターンの変動性を測定します。
単一のシグナルは平均して1日あたり0.1%の利益を上げるかもしれないが、時には5%の利益を上げ、時には4%の損失を出すこともある。
もう一つのシグナルは、平均日次利益が0.1%であるものの、変動幅が-0.5%から+0.7%の間に限られていることです。
2つのシグナルの平均リターンは同じだが、 2番目のシグナルの方が明らかに「安定」していて信頼性が高い。
変動性は、この「安定性」を定量化するために用いられる。
具体的な式は次のとおりです。σ(i)² = (1/M) x Σ X(i,s)²。
ステップ4:標準化処理
ステップ2の結果をステップ3のボラティリティで割ります。
なぜこの手順が必要なのでしょうか?それは、異なるシグナルが異なる「単位」を使用するからです。モメンタムシグナルはパーセンテージで計算される場合があり、ミクロストラクチャーシグナルはベーシスポイント(0.01%)で計算される場合があり、ボラティリティシグナルは絶対値で計算される場合があります。これらを直接比較することは、リンゴとオレンジの大きさを比較するようなもので、意味がありません。
標準化によって、すべての信号が同じ尺度に統一されます。これは、米ドル、ユーロ、日本円を同じ通貨に換算するようなもので、公平な比較が可能になります。
具体的な式は次のとおりです。Y(i,s) = X(i,s) / σ(i)。
フェーズ2:市場の雑音の排除
この段階での目標は、「市場全体の変動」と各シグナルのパフォーマンスを切り離し、シグナル自体の真の能力のみを明らかにすることです。
ステップ5:サンプル外セグメンテーション
重みを計算する際には、過去のデータのみが使用され、最新の観測値は破棄されます。
この手順は「過学習」を防ぐためのものです。
過学習とは何でしょうか?例えば、ある学生が過去10年分の試験問題をすべて暗記し、模擬試験では毎回満点を取ったとします。しかし、実際の試験で新しい問題が出題されると、全く答えられません。彼は「知識を理解している」のではなく、「答えを暗記している」だけなのです。
定量取引においては、過学習はさらに危険です。モデルは過去のデータでは完璧なパフォーマンスを発揮するかもしれませんが、実際の取引では期待を下回る結果となる可能性があります。サンプル外分割を行うことで、モデルが「過去のデータを記憶する」のではなく、「パターンを学習する」ことができるようになります。
具体的な手順は以下のとおりです。
データを2つの部分に分けます。
・データの最初の80%を使用してモデルをトレーニングします(重みを計算します)。
・最後の20%のデータを使用して、モデルが本当に効果的かどうかを検証します。
モデルがデータの最後の20%でも利益を上げられるのであれば、それはモデルが真のパターンを学習したことを意味する。
ステップ6:横断的軽蔑
各時点において、その時点における全信号の平均パフォーマンスを、各信号のパフォーマンスから差し引く。
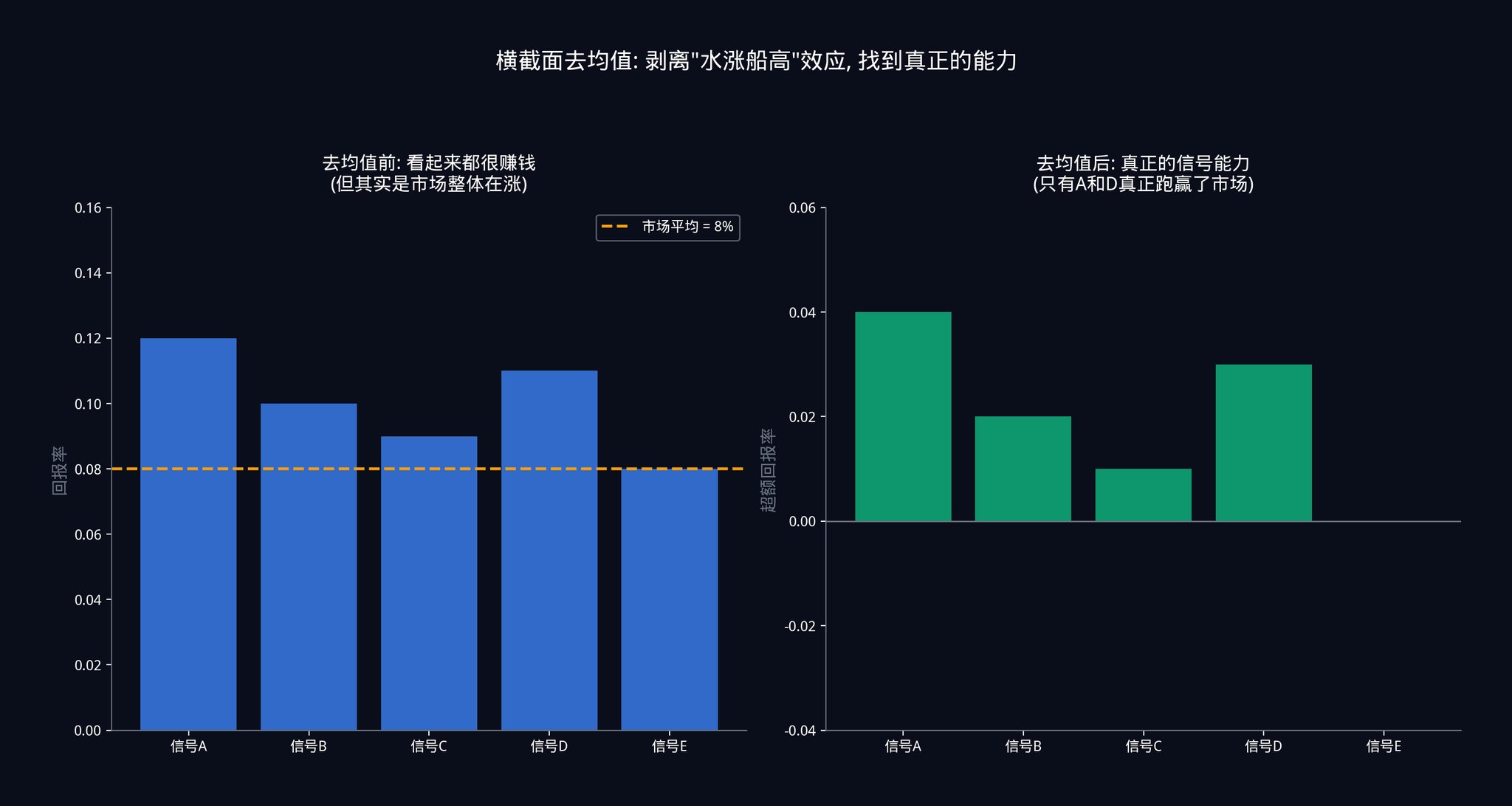
この手順は非常に重要なので、具体的なシナリオを用いて説明します。
仮に連邦準備制度理事会が今日、突然利下げを発表したとしましょう。市場全体が急騰します。あなたの50個のシグナルが同時に「買い」注文を出し、どのシグナルも利益を上げているように見えるかもしれません。
複数のセクションにわたる平均値を計算しないと、50個のシグナルすべてが正確だと考えてしまうかもしれません。しかし実際には、これは単に「潮が満ちればすべての船が浮かぶ」という現象です。市場全体が上昇しているため、シグナルの精度に関係なく、あなたのシグナルも利益を生み出すのです。これはシグナルの能力によるものではなく、市場からの恩恵と言えるでしょう。
すべてのシグナルの平均パフォーマンスを差し引いて初めて真実が見えてきます。つまり、全員が利益を上げている日には、どのシグナルが他のシグナルよりも多くの利益を上げているのか?全員が損失を出している日には、どのシグナルが他のシグナルよりも損失が少ないのか?この「相対的なパフォーマンス」こそが、シグナルの真の実力なのです。
より具体的には、Λ(i,s) = Y(i,s) - (1/N) x Σ Y(j,s)。
※ステップ2の「平均値除去」とステップ6の「横断的平均値除去」は異なります。ステップ2では、各シグナルの時系列から平均値を除去します(長期トレンドの除去)。ステップ6では、各時点におけるすべてのシグナルの平均値を除去します(市場全体の影響の除去)。どちらも不可欠です。
ステップ7:最終データクリーニング
これはデータクレンジングの最終段階です。データシーケンスに「将来的な情報」が残っていないことを保証します。
将来予測情報とは何でしょうか?それは、意思決定を行う時点では到底知り得ない将来のデータのことです。例えば、金曜日の終値に基づいて月曜日に意思決定を行うことはできません。これは常識のように聞こえますが、複雑なデータ処理ワークフローにおいては、このような「データ漏洩」は想像以上に起こりやすいのです。
フェーズ3:独立した優位性の抽出
この段階はエンジン全体の魂とも言える部分です。その役割は、各信号が持つ独自の予測力を抽出し、他の信号と重複する部分を排除することです。
ステップ8:期待収益率を計算する
移動平均を用いて、各シグナルが将来にもたらすであろう寄与度を計算します。
具体的には、各シグナルの直近d日間の平均リターンを将来のパフォーマンス予測値として算出します。この予測値は、異なるシグナルの期待リターンを直接比較できるように、標準化(ボラティリティで割る)されます。
式で表すと次のようになります。
E(i) = (1/d) x Σ R(i,s)
・E_norm(i) = E(i) / σ(i)。
ステップ9:独立した残差を抽出する(直交化)
これは全11ステップの中で最も重要なステップです。
2つの信号があると仮定します。
信号Aは「天気予報を確認してください」という意味です。
・信号Bは「歩行者が傘を持っているかどうかを確認する」ためのものです。
これらの2つの兆候はどちらも、今日雨が降るかどうかを予測できる。
問題は、傘を差している通行人が、天気予報を確認したから傘を差している可能性もあるということです。そのため、信号Aと信号Bの間には情報が大きく重複しています。これらを同時に使用すると、 2つの独立した信号があるように思えるかもしれませんが、実際には、1つの信号(天気予報)が2回伝達されているだけです。
ステップ9の課題は、この情報の重複を解消することです。
具体的にどのように行うのでしょうか?各シグナルの期待収益率 E_norm(i) に対して、他のすべてのシグナルの履歴データ Λ(i,s) を使用して回帰分析を実行します。回帰とは、他のシグナルを使用してこのシグナルを「説明」することです。説明可能な部分、つまり重複する部分は破棄されます。説明できない部分、つまりこのシグナル固有の寄与部分は保持されます。
この「説明できない部分」は、数学では残差と呼ばれ、ε(i)と表記される。
線形代数を学んだことがある方なら、これはグラム・シュミット直交化の応用だとお分かりでしょう。学んでいない方もご安心ください。ただ一つ覚えておいていただきたいのは、ステップ9は各信号の真にユニークでかけがえのない予測力を見つけることだということです。
第4段階:最終的な重み付けの決定
ステップ10:最適な重みを設定する
重みを計算する式は次のとおりです。w(i) = η x ε(i) / σ(i)。
この式は、各信号の重みが、その独立した寄与ε(i)(ステップ9で計算)をその変動性σ(i)(ステップ3で計算)で割った値に、スケーリング係数ηを掛けたものに等しいことを示しています。
これはどういう意味でしょうか?エンジンは、独立した重要な貢献をし、安定したパフォーマンスを示す信号に自動的に高い重みを割り当てます。ノイズが多い信号や、単にトレンドに従うだけの信号は、自動的に低い重みが割り当てられます。
これらはすべて数学によって自動的に行われるため、主観的な判断は一切必要ありません。自分の感覚に基づいて「この信号のどのくらいの割合を配分すべきか」を決める必要はありません。数式が最適な答えを教えてくれます。
ステップ11:正規化
最後のステップは、すべての重みの絶対値の合計が 1 になるようにスケーリング係数 η を調整することです。
これにより、総資本配分が100%になることが保証され、意図せずレバレッジをかけてしまうことを防ぎます。この手順を踏まないと、配分が150%になってしまい、気づかないうちに1.5倍のレバレッジで取引しているという事態になりかねません。
数学的に言うと、η は Σ|w(i)| = 1 となるようなものとする。
これら11ステップの最終出力は、N個のシグナルそれぞれの最終的な重みです。これらの弱いシグナルをそれぞれの重みに従って組み合わせると、メガアルファ、つまり高い勝率と高い信頼性を持つ単一の出力が得られます。
上級演習2:
このプログラムを現在のシグナルスタックで実行した場合、どのシグナルが高い重み付けを受け、どのシグナルが低い重み付けを受けるかに驚くでしょうか?その答えは、あなたが実行しているシステムの独立性構造をどれだけ理解しているかを示すものとなるでしょう。
これらの行列演算の背後にある論理を深く理解したいのであれば、MITの無料オンライン講座「線形代数」の直交化に関する章を視聴することを強くお勧めします。ギルバート・ストラング教授が非常に分かりやすく解説しています。
第4部:独立の罠
組み合わせエンジンは問題を解決する。この問題は、一度に1つの信号だけを見ている場合には見えないが、数学的な原理を理解すれば、あらゆる場面に存在する問題であることがわかる。
パート1で述べた、プロアクティブマネジメントの基本原則に戻りましょう。
IR = IC × √N
この3文字が何を表しているか覚えていますか? IRはシステム全体の「リスク調整後リターン」(つまり、戦略の安定性)を表します。ICは個々のシグナルの平均精度です。Nはポートフォリオ内の独立したシグナルの数です。
ここで、多くの人が見落としがちな重要なキーワードを強調したいと思います。それは「独立」です。
ここで、Nはシグナルスタック内のシグナルの総数ではありません。有効で独立したシグナルの数です。この2つの数値は大きく異なる場合があります。
なぜか?それは、信号が「密かに」相互接続されている可能性があるからだ。
モメンタムシグナルと平均回帰シグナルは、性質が全く正反対であるように見える(一方は価格上昇を追いかけ、もう一方は底値で買いを入れる)。しかし、特定の市場環境下では、両者は同じマクロ経済ニュースに同時に、同じ方向に反応する可能性がある。
例えば、連邦準備制度理事会が突然金利を引き上げた場合、モメンタムシグナルは「トレンドは下降傾向にあるので売り」と示し、平均回帰シグナルも「平均から大きく乖離しているが、方向も下降傾向にある」と示す。
現時点では、一見独立しているように見える2つの信号が、実際には同じ見解を表明している。
両者に同じ重み付けをすれば、二つの独立した視点の間でリスクを分散しているように思えるかもしれません。しかし実際には、同じ視点に対する投資比率を倍増させているに過ぎません。

そのため、第3部のステップ6(横断的平均値の減算。これは、各時点におけるすべての信号の平均パフォーマンスを減算することで、「潮が満ちればすべての船が浮かぶ」効果を排除する)とステップ9(独立残差の抽出。これは、回帰分析によって信号間の情報重複を排除し、各信号固有の寄与のみを保持する)が非常に重要なのです。これらのステップの目的は、信号間に隠れた共通要素を特定し、排除することです。
50個の関連シグナルを実行しても、得られる効果は10~15個の独立したシグナルと同程度にとどまる可能性があります。シグナルが真に独立した情報源に基づいて構築され、かつ組み合わせエンジンが正しく動作している場合にのみ、50個のシグナルすべてのメリットを最大限に享受できるのです。
これは実際にはどういう意味を持つのでしょうか?
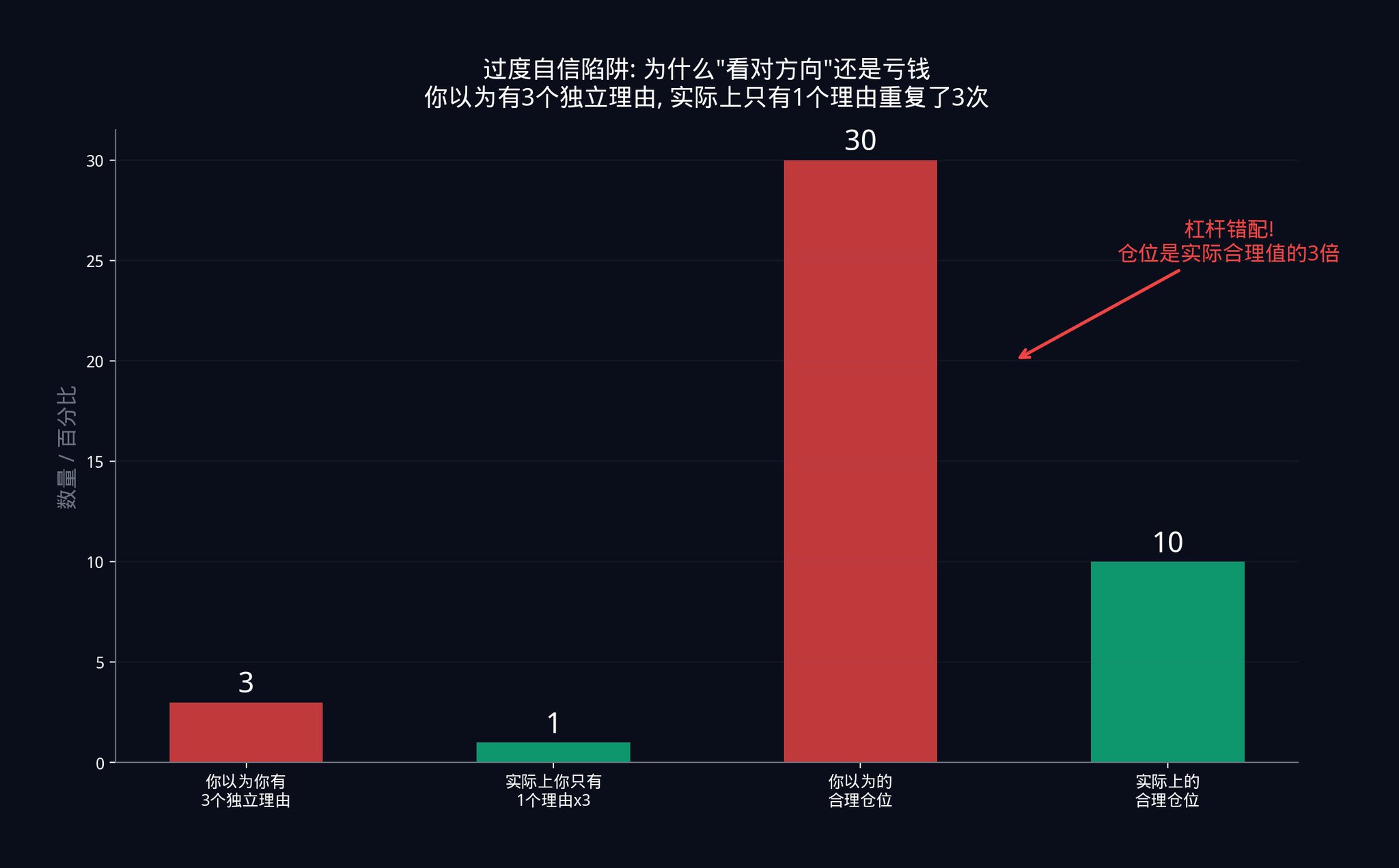
・あるトレーダーが、20個の独立したシグナルに基づいて取引を行っていると考えているとします。トレーダーはこれらの20個の独立したシグナルに基づいてポジションサイズを計算します。しかし、シグナル間に隠れた相関関係があるため、有効な独立したシグナルは6個しかありません。
20個の独立したシグナルによって裏付けられたポジションサイズは、わずか6個のシグナルによって裏付けられたポジションサイズよりも大きすぎます。どれくらい大きいのでしょうか?20/6 ≈ 3.3倍です。彼の実際のレバレッジは、彼が考えていたよりも3倍以上大きいのです。
このレバレッジのミスマッチこそが、ほとんどのシステマティック戦略が破綻する真の理由です。トレーダーは方向性に関しては正しかったものの、規模に関しては間違っていました。市場の上昇を正しく予測したものの、賭け金が大きすぎたのです。通常の調整局面でも、彼は全財産を失ってしまうでしょう。
組み合わせエンジンは、正確な計算を強制します。自己欺瞞を許しません。信号スタックの真の独立構造がどのようなものかを示し、あなたの推測ではなく、現実に基づいて重みを割り当てます。
正しく分析した取引でも常に損失を出してしまうトレーダーは、ほとんどの場合、測定していない相関関係が原因で損失を出している。彼らは自信を持つための独立した3つの理由があると考えているが、実際には、3回繰り返されているのは1つの理由に過ぎない。にもかかわらず、彼らは3つの理由に基づいてポジションサイズを決定しているのだ。
複合エンジンは、この故障モードを構造的に排除します。
上級演習3:
現在使用しているすべての信号をペアにして、相関係数を計算してください。Pythonの` numpy.corrcoef()`関数を使用できます。いずれかの信号のペアの相関係数が0.5を超える場合、それらは数学的に独立していません。信号スタックを再検討する必要があります。
マルコス・ロペス・デ・プラド著『金融機械学習の進歩』、特に特徴量の重要性と直交化に関する章を読むことをお勧めします。この本は、現代の定量的手法を学ぶ上で必読書です。
パート5:Polymarketでの実装
最初の4つのセクションはすべて、株式およびマルチアセット市場における体系的な取引の文脈に基づいて構築されています。朗報は、この数学的手法を市場予測に直接応用できるということです。必要なのは、単に置き換えを行うだけです。「期待収益率」に関するシグナルを組み合わせる代わりに、「期待確率」に関するシグナルを組み合わせるのです。
予測市場では、各シグナルは収益率の推定値を生成するのではなく、暗黙の確率推定値を生成する。
5.1 確率信号の5つのタイプ
まず、プラットフォーム間の価格差が重要なシグナルとなります。例えば、Polymarketでの契約のYES価格が0.45ドルであるにもかかわらず、Betfairでの同じイベントのオッズが52%の確率を示している場合、この7パーセントポイントの価格差がシグナルとなります。2つのプラットフォームで同じイベントの価格設定が異なっている場合、少なくともどちらか一方の価格設定が間違っていることになります。
第二に、キャリブレーションシグナルについて: Polymarketの過去4億件の取引を分析した結果、体系的なバイアスが明らかになりました。5%から15%の価格帯で契約された案件のうち、最終的に「YES」と判定されたのはわずか4%から9%でした。これは、市場が低確率の事象の発生確率を体系的に過大評価していることを意味します。このバイアスは安定しており再現性があるため、有効なシグナルと言えます。
第三に、ベイズ更新シグナル:これは定量取引の根幹をなすツールです。その核心的な問いは、新しいデータを入手した際に、既存の信念をどのように正確に更新すべきか、ということです。
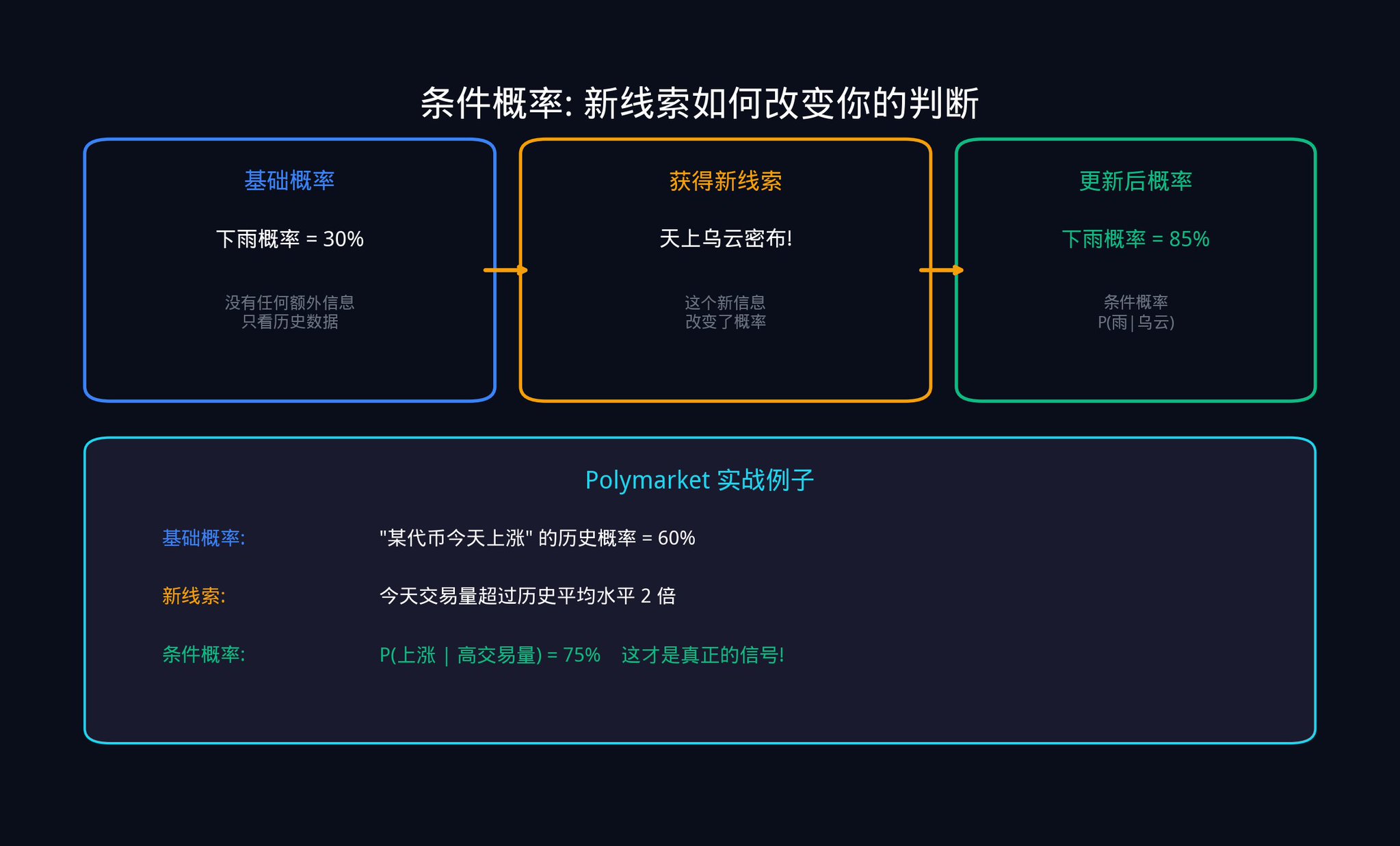
ベイズ更新について、具体的な例を用いて説明しましょう。
あなたがPolymarketの契約「今月、ある議会法案が可決されるか?」に従っているとします。現在の市場価格は0.40ドルで、これは市場が可決確率を40%と見込んでいることを意味します。これがあなたの事前確率です。
突然、あるニュースが飛び込んできた。その法案が、有力な上院議員から公的な支持を得たというのだ。
確率を単純に80%に変更することはできません。正確な計算にはベイズの定理を用いる必要があります。
ベイズの定理は次のとおりです。
P(合格|支持) = P(支持|合格) × P(合格) / P(支持)
平易な言葉で言うと:
「上院議員が法案を公に支持した場合の法案可決の確率」=「法案が実際に可決された場合に上院議員が法案を公に支持する確率」×「法案が可決される事前確率」/「上院議員が法案を公に支持する全体の確率」。
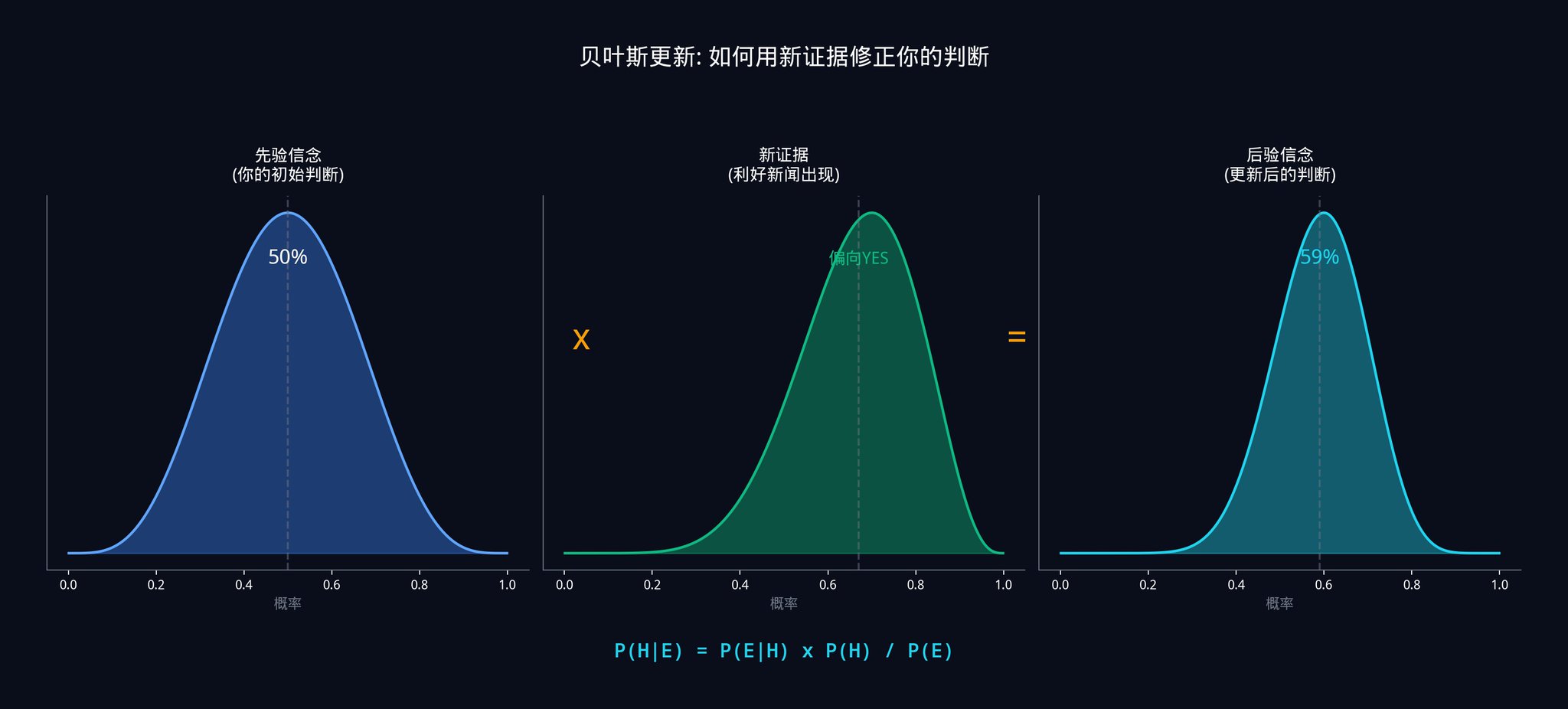
仮にあなたが以下のように見積もるとします。
・もし法案が可決された場合、この上院議員が公に支持する可能性は80%ある(なぜなら彼は通常、確信が持てる場合にのみ意見を表明するからである)。
・法案が否決された場合、この上院議員が公に支持する可能性は20%ある(彼は時折間違った側に立つこともある)。
法案が可決される事前確率は40%である。
それで:
• P(支持)= 0.80 x 0.40 + 0.20 x 0.60 = 0.32 + 0.12 = 0.44
• P(through|support) = 0.80 x 0.40 / 0.44 = 0.32 / 0.44 = 72.7%
したがって、このニュースを受けて、法案可決の確率予測を40%から72.7%に修正すべきです。市場価格が0.50ドルのままであれば、22.7%の有利な立場になります。
ベイズ更新の本質は、新たな確率を「推測」するのではなく、数学を用いて正確に計算するという点にある。つまり、あらゆる判断は証拠に基づいて行われるのである。
第4に、ミクロ構造シグナル: VPIN(第2部で説明した「情報に基づいた取引確率」指標で、買いと売りのボリュームの不均衡を分析することで、情報に基づいたトレーダーが行動しているかどうかを判断する)と実効スプレッドを使用して、情報に基づいた注文フローの方向に基づいて確率が示唆されます。
第 5 に、勢いシグナル:契約が完了に近づくにつれて価格が変化する速度と方向は、確率を示唆します。
5.2 シグナルからベットまで:完全なプロセス
これらの暗黙的な確率推定はそれぞれ、第3部で説明した11ステップの組み合わせエンジンと全く同じように実行されます。出力は単一の重み付き組み合わせ確率推定値です。この推定値には、各信号の独立した寄与に基づいて数学的に最適な重みが割り当てられます(ステップ9の直交化を思い出してください。つまり、信号間の情報の重複を排除し、固有の部分のみを保持するということです)。
その合計見積もりと現在のPolymarket価格との差額が、あなたの優位性となります。
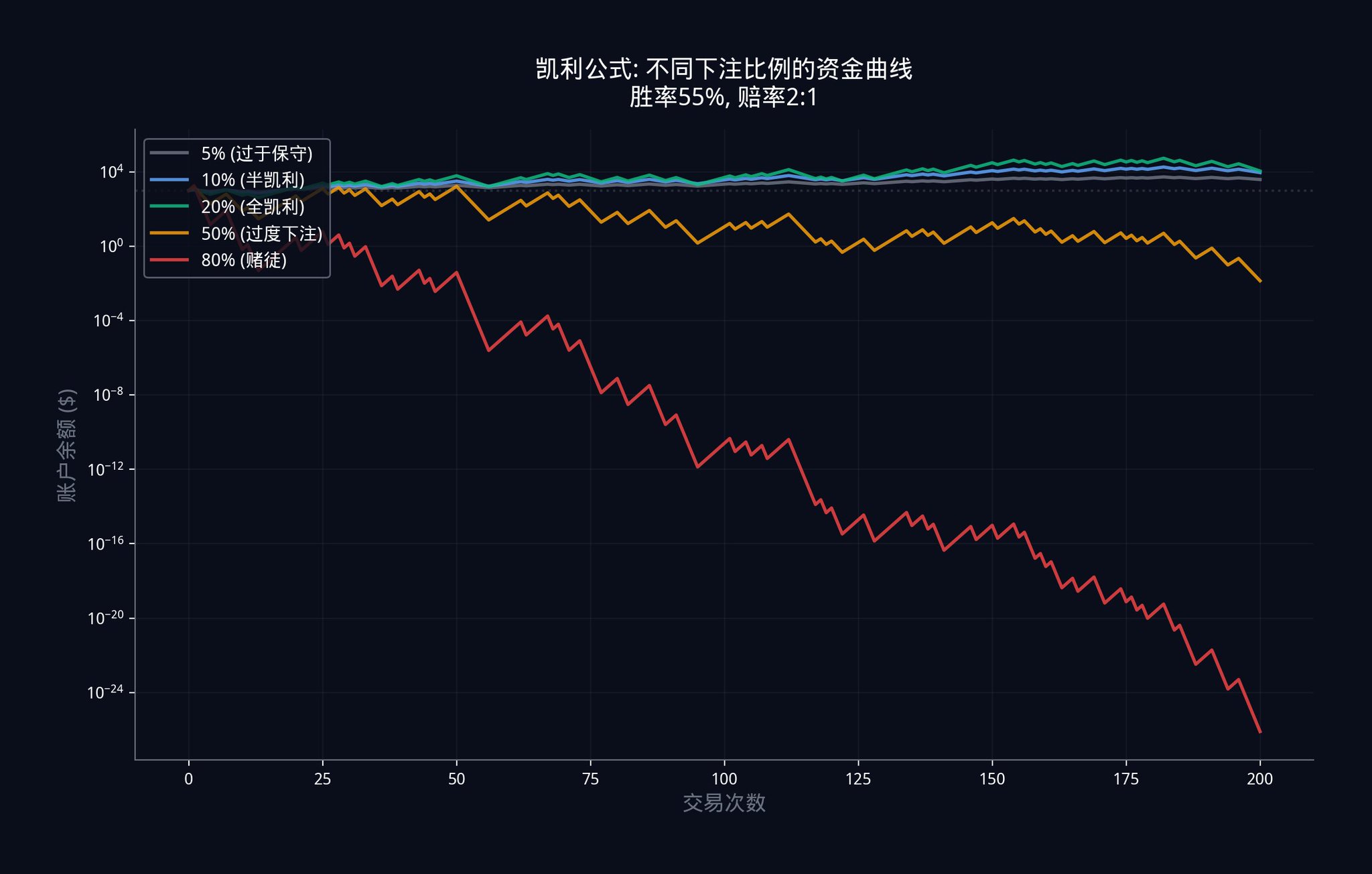
5.3 ケリー基準:いくら賭けるべきか?
有利な立場に立った今、最も重要な問題は、いくら賭けるべきかということです。
賭け金が少なすぎると、せっかくのアドバンテージを無駄にしてしまい、十分な利益を得ることができません。逆に賭け金が多すぎると、たった一度の判断ミスで全てを失ってしまう可能性があります。
この組織はケリー基準を採用しています。標準的なケリー基準は以下のとおりです。
f_kelly = (pxb - q) / b
ここで、p は推定される勝率(組み合わせの確率)、q = 1 - p は負ける確率、b はオッズです。
Polymarketでは、オッズbは価格から直接計算できます。b = (1 / 市場価格) - 1。たとえば、市場価格が$0.40の場合、オッズb = (1/0.40) - 1 = 1.5となります。
ポートフォリオモデルによると、真の確率は60%(p = 0.60)、市場価格は0.40ドル(オッズb = 1.5)だとします。この場合、標準的なケリー基準では、次のように賭けることを推奨します。
f_kelly = (0.60 x 1.5 - 0.40) / 1.5 = (0.90 - 0.40) / 1.5 = 0.50 / 1.5 = 資金の 33.3%。
しかし、標準的なケリー基準には致命的な前提があります。それは、勝率の推定値が100%正確であるという前提です。実際には、推定値には必ず何らかの誤差が生じます。そのため、金融機関は「不確実性ペナルティ」を組み込んだ経験的ケリー基準を採用しています。
f_empirical = f_kelly x (1 - CV_edge)
ここで、CV_edgeはエッジ推定値の変動係数です。これは推定値の不確実性を表します。CV_edgeが大きいほど不確実性が高く、計算式は自動的に賭け金を減らします。
CV_edgeはどのように計算するのでしょうか?モンテカルロシミュレーションを用いることができます。簡単に言うと、モデルを何千回もシミュレーションして、さまざまなシナリオで優位性の推定値がどれだけ変化するかを確認します。変化が大きいほどCV_edgeは高くなり、賭けるべき金額は少なくなります。
上記の例を続けて説明します。CV_edge = 0.3(つまり、推定値に30%の不確実性がある)の場合、経験的ケリー基準では、次のように賭けることを推奨します。
f_empirical = 33.3% x (1 - 0.3) = 33.3% x 0.7 = 23.3% の資金。
実際には、多くの金融機関は「ハーフ・ケリー」マージン、つまり2で割った約12%しか使用していません。これは、長期的に見れば、少し収益が少なくても、資産をすべて失うよりははるかに良いからです。
5.4 ポリマーケットの完全な取引パイプライン
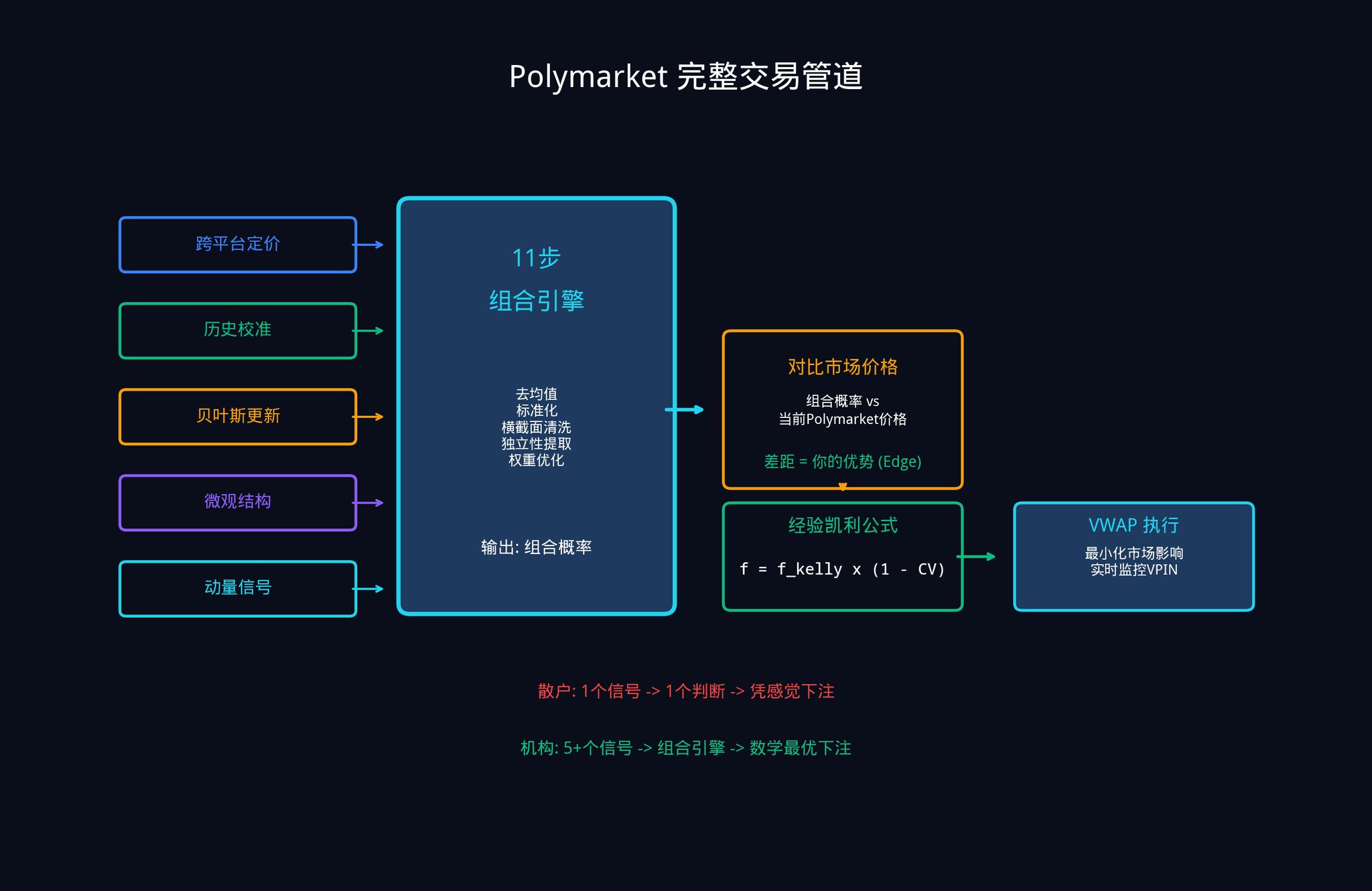
すべてをまとめると、全体のワークフローは以下のようになります。
1. それぞれが暗黙的な確率推定値を生成する、5つ以上の入力信号。
2. 11段階の複合エンジンで処理されます。
3. 単一の重み付き組み合わせ確率を出力する。
4. 現在の市場価格と比較して、自社の優位性(エッジ)を計算します。
5. 経験的ケリー基準を用いて賭け金の額を決定する。
6. VWAP(出来高加重平均価格)を使用して執行を最適化し、大量注文が市場価格に与える影響を軽減します。
7. VPINの変化をリアルタイムで監視し、情報通のトレーダーの活動が活発化した場合は、速やかに戦略を調整する。
このフレームワークが市場予測において特に価値を発揮する理由は単純明快です。競合他社のほとんどは、単一のモデル、単一のデータソース、そして単一の確率推定値を用いて取引を行っています。一方、あなたは複数の弱いシグナルを単一の強力なシグナルに統合する方法を既に知っています。これがあなたの構造的な優位性です。
上級演習4:
興味のあるPolymarket契約を選択してください。少なくとも3つの異なる視点(例えば、プラットフォーム間の価格設定、過去のキャリブレーション、最近のニュースなど)から、その契約の成立確率を推定してみてください。次に、単純に加重平均を計算し、それらの推定値と現在の市場価格との間に乖離があるかどうかを確認してください。
もしそうなら、おめでとうございます!あなたは今、アルファの組み合わせの簡略版を手動で完了しました。
エドワード・ソープの著書『あらゆる市場に対応できる男』を読むことをお勧めします。ソープはケリー基準を投資に応用した先駆者であり、この本では彼が数学を用いてカジノやウォール街で利益を上げた方法を非常に分かりやすい言葉で解説しています。
第6部:insiders.botを使用したこのシステムの実装
この時点で、あなたはこう考えているかもしれません。「このシステムの論理は理解できたが、どうすればこれをゼロから自分で構築できるのだろうか?」
朗報です。ゼロから始める必要はありません。
insiders.bot(@insidersdotbot)の構築過程において、この記事で言及されている「アクティブ管理の基本法則」(つまり、 IR = IC x √N 、システム全体のパフォーマンスは、単一のシグナルの精度に独立したシグナルの数の平方根を掛けたものに等しい)から多くのインスピレーションを得ました。
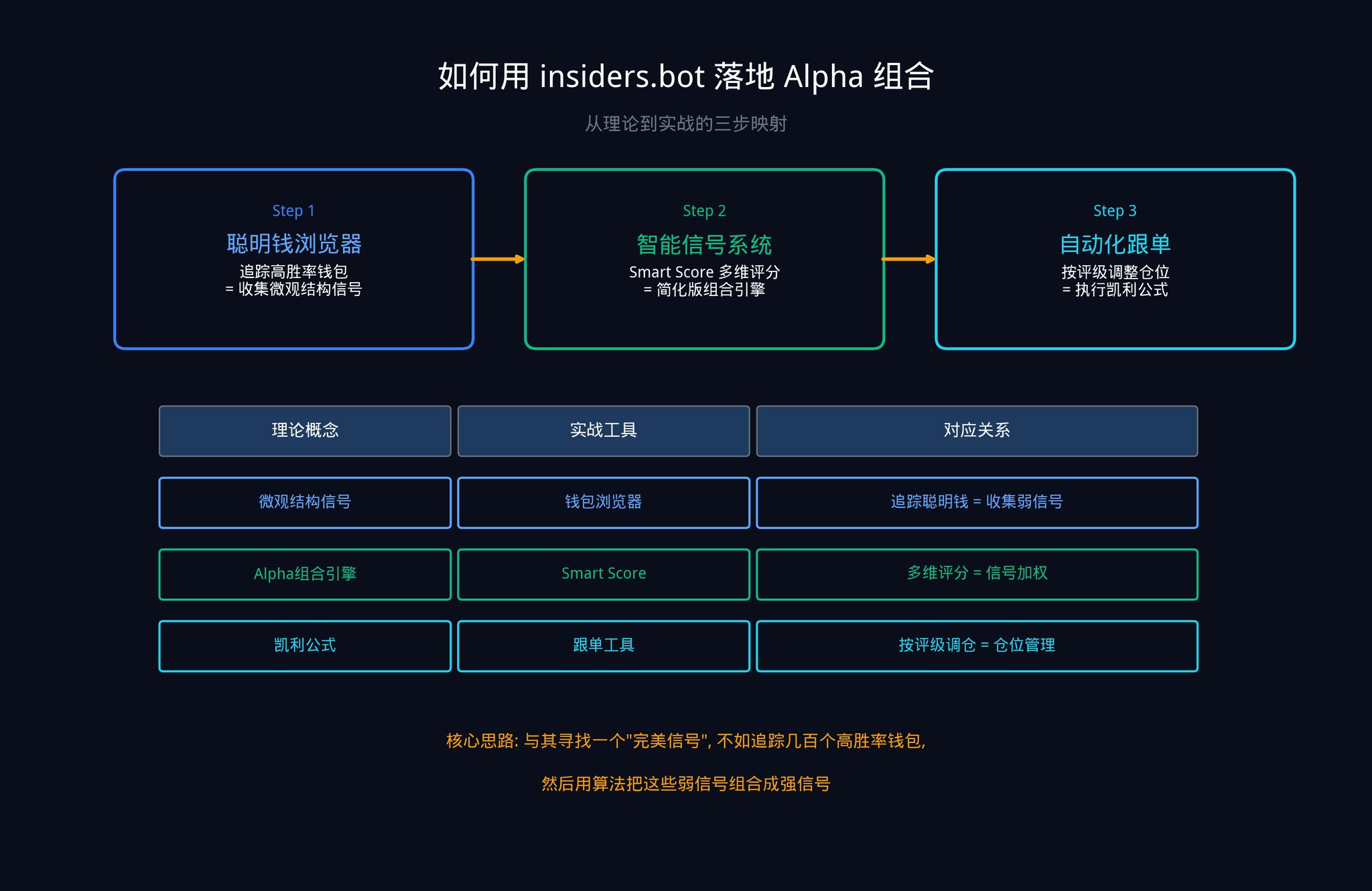
すぐに始められる3つのステップをご紹介します。
ステップ1:スマートマネーブラウザを使用してシグナルの原材料を収集します。
insiders.botでスマートマネーブラウザを開きます。フィルタリングパネルを使用すると、勝率、総損益、取引頻度などの指標に基づいて、Polymarketで最もパフォーマンスの高いウォレットを見つけることができます。
これらのウォレットにおけるあらゆる異常な活動は、あなたにとって「微細構造シグナル」となります(第2部で説明した5種類のシグナルのうち、5番目のカテゴリーを思い出してください)。単一のウォレットからのシグナルは弱い(ICが低い)かもしれませんが、数十個のウォレットを同時に追跡することで、記事で述べた「シグナルの組み合わせ」を作り出すことができます。これがアクティブ運用の基本法則の中核です。Nが大きいほど、IRは高くなります。
ステップ2:インテリジェント信号システムを使用してアルファ結合を実装する
当社のスマートシグナルシステム(「シグナル」タブ)は、基本的にアルファコンビネーションエンジンの簡易版です。高品質のウォレットが大きな取引を行うと、システムはシグナルを生成し、スマートスコアを使用して、過去の勝率、総損益、賭けの安定性、カテゴリー別パフォーマンス、ポジションサイズなど、複数の要素に基づいた強度評価を提供します。
LOW :基本基準は満たしているが、トレーダーの優位性は平均的。ICシグナルが低いため、組み合わせるにはより多くのシグナルが必要となる。
中型:確かな実績が揺るぎないコミットメントを証明しています。中距離IC信号に適しており、適切な構成を推奨します。
高:パフォーマンスの高いウォレットからの高額取引。高いICシグナルに対応して、組み合わせエンジンは高い重み付けを割り当てます。
このスコアリングシステムは、基本的に第3部の11ステップエンジンのステップ10(最適な重みの設定、つまり各シグナルの独立した貢献度と安定性に基づいて資金を配分すること)と同じことを行います。つまり、複数の側面を総合的に評価して、各シグナルに異なる重みを割り当てます。
ステップ3:コピートレードツールを使用して、ケリー基準を実行します。
高評価シグナルを受け取ったら、当社の自動コピートレードツールを使用して、比例配分または固定額のコピートレードを設定できます。
第5部で説明した経験的ケリーの公式(f_empirical = f_kelly x (1 - CV_edge)、つまり不確実性に応じて賭け金の比率を割り引く必要がある)を思い出してください。推定値の不確実性が高いほど、賭け金は少なくする必要があります。
低評価のシグナルが出た場合は、ポジションを減らしてください。
高評価を示すシグナルが出た場合は、ポジションを適度に増やすのが適切です。感情ではなく、数学的な分析に基づいて判断を下しましょう。
結論
最初に提起した質問に戻りましょう。
単一のシグナルは弱い。完璧なシグナルを探し求めるのは、全く見当違いなアプローチだ。
アクティブマネジメントの基本法則(IR = IC × √N)は、多くの弱い独立したシグナルを組み合わせる方が、単一の強いシグナルを見つけるよりも優れていることが数学的に証明されています。情報比率は、展開する真に独立したシグナルの数の平方根に比例して増加します。
11段階のアルファ結合エンジンは、最適な重みを計算するための正確な方法を提供します。これらの重みは、各信号の独立した寄与を反映し、ノイズにペナルティを与え、信号間の共通分散を排除します。
予測市場に適用した場合、このフレームワークは5つ以上の暗黙的な確率シグナルを単一の統合推定値に変換します。この推定値は、個々の要素よりも高い精度を示すことが証明されています。
ポジション管理のためのケリー基準と併用すると、結果として得られるポジションは、あなたが感じている自信ではなく、実際にどれだけの自信を持つべきかを正確に反映します。
複利の長期的な利点は、あなたが実際に知っていることを最も正直に反映したモデルに基づいています。
最後に、皆さんに考えていただきたい質問があります。
数百ものシグナルを組み合わせた機関投資家向けトレーディングデスクでさえ、情報係数が0.05から0.15の間しか達成できないとしたら、単一のモデルから高い確信度で常に勝ち銘柄を選び出せると主張するシステムは一体何なのでしょうか?
上級者向け読書資料と参考文献
このトピックについてさらに深く掘り下げたい場合は、以下の高度な資料を参照してください。
初心者レベル:
ハーバード大学統計学110:確率論入門(無料オンライン教科書)。確率論の基礎を学ぶ。最初の6章で十分です。
エドワード・ソープ著『あらゆる市場に対応できる男』。ケリー基準の先駆者である彼の自伝。数学がカジノやウォール街でいかに利益を生み出すかを、分かりやすい言葉で解説している。
上級レベル:
グリノルド&カーン著『アクティブ・ポートフォリオ・マネジメント』。定量投資の「バイブル」とも言える本書は、アクティブ運用の基本法則を詳細に解説している。
MIT 18.06 線形代数。ギルバート・ストラング教授による古典的な講義であり、直交化を理解するための最良の教材です。
上流階級:
マルコス・ロペス・デ・プラド著『金融機械学習の進歩』。現代の定量的手法を学ぶ上で必読の書であり、特に交差検証、特徴量の重要度、直交化に関する章は必見です。
Easley、Lopez de Prado、O'Hara (2012)、「高頻度取引の世界におけるフロー毒性と流動性」、Review of Financial Studies。VPIN指標に関する原著論文。


