
原著者: Malika Aubakirova、Matt Bornstein、a16z crypto
原文翻訳:Deep Tide TechFlow
クリストファー・ノーラン監督の映画『メメント』では、主人公のレナード・シェルビーは断片化された現在を生きている。脳損傷により前向性健忘症を患い、新たな記憶を形成できないのだ。数分ごとに彼の世界はリセットされ、永遠の「今」に閉じ込められ、ついさっき起こったことやこれから起こることを思い出すことができない。生き延びるために、彼はタトゥーを入れたりポラロイド写真を撮ったりする。これらの外的手段を用いて、脳が記憶を保持できないことを補っているのだ。
大規模な言語モデルもまた、同様の永続的な状態にあります。学習後、膨大な量の知識がパラメータに固定されるため、モデルは新しい記憶を形成したり、新しい経験に基づいてパラメータを更新したりすることができません。この欠点を補うために、チャット履歴は短期的なメモとして、検索システムは外部のノートとして、システムプロンプトはタトゥーのように、様々な仕組みを構築してきました。しかし、モデル自体がこの新しい情報を真に内面化することはありません。
研究者の間では、これだけでは不十分だと考える人が増えている。文脈学習(ICL)は、答え(あるいは答えの断片)が既に世界のどこかに存在することを前提とする問題を解決できる。しかし、真の発見(全く新しい数学的証明など)、敵対的シナリオ(セキュリティ攻撃と防御など)、あるいは言葉で表現するには暗黙的すぎる知識を必要とする問題の場合、モデルが展開後に新しい知識や経験をパラメータに直接組み込む方法が必要だと考える強い理由がある。
文脈学習は一時的なものです。真の学習には圧縮が必要です。モデルが継続的に圧縮できるようになるまでは、私たちは映画『メメント』の永遠の現在に囚われてしまうかもしれません。逆に、外部のカスタムツールに頼るのではなく、モデル自身がメモリアーキテクチャを学習できるように訓練できれば、スケーリングの全く新しい次元が開かれるかもしれません。
この研究分野は継続的学習と呼ばれています。この概念自体は新しいものではありませんが(マクロスキーとコーエンの1989年の論文を参照)、私たちはこれが今日のAIにおける最も重要な研究方向の一つだと考えています。過去2、3年のモデル能力の爆発的な向上により、モデルが「知っていること」と「知り得ること」の間のギャップがますます顕著になってきています。この記事の目的は、この分野のトップ研究者から得た知見を共有し、継続的学習への様々なアプローチを明確にするとともに、スタートアップエコシステム内でこのテーマを推進することです。
注:この記事は、継続学習の分野における優れた研究者、博士課程学生、起業家の方々との綿密な意見交換によって実現しました。彼らは、自身の研究成果や知見を惜しみなく共有してくださいました。理論的基盤から、導入後の学習における工学的現実まで、彼らの洞察のおかげで、この記事は私たちだけで書き上げたものよりもはるかに充実したものとなりました。貴重なお時間とアイデアをありがとうございました。
まずは背景について話し合いましょう。
パラメトリック学習(すなわち、モデルの重みを更新する学習)を擁護する前に、コンテキスト学習が実際に機能するという事実を認める必要がある。そして、コンテキスト学習が今後も主流であり続けるという強い根拠がある。
Transformerの本質は、シーケンスに基づいた条件付きトークン予測器です。適切なシーケンスを与えると、重みを一切変更することなく、驚くほど多彩な動作が得られます。コンテキスト管理、ヒントエンジニアリング、命令の微調整、少数の例といった手法が非常に強力なのはそのためです。インテリジェンスは静的パラメータにカプセル化されていますが、その機能は入力される内容によって大きく変化します。
Cursorが最近発表した、自律プログラミングエージェントのスケーリングに関する詳細な記事は良い例です。モデルの重みは固定されており、システムを実際に動作させるのは、コンテキストの慎重な配置、つまり何を入力するか、いつ要約を実行するか、そして何時間にも及ぶ自律動作中に一貫性のある状態を維持する方法です。
OpenClawもその好例です。その人気の理由は、特別なモデルアクセス(基盤となるモデルは誰でも利用可能)によるものではなく、コンテキストとツールを極めて効率的に作業状態に変換する能力にあります。具体的には、作業内容の追跡、中間成果物の構造化、キューワードの再挿入タイミングの決定、過去の作業内容の永続的な記憶の保持などです。OpenClawは、インテリジェントエージェントの「シェル設計」を独立した学問分野へと高めています。
サジェスチョンエンジニアリングが初めて登場した時、多くの研究者は「サジェスチョンワードだけ」で正当なインターフェースが実現できるのかと懐疑的でした。それはまるでハックのように思えたのです。しかし、これはTransformerアーキテクチャのネイティブな産物であり、再学習は不要で、モデルの改善に伴って自動的にアップグレードされます。モデルが強力であればあるほど、サジェスチョンも強力になります。「シンプルでありながらネイティブな」インターフェースは、基盤となるシステムと直接連携しているため、しばしば成功を収めます。これはまさに、今日までのLLM開発の軌跡と言えるでしょう。
状態空間モデル:コンテキストの強化版
主流のワークフローが、生のLLM呼び出しからエージェントループへと移行するにつれて、コンテキスト学習モデルへのプレッシャーは増大しています。以前は、コンテキストウィンドウが完全に満たされることは比較的まれでした。これは通常、LLMが一連の個別のタスクを完了する必要がある場合に発生し、アプリケーション層がチャット履歴をより直接的に整理・圧縮することを可能にしました。
しかし、エージェントにとって、単一のタスクが利用可能なコンテキストの大部分を消費してしまう可能性があります。エージェントのループの各ステップは、前のイテレーションから渡されたコンテキストに依存します。さらに、コンテキストが乱雑になり、一貫性が低下し、収束が失敗するため、「スレッドが壊れる」ことで、20~100ステップ後に失敗することがよくあります。
そのため、主要なAI研究所は現在、極めて長いコンテキストウィンドウを持つモデルの開発に多額の投資(すなわち、大規模なトレーニング実行)を行っています。これは、既に効果的な手法(コンテキスト学習)に基づいており、推論時計算への業界全体の傾向とも合致しているため、自然な流れと言えます。最も一般的なアーキテクチャは、通常の注意ヘッド、すなわち状態空間モデル(SSM)と線形注意バリアント(以下、総称してSSMと呼ぶ)の間に固定メモリ層を挟み込むものです。SSMは、長いコンテキストのシナリオにおいて、根本的に優れたスケーリング曲線を提供します。
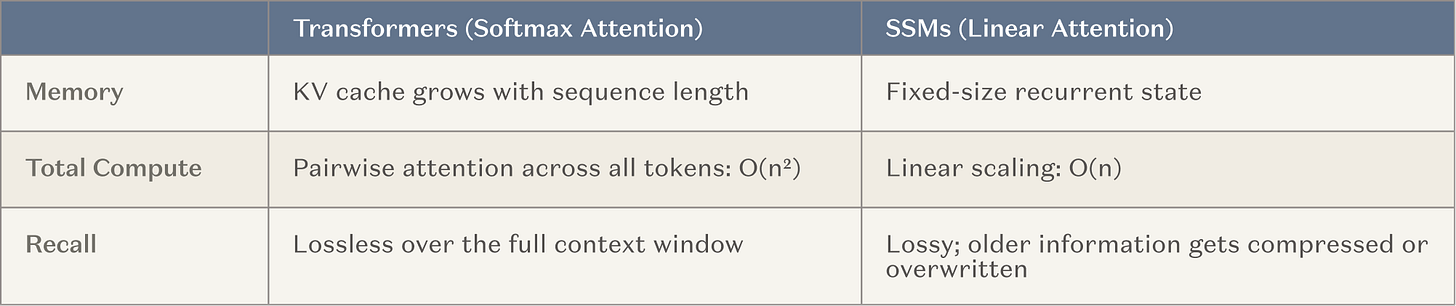
キャプション:SSMと従来のアテンションメカニズムのスケーリングの比較
目標は、従来のトランスフォーマーが提供する高度なスキルと知識を損なうことなく、エージェントが連続して実行できるステップ数を、約20ステップから約20,000ステップへと数桁増加させることです。これが成功すれば、長時間実行型エージェントにとって大きなブレークスルーとなるでしょう。
このアプローチは、継続的学習の一形態と考えることもできます。モデルの重みは更新されませんが、リセットをほとんど必要としない外部メモリ層が導入されます。
したがって、これらのノンパラメトリック手法は実用的で強力です。継続的学習の評価は、ここから始めなければなりません。問題は、今日のコンテキストシステムが有用かどうかではなく(確かに有用です)、私たちは限界に達したのか、そして新しい手法によってさらに前進できるのか、ということです。
文脈から抜け落ちているもの:「ファイリングキャビネットの誤謬」
「汎用人工知能(AGI)と事前学習に関して言えば、ある意味で行き過ぎていると言えるでしょう。人間はAGIではありません。確かに人間にはスキルベースがありますが、膨大な知識が欠けています。私たちが頼りにしているのは、継続的な学習なのです。」
もし私が超知能の15歳児を作り出したとしたら、彼は何も知らない。優秀な生徒で、学ぶ意欲に満ちている。プログラマーになりたいとか、医者になりたいとか言えるだろう。展開自体が学習と試行錯誤のプロセスを伴う。それはプロセスであり、完成品をただ捨てるだけではない。—イリヤ・サツケバー
無限のストレージ容量を持つシステムを想像してみてください。世界最大のファイルキャビネットで、あらゆる事実が完璧にインデックス化され、瞬時に検索できます。何でも見つけることができます。では、このシステムは何かを学んだのでしょうか?
いいえ。強制的に圧縮されたことは一度もありません。
これが私たちの議論の核心であり、イリヤ・スツケバー氏が以前指摘した点を引用すると、LLM(損失損失モデル)は本質的に圧縮アルゴリズムであるということです。学習中、LLMはインターネットをパラメータに圧縮します。圧縮は非可逆的であり、まさにこの非可逆性こそがLLMの強力な点なのです。圧縮によってモデルは構造を見つけ、一般化し、様々な状況で応用できる表現を構築することを強いられます。すべての学習サンプルを記憶するモデルは、根底にあるパターンを抽出するモデルよりも効果が低いのです。非可逆圧縮自体が学習の一形態と言えるでしょう。
皮肉なことに、トレーニング中にLLMを非常に強力なものにするメカニズム(生データをコンパクトで転送可能な表現に圧縮する)こそが、展開後に継続させることを拒否するまさにそのメカニズムなのです。私たちはリリースと同時に圧縮を停止し、外部メモリに置き換えました。
もちろん、ほとんどのエージェントシェルは独自の方法でコンテキストを圧縮します。しかし、苦い教訓から、モデル自体がこの圧縮を直接的かつ大規模に学習すべきだと私たちは考えているのではないでしょうか?
ユ・スンはこの議論を説明するために、数学を例に挙げた。フェルマーの最終定理を考えてみよう。350年以上もの間、どの数学者もそれを証明できなかった。それは正しい資料が不足していたからではなく、その解法があまりにも斬新だったからだ。既存の数学的知識と最終的な答えとの概念的な隔たりが大きすぎたのである。
アンドリュー・ワイルズが1990年代にようやくこの謎を解き明かしたとき、彼は7年間ほぼ孤立した状態で研究を続け、答えにたどり着くために全く新しい手法を考案しなければならなかった。彼の証明は、楕円曲線とモジュラー形式という2つの異なる数学分野をうまく結びつけることに基づいていた。ケン・リベットは、このつながりを確立すればフェルマーの最終定理が自動的に解決されることを既に証明していたが、ワイルズ以前には、実際にこの橋渡しをするための理論的ツールを持った者はいなかった。グリゴリー・ペレルマンによるポアンカレ予想の証明も、同様の方法で証明できる。
核心的な疑問は、これらの事例はLLMに何かが欠けていること、つまり既存の知識を更新し、真に創造的な思考を行う能力が欠けていることを証明しているのか、それとも実際には正反対の結論、つまり人間の知識はすべて訓練や再編成が可能な単なるデータであり、ワイルズとペレルマンはLLMがより大規模なスケールで何ができるかを示したに過ぎない、という点である。
これは経験的な問題であり、答えはまだ不明確です。しかし、今日では多くの種類の問題に対して文脈学習がうまく機能しない一方で、パラメトリック学習は有用である可能性があることは分かっています。例えば、次のとおりです。

キャプション:文脈学習が失敗し、パラメータ学習が成功する可能性のある問題のカテゴリ。
さらに重要なことに、文脈学習は言語で表現できるものしか扱えないのに対し、重み付けは手がかりとなる単語では伝えられない概念を符号化できる。一部のパターンは、次元が高すぎたり、暗黙的すぎたり、構造が深すぎたりして、文脈に当てはめることができない。例えば、医療スキャンで良性アーティファクトと腫瘍を区別するために使用される視覚的なテクスチャや、話者の独特なリズムを定義する微妙な音声の変動は、正確な言葉に分解するのは容易ではない。
言語はそれらを近似的にしか表現できない。プロンプトがどれほど長くても、これらの情報を伝えることはできない。この種の知識は重みの中にしか存在し得ない。それらは言葉ではなく、学習された表現の潜在空間に存在する。コンテキストウィンドウがどれほど大きくなっても、テキストでは記述できず、パラメータによってのみ伝達できる知識が必ず存在する。
これは、ChatGPTのメモリ機能のような、明示的な「ボットがあなたを記憶します」機能が、ユーザーを喜ばせるどころか不快にさせる理由を説明できるかもしれません。ユーザーが本当に求めているのは「記憶」ではなく「能力」です。ユーザーの行動パターンを内面化したモデルは、新しいシナリオにも応用できますが、単に過去の記録を思い出すだけのモデルはできません。「これはあなたがこのメールに最後に返信した際に書いた内容です」(逐語的な再現)と「私はあなたの思考プロセスを十分に理解しているので、あなたのニーズを予測できます」の違いは、検索と学習の違いです。
継続学習を始める
継続学習には複数の方法があります。その境界線は、記憶機能の有無ではなく、圧縮が行われる場所にあります。これらの方法は、圧縮なし(純粋な検索、重みの固定)から完全な内部圧縮(重みレベル学習、モデルがより賢くなる)まで、連続的なスペクトル上に分布しており、その中間には重要な領域(モジュール)が存在します。
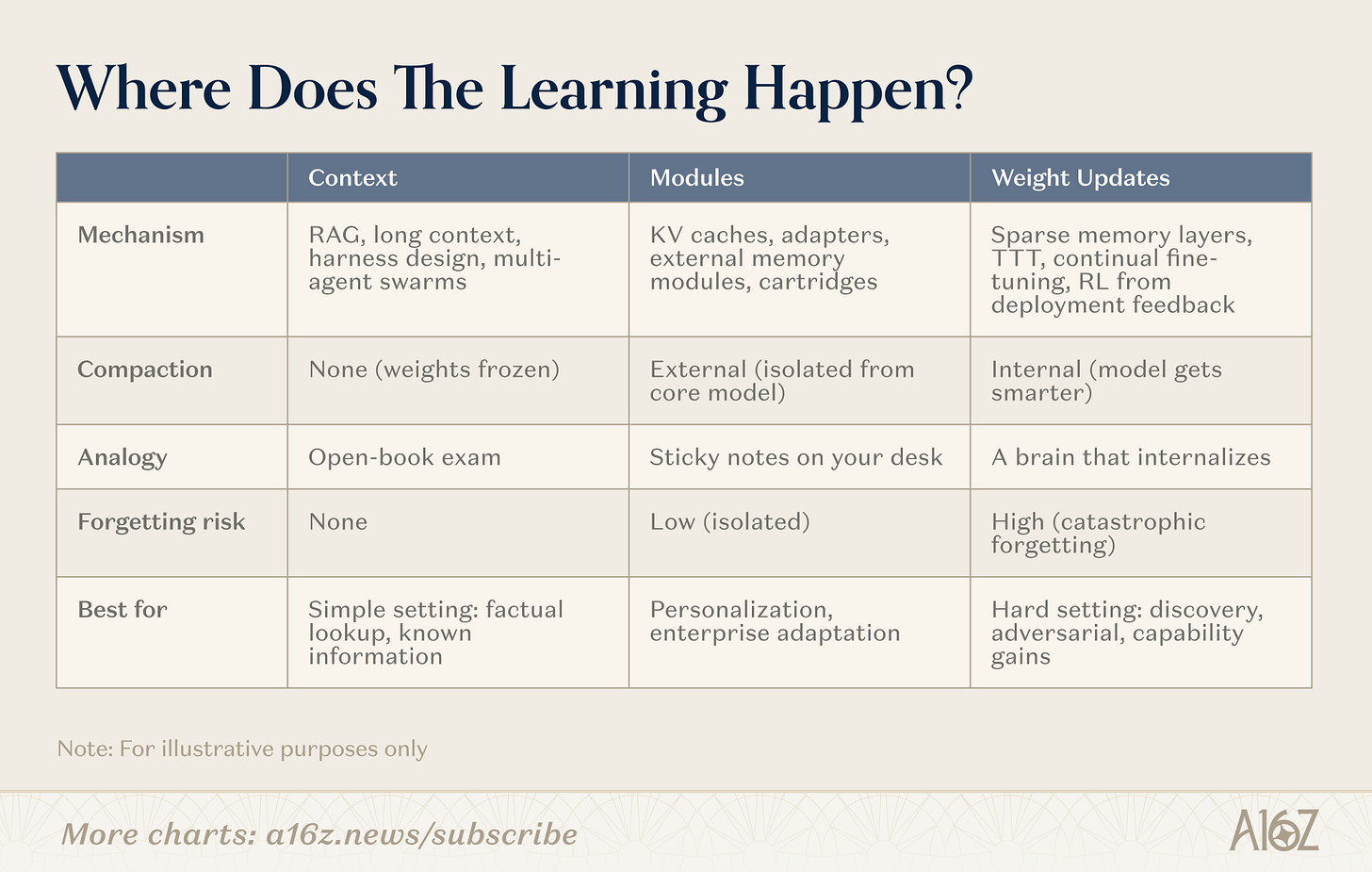
キャプション:継続的な学習への3つの道筋 ― 文脈、モジュール、そして重み。
コンテクスト
コンテキストに関しては、チームはより高度な検索パイプライン、エージェントシェル、およびキューワードオーケストレーションを構築しています。これは最も成熟した分野であり、インフラストラクチャは実証済みで、導入パスも明確です。制約は深度、つまりコンテキストの長さにあります。
注目すべき新たな方向性として、コンテキスト自体のスケーリング戦略としてのマルチエージェントアーキテクチャが挙げられます。単一のモデルが128Kトークンのウィンドウに限定されている場合、それぞれが独自のコンテキストを持ち、問題の一部に焦点を当て、結果を相互に伝達するエージェントの協調的な群れは、全体として無限のワーキングメモリに近づくことができます。各エージェントは自身のウィンドウ内でコンテキストを学習し、システムはそれを集約します。Karpathy氏の最近の自動研究プロジェクトや、Cursor社によるWebブラウザ構築の例は、その初期の事例です。これは(重みを変更しない)完全に非パラメトリックなアプローチですが、コンテキストベースのシステムが達成できる上限を大幅に引き上げます。
モジュール
モジュール空間内で、チームはプラグイン可能な知識モジュール(圧縮キーバリューキャッシュ、アダプタ層、外部メモリストレージ)を構築し、汎用モデルが再学習なしで特化できるようにしています。適切なモジュールを備えた8Bモデルは、メモリ使用量をわずか数パーセントに抑えながら、対象タスクにおいて109Bモデルと同等のパフォーマンスを発揮できます。その魅力は、既存のTransformerインフラストラクチャとの互換性にあります。
重さ
重み更新の面では、研究者たちは真のパラメータレベル学習を追求している。関連するパラメータ断片のみを更新するスパースメモリ層、フィードバックに基づいてモデルを最適化する強化学習ループ、推論時にコンテキストを重みに圧縮するテスト時トレーニングなどだ。これらは最も高度な手法であり、実装も最も難しいが、モデルが新しい情報やスキルを完全に内面化することを可能にする。
パラメータ更新には様々な具体的なメカニズムが存在する。以下にいくつかの研究方向を示す。
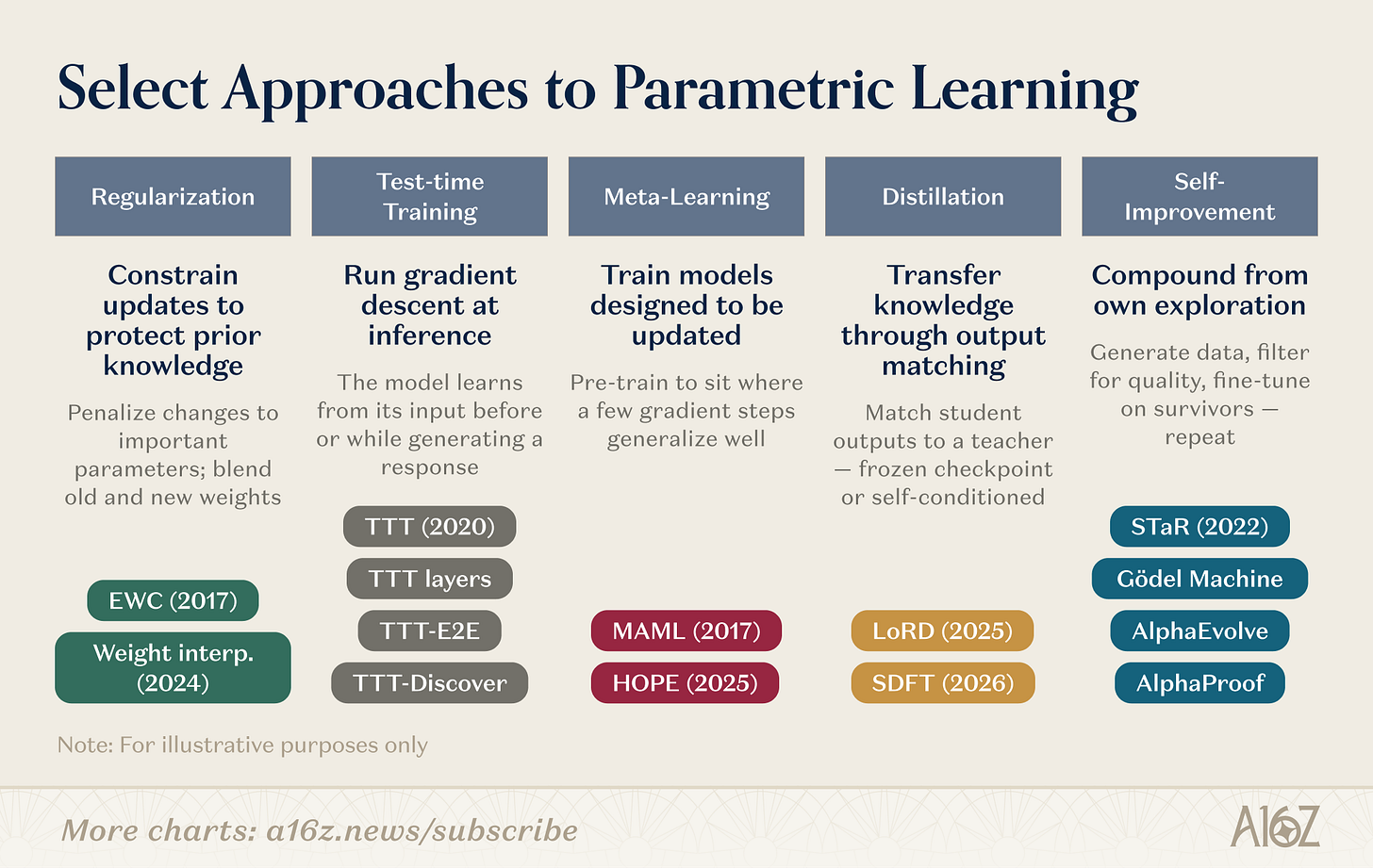
キャプション:加重学習における研究方向の概要
重み付きシステムの研究は、複数の並行アプローチを包含しています。正則化と重み空間法は最も長い歴史を持ち、EWC(Kirkpatrick et al., 2017)は、以前のタスクにおける重要度に基づいてパラメータの変動にペナルティを課します。重み付き補間(Kozal et al., 2024)は、パラメータ空間で新しい重み構成と古い重み構成を混合しますが、どちらも大規模な場合には比較的脆弱です。
テスト中のトレーニングはSunら(2020)によって先駆的に行われ、その後、まったく異なるアプローチでアーキテクチャの基本要素(TTTレイヤー、TTT-E2E、TTT-Discover)へと発展しました。そのアプローチとは、テストデータに対して勾配降下法を実行し、必要な時点で新しい情報をパラメータに圧縮するというものです。
メタ学習は、「学習方法を知っている」モデルを訓練できるか、という問いを投げかけます。MAML(Finn et al., 2017)の少数のショットでパラメータを初期化する手法から、Behrouz et al.(Nested Learning, 2025)のネスト学習まで、後者はモデルを階層的な最適化問題として構造化し、生物学的記憶の統合に触発されて、異なる時間スケールで素早く適応し、ゆっくりと更新するモジュールを実行します。
蒸留法は、生徒モデルが固定された教師チェックポイントと一致するようにすることで、以前のタスクの知識を保持します。LoRD(Liu et al., 2025)は、モデルとリプレイバッファを同時に剪定することで、蒸留法を継続的に実行できるほど効率的にします。自己蒸留法(SDFT、Shenfeld et al., 2026)は、ソースを反転させ、専門家の条件下でのモデル自身の出力をトレーニング信号として使用することで、逐次微調整による壊滅的な忘却を回避します。
再帰的な自己改善は同様のアイデアに基づいて動作します。STaR(Zelikman et al., 2022)は、自己生成された推論チェーンから推論能力を導きます。AlphaEvolve(DeepMind、2025)は、数十年間改善されていないアルゴリズムの最適化を発見します。SilverとSuttonの「経験の時代」(2025)は、エージェント学習を終わりのない継続的な経験の流れとして定義しています。
これらの研究方向は収束しつつあります。TTT-Discoverは、テスト時のトレーニングと強化学習による探索を統合しています。HOPEは、高速学習ループと低速学習ループを単一のアーキテクチャ内にネストしています。SDFTは、蒸留を基本的な自己改善操作へと変えています。各分野の境界は曖昧になりつつあります。次世代の継続的学習システムは、安定化のための正則化、加速のためのメタ学習、そして複利効果のための自己改善といった複数の戦略を組み合わせる可能性が高いでしょう。ますます多くのスタートアップ企業が、この技術スタックの様々なレイヤーに投資しています。
起業家を取り巻く環境を継続的に学習する
非パラメトリックな側面はよく知られています。シェルカンパニー(Letta、mem0、Subconsciousなど)は、コンテキストウィンドウに配置されたコンテンツを管理するためのオーケストレーションレイヤーとスキャフォールディングを構築します。外部ストレージとRAGインフラストラクチャ(Pinecone、xmemoryなど)が、データ取得の基盤を提供します。データは存在しますが、課題は適切なタイミングで適切なスライスをモデルの前に配置することです。コンテキストウィンドウが拡大するにつれて、これらの企業の設計空間も拡大し、特にシェルサイドでは、ますます複雑化するコンテキスト戦略を管理するために、新たなスタートアップの波が生まれています。
パラメータはより早期に、より多様化している。この企業は、モデルが重みの中に新しい情報を組み込めるようにする「展開後圧縮」の手法を実験的に導入している。展開後にモデルがどのように学習すべきかという点に関して、いくつかの異なるアプローチに大別できる。
部分圧縮:再学習なしの学習。一部のチームは、汎用モデルがコアウェイトを変更することなく特化できるように、プラグイン可能な知識モジュール(圧縮キーバリューキャッシュ、アダプタレイヤー、外部メモリストレージ)を構築しています。共通の主張は、学習がパラメータ空間全体に分散されるのではなく、分離されているため、安定性と可塑性のトレードオフを管理可能な範囲に抑えながら、意味のある圧縮(単なる検索ではなく)を実現できるということです。適切なモジュールを備えた8Bモデルは、対象タスクにおいて、はるかに大規模なモデルのパフォーマンスに匹敵することができます。利点は構成可能性です。モジュールは既存のTransformerアーキテクチャに簡単に組み込むことができ、独立して交換または更新でき、実験コストは再学習よりもはるかに低くなります。
強化学習とフィードバックループ:シグナルからの学習。一部のチームは、展開後の学習に最も役立つシグナルは、ユーザーによる修正、タスクの成功と失敗、現実世界の結果からの報酬シグナルなど、展開ループ自体の中に既に存在すると考えています。その核心となる考え方は、モデルがすべてのインタラクションを推論要求としてだけでなく、潜在的なトレーニングシグナルとして扱うべきだということです。これは、人間が仕事で上達する方法と非常によく似ています。つまり、仕事をしてフィードバックを得て、どの方法が効果的かを内面化するのです。エンジニアリング上の課題は、疎でノイズが多く、時には敵対的なフィードバックを、壊滅的な忘却を起こさずに安定した重み更新に変換することです。しかし、展開から真に学習するモデルは、コンテキストシステムでは不可能な方法で複利的な価値を生み出すでしょう。
データ中心:適切なシグナルから学習する。関連するものの異なるアプローチとして、ボトルネックは学習アルゴリズムではなく、トレーニングデータと周辺システムにあるという考え方がある。これらのチームは、継続的な更新を促進するために適切なデータを選別、生成、または合成することに重点を置いている。これは、質の高い構造化された学習シグナルを持つモデルであれば、意味のある改善に必要な勾配ステップがはるかに少なくて済むという前提に基づいている。これはフィードバックループ企業と自然に結びつくが、上流の問題を強調している。モデルが学習できるかどうかは一つの問題だが、何をどの程度学習すべきかは別の問題である。
新アーキテクチャ:ゼロから設計された学習機能。最も大胆な主張は、Transformerアーキテクチャ自体がボトルネックであり、継続的な学習には根本的に異なる計算プリミティブ、すなわち連続時間ダイナミクスと組み込みメモリ機構を備えたアーキテクチャが必要だというものです。ここでの主張は構造的なものです。継続的に学習するシステムを望むなら、学習メカニズムを基盤となるインフラストラクチャに組み込むべきです。

キャプション:継続学習型スタートアップの現状
主要な研究機関はすべて、これらの分野で積極的に活動を展開している。コンテキスト管理や思考連鎖推論の改善に取り組む研究機関もあれば、外部メモリモジュールやスリープ時間計算パイプラインの実験を行う研究機関もあり、また、少数の秘密裏に活動する企業は新たなアーキテクチャの開発を進めている。この分野はまだ黎明期にあるため、現時点で決定的な成功を収めたアプローチは存在せず、ユースケースの幅広さを考えると、勝者は一つだけではないはずだ。
単純な重み更新が失敗する理由は?
本番環境でモデルパラメータを更新すると、現在大規模に解決されていない一連の障害モードが引き起こされる可能性があります。

キャプション:単純な重み更新の失敗モード
工学上の問題点は十分に文書化されている。壊滅的忘却とは、新しいデータから学習できるほど感度の高いモデルが、既存の表現を破壊してしまう可能性があることを意味する。これは安定性と可塑性のジレンマである。時間的分離とは、不変ルールと可変状態が同じ重みセットに圧縮され、一方を更新すると他方が破損してしまう状態を指す。論理的統合は、事実の更新が推論に伝播しないために失敗する。変更はトークンシーケンスレベルに限定され、意味概念レベルには及ばない。学習の消去は依然として不可能である。微分可能な減算演算が存在しないため、誤った知識や有害な知識を正確に外科的に除去する手法は存在しない。
あまり注目されていないもう一つの問題があります。現在のトレーニングとデプロイメントの分離は、単なる技術的な便宜のためではなく、セキュリティ、監査可能性、ガバナンスの境界を表しています。この境界を開放すると、複数の問題が同時に発生する可能性があります。セキュリティの整合性は予測不能な形で低下する可能性があり、無害なデータに対するわずかな変更でさえ、広範囲にわたる不整合を引き起こす可能性があります。
継続的な更新は、データポイズニング攻撃の標的領域を生み出します。これは、重みの中に潜むヒントの、ゆっくりとした永続的なバージョンです。継続的に更新されるモデルは常に変化するため、バージョン管理、回帰テスト、ワンタイム認証が不可能になり、監査可能性が崩壊します。ユーザー操作がパラメータに圧縮されると、機密情報が表現に組み込まれるため、コンテキストから取得される情報よりもフィルタリングが困難になり、プライバシーリスクが悪化します。
これらは未解決の問題であり、根本的に解決不可能な問題ではありません。これらの問題を解決することは、中核的なアーキテクチャ上の課題に取り組むことと同様に、継続的な学習と研究の課題の一部です。
「記憶の断片」から真の記憶へ
『メメント』におけるレナードの悲劇は、彼が機能不全に陥っていることではない。彼はどの場面でも機転が利き、むしろ聡明だ。彼の悲劇は、知識を積み重ねることができない点にある。あらゆる経験は外部的なものにとどまる――ポラロイド写真、タトゥー、他人の筆跡によるメモなど。彼は情報を引き出すことはできるが、新たな知識を凝縮することはできないのだ。
レナードが自ら作り上げたこの迷宮をさまようにつれ、現実と信念の境界線は曖昧になり始める。彼の病気は単に記憶を奪うだけでなく、絶えず意味を再構築することを強いる。その結果、彼は探偵であると同時に、自らの物語の信頼できない語り手となってしまうのだ。
今日のAIも同じ制約の下で動作しています。私たちは、より長いコンテキストウィンドウ、よりスマートなシェル、協調的なマルチエージェント群など、非常に強力な検索システムを構築し、それらは機能しています。しかし、検索は学習ではありません。あらゆる事実を検索できるシステムは、構造を探すことを強いられません。汎化を強いられることもありません。トレーニングを非常に強力なものにしている、生データを転送可能な表現に変換するメカニズムである非可逆圧縮は、まさにそれを展開した瞬間に無効にしてしまうものなのです。
今後の道筋は、単一の画期的な技術ではなく、階層化されたシステムとなる可能性が高い。コンテキスト学習は、適応型防御の第一線であり続けるだろう。それは、ネイティブで実績があり、常に進化し続けているからだ。モジュール式のメカニズムは、パーソナライゼーションとドメイン特化の中間領域を担うことができる。
しかし、真に困難な問題、例えば発見、敵対的適応、言葉では表現できない暗黙知などについては、モデルが学習後も経験をパラメータに圧縮し続けることを可能にする必要があるかもしれません。これは、疎なアーキテクチャ、メタ学習目標、自己改善ループの進歩を意味します。また、「モデル」の意味を再定義する必要もあるかもしれません。つまり、固定された重みの集合ではなく、記憶、更新アルゴリズム、そして自身の経験から抽象化する能力を含む、進化し続けるシステムとして捉える必要があるでしょう。
ファイルキャビネットはどんどん大きくなっている。しかし、どんなに大きなファイルキャビネットでも、結局はただのファイルキャビネットに過ぎない。ブレークスルーの鍵は、展開後のトレーニングにおいてモデルを強力にする要素、すなわち圧縮、抽象化、そして学習にある。私たちは、記憶喪失のモデルから、かすかな経験の兆しを見せるモデルへと転換する岐路に立っている。さもなければ、私たちは自らの断片的な記憶に囚われ続けることになるだろう。


