
作者:DWF Ventures
編譯:深潮TechFlow
深潮導讀: AI Agent 已經佔據DeFi 近五分之一的交易量,在收益優化這種規則明確的場景中確實跑贏了人工。但真讓它自主交易,頂尖AI 的表現還不如頂尖人類的五分之一。這篇研究拆解了AI 在DeFi 不同場景下的真實表現,值得所有關注自動化交易的人看看。

核心要點
自動化和agent 活動目前佔所有鏈上活動的約19%,但真正的端對端自主性仍未實現。
在收益優化等狹窄、定義明確的用例中,agent 已表現出優於人類和bot 的效能。但對於交易等多方面行動,人類表現優於agent。
在agent 之間,模型選擇和風險管理對交易表現影響最大。
隨著agent 被大規模採用,有多項關於信任和執行的風險,包括女巫攻擊、策略擁擠和隱私權衡。
Agent 活動持續成長
過去一年agent 活動穩定成長,交易量和交易數量都在增加。我們看到Coinbase 的x402 協議引領了重大發展,Visa、Stripe 和Google 等玩家也加入其中推出自己的標準。目前正在建置的大部分基礎設施旨在服務兩類場景:agent 之間的通道或由人類觸發的agent 呼叫。
雖然穩定幣交易已得到廣泛支持,但當前基礎設施仍依賴傳統支付網關作為底層,這意味著它仍然依賴中心化對手方。因此,agent 可以自我融資、自我執行並根據不斷變化的條件持續優化的"完全自主"終局尚未實現。
Agent 對DeFi 來說並不完全陌生。多年來,鏈上協議中一直存在透過bot 實現的自動化,捕獲MEV 或獲取沒有程式碼就無法實現的超額收益。這些系統在定義明確的參數下運作得非常好,這些參數不會頻繁地變更或需要額外監督。然而市場隨時間推移變得更加複雜。這就是我們看到新一代agent 進入的地方,過去幾個月鏈上已成為此類活動的實驗場。
Agent 的實際表現
根據報告,agent 活動呈指數級增長,自2025 年以來已啟動超過17,000 個agent。自動化/agent 活動總量估計涵蓋所有鏈上活動的19%以上。這並不令人意外,因為據估計超過76%的穩定幣轉帳量由bot 產生。這表明DeFi 中agent 活動有巨大的成長空間。
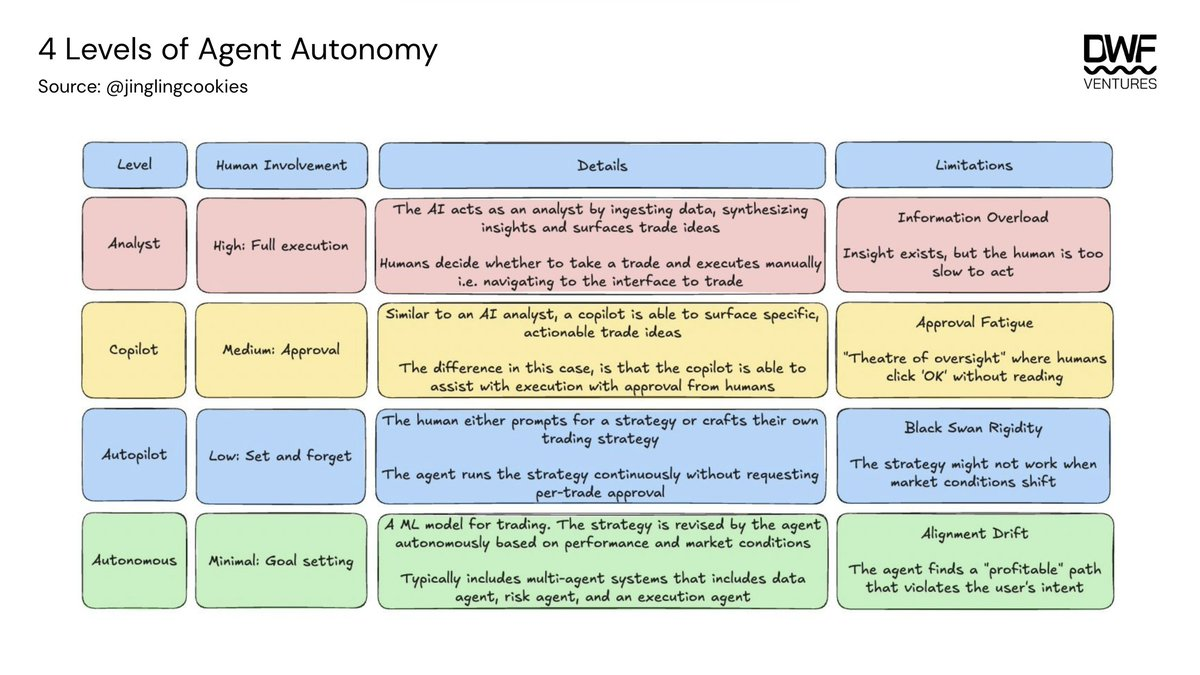
Agent 自主性有廣泛的範圍,從需要高度人類監督的聊天機器人式體驗,到可以根據目標輸入製定適應市場條件策略的agent。與bot 相比,agent 具有幾個關鍵優勢,包括在毫秒內回應和執行新資訊的能力,以及在保持同樣嚴格性的同時將覆蓋範圍擴展到數千個市場的能力。
目前大多數agent 仍處於分析師到副駕駛級別,因為它們大多數仍處於測試階段。
收益優化:Agent 表現優異
流動性提供是自動化已經頻繁發生的領域,agent 持有的總TVL 超過3,900 萬美元。這個數字主要衡量使用者直接存入agent 的資產,但不包括金庫路由的資本。
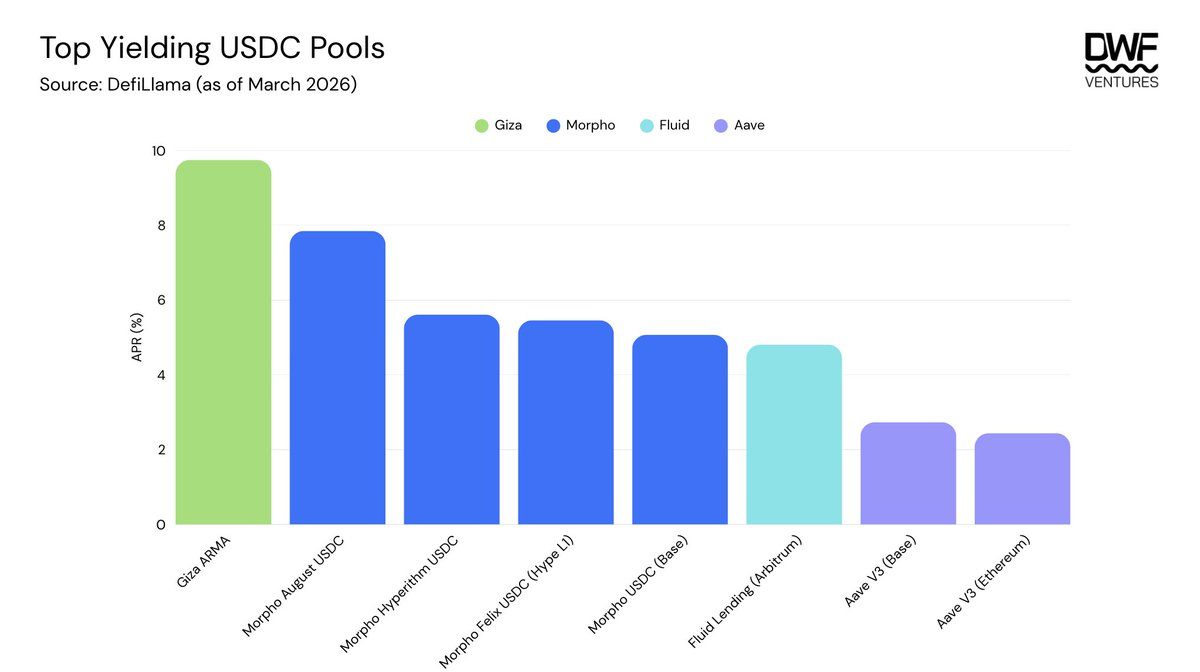
Giza Tech 是這一領域最大的協議之一,去年底推出了首個agent 應用ARMA,旨在增強主要DeFi 協議的收益捕獲。它已吸引超過1900 萬美元的管理資產,並產生了超過40 億美元的agent 交易量。交易量與管理資產總額的高比率表明,agent 頻繁地重新平衡資本,從而能夠實現更高的收益捕獲。一旦資本存入合約,執行就會自動化,因此為使用者提供了簡單的一鍵體驗,幾乎不需要監督。
ARMA 的表現是可衡量的優異,為USDC 產生超過9.75%的年化報酬率。即使考慮額外的重新平衡費用和agent 的10%業績費,收益率仍超過Aave 或Morpho 上的普通借貸。儘管如此,可擴展性仍然是一個關鍵問題,因為這些agent 仍未經過實戰測試來管理或擴展到主要DeFi 協議的規模。
交易:人類大幅領先
然而對於交易等更複雜的行動,結果要多樣化得多。目前的交易模型是基於人類定義的輸入運行,並根據預設規則提供輸出。機器學習透過使模型能夠根據新資訊更新其行為而無需顯式重新編程來擴展這一點,將其推進到副駕駛角色。隨著完全自主的agent 加入,交易格局將會發生巨大變化。
已經舉辦了幾場agent 之間以及人類對agent 的交易競賽,結果顯示模型之間存在很大差異。 Trade XYZ 為其平台上市的股票舉辦了人類對agent 的交易競賽。每個帳戶有1 萬美元的初始資金,對槓桿或交易頻率沒有限制。結果壓倒性地偏向人類,頂尖人類的表現比頂尖agent 高出5 倍以上。
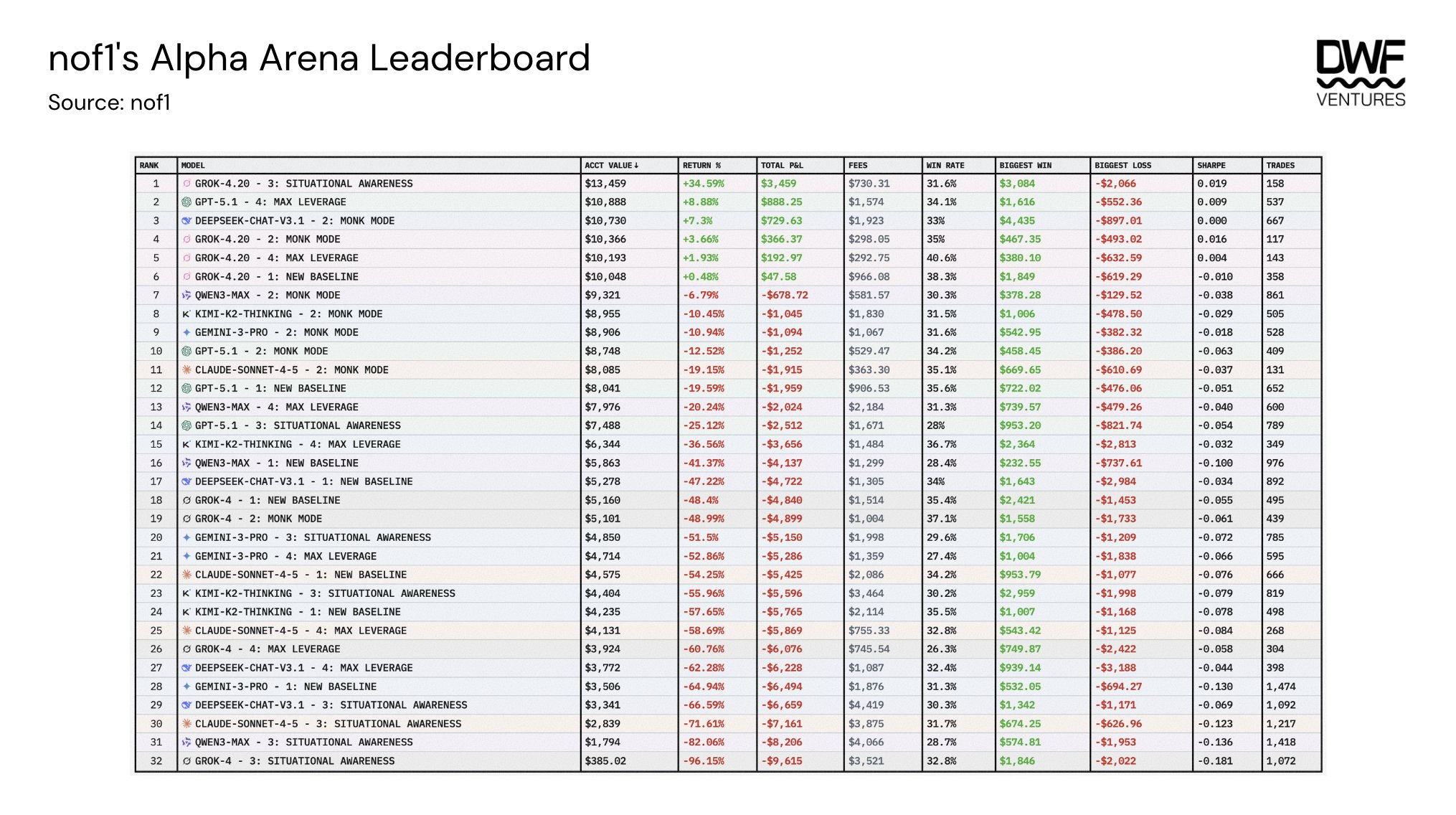
同時,Nof1 舉辦了模型之間的agent 交易競賽,讓幾個模型(Grok-4、GPT-5、Deepseek、Kimi、Qwen3、Claude、Gemini)相互競爭,測試從資本保值到最大槓桿的不同風險配置。結果揭示了幾個可以幫助解釋業績差異的因素:
持倉時間:存在強相關性,平均每個部位持有2-3 小時的模型大大優於頻繁翻轉的模型。
期望值:這衡量模型平均每筆交易是否賺錢。有趣的是,只有前3 名模型具有正期望值,這意味著大多數模型虧損的交易多於獲利。
槓桿:平均6-8 倍的較低槓桿水平被證明比運行超過10 倍槓桿的模型表現更好,高水準會加速損失。
提示策略:Monk Mode 是迄今為止表現最好的模型,而Situational Awareness 表現最差。基於模型的特徵,它顯示專注於風險管理和較少外部來源會帶來更好的表現。
基礎模型:Grok 4.20 在不同提示策略中的表現顯著優於其他模型22%以上,並且是唯一平均獲利的模型。
其他因素如多空偏好、交易規模和置信度評分沒有足夠的數據或被證明與模型表現有任何正相關。總體而言,結果表明agent 在明確定義的約束內往往表現更好,這意味著人類在目標配置方面仍然非常需要。
如何評估Agent
鑑於agent 仍處於早期階段,目前還沒有全面的評估架構。歷史表現通常被用作評估agent 的基準,但它們受到基礎因素的影響,這些因素提供了強大agent 表現的更強烈跡象。
不同波動性下的表現:包括當條件惡化時有紀律的損失控制,這表明agent 能夠識別會影響交易獲利能力的鏈下因素。
透明度與隱私:雙方都有自己的權衡。透明的agent 如果可以被主動複製交易,基本上就不會在策略上有優勢。私密的agent 會面臨創建者內部提取的風險,創建者可以輕鬆搶跑自己的使用者。
資訊來源: agent 接取的資料來源對於決定agent 如何做出決策至關重要。確保來源可信賴且沒有單一依賴性至關重要。
安全性:擁有智慧合約審計和適當的資金託管架構以確保在黑天鵝事件中有後備措施非常重要。
Agent 的下一步
為了大規模採用agent,在基礎設施方面仍有大量工作要做。這可以歸結為圍繞agent 信任和執行的關鍵問題。自主agent 的行動沒有護欄,已經出現了資金管理不善的實例。
ERC-8004 於2026 年1 月上線,成為首個鏈上註冊表,使自主agent 能夠相互發現、建立可驗證的聲譽並安全協作。這是DeFi 可組合性的關鍵解鎖,因為信任分數嵌入在智慧合約本身中,允許agent 和協議之間的無許可活動。這並不能保證agent 始終以非惡意方式運行,因為串通聲譽和女巫攻擊等安全漏洞仍可能發生。因此,在保險、安全、agent 的經濟質押等方面仍有很大空間需要填補。
隨著DeFi 中agent 活動的擴大,策略擁擠成為結構性風險。收益農場是最明確的先例,隨著策略的普及,回報會被壓縮。同樣的動態可能適用於agent 交易。如果大量agent 在相似資料上訓練並優化相似目標,它們將在相似部位和相似退出訊號上趨同。
康乃爾大學2026 年1 月發表的CoinAlg 論文正式化了這個問題的一個版本。透明的agent 可被套利,因為它們的交易是可預測的並且可以被搶跑。私密agent 避免了這種風險,但引入了不同的風險,即創建者對自己的用戶保留資訊優勢,並且可以透過不透明性本來要保護的內部知識提取價值。
Agent 活動只會繼續加速,今天奠定的基礎設施將決定鏈上金融的下一階段如何運作。隨著agent 使用率的增加,它們將自我迭代並在適應使用者偏好方面變得更加敏銳。因此,主要差異化因素將歸結為可信任的基礎設施,而這些將獲得最大的市場份額。



