
本文將介紹以下內容:
一個基於TurboGeth 的操作碼追踪器能夠以每秒28 個區塊的速度處理並導出EVM 層面的事務詳情。一個腳本可以根據事務執行的基本塊計算出固定大小分塊的默克爾化結果。
ConsenSys 的TeamX 團隊正在研究其它主題,因此我們希望這些工具能夠對社區有用。
默克爾化:問題陳述
無狀態以太坊的基本思路之一是使用了狀態見證數據(witeness)。見證數據會為客戶端提供足夠的狀態用以執行區塊,無需更多狀態信息。
見證消息需要盡可能小,因此減少見證消息的大小是當務之急。見證消息的大小主要受到合約代碼的影響。這就是我們採用代碼默克爾化的原因:使用多種不同的策略將合約代碼拆分成較小的部分,這樣就可以只將必要的部分包括在見證消息內。
這些代碼塊仍需由無狀態客戶端驗證,因此它們會附帶結構化數據(默克爾證明),讓客戶端能夠確保其收到的代碼與全狀態中包含的代碼相同。
合約行為、分塊策略、默克爾證明和見證消息大小之間的相互作用讓人難以決定什麼是代碼默克爾化的最佳方法。
在本文中,我們將探索最簡單的分塊策略:固定大小分塊。所謂的固定大小分塊,就是將合約拆分成固定大小的部分,其中唯一的變量就是分塊大小。
鑑於EVM 行為的特殊性,以及其它文章中的相關討論(見文末《通過EVM 代碼默克爾化縮減見證數據大小》),這些分塊可能還需要一些元數據,以便無狀態客戶端辨別分塊中的一些字節碼是否存在於完整合約的PUSHDATA 內。
結果
請注意:開銷結果是非常不可靠的。 Python 工具存在缺陷,並且正在改進中。
我們已經在超過50 萬個主網交易區塊(從第900 萬個區塊向後)的痕跡上運行了我們自己的默克爾化腳本。我們得出的主要結論是:
現實世界交易的基本塊(basic block)的平均長度約為16,統計分佈嚴重偏向小型基本塊。分塊之間的距離越近,證明哈希的分攤程度越高/構建多重證明(multiproof)所必需的哈希值就越少。 N 個連續的分塊所需的哈希值數量<= 一個分塊所需的哈希值數量。以下開銷數據都是在50 萬個區塊上運行默克爾化流程得出的結果,但是在1000 個區塊上運行下來的結果相同,並且穩定在±1% 的範圍內。
默克爾化開銷取決於分塊中包含的合約字節(即使這些合約字節沒有使用),以及這些分塊的多重證明的哈希值所使用的字節:
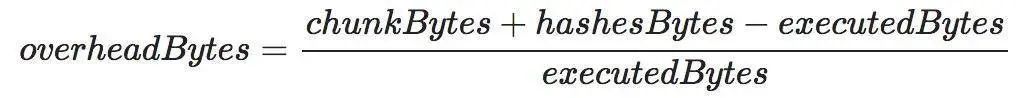
工具
基於TurboGeth 的操作碼追踪器
我們使用Go 語言創建了一個基於TurboGeth 的追踪器,該追踪器能夠從EVM 內的交易執行中提取任意跟踪數據。截至發稿時,TurboGeth 每秒可(在AWSi3.xlarge 類型的實例上)處理超過28 個區塊;我們的追踪器顯示瞭如何在收集跟踪數據時對其進行處理,並以最低的延遲提取這些數據,這主要取決於待導出數據的數量。這就意味著,在大約12 小時內可以提取100 萬個區塊的信息,在一周不到的時間裡可以提取主網上的全部歷史記錄。
鑑於我們的追踪器與TurboGeth 緊密連接,如果TurboGeth 繼續加快速度,我們的追踪器也會自動加快速度。
舉一個具體的例子,探測EVM 運行的連續代碼段(即,基本塊)以及將這些數據導出成記錄各種元數據的JSON 文件是以每秒20 個區塊以上的速度完成的。
這個速度,再加上部分流程是在一開始就完成的,減少了“為以防萬一” 而收集額外數據的需求。這樣可以簡化後續流程,並極大提高研究項目迭代的靈活性。
我們認為這部分代碼依然是有用的,但是對於其它項目來說,自定義流程類型和導出數據類型是一個很好的切入點。追踪器已經整合進了TurboGeth。
之前的方法由於數據收集緩慢,需要為中間步驟存儲大量數據,從而產生使用門檻。相比之下,基於TurboGeth 的追踪器能夠有效降低准入壁壘。我們希望它可以促進以太坊研究項目更快速迭代,同時也讓其它團隊能夠使用其結果。
當然了,我們希望你能仔細檢查我們的結果。
實現主網交易痕跡默克爾化的腳本
我們編寫了一個工具,使用操作碼追踪器的輸出和分塊大小來計算每個區塊的默克爾化代碼見證數據,以此收集每筆交易、每個區塊、每批交易和全局層面的統計數據。這些統計數據是我們了解現實世界交易的運行時特徵的關鍵。
32 字節分塊的輸出如下所示:
Block 9904995: segs=816 median=14 2▁▃▁▃▅▄▆█▂▂▄▂▄26 (+29% more)Block 9904995: overhead=42.4% exec=12K merklization= 16.6 K = 15.6 + 1.0 KBlock 9904996 : segs=8177 median=18 2▁▂▁▄█▄▆▄▃▅▃▃▄▁▂▂▂34 (+24% more)Block 9904996: overhead=34.1% exec=101K merklization= 136.0 K = 135.1 + 0.9 KBlock 9904997: segs=14765 median=14 2▁▂▂▄█▃▆▄▃▃▂▄▂26 (+25% more)Block 9904997: overhead=31.5% exec=106K merklization= 139.8 K = 139.0 + 0.8 KBlock 9904998 : segs=20107 median=14 2▁▁▂▄▅▄█▃▃▄▂▂▃26 (+27% more)Block 9904998: overhead=36.4% exec=76K merklization= 103.8 K = 103.0 + 0.8 KBlock 9904999: segs =10617 median=12 2▁▂▃▅▆▅█▄▃▃▂22 (+29% more)Block 9904999: overhead=37.4% exec=59K merklization= 81.4 K = 80.8 + 0.7 Kfile /data/traces2/segments- 9904000.json.gz: overhead=32.1% exec=74493K merklization=98368.4K = 97481.3 K chunks + 887.1 K hashes segment sizes:median=14 2▁▁▂▆█▆█▆▄▄▃▃▃26 (+28% more)running total: blocks=905000 overhead=30.8% exec=65191590K merklization=85278335.0K = 84535640.5 K chunks + 742694.5 K hashes estimated median:15.0該腳本假定的是普通的默克爾樹,其參數數量和哈希大小都是可配置的,但是沒有黃皮書中所定義的特殊節點(分支節點、擴展節點等)。
很期待看到社區將如何使用這些工具!
致謝
非常感謝AlexeyAkhunov 及TurboGeth 團隊中其他成員的遠見卓識和辛勤付出。沒有他們,這一切都是不可能發生的!
(完)
作者: Horacio Mijail
翻譯&校對: 閔敏&阿劍

