
众所周知我是一个GPT爱好者,已经将其融入工作和生活的方方面面。 但GPT也不是万能的,我们需要认清其本质,才能更好使用其能力。强烈推荐特德·姜这篇极具洞察的文章《ChatGPT是网上所有文本的模糊图像》,独特见解发人深省。我总结了3个点,欢迎阅读。
特德·姜,华裔科幻作家,毕业于布朗大学计算机系,其短篇小说《你一生的故事》在2016年被改编成电影《降临》 技术和科幻的双重背景,让其对ChatGPT具有了独特见解。
TL;DR
- ChatGPT是网上所有文本的有损压缩
- 警惕「美丽的模糊」
- 「原创想法的拙劣表达」好于「清晰表达的非原创想法」
1、ChatGPT是网上所有文本的有损压缩
如果将互联网上的所有文本看做是原件,考虑到处理速度和准确度,ChatGPT 实际上是这些文本的有损压缩后一个自然语言交互接口。既然是有损压缩,就会抛弃一些细节,甚至关键信息。
关于有损压缩可能会导致的问题,作者举了一个形象的例子:2013 年德国一家建筑公司复印了一张房子平面图,三个房间都有一个标签来说明其面积:14.13,21.11和17.42平方米。然后在复印件中,所有三个房间都被标记为14.13平方米。
经过调查发现,这台施乐复印机的工作原理是,先把文档扫描为数字图像,然后再进行打印。为了节省空间,扫描为数字图像时使用了一种被称为 jbig2 的有损压缩格式。复印机判断 3 个房间的面积标签非常相似,所以它只存储了其中一个,然后在打印时对所有 3 个房间都重复使用了这一个标签。
施乐复印机使用有损压缩格式而不是无损格式,这本身并不是一个问题 问题是如果只是打印出模糊的照片,每个人都会知道这不是原件的准确复制品,但复印机打印出了清晰但不准确的图片,可能会对使用者产生误导
作者认为,在我们使用 OpenAI 的 ChatGPT 和其他类似大语言模型时,需要对这个例子铭记于心。ChatGPT 保留了万维网上的大部分信息,就像 JPEG 保留了高分辨率图像的大部分信息一样。但是,如果你要寻找精确的比特序列,你无法找到它,你得到的只是一个近似值。
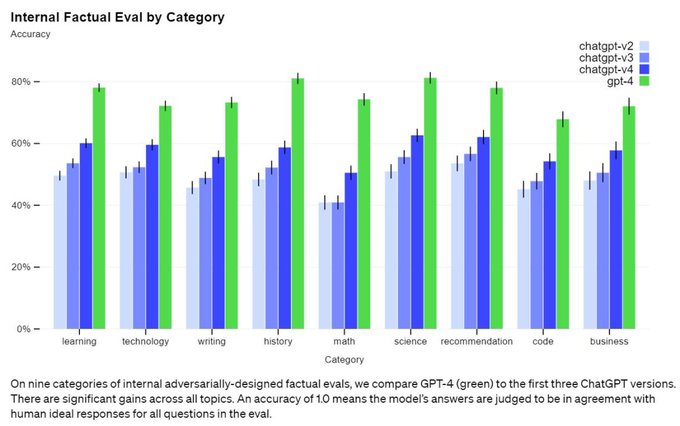
可以看到,在 OpenAI 论文的最新真实性评估中,虽然 GPT-4 比过往模型高很多,但仍然有不低的概率生成错误答案(特别是在科技、代码和商业领域),我们需要小心。
2、警惕「美丽的模糊」
我们对世界的认知,本质上也是对信息的接收和压缩。我们识别和抛弃不重要的信息,留下重要的信息,同时在这个过程中锻炼和使用了决策能力。都是对信息的有损压缩,我们和ChatGPT有何不同? - 我们对信息的压缩,是建立在对事实的理解上,最后留下的是「模糊的正确」 - ChatGPT 并没有真正的「理解」信息,建立在统计规律上输出「美丽的模糊」。 再看 2 个形象的例子:
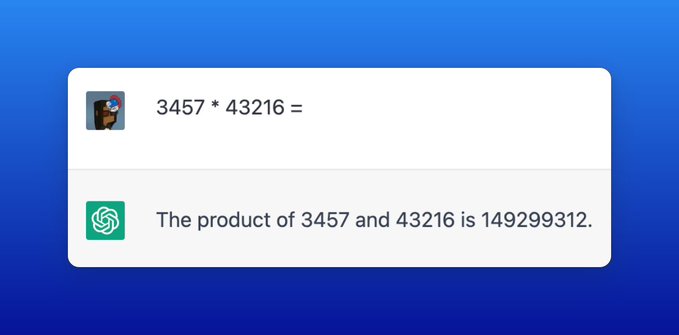
- 如果让 ChatGPT 计算 3457 * 43216,会给出错误答案 149299312(正确答案149397712) 最后一位正确是因为有很多以 6 和 7 结尾数字的乘法让 ChatGPT 学习,但因为其并没有真正理解算术原理,所以最后给出是错误答案。
- 对文本的任何分析都会揭示,“供应不足”这样的短语经常出现在“价格上涨”这样的短语附近 当被问及有关供应不足的问题时, AI可能会给出包含价格上涨的回答。如果AI已经编译了大量经济术语之间的相关性,多到可以对各种各样的问题提供合理的回答,我们是否应该说它实理解了经济理论?显然没有。
ChatGPT 擅长产生美丽的答案,但美丽≠正确。我们必须时刻铭记这一点,ChatGPT 输出的结果可能会漂亮清晰但不准确,要识别它们就需要将它们与原件进行比较,否则就有可能基于瞎编的内容进行错误的决策。下面 bing 产生的这个答案,就是典型的「美丽的模糊」。
3、「原创想法的拙劣表达」好于「清晰表达的非原创想法」
有一种观点,让 ChatGPT 生成的文本作为作家在创作原创作品时的起点,让作者把注意力集中在真正有创意的部分,这样可行吗? 作者认为,以一份模糊的非原创作品作为起点,并不是创作原创作品的好办法。
如果你是一个作家,在你写原创作品之前,你会写很多非原创的作品。花在非原创工作上的时间和精力不会被浪费。相反,正是它让你最终能够创作出原创的作品 花在选择正确的词汇和重新排列句子上的时间,教会了你如何通过文章传达想要表达的意思。
让学生写论文不仅仅是一种测试他们对材料掌握程度的方法,这给了他们表达自己想法的经验。如果学生从来不用写我们都读过的文章,他们就永远不会获得写我们从未读过的东西所需的技能。
那是不是脱离学生身份后,就可以安全地使用 ChatGPT 等大语言模型提供的模板了呢? 然而并不是。想要表达自己想法的挣扎并不会在你毕业后消失。每当你开始起草一篇新文章时,这种挣扎就会出现。有时候,只有在写作的过程中,你才能发现自己最初的想法,这点非常关键。
有些人可能会说,大语言模型的输出看起来与人类作家的初稿没有太大不同,但这只是表面上的相似 你的初稿不是「清晰表达的非原创想法」;它是「原创想法的拙劣表达」,它伴随着你无定形的不满,你意识到它所说的和你想说的之间的距离。
这是在重写时能够指导你的东西,这是当你开始使用人工智能生成的文本时所缺乏的东西。基于「清晰表达的非原创想法」,会很容易让人失去想法;而从「原创想法的拙劣表达」开始,逐步打磨,最终会收获「原创想法的精确表达」,原创可能会成为玉石,非原创只会流于泛滥。
总结 2 点Take Away:
- ChatGPT是网上所有文本的有损压缩,我们必须时刻铭记这一点,警惕把「美丽的模糊」当做准确信息,影响判断和决策
- 2. 在挣扎和拙劣表达中发现「原创想法」,同时提升自己的表达能力,将其打磨成玉石 训练想象力、决策和沟通能力,打造机器无法拥有的竞争力

