
2026年4月末、「Owl Alpha」という匿名モデルが、世界最大級の大規模モデル集約・配信プラットフォーム「OpenRouter」にひっそりと登場した。公式発表もなければ、メディア向け発表会もなく、開発チームの情報すら一切なかった。しかし、その後約2カ月の間に、この謎のモデルは驚異的なスループットでプラットフォームの呼び出し量上位に急浮上した。VentureBeatによると、匿名テスト期間中の月間トークンスループットは約10.1兆に達し、1日平均559Bトークンを処理、前月比242%増を記録したという。6月30日にMeituanが「LongCat-2.0」を正式発表するまで、5万基の国産GPUで訓練された1.6兆パラメータのこの大規模モデルはベールを脱がず、Meituanの公式発表によってOwl Alphaがそのプレビュー版であることが確認され、現在の月間呼び出し量はOpenRouterで世界トップ3に入ると発表された。
LongCat-2.0のMOPDマルチエキスパート融合アーキテクチャの模式図(出典:longcatai.org)
プレビュー版のモデルが海外のデベロッパープラットフォームでこれほど高い呼び出し量を獲得したのは、単一の要因によるものではなく、技術アーキテクチャと配信戦略が相乗的に作用した結果だ。そして、LongCat以前にも、Zhipu AIからXiaomiに至るまで、国産大規模モデルは正式発表前にOpenRouterを通じて「ステルス訓練」を行うことに熱心であるように見える。
Owl Alphaの2カ月:匿名モデルはいかにしてOpenRouterトップ3に食い込んだのか?
LongCat-2.0の高い呼び出し量を理解するには、まず現在の大規模モデルエコシステムにおけるOpenRouterの役割を理解する必要がある。デベロッパーにとって、OpenRouterは統一されたAPIインターフェースを提供し、世界中の数十社の数百ものモデルにアクセスできる。デベロッパーはモデルを選ぶ際、同じプロンプトで異なるモデルの速度、品質、価格を比較することが多い。新たなモデルが登場した際、同価格帯のモデルを凌駕する性能を示したり、破壊的な価格を提示したりすれば、デベロッパーコミュニティでの口コミは非常に速く広がる。
Owl AlphaのOpenRouter上でのブレイクも、まさにこのロジックに従った。Meituanの公式発表によると、Owl AlphaはHermes(エージェントワークスペース)、Claude Code、OpenClawという月間呼び出し量上位3シナリオにおいて、それぞれ1位、2位、3位を獲得した。これら3シナリオの共通点は、エージェント能力への依存度が非常に高いこと、すなわちモデルがコードベースの繰り返し読み込み、複数回のツール呼び出し、長文脈推論を行う必要があることだ。
高い呼び出し量は偶然ではなく、モデル自体のパラメータ規模に加え、特定シナリオへの適合性と非常に攻撃的な価格戦略に起因する。匿名テスト期間中、Owl Alphaは国産コンピューティング基盤を明かさず、純粋に技術性能と価格だけでデベロッパーを魅了した。VentureBeatが報じた10.1兆トークンという月間スループットはメディアによる推定であり、OpenRouterも正確な数値を公式公開していないが、この数字だけでも同モデルがデベロッパーコミュニティで極めて高い実採用率を得ていることを示すには十分だ。この採用率はマーケティング予算で購入したものではなく、実際のAPI呼び出しによって積み上げられたものなのだ。
コードベースをキャッシュに詰め込む:LongCat-2.0はいかにしてエージェントの課金ロジックを書き換えるのか
LongCat-2.0がこれほど膨大な呼び出し量を支えられる核心は、その技術アーキテクチャとビジネス戦略の深い結合にある。Meituanの公式発表によれば、LongCat-2.0の総パラメータ数は1.6兆、平均アクティベーションパラメータは約480億、動的範囲は330億から560億であり、100万トークンの超長文脈をネイティブにサポートする。この1.6Tの総パラメータと48Bのアクティブパラメータを持つMoE(Mixture of Experts)アーキテクチャは、現在の大規模モデルが性能とコストのバランスを取るための主流な選択肢である。
技術アーキテクチャ面では、LongCat-2.0は4つの重要なイノベーションを融合しており、いずれもエージェント開発における具体的なペインポイントを狙っている。
まず、メモリウォール問題を解決するLSA(LongCat Sparse Attention)である。100万トークンの超長文脈を処理する場合、従来のアテンション機構の計算量は二次関数的に増加し、大きなメモリ帯域幅のボトルネックを引き起こす。LSAはStreaming-aware Indexingによって断片化したメモリアクセスを連続ブロック読み出しに変換し、Cross-Layer Indexingによってレイヤー間でのアテンションインデックス再利用を実現し、さらにHierarchical Indexingによって粗粒度から細粒度への二段階フィルタリングを行い、長文テキスト処理の計算量を二次から線形に低減する。これにより、エージェントが大規模なコードベースを読み込む際に直面するメモリウォール問題が解決される。
メモリウォールを解決した次は、計算リソース割り当ての精緻化だ。MoEアーキテクチャでは、すべてのトークンに複雑な計算が必要なわけではない。句読点や機能語などの単純なトークンが複雑なエキスパートネットワークにルーティングされると、計算リソースの浪費につながる。LongCat-2.0はエキスパートプールに「ゼロ計算エキスパート」を追加し、このエキスパートにルーティングされたトークンは入力をそのまま返し、計算リソースを消費しない。システムはPIDコントローラーによってエキスパートバイアスを動的に調整し、平均アクティベーションパラメータを目標範囲内に維持する。これは高速道路に追越車線を設置し、簡単なタスクを速やかに通過させ、計算リソースを複雑な再帰的推論に振り向けるようなものだ。
計算リソース割り当てが最適化されると、次に克服すべきボトルネックは通信遅延となる。ScMoE(Shortcut-connected MoE)はレイヤーを跨ぐショートカット接続を採用し、前のブロックのdense FFN計算と現在のMoEレイヤーのdispatch/combine通信を並列実行する。このパイプライン設計により、理論上のTPOT(Time-Per-Output-Token、1出力トークンあたりの所要時間)は約50%低減され、モデルの応答速度が直接向上する。これは頻繁なインタラクションが必要なエージェントシナリオにとって極めて重要だ。
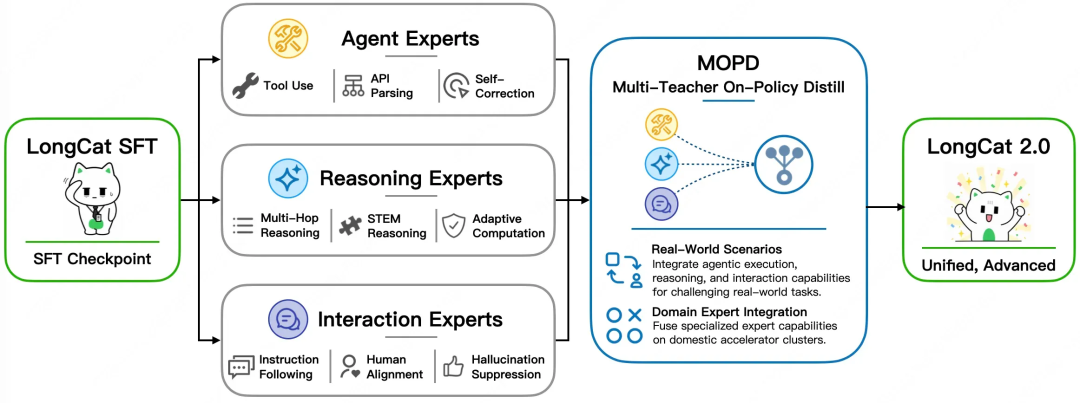
最後に、タスクスケジューリングレベルでのMOPD(Multi-Teacher Optimization via Mixture of Specialized Experts)がある。ポストトレーニング段階において、LongCat-2.0は最適化をAgent、Reasoning、Interactionという3つの専門エキスパートクラスタに分割する。Agent Expertsはツール呼び出しと複数ラウンドのAPIパラメータ解析を担当し、Reasoning Expertsは多段論理や数学的推論を担当し、Interaction Expertsは指示追従とセーフティガードレールを担当する。推論時にはゲートネットワークがタスクタイプに応じて動的にスケジューリングする。つまり、デベロッパーがコードレビューのためにモデルを呼び出す時はAgentエキスパートが、数学的導出を行う時はReasoningエキスパートがアクティベートされる。この分業により、特定タスクにおけるモデルの専門性が高まる。
しかし、技術アーキテクチャはあくまでコスト削減の基盤に過ぎず、デベロッパーのコスト計算ロジックを本当に変えたのはその価格戦略だ。LongCatのAPI価格ページによると、標準価格は入力が100万トークンあたり¥5、出力が100万トークンあたり¥20である。しかし、期間限定割引中は、入力が100万トークンあたり$0.30、出力が100万トークンあたり$1.20に値下がりする。さらに破壊的なのは、その「キャッシュヒット無料」メカニズムだ。
エージェント開発では、モデルは同じコードベースやシステムプロンプトを繰り返し読み込む必要がある。従来の課金モデルでは、これらの重複した入力トークンは毎回費用が発生し、インタラクションのラウンド数に応じてエージェントの運用コストが線形的に増加していた。LongCat-2.0のキャッシュヒット無料メカニズムは、入力のプレフィックス部分がキャッシュにヒットすれば課金されないことを意味する。この設計はエージェントシナリオのコストのペインポイントを直撃しており、多くのデベロッパーから「エージェントのコスト経済学を変える」創挙と見なされている。
LongCat-2.0のコストパフォーマンスをより直感的に理解するために、公開されているエコシステムシグナルに基づいて作成した比較表を以下に示す。
| モデル | ベンダー | SWE-bench Pro スコア | 出力標準価格 ($/Mトークン) | 出力期間限定価格 ($/Mトークン) | オープンソースライセンス | データ集計基準 |
|---|---|---|---|---|---|---|
| Claude Opus 4.8 | Anthropic | 69.2 | $25.00 | なし | クローズドソース | ベンダー自己申告/第三者集計 |
| GLM-5.2 | Zhipu AI | 62.1 | $4.40 | なし | MIT | ベンダー自己申告/第三者集計 |
| Qwen3.7 Max | Alibaba | 60.6 | $3.75 | なし | 一部オープンソース | ベンダー自己申告/第三者集計 |
| LongCat-2.0 | Meituan | 59.5 | $2.95 | $1.20 | MIT | ベンダー自己申告、Scale AI標準化公開ベンチマーク未掲載 |
| MiniMax M3 | MiniMax | 59.0 | $2.40 | なし | オープンソース | ベンダー自己申告/第三者集計 |
| GPT-5.5 | OpenAI | 58.6 | $30.00 | なし | クローズドソース | ベンダー自己申告/第三者集計 |
| DeepSeek V4 Pro Max | DeepSeek | 55.4 | $0.87 | なし | MIT | ベンダー自己申告/第三者集計 |
注意すべき点として、上記の表におけるSWE-bench Proのスコアはすべて各ベンダーの自己申告またはサードパーティが集計したデータであり、モデルによって異なるバッチや評価条件でテストされているため、横断的な比較はあくまでも参考程度にとどめる必要がある。さらに、LongCat-2.0の59.5点は美団の自己申告であり、本稿執筆時点でScale AIの標準化公開ランキングにはまだ掲載されていない。Scaleの標準化公開ランキングでは、GPT-5.4 (xHigh) が59.1%の標準化スコアで首位に立っており、標準化スコアは一般的にベンダーの自己申告より10〜30ポイント低い。それでもなお、LongCat-2.0は期間限定の割引価格である100万トークンあたり1.20ドルに加え、キャッシュ無料の仕組みも相まって、オープンソースモデルにおける価格破壊力は依然として際立っている。
ベンチマーク上位と「プログラミングは期待外れ」:LongCat-2.0の実際の能力限界
ベンダーが公表するベンチマークスコアは往々にして完璧な構図を描き出すが、開発者の実体験はより複雑である。LongCat-2.0はSWE-bench Proで59.5点、SWE-bench Multilingualで77.3点、Terminal-Bench 2.1で70.8点を獲得した。これらの数字は、同モデルがソフトウェアエンジニアリングのベンチマークにおいてオープンソースモデルのトップクラスに位置することを示している。
しかし、Redditのr/LocalLLaMAコミュニティでは、開発者のフィードバックが異なる視点を示している。テスト後に「It's not good in coding, very good in reviews though. Instruction following is also pretty good. A little bit of a waste with that parameter...」(コーディング能力は期待外れで、コードレビューと指示追従は非常に良好。パラメーター規模がやや無駄に感じられる)と述べたユーザーもいる。これは、モデルが汎用的なコード生成タスクにおいて、コードレビューや指示追従タスクほど優れていない可能性があることを反映している。r/SillyTavernAIコミュニティでも、ロールプレイのシナリオにおいてモデルがユーザーの発言を代行しがちで、インタラクション体験に難があるとのフィードバックが寄せられている。
こうしたベンチマークと実体験の乖離は、大規模モデル業界では珍しくない。ベンダー自己申告のスコアは通常、特定のテスト環境とプロンプトの下で得られたものであり、開発者の実際の利用シーンは往々にしてより多様かつ複雑である。LongCat-2.0はMOPDアーキテクチャにおいて、Agent、Reasoning、Interactionの三つの専用エキスパートを特別に設定しており、このことが特定のタスクでの優れたパフォーマンスに繋がる一方、汎用的なプログラミング生成には依然として限界がある可能性がある。
さらに、LongCat-2.0のオープンソース化の約束は、まだ時間をかけた検証が必要である。6月30日のリリース日時点で、HuggingFace上のページではモデルの重みは「coming soon」と表示され、ダウンロードは提供されていない。公式にはMITライセンスを採用し、法人ユーザーに優しくクローズドソースの商用製品への組み込みが可能と発表されているが、重みが実際に提供されるまでは、開発者は依然として様子見の姿勢を崩していない。同時に、謳われている100万トークンの超長文脈における実際の情報保持率についても、Needle-in-a-Haystackのようなテストによる第三者独立検証の公開データが不足している。これらの制約はいずれも、LongCat-2.0の実際の能力限界は、より広範な開発者による実践の中で画定される必要があることを意味している。
PonyからOwlへ:国産大規模モデルはなぜ海外での「フライング公開」に熱心なのか
LongCat-2.0がOwl AlphaとしてOpenRouter上で実施した匿名テストは、孤立した出来事ではない。2026年以降の業界動向を振り返ると、顕著なトレンドが浮かび上がる。国産大規模モデルが正式発表に先立ち、OpenRouter上で匿名プレビューを実施する動きがますます盛んになっているのだ。
2026年2月、OpenRouterに匿名モデル「Pony Alpha」が登場し、後に证券时报などのメディアによりその正体が智譜AIのGLM-5であると確認された。このモデルはプログラミングとAgent最適化に優れ、無料で呼び出しが可能だった。続く3月には、匿名モデル「Hunter Alpha」が現れ、後にXiaomiのMiMo-V2-Proであることが確認された。1Tパラメータと1Mコンテキストを備えている。4月末にはOwl Alphaが登場し、これが美団のLongCat-2.0である。これらの事例は、国産大規模モデルによる「見えない演習」の明確なタイムラインを形成している。
なぜ国産大規模モデルは海外プラットフォームでの匿名の「フライング公開」という手法を選ぶのか。
第一に、それは効率的なコールドスタートとリアルなフィードバックを獲得する戦略である。国内市場では、大規模モデルの発表には往々にして極めて高い世論の注目とパラメーター競争の過熱が伴う。ベンダーは一度正式発表すれば、ただちにすべての競合製品との顕微鏡レベルの比較に晒される。一方、OpenRouterで匿名公開すれば、ブランドの光輪や世論の重荷を取り除き、モデルを純粋に技術力と価格だけでグローバルの開発者に向き合わせることができる。開発者コミュニティからのフィードバックはリアルかつ容赦がなく、彼らが気にするのは呼び出しがスムーズか、価格が安いか、出力が高品質かどうかだけである。この「ブラインドテスト」環境こそ、ベンダーに最もリアルな限界スループットのフィードバックとバグ発見の機会を提供する。
第二に、これはインフラの安定性を実戦で検証するものである。LongCat-2.0は全工程で5万枚の国産AI ASICカードを用いてトレーニングから推論までを完遂した。これほどの規模の国産計算力クラスターが、1日あたり1Tトークンを超える安定スループットの実戦圧力下で、回復不能なロススパイクや通信ボトルネックを起こさずに済むかどうかは、実際のグローバルなトラフィックの衝撃によってのみ検証可能である。OpenRouterは、すぐに利用できる高並列のトラフィック入口を提供し、美団がその国産計算力クラスターの限界耐荷力をテストするのに役立つ。
最後に、市場のタイミングウィンドウの客観的な存在も、この戦略を後押ししている。米国の輸出規制は一部のクローズドソースモデル(Claude Fable 5/Mythos 5、GPT-5.6など)の海外供給を制限しており、これが客観的に国産モデルにとって海外市場でのウィンドウを生み出している。OpenRouterでの匿名テストを通じて、国産モデルは一部の開発者の高性能・低コストモデルへの需要ギャップを迅速に埋め、ユーザーベースと評価を蓄積し、その後の正式発表と商業化への布石を打つことができる。
PonyからHunter、そしてOwlへと至るまで、OpenRouter上での国産大規模モデルによる「見えない演習」は、偶発的な試みから業界共通のコールドスタート戦略へと進化を遂げた。開発者にとっては、実際のトラフィックで検証されたモデルにより早く触れ、より競争力のある価格で開発テストを行えることを意味する。業界にとっては、このような実際のAPI呼び出し量に基づくコールドスタートモデルが、単一の権威あるベンチマークリストに取って代わり、大規模モデルのインフラ安定性と実力を検証する新たな基準となりつつある。

