
著者: Eli5DeFi
編集:ティム、PANews
PANews編集部注:11月25日、Googleの時価総額は過去最高の3兆9,600億ドルに達しました。この株価上昇の要因としては、新たにリリースされた最強のAIチップ「Gemini 3」と、同社が独自開発したTPUチップが挙げられます。TPUはAI分野だけでなく、ブロックチェーン技術においても重要な役割を果たすでしょう。
現代のコンピューティングのハードウェアの物語は、主に GPU の台頭によって定義されてきました。
ゲームからディープラーニングまで、NVIDIA の並列アーキテクチャは業界で認められた標準となり、CPU は徐々に共同管理の役割に移行しています。
しかし、AI モデルがスケーリングのボトルネックに遭遇し、ブロックチェーン技術が複雑な暗号化アプリケーションへと移行するにつれて、新たな競合相手である Tensor Processor (TPU) が登場しました。
TPU は Google の AI 戦略の枠組みの中で議論されることが多いのですが、そのアーキテクチャは意外にも、ブロックチェーン技術の次のマイルストーンである量子耐性暗号の中核的なニーズと一致しています。
この記事では、ハードウェアの進化を振り返り、アーキテクチャの特徴を比較することで、量子攻撃に耐性のある分散型ネットワークを構築する際に、量子耐性暗号に必要な集中的な数学的演算を処理するのに GPU ではなく TPU が適している理由を説明します。
ハードウェアの進化: シリアル処理からパルスアーキテクチャへ
TPU の重要性を理解するには、まず TPU が解決する問題を理解する必要があります。
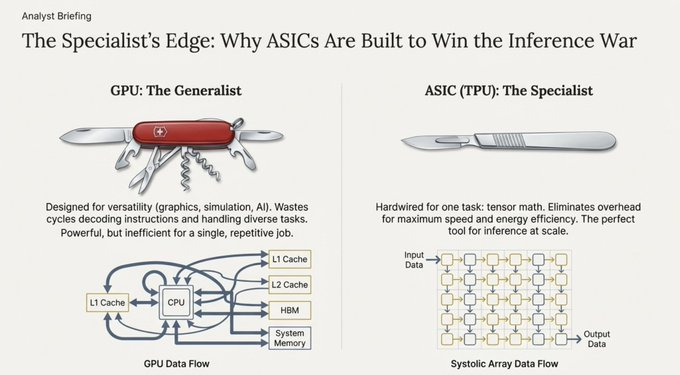
- 中央処理装置 (CPU): オールラウンダーとして、逐次処理や論理分岐演算に優れていますが、大量の数学演算を同時に実行する必要がある場合、その役割は限られます。
- グラフィックス・プロセッシング・ユニット(GPU):並列処理のエキスパートとして、元々はピクセルのレンダリングを目的として設計されたため、多数の同一タスクを同時に実行することに優れています(SIMD:Single Instruction Multiple Data)。この特性により、GPUは人工知能の初期の爆発的な発展において中心的な存在となりました。
- Tensor プロセッサ (TPU): Google がニューラル ネットワーク コンピューティング タスク専用に設計した専用チップ。
脈動アーキテクチャの利点
GPU と TPU の根本的な違いは、データ処理方法にあります。
GPUは計算のためにメモリ(レジスタ、キャッシュ)への繰り返しアクセスを必要としますが、TPUは脈動型アーキテクチャを採用しています。このアーキテクチャは、心臓が血液を送り出すように、大規模な計算セルグリッドを規則的に脈動しながらデータを流します。
https://www.ainewshub.org/post/ai-inference-costs-tpu-vs-gpu-2025
計算結果はメモリへの書き戻しを必要とせず、次の計算ユニットに直接渡されます。この設計により、メモリとプロセッサ間のデータ移動の繰り返しによって生じる遅延であるフォン・ノイマン・ボトルネックが大幅に軽減され、特定の数学演算におけるスループットが桁違いに向上します。
量子耐性暗号の鍵: ブロックチェーンに TPU が必要な理由
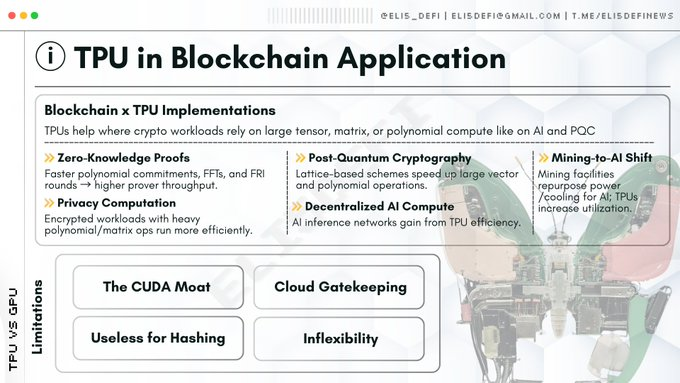
ブロックチェーン分野における TPU の最も重要な用途は、マイニングではなく、暗号化セキュリティです。

現在のブロックチェーンシステムは楕円曲線暗号やRSA暗号に依存していますが、これらはショアのアルゴリズムを扱う際に致命的な弱点を持っています。つまり、十分に強力な量子コンピュータが利用可能になれば、攻撃者は公開鍵から秘密鍵を推測することができ、ビットコインやイーサリアム上のすべての暗号資産を消失させる可能性があります。
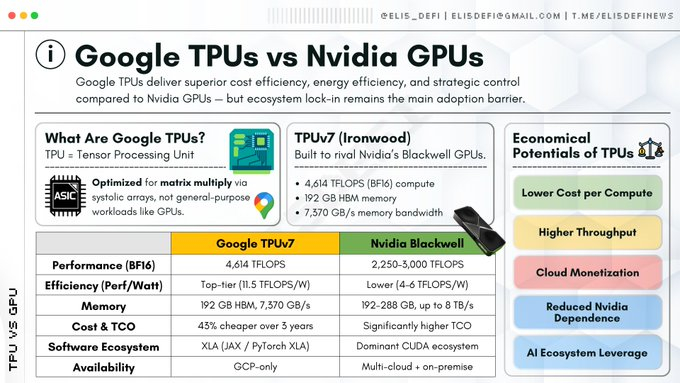
解決策は耐量子暗号にあります。現在、主流のPQC標準アルゴリズム(KyberやDilithiumなど)はすべて、Lattice暗号に基づいています。
TPUの数学的適合
これこそが、TPUがGPUに対して持つ優位性です。格子暗号は、主に以下のような大規模な行列やベクトルに対する集中的な演算に大きく依存しています。
- 行列-ベクトル乗算: As + e (ここで、A は行列、s と e はベクトル)。
- 多項式演算: 通常は数論変換を使用して実装される、環に基づく代数演算。
従来のGPUはこれらの計算を汎用並列タスクとして扱いますが、TPUはハードウェアレベルの固定行列計算ユニットを通じて専用の高速化を実現します。ラティス暗号の数学的構造とTPUのパルスアレイの物理的構造は、ほぼシームレスなトポロジカルマッピングを形成します。
TPUとGPUの技術的戦い
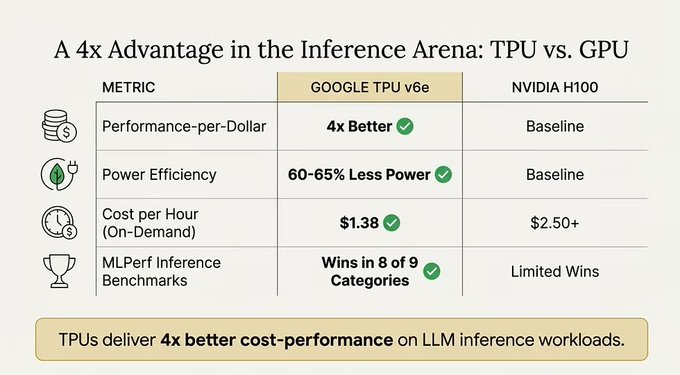
GPU は依然として業界の万能王者ですが、特定の数学集約型タスクを処理する場合、TPU には明らかな利点があります。

結論: GPU は汎用性とエコシステムに優れていますが、TPU は AI と現代の高度な暗号化が依存する中核的な数学演算である集中的な線形代数計算の効率に優れています。
TPU が物語を拡張: ゼロ知識証明と分散型 AI
量子耐性暗号以外にも、TPU は Web3 の他の 2 つの重要な分野でも応用の可能性を示しています。
ゼロ知識証明
Ethereum のスケーリング ソリューションとしての ZK-Rollups (Starknet や zkSync など) は、主に次のような証明生成プロセスで膨大な計算を必要とします。
- 高速フーリエ変換: データ表現形式の高速変換を可能にします。
- マルチスカラー乗算: 楕円曲線上の点演算を実装します。
- FRIプロトコル:多項式検証のための暗号証明システム
これらの演算は、ASICが得意とするハッシュ計算ではなく、多項式演算です。汎用CPUと比較して、TPUはFFT演算や多項式コミットメント演算を大幅に高速化できます。また、これらのアルゴリズムは予測可能なデータフロー特性を持つため、TPUは通常、GPUよりも高い効率性を実現できます。
Bittensorのような分散型AIネットワークの台頭に伴い、ネットワークノードはAIモデル推論を実行する能力を備える必要が生じています。汎用の大規模言語モデルを実行することは、本質的に大規模な行列乗算演算を実行することに相当します。
TPU を使用すると、GPU クラスターと比較して、分散ノードがより低いエネルギー消費で AI 推論リクエストを処理できるため、分散型 AI の商業的実現可能性が向上します。
TPUエコシステム
CUDA が広く採用されているため、ほとんどのプロジェクトは依然として GPU に依存していますが、特に量子コンピュータ暗号化とゼロ知識証明の物語フレームワーク内では、次の領域が TPU 統合の準備が整っています。
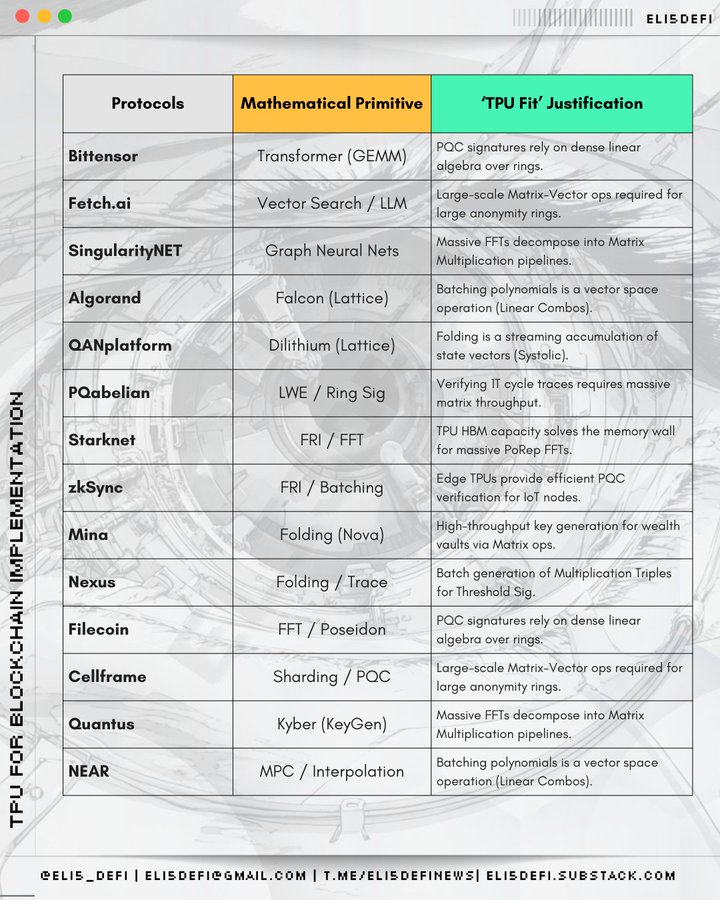
ゼロ知識証明とスケーリングソリューション
TPU を選ぶ理由とは?ZK 証明の生成には多項式演算の超並列処理が必要であり、特定のアーキテクチャ構成では、TPU はそのようなタスクの処理において汎用 GPU よりもはるかに効率的だからです。
- Starknet (2 層拡張方式): STARK 証明は、高速フーリエ変換と高速リード・ソロモン対話型オラクル証明に大きく依存しており、これらの計算集約的な操作は TPU の計算ロジックと非常に互換性があります。
- zksync (2 層スケーリング ソリューション): その Airbender 証明器は、大規模な FFT と多項式演算を処理する必要がありますが、これが TPU が解決できるコアのボトルネックです。
- Scroll(2層拡張方式):Halo2およびPlonk証明システムを採用し、そのコア操作であるKZGコミットメント検証とマルチスカラー乗算は、TPUのパルスアーキテクチャに完全に一致します。
- Aleo (プライバシー保護パブリック チェーン): zk-SNARK ゼロ知識証明の生成に重点を置いており、そのコア操作は、TPU の専用コンピューティング スループットと互換性の高い多項式の数学的特性に依存しています。
- Mina(軽量パブリックブロックチェーン):再帰SNARKs技術を採用しています。証明を継続的に再生成するメカニズムは、多項式演算の繰り返し実行を必要とします。この特性は、TPUの高効率コンピューティングの価値を際立たせています。
- Zcash(プライバシーコイン):古典的なGroth16証明システムは多項式演算に依存しています。これは初期の技術ですが、高スループットのハードウェアによって依然として大きなメリットが得られます。
- Filecoin (DePIN、ストレージ): 複製証明メカニズムは、ゼロ知識証明と多項式コーディング技術を通じて、保存されたデータの有効性を検証します。
分散型AIとエージェントコンピューティング
TPU を選ぶ理由とは?これはまさに、ニューラル ネットワークの機械学習タスクを高速化するために特別に設計された、TPU のネイティブ アプリケーション シナリオです。
- Bittensor のコア アーキテクチャは分散型 AI 推論であり、TPU のテンソル コンピューティング機能に完全に適合します。
- フェッチ(AI エージェント):自律 AI エージェントは、継続的なニューラル ネットワーク推論に基づいて意思決定を行い、TPU はこれらのモデルをより低いレイテンシで実行できます。
- Singularity (AI サービス プラットフォーム): 人工知能サービスの取引マーケットプレイスである Singularity は、TPU を統合することで、基盤となるモデル実行の速度とコスト効率を大幅に向上させます。
- NEAR (パブリック チェーン、AI 戦略的変革): オンチェーン AI と信頼できる実行環境プロキシへの変革。それが依存するテンソル演算には TPU アクセラレーションが必要です。
耐量子暗号ネットワーク
TPUを選ぶ理由とは?量子耐性暗号の中核となる演算は、格子内の最短ベクトルを求める問題によく含まれます。これらのタスクは密な行列演算とベクトル演算を必要とし、計算アーキテクチャの点ではAIワークロードと非常に類似しています。
- Algorand(パブリックブロックチェーン):TPU の並列数学計算機能と高い互換性を持つ、耐量子ハッシュおよびベクトル演算方式を採用しています。
- QAN (量子耐性パブリックチェーン): 格子暗号を採用しており、その基礎となる多項式およびベクトル演算は、TPU が専門とする数学的最適化分野と高度に同型です。
- Nexus (コンピューティング プラットフォーム、ZkVM): 量子耐性のある計算準備には、TPU アーキテクチャに効率的にマッピングできる多項式および格子基底アルゴリズムが含まれます。
- Cellframe (量子耐性パブリック ブロックチェーン): 使用される Lattice 暗号化およびハッシュ暗号化テクノロジにはテンソルのような演算が含まれるため、TPU アクセラレーションに最適です。
- Abelian(プライバシートークン):耐量子暗号の格子演算に重点を置いています。QANと同様に、その技術アーキテクチャはTPUベクトルプロセッサの高いスループットを最大限に活用しています。
- Quantus(パブリックブロックチェーン):量子耐性暗号署名は大規模なベクトル演算に依存しており、TPU は標準的な CPU よりもはるかに高い並列化能力でこのような演算を処理できます。
- Pauli (コンピューティング プラットフォーム): 量子耐性コンピューティングには多数の行列演算が含まれており、これがまさに TPU アーキテクチャの核となる利点です。
開発のボトルネック: TPU がまだ広く採用されていないのはなぜでしょうか?
TPU が量子耐性暗号やゼロ知識証明に非常に効果的であるならば、なぜ業界は依然として H100 チップの購入に躍起になっているのでしょうか?
- CUDAの堀:NVIDIAのCUDAソフトウェアライブラリは業界標準となり、暗号エンジニアの大多数がCUDAをベースにプログラミングを行っています。TPUに必要なJAXまたはXLAフレームワークへのコードの移植は、技術的に困難であるだけでなく、多大なリソースの投入も必要です。
- クラウドプラットフォームへの参入障壁:ハイエンドTPUはGoogle Cloudによってほぼ独占されています。単一の集中型クラウドサービスプロバイダーに過度に依存する分散型ネットワークは、検閲リスクや単一障害点に直面することになります。
- 堅牢なアーキテクチャ:暗号化アルゴリズムに微調整(分岐ロジックの導入など)が必要な場合、TPU のパフォーマンスは大幅に低下します。一方、GPU は、このような不規則なロジックの処理において TPU よりもはるかに優れています。
- ハッシュ演算の限界:TPUはビットコインマイニングマシンの代替にはなりません。SHA-256アルゴリズムは行列演算ではなくビットレベルの演算を行うため、この分野ではTPUは役に立ちません。
結論: 階層化アーキテクチャこそが未来です。
Web3 ハードウェアの将来は、勝者総取りの競争ではなく、むしろ階層化アーキテクチャへの進化です。
GPU は、一般的なコンピューティング、グラフィックス レンダリング、複雑な分岐ロジックを必要とするタスクにおいて引き続き主導的な役割を果たします。
TPU(および同様の ASIC ベースのアクセラレータ)は、ゼロ知識証明と検証済みの量子暗号署名を生成するために特別に設計された、Web3「数学レイヤー」の標準構成に徐々になります。
ブロックチェーンが量子耐性セキュリティ標準に移行すると、トランザクションの署名と検証に必要な大規模なマトリックス演算により、TPU のパルス アーキテクチャはもはやオプションではなく、スケーラブルな量子耐性分散型ネットワークを構築するための不可欠なインフラストラクチャになります。



