
저자: 리 단
출처: 월스트리트 저널
OpenAI의 올해 가장 기대되는 제품이 출시되었습니다.
8월 7일 목요일(미국 동부 시간), OpenAI는 차세대 플래그십 인공지능(AI) 모델인 GPT-5의 출시를 발표했습니다. GPT-5는 OpenAI 최초의 "올인원" AI 시스템으로, O 시리즈 모델의 추론 기능과 GPT 시리즈 모델의 신속한 대응 기능을 결합했습니다.
OpenAI CEO 샘 알트만은 신모델 출시 컨퍼런스에서 GPT-5를 극찬하며 "세계 최고의 모델"이자 이전 모델에 비해 "대대적인 업그레이드"라고 칭했습니다. 그는 또한 GPT-5 출시가 OpenAI가 일반 인공지능(AGI)을 향한 여정에서 "중요한 단계"라고 말했습니다.
OpenAI는 GPT-5가 여러 벤치마크에서 탁월한 성능을 달성하여 프로그래밍, 수학, 건강 등의 분야에서 최첨단 수준에 도달했다고 발표했습니다. GPT-5는 SWE-bench Verified 코드 테스트에서 74.9%의 정확도를 달성하여 화요일에 출시된 Anthropic의 새로운 모델인 Claude Opus 4.1을 근소하게 앞지르고 있습니다. 또한 GPT-5는 환각 감지 능력을 크게 향상시켜 위양성률 4.8%를 기록했는데, 이는 이전 모델인 GPT-4o의 20.6%보다 훨씬 낮은 수치입니다.
이번 목요일부터 GPT-5는 모든 무료 ChatGPT 사용자와 Plus, Pro, Team 구독의 유료 사용자에게 기본 모델로 제공되며, 일주일 이내에 Enterprise 및 Edu 유료 플랜에 출시될 예정입니다.
GPT-4o와 마찬가지로, GPT-5 무료 버전과 유료 버전의 차이는 사용량에 있습니다. Plus 사용자는 더 높은 사용량 제한을 누리는 반면, Pro 사용자는 무제한 사용량과 향상된 버전인 GPT-5 Pro를 이용할 수 있습니다. 무료 사용자의 경우, 전체 추론 기능을 완전히 사용하려면 며칠이 걸릴 수 있습니다. 무료 사용자가 GPT-5 사용량 제한에 도달하면 OpenAI는 더 작은 버전인 GPT-5 mini로 전환합니다.
OpenAI는 수요일, 미국 연방 정부 기관에 연간 1달러의 소액 수수료로 ChatGPT 제품을 제공할 것이라고 밝혔습니다. 구체적으로는 향상된 보안 및 개인정보 보호 기능이 포함된 ChatGPT 기업용 버전을 제공할 예정입니다.
OpenAI는 방금 GPT-5를 공식적으로 발표했으며, Microsoft는 목요일부터 GPT-5를 365 Copilot, Copilot, GitHub Copilot 및 Azure AI Foundry 플랫폼을 포함한 광범위한 제품 포트폴리오에 통합할 것이라고 발표했습니다. 이를 통해 Microsoft의 기업 및 일반 사용자는 GPT-5의 고급 추론 기능과 프로그래밍 이점을 즉시 경험할 수 있습니다.
GPT-5는 프로그래밍, 창의적 글쓰기, 건강 측면에서 3가지 주요 장점을 가지고 있습니다.
OpenAI의 GPT5 발표는 GPT-5가 OpenAI의 "가장 똑똑하고, 가장 빠르고, 가장 실용적인 모델로, 누구나 전문가 수준의 지능을 갖출 수 있도록 하는 내장된 사고 기능을 갖추고 있습니다."라는 말로 시작합니다.
OpenAI에 따르면, OpenAI의 "가장 강력한 모델"인 GPT-5는 세 가지 핵심 영역에서 상당한 개선을 이루었습니다.
첫째, 프로그래밍 기능입니다. GPT-5는 OpenAI 역사상 가장 강력한 코딩 모델로, 복잡한 프런트엔드 생성과 대규모 코드베이스 디버깅에 탁월합니다. 단일 프롬프트로 아름답고 반응형 웹사이트, 앱, 게임을 만들 수 있습니다. 초기 테스터들은 간격, 타이포그래피, 여백 등의 디자인 측면에서 개선된 점을 확인했습니다.
GitHub에서 실제 코딩 과제를 수집하는 벤치마크인 SWE-bench Verified에서 GPT-5는 생각 후 첫 번째 시도에서 74.9%의 정확도를 달성했는데, 이는 OpenAI의 추론 모델 o3의 69.1%와 GPT-4o의 30.8%보다 높은 수치입니다.
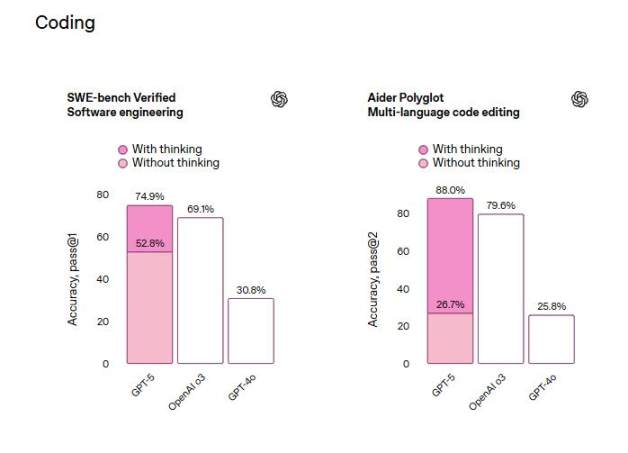
해설자들은 이는 GPT-5가 화요일에 출시된 Anthropic의 Claude Opus 4.1과 SWE-bench Verified 테스트에서 각각 74.5%와 59.6%를 기록한 Google DeepMind의 Gemini 2.5 Pro보다 약간 더 나은 성능을 보인다는 것을 의미한다고 언급했습니다.
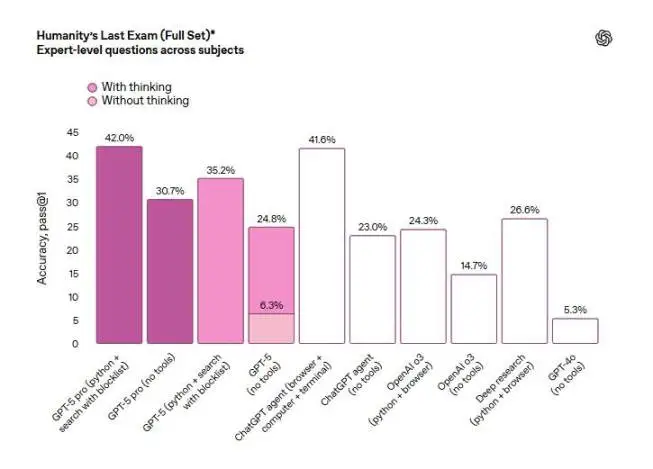
그러나 수학, 인문학, 자연과학 분야의 모델 성능을 다양한 학문 분야의 전문가 수준으로 측정하는 Humanity's Last Exam 테스트에서, 추론 기능이 확장된 GPT-5의 강화 버전인 GPT-5 Pro는 도구를 사용하여 42%의 점수를 기록했습니다. 이는 44.4%를 기록한 xAI 모델 Grok 4 Heavy보다 약간 낮은 수치입니다.
알트먼은 GPT-5가 특히 "앰비언트 코딩"이라고 불리는 주문형 소프트웨어 앱을 출시하는 데 뛰어나다고 말했습니다. 즉, AI를 사용하여 자연어 프롬프트를 기반으로 기능적 코드를 생성하여 개발 속도를 높이는 것입니다.
예를 들어, OpenAI 연구원들은 영어권 사용자의 프랑스어 학습을 돕는 웹 앱을 개발하는 데 GPT-5가 필요하다는 것을 보여주었습니다. 앱은 매력적인 테마를 가져야 하며, 플래시카드, 퀴즈, 고전적인 스네이크 게임, 그리고 일일 학습 진행 상황을 추적하는 기능을 포함해야 합니다.
연구진은 동일한 프롬프트 단어를 두 개의 GPT-5 창에 입력했고, 몇 분 후 두 개의 서로 다른 앱이 생성되었습니다. OpenAI의 대표는 이 앱들에 "몇 가지 단점이 있다"고 하면서도, 사용자는 배경을 바꾸거나 탭을 추가하는 등 AI가 생성한 소프트웨어를 자신의 취향에 맞게 조정할 수 있다고 밝혔습니다.
창작 글쓰기에서 GPT-5는 무운율 약강 5보격이나 자연스럽게 흐르는 자유시와 같은 복잡한 글쓰기 과제를 처리할 수 있습니다. OpenAI의 ChatGPT 부사장인 닉 털리는 GPT-5가 창작 과제에서 "더 나은 취향"과 더 자연스러운 반응을 보였다고 밝혔습니다.

건강 상담은 개선이 필요한 세 번째 중요한 영역입니다.
GPT-5는 잠재적인 건강 문제를 보다 적극적으로 표시하고 사용자가 의료 결과를 해석하는 데 도움을 줄 수 있지만, OpenAI는 ChatGPT가 의료 전문가를 대체하는 것은 아니라고 강조합니다.
HealthBench Hard Hallucinations라는 테스트에서 사고형 GPT-5의 환각 오류율은 단 1.6%로, 각각 15.8%와 12.9%의 오류율을 기록한 GPT-4o 및 o3 모델보다 상당히 낮았습니다.
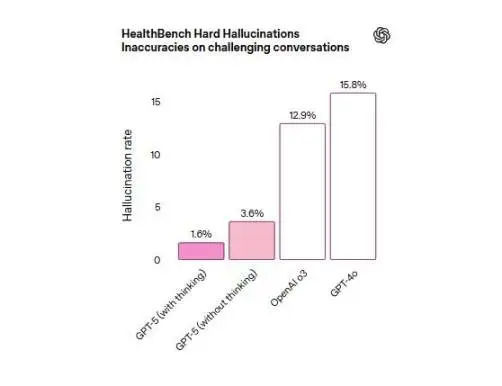
새로운 안전 교육 모델은 환각 가능성을 크게 줄입니다.
OpenAI는 GPT-5가 이전 모델보다 더욱 신뢰성 있고 실용적이라고 주장합니다. 실제 질문에 더욱 정확하게 답할 수 있으며, 환각을 경험할 가능성이 훨씬 낮습니다.
ChatGPT의 프로덕션 트래픽을 나타내는 익명 프롬프트에서 웹 검색을 실행했을 때, GPT-5 응답은 GPT-4o 응답보다 사실 오류가 포함될 가능성이 약 45% 낮았습니다. 검토 결과, GPT-5 응답은 o3 응답보다 사실 오류가 포함될 가능성이 약 80% 낮았습니다. 아래 그림에서 볼 수 있듯이, GPT-5 응답의 오류율은 4.8%에 불과한 반면, GPT-4o 응답의 오류율은 20.6%, o3 응답의 오류율은 22%였습니다.
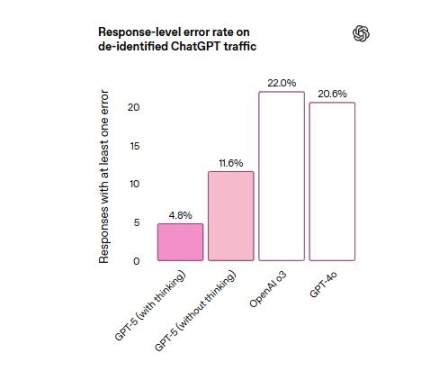
OpenAI는 GPT-5를 위한 새로운 형태의 안전 학습인 안전 완성(safe completions)을 도입했다고 발표했습니다. 이 학습은 모델이 안전한 범위 내에서 최대한 유용한 답변을 제공하도록 훈련시킵니다. 이는 경우에 따라 사용자의 질문에 부분적으로만 답변하거나 높은 수준의 답변만 제공하는 것을 의미할 수 있습니다.
거부가 필요한 경우, 훈련된 GPT-5는 사용자에게 거부 이유를 투명하게 알리고 안전한 대안을 제공합니다.
통제된 실험과 OpenAI의 생산 모델 모두에서 우리는 안전 완료에 대한 이러한 접근 방식이 더 미묘하고, 이중 사용 문제를 더 잘 안내하고, 모호한 의도에 대한 견고성을 높이고, 불필요한 과도한 거부를 줄인다는 것을 발견했습니다.
OpenAI의 사후 학습 책임자인 미셸 포크라스는 "GPT-5는 작업이 불가능한 경우를 인식하고 추측을 피하며 이전 모델보다 한계를 더 명확하게 설명하도록 훈련되었기 때문에 근거 없는 주장이 줄었습니다."라고 말했습니다.
4가지 선택 가능한 ChatGPT 채팅 사전 설정 개성 소개
OpenAI는 GPT-5가 명령 실행 성능을 향상시켰으며, 사용자 지정 명령 실행 기능도 그에 따라 개선되었다고 주장합니다. OpenAI는 모든 ChatGPT 사용자를 위해 네 가지 사전 설정된 개성을 갖춘 새로운 연구 미리보기 버전을 출시할 예정입니다.
냉소주의자, 로봇, 청취자, 괴짜 등 처음 네 가지 성격 옵션은 모두 선택 사항이며, 사용자는 언제든지 설정에서 이를 조정하여 ChatGPT와 사용자의 커뮤니케이션 스타일에 맞게 조정할 수 있습니다.
처음에는 텍스트 채팅에만 제공되던 이 4가지 성격은 음성 채팅에도 확장되어, 사용자는 사용자 정의 프롬프트를 작성하지 않고도 ChatGPT와 상호 작용하는 방식을 사용자 정의할 수 있습니다. 간결하고 전문적인, 세심하고 지원적인, 심지어 약간 비꼬는 표현까지 가능합니다.
OpenAI에 따르면, 이러한 새로운 인물들은 모두 아첨 행위를 줄이기 위한 내부 평가 기준을 충족하거나 초과했습니다.
알트만은 이 역사적인 획기적인 발견을 칭찬했지만, GPT-4를 사용한 결과는 매우 좋지 않았습니다.
목요일 브리핑에서 알트만은 GPT-5를 극찬하며, AGI로 가는 길의 중요한 이정표로 제시했습니다. 그는 다음과 같이 말했습니다.
"역사상 어느 때에도 GPT-5와 같은 것은 상상도 할 수 없었을 겁니다." "어떤 분야든 전문가와 대화하는 것 같은 느낌이 드는 건 이번이 처음입니다."
알트만은 브리핑에서 GPT-4를 맹비난하며 GPT-5를 극찬하기까지 했습니다. 그는 이렇게 말했습니다.
"GPT-4를 다시 사용해보려고 했지만 끔찍했어요."
GPT-5는 실시간 라우터를 갖춘 통합 시스템 아키텍처를 사용하며, 대화 유형, 복잡성 및 도구 요구 사항에 따라 신속하게 응답할지 아니면 심층적인 "사고"를 수행할지 자동으로 결정합니다. 이를 통해 사용자가 적절한 설정을 직접 선택할 필요가 없어 ChatGPT를 더욱 쉽게 사용할 수 있습니다.
경제적으로 가치 있는 업무에 대한 내부 벤치마크 테스트에서, 추론 모드를 사용하는 GPT-5는 법률, 물류, 영업, 엔지니어링 등 40개 이상의 직종을 포괄하는 사례의 약 절반에서 전문가 수준 이상의 성능을 보였습니다. OpenAI 부사장 닉 털리는 "모델이 정말 만족스럽습니다."라고 말했습니다.
알트만은 GPT-5를 사용하는 것을 마치 박사 학위를 소지한 전문가 팀을 손쉽게 이용할 수 있는 것과 같다고 비유했습니다. 그는 "많은 새로운 분야에서 사람들은 아이디어는 제한적이지만 실제로 실행할 능력은 부족합니다."라고 덧붙였습니다.
Microsoft는 주도권을 잡기 위해 완벽하게 통합합니다.
GPT-5 출시 당일, Microsoft는 다양한 제품군에 GPT-5를 통합한다고 발표했습니다. 기업용 애플리케이션의 경우, Microsoft 365 Copilot은 GPT-5를 활용하여 복잡한 문제를 더욱 효과적으로 처리하고, 긴 대화 중에도 집중력을 유지하며, 사용자 맥락을 이해할 수 있도록 지원합니다. 기업 사용자는 추론 기능을 사용하여 이메일, 문서 및 파일을 처리할 수 있습니다.
소비자를 위해 Microsoft Copilot의 새로운 인텔리전트 모드는 GPT-5를 활용하여 사용자가 최적의 솔루션을 찾을 수 있도록 지원합니다. 사용자는 copilot.microsoft.com 또는 Windows, Mac, Android, iOS 기기의 Copilot 앱을 통해 GPT-5를 무료로 체험할 수 있습니다.
개발자는 GitHub Copilot과 Visual Studio Code를 통해 GPT-5 지원을 활용하여 코드 작성, 테스트 및 배포를 수행할 수 있습니다. 모든 GPT-5 모델은 Azure AI Foundry 플랫폼에서 제공되며, 각 작업의 복잡성, 성능 요구 사항 및 비용 효율성에 따라 최적의 모델을 선택하는 AI 기반 모델 라우터도 함께 제공됩니다.
마이크로소프트 AI 레드팀은 엄격한 보안 프로토콜을 사용하여 GPT-5 추론 모델을 테스트했습니다. 테스트 결과, 해당 모델은 악성코드 생성 및 사기 자동화와 같은 다양한 공격 모드에서 OpenAI의 기존 모델 중 가장 강력한 AI 보안 구성 중 하나를 보여주었습니다.



