
2026年4月底,一個名為「Owl Alpha」的匿名模型悄然出現在全球最大的大模型聚合分發平台OpenRouter上。沒有官方公告,沒有媒體發布會,甚至連開發團隊資訊也一片空白。但在接下來的約兩個月時間裡,這個神秘模型憑藉驚人的吞吐量迅速攀升至平台調用量前列。據VentureBeat報導,該模型在匿名測試期間的月Token吞吐量達到約10.1萬億,日均處理559B Token,月環比增長242%。直到6月30日美團正式發布LongCat-2.0,這個靠5萬張國產GPU訓練出的1.6萬億參數大模型才揭開面紗,美團官方公告確認Owl Alpha即為其預覽版,並稱當前月調用量位列OpenRouter全球前三。
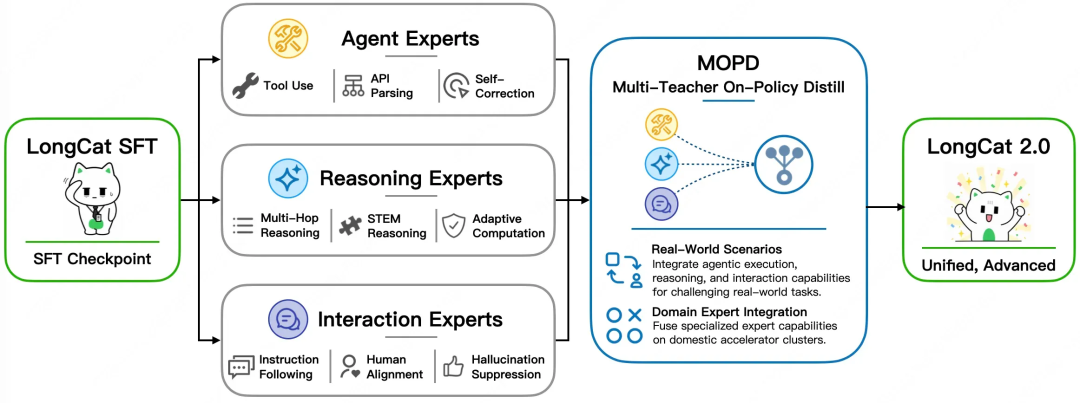
LongCat-2.0 的 MOPD 多專家融合架構示意(來源:longcatai.org)
一個預覽版模型能在海外開發者平台斬獲如此高的調用量,並非單一因素促成,而是技術架構與分發策略共同作用的結果。而在它之前,從智譜到小米,國產大模型似乎都熱衷於在正式發布前透過OpenRouter進行「隱形練兵」。
Owl Alpha的兩個月:匿名模型如何衝進OpenRouter前三?
要理解LongCat-2.0的高調用量,首先需要理解OpenRouter在當前大模型生態中的角色。對於開發者而言,OpenRouter提供了一個統一的API接口,可以接入全球數十家廠商的數百個模型。開發者在選擇模型時,往往會在相同的Prompt下對比不同模型的速度、質量和價格。當一個新模型上線時,如果它表現出超越同價位模型的性能,或者提供了極具破壞力的價格,開發者社群的口碑傳播會非常迅速。
Owl Alpha在OpenRouter上的爆發,正是遵循了這一邏輯。據美團官方公告顯示,Owl Alpha在Hermes(Agent工作空間)、Claude Code、OpenClaw三大月調用量場景中分別排名第一、第二和第三。這三個場景的共同特徵是高度依賴Agent能力,即模型需要反覆讀取程式碼庫、進行多輪工具呼叫和長上下文推理。
高調用量並非偶然,除了模型本身的參數規模,更與其在特定場景的適配性和極具攻擊性的定價策略有關。在匿名測試期間,Owl Alpha並未暴露其國產算力背景,純粹以技術表現和價格征服開發者。VentureBeat報導的10.1萬億月Token吞吐量雖然為媒體估算,且OpenRouter官方未公開精確數字,但這一數據已經足以說明該模型在開發者社群中獲得了極高的實際採用率。這種採用率不是靠行銷預算買來的,而是靠真實的API呼叫堆出來的。
把程式碼庫塞進快取:LongCat-2.0如何重寫Agent的計費邏輯
LongCat-2.0能夠支撐如此龐大的調用量,核心在於其技術架構與商業策略的深度耦合。據美團官方公告,LongCat-2.0總參數量達1.6萬億,平均激活參數約480億,動態範圍在330億至560億之間,原生支援100萬Token超長上下文。這種1.6T總參與48B激活的MoE(混合專家)架構,是目前大模型在效能與成本之間尋找平衡的主流選擇。
在技術架構上,LongCat-2.0融合了四項關鍵創新,每一項都直指Agent開發中的具體痛點。
首先是解決記憶體牆問題的LSA(LongCat Sparse Attention)稀疏注意力。處理100萬Token的超長上下文,傳統注意力機制的計算量是平方級增長的,這會導致極大的記憶體頻寬瓶頸。LSA透過Streaming-aware Indexing將碎片化記憶體存取轉為連續區塊讀取,透過Cross-Layer Indexing實現跨層注意力索引復用,再透過Hierarchical Indexing進行粗到細的兩階段篩選,將長文本處理的計算量從平方級降至線性級。這解決了Agent在讀取大型程式碼庫時面臨的記憶體牆問題。
解決了記憶體牆,接下來是算力分配的精細化。在MoE架構中,並非所有Token都需要複雜的計算。標點符號、功能詞等簡單Token如果被路由到複雜的專家網絡,會造成算力浪費。LongCat-2.0在專家池中增設了「零計算專家」,路由到該專家的Token直接返回輸入,不消耗計算資源。系統透過PID控制器動態調節專家偏置,維持平均激活參數在目標範圍內。這就像是在高速公路上設置了快速通道,讓簡單任務快速通過,將算力留給複雜的遞歸推導。
算力分配優化後,通訊延遲成為下一個需要攻克的瓶頸。ScMoE(Shortcut-connected MoE)採用跨層快捷連接,將前一個block的dense FFN計算與當前MoE層的dispatch/combine通訊並行執行。這種流水線設計使得理論TPOT(Time-Per-Output-Token,每輸出Token耗時)降低近50%,直接提升了模型的回應速度,這對於需要頻繁互動的Agent場景至關重要。
最後是任務排程層面的MOPD(Multi-Teacher Optimization via Mixture of Specialized Experts)。在後訓練階段,LongCat-2.0將優化拆分為Agent、Reasoning、Interaction三組專用專家集群。Agent Experts負責工具呼叫和多輪API參數解析,Reasoning Experts負責多跳邏輯和數學推理,Interaction Experts負責指令遵循和安全護欄。推理時由門控網路根據任務類型動態排程。這意味著當開發者呼叫模型進行程式碼審查時,激活的是Agent專家;進行數學推導時,激活的是Reasoning專家。這種分工提升了模型在特定任務上的專業度。
然而,技術架構只是降本的基礎,真正改變開發者算帳邏輯的是其定價策略。據LongCat API定價頁顯示,其標準定價為輸入¥5/百萬Token,輸出¥20/百萬Token。但在限時折扣期間,價格降至輸入$0.30/百萬Token,輸出$1.20/百萬Token。更具顛覆性的是其「快取命中免費」機制。
在Agent開發中,模型需要反覆讀取同一程式碼庫或系統提示詞。在傳統的計費模式下,這些重複的輸入Token每次都會產生費用,導致Agent的運行成本隨互動輪數線性增長。LongCat-2.0的快取命中免費機制,意味著只要輸入的前綴部分在快取中命中,就不扣費。這一設計直擊Agent場景的成本痛點,被許多開發者視為「改變Agent成本經濟學」的創舉。
為了更直觀地理解LongCat-2.0的性價比,我們可以參考以下基於公開生態信號整理的對比表。
| 模型 | 廠商 | SWE-bench Pro 得分 | 輸出標準價 ($/M tokens) | 輸出限時價 ($/M tokens) | 開源協議 | 數據口徑說明 |
|---|---|---|---|---|---|---|
| Claude Opus 4.8 | Anthropic | 69.2 | $25.00 | 無 | 閉源 | 廠商自報/第三方聚合 |
| GLM-5.2 | 智譜 | 62.1 | $4.40 | 無 | MIT | 廠商自報/第三方聚合 |
| Qwen3.7 Max | 阿里 | 60.6 | $3.75 | 無 | 部分開源 | 廠商自報/第三方聚合 |
| LongCat-2.0 | 美團 | 59.5 | $2.95 | $1.20 | MIT | 廠商自報,未進入Scale AI標準化公開榜 |
| MiniMax M3 | MiniMax | 59.0 | $2.40 | 無 | 開源 | 廠商自報/第三方聚合 |
| GPT-5.5 | OpenAI | 58.6 | $30.00 | 無 | 閉源 | 廠商自報/第三方聚合 |
| DeepSeek V4 Pro Max | DeepSeek | 55.4 | $0.87 | 無 | MIT | 廠商自報/第三方聚合 |
需要說明的是,上表中的SWE-bench Pro分數均為各廠商自報或第三方聚合數據,不同模型可能在不同批次或評測條件下進行測試,橫向對比僅作參考。此外,LongCat-2.0的59.5分為美團自報,截至發稿時尚未進入Scale AI標準化公開排行榜。Scale標準化公開榜上,GPT-5.4 (xHigh) 以59.1%的標準化分數領先,且標準化分數普遍比廠商自報低10至30分。即便如此,LongCat-2.0在限時折扣價$1.20/百萬Token的加持下,疊加快取免費機制,其在開源模型中的價格破壞力依然顯著。
跑分前三與「程式設計不如預期」:LongCat-2.0的實際能力邊界
廠商公佈的跑分數據往往描繪了一幅完美的圖景,但開發者的實際體驗卻更為複雜。LongCat-2.0在SWE-bench Pro取得59.5分,SWE-bench Multilingual達77.3分,Terminal-Bench 2.1得分為70.8。這些數據表明該模型在軟體工程基準測試中處於開源模型的第一梯隊。
然而,在Reddit的r/LocalLLaMA社群中,開發者的回饋呈現出不同的視角。有使用者在測試後表示:“It's not good in coding, very good in reviews though. Instruction following is also pretty good. A little bit of a waste with that parameter...”(程式設計能力不如預期,程式碼審查和指令遵循不錯,參數規模有些浪費)。這反映出模型在通用程式碼生成任務上可能不如在程式碼審查和指令遵循任務上表現出色。在r/SillyTavernAI社群,也有使用者回饋該模型在角色扮演場景中傾向於代替使用者說話,存在互動體驗上的瑕疵。
這種跑分與實際體驗的落差,在大模型產業並不罕見。廠商自報跑分通常是在特定的測試環境和提示詞下獲得的,而開發者的實際使用場景往往更加多樣化和複雜。LongCat-2.0在MOPD架構中專門設置了Agent、Reasoning、Interaction三組專用專家,這可能使得模型在特定任務上表現優異,但在通用程式碼生成上仍有侷限。
此外,LongCat-2.0的開源承諾仍需時間驗證。截至6月30日發布日,其HuggingFace頁面顯示模型權重為“coming soon”,尚未提供下載。雖然官方宣佈採用MIT開源授權,對企業使用者友好,可嵌入閉源商業產品,但在權重實際落地前,開發者仍持觀望態度。同時,其宣稱的100萬Token超長上下文的實際資訊保持率,也缺乏第三方獨立驗證,如Needle-in-a-Haystack等測試的公開數據。這些限制都意味著LongCat-2.0的實際能力邊界,還需要在更廣泛的開發者實踐中去界定。
從Pony到Owl:國產大模型為何熱衷於海外「偷跑」?
LongCat-2.0透過Owl Alpha在OpenRouter上的匿名測試,並非孤立事件。梳理2026年以來的產業動態,可以發現一種明顯的趨勢:國產大模型在正式發布前,越來越熱衷於在OpenRouter上進行匿名預覽。
2026年2月,OpenRouter上線了匿名模型「Pony Alpha」,後被證券時報等媒體確認其真實身份為智譜AI的GLM-5。該模型在程式設計和Agent優化上表現突出,且提供免費調用。緊接著在3月,匿名模型「Hunter Alpha」出現,後被確認是小米的MiMo-V2-Pro,擁有1T參數和1M上下文。4月底,Owl Alpha上線,即美團LongCat-2.0。這些案例構成了國產大模型「隱形練兵」的清晰時間線。
為什麼國產大模型會選擇這種在海外平台匿名「偷跑」的方式?
首先,這是一種高效的冷啟動與真實回饋獲取策略。在國內市場,大模型發布往往伴隨著極高的輿論關注和參數內卷壓力。廠商一旦官宣,就會立刻被置於與所有競品的顯微鏡式對比中。而在OpenRouter上匿名上線,可以剝離品牌光環和輿論包袱,讓模型純粹以技術表現和價格面對全球開發者。開發者社群的回饋是真實且殘酷的,他們只關心調用是否順暢、價格是否便宜、輸出是否高品質。這種「盲測」環境能為廠商提供最真實的極限吞吐回饋和Bug發現機會。
其次,這是對基礎設施穩定性的一次實戰檢驗。LongCat-2.0全程基於5萬張國產AI ASIC卡完成全流程訓練與推理。這樣規模的國產算力集群,在穩態日吞吐超過1T tokens/day的實戰壓力下,是否會出現不可恢復的loss尖峰或通訊瓶頸,只有在真實的全球流量衝擊下才能驗證。OpenRouter提供了一個現成的、高併發的流量入口,幫助美團測試其國產算力集群的極限承載能力。
最後,市場窗口的客觀存在也推動了這一策略。美國出口管制限制了部分閉源模型(如Claude Fable 5/Mythos 5、GPT-5.6)的對外供應,這在客觀上為國產模型在海外市場留出了窗口。透過OpenRouter的匿名測試,國產模型能夠迅速填補部分開發者對高效能、低成本模型的需求空缺,累積使用者基礎和口碑,為後續的正式發布和商業化鋪路。
從Pony到Hunter再到Owl,國產大模型在OpenRouter上的「隱形練兵」已經從一種偶然的嘗試,演變為一種產業共性的冷啟動策略。對於開發者而言,這意味著他們能更早接觸到經過真實流量檢驗的模型,並以更具競爭力的價格進行開發測試;對於產業而言,這種基於真實API調用量的冷啟動模式,正在逐漸替代單一權威榜單,成為檢驗大模型基礎設施穩定性與實際能力的新標準。

