

作者| ZeR0 駿達,智東西
編輯| 漠影
芯東西拉斯維加斯1月5日報道,剛剛,英偉達創辦人兼CEO黃仁勳在國際消費電子展CES 2026發表2026年首場主題演講。黃仁勳一如既往穿著皮衣,在1.5小時內連宣8項重要發布,從晶片、機架到網路設計,對整個全新代際平台進行了深入介紹。

在加速運算和AI基礎設施領域,英偉達發布NVIDIA Vera Rubin POD AI超級電腦、NVIDIA Spectrum-X乙太網路共封裝光學元件、NVIDIA推理上下文記憶體儲存平台、基於DGX Vera Rubin NVL72的NVIDIA DGX SuperPOD。

NVIDIA Vera Rubin POD採用英偉達6大自研晶片,涵蓋CPU、GPU、Scale-up、Scale-out、儲存與處理能力,所有部分均為協同設計,可滿足先進模式需求並降低運算成本。
其中,Vera CPU採用客製化Olympus核心架構,Rubin GPU引進Transformer引擎後NBFP4推理效能高達50PFLOPS,每GPU NVLink頻寬快至3.6TB/s,支援第三代通用機密運算(第一個機架級TEE),實現CPU與GPU跨域的完整可信任執行環境。

這些晶片都已回片,英偉達已對整個NVIDIA Vera Rubin NVL72系統進行驗證,合作夥伴也已開始運行其內部集成的AI模型和演算法,整個生態系統都在為Vera Rubin做部署準備。
其他發布中,NVIDIA Spectrum-X以太網共封裝光學元件顯著優化了電源效率和應用正常運行時間;NVIDIA推理上下文記憶體存儲平台重新定義了存儲堆疊,以減少重複計算並提升推理效率;基於DGX Vera Rubin NVL72的NVIDIA DGX SuperPOD將大型MoE模型的token成本降低至1/10。

開放模型方面,英偉達宣布擴展開源模型全家桶,發布新的模型、資料集和庫,包括NVIDIA Nemotron開源模型系列新增Agentic RAG模型、安全模型、語音模型,也發布了適用於所有類型機器人的全新開放模型。不過,黃仁勳並未在演講中詳細介紹。
物理AI方面,物理AI的ChatGPT時刻已經到來,英偉達全端技術使全球生態系統能透過AI驅動的機器人技術改變產業;英偉達廣泛的AI工具庫,包括全新Alpamayo開源模型組合,使全球交通行業能快速實現安全的L4駕駛;NVIDIA DRIVE自動駕駛平台現已投入生產,搭載於所有全新梅賽德斯-奔馳2CLA,用於駕駛的 AIC2 AIC。

01.全新AI超級電腦:6款自研晶片,單機架算力達3.6EFLOPS
黃仁勳認為,每10到15年,電腦產業就會迎來一次全面的重塑,但這次,兩個平台變革同時發生,從CPU到GPU,從“編程軟體”到“訓練軟體”,加速運算與AI重構了整個運算堆疊。過去十年價值10兆美元的計算產業,正經歷一場現代化改造。
同時,對算力的需求也急劇飆升。模型的尺寸每年增長10倍,模型用於思考的token數量每年增長5倍,每個token的價格每年降低10倍。
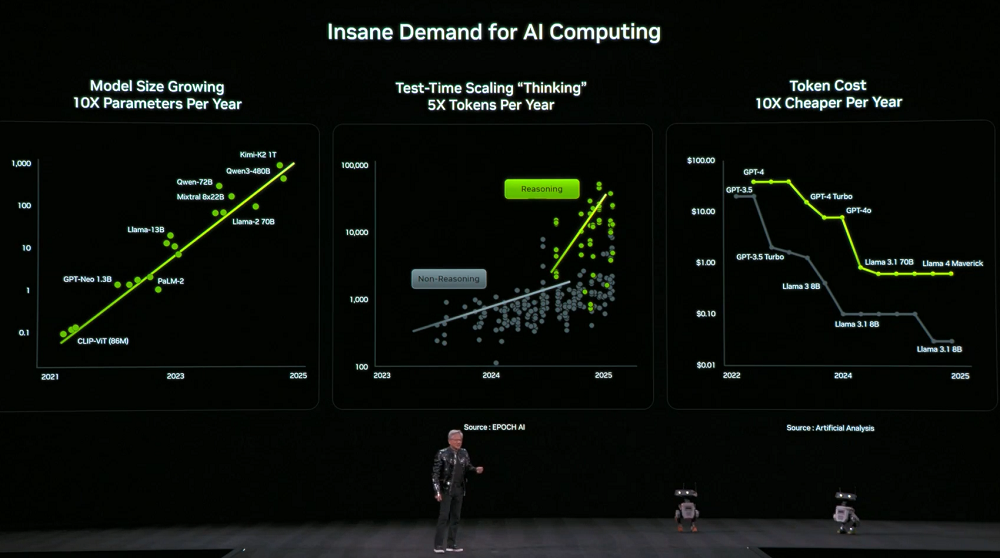
為了因應這項需求,英偉達決定每年都會發布新的運算硬體。黃仁勳透露,目前Vera Rubin也已經全面開啟生產。
英偉達全新AI超級電腦NVIDIA Vera Rubin POD採用了6款自研晶片:Vera CPU、Rubin GPU、NVLink 6 Switch、ConnectX-9(CX9)智慧網卡、BlueField-4 DPU、Spectrum-X 102.4T CPO。
Vera CPU:為資料移動與智慧體處理而設計,擁有88個英偉達客製化Olympus核心、176線程的英偉達空間多線程,1.8TB/sNVLink-C2C支援CPU:GPU統一內存,系統記憶體達1.5TB(是Grace CPU的3倍),SOCAMM LPDDR5XTB 寬頻裝置為1.

Rubin GPU:導入Transformer引擎,NVFP4推理性能高達50PFLOPS,是Blackwell GPU的5倍,向後相容,在保持推理精度的同時提升BF16/FP4級別的性能;NVFP4訓練性能達到35PFLOPS,是Blackwell的3.5倍。
Rubin也是第一個支援HBM4的平台,HBM4頻寬達22TB/s,是上一代的2.8倍,能夠為苛刻的MoE模型和AI工作負載提供所需性能。

NVLink 6 Switch:單lane速率提升至400Gbps,採用SerDes技術實現高速訊號傳輸;每顆GPU可實現3.6TB/s的全互連通訊頻寬,是上一代的2倍,總頻寬為28.8TB/s,FP8精度下in-network運算效能達到14.4TFLOPS,支援100%。

NVIDIA ConnectX-9 SuperNIC:每顆GPU提供1.6Tb/s頻寬,針對大規模AI進行了最佳化,具備完全軟體定義、可程式化、加速的資料路徑。

NVIDIA BlueField-4: 800Gbps DPU,用於智慧網卡和儲存處理器,配備64核心Grace CPU,結合ConnectX-9 SuperNIC,用於卸載網路與儲存相關的運算任務,同時增強了網路安全能力,運算效能是上一代的6倍,記憶體頻寬達3倍,GPU存取資料儲存的速度提升至2倍。

NVIDIA Vera Rubin NVL72:在系統層面將上述所有組件整合成單機架處理系統,擁有2兆顆電晶體,NVFP4推理性能達3.6EFLOPS,NVFP4訓練性能達2.5EFLOPS。
該系統LPDDR5X記憶體容量達54TB,是上一代的2.5倍;總HBM4內存達20.7TB,是上一代的1.5倍;HBM4頻寬是1.6PB/s,是上一代的2.8倍;總縱向擴展頻寬達到260TB/s,超過全球互聯網的總頻寬規模。

本系統基於第三代MGX機架設計,計算托盤採用模組化、無主機、無纜化、無風扇設計,使組裝和維護速度比GB200快18倍。原本需要2小時的組裝工作,現在只需5分鐘左右,原本系統使用約80%的液冷,目前已經100%使用液冷。單一系統本身就重達2噸,加上水冷液後就能達到2.5噸。

NVLink Switch托盤顆實現零停機維護與容錯,在托盤被移除或部分部署時機架仍可運作。第二代RAS引擎可進行零停機運轉狀況檢查。
這些特性提升了系統運作時間與吞吐率,進一步降低訓練與推理成本,滿足資料中心對高可靠性、高可維護性的要求。
已有超過80家MGX合作夥伴準備好支援Rubin NVL72在超大規模網路中的部署。
02.三大新品爆改AI推理效率:新CPO裝置、新上下文儲存層、新DGX SuperPOD
同時,英偉達發布了3款重要新品:NVIDIA Spectrum-X乙太網路共封裝光學元件、NVIDIA推理上下文記憶體儲存平台、基於DGX Vera Rubin NVL72的NVIDIA DGX SuperPOD。
1、NVIDIA Spectrum-X乙太網路共封裝光學元件
NVIDIA Spectrum-X乙太網路共封裝光學元件基於Spectrum-X架構,採用2顆晶片設計,採用200Gbps SerDes,每顆ASIC顆可提供102.4Tb/s頻寬。
此交換平台包括一個512埠高密度系統,以及一個128埠緊湊系統,每個埠的速率均為800Gb/s。

CPO(共封裝光學)交換系統可達到5倍的能源效率提升、10倍的可靠性提升、5倍的應用程式正常運作時間提升。
這意味著每天可以處理更多token,從而進一步降低資料中心的總擁有成本(TCO)。
2、NVIDIA推理上下文記憶體儲存平台
NVIDIA推理上下文記憶體儲存平台是一個POD級AI原生儲存基礎設施,用於儲存KV Cache,基於BlueField-4與Spectrum-X Ethernet加速,與NVIDIA Dynamo和NVLink緊密耦合,實現記憶體、儲存、網路之間的協同上下文調度。
本平台將上下文視為一等資料型態處理,可達到5倍的推理效能、5倍的更優能效。

這對改進多輪對話、RAG、Agentic多步驟推理等長上下文應用至關重要,這些工作負載高度依賴上下文在整個系統中被高效儲存、重複使用與共享的能力。
AI正在從聊天機器人演進為Agentic AI(智能體),會推理、調用工具並長期維護狀態,上下文視窗已擴展到數百萬個token。這些上下文保存在KV Cache中,每一步都重新計算會浪費GPU時間並帶來巨大延遲,因此需要儲存。
但GPU顯存雖快卻稀缺,傳統網路儲存對短期上下文而言效率過低。 AI推理瓶頸正從運算轉向上下文儲存。所以需要一個介於GPU與儲存之間、專為推理優化的新型記憶體層。

這一層不再是事後補丁,而必須與網路儲存協同設計,以最低的開銷行動上下文資料。
作為一種新型儲存層級,NVIDIA推理上下文記憶體儲存平台並非直接存在於主機系統中,而是透過BlueField-4連接到運算設備之外。其關鍵優勢在於,可以更有效率地擴展儲存池規模,從而避免重複運算KV Cache。
英偉達正與儲存合作夥伴緊密合作,將NVIDIA推理上下文記憶體儲存平台引入Rubin平台,使客戶能夠將其作為完整整合AI基礎設施的一部分進行部署。
3.基於Vera Rubin建構的NVIDIA DGX SuperPOD
在系統層面,NVIDIA DGX SuperPOD作為大規模AI工廠部署藍圖,採用8套DGX Vera Rubin NVL72系統,用NVLink 6縱向擴展網絡,用Spectrum-X Ethernet橫向擴展網絡,內置NVIDIA推理上下文內存存儲平台,並經過工程化驗證。
整個系統由NVIDIA Mission Control軟體管理,實現極致效率。客戶可將其作為交鑰匙平台部署,以更少GPU完成訓練與推理任務。
由於在6款晶片、托盤、機架、Pod、資料中心與軟體層面實現了極致協同設計,Rubin平台在訓練與推理成本上實現了大幅下降。與上一代Blackwell相比,訓練相同規模的MoE模型,僅需1/4的GPU數量;在相同延遲下,大型MoE模型的token成本降低至1/10。
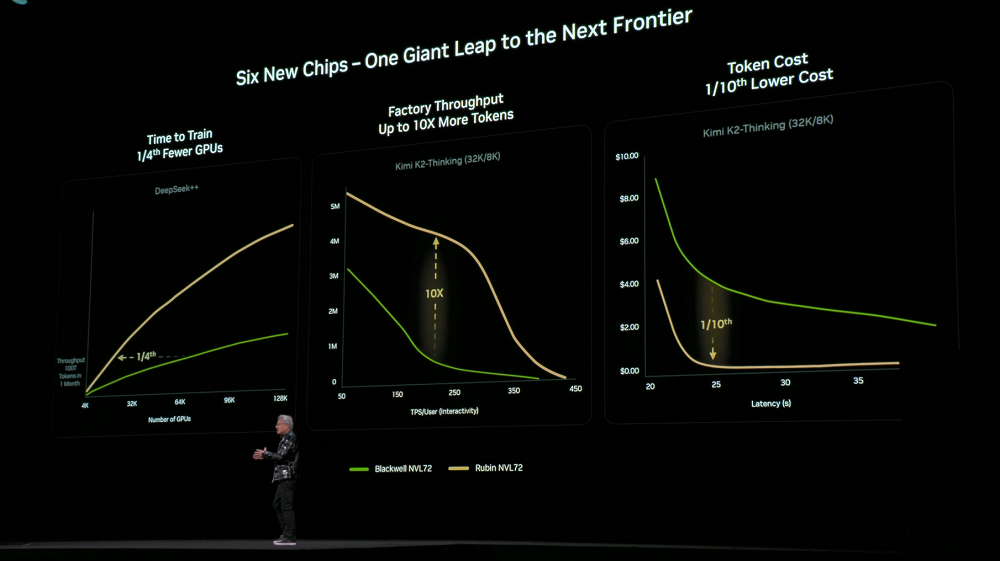
採用DGX Rubin NVL8系統的NVIDIA DGX SuperPOD也一併發布。
透過Vera Rubin架構,英偉達正與合作夥伴和客戶一起,建構世界上規模最大、最先進、成本最低的AI系統,加速AI的主流化落地。

Rubin基礎設施將於今年下半年透過CSP與系統整合商提供,微軟等將成為首批部署者。
03.開放模型宇宙再擴展:新模型、資料、開源生態的重要貢獻者
在軟體與模型層面,英偉達持續加強開源投入。
OpenRouter等主流開發平台顯示,過去一年,AI模型使用量成長20倍,其中約1/4的token來自開源模型。
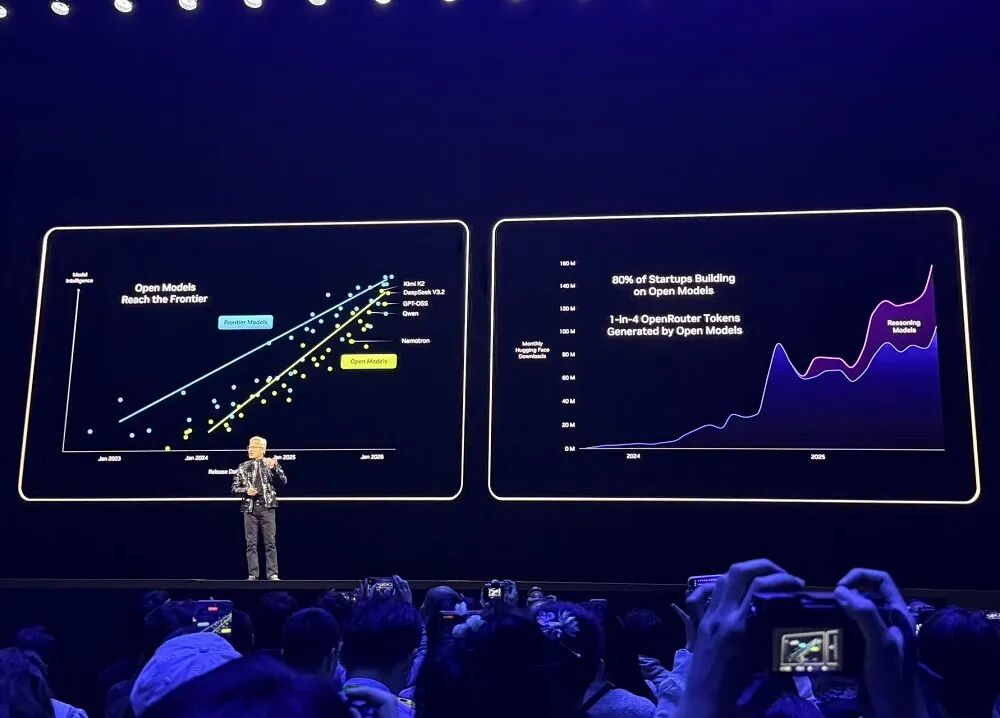
2025年,英偉達是Hugging Face上開源模型、資料和配方的最大貢獻者,發布了650個開源模型和250個開源資料集。

英偉達的開源模型在多項排行榜中名列前茅。開發者不僅可以使用這些開源模型,還可以從中學習、持續訓練、擴展資料集,並使用開源工具和文件化技術來建立AI系統。

受到Perplexity的啟發,黃仁勳觀察到,Agents應該是多模式、多雲和混合雲的,這也是Agentic AI系統的基本架構,幾乎所有的創企都在採用。
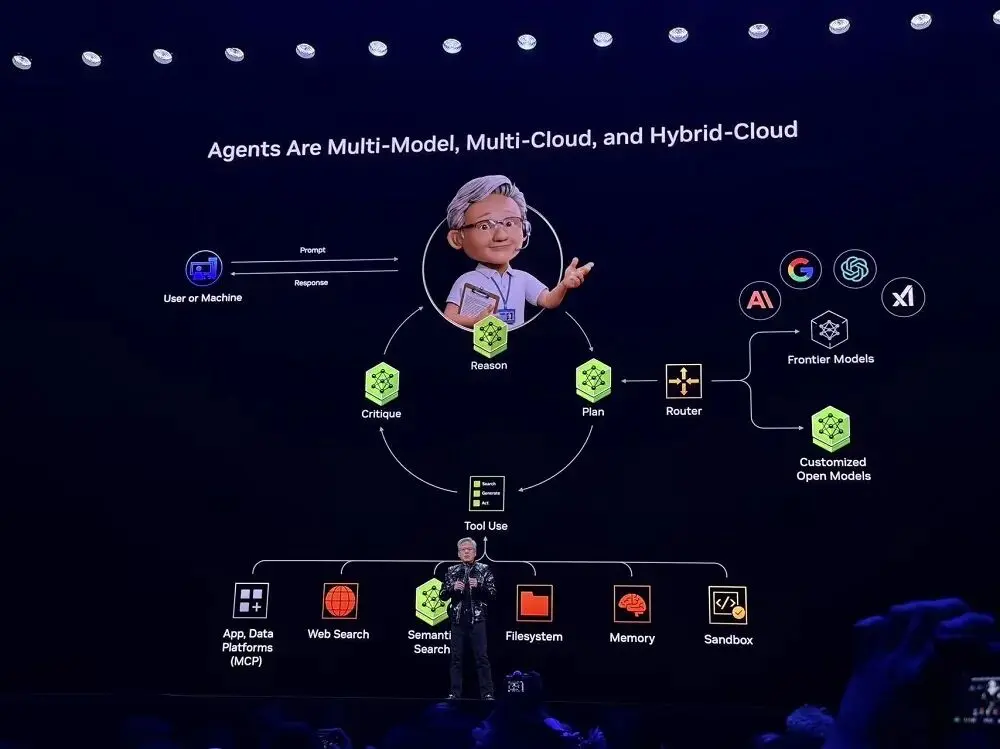
借助英偉達提供的開源模型和工具,開發者現在也可以客製化AI系統,並使用最前沿的模型能力。目前,英偉達已經將上述框架整合為“藍圖”,並整合到SaaS平台中去。使用者可以藉助藍圖實現快速部署。
在現場示範的案例中,此系統系統可依據使用者意圖,自動判斷任務應由本地私有模型或雲端前緣模型處理,也可呼叫外部工具(如郵件API、機器人控制介面、日曆服務等),並實現多模態融合,統一處理文字、語音、影像、機器人感測訊號等資訊。
這些複雜的能力在過去是絕對無法想像的,但如今已經變得微不足道。在ServiceNow、Snowflake等企業平台上,都能運用到類似的能力。
04.開源Alpha-Mayo模型,讓自動駕駛汽車“思考”
英偉達相信實體AI和機器人最終將成為全球最大的消費性電子細分市場。所有能夠移動的事物,最終將實現完全自主,由物理AI驅動。
AI已經經歷了感知AI、生成式AI、Agentic AI階段,現在正進入物理AI時代,智慧走入真實世界,這些模型能夠理解物理規律,並直接從物理世界的感知中生成行動。
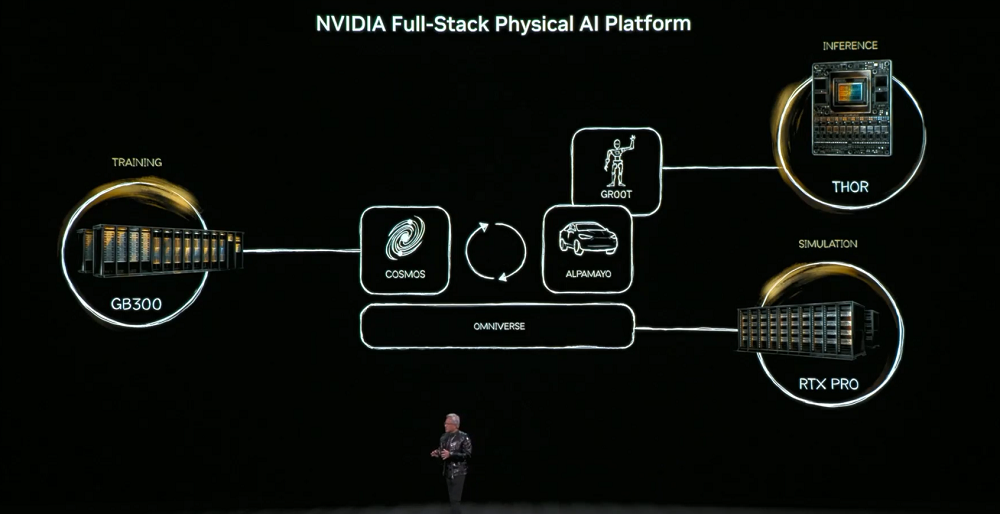
不要要達成這個目標,物理AI必須學會世界的常識──物體恆存、重力、摩擦。這些能力的取得將依賴三台電腦:訓練電腦(DGX)用於打造AI模型,推理電腦(機器人/車載晶片)用於即時執行,模擬電腦(Omniverse)用於產生合成資料、驗證物理邏輯。
而其中的核心模型是Cosmos世界基礎模型,將語言、影像、3D與物理法則對齊,支撐從模擬產生訓練資料的全連結。
實體AI將出現在三類實體:建築(如工廠、倉庫),機器人,自動駕駛汽車。
黃仁勳認為,自動駕駛將成為實體AI的第一個大規模應用場景。此類系統需要理解現實世界、做出決策並執行動作,對安全性、模擬和資料要求極高。
對此,英偉達發布Alpha-Mayo,一個由開源模型、模擬工具和實體AI資料集組成的完整體系,用於加速安全、基於推理的實體AI開發。
其產品組合為全球車企、供應商、創企和研究人員提供建置L4級自動駕駛系統的基礎模組。

Alpha-Mayo這是業界首個真正讓自動駕駛汽車「思考」的模型,這個模型已經開源。它透過將問題拆解為步驟,對所有可能性進行推理,並選擇最安全的路徑。

這種推理型任務-行動模型使自動駕駛系統能夠解決以前從未經歷過的複雜邊緣場景,例如繁忙路口的交通燈失效。
Alpha-Mayo擁有100億個參數,規模足以處理自動駕駛任務,同時又足夠輕量,可運行在為自動駕駛研究人員打造的工作站上。
它能接收文字、環景攝影機、車輛歷史狀態和導航輸入,並輸出行駛軌跡和推理過程,讓乘客理解車輛為何採取某個行動。
在現場播放的宣傳片中,在Alpha-Mayo的驅動下,自動駕駛汽車可以在0介入的情況下自主完成行人避讓、預判左轉車輛並變換車道繞開等操作。

黃仁勳稱,搭載Alpha-Mayo的賓士CLA已經投產,還剛被NCAP評為全世界最安全的車款。每條代碼、晶片、系統都經過安全認證。該系統將在美國市場上線,並將在今年稍後推出更強駕駛能力,包括高速公路脫手駕駛,以及城市環境下的端到端自動駕駛。

英偉達也發布了用於訓練Alpha-Mayo的部分資料集、開源推理模型評估模擬架構Alpha-Sim。開發者可以使用自有數據對Alpha-Mayo進行微調,也可以使用Cosmos產生合成數據,並在真實數據與合成數據結合的基礎上訓練和測試自動駕駛應用。除此之外,英偉達宣布NVIDIA DRIVE平台現已投入生產。
英偉達宣布,波士頓動力、Franka Robotics、Surgical手術機器人、LG電子、NEURA、XRLabs、智元機器人等全球機器人領導者均基於NVIDIA Isaac和GR00T建構。

黃仁勳還官宣了與西門子的最新合作。西門子正將英偉達CUDA-X、AI模型和Omniverse整合到其EDA、CAE和數位孿生工具與平台組合中。實體AI將被廣泛用於設計、模擬到生產製造和營運的完整流程。
05.結語:左手擁抱開源,右手將硬體系統做到不可取代
隨著AI基礎設施的重心正從訓練轉向大規模推理,平台競爭已從單點算力,演進為覆蓋晶片、機架、網路與軟體的系統工程,目標轉向以最低TCO交付最大推理吞吐,AI正進入「工廠化運作」的新階段。
英偉達非常注重系統級設計,Rubin同時在訓練和推理上實現了性能與經濟性的提升,並能作為Blackwell的即插即用替代方案,可從Blackwell無縫過渡。
在平台定位上,英偉達仍認為訓練至關重要,因為只有快速訓練出最先進模型,推理平台才能真正受益,因此在Rubin GPU中引入NVFP4訓練,進一步提升效能、降低TCO。
同時,這家AI運算巨頭也持續在縱向擴展和橫向擴展架構上大幅強化網路通訊能力,並將上下文視為關鍵瓶頸,實現儲存、網路、運算的協同設計。
英偉達一邊大舉開源,另一邊正將硬體、互連、系統設計做得越來越“不可替代”,這種持續擴大需求、激勵token消耗、推動推理規模化、提供高性價比基礎設施的策略閉環,正為英偉達構築更加堅不可摧的護城河。


