

작성자 | ZeR0 쥔다, 지둥시
편집: 모잉
1월 5일, C114는 라스베이거스에서 NVIDIA 창립자 겸 CEO인 젠슨 황이 CES 2026에서 2026년 첫 기조연설을 했다고 보도했습니다. 황 CEO는 늘 그렇듯 가죽 재킷을 입고 1시간 30분 동안 8가지 중요한 개발 사항을 발표하며 칩과 랙부터 네트워크 설계에 이르기까지 차세대 플랫폼 전반에 대한 심층적인 개요를 제공했습니다.

가속 컴퓨팅 및 AI 인프라 분야에서 NVIDIA는 NVIDIA Vera Rubin POD AI 슈퍼컴퓨터, NVIDIA Spectrum-X 이더넷 코패키지 광학 장치, NVIDIA 추론 컨텍스트 메모리 스토리지 플랫폼, 그리고 DGX Vera Rubin NVL72 기반의 NVIDIA DGX SuperPOD를 출시했습니다.

NVIDIA Vera Rubin POD는 CPU, GPU, 스케일업, 스케일아웃, 스토리지 및 처리 기능을 포괄하는 NVIDIA 자체 개발 칩 6개를 사용합니다. 모든 구성 요소는 고급 모델의 요구 사항을 충족하고 컴퓨팅 비용을 절감하도록 공동 설계되었습니다.
그중 Vera CPU는 올림푸스 맞춤형 코어 아키텍처를 채택했고, Rubin GPU는 Transformer 엔진을 도입하여 최대 50 PFLOPS의 NBFP4 추론 성능과 GPU당 최대 3.6TB/s의 NVLink 대역폭을 제공합니다. 또한 3세대 범용 기밀 컴퓨팅(최초의 랙 레벨 TEE)을 지원하며 CPU와 GPU 영역에 걸쳐 완벽한 신뢰 실행 환경을 구현합니다.

이 칩들은 모두 공장으로 반환되었고, NVIDIA는 NVIDIA Vera Rubin NVL72 시스템 전체를 검증했으며, 파트너사들은 통합 AI 모델과 알고리즘 실행을 시작했고, 전체 생태계는 Vera Rubin 배포를 준비하고 있습니다.
다른 발표 내용으로는 NVIDIA Spectrum-X Ethernet 코패키징 광학 장치가 전력 효율성과 애플리케이션 가동 시간을 크게 최적화한다는 점, NVIDIA 추론 컨텍스트 메모리 스토리지 플랫폼이 스토리지 스택을 재정의하여 중복 연산을 줄이고 추론 효율성을 향상시킨다는 점, 그리고 DGX Vera Rubin NVL72 기반의 NVIDIA DGX SuperPOD가 대규모 MoE 모델의 토큰 비용을 1/10로 줄인다는 점 등이 있습니다.

오픈 모델과 관련하여 NVIDIA는 오픈 소스 모델 제품군 확장을 발표하며 새로운 모델, 데이터 세트 및 라이브러리를 공개했습니다. 여기에는 NVIDIA Nemotron 오픈 소스 모델 제품군에 Agentic RAG 모델, 안전 모델 및 음성 모델이 추가되었으며, 모든 유형의 로봇에 적용 가능한 완전히 새로운 오픈 모델도 포함됩니다. 그러나 젠슨 황은 발표에서 이러한 세부 사항에 대해 자세히 설명하지 않았습니다.
물리적 AI 분야에서 ChatGPT 시대가 도래했습니다 . NVIDIA의 풀스택 기술은 AI 기반 로봇 공학을 통해 전 세계 산업을 혁신할 수 있는 글로벌 생태계를 구축합니다. 새로운 Alpamayo 오픈 소스 모델 제품군을 포함한 NVIDIA의 광범위한 AI 툴킷은 전 세계 운송 업계가 안전한 레벨 4 자율주행을 신속하게 구현할 수 있도록 지원합니다. NVIDIA DRIVE 자율주행 플랫폼은 현재 양산 중이며, 모든 신형 메르세데스-벤츠 CLA에 탑재되어 레벨 2++ AI 기반 주행을 제공합니다.

01. 완전히 새로운 AI 슈퍼컴퓨터: 자체 개발 칩 6개 탑재, 단일 랙 컴퓨팅 성능 3.6 EFLOPS 달성
젠슨 황은 컴퓨터 산업이 10~15년마다 완전히 재편된다고 믿지만, 이번에는 CPU에서 GPU로, "프로그래밍 소프트웨어"에서 "학습 소프트웨어"로의 전환과 가속 컴퓨팅, 그리고 인공지능(AI)이라는 두 가지 플랫폼 혁명이 동시에 일어나고 있다고 말합니다. 이 두 혁명은 전체 컴퓨팅 스택을 재편하고 있습니다. 지난 10년간 10조 달러 규모로 성장한 컴퓨팅 산업은 현대화 과정을 거치고 있습니다.
동시에 컴퓨팅 파워에 대한 수요는 급증했습니다. 모델의 크기는 매년 10배씩 증가하고, 모델 사고에 사용되는 토큰 수는 매년 5배씩 증가하는 반면, 각 토큰의 가격은 매년 10배씩 감소합니다.
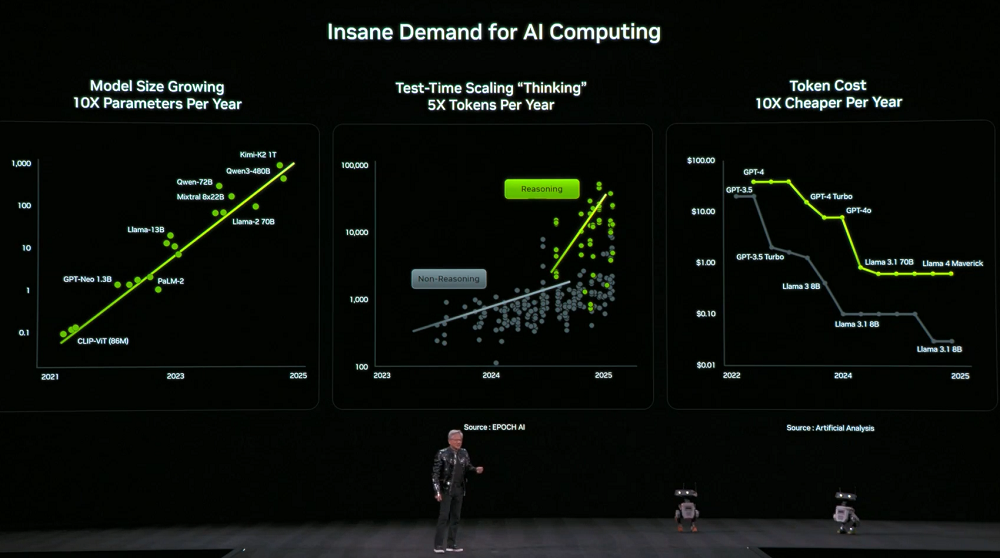
이러한 수요를 충족하기 위해 엔비디아는 매년 새로운 컴퓨팅 하드웨어를 출시하기로 결정했습니다. 젠슨 황은 베라 루빈이 현재 본격적인 생산에 들어갔다고 밝혔습니다.
NVIDIA의 새로운 AI 슈퍼컴퓨터인 NVIDIA Vera Rubin POD는 Vera CPU, Rubin GPU, NVLink 6 스위치, ConnectX-9(CX9) 스마트 네트워크 카드, BlueField-4 DPU, Spectrum-X 102.4T CPO 등 자체 개발한 6개의 칩을 사용합니다.
Vera CPU: 데이터 이동 및 에이전트 처리를 위해 설계된 이 CPU는 88개의 맞춤형 NVIDIA Olympus 코어, 176개의 NVIDIA Space 멀티스레딩 스레드, CPU-GPU 통합 메모리를 위한 1.8TB/s NVLink-C2C 지원, 최대 1.5TB의 시스템 메모리(Grace CPU의 3배), 1.2TB/s의 SOCAMM LPDDR5X 메모리 대역폭을 특징으로 하며, 랙 수준의 기밀 컴퓨팅을 지원하여 데이터 처리 성능을 두 배로 향상시킵니다.

Rubin GPU: Transformer 엔진을 도입하여 NVFP4 추론 성능이 최대 50 PFLOPS에 달하며, 이는 Blackwell GPU보다 5배 높은 성능입니다. 하위 호환성을 유지하면서 BF16/FP4 수준의 성능을 향상시키고 추론 정확도를 유지합니다. NVFP4 학습 성능은 35 PFLOPS에 이르며, 이는 Blackwell보다 3.5배 높은 성능입니다.
Rubin은 또한 22TB/s의 대역폭을 자랑하는 HBM4를 지원하는 최초의 플랫폼으로, 이전 세대보다 2.8배 빠른 성능을 제공하여 까다로운 MoE 모델 및 AI 워크로드에 필요한 성능을 제공합니다.

NVLink 6 스위치: SerDes 기술을 사용하여 고속 신호 전송을 구현하고 단일 레인 속도를 400Gbps로 향상시켰습니다. 각 GPU는 이전 세대보다 두 배 빠른 3.6TB/s의 전체 상호 연결 통신 대역폭을 달성할 수 있으며, 총 대역폭은 28.8TB/s에 달합니다. 또한 FP8 정밀도에서 14.4TFLOPS의 네트워크 내 컴퓨팅 성능을 제공하며 100% 액체 냉각을 지원합니다.

NVIDIA ConnectX-9 SuperNIC: 각 GPU는 대규모 AI에 최적화된 1.6Tb/s의 대역폭을 제공하며, 완전 소프트웨어 정의 방식의 프로그래밍 가능하고 가속되는 데이터 경로를 특징으로 합니다.

NVIDIA BlueField-4: 스마트 네트워크 카드 및 스토리지 프로세서용 800Gbps DPU로, 64코어 Grace CPU와 ConnectX-9 SuperNIC를 탑재하여 네트워크 및 스토리지 관련 컴퓨팅 작업을 분담하고 네트워크 보안 기능을 강화합니다. 이전 세대 대비 6배 향상된 컴퓨팅 성능, 3배 빠른 메모리 대역폭, 그리고 최대 2배 빠른 GPU 데이터 스토리지 접근 속도를 제공합니다.

NVIDIA Vera Rubin NVL72: 2조 개의 트랜지스터, 3.6 EFLOPS의 NVFP4 추론 성능, 2.5 EFLOPS의 NVFP4 학습 성능을 갖춘 시스템 수준에서 위의 모든 구성 요소를 단일 랙 처리 시스템으로 통합합니다.
이 시스템은 이전 세대보다 2.5배 많은 54TB의 LPDDR5X 메모리, 이전 세대보다 1.5배 많은 20.7TB의 HBM4 메모리, 이전 세대보다 2.8배 많은 1.6PB/s의 HBM4 대역폭, 그리고 전 세계 인터넷의 총 대역폭을 능가하는 260TB/s의 수직 확장 대역폭을 갖추고 있습니다.

3세대 MGX 랙 설계를 기반으로 하는 이 시스템은 모듈식, 호스트리스, 케이블리스, 팬리스 컴퓨팅 트레이를 특징으로 하여 조립 및 유지 관리가 GB200보다 18배 빠릅니다. 기존에 2시간이 걸리던 조립 시간이 이제 약 5분으로 단축되었으며, 시스템 냉각 방식 또한 기존 약 80%에서 100% 액체 냉각으로 개선되었습니다. 시스템 자체 무게는 2톤이며, 냉각제를 추가하면 2.5톤에 달합니다.

NVLink 스위치 트레이는 가동 중지 시간 없이 유지 보수 및 장애 복구를 지원하여 트레이가 제거되거나 부분적으로 설치된 경우에도 랙이 계속 작동할 수 있도록 합니다. 2세대 RAS 엔진은 가동 중지 시간 없이 작동 상태를 확인할 수 있도록 합니다.
이러한 기능은 시스템 가동 시간과 처리량을 향상시키고, 학습 및 추론 비용을 더욱 절감하며, 데이터 센터의 높은 신뢰성과 유지 관리 용이성에 대한 요구 사항을 충족합니다.
80개 이상의 MGX 파트너사가 하이퍼스케일 네트워크에 Rubin NVL72를 배포하는 것을 지원할 준비가 되어 있습니다.
02. 세 가지 주요 신제품이 AI 추론 효율성을 혁신적으로 향상시킵니다: 새로운 CPO 장치, 새로운 컨텍스트 저장 계층, 그리고 새로운 DGX SuperPOD.
이와 동시에 NVIDIA는 NVIDIA Spectrum-X 이더넷 코패키징 광학 장치, NVIDIA 추론 컨텍스트 메모리 스토리지 플랫폼, 그리고 DGX Vera Rubin NVL72 기반의 NVIDIA DGX SuperPOD 등 세 가지 중요한 신제품을 출시했습니다.
1. NVIDIA Spectrum-X 이더넷 코패키지 광학 부품
NVIDIA Spectrum-X 이더넷 코패키지 광학 모듈은 Spectrum-X 아키텍처를 기반으로 하며, 2칩 설계를 채택하고, 200Gbps SerDes를 사용하며, 각 ASIC는 102.4Tb/s의 대역폭을 제공할 수 있습니다.
스위칭 플랫폼에는 512포트 고밀도 시스템과 128포트 소형 시스템이 포함되어 있으며, 각각 800Gb/s의 속도를 제공합니다.

CPO(Co-packaged Optical) 스위칭 시스템은 에너지 효율 5배, 신뢰성 10배, 애플리케이션 가동 시간 5배 향상을 달성할 수 있습니다.
이는 매일 더 많은 토큰을 처리할 수 있게 되어 데이터 센터의 총 소유 비용(TCO)을 더욱 절감할 수 있음을 의미합니다.
2. NVIDIA 추론 컨텍스트 메모리 스토리지 플랫폼
NVIDIA 추론 컨텍스트 메모리 스토리지 플랫폼은 키-값 캐시를 저장하기 위한 POD 수준의 AI 네이티브 스토리지 인프라입니다. BlueField-4 및 Spectrum-X 이더넷으로 가속되며, NVIDIA Dynamo 및 NVLink와 긴밀하게 연동되어 메모리, 스토리지 및 네트워크 간의 협업 컨텍스트 스케줄링을 구현합니다.
이 플랫폼은 컨텍스트를 핵심 데이터 유형으로 취급하여 추론 성능을 5배, 에너지 효율성을 5배 향상시킵니다.

이는 다중 턴 대화, RAG, 에이전트 기반 다단계 추론과 같이 시스템 전체에서 컨텍스트를 효율적으로 저장, 재사용 및 공유하는 기능에 크게 의존하는 장기 컨텍스트 애플리케이션의 성능 향상에 매우 중요합니다.
인공지능은 챗봇에서 추론하고, 도구를 호출하며, 장기간 상태를 유지할 수 있는 에이전트형 인공지능으로 진화하고 있습니다. 컨텍스트 윈도우는 수백만 개의 토큰으로 확장되었습니다. 이러한 컨텍스트는 키-값 캐시에 저장되는데, 매 단계마다 이를 다시 계산하는 것은 GPU 시간을 낭비하고 상당한 지연 시간을 발생시켜 저장 공간을 필요로 합니다.
하지만 GPU 메모리는 빠르지만 용량이 부족하고, 기존 네트워크 스토리지는 단기 컨텍스트 저장에 너무 비효율적입니다. AI 추론의 병목 현상은 연산에서 컨텍스트 저장으로 이동하고 있습니다. 따라서 GPU와 스토리지 사이에 위치하는, 추론에 특화된 새로운 유형의 메모리 계층이 필요합니다.

이 계층은 더 이상 반응형 패치가 아니라, 최소한의 오버헤드로 컨텍스트 데이터를 이동하기 위해 네트워크 스토리지와 연동하여 설계되어야 합니다.
새로운 스토리지 계층인 NVIDIA 추론 컨텍스트 메모리 스토리지 플랫폼은 호스트 시스템에 직접 상주하지 않고 BlueField-4를 통해 컴퓨팅 장치에 연결됩니다. 이 플랫폼의 핵심 장점은 스토리지 풀을 더욱 효율적으로 확장하여 키-값 캐시의 중복 계산을 방지할 수 있다는 점입니다.
NVIDIA는 스토리지 파트너와 긴밀히 협력하여 NVIDIA 추론 컨텍스트 메모리 스토리지 플랫폼을 Rubin 플랫폼에 통합함으로써 고객이 이를 완벽하게 통합된 AI 인프라의 일부로 배포할 수 있도록 지원하고 있습니다.
3. Vera Rubin 기반의 NVIDIA DGX SuperPOD
시스템 수준에서 NVIDIA DGX SuperPOD는 대규모 AI 팩토리 구축을 위한 청사진 역할을 합니다. 이 시스템은 8개의 DGX Vera Rubin NVL72 시스템을 사용하고, NVLink 6를 통해 네트워크를 수직으로 확장하고, Spectrum-X 이더넷을 통해 네트워크를 수평으로 확장하며, NVIDIA 추론 컨텍스트 메모리 스토리지 플랫폼을 통합하고, 엔지니어링 검증을 거쳤습니다.
전체 시스템은 NVIDIA Mission Control 소프트웨어로 관리되어 최고의 효율성을 제공합니다. 고객은 이 시스템을 즉시 사용 가능한 플랫폼으로 구축하여 더 적은 GPU로 학습 및 추론 작업을 완료할 수 있습니다.
6개의 칩, 트레이, 랙, 포드, 데이터 센터 및 소프트웨어 전반에 걸친 고도의 협업 설계 덕분에 Rubin 플랫폼은 학습 및 추론 비용을 크게 절감했습니다. 이전 세대 Blackwell과 비교했을 때, 동일한 크기의 MoE 모델을 학습하는 데 필요한 GPU 수는 1/4에 불과하며, 동일한 지연 시간에서 대규모 MoE 모델의 토큰 비용은 1/10로 줄어듭니다.
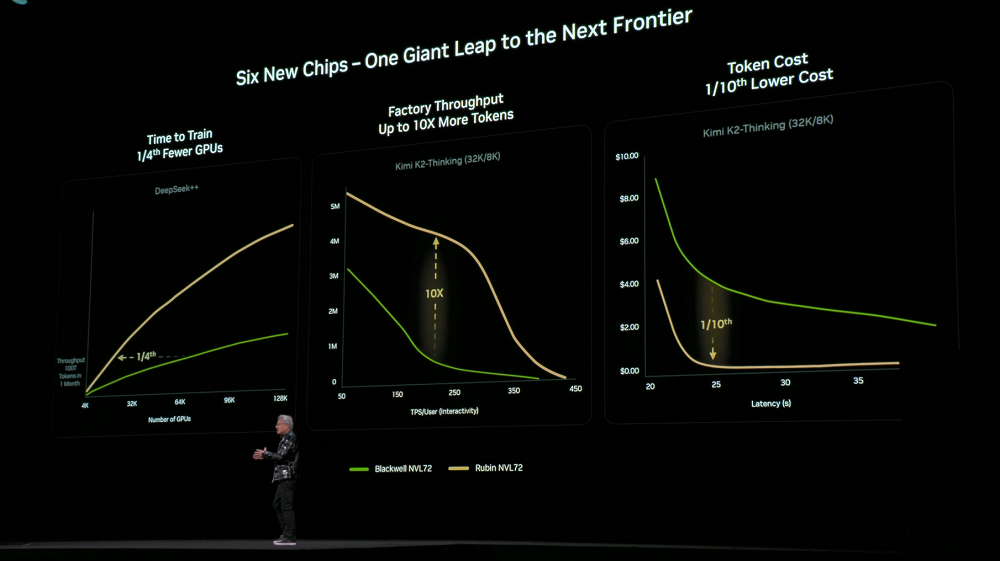
NVIDIA DGX Rubin NVL8 시스템을 사용하는 NVIDIA DGX SuperPOD도 같은 시기에 출시되었습니다.
NVIDIA는 Vera Rubin 아키텍처를 활용하여 파트너 및 고객과 협력하여 세계 최대 규모, 가장 진보된, 그리고 가장 저렴한 AI 시스템을 구축함으로써 AI의 주류 도입을 가속화하고 있습니다.

Rubin 인프라는 올해 하반기에 CSP(클라우드 서비스 제공업체)와 시스템 통합업체를 통해 제공될 예정이며, 마이크로소프트를 비롯한 여러 기업이 최초로 이를 도입할 것으로 예상됩니다.
03. 오픈 모델 생태계 확장: 새로운 모델, 데이터 및 오픈 소스 생태계에 핵심적인 기여
NVIDIA는 소프트웨어 및 모델 수준에서 오픈 소스에 대한 투자를 지속적으로 확대하고 있습니다.
OpenRouter와 같은 주요 개발 플랫폼의 데이터에 따르면 AI 모델 사용량은 지난 1년 동안 20배 증가했으며, 그중 약 4분의 1은 오픈 소스 모델에서 나온 것입니다.
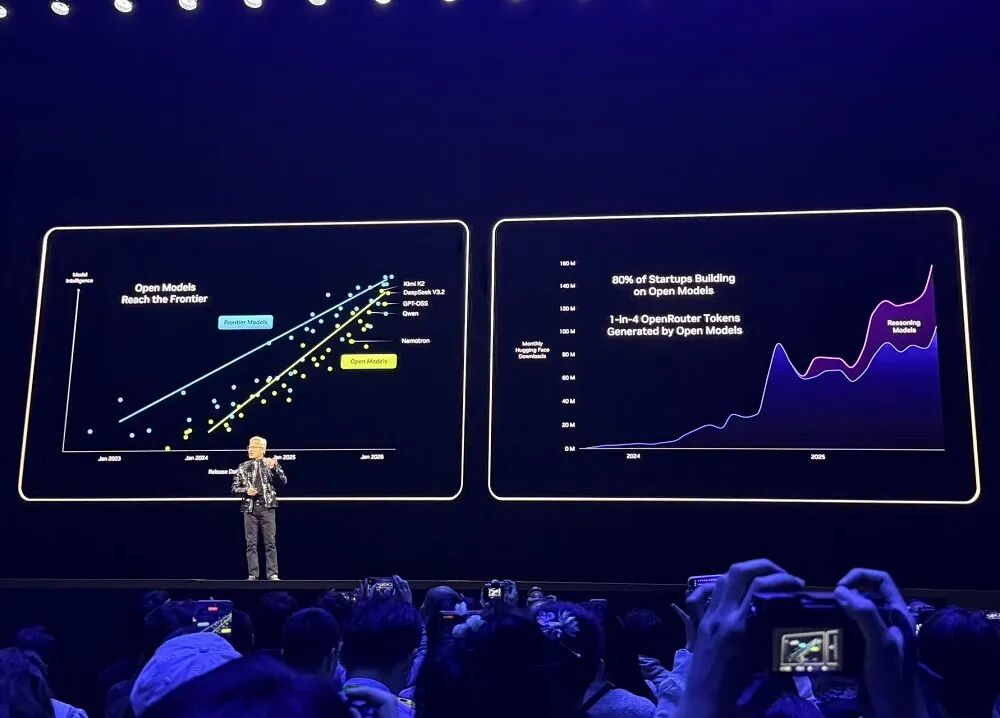
2025년 NVIDIA는 Hugging Face에서 오픈 소스 모델, 데이터 및 레시피에 가장 많이 기여한 기업으로, 650개의 오픈 소스 모델과 250개의 오픈 소스 데이터 세트를 공개했습니다.

NVIDIA의 오픈 소스 모델은 다양한 순위표에서 꾸준히 높은 순위를 차지하고 있습니다. 개발자는 이러한 오픈 소스 모델을 사용할 뿐만 아니라, 이를 통해 학습하고, 지속적으로 훈련시키고, 데이터 세트를 확장하고, 오픈 소스 도구 및 문서화 기술을 활용하여 AI 시스템을 구축할 수 있습니다.

Perplexity에서 영감을 받은 Jensen Huang은 에이전트가 멀티 모델, 멀티 클라우드, 하이브리드 클라우드를 지원해야 한다는 점을 발견했는데, 이는 에이전트 기반 AI 시스템의 기본 아키텍처이기도 하며 거의 모든 스타트업이 이를 채택하고 있습니다.
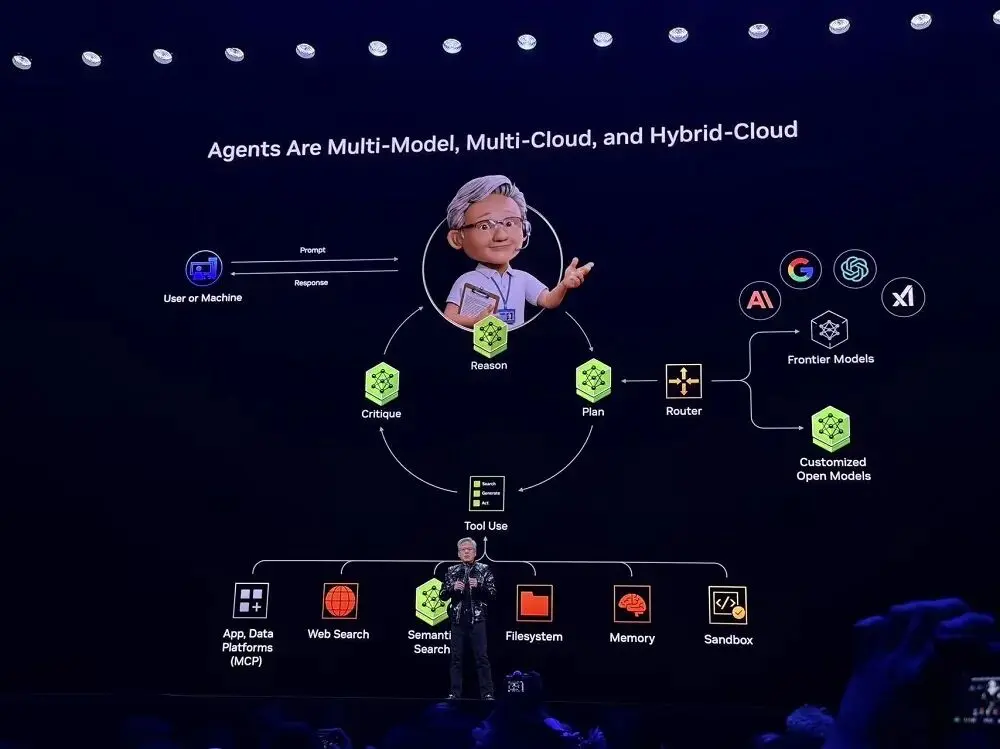
NVIDIA가 제공하는 오픈 소스 모델과 도구를 활용하면 개발자는 이제 AI 시스템을 맞춤 설정하고 최첨단 모델 기능을 사용할 수 있습니다. NVIDIA는 이 프레임워크를 "블루프린트"에 통합하고 이를 자사의 SaaS 플랫폼에 포함시켰습니다. 사용자는 블루프린트를 사용하여 신속하게 시스템을 배포할 수 있습니다.
현장 시연에서 이 시스템은 사용자의 의도를 기반으로 로컬 프라이빗 모델 또는 클라우드 기반 프론티어 모델 중 어느 쪽에서 작업을 처리해야 하는지 자동으로 판단할 수 있습니다. 또한 외부 도구(이메일 API, 로봇 제어 인터페이스, 캘린더 서비스 등)를 호출하여 텍스트, 음성, 이미지, 로봇 센서 신호와 같은 정보를 통합적으로 처리하는 멀티모달 융합 기능을 구현할 수 있습니다.
이러한 복잡한 기능들은 과거에는 상상도 할 수 없었지만, 이제는 일반적인 것이 되었습니다. ServiceNow나 Snowflake와 같은 엔터프라이즈 플랫폼에서도 유사한 기능들을 찾아볼 수 있습니다.
04. 오픈소스 알파-메이요 모델은 자율주행차가 "생각"할 수 있도록 합니다.
엔비디아는 물리적 AI와 로봇공학이 결국 세계 최대의 소비자 전자제품 시장이 될 것이라고 믿습니다. 움직일 수 있는 모든 것은 결국 물리적 AI에 의해 구동되는 완전 자율화를 경험하게 될 것입니다.
인공지능은 지각 인공지능, 생성 인공지능, 에이전트 인공지능 단계를 거쳐 이제 물리적 인공지능 시대로 진입하고 있습니다. 지능이 현실 세계에 발을 들여놓으면서, 이러한 모델들은 물리 법칙을 이해하고 물리적 세계에 대한 인식을 바탕으로 직접적인 행동을 생성할 수 있게 되었습니다.
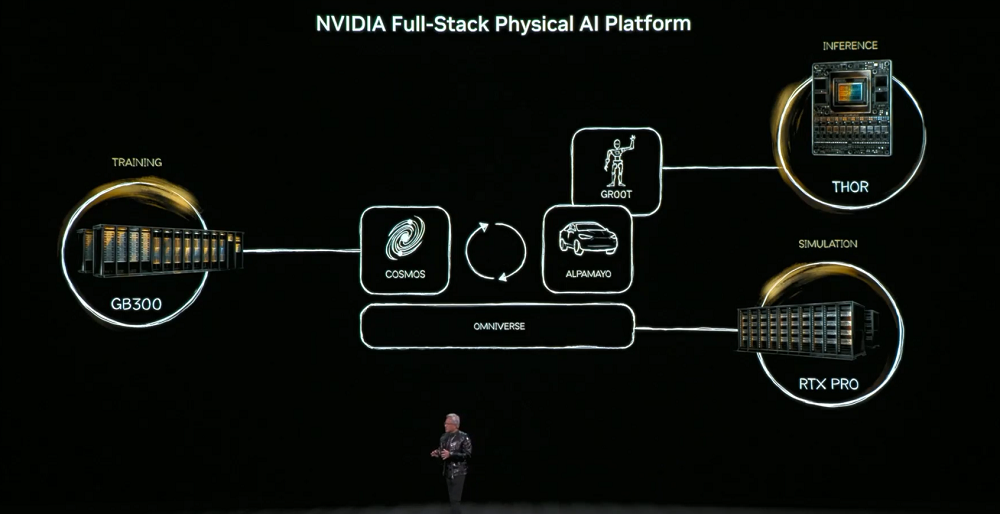
이 목표를 달성하기 위해 물리 AI는 물체 영속성, 중력, 마찰력과 같은 세상의 상식을 학습해야 합니다. 이러한 능력을 습득하려면 세 대의 컴퓨터가 필요합니다. AI 모델 구축을 위한 학습용 컴퓨터(DGX), 실시간 실행을 위한 추론용 컴퓨터(로봇/차량 칩), 그리고 합성 데이터를 생성하고 물리적 논리를 검증하는 시뮬레이션용 컴퓨터(옴니버스)입니다.
핵심 모델은 코스모스 월드 파운데이션 모델로, 언어, 이미지, 3D 및 물리 법칙을 통합하여 시뮬레이션부터 훈련 데이터 생성에 이르는 전체 과정을 지원합니다.
물리적 인공지능은 건물(공장 및 창고 등), 로봇, 자율주행 자동차의 세 가지 유형으로 나타날 것입니다.
젠슨 황은 자율 주행이 물리적 AI의 첫 번째 대규모 적용 시나리오가 될 것이라고 믿습니다. 이러한 시스템은 현실 세계를 이해하고, 결정을 내리고, 행동을 실행해야 하므로 안전, 시뮬레이션 및 데이터에 대한 요구 사항이 매우 높습니다.
이에 NVIDIA는 안전하고 추론 기반의 물리적 AI 개발을 가속화하기 위해 오픈 소스 모델, 시뮬레이션 도구 및 물리적 AI 데이터 세트로 구성된 완벽한 시스템인 Alpha-Mayo를 출시했습니다.
이 회사의 제품 포트폴리오는 전 세계 자동차 제조업체, 부품 공급업체, 스타트업 및 연구원에게 레벨 4 자율 주행 시스템 구축에 필요한 기본 모듈을 제공합니다.

알파-메이오는 자율주행차가 '생각'할 수 있도록 하는 업계 최초의 진정한 오픈 소스 모델입니다. 문제를 단계별로 나누고, 모든 가능성을 검토하며, 가장 안전한 경로를 선택합니다.

이 추론 기반 작업-행동 모델은 자율 주행 시스템이 이전에 경험하지 못했던 복잡한 예외 상황, 예를 들어 혼잡한 교차로에서의 신호등 고장과 같은 상황을 처리할 수 있도록 합니다.
Alpha-Mayo는 100억 개의 매개변수를 가지고 있어 자율 주행 작업을 처리할 만큼 충분히 크지만, 자율 주행 연구원을 위해 설계된 워크스테이션에서도 실행될 만큼 가볍습니다.
이 시스템은 텍스트, 서라운드 뷰 카메라 데이터, 차량 이력 상태 및 내비게이션 입력을 수신하고 주행 궤적과 추론 과정을 출력하여 승객이 차량이 특정 행동을 취한 이유를 이해할 수 있도록 합니다.
행사에서 상영된 홍보 영상에서는 알파-메이요가 운전하는 자율주행차가 보행자 회피, 좌회전 차량 예측, 차선 변경 등을 운전자의 개입 없이 자율적으로 수행할 수 있는 모습이 소개되었습니다.

젠슨 황은 알파-마요(Alpha-Mayo) 시스템이 탑재된 메르세데스-벤츠 CLA가 이미 생산 중이며, 최근 NCAP(미국 국립안전시험센터)에서 세계에서 가장 안전한 차로 선정되었다고 밝혔습니다. 모든 코드, 칩, 시스템은 안전 인증을 거쳤습니다. 이 시스템은 미국 시장에 출시될 예정이며, 올해 하반기에는 고속도로 핸즈프리 주행과 도심 환경에서의 완전 자율 주행을 포함한 향상된 주행 기능을 제공할 것입니다.

NVIDIA는 Alpha-Mayo 학습에 사용된 데이터셋의 일부와 오픈소스 추론 모델 평가 시뮬레이션 프레임워크인 Alpha-Sim도 공개했습니다. 개발자는 자체 데이터를 사용하여 Alpha-Mayo를 미세 조정하거나 Cosmos를 사용하여 합성 데이터를 생성하고, 실제 데이터와 합성 데이터를 조합하여 자율 주행 애플리케이션을 학습 및 테스트할 수 있습니다. 또한 NVIDIA는 NVIDIA DRIVE 플랫폼이 상용화되었다고 발표했습니다.
NVIDIA는 보스턴 다이내믹스, 프랑카 로보틱스, 서지컬, LG 일렉트로닉스, 뉴라, XRLabs, 로직 로보틱스를 포함한 세계 유수의 로봇 기업들이 NVIDIA Isaac 및 GR00T를 기반으로 시스템을 구축하고 있다고 발표했습니다.

젠슨 황 CEO는 지멘스와의 새로운 협력 관계를 공식 발표했습니다. 지멘스는 NVIDIA CUDA-X, AI 모델, 그리고 Omniverse를 자사의 EDA, CAE, 디지털 트윈 툴 및 플랫폼 포트폴리오에 통합할 예정입니다. 물리적 AI는 설계 및 시뮬레이션부터 제조 및 운영에 이르기까지 전체 프로세스에 걸쳐 폭넓게 활용될 것입니다.
05. 결론: 한편으로는 오픈소스를 수용하고, 다른 한편으로는 하드웨어 시스템을 대체 불가능하게 만들어야 합니다.
AI 인프라의 초점이 학습에서 대규모 추론으로 이동함에 따라, 플랫폼 경쟁은 단일 컴퓨팅 성능에서 칩, 랙, 네트워크 및 소프트웨어를 포괄하는 시스템 엔지니어링 접근 방식으로 진화했습니다. 목표는 최저 총소유비용(TCO)으로 최대 추론 처리량을 제공하는 것이며, AI는 "공장식 운영"이라는 새로운 단계로 진입하고 있습니다.
NVIDIA는 시스템 수준 설계에 큰 비중을 두고 있습니다. Rubin은 학습 및 추론에서 성능과 비용 효율성을 모두 향상시키며, Blackwell을 대체할 수 있는 플러그 앤 플레이 방식의 솔루션으로, Blackwell에서 Rubin으로의 원활한 전환을 가능하게 합니다.
플랫폼 포지셔닝 측면에서 NVIDIA는 최첨단 모델을 빠르게 학습시켜야만 추론 플랫폼이 진정한 이점을 얻을 수 있다고 믿기 때문에 학습이 여전히 중요하다고 생각합니다. 따라서 NVIDIA는 성능을 더욱 향상시키고 총소유비용(TCO)을 절감하기 위해 Rubin GPU에 NVFP4 학습 기능을 도입했습니다.
동시에, 이 AI 컴퓨팅 거대 기업은 수직적 및 수평적 확장 아키텍처 모두에서 네트워크 통신 기능을 크게 향상시키고 있으며, 스토리지, 네트워크 및 컴퓨팅의 협업 설계를 달성하는 데 있어 컨텍스트를 핵심 병목 현상으로 간주합니다.
엔비디아는 공격적인 오픈소스 전략을 펼치는 동시에 하드웨어, 인터커넥트, 시스템 설계를 점점 더 "대체 불가능"하게 만들고 있습니다. 수요를 지속적으로 확대하고, 토큰 사용을 장려하며, 추론 확장성을 높이고, 비용 효율적인 인프라를 제공하는 이러한 폐쇄형 전략은 엔비디아에게 더욱 견고한 해자를 구축하고 있습니다.



