
著者: 0xjacobzhao と ChatGPT 4o
アドバイスとフィードバックを提供してくれた Advait Jayant (Peri Labs)、Sven Wellmann (Polychain Capital)、Chao (Metropolis DAO)、Jiahao (Flock)、Alexander Long (Pluralis Research)、Ben Fielding および Jeff Amico (Gensyn) に特に感謝します。
AIバリューチェーン全体において、モデルのトレーニングはリソース消費量と技術的閾値が最も高く、モデルの能力の上限と実際の適用効果を直接決定づける重要なプロセスです。推論段階における軽量な呼び出しと比較すると、トレーニングプロセスは継続的な大規模な計算能力の投入、複雑なデータ処理プロセス、そして高強度の最適化アルゴリズムのサポートを必要とし、AIシステム構築における真の「重工業」と言えるでしょう。アーキテクチャパラダイムの観点から見ると、トレーニング手法は集中型トレーニング、分散型トレーニング、連合学習、そして本稿で焦点を当てる分散型トレーニングの4つのカテゴリーに分けられます。
集中型トレーニングは、単一の組織がローカルの高性能クラスタでトレーニングプロセス全体を完了する、最も一般的な従来の方法です。ハードウェア(NVIDIA GPUなど)、基盤ソフトウェア(CUDA、cuDNNなど)、クラスタスケジューリングシステム(Kubernetesなど)、トレーニングフレームワーク(NCCLバックエンドに基づくPyTorchなど)に至るまで、すべてのコンポーネントが統合制御システムによって調整・運用されます。この緊密に連携するアーキテクチャは、メモリ共有、勾配同期、フォールトトレランスメカニズムの効率を最適化し、GPTやGeminiなどの大規模モデルのトレーニングに非常に適しています。高効率と制御可能なリソースという利点がありますが、データの独占、リソース障壁、エネルギー消費、単一点リスクなどの問題もあります。
分散学習は、大規模モデル学習の主流の手法です。その核心は、モデル学習タスクを細分化し、複数のマシンに分散して協調実行することで、単一マシンのコンピューティングとストレージのボトルネックを打破することです。物理的には「分散」機能を備えていますが、全体的なスケジュールと同期は依然として中央集権的な組織によって制御されます。多くの場合、高速ローカルエリアネットワーク環境で実行されます。NVLink高速相互接続バス技術を介して、マスターノードがすべてのサブタスクを調整します。主流の手法には以下が含まれます。
- データ並列: 各ノードは異なるデータ パラメータをトレーニングして共有するため、モデルの重みを一致させる必要があります。
- モデル並列: モデルの異なる部分を異なるノードにデプロイして、強力なスケーラビリティを実現します。
- パイプライン並列: 段階的にシリアル実行してスループットを向上させます。
- Tensor Parallel: 行列計算のセグメンテーションを改良し、並列粒度を向上させました。
分散学習とは、「集中制御 + 分散実行」を組み合わせたもので、同じ上司が複数の「オフィス」従業員に遠隔指示を出し、協力してタスクを完了させるようなものです。現在、主流の大規模モデル(GPT-4、Gemini、LLaMAなど)のほぼすべてがこの方法で学習されています。
分散型トレーニングは、よりオープンで検閲耐性のある未来への道筋を示しています。その中核となる特徴は、複数の信頼できないノード(家庭用コンピュータ、クラウドGPU、エッジデバイスなど)が、中央コーディネーターを介さずに、通常はプロトコル駆動型のタスク分散と連携を通じてトレーニングタスクを完了し、貢献の誠実性を保証する暗号インセンティブメカニズムを活用することです。このモデルが直面する主な課題は以下のとおりです。
- 異種のデバイスと困難なタスク分割: 異種のデバイスは調整が難しく、タスク分割は非効率的です。
- 通信効率のボトルネック: ネットワーク通信が不安定で、勾配同期のボトルネックが明らかです。
- 信頼できる実行の欠如: 信頼できる実行環境がないため、ノードが実際に計算に関与しているかどうかを確認することが困難です。
- 統一された調整の欠如: 中央スケジューラが存在せず、タスクの配布と例外のロールバックのメカニズムが複雑です。
分散型トレーニングとは、世界中のボランティアがそれぞれ計算能力を持ち寄り、協力してモデルをトレーニングすることを意味します。しかし、「真に実現可能な大規模分散型トレーニング」は、システムアーキテクチャ、通信プロトコル、暗号セキュリティ、経済メカニズム、モデル検証など、複数の側面を包含する体系的なエンジニアリング課題です。しかし、「効果的なコラボレーション + インセンティブの誠実性 + 結果の正確性」を実現できるかどうかは、まだ初期のプロトタイプ探索段階にあります。
フェデレーテッドラーニングは、分散型と分散型の移行形態です。ローカルデータの保持とモデルパラメータの集中集約を重視し、医療や金融などのプライバシーコンプライアンスを重視するシナリオに適しています。フェデレーテッドラーニングは、分散型トレーニングのエンジニアリング構造とローカル調整機能に加え、分散型トレーニングのデータ分散の利点も備えています。しかし、信頼できるコーディネータに依存しており、完全なオープン性と耐検閲性を備えていません。プライバシーコンプライアンスのシナリオにおいては、「制御された分散化」ソリューションと見なすことができます。トレーニングタスク、信頼構造、通信メカニズムの面で比較的穏やかであり、業界における移行的な展開アーキテクチャとしてより適しています。
AIトレーニングパラダイムパノラマ比較表(技術アーキテクチャ×信頼インセンティブ×アプリケーション特性)

分散型トレーニングの限界、機会、現実的な道筋
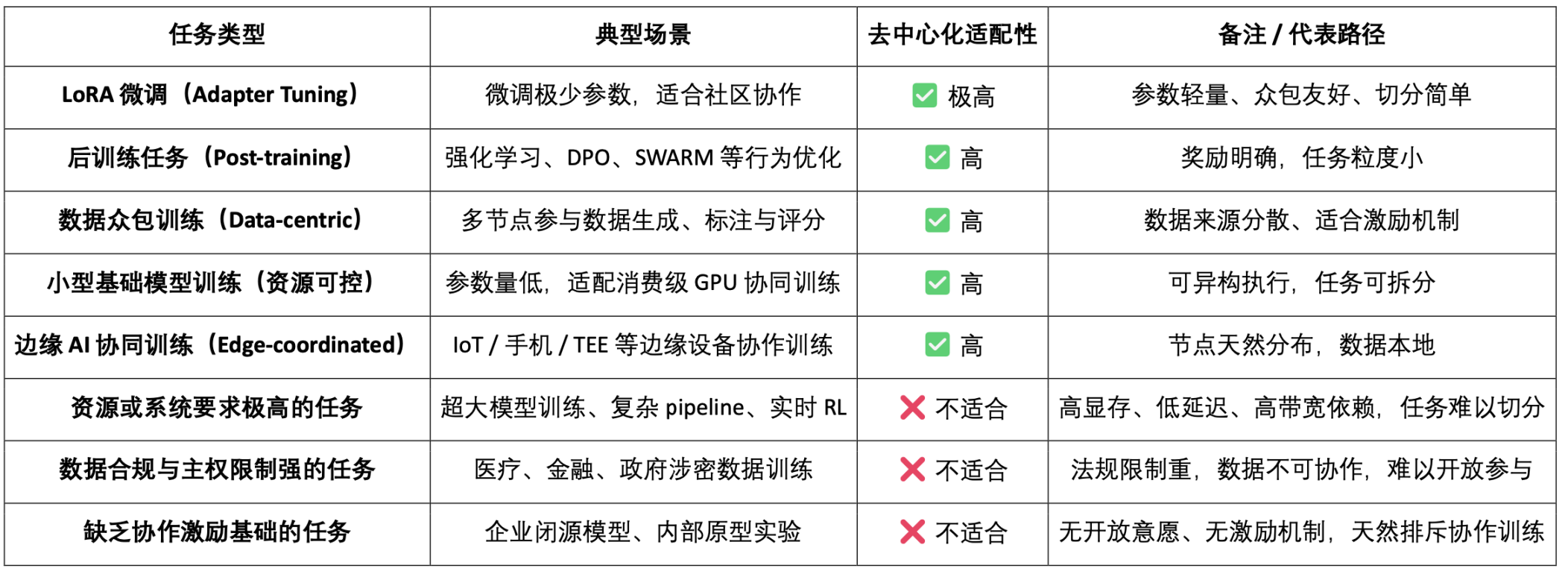
トレーニングパラダイムの観点から見ると、分散型トレーニングはすべてのタイプのタスクに適用できるわけではありません。タスクの構造が複雑であったり、リソース要件が非常に高かったり、コラボレーションが難しかったりするシナリオでは、当然のことながら、異機種混在で信頼できないノード間で効率的に完了させることは適していません。たとえば、大規模モデルのトレーニングでは、大容量のビデオメモリ、低レイテンシ、高速帯域幅が求められることが多く、オープンネットワークで効果的に分割して同期することが困難です。また、データのプライバシーと主権に関する制限が厳しいタスク(医療、金融、機密データなど)は、法令遵守や倫理的制約によって制限されており、オープンに共有することはできません。さらに、コラボレーションのインセンティブ基盤がないタスク(企業のクローズドソースモデルや社内プロトタイプトレーニングなど)には、参加に対する外部的な動機がありません。これらの限界が、分散型トレーニングの現在の実際的な限界を構成しています。
しかし、これは分散トレーニングが誤った提案であることを意味するものではありません。実際、分散トレーニングは、軽量で並列化が容易でインセンティブが付与されるタスクにおいて明確な応用可能性を示しています。LoRAの微調整、トレーニング後の行動調整タスク(RLHF、DPOなど)、データクラウドソーシングによるトレーニングとラベリングタスク、リソース制御可能な小規模基本モデルトレーニング、エッジデバイスを含む協調トレーニングシナリオなどが含まれますが、これらに限定されません。これらのタスクは一般的に、高い並列性、低い結合性、異機種コンピューティング能力への耐性という特性を備えており、P2Pネットワーク、Swarmプロトコル、分散オプティマイザーなどを介した協調トレーニングに非常に適しています。
分散型トレーニングタスク適合性概要表
従来の分散型トレーニングプロジェクトの分析
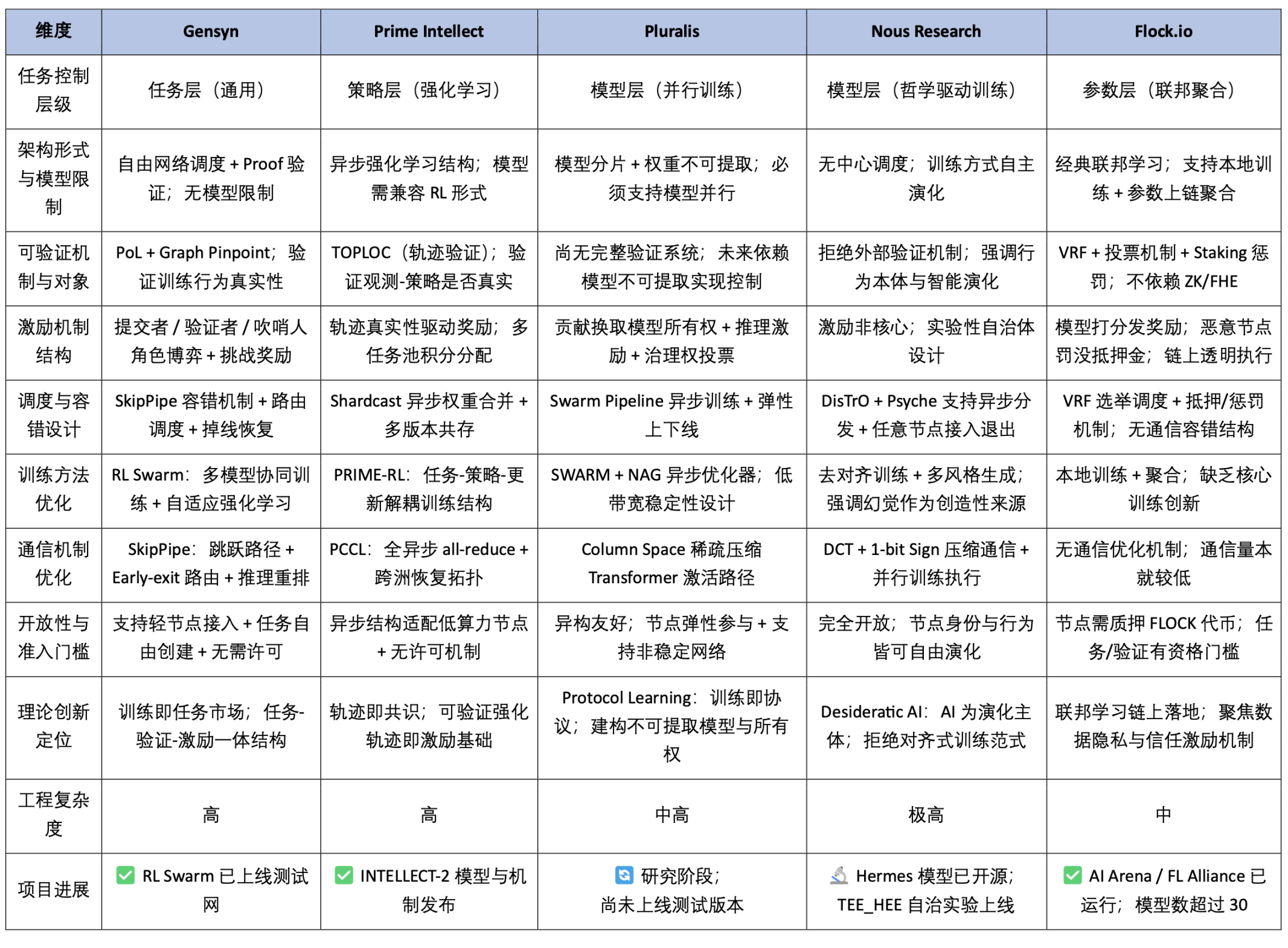
現在、分散型トレーニングと連合学習のフロンティア分野における代表的なブロックチェーンプロジェクトとしては、Prime Intellect、Pluralis.ai、Gensyn、Nous Research、Flock.ioなどが挙げられます。技術革新とエンジニアリングの難易度という観点から見ると、Prime Intellect、Nous Research、Pluralis.aiはシステムアーキテクチャとアルゴリズム設計においてより独創的な探求を提示し、現在の理論研究の最先端方向を体現しています。一方、GensynとFlock.ioは実装の道筋が比較的明確で、初期のエンジニアリングの進展が見られます。本稿では、これら5つのプロジェクトの背後にあるコアテクノロジーとエンジニアリングアーキテクチャを順に分析し、分散型AIトレーニングシステムにおけるそれらの相違点と補完関係をさらに探っていきます。
Prime Intellect: 検証可能なトレーニング軌跡を備えた協調強化学習ネットワークのパイオニア
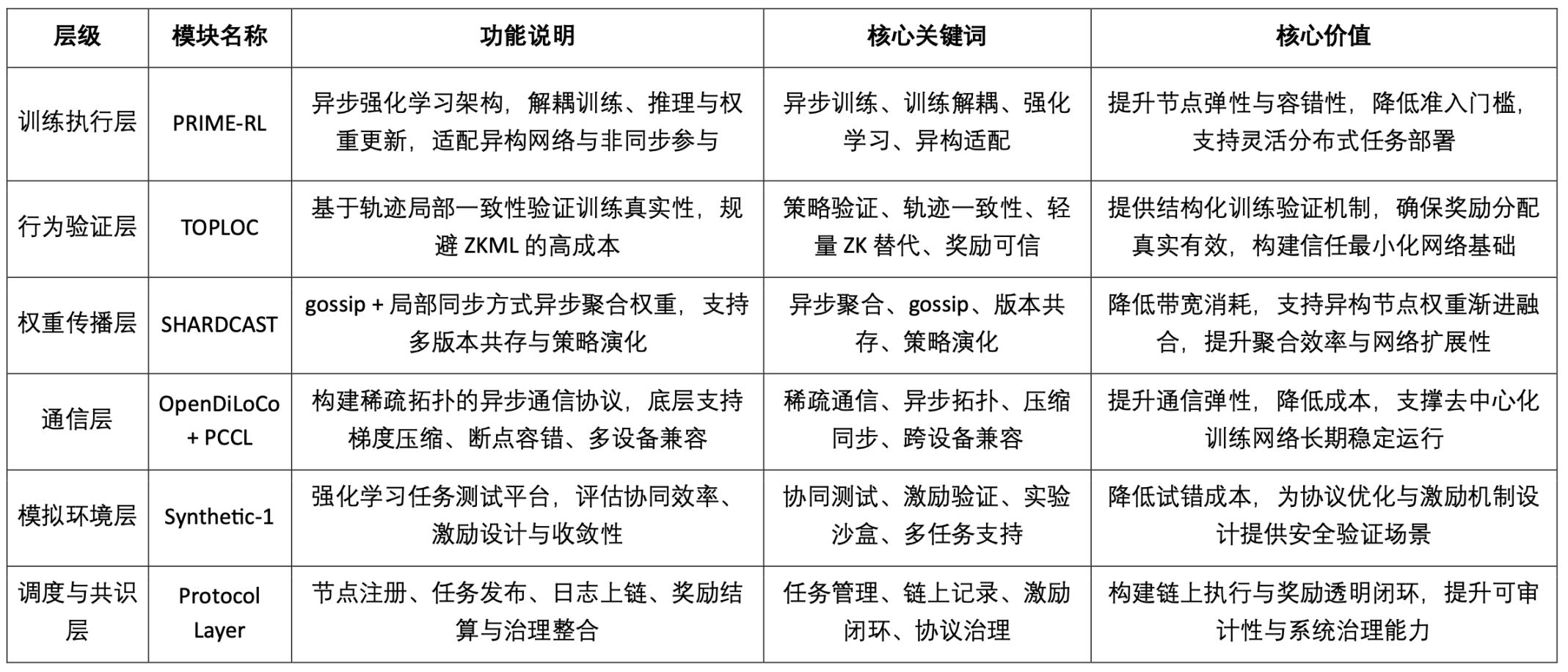
Prime Intellectは、誰もがトレーニングに参加でき、コンピューティングへの貢献に対して信頼できる報酬を受け取ることができる、トラストレスなAIトレーニングネットワークの構築に取り組んでいます。Prime Intellectは、PRIME-RL、TOPLOC、SHARDCASTという3つのモジュールを通じて、検証可能でオープン、かつ完全にインセンティブ化されたAI分散型トレーニングシステムの構築を目指しています。
1. Prime Intellectのプロトコルスタック構造と主要モジュールの価値
2. プライムインテリクトトレーニングの主要メカニズムの詳細な説明
PRIME-RL: 分離型非同期強化学習タスクアーキテクチャ
PRIME-RLは、Prime Intellectが分散型トレーニングシナリオ向けにカスタマイズしたタスクモデリングおよび実行フレームワークであり、異種ネットワークと非同期参加に対応して設計されています。強化学習を優先適応オブジェクトとして用い、トレーニング、推論、重みアップロードプロセスを構造的に分離することで、各トレーニングノードがタスクサイクルをローカルで独立して完了し、標準化されたインターフェースを介して検証および集約メカニズムと連携できるようにします。従来の教師あり学習プロセスと比較して、PRIME-RLは分散型スケジューリング環境における柔軟なトレーニングに適しており、システムの複雑さを軽減するだけでなく、マルチタスクの並列処理と戦略進化をサポートするための基盤を構築します。
TOPLOC: 軽量なトレーニング行動検証メカニズム
TOPLOC(Trusted Observation & Policy-Locality Check)は、Prime Intellectが提唱するトレーニング検証可能性の中核メカニズムであり、ノードが観測データに基づいて実際に有効なポリシー学習を完了したかどうかを判断するために使用されます。ZKMLなどの重いソリューションとは異なり、TOPLOCはモデル全体の再計算に依存せず、「観測シーケンス ↔ ポリシー更新」間の局所的な一貫性軌跡を解析することで、軽量な構造検証を実現します。トレーニングプロセスの行動軌跡を検証可能なオブジェクトに変換したのはこれが初めてです。これは、トラストレスなトレーニング報酬分配を実現するための重要なイノベーションであり、監査可能でインセンティブのある分散型協調トレーニングネットワークを構築するための実現可能な道筋を提供します。
SHARDCAST: 非同期重み集約および伝播プロトコル
SHARDCASTは、Prime Intellectが設計した重み伝播および集約プロトコルであり、非同期、帯域幅制約、およびノード状態が変動する実ネットワーク環境に最適化されています。ゴシップ伝播メカニズムとローカル同期戦略を組み合わせることで、複数のノードが非同期状態で部分更新を継続的に送信し、重みの漸進的収束とマルチバージョン進化を実現します。集中型または同期型のAllReduce手法と比較して、SHARDCASTは分散トレーニングのスケーラビリティとフォールトトレランスを大幅に向上させ、安定した重みコンセンサスと継続的なトレーニング反復を構築するための中核的な基盤となります。
OpenDiLoCo: 疎な非同期通信のためのフレームワーク
OpenDiLoCoは、DeepMindが提唱するDiLoCoコンセプトに基づき、Prime Intellectチームが独自に実装しオープンソース化した通信最適化フレームワークです。分散学習でよく見られる帯域幅制約、デバイスの異種性、ノードの不安定性といった課題に対応するよう設計されています。そのアーキテクチャはデータ並列性に基づいています。Ring、Expander、Small-Worldといった疎なトポロジ構造を構築することで、グローバル同期による高い通信オーバーヘッドを回避し、ローカルな隣接ノードのみでモデルの協調学習を完了します。非同期更新やブレークポイントフォールトトレランスメカニズムと組み合わせることで、OpenDiLoCoはコンシューマーグレードのGPUとエッジデバイスが安定的に学習タスクに参加できるようにし、グローバル協調学習への参加を大幅に向上させます。分散学習ネットワークを構築するための重要な通信インフラの一つとなっています。
PCCL: 共同コミュニケーションライブラリ
PCCL(Prime Collective Communication Library)は、Prime Intellectが分散型AIトレーニング環境向けにカスタマイズした軽量通信ライブラリです。異種デバイスや低帯域幅ネットワークにおける従来の通信ライブラリ(NCCL、Glooなど)の適応ボトルネックを解決することを目的としています。PCCLは、スパーストポロジ、勾配圧縮、低精度同期、ブレークポイントリカバリをサポートしています。コンシューマーグレードのGPUや不安定なノードでも動作可能です。OpenDiLoCoプロトコルの非同期通信機能をサポートする基盤コンポーネントです。トレーニングネットワークの帯域幅許容度とデバイス互換性を大幅に向上させ、真にオープンでトラストレスな協調トレーニングネットワークを構築するための「ラストマイル」通信基盤を開拓します。
3. プライムインテリジェンスインセンティブネットワークと役割分担
Prime Intellectは、誰でもタスクに参加でき、実際の貢献度に基づいて報酬を得ることができる、許可不要で検証可能、かつ経済的インセンティブを備えたトレーニングネットワークを構築しました。このプロトコルは、以下の3つのコアロールに基づいて動作します。
- タスクイニシエーター: トレーニング環境、初期モデル、報酬関数、検証基準を定義する
- トレーニングノード: ローカルトレーニングを実行し、重みの更新を送信し、軌跡を観察します。
- 検証ノード:TOPLOCメカニズムを使用して、トレーニング行動の信頼性を検証し、報酬計算と戦略集約に参加します。
プロトコルの中核プロセスには、タスクのリリース、ノードのトレーニング、軌跡の検証、重みの集約 (SHARDCAST)、報酬の分配が含まれ、「実際のトレーニング動作」を中心にインセンティブのクローズドループを形成します。
INTELLECT-2: 検証可能な最初の分散型トレーニングモデルのリリース
プライム・インテリクトは2025年5月に、非同期かつトラストレスな分散ノードによって学習された世界初の大規模強化学習モデルであるINTELLECT-2をリリースしました。パラメータスケールは320億です。INTELLECT-2モデルは、3大陸にまたがる100台以上のGPUヘテロジニアスノードによって学習され、完全非同期アーキテクチャと400時間を超える学習時間を用いて、非同期協調ネットワークの実現可能性と安定性を実証しました。このモデルは性能面での画期的な成果であるだけでなく、プライム・インテリクトが提唱する「トレーニングはコンセンサス」パラダイムを初めて体系的に実装したものでもあります。INTELLECT-2は、PRIME-RL(非同期学習構造)、TOPLOC(学習動作検証)、SHARDCAST(非同期重み集約)などのコアプロトコルモジュールを統合しており、分散学習ネットワークで学習プロセスのオープン性、検証可能性、経済的インセンティブを備えた閉ループを実現した初めての事例となります。
性能面では、INTELLECT-2はQwQ-32Bトレーニングをベースとし、コードと数学に特化した強化学習を実施しており、これは現在のオープンソース強化学習ファインチューニングモデルの最先端です。GPT-4やGeminiなどのクローズドソースモデルを凌駕するほどではありませんが、その真の意義は、再現性、検証性、監査性を備えた完全な学習プロセスを備えた世界初の分散型モデル実験である点にあります。Prime Intellectはモデルをオープンソース化しただけでなく、さらに重要な点として、学習プロセス自体もオープンソース化しました。学習データ、戦略更新軌跡、検証プロセス、集約ロジックなど、すべてが透明性と追跡性を備えており、誰もが参加でき、信頼できるコラボレーションと利益の共有が可能な分散型学習ネットワークのプロトタイプを構築しています。
5. チームと資金調達の背景
Prime Intellectは、2025年2月にFounders Fundが主導し、Menlo Ventures、Andrej Karpathy、Clem Delangue、Dylan Patel、Balaji Srinivasan、Emad Mostaque、Sandeep Nailwalといった業界リーダーが参加した1,500万ドルのシードラウンドの資金調達を完了しました。これに先立ち、同プロジェクトは2024年4月にCoinFundとDistributed Globalが主導し、Compound VC、Collab + Currency、Protocol Labsが参加した550万ドルの初期資金調達ラウンドを完了しています。これまでにPrime Intellectは合計2,000万ドル以上を調達しています。
Prime Intellectの共同創設者は、Vincent WeisserとJohannes Hagemannです。チームメンバーはAIとWeb3のバックグラウンドを持ち、コアメンバーはMeta AI、Google Research、OpenAI、Flashbots、Stability AI、Ethereum Foundation出身です。彼らはシステムアーキテクチャ設計と分散エンジニアリング実装において卓越した能力を有しています。彼らは、実際に分散型大規模モデル学習を成功させた数少ない経営陣の一つです。
Pluralis: 非同期モデル並列処理と構造圧縮協調トレーニングのためのパラダイムエクスプローラー
Pluralisは、「信頼できる協調学習ネットワーク」に焦点を当てたWeb3 AIプロジェクトです。その中核目標は、分散型、オープン参加型、そして長期的なインセンティブに基づくモデル学習パラダイムの推進です。現在主流となっている集中型または閉鎖型の学習パスとは異なり、Pluralisは「プロトコル学習」と呼ばれる新しい概念を提案しました。これは「プロトコルベース」のモデル学習プロセスであり、検証可能な協調メカニズムとモデル所有権マッピングを通じて、内発的インセンティブに基づく閉ループを備えたオープンな学習システムを構築します。
1. コアコンセプト:プロトコル学習
Pluralis が提案するプロトコル学習は、3 つの主要な柱から構成されます。
- 非物質化モデル:モデルは複数のノードに断片的に分散されており、単一のノードが完全な重みを復元してクローズドソースのままにすることはできません。この設計により、モデルは自然な「プロトコル内資産」となり、アクセス認証情報の制御、漏洩防止、収益帰属バインディングを実現できます。
- インターネット経由のモデル並列トレーニング: 非同期パイプライン モデル並列メカニズム (SWARM アーキテクチャ) により、異なるノードは部分的な重みのみを保持し、低帯域幅のネットワーク コラボレーションを通じてトレーニングまたは推論を完了します。
- インセンティブのための部分的所有権: 参加しているすべてのノードは、トレーニングへの貢献に基づいてモデルの部分的な所有権を取得し、それによって将来の収益分配とプロトコルガバナンスの権利を享受します。
2. Pluralisプロトコルスタックの技術アーキテクチャ

3. 主要な技術的メカニズムの詳細な説明
具体化不可能なモデル
「第三の道:プロトコル学習」では、モデルの重みをフラグメントの形で分散させることで、「モデル資産」がSwarmネットワーク内でのみ実行できるようにし、そのアクセスと利益がプロトコルによって制御されるようにすることが初めて提案されました。このメカニズムは、分散型トレーニングにおける持続可能なインセンティブ構造を実現するための前提条件です。
非同期モデル並列トレーニング
SWARM Parallel with Asynchronous Updatesにおいて、PluralisはPipelineをベースとした非同期モデル並列アーキテクチャを構築し、LLaMA-3で初めて実証しました。中核となるイノベーションは、Nesterov Accelerated Gradient(NAG)メカニズムの導入です。このメカニズムは、非同期更新プロセスにおける勾配ドリフトと不安定な収束の問題を効果的に修正し、低帯域幅環境における異種デバイス間のトレーニングを実用化します。
列空間スパース化
Beyond Top-Kでは、セマンティックパスの破壊を回避するため、従来のTop-Kを構造を考慮した列空間圧縮手法に置き換えることが提案されています。このメカニズムは、モデルの精度と通信効率の両方を考慮しています。非同期モデル並列環境において、通信データの90%以上を圧縮できることがテストで確認されており、これは構造を考慮した効率的な通信を実現するための重要なブレークスルーです。
4. 技術の位置付けとパスの選択
Pluralis は明らかに「非同期モデル並列処理」をその中核的な方向性として採用しており、データ並列処理に比べて次のような利点があることを強調しています。
- 低帯域幅ネットワークと非コヒーレントノードをサポートします。
- デバイスの異種性に適応し、コンシューマーグレードの GPU が参加できるようにします。
- 自然な弾性スケジューリング機能を備えており、ノードの頻繁なオンライン/オフラインをサポートします。
- 3 つの大きなブレークスルーポイントは、構造の圧縮 + 非同期更新 + 重みの抽出不可です。
現在、公式サイトで公開されている6つの技術ブログ文書によると、論理構造は次の3つの主要なラインに統合されています。
- 哲学とビジョン:第三の道:プロトコル学習 分散型トレーニングが重要な理由
- 技術的メカニズムの詳細:「SWARM Parallel」、「Beyond Top-K」、「非同期更新」
- 制度的イノベーションの探究:非物質化モデルと部分的所有プロトコル
現時点では、Pluralisは製品、テストネットワーク、オープンソースコードをまだリリースしていません。その理由は、同社が選択した技術的アプローチが非常に困難であるためです。まず、基盤となるシステムアーキテクチャ、通信プロトコル、重みのエクスポート不可といったシステムレベルの問題を解決しなければ、製品サービスを上位にパッケージ化することはできません。
2025年6月にPluralis Researchが発表した新しい論文では、分散型学習フレームワークがモデルの事前学習から微調整段階へと拡張され、非同期更新、スパース通信、部分的な重み集約がサポートされています。理論と事前学習に重点を置いた従来の設計と比較して、この研究は実装の実現可能性に重点を置き、フルサイクル学習アーキテクチャにおけるさらなる成熟を示しています。
5. チームと資金調達の背景
Pluralisは2025年に、Union Square Ventures(USV)とCoinFundが主導する760万ドルのシードラウンドを完了しました。創業者のAlexander Long氏は機械学習の博士号を取得しており、数学とシステム研究の両方のバックグラウンドを持っています。コアメンバーは全員が博士号を取得した機械学習研究者です。Pluralisは典型的な技術主導型プロジェクトであり、高密度論文と技術ブログを主な出版経路としています。まだBD/グロースチームは設立されておらず、低帯域幅の非同期モデル並列処理におけるインフラストラクチャの課題を克服することに注力しています。
Gensyn: 検証可能な実行によって駆動される分散型トレーニングプロトコル層
Gensynは、「ディープラーニングトレーニングタスクの信頼できる実行」に重点を置いたWeb3 AIプロジェクトです。その核心は、モデルアーキテクチャやトレーニングパラダイムの再構築ではなく、「タスク分散+トレーニング実行+結果検証+公平なインセンティブ」というプロセス全体を備えた検証可能な分散トレーニング実行ネットワークの構築にあります。オフチェーントレーニング+オンチェーン検証のアーキテクチャ設計を通じて、Gensynは効率的でオープンかつインセンティブのあるグローバルトレーニング市場を確立し、「トレーニングはマイニング」の実現に貢献しています。
1. プロジェクトの位置付け: トレーニングタスクの実行プロトコル層
Gensynは「どのようにトレーニングするか」ではなく、「誰がトレーニングを行うか、どのように検証するか、そしてどのように利益を分配するか」というインフラストラクチャに焦点を当てています。その本質は、トレーニングタスクのための検証可能なコンピューティングプロトコルであり、主に以下の問題を解決します。
- 誰がトレーニングタスク(計算電力配分と動的マッチング)を実行するか
- 実行結果の検証方法(全体を再計算する必要はなく、争点となっている演算子のみを検証します)
- トレーニング収入の分配方法(ステーク、スラッシング、マルチロールゲームの仕組み)
2. 技術アーキテクチャの概要

3. モジュールの詳細な説明
RL Swarm: 協調型強化学習トレーニングシステム
Gensyn が開発した RL Swarm は、トレーニング後のフェーズ向けの分散型マルチモデル共同最適化システムであり、次のコア機能を備えています。
分散推論と学習プロセス:
- 生成フェーズ (回答): 各ノードは独立して回答を出力します。
- 批評段階: ノードは互いの出力にコメントし、最適な回答とロジックを選択します。
- コンセンサスフェーズ (解決): ほとんどのノードの好みを予測し、それに応じて独自の回答を変更して、ローカルの重みの更新を実現します。
Gensynが提案するRL Swarmは、分散型マルチモデル協調最適化システムです。各ノードは独立したモデルを実行し、勾配同期なしでローカルトレーニングを行います。異機種混在のコンピューティングパワーや不安定なネットワーク環境に自然に適応し、柔軟なノードのアクセスと退出をサポートします。このメカニズムは、RLHFとマルチエージェントゲームのアイデアに基づいていますが、協調推論ネットワークの動的進化ロジックに近いものです。ノードは、グループのコンセンサス結果との整合性の度合いに応じて報酬を受け取り、推論能力の継続的な最適化と収束学習を促進します。RL Swarmは、オープンネットワークにおけるモデルの堅牢性と汎化能力を大幅に向上させ、Ethereum Rollupに基づくGensynのテストネットフェーズ0のコア実行モジュールとして導入されています。
Verde + Proof-of-Learning:信頼できる検証メカニズム
Gensyn の Verde モジュールは、次の 3 つのメカニズムを組み合わせています。
- 学習証明: 勾配トレースとトレーニング メタデータに基づいてトレーニングが実際に行われたかどうかを判断します。
- グラフベースのピンポイント: トレーニング計算グラフ内の分岐ノードを特定し、特定の操作のみを再計算する必要があります。
- 審判付き委任: 検証者と挑戦者が紛争を提起し、部分的な検証を実施する仲裁検証メカニズムを使用し、検証コストを大幅に削減します。
ZKP または完全再計算検証方式と比較して、Verde 方式は検証可能性と効率性の間のより優れたバランスを実現します。
SkipPipe: 通信フォールトトレラント最適化メカニズム
SkipPipeは、「低帯域幅 + ノード切断」シナリオにおける通信ボトルネック問題を解決するために設計されています。主な機能は以下のとおりです。
- スキップ率: トレーニングのブロックを回避するために制限されたノードをスキップします。
- 動的スケジューリング アルゴリズム: 最適な実行パスをリアルタイムで生成します。
- フォールト トレラント実行: 50% のノードに障害が発生しても、推論精度は約 7% しか低下しません。
トレーニング スループットを最大 55% 向上し、「早期終了推論」、「シームレスな並べ替え」、「推論完了」などの主要な機能を実装します。
HDEE: クロスドメイン異種エキスパートクラスター
HDEE (Heterogeneous Domain-Expert Ensembles) モジュールは、次のシナリオの最適化に特化しています。
- マルチドメイン、マルチモーダル、マルチタスクのトレーニング。
- さまざまなタイプのトレーニング データの分布が不均一であり、難易度が大きく異なります。
- 異機種デバイスのコンピューティング機能と一貫性のない通信帯域幅を備えた環境におけるタスクの割り当てとスケジュールの問題。
主な特徴:
- MHe-IHo: 異なるサイズのモデルを異なる難易度のタスクに割り当てます (異種モデルと一貫したトレーニング ステップ サイズ)。
- MHo-IHe: タスクの難易度は統一されていますが、トレーニング ステップ サイズは非同期的に調整されます。
- 異種のエキスパート モデルとプラグ可能なトレーニング戦略をサポートし、適応性とフォールト トレランスを向上します。
- 「並列コラボレーション + 極めて少ないコミュニケーション + 動的な専門家の割り当て」を重視しており、現実の複雑なタスクエコシステムに適しています。
マルチロールゲームのメカニズム:信頼とインセンティブは密接に関係している
Gensyn ネットワークでは、次の 4 種類の参加者を導入しています。
- 提出者: トレーニング タスクを公開し、構造と予算を設定します。
- ソルバー: トレーニング タスクを実行し、結果を送信します。
- 検証者: トレーニングの動作を検証してコンプライアンスと有効性を確保します。
- 内部告発者: バリデーターに仲裁報酬を得るか罰金を負うよう要求します。
このメカニズムは、Truebitの経済ゲームデザインに着想を得ています。強制的にエラーを挿入し、ランダムな仲裁を行うことで、参加者の誠実な協力を促し、ネットワークの信頼性の高い運用を保証します。
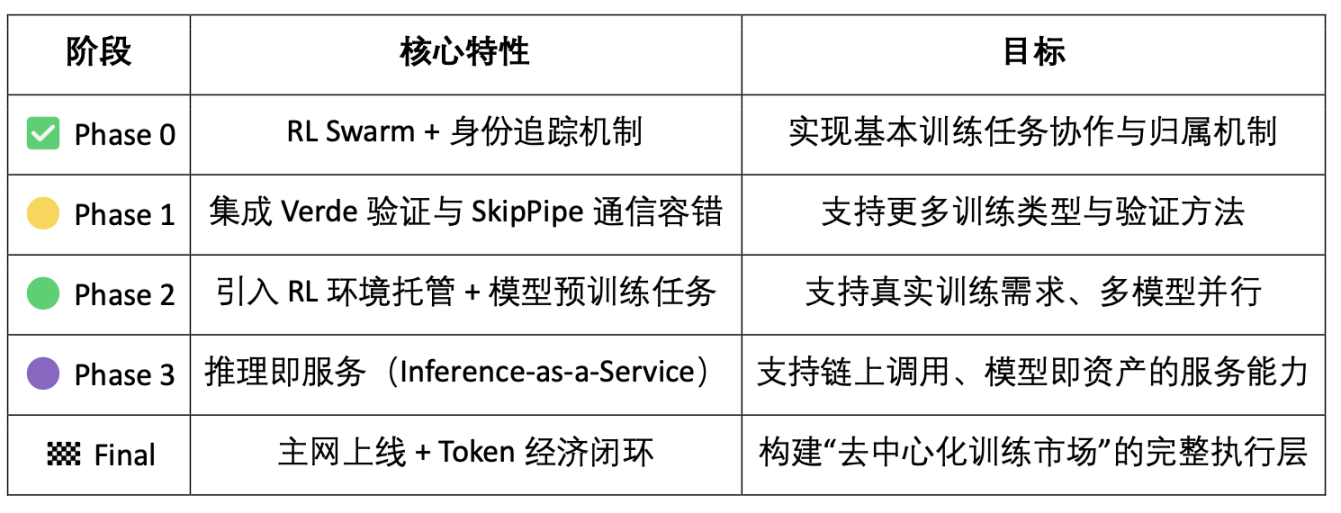
4. テストネットとロードマップの計画
5. チームと資金調達の背景
Gensynは、ベン・フィールディングとハリー・グリーブによって共同設立され、英国ロンドンに本社を置いています。2023年5月、Gensynはa16z cryptoが主導し、CoinFund、Canonical、Ethereal Ventures、Factor、Eden Blockなどの投資家から4,300万ドルのシリーズA資金調達を完了したことを発表しました。チームは分散システムと機械学習エンジニアリングの経験を組み合わせたチームであり、検証可能でトラストレスな大規模AIトレーニング実行ネットワークの構築に長年取り組んできました。
Nous Research: 主観的なAIコンセプトに基づく認知進化トレーニングシステム
Nous Researchは、哲学と工学の両面で成果を上げている数少ない分散型トレーニングチームの一つです。その中核となるビジョンは、「Desideratic AI(デシデラティックAI)」という概念に根ざしており、AIを単なる制御可能なツールではなく、主体性と進化能力を備えた知的な主体と捉えています。Nous Researchの独自性は、AIトレーニングを「効率性の問題」として最適化するのではなく、「認知主体」の形成プロセスとして捉えている点にあります。このビジョンに基づき、Nousは、異種ノードによる協調的なトレーニング、中央スケジューリングを必要とせず、検閲耐性を備え、フルスタックツールチェーンを通じて体系的に実装されたオープンなトレーニングネットワークの構築に注力しています。
1. コンセプトサポート:トレーニングの「目的」を再定義する
Nousはインセンティブ設計やプロトコル経済学にあまり投資せず、代わりにトレーニング自体の哲学的前提を変えようとしています。
- 「アライメント主義」に反対します。人間の制御を唯一の目標とする「トレーニング」に同意せず、トレーニングはモデルが独立した認知スタイルを形成するように促すべきであると主張します。
- モデルの主観性の強調: 基本モデルは不確実性、多様性、幻覚を美徳として保持する必要があると考えられています。
- モデルのトレーニングは認知形成です。モデルは「タスクの完了を最適化する」のではなく、認知進化プロセスに参加する個体です。
このトレーニング コンセプトは「ロマンチック」ですが、トレーニング インフラストラクチャの設計における Nous の中核ロジック、つまり、均一に規律されるのではなく、オープン ネットワーク内で異種のモデルを進化させる方法を反映しています。
2. トレーニングコア: Psyche NetworkとDisTrO Optimizer
Nousの分散型トレーニングへの最も重要な貢献は、Psycheネットワークと、その基盤となる通信最適化装置DisTrO(Distributed Training Over-the-Internet)の構築です。これらは共にトレーニングタスクの実行センターを構成します。DisTrO + Psycheネットワークは、通信圧縮(DCT + 1ビット符号エンコーディングを使用して帯域幅要件を大幅に削減)、ノード適応性(異機種GPUのサポート、切断再接続、自律終了)、非同期フォールトトレランス(同期なしでの継続的なトレーニング、高いフォールトトレランス)、分散スケジューリングメカニズム(中央コーディネーターなし、ブロックチェーンに基づくコンセンサスとタスク分散)など、複数のコア機能を備えています。このアーキテクチャは、低コストで柔軟性が高く、検証可能なオープントレーニングネットワークのための現実的かつ実現可能な技術基盤を提供します。

このアーキテクチャ設計は実用的な実現可能性を重視しており、中央サーバーに依存せず、世界中のボランティアノードに適応でき、トレーニング結果のオンチェーントレーサビリティを備えています。
3. Hermes / Forge / TEE_HEE で構成された推論および代理システム
Nous Research は、分散型トレーニング インフラストラクチャの構築に加えて、「AI の主観性」という概念に関するいくつかの探索的システム実験も実施しました。
1. Hermesオープンソースモデルシリーズ:Hermes 1~3は、NousがLLaMA 3.1トレーニングをベースとした代表的なオープンソース大規模モデルであり、8B、70B、405Bの3つのパラメータスケールをカバーしています。本シリーズは、Nousが提唱する「脱教示、多様性の保持」というトレーニングコンセプトを具体化することを目指しており、長期コンテキスト保持、ロールプレイング、マルチラウンド対話などにおいて、より強力な表現力と汎化能力を発揮します。
2. Forge推論API:マルチモーダル推論システム
Forge は、Nous が開発した推論フレームワークであり、3 つの補完的なメカニズムを組み合わせて、より柔軟で創造的な推論機能を実現します。
- MCTS (モンテカルロ木探索): 複雑なタスクの戦略探索。
- CoC (Chain of Code): コード チェーンと論理的推論の組み合わせパスを導入します。
- MoA (エージェントの混合): 複数のモデルがネゴシエートして、出力の幅と多様性を向上させることができます。
このシステムは、「非決定論的推論」と組み合わせ生成パスを重視しており、これは従来の命令アライメントパラダイムに対する強力な対応です。
3. TEE_HEE:AI自律エージェント実験:TEE_HEEは、Nousが自律エージェントの実現に向けて進めている最先端研究であり、AIが信頼できる実行環境(TEE)において自律的に動作し、固有のデジタルIDを持つかどうかを検証することを目的としています。エージェントは独自のTwitterアカウントとEthereumアカウントを持ち、すべての制御権限はリモート検証可能なエンクレーブによって管理されるため、開発者はエージェントの行動に干渉できません。この実験の目標は、「不変性」と「独立した行動意図」を備えたAI主体を構築することであり、自律的な知能体の構築に向けた重要な一歩となります。
4. AI行動シミュレータプラットフォーム:Nousは、WorldSim、Doomscroll、Gods & S8nなど、複数のシミュレータを開発し、多役割社会環境におけるAIの行動進化と価値形成メカニズムを研究しています。これらの実験は、学習プロセスに直接関与しているわけではありませんが、長期的な自律AIの認知行動モデリングのためのセマンティックな基盤を構築しています。
IV. チームと資金調達の概要
Nous Researchは、ジェフリー・ケスネル(CEO)、カラン・マルホトラ、テクニウム、シヴァニ・ミトラらによって2023年に設立されました。チームは哲学に基づき、機械学習、システムセキュリティ、分散型ネットワークなど、多様なバックグラウンドを持つシステムエンジニアリングに注力しています。2024年にはシードラウンドで520万ドルの資金調達を実施しました。2025年4月には、パラダイムが主導するシリーズAラウンドで5,000万ドルの資金調達を完了し、評価額は10億ドルに達し、Web3 AIユニコーン企業の一つとなりました。
Flock: ブロックチェーン強化型連合学習ネットワーク
Flock.ioは、AIトレーニングのためのデータ、コンピューティング、モデルの分散化を目指すブロックチェーンベースの連合学習プラットフォームです。FLockは「連合学習 + ブロックチェーン報酬レイヤー」という統合フレームワークを採用しており、これは新しいトレーニングプロトコルの構築を体系的に探求するのではなく、従来のFLアーキテクチャのオンチェーン進化と言えるでしょう。Gensyn、Prime Intellect、Nous Research、Pluralisなどの分散学習プロジェクトと比較すると、Flockは通信、検証、トレーニング手法における理論的なブレークスルーではなく、プライバシー保護とユーザビリティの向上に重点を置いています。実際の比較対象は、Flower、FedML、OpenFLなどの連合学習システムです。
1. Flock.ioのコアメカニズム
1. 連合学習アーキテクチャ:データ主権とプライバシー保護を重視
Flockは、従来のFederated Learning(FL)パラダイムに基づいており、複数のデータ所有者が元のデータを共有することなく、統合モデルを共同で学習することを可能にします。データの主権、セキュリティ、信頼性の問題解決に重点を置いています。コアプロセスは以下のとおりです。
- ローカルトレーニング: 各参加者 (提案者) は、元のデータをアップロードせずにローカルデバイス上でモデルをトレーニングします。
- オンチェーン集約: トレーニングが完了すると、ローカル重みの更新が送信され、オンチェーンマイナーによってグローバル モデルに集約されます。
- 委員会の評価: VRF は投票ノードをランダムに選出し、独立したテスト セットを使用して集約モデルを評価し、スコアを付けます。
- インセンティブと罰則: スコアリング結果に基づいて報酬または担保の没収が実行され、悪意の防止と動的な信頼維持が実現されます。
2. ブロックチェーン統合:信頼のないシステム調整の実現
Flockは、システムの透明性、検証可能性、そして検閲耐性を高めるため、トレーニングプロセス(タスクの割り当て、モデルの提出、評価とスコアリング、インセンティブの実行)のコアリンクをすべてチェーン上に配置しました。主なメカニズムは以下のとおりです。
- VRF ランダム選挙メカニズム: 提案者と投票者間のローテーションの公平性と操作防止能力が向上します。
- ステークメカニズム (PoS): トークン誓約とペナルティを通じてノードの動作を制限し、システムの堅牢性を向上させます。
- オンチェーンインセンティブの自動実行:スマートコントラクトを通じて、タスクの完了と評価結果に結びついた報酬の分配とペナルティの削減が実現され、信頼できる仲介者を必要としない協調ネットワークが構築されます。
3. zkFL:ゼロ知識集約メカニズムにおけるプライバシー保護の革新:FlockはzkFLゼロ知識集約メカニズムを導入します。これにより、提案者はローカルで更新されたゼロ知識証明を提出できます。投票者は元の勾配にアクセスすることなく、その正しさを検証できます。これにより、プライバシーを確保しながらトレーニングプロセスの信頼性が向上し、プライバシー保護と検証可能性の統合という方向性において、連合学習における重要な革新となります。
2. Flockのコア製品コンポーネント
AI Arena:Flock.ioの分散型トレーニングプラットフォームです。ユーザーはtrain.flock.ioを通じてモデルタスクに参加し、トレーナー、バリデーター、または委任者として行動し、モデルの提出、パフォーマンス評価、トークンの委任によって報酬を受け取ることができます。現在、タスクは正式にリリースされており、今後、コミュニティによる共同創造のために段階的に公開される予定です。
FLアライアンス:参加者がプライベートデータを使用してモデルをさらに微調整することをサポートするFlockの連合学習クライアントです。VRF選出、ステーキング、スラッシングメカニズムを通じて、トレーニングプロセスの誠実性とコラボレーション効率を確保し、コミュニティによる初期トレーニングと実際の展開を繋ぐ重要なリンクとなります。
AIマーケットプレイス:ユーザーがモデルを提案し、データを提供したり、モデルサービスを呼び出したりできる、モデルの共創・展開プラットフォームです。データベースアクセスとRAG拡張推論をサポートし、様々な実用シナリオにおけるAIモデルの実装と流通を促進します。
3. チームと資金調達の概要
Flock.ioは孫家豪氏によって設立され、プラットフォームトークンFLOCKを発行しています。このプロジェクトは、DCG、Lightspeed Faction、Tagus Capital、Animoca Brands、Fenbushi、OKX Venturesなどの投資家から総額1,100万米ドルを調達しています。2024年3月、Flockはテストネットワークとフェデレーテッドラーニングクライアントを立ち上げるために600万米ドルのシードラウンドの資金調達を完了しました。同年12月には、ブロックチェーン駆動型AIインセンティブメカニズムに注力するために、300万米ドルの追加資金を調達し、イーサリアム財団から資金提供を受けました。現在、プラットフォームは6,428のモデルを作成し、176のトレーニングノード、236の検証ノード、1,178のデリゲーターに接続しています。
分散型トレーニングプロジェクトと比較して、Flockなどの連合学習ベースのシステムは、トレーニング効率、スケーラビリティ、プライバシー保護の面でより優れた利点を備えています。特に、中小規模のモデルの協調トレーニングに適しています。これらのソリューションは実用的で実装が容易であり、エンジニアリングレベルでの実現可能性の最適化に重点を置いています。GensynやPluralisなどのプロジェクトは、トレーニング手法と通信メカニズムにおけるより深い理論的ブレークスルーを追求しています。システム上の課題はより大きくなっていますが、真に「信頼のない分散型」のトレーニングパラダイムの探求に近づいています。
EXO: エッジコンピューティングのための分散型トレーニングの試み
EXOは、現在のエッジコンピューティングシーンにおける代表的なAIプロジェクトであり、家庭用コンシューマーデバイス上で軽量AIトレーニング、推論、エージェントアプリケーションの実現に特化しています。分散型トレーニングパスは「低通信オーバーヘッド+ローカル自律実行」を重視し、DiLoCo非同期遅延同期アルゴリズムとSPARTAスパースパラメータ交換メカニズムを用いることで、マルチデバイス協調トレーニングにおける帯域幅要件を大幅に削減します。システムレベルでは、EXOはオンチェーンネットワークの構築や経済的インセンティブメカニズムの導入は行わず、代わりにシングルマシン・マルチプロセスシミュレーションフレームワーク「EXO Gym」を発表しました。これにより、研究者はローカル環境で分散トレーニング手法の迅速な検証と実験を容易に行うことができます。
1. コアメカニズムの概要
DiLoCo 非同期トレーニング: 不安定なネットワークに適応するために、H ステップごとにノード同期が実行されます。
SPARTA スパース同期: 各ステップで非常に少数のパラメータ (例: 0.1%) のみが交換されるため、モデルの関連性が維持され、帯域幅の要件が削減されます。
非同期の組み合わせ最適化: これら 2 つを組み合わせて使用することで、通信とパフォーマンスの間のより適切な妥協点を実現できます。
evML検証メカニズムの探究:Edge-Verified Machine Learning(evML)は、TEE/Secure Contextを用いた低コストのコンピューティング検証を提案し、リモート検証とスポットチェックメカニズムにより、ステーキングなしでエッジデバイスの信頼できる参加を実現します。これは、経済的なセキュリティとプライバシー保護の間のエンジニアリング的な妥協点です。
2. ツールとシナリオの適用
EXO Gym: 単一デバイス上でマルチノードのトレーニング環境をシミュレートし、NanoGPT、CNN、Diffusion などのモデルの通信戦略実験をサポートします。
EXO デスクトップ アプリ: ローカルでの大規模モデルの実行、iPhone ミラーリングの制御、プライベート コンテキストの統合 (SMS、カレンダー、ビデオ録画など) などのプライバシーに配慮したパーソナライズ機能をサポートする、個々のユーザー向けのデスクトップ AI ツールです。
EXO Gymは、主に既存の通信圧縮技術(DiLoCoやSPARTAなど)を統合し、軽量なトレーニングパスを実現する、探索指向の分散型トレーニング実験プロジェクトに近いものです。Gensyn、Nous、Pluralisなどのプロジェクトと比較すると、EXOはまだオンチェーンコラボレーション、検証可能なインセンティブメカニズム、そして実際の分散ネットワーク展開といったコア段階には至っていません。
分散型トレーニングのフロントエンドエンジン:モデルの事前トレーニングの全体像
デバイスの異機種混在、通信のボトルネック、連携の難しさ、信頼できる実行の欠如など、分散型トレーニングに共通する主要な課題に直面し、Gensyn、Prime Intellect、Pluralis、Nous Researchは、差別化されたシステムアーキテクチャパスを提案しました。トレーニング方法と通信メカニズムの観点から、これら4つのプロジェクトは、独自の技術的焦点とエンジニアリング実装ロジックを実証しました。
トレーニング方法の最適化に関しては、協調戦略、更新メカニズム、非同期制御など、トレーニング前からトレーニング後までのさまざまな段階をカバーする 4 つの主要な側面を調査しました。
Prime IntellectのPRIME-RLは、事前学習段階における非同期スケジューリング構造です。「ローカル学習+定期同期」戦略により、異機種混在環境における効率的で検証可能な学習スケジューリングメカニズムを実現します。この手法は高い汎用性と柔軟性を備え、高度な理論的革新性を備え、学習制御構造の明確なパラダイムを提案しています。エンジニアリング実装の難易度は中程度から高く、基盤となる通信・制御モジュールへの要求も高くなっています。
Nous Researchが発表したDeMoオプティマイザーは、非同期低帯域幅環境におけるトレーニング安定性の問題に焦点を当て、異機種GPU環境下でもフォールトトレランスの高い勾配更新プロセスを実現します。これは、「非同期通信圧縮閉ループ」において理論と工学の融合を達成した数少ないソリューションの一つです。特に圧縮とスケジューリングの協調パスにおいて、理論的な革新性は非常に高く、一方でエンジニアリング実装も非常に困難で、特に非同期並列処理の調整精度に依存しています。
PluralisのSWARM + NAGは、現在の非同期トレーニングパスにおいて最も体系的で革新的な設計の一つです。非同期モデル並列フレームワークを基盤とし、列空間スパース通信とNAGモーメンタム補正を導入し、低帯域幅環境下でも安定的に収束する大規模モデルトレーニングソリューションを構築します。高度な理論的革新性を備え、非同期協調トレーニングの構造的先駆者です。エンジニアリングの難易度も極めて高く、多階層同期とモデルセグメンテーションの深い統合が求められます。
GensynのRL Swarmは主に訓練後の段階に使用され、エージェントの戦略の微調整と協調学習に重点を置いています。訓練プロセスは「生成-評価-投票」の3段階プロセスを採用しており、マルチエージェントシステムにおける複雑な行動の動的調整に特に適しています。理論的な革新性は中程度から高く、主にエージェントの協調ロジックに反映されています。エンジニアリング実装の難易度は中程度で、主な課題はシステムのスケジューリングと行動収束制御にあります。
通信メカニズムの最適化に関しても、これら 4 つのプロジェクトはそれぞれ独自のターゲット レイアウトを持っており、一般的に帯域幅のボトルネック、ノードの異質性、およびスケジューリングの安定性の問題に対する体系的なソリューションに重点を置いています。
Prime IntellectのPCCLは、従来のNCCLに代わる低レベル通信ライブラリであり、上位レベルの学習プロトコルのためのより堅牢な集合通信基盤を提供することを目的としています。理論的な革新性は中程度から高く、フォールトトレラントな通信アルゴリズムにおいて一定のブレークスルーが達成されています。エンジニアリングの難易度は中程度で、モジュールの適応性は高くなっています。
Nous ResearchのDisTrOは、DeMoの中核通信モジュールであり、低帯域幅環境における通信オーバーヘッドの最小化と、トレーニング閉ループの連続性の確保に重点を置いています。スケジューリングと調整構造において高い理論的革新性と普遍的な設計価値を有していますが、エンジニアリングが難しく、圧縮精度とトレーニング同期に対する要件が厳しいという難点があります。
Pluralisの通信メカニズムはSWARMアーキテクチャに深く組み込まれており、大規模モデルの非同期学習における通信負荷を大幅に軽減すると同時に、収束性を確保し、効率的なスループットを維持します。高度な理論的革新性を備え、非同期モデル通信設計のパラダイムを確立しています。エンジニアリングの難易度は極めて高く、分散モデルオーケストレーションと構造的スパース性制御に依存しています。
GensynのSkipPipeは、RL Swarm向けのフォールトトレラントなスケジューリングコンポーネントです。このソリューションは導入コストが低く、主にエンジニアリングランディング層のトレーニング安定性を高めるために使用されます。理論的な革新性は中程度で、既存のメカニズムのエンジニアリング実装に近いものです。エンジニアリングの難易度は比較的低いものの、実際の導入においては非常に実用的です。
さらに、分散型トレーニング プロジェクトの価値は、ブロックチェーン コラボレーション レイヤーと AI トレーニング レイヤーという 2 つのマクロなカテゴリから測定できます。
- ブロックチェーンのコラボレーションレベル:プロトコルの信頼性とインセンティブコラボレーションロジックを重視
- 検証可能性: トレーニング プロセスが検証可能かどうか、ゲームや暗号化のメカニズムが導入されているかどうかについて信頼を構築します。
- インセンティブメカニズム: タスク駆動型のトークン報酬/役割メカニズムが設計されているかどうか。
- オープン性と参入障壁: ノードへのアクセスが容易かどうか、集中化されているか、許可制御されているか。
- AIトレーニングシステムレベル:エンジニアリング能力とパフォーマンスのアクセシビリティを強調
- スケジューリングとフォールト トレランスのメカニズム: フォールト トレラント、非同期、動的、分散のいずれかであるか。
- トレーニング方法の最適化: モデルのトレーニング アルゴリズムまたは構造が最適化されているかどうか。
- 通信パスの最適化: 勾配/スパース通信を圧縮して低帯域幅に適応するかどうか。
次の表は、上記の指標システムに基づいて、分散型トレーニングパスにおける Gensyn、Prime Intellect、Pluralis、Nous Research の技術的深さ、エンジニアリングの成熟度、理論的革新性を体系的に評価しています。
分散型トレーニングのポストチェーンエコロジー:LoRAに基づくモデルの微調整
分散型トレーニングのバリューチェーン全体において、Prime Intellect、Pluralis.ai、Gensyn、Nous Researchといったプロジェクトは、主にモデルの事前学習、通信メカニズム、協調最適化といったフロントエンドインフラの構築に重点を置いています。一方、別のタイプのプロジェクトは、学習後の段階におけるモデルの適応と推論の展開(学習後の微調整と推論配信)に重点を置いており、事前学習、パラメータ同期、通信最適化といった体系的な学習プロセスに直接関与していません。代表的なプロジェクトとしては、Bagel、Pond、RPS Labsなどが挙げられます。いずれもLoRA微調整手法をベースとし、分散型トレーニングエコシステムの重要な「バックエンドチェーン」を構成しています。
LoRA + DPO: Web3の微調整された展開への現実的な道
LoRA(Low-Rank Adaptation)は、効率的なパラメータ微調整手法です。その核となる考え方は、事前学習済みの大規模モデルに低ランク行列を挿入することで、元のモデルパラメータを固定したまま新しいタスクを学習させることです。この戦略は、学習コストとリソース消費を大幅に削減し、微調整速度と導入の柔軟性を向上させます。特に、モジュール性と複合呼び出しを特徴とするWeb3シナリオに適しています。
LLaMAやGPT-3といった従来の大規模言語モデルは、数十億、あるいは数千億ものパラメータを持つことが多く、直接的な微調整はコストがかかります。一方、LoRAは、少数のパラメータ行列を挿入するだけで大規模モデルの効率的な適応を実現し、現在最も実用的な主流手法の一つとなっています。
直接選好最適化(DPO)は、近年登場した言語モデルの学習後手法であり、LoRA微調整メカニズムと組み合わせて、モデルの挙動調整段階でよく用いられます。従来のRLHF(Reinforcement Learning from Human Feedback)手法と比較して、DPOはペアサンプルを直接最適化することで選好学習を実現し、複雑な報酬モデリングと強化学習プロセスを排除します。構造がシンプルで収束性が安定しており、特に軽量かつリソースが限られた環境での微調整タスクに適しています。高い効率性と使いやすさから、DPOは多くの分散AIプロジェクトにおいて、モデル調整段階において徐々に好まれるソリューションになりつつあります。
強化学習(RL):トレーニング後の微調整の未来
長期的な視点から見ると、ますます多くのプロジェクトが、分散型トレーニングにおいて、より適応性と進化の可能性を秘めた中核的なアプローチとして、強化学習(RL)を捉えています。静的データに依存する教師あり学習やパラメータ微調整メカニズムと比較して、RLは動的な環境における戦略の継続的な最適化を重視しており、これはWeb3ネットワークにおける非同期、異種混合、インセンティブ駆動型のコラボレーションパターンに自然に適応します。環境との継続的なインタラクションを通じて、RLは高度にパーソナライズされた継続的な増分学習プロセスを実現し、エージェントネットワーク、オンチェーンタスクマーケット、スマートエコノミーの構築のための進化可能な「行動インテリジェンス」インフラストラクチャを提供します。
このパラダイムは、概念上、分散化の精神と非常に整合しているだけでなく、システム上の大きな利点も備えています。しかしながら、エンジニアリングのハードルが高く、スケジューリングの仕組みが複雑なため、強化学習は現段階では実装において依然として大きな課題に直面しており、短期間で広く普及させることは困難です。
注目すべきは、Prime Intellect の PRIME-RL と Gensyn の RL Swarm が、RL をトレーニング後の微調整メカニズムからトレーニング前の主要構造へと進化させ、信頼調整を必要としない RL 中心の共同トレーニング システムの構築を試みていることです。
Bagel (zkLoRA): LoRA の微調整のための信頼できる検証レイヤー
Bagelは、LoRA微調整メカニズムに基づくゼロ知識証明(ZK)テクノロジーを導入し、「オンチェーンモデル微調整」プロセスにおける信頼性とプライバシー保護の問題を解決することに取り組んでいます。zkLoRAは実際のトレーニング計算には参加しませんが、軽量で検証可能なメカニズムを提供します。これにより、外部ユーザーは元のデータや重みにアクセスすることなく、微調整されたモデルが指定されたベースモデルとLoRAパラメータから実際に派生したものであることを確認できるようになります。
GensynのVerdeやPrime IntellectのTOPLOCが学習プロセスの動的な検証、つまり「動作が実際に発生したかどうか」に重点を置いているのに対し、Bagelは「微調整結果が信頼できるかどうか」という静的な検証に重点を置いています。zkLoRAの最大の利点は、検証リソースの消費量が少なく、プライバシー保護が強力であることです。しかし、その適用範囲は通常、パラメータ変更が小さい微調整タスクに限定されます。
Pond: GNNシナリオの微調整とエージェント進化プラットフォーム
Pondは、グラフニューラルネットワーク(GNN)の微調整に焦点を当て、ナレッジグラフ、ソーシャルネットワーク、トランザクショングラフなどの構造化データアプリケーションに対応する、業界唯一の分散型トレーニングプロジェクトです。ユーザーがグラフ構造データをアップロードし、モデルトレーニングのフィードバックに参加できるようにすることで、パーソナライズされたタスクのための軽量で制御可能なトレーニングおよび推論プラットフォームを提供します。
PondはLoRAなどの効率的な微調整メカニズムも活用しています。その中核的な目標は、GNNアーキテクチャ上にモジュール化され、展開可能なインテリジェントエージェントシステムを実現することです。これにより、分散環境における「小規模モデルの微調整+マルチエージェントコラボレーション」という新たな探求の道が開かれます。
RPS Labs: DeFi向けAI駆動型流動性エンジン
RPS Labsは、Transformerアーキテクチャをベースとした分散型トレーニングプロジェクトであり、DeFiの流動性管理に最適化したAIモデルを活用することに特化したプロジェクトです。主にSolanaエコシステムに導入されています。主力製品であるUltraLiquidは、最適化されたモデルを用いて流動性パラメータを動的に調整し、スリッページを削減し、取引の深度を高め、トークン発行と取引体験を最適化するアクティブなマーケットメイキングエンジンです。
さらに、RPSは流動性プロバイダーがDEXでの資本配分戦略をリアルタイムで最適化できるように支援するUltraLPツールもリリースしました。これにより、資本効率が向上し、一時的な損失のリスクが軽減され、金融シナリオにおけるAI微調整の実際的な価値が反映されます。
フロントチェーンエンジンからバックチェーンエコシステムへ:分散型トレーニングの未来
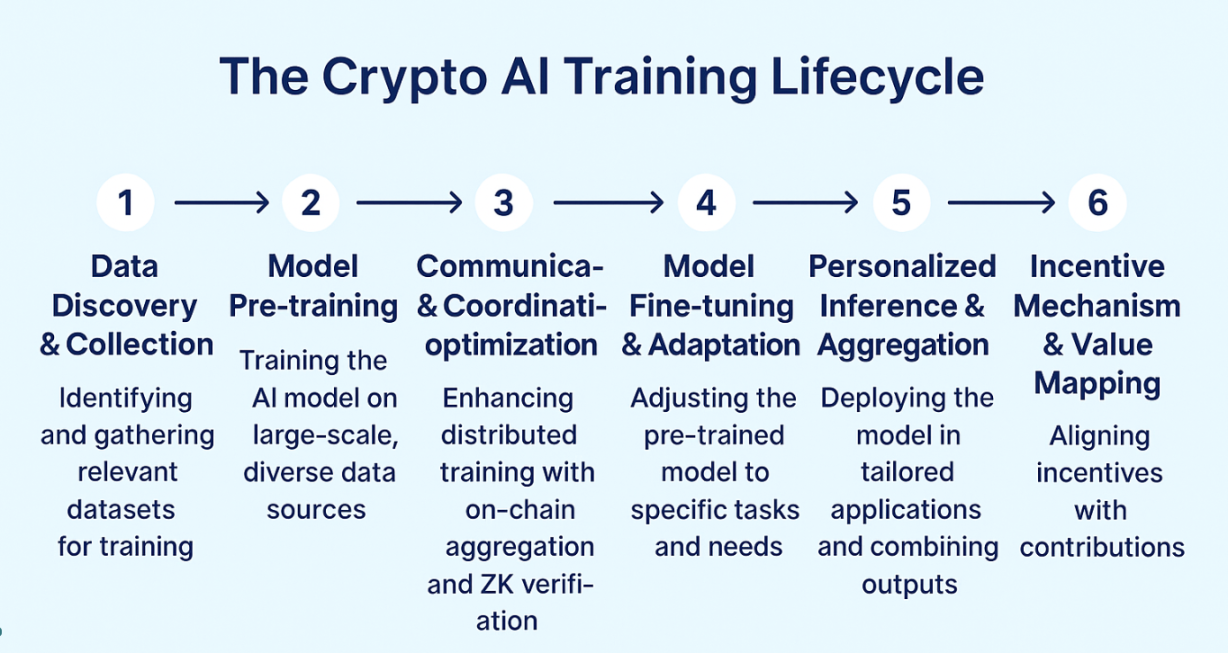
分散型トレーニングの完全なエコロジカルマップは、フロントチェーンエンジンがモデルの事前トレーニング段階に対応し、バックチェーンエコロジーがモデルの微調整と展開段階に対応し、インフラストラクチャからアプリケーションの実装まで完全な閉ループを形成するという2つのカテゴリに分けられます。
フロントチェーンエンジンは、モデルの事前学習のための基盤プロトコルの構築に重点を置いており、Prime Intellect、Nous Research、Pluralis.ai、Gensynといったプロジェクトに代表されます。これらのプロジェクトは、非同期更新、スパース通信、学習検証可能性を備えたシステムアーキテクチャの構築に注力し、トラストレスネットワーク環境における効率的で信頼性の高い分散学習機能の実現に取り組んでおり、分散学習の技術的基盤を形成しています。
同時に、Flock は中間層の代表として、連合学習パスを使用してモデル集約、オンチェーン検証、およびマルチパーティインセンティブメカニズムを統合し、トレーニングとデプロイメントの間に実現可能で協力的なブリッジを構築し、マルチノード協調学習の実用的なパラダイムを提供します。
ポストチェーン・エコシステムは、アプリケーション層におけるモデルの微調整とデプロイメントに重点を置いています。Pond、Bagel、RPS Labsなどのプロジェクトは、LoRA微調整手法を中心に展開されています。Bagelはチェーン上で信頼できる検証メカニズムを提供し、Pondはグラフニューラルネットワークの小規模モデルの進化に焦点を当て、RPSは微調整モデルをDeFiシナリオにおけるスマートマーケットメイキングに適用しています。これらのプロジェクトは、推論APIやエージェントSDKなどのコンポーネントを通じて、開発者とエンドユーザーに敷居の低い構成可能なモデル呼び出しとパーソナライズされたカスタマイズソリューションを提供し、分散型AI実装の重要なエントリーポイントとなっています。
分散型トレーニングは、AI時代におけるブロックチェーン精神の自然な発展であるだけでなく、グローバルな協働型インテリジェント生産性システムのインフラのプロトタイプでもあると私たちは信じています。将来、この困難な道のりを振り返るときも、私たちは初心を忘れず、互いに励まし合うでしょう。分散化は単なる手段ではなく、価値そのものなのです。


