
著者: 秦 静春
レビュアー:Leon lee
出典: コンテンツ協会 - 投資調査
現在、分散型AIエージェント(DAI-Agent)の分野は大きな注目を集めており、関連プロジェクトの特徴や解決する問題、将来性などが紹介された記事も多くあります。これらの記事は投資家がプロジェクトをある程度理解するのに役立ちますが、そのほとんどは詳細な分析に欠けており、AIの基本的な特性やWeb3の現状を掘り下げていません。そのため、Web3 を最適化するのか、それとも重要なコンポーネントとして機能するのかなど、Web3 価値インターネットの実践における分散型 AI の役割を明確にすることは困難です。分散型 AI と Web3 価値インターネット経済の間の内部ロジックを明確にしなければ、分散型 AI の役割を深く理解することはできませんし、そのコアコンポーネントが Web3 に存在する問題をどのように解決できるかを把握することもできません。たとえば、2 つの主要コンポーネントである分散モデルと DAI エージェントはそれぞれどのような問題を解決するのか、また、それらと Web3 の間にはどのような固有のロジックがあるのかなどです。これらの内部ロジックを理解しなければ、この分野の潜在的な価値を評価することは困難です。これにより、潜在性の高い投資方向を正確に選択することが困難になるだけでなく、正しい軌道とプロジェクトを選択したとしても、市場センチメントの変動によりそれに固執することが困難になる可能性があります。そのために、Web3の現在の基本状況とAIの基本特性を深く分析し、両者の統合によって価値あるインターネットの実現がどのように実現できるか、そしてArweaveとAOがAIを通じてこのプロセスをどのように支援できるかを探るつもりです。内容が豊富なため、著者は 2 つの記事で詳しく説明します。
- 価値あるインターネットの実現には、現在の Web3 を分散型 AI と統合する必要がある理由。
現在、多くのパブリックチェーンプロジェクトは、ETHやさまざまなL2、Solanaなどのブロックチェーンなど、基盤となるインフラストラクチャの最適化と拡張に主な取り組みを集中しています。しかし、AIを統合せずにブロックチェーンの拡張のみを追求した場合、Web3価値インターネットの実装を促進することは困難になると思います。現在、Web3 にはスケーラビリティの限界に加えて、データの断片化の問題もあります。ユーザーの個人データはさまざまなチェーンや DApp に分散しているため、管理が難しく、インタラクション コストが高く、操作が複雑になり、ユーザーによるデータの積極的な貢献が著しく制限されています。さらに、分散化された性質により、管理と調整が非効率になります。これらの問題は Web3 の開発を大きく制限します。 AI は、学習、推論、意思決定を自主的に行う能力を備えています。AI エージェントは、ユーザーのインテリジェント アシスタントとして機能し、効率を大幅に向上させます。両者の統合により、ユーザーエクスペリエンスが大幅に向上し、参入障壁が低下し、Web3 の開発が促進されます。
- 分散型ストレージとコンピューティング プラットフォーム、分散型モデル、DAIAgent の固有の関係: これら 3 つを組み合わせることで、Web3 データ資産の経済活動の閉ループが開かれ、インターネットの真の価値が実現されます。
1.1 DAIエージェント
Web3 のコア機能の 1 つは、ユーザーが自分のデータを制御できることです。 DAIAgent は、ユーザーがデータを集中的に管理および収集できるように支援し、さまざまなプラットフォームにデータが分散しているという問題を効果的に解決します。同時に、ユーザーのインテリジェント アシスタントとして機能し、操作の難易度を軽減し、Web3 とのインタラクション効率を向上させます。たとえば、DAIAgent は、DID の作成、更新、取り消しなど、DID ライフサイクルの管理をユーザーを支援し、データの管理と使用エクスペリエンスを簡素化します。以降の議論の基礎を築くために、ここで AI-Agent と DID の関係について詳しく議論する必要があります。 Web3.0 環境では、DID と DAI-Agent は高い補完性と互換性を備えています。
a.データ統合と高品質な入力:
AI-Agent は、プラットフォーム間でデータ (ソーシャル、医療、専門データなど) を統合し、情報サイロを効果的に解消します。そのインテリジェントなアルゴリズムは、DID のニーズ (各データ ソースの信頼性の評価、重複データや価値の低いデータの削除、DID データ モデル仕様に従ったデータの整理など) に応じてデータをフィルタリング、クリーンアップ、フォーマットできるため、高品質の DID の作成が保証されます。同時に、差分プライバシー、準同型暗号化、最新のマルチパーティセキュアコンピューティング(MPC)テクノロジーを使用して、元のデータを漏らすことなくデータ分析と計算を完了します(たとえば、機密性の高い医療データを収集する場合、個人のプライバシーを保護しながら健康情報のニーズを満たすことができます)。さらに、クロスチェーン相互運用性プロトコル(Polkadot、Cosmos、その他のエコシステムなど)が成熟するにつれて、DAIAgent はより多くのデータソース間のシームレスな接続を実現し、データ統合の効率と精度をさらに向上させることが期待されます。分散型アーキテクチャは、単一障害点や単一のエンティティによるデータ制御のリスクを回避するだけでなく、スマート コントラクトによる自動データ収集とリアルタイム更新を可能にし、信頼性が高く動的なデジタル ID システムの構築を強力にサポートします。
b.アイデンティティ認証と承認の基盤:
分散環境では、デジタル ID システムが DAIAgent に必要な認証および承認メカニズムを提供し、AI-Agent が他のエージェントと安全にやり取りする際に正当な ID と権限を証明できるようにします。このプロセスは技術的な手段に依存するだけでなく、分散型自律組織 (DAO) メカニズムを通じてさらに強化され、コミュニティが監督とガバナンスに参加することで、システムの透明性とセキュリティがさらに強化されます。
c.信頼を高め、インタラクションコストを削減する:
DID システムの助けにより、DAIAgent のアイデンティティと動作はより透明かつ検証可能になり、それによって信頼が構築され、他のエージェントとのコラボレーションが促進されます。同時に、AI-Agent は、ユーザーとシステム間のインタラクション コストを削減し、複雑な操作を簡素化することで、分散型の性質によって引き起こされる非効率性を効果的に軽減します。さらに、DAIAgent は、新興のフェデレーテッド ラーニングやプライバシー コンピューティング テクノロジーと組み合わせることで、将来的には、元のデータを公開することなく、クロスプラットフォームおよびクロスドメインのデータ コラボレーションとインテリジェントな意思決定を実現し、ユーザーにさらに正確でパーソナライズされたサービスを提供できるようになります。
1.2分散型モデル
このモデルは、主に AI エージェントの「頭脳」とみなすことができ、インテリジェンスを実現するための中核コンポーネントです。今後、さまざまな業界で多数の AI エージェントが登場し、役割を果たすようになるでしょう。これらの専門分野 (医療、教育、金融など) では、それらをサポートする独自の AI モデルが必要になります。一般的な AGI はユーザーの基本的なニーズを満たすことができますが、さまざまな専門分野では、多数の専門 AI エージェントが連携して動作する必要があり、多種多様なモデルが必要になります。分散型モデルは集中型モデルに比べて許可不要性や検証可能性などのメリットがあるため、将来的にはDAI-Agentに確実に支持されるでしょう。許可不要の機能により、中央機関の承認に頼ることなく誰でもモデル開発に参加でき、技術的なオープン性が促進されます。同時に、許可不要の機能により、DAIAgentはさまざまなモデルをより柔軟にスケジュールし、インテリジェントな特性を大幅に強化できます。上記の利点に加えて、将来的には、データ共有とモデルトレーニングの面では、フェデレーテッドラーニングとクロスドメインコラボレーションメカニズムも、分散型モデルの開発を促進し、データのプライバシーを保護しながらモデルトレーニングの効率とセキュリティを確保するための重要なテクノロジーになるでしょう。特に金融や医療などの機密性の高い分野の場合、システムの全体的な信頼性と堅牢性を確保するために、モデルのトレーニング プロセスとデータ ソースを複数回検証する必要があります。
1.3ブロックチェーン技術に基づく分散型ストレージおよびコンピューティングプラットフォーム
Web3データ権利確認を実現するには、大規模なデータ交換をサポートする検証可能なデータコンセンサスインフラストラクチャを確立するための分散型ストレージおよびコンピューティングプラットフォームを構築する必要があります。具体的には、Arweave と AO の全体的なソリューションは、ストレージ側とコンピューティング側の両方にデータコンセンサス インフラストラクチャを構築し、それによって次の目標を達成します。
- データ保存コストを削減し、データのセキュリティと不変性を確保します。
- 大規模なデータ交換を促進し、分散型 AI エコシステムのホスティングと運用のための強固な基盤を提供します。
- 統合されたデータ ストレージ層により、データ統合プロセスが簡素化され、データの分散によって生じる統合の複雑さが軽減されます。
- 同時に、このプラットフォームは、Web3 での DID システムの構築に必要なデータ サポートも提供し、デジタル ID の管理と適用を強化します。
上記の 3 つの点は互いに補完し合います。
- DAIAgent はトークンインセンティブを組み合わせて、ユーザーがデータを投稿し、Web3 と積極的にやり取りして、より多くのデータを生成するように促します。
- 大量のデータの生成により、分散型ストレージおよびコンピューティング プラットフォームの開発が促進されました。これらのプラットフォームは、データ ストレージ コストを削減できるだけでなく、データ所有権の確認も促進できるためです。
- 分散型モデルは分散型プラットフォーム上でホストされる必要があります。これにより、ストレージとコンピューティングのコストが削減されるだけでなく、モデルの検証可能性と検閲耐性が確保され、モデルのセキュリティと信頼性が向上し、モデル開発がさらに促進されます。
さらに、分散型モデルのトレーニングには大量の高品質データが必要であり、大規模で高品質なデータの出現により、モデルの品質が大幅に向上します。モデルの品質の向上により、DAIAgent はますますインテリジェントになり、ユーザーのインタラクションが促進され、より多くのデータが生成されます。また、データの継続的な充実により、ストレージおよびコンピューティング プラットフォームの改善がさらに促進され、相互接続された無限の正のサイクルが形成され、最終的に完全なデータ資産経済エコシステムが構成されます。このエコシステムは、データ資産の循環のための閉ループを作成し、真に価値のあるインターネット エコシステムを形成するための鍵となります。図に示すように:
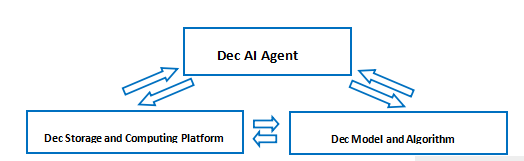
上記の論理分析に基づくと、DAI-Agent はエコシステム全体における重要なリンクにすぎず、その開発は他の 2 つの部分 (分散型ストレージ/コンピューティング プラットフォームと分散型モデル) のサポートに大きく左右されることがわかります。したがって、このようなプロジェクトに投資する際には、プロジェクトが完全なデータ資産経済エコシステムを構築する能力を持っているかどうか、または他の2つの当事者と比較的安定した協力関係を確立しているかどうかに注意を払う必要があります。単一方向のプロジェクトにのみ投資すると、リスクが大幅に増加します。また、現在普及しているELIZA、VIRTUAL、APCなどのDAIAgentプロトコルは、多様なモデルをサポートしていますが、OpenAIなどの集中型モデルプロバイダーがアクセスできるものもあります。これにより、ユーザーの多様なニーズを満たすことができますが、集中型モデルの割合が高すぎると、許可のない機能が不足しているため、プロトコルの長期的な開発が制限されます。
2.ここで注目したいのは、Arweave 永久ストレージ + AO 超並列コンピュータの総合ソリューションです。
1. 並列処理機能
ベースレイヤーと個々のロールアップが通常単一のプロセスとして実行される Ethereum などのネットワークとは異なり、AO は計算の完全な検証可能性を確保しながら、任意の数のプロセスを並行して実行することをサポートします。さらに、これらのネットワークは、各 AO プロセスが独立したまま、グローバルに同期された状態で動作する必要があります。この独立性により、各プロセスはより多くの相互作用を処理できるようになり、コンピューティングのスケーラビリティが大幅に向上します。これは、高いパフォーマンスと信頼性が求められるアプリケーション シナリオに特に適しています。将来、多数の DAIAgent がチェーン上で継続的にタスクを実行するようになると、システムのスケーラビリティに対する要件はより厳しくなりますが、AO の超並列処理機能はまさにこの要求を満たします。
2. 大規模モデルやその他の種類のモデルを保存および実行する機能
AO ネットワークでは、単一ノードのメモリ制限は現在 16 GB ですが、プロトコル レベルでのメモリ拡張制限は 18 EB に達する可能性があり、これは既存の AI 分野のほとんどのモデル (Llama3 の非量子化バージョン、Falcon シリーズ、その他多くのモデルなど) を実行するのに十分です。 GPT-4のパラメータが1兆7600億を超えたことを考えると、GPT-5では50兆を超えると予想されており、今後もモデルサイズは拡大し続けるでしょう。 AO は非常に強力なスケーラビリティを備えています。大規模モデルの実行要件を満たすためにコンピューティング ユニットを拡張するには、物理的にメモリまたはグラフィック カードを増やすだけで済みます。
Arweave は、新しいブロックを複数の古いブロックに接続できる独自のブロックウィーブ テクノロジを使用しているため、非常にスケーラブルで、理論的にはさまざまなモデルや大規模なデータを保存できます。同時に、WeaveDriveテクノロジーにより、アプリケーションはローカルディスクにアクセスするのと同じくらい簡単にArweave上のデータにアクセスできるため、さまざまなアプリケーションを構築できます。あらゆる種類のアプリケーションが Arweave 上に永久に保存されたデータにアクセスでき、AO+Arweave はコンピューティングとストレージの両面からデータ権利確認のためのインフラストラクチャを構築し、大規模なデータ資産交換の基盤を築いています。これは、AO プラットフォーム上でアプリケーションを開発しようとする開発者にとって非常に魅力的です。同時に、さまざまなアプリケーションシナリオにより、さまざまなモデルとDAIエージェントに多様な着陸シナリオが提供され、AIエコシステムの発展が促進されます。
3. データはAIエコシステムの3つの主要要素の1つです。AO + Arweaveエコシステムのデータのほとんどは高品質のデータであり、統一されたデータストレージレイヤーを備えています。
大規模で高品質なデータは、モデルのトレーニングに不可欠です。高品質なデータには通常、正確性、一貫性、妥当性、完全性、適時性、一意性などの特性があります。 AO+Arweave エコシステムでは、流通しているデータのほとんどがこれらの特性を満たしています。詳細な技術的実装の詳細については、以前の記事「Arweave 永続ストレージ + AO スーパー並列コンピュータ: データ合意インフラストラクチャの構築」をお読みください。ここで強調する必要があるのは、Arweave の永続ストレージの利点です。永続ストレージの特性により、保存されるデータはより重要になることが多く、データの保存期間が長くなるほど、その価値が反映されます。これは、保存と追跡が容易になるだけでなく、データの所有権も容易になるためです。 AIトレーニングには、大規模で高品質なデータが極めて重要です。Arweaveは統合データストレージレイヤーとして、さまざまなプロジェクトのデータを統合する機能を備えています。比較すると、Ethereum、Solanaなどは統合ストレージレイヤーがないため、データ統合がより困難です。 Arweave のこれらの機能は、Web3 内で DID を構築する上で極めて重要な、データの収集、統合、整合性の保証において重要な役割を果たします。統合されたデータ ストレージ レイヤーは、クロスプラットフォームのデータ統合よりもはるかに便利です。さらに、AO と Arweave の統合により、すべてのエージェント インタラクション データを永続的に保存できるようになり、説明責任メカニズム、DID、および評価システムの確立を強力にサポートします。たとえば、RedStone プロジェクトでは現在、Arweave を使用して DID を構築し、AI エージェントの開発にインフラストラクチャ サポートを提供するための説明責任メカニズムを確立しています。
4. AO + ArweaveはAIの検証可能性を高める
検証可能性は AI の開発にとって極めて重要です。検証可能性により、AI モデルの予測と出力が透明で、改ざん不可能であり、独立して検証可能であることが保証され、AI の信頼性とセキュリティが向上し、金融、ヘルスケア、法律、自動運転などの信頼性が高い分野で AI を広く使用できるようになります。同時に、検証可能性により、開発者は悪意のある改ざんを心配することなく、より自信を持ってモデルを共有し、共同作業を行うことができます。 AO+Arweave は SCP ストレージ方式を採用しているため、AO 内のすべてのデータとモデルを Arweave にホログラフィックに保存でき、誰でもデータ ソース、モデル操作プロセス、出力結果を検証できます。同時に、コンピューティング ユニットによって提供される暗号化された署名により、計算結果の信頼性と整合性がさらに保証されます。ゼロ知識証明技術と分散検証メカニズムの継続的な改善により、将来的には、モデル出力をリアルタイムで検証できるだけでなく、モデルのトレーニングデータ、パラメータ更新などのプロセス全体を追跡および監査することも可能になり、包括的なマルチレベルの信頼システムが形成されます。さらに、AO と PADO が共同で開始した検証可能機密コンピューティング (vcc) では、ZKFHE (ゼロ知識完全準同型暗号化) テクノロジを使用して、データとモデルのプライバシーを保護しながら、検証可能性と計算可能性を保証します。このようなメカニズムは、データ共有のリスクを大幅に軽減するだけでなく、モデルプロバイダーに知的財産保護を提供し、より高品質なモデルの公開と共有を促進します。この信頼システムは、トークンインセンティブメカニズムと組み合わせることで、ユーザーが積極的にデータを提供し、AIエコシステム全体をより高いレベルに引き上げるようさらに促すことが期待されます。
AO+Arweave エコシステムの基本的なコンポーネントと関係を図に示します。
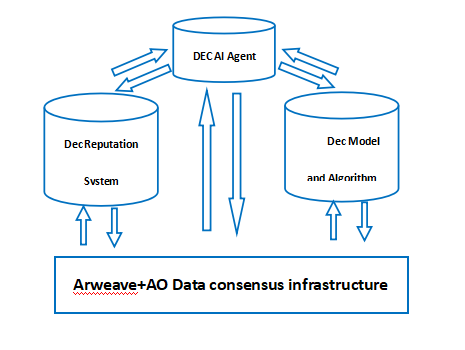
要約すると、AO+Arweave エコシステムは、分散型 AI に優れた動作環境を提供します。分散型 AI エコシステムのサポートに適した優れたスケーラビリティとホスティング機能を備えているだけでなく、大規模で高品質なデータの保存と交換、並列コンピューティング、検証可能性においても大きな利点があります。これらの要素を組み合わせることで、AO + Arweave エコシステムは分散型 AI の開発に理想的なプラットフォームになります。上記のデモンストレーションを通じて、分散型 AI は間違いなく、Web3 価値インターネット エコシステムの実装に必要な 3 つの主要要素において重要な役割を果たします。 AO+Arweave+AIがWeb3の実装を大きく促進することが期待できることがわかります!



