

著者 | ZeR0 ジュンダ、知東渓
編集者 | Mo Ying
1月5日、C114はラスベガスから、NVIDIAの創業者兼CEOであるジェンスン・フアン氏がCES 2026で2026年最初の基調講演を行ったと報じました。いつものように革のジャケットを着たフアン氏は、1時間半で8つの重要な開発成果を発表し、チップやラックからネットワーク設計まで、新世代プラットフォーム全体の詳細な概要を示しました。

アクセラレーテッド コンピューティングおよび AI インフラストラクチャの分野では、NVIDIA は、NVIDIA Vera Rubin POD AI スーパーコンピューター、NVIDIA Spectrum-X Ethernet 併パッケージ光学系、NVIDIA 推論コンテキスト メモリ ストレージ プラットフォーム、および DGX Vera Rubin NVL72 に基づく NVIDIA DGX SuperPOD をリリースしました。

NVIDIA Vera Rubin PODは、CPU、GPU、スケールアップ、スケールアウト、ストレージ、そして処理能力をカバーする、NVIDIAが自社開発した6つのチップを搭載しています。すべてのコンポーネントは、高度なモデルのニーズを満たし、コンピューティングコストを削減するために共同設計されています。
このうち、Vera CPUはカスタムOlympusコアアーキテクチャを採用し、Rubin GPUはTransformerエンジンを導入することで、最大50PFLOPSのNBFP4推論性能と、GPUあたり最大3.6TB/sのNVLink帯域幅を実現しています。第3世代汎用機密コンピューティング(初のラックレベルTEE)をサポートし、CPUとGPUのドメインをまたぐ完全な信頼実行環境を実現します。

これらのチップはすべて工場に戻され、NVIDIA は NVIDIA Vera Rubin NVL72 システム全体を検証し、パートナーは統合 AI モデルとアルゴリズムの実行を開始しており、エコシステム全体が Vera Rubin の展開に向けて準備を進めています。
その他の発表としては、NVIDIA Spectrum-X Ethernet のパッケージ化された光学系により電力効率とアプリケーションの稼働時間が大幅に最適化されること、NVIDIA 推論コンテキスト メモリ ストレージ プラットフォームによりストレージ スタックが再定義され、冗長な計算が削減されて推論の効率が向上すること、DGX Vera Rubin NVL72 に基づく NVIDIA DGX SuperPOD により大規模な MoE モデルのトークン コストが 1/10 に削減されることなどが挙げられます。

オープンモデルに関しては、NVIDIAはオープンソースモデルスイートの拡張を発表し、新しいモデル、データセット、ライブラリをリリースしました。これには、NVIDIA NemotronオープンソースモデルファミリーへのAgentic RAGモデル、安全モデル、音声モデルの追加に加え、あらゆる種類のロボットに適用可能な全く新しいオープンモデルが含まれます。ただし、ジェンセン・フアン氏はプレゼンテーションでこれらの詳細について詳しく説明しませんでした。
フィジカルAIに関しては、 ChatGPTの時代が到来しました。NVIDIAのフルスタック技術は、AI駆動型ロボティクスを通じてグローバルエコシステムが産業を変革することを可能にします。新しいAlpamayoオープンソースモデルスイートを含むNVIDIAの包括的なAIツールキットは、世界の輸送業界が安全なレベル4運転を迅速に実現することを可能にします。NVIDIA DRIVE自動運転プラットフォームは現在生産中で、レベル2++のAI定義運転を実現するすべての新型メルセデス・ベンツCLAに搭載されています。

01. 新型AIスーパーコンピュータ:自社開発チップ6個、シングルラックの演算能力は3.6 EFLOPSに達する
ジェンセン・フアンは、コンピュータ業界は10年から15年ごとに完全に生まれ変わると考えていますが、今回は2つのプラットフォーム革命が同時に起こっています。CPUからGPUへ、「プログラミングソフトウェア」から「トレーニングソフトウェア」へ、そしてアクセラレーティングコンピューティングとAIがコンピューティングスタック全体を再構築しています。過去10年間で10兆ドル規模のコンピューティング業界は、まさに近代化の真っ只中にあります。
同時に、コンピューティング能力に対する需要は急増しています。モデルの規模は毎年10倍に拡大し、モデル思考に使用されるトークンの数は毎年5倍に増加している一方で、各トークンの価格は毎年10分の1に減少しています。
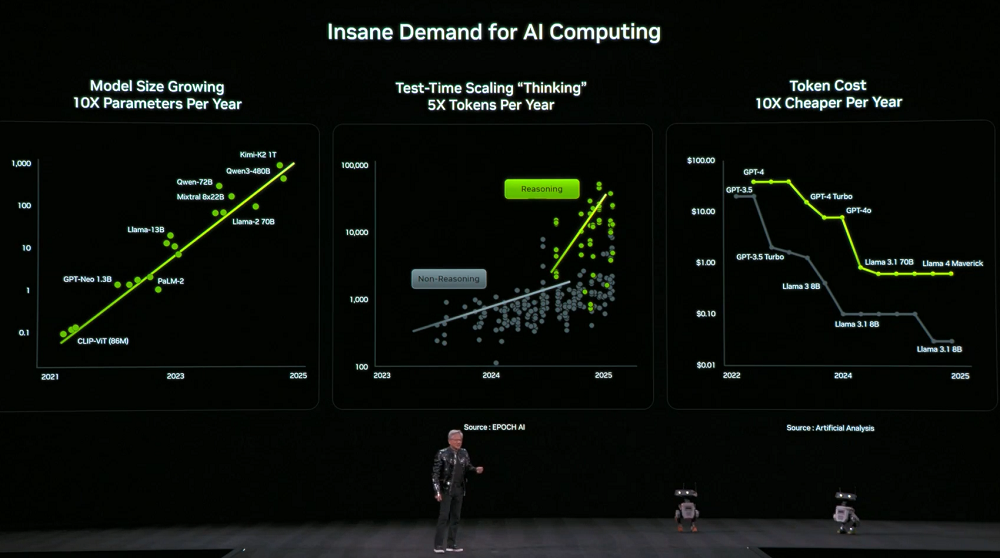
この需要に応えるため、Nvidiaは毎年新しいコンピューティングハードウェアをリリースすることを決定しました。Jensen Huang氏は、Vera Rubinが現在フル生産中であることを明らかにしました。
NVIDIA の新しい AI スーパーコンピューターである NVIDIA Vera Rubin POD は、Vera CPU、Rubin GPU、NVLink 6 スイッチ、ConnectX-9 (CX9) スマート ネットワーク カード、BlueField-4 DPU、Spectrum-X 102.4T CPO という 6 つの自社開発チップを使用しています。
Vera CPU:データ移動とエージェント処理向けに設計されており、88 個のカスタム NVIDIA Olympus コア、176 スレッドの NVIDIA Space Multithreading、CPU:GPU 統合メモリ用の 1.8TB/s NVLink-C2C サポート、最大 1.5TB (Grace CPU の 3 倍) のシステム メモリ、1.2TB/s の SOCAMM LPDDR5X メモリ帯域幅を備え、ラックレベルの機密コンピューティングをサポートし、データ処理パフォーマンスを 2 倍にします。

Rubin GPU: Transformerエンジンを導入し、NVFP4推論性能は最大50PFLOPSに達し、Blackwell GPUの5倍の性能を発揮します。下位互換性を備え、推論精度を維持しながらBF16/FP4レベルの性能向上を実現しています。NVFP4のトレーニング性能は35PFLOPSに達し、Blackwellの3.5倍の性能を発揮します。
Rubin は、前世代の 2.8 倍となる 22TB/秒の帯域幅を誇る HBM4 をサポートする最初のプラットフォームでもあり、要求の厳しい MoE モデルや AI ワークロードに必要なパフォーマンスを提供します。

NVLink 6 スイッチ:シングルレーン速度が 400Gbps に向上し、SerDes テクノロジを使用して高速信号伝送を実現します。各 GPU は、前世代の 2 倍となる 3.6TB/s の完全相互接続通信帯域幅を実現し、総帯域幅は 28.8TB/s、FP8 精度で 14.4TFLOPS のネットワーク内コンピューティング性能を実現し、100% 液体冷却をサポートします。

NVIDIA ConnectX-9 SuperNIC:各 GPU は 1.6Tb/s の帯域幅を提供し、大規模 AI 向けに最適化されており、完全にソフトウェア定義でプログラム可能な高速データ パスを備えています。

NVIDIA BlueField-4:スマートネットワークカードおよびストレージプロセッサ向けの800Gbps DPU。64コアのGrace CPUとConnectX-9 SuperNICを搭載し、ネットワークおよびストレージ関連のコンピューティングタスクをオフロードするとともに、ネットワークセキュリティ機能を強化します。前世代比で6倍のコンピューティング性能、3倍のメモリ帯域幅、GPUからデータストレージへのアクセス速度は最大2倍を実現します。

NVIDIA Vera Rubin NVL72:上記のすべてのコンポーネントをシステム レベルで単一ラック処理システムに統合し、2 兆個のトランジスタ、3.6 EFLOPS の NVFP4 推論パフォーマンス、2.5 EFLOPS の NVFP4 トレーニング パフォーマンスを実現します。
このシステムは、前世代の 2.5 倍となる 54TB の LPDDR5X メモリ、前世代の 1.5 倍となる合計 20.7TB の HBM4 メモリ、前世代の 2.8 倍となる 1.6PB/s の HBM4 帯域幅、および世界のインターネットの総帯域幅を超える 260TB/s の合計垂直スケーリング帯域幅を備えています。

第3世代MGXラック設計をベースにしたこのシステムは、モジュール式、ホストレス、ケーブルレス、ファンレスのコンピュートトレイを搭載しており、GB200と比較して組み立てとメンテナンスが18倍高速化されています。以前は2時間かかっていた組み立てが、今では約5分で完了し、システムの液冷比率は約80%から100%に向上しました。システム本体の重量は2トンで、冷却剤を追加すると2.5トンになります。

NVLinkスイッチトレイは、ゼロダウンタイムのメンテナンスとフォールトトレランスを実現し、トレイが取り外されたり、部分的に展開されたりした場合でもラックは動作を継続します。第2世代のRASエンジンにより、ゼロダウンタイムの運用ステータスチェックが可能になります。
これらの機能により、システムの稼働時間とスループットが向上し、トレーニングと推論のコストがさらに削減され、データセンターの高い信頼性と保守性の要件が満たされます。
80 社を超える MGX パートナーが、ハイパースケール ネットワークでの Rubin NVL72 の導入をサポートする準備ができています。
02. 新しい CPO デバイス、新しいコンテキスト ストレージ レイヤー、新しい DGX SuperPOD という 3 つの主要な新製品が AI 推論の効率に革命をもたらします。
同時に、NVIDIA は、NVIDIA Spectrum-X Ethernet 共同パッケージ光学系、NVIDIA 推論コンテキスト メモリ ストレージ プラットフォーム、DGX Vera Rubin NVL72 に基づく NVIDIA DGX SuperPOD という 3 つの重要な新製品をリリースしました。
1. NVIDIA Spectrum-X Ethernet 一体型オプティクス
NVIDIA Spectrum-X Ethernet 一体型オプティクスは、Spectrum-X アーキテクチャに基づいており、2 チップ設計を採用し、200Gbps SerDes を活用し、各 ASIC は 102.4Tb/s の帯域幅を提供できます。
スイッチング プラットフォームには、速度がそれぞれ 800Gb/s の 512 ポートの高密度システムと 128 ポートのコンパクト システムが含まれています。

CPO (Co-packaged Optical) スイッチング システムは、5 倍のエネルギー効率、10 倍の信頼性、5 倍のアプリケーション稼働時間を実現できます。
つまり、毎日処理できるトークンの数が増えるため、データセンターの総所有コスト (TCO) がさらに削減されます。
2. NVIDIA推論コンテキストメモリストレージプラットフォーム
NVIDIA推論コンテキストメモリストレージプラットフォームは、キーバリューキャッシュを保存するためのPODレベルのAIネイティブストレージインフラストラクチャです。BlueField-4とSpectrum-X Ethernetによって高速化され、NVIDIA DynamoおよびNVLinkと緊密に連携することで、メモリ、ストレージ、ネットワーク間の協調的なコンテキストスケジューリングを実現します。
このプラットフォームはコンテキストを第一級のデータ型として扱い、推論パフォーマンスを 5 倍、エネルギー効率を 5 倍に向上します。

これは、システム全体でコンテキストを効率的に保存、再利用、共有する能力に大きく依存する、マルチターン ダイアログ、RAG、エージェント マルチステップ推論などのロング コンテキスト アプリケーションを改善するために重要です。
AIはチャットボットから、推論、ツールの呼び出し、そして長期的な状態維持が可能なエージェント型AIへと進化しています。コンテキストウィンドウは数百万トークンにまで拡大しています。これらのコンテキストはKVキャッシュに保存されますが、ステップごとに再計算を行うとGPUの時間が浪費され、大きなレイテンシが発生するため、ストレージが必要になります。
しかし、GPUメモリは高速である一方で、容量が不足しており、従来のネットワークストレージは短期的なコンテキストには非効率的です。AI推論におけるボトルネックは、計算からコンテキストストレージへと移行しています。そのため、GPUとストレージの間に配置された、推論専用に最適化された新しいタイプのメモリ層が必要です。

このレイヤーはもはやリアクティブ パッチではありませんが、最小限のオーバーヘッドでコンテキスト データを移動するために、ネットワーク ストレージと組み合わせて設計する必要があります。
新しいストレージ層であるNVIDIA推論コンテキストメモリストレージプラットフォームは、ホストシステムに直接常駐するのではなく、BlueField-4を介してコンピューティングデバイスに接続されます。その主な利点は、ストレージプールをより効率的に拡張できるため、キーバリューキャッシュの冗長な計算を回避できることです。
NVIDIA はストレージ パートナーと緊密に連携して、NVIDIA 推論コンテキスト メモリ ストレージ プラットフォームを Rubin プラットフォームに導入し、顧客が完全に統合された AI インフラストラクチャの一部として導入できるようにしています。
3. Vera Rubin 上に構築された NVIDIA DGX SuperPOD
システムレベルでは、NVIDIA DGX SuperPOD は大規模な AI ファクトリー導入の青写真として機能します。8 基の DGX Vera Rubin NVL72 システムを採用し、NVLink 6 による垂直方向のネットワーク拡張と Spectrum-X Ethernet による水平方向のネットワーク拡張を実現し、NVIDIA 推論コンテキスト メモリ ストレージ プラットフォームを組み込み、エンジニアリング検証も実施されています。
システム全体はNVIDIA Mission Controlソフトウェアによって管理され、最大限の効率性を実現します。お客様はターンキープラットフォームとして導入し、より少ないGPUでトレーニングと推論のタスクを完了できます。
6つのチップ、トレイ、ラック、ポッド、データセンター、そしてソフトウェアを高度に連携させた設計により、Rubinプラットフォームはトレーニングと推論のコストを大幅に削減しました。前世代のBlackwellと比較して、同サイズのMoEモデルのトレーニングに必要なGPU数はわずか4分の1に削減され、同じレイテンシであれば、大規模なMoEモデルのトークンコストは10分の1に削減されます。
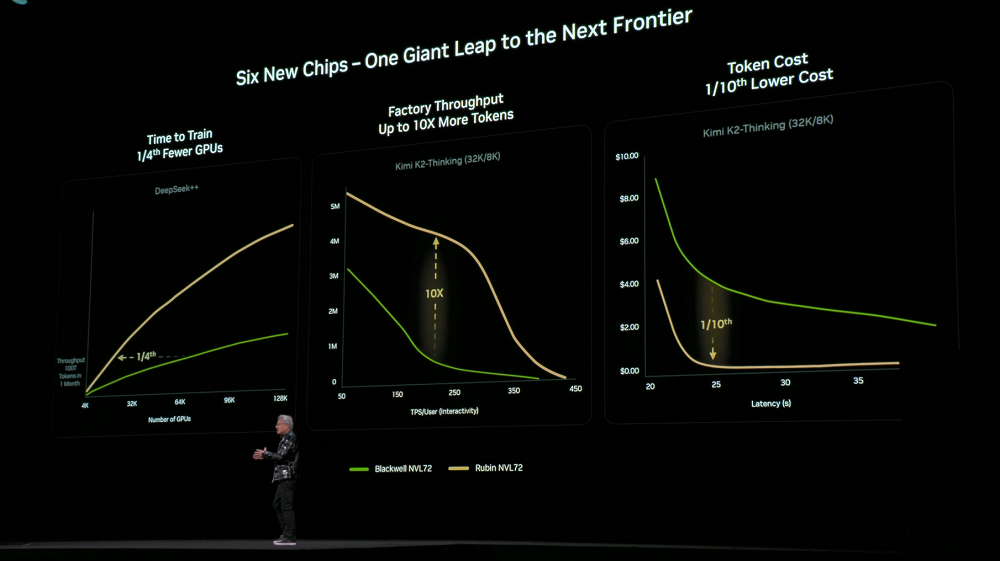
DGX Rubin NVL8 システムを採用した NVIDIA DGX SuperPOD も同時にリリースされました。
NVIDIA は、Vera Rubin アーキテクチャを活用し、パートナーや顧客と協力して世界最大かつ最先端で低コストの AI システムを構築し、AI の主流導入を加速しています。

Rubin インフラストラクチャは今年後半に CSP およびシステム インテグレーターを通じて提供され、Microsoft などが最初に導入する予定です。
03. オープンモデルユニバースの拡大:新しいモデル、データ、オープンソースエコシステムへの重要な貢献者
ソフトウェアとモデルのレベルで、NVIDIA はオープンソースへの投資を増やし続けています。
OpenRouter などの主流の開発プラットフォームのデータによると、AI モデルの使用量は過去 1 年間で 20 倍に増加しており、トークンの約 4 分の 1 はオープンソース モデルからのものとなっています。
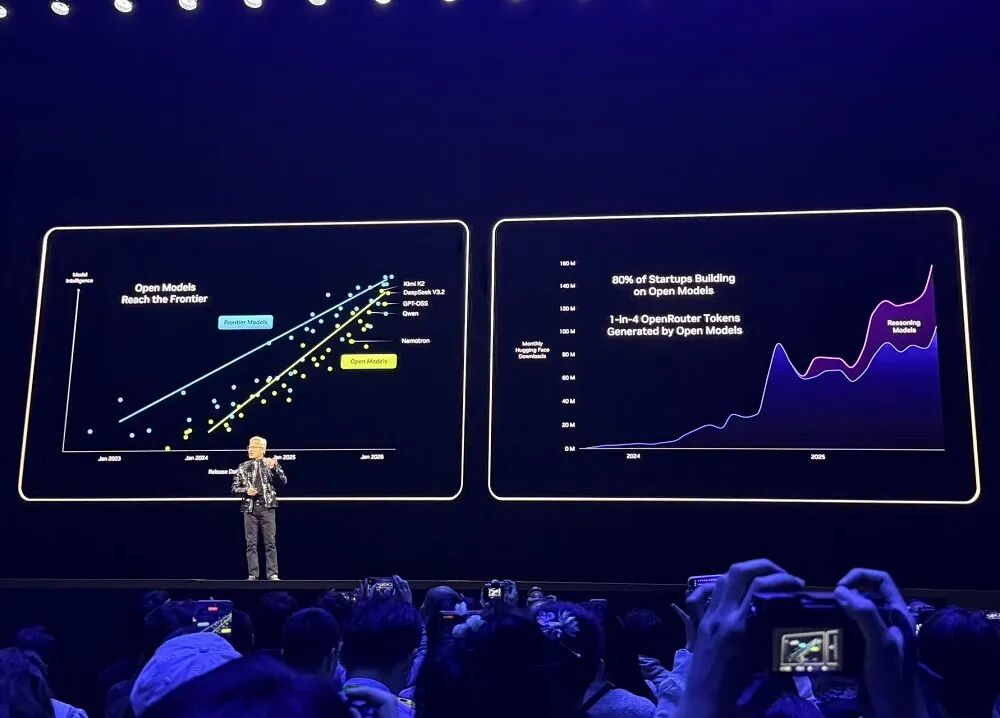
2025 年、NVIDIA は Hugging Face のオープンソース モデル、データ、レシピへの最大の貢献者となり、650 のオープンソース モデルと 250 のオープンソース データセットをリリースしました。

NVIDIAのオープンソースモデルは、様々なリーダーボードで常に高い評価を得ています。開発者はこれらのオープンソースモデルを活用できるだけでなく、そこから学び、継続的にトレーニングを行い、データセットを拡張し、オープンソースツールやドキュメント技術を活用してAIシステムを構築することができます。

Perplexity に触発された Jensen Huang 氏は、エージェントはマルチモデル、マルチクラウド、ハイブリッド クラウドであるべきだと指摘しました。これはエージェント AI システムの基本アーキテクチャでもあり、ほぼすべてのスタートアップがこれを採用しています。
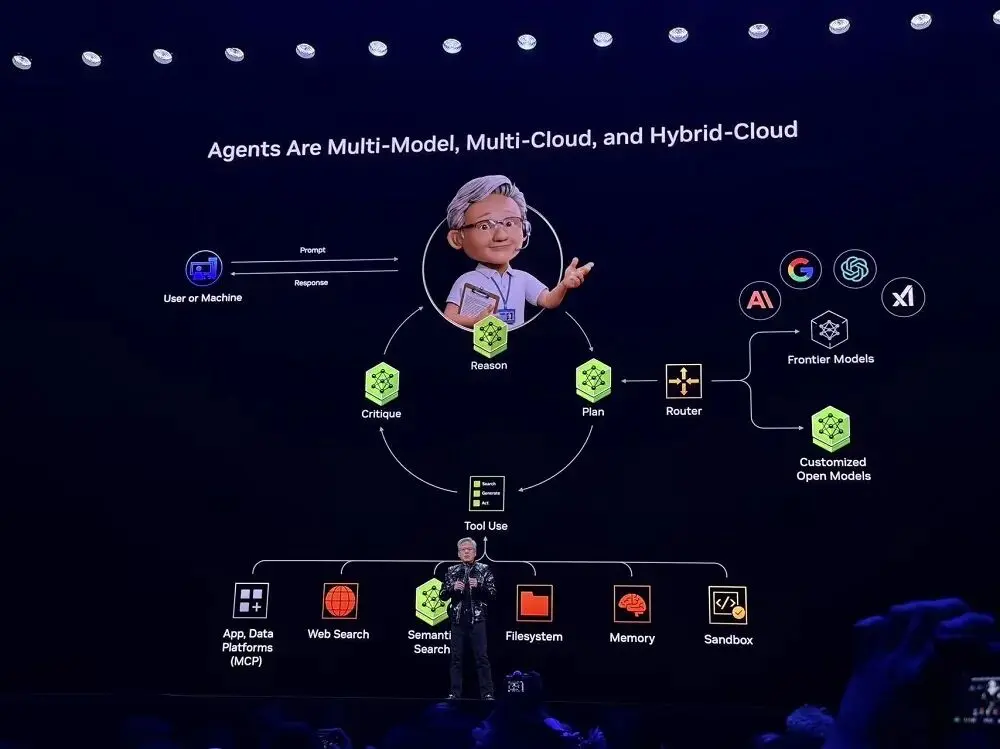
NVIDIAが提供するオープンソースのモデルとツールを活用することで、開発者はAIシステムをカスタマイズし、最先端のモデル機能を利用できるようになります。NVIDIAはこのフレームワークを「Blueprints」に統合し、SaaSプラットフォームに統合しました。ユーザーはBlueprintsを利用することで、迅速な導入が可能になります。
現地デモでは、このシステムはユーザーの意図に基づき、タスクをローカルのプライベートモデルで処理するか、クラウドベースのフロンティアモデルで処理するかを自動的に判断します。また、外部ツール(メールAPI、ロボット制御インターフェース、カレンダーサービスなど)を呼び出し、マルチモーダルフュージョンを実現することで、テキスト、音声、画像、ロボットセンサー信号などの情報を統一的に処理します。
これらの複雑な機能はかつては想像もできなかったものですが、今では当たり前のものとなっています。ServiceNowやSnowflakeなどのエンタープライズプラットフォームにも同様の機能が存在します。
04. オープンソースの Alpha-Mayo モデルにより、自動運転車が「考える」ことが可能になる。
Nvidiaは、物理AIとロボティクスが最終的に世界最大のコンシューマーエレクトロニクス分野になると考えています。動くものはすべて、最終的には物理AIによって駆動される完全自律型になるでしょう。
AIは知覚AI、生成AI、エージェントAIという段階を経て、今や物理AIの時代に入りつつあります。知能が現実世界に進出し、これらのモデルは物理法則を理解し、物理世界の知覚から直接行動を生み出すことができます。
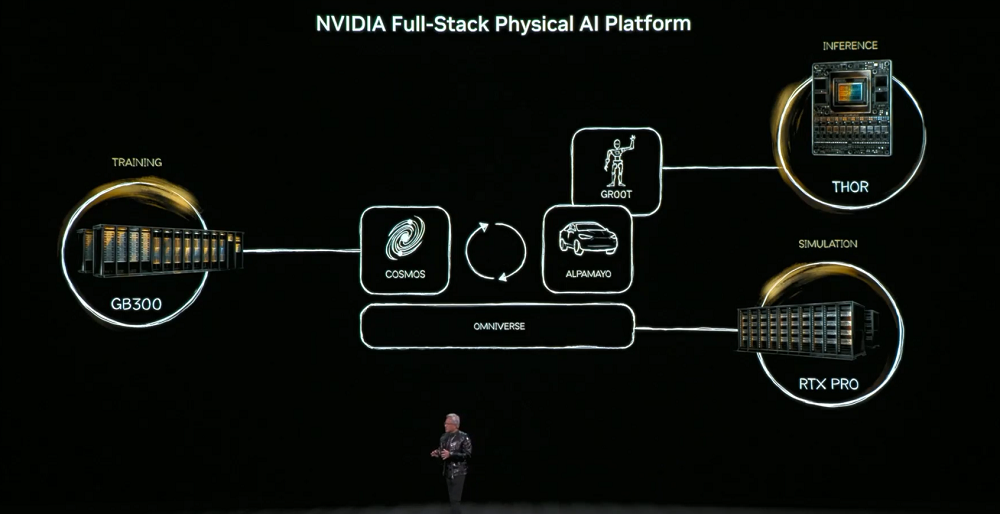
この目標を達成するために、物理AIは物体の永続性、重力、摩擦といった世界の常識を学習する必要があります。これらの能力を獲得するには、AIモデルを構築するためのトレーニング用コンピュータ(DGX)、リアルタイム実行のための推論用コンピュータ(ロボット/車両チップ)、そして合成データを生成し物理ロジックを検証するためのシミュレーション用コンピュータ(Omniverse)という3つのコンピュータが必要です。
コアモデルは、言語、画像、3D、物理法則を調整して、シミュレーションからトレーニング データ生成までのチェーン全体をサポートする Cosmos World Foundation Model です。
物理的な AI は、建物 (工場や倉庫など)、ロボット、自動運転車という 3 種類のエンティティに登場します。
ジェンセン・フアンは、自動運転がフィジカルAIの最初の大規模応用シナリオになると考えています。このようなシステムは現実世界を理解し、意思決定を行い、行動を実行する必要があり、安全性、シミュレーション、そしてデータに対する極めて高い要求が求められます。
これに応えて、NVIDIA は、安全な推論ベースの物理 AI の開発を加速するために、オープンソース モデル、シミュレーション ツール、物理 AI データセットで構成された完全なシステムである Alpha-Mayo をリリースしました。
同社の製品ポートフォリオは、世界中の自動車メーカー、サプライヤー、新興企業、研究者に、レベル 4 の自動運転システムを構築するための基本モジュールを提供します。

Alpha-Mayoは、自動運転車が「考える」ことを可能にする業界初の真のオープンソースモデルです。問題を段階的に分解し、あらゆる可能性を検討し、最も安全な経路を選択します。

この推論ベースのタスクアクションモデルにより、自動運転システムは、混雑した交差点での信号機の故障など、これまで遭遇したことのない複雑なエッジケースを処理できるようになります。
Alpha-Mayo には 100 億のパラメータがあり、自動運転タスクを処理するのに十分な大きさですが、自動運転研究者向けに設計されたワークステーションで実行できるほど軽量です。
テキスト、サラウンドビューカメラデータ、車両履歴ステータス、ナビゲーション入力を受信し、運転軌跡と推論プロセスを出力できるため、乗客は車両が特定のアクションをとった理由を理解できます。
イベントで上映されたプロモーションビデオでは、アルファ・メイヨーによって運転される自動運転車が、歩行者を避けたり、左折車を予測したり、左折車を避けるために車線を変更したりするなどのタスクを、介入なしに自律的に完了できることが示されました。

ジェンセン・フアンは、アルファ・メイヨーを搭載したメルセデス・ベンツCLAが既に生産開始されており、NCAP(ニューカッスル・アポン・エイト)によって世界で最も安全な車として認定されたと述べた。コード、チップ、そしてシステムの全てが安全認証を取得している。このシステムは米国市場で販売開始され、高速道路でのハンズフリー運転や市街地でのエンドツーエンドの自動運転など、強化された運転機能を備え、今年後半に発売される予定だ。

NVIDIAは、Alpha-Mayoの学習に使用されたデータセットのサブセットと、オープンソースの推論モデル評価シミュレーションフレームワークであるAlpha-Simも公開しました。開発者は、独自のデータを使用してAlpha-Mayoを微調整したり、Cosmosを使用して合成データを生成したり、実データと合成データの組み合わせに基づいて自動運転アプリケーションの学習とテストを行うことができます。さらに、NVIDIAはNVIDIA DRIVEプラットフォームが現在製品化されていることを発表しました。
NVIDIA は、Boston Dynamics、Franka Robotics、Surgical、LG Electronics、NEURA、XRLabs、Logic Robotics など、世界有数のロボット企業が、NVIDIA Isaac と GR00T 上にシステムを構築していると発表しました。

ジェンセン・フアンは、シーメンスとの新たな協業も正式に発表しました。シーメンスは、NVIDIA CUDA-X、AIモデル、そしてOmniverseを、EDA、CAE、デジタルツインツールおよびプラットフォームのポートフォリオに統合します。これにより、設計・シミュレーションから製造・運用に至るまで、プロセス全体にわたってフィジカルAIが幅広く活用されるようになります。
05. 結論: 一方の手でオープンソースを採用し、もう一方の手でハードウェア システムを不可欠なものにする。
AIインフラの焦点が学習から大規模推論へと移行するにつれ、プラットフォーム競争は単一点のコンピューティング能力をめぐる争いから、チップ、ラック、ネットワーク、ソフトウェアを網羅するシステムエンジニアリングのアプローチへと進化しました。目標は、最小のTCOで最大の推論スループットを実現することであり、AIは「工場型運用」という新たな段階に入りつつあります。
NVIDIAはシステムレベルの設計を重視しています。Rubinは、トレーニングと推論におけるパフォーマンスとコスト効率の両方の向上を実現し、Blackwellのプラグアンドプレイの代替として機能し、Blackwellからのシームレスな移行を可能にします。
プラットフォームの位置付けに関して、NVIDIAは依然としてトレーニングが極めて重要であると考えています。なぜなら、最先端モデルを迅速にトレーニングすることでのみ、推論プラットフォームが真のメリットを享受できるからです。そのため、NVIDIAはRubin GPUにNVFP4トレーニングを導入し、パフォーマンスをさらに向上させ、TCOを削減しました。
同時に、この AI コンピューティングの巨人は、垂直および水平スケーリング アーキテクチャの両方でネットワーク通信機能を大幅に強化し続けており、ストレージ、ネットワーク、コンピューティングの共同設計を実現するための重要なボトルネックとしてコンテキストを重視しています。
Nvidiaはオープンソース戦略を積極的に展開する一方で、ハードウェア、インターコネクト、システム設計をますます「かけがえのない」ものにしつつあります。需要を継続的に拡大し、トークン消費を奨励し、推論のスケーリングを促進し、費用対効果の高いインフラストラクチャを提供するというこのクローズドループ戦略は、Nvidiaにとってさらに堅固な堀を築きつつあります。



