
著者: Biteye コアコントリビューター @anci_hu49074
「私たちは今、最高の基本モデルを構築するための世界的な競争の時代にあります。計算能力とモデルアーキテクチャは重要ですが、真の防壁はトレーニングデータです。」
—ストーリーの最高AI責任者、サンディープ・チンチャリ
スケールAIの観点からAIデータトラックの可能性についてお話ししましょう
今月のAI界隈で最も話題になったのは、Metaがその資金力を見せつけたことだ。ザッカーバーグは各地から人材を集め、主に中国の科学研究人材で構成された豪華なMeta AIチームを結成した。チームリーダーは、Scale AIの創業者で若干28歳のアレクサンダー・ワンだ。Scale AIの創業者であり、現在その評価額は290億ドルに達している。サービス対象には、米軍のほか、OpenAI、Anthropic、Metaなどの競合AI大手企業が含まれており、いずれもScale AIが提供するデータサービスに依存している。Scale AIの中核事業は、大量の正確なラベル付きデータを提供することである。
Scale AI がユニコーン企業群の中で一際目立っているのはなぜでしょうか?
その理由は、AI業界におけるデータの重要性を早くから認識していたからだ。
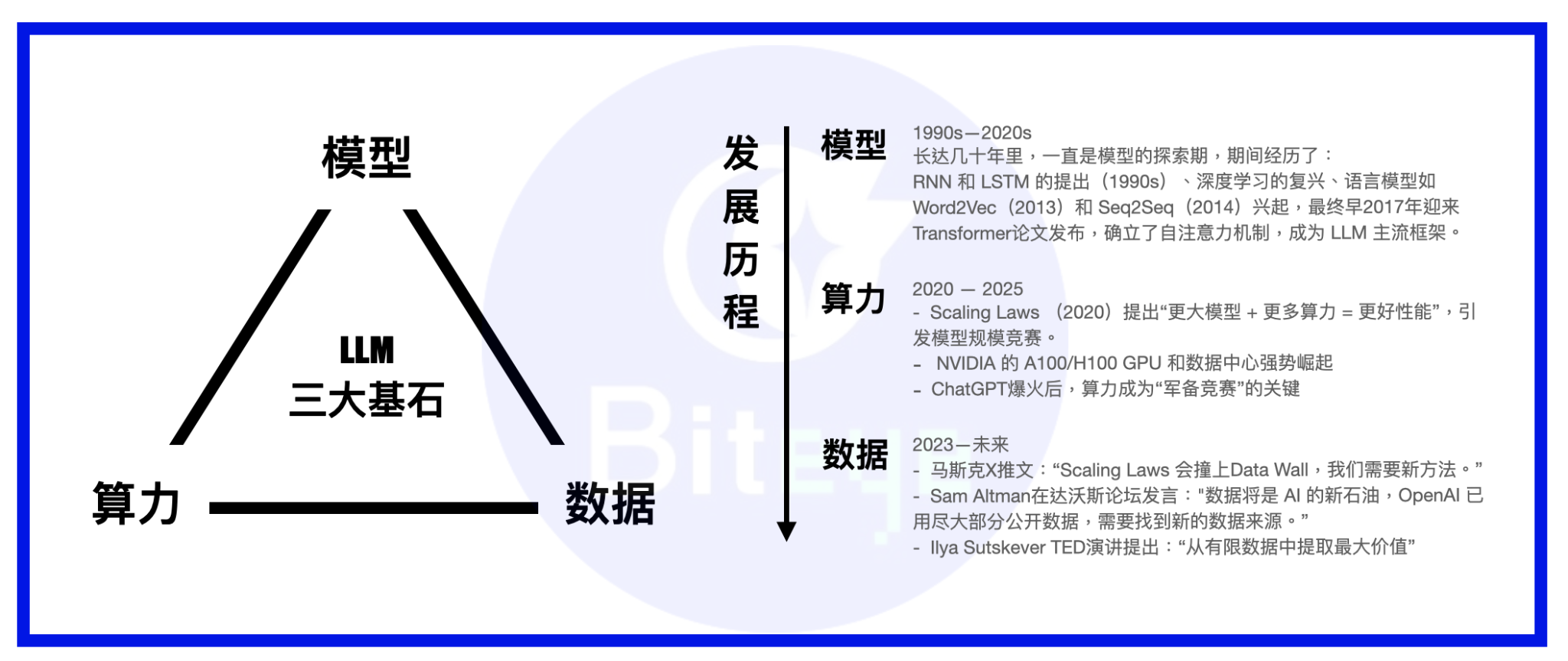
AIモデルの3つの柱は、計算能力、モデル、そしてデータです。大きなモデルを人に例えると、モデルは人体、計算能力は食料、そしてデータは知識・情報です。
LLMの台頭以来、業界の発展の焦点はモデルからコンピューティングパワーへと移行しました。現在、ほとんどのモデルはトランスフォーマーをモデルフレームワークとして確立しており、MoEやMoReといった革新的な技術が時折登場しています。大手企業は、独自のスーパークラスターを構築してコンピューティングパワーの万里の長城を完成させるか、AWSなどの強力なクラウドサービスと長期契約を締結しています。基本的なコンピューティングパワーが満たされると、データの重要性が徐々に高まっています。
Palantirのような二次市場で高い評価を得ている従来のToBビッグデータ企業とは異なり、Scale AIはその名の通り、AIモデルのための強固なデータ基盤の構築に注力しています。既存データのマイニングにとどまらず、長期的なデータ生成事業にも注力しています。また、様々な分野の人工知能(AI)専門家からなるAIトレーナーチームを結成し、AIモデルのトレーニングに高品質なトレーニングデータを提供することを目指しています。
このビジネスに同意できない場合は、モデルがどのようにトレーニングされるかを見てみましょう。
モデルのトレーニングは、事前トレーニングと微調整の 2 つの部分に分かれています。
事前学習の部分は、人間の赤ちゃんが徐々に話し方を学ぶ過程に似ています。通常必要なのは、オンラインクローラーから取得した大量のテキスト、コード、その他の情報をAIモデルに入力することです。モデルはこれらのコンテンツを自ら学習し、人間の言語(学術的には自然言語と呼ばれます)を話すことを学習し、基本的なコミュニケーションスキルを身につけます。
微調整の部分は学校に通うのと似ています。学校では通常、正解と不正解、答えと指示が明確に示されています。学校では、生徒のポジショニングに基づいて、異なる才能を育むための訓練を行います。また、事前に処理され、ターゲットを絞ったデータセットを使用して、モデルが期待する能力を発揮できるように訓練します。

この時点で、必要なデータも 2 つの部分に分かれていることがおわかりになったかと思います。
- 一部のデータは、あまり処理する必要がなく、十分な量で十分です。通常、Reddit、Twitter、Github、公開文献データベース、企業のプライベートデータベースなどの大規模な UGC プラットフォームのクローラーデータから取得されます。
- もう一方の部分は、専門書と同様に、モデル特有の優れた特性を確実に発揮できるよう、慎重な設計とスクリーニングが必要です。そのためには、データのクリーニング、スクリーニング、ラベル付け、手動フィードバックといった必要な作業を実行する必要があります。
これら2つのデータセットは、AIデータトラックの主要部分を構成しています。一見ローテクに見えるこれらのデータセットを過小評価しないでください。現在の主流の見解は、スケーリング則におけるコンピューティングパワーの優位性が徐々に無効になるにつれて、データは様々な大型モデルメーカーが競争優位性を維持するための最も重要な柱となるだろうというものです。
モデル能力の向上に伴い、より高度で専門的な学習データがモデル能力に影響を与える重要な変数となるでしょう。さらに、モデルの学習を武術の達人の育成に例えると、高品質なデータセットこそが武術の秘訣と言えるでしょう(この比喩を完成させるために、計算能力は万能薬であり、モデルは資質そのものであるとも言えます)。
垂直的な視点から見ると、AIデータもまた、雪だるま式に成長する可能性のある長期的な軌道です。過去の成果の蓄積により、データ資産も複利効果を発揮し、時間の経過とともに人気が高まるでしょう。
Web3 DataFi: AIデータのための肥沃な土壌
フィリピン、ベネズエラなどの数十万人からなるScale AIの遠隔手動ラベリングチームと比較すると、Web3はAIデータ分野で自然な優位性を持っており、「DataFi」という新しい用語が生まれました。
理想的には、Web3 DataFi の利点は次のとおりです。
1. スマートコントラクトによって保証されるデータ主権、セキュリティ、プライバシー
既存の公開データが開発され、枯渇しつつある段階において、未公開データ、さらには個人データをいかに掘り起こすかは、データソースの取得と拡大に向けた重要な方向性です。これは、重要な信頼の選択問題に直面しています。中央集権的な大企業の契約買収システムを選択し、データを売却するのか、それともブロックチェーン方式を選択し、データの知的財産権を保有し続け、スマートコントラクトを通じて、誰が、いつ、どのような目的でデータを使用するのかを明確に把握するのか、という問題です。
同時に、機密情報については、zk、TEE などの方法を使用して、プライベートなデータが口を閉ざしたマシンによってのみ処理され、漏洩されないことを保証できます。
2. 自然な地理的裁定優位性:最も適した労働力を引き付けるための自由な分散型アーキテクチャ
もしかしたら、伝統的な労働生産関係に挑戦する時が来ているのかもしれません。Scale AIのように世界中から安価な労働力を探すのではなく、ブロックチェーンの分散特性を活用し、スマートコントラクトによって保証されたオープンで透明なインセンティブを通じて、世界中に散在する労働力がデータ貢献に参加できるようにする方が賢明です。
データのラベル付けやモデル評価などの労働集約的なタスクの場合、データファクトリーを確立する集中型のアプローチよりも、Web3 DataFi を使用する方が参加者の多様性につながり、データの偏りを回避する上で長期的な意義も得られます。
3. ブロックチェーンの明確なインセンティブと決済上の利点
「江南皮革工場」の悲劇をどう回避するか?当然、スマートコントラクトの明確な価格設定のインセンティブシステムを活用して、人間の本性の闇を補う必要がある。
避けられない脱グローバル化の文脈において、低コストで地理的裁定取引を継続するにはどうすればよいでしょうか?世界中に企業を設立するのは明らかに困難です。だからこそ、旧世界の障壁を回避し、オンチェーン決済方式を採用してみてはいかがでしょうか?
4. より効率的でオープンな「ワンストップ」データ市場の構築に貢献する
「価格差で利益を上げる仲介業者」は、供給側と需要側の両方にとって永遠の悩みです。中央集権的なデータ企業に仲介を任せるのではなく、タオバオのようなオープンマーケットを通じてチェーン上にプラットフォームを構築し、データの供給側と需要側をより透明かつ効率的に繋げる方が賢明です。
オンチェーンAIエコシステムの発展に伴い、オンチェーンデータへの需要はより活発化し、細分化・多様化していくでしょう。こうした需要を効率的に消化し、エコシステムの繁栄へと転換できるのは、分散型市場だけです。
個人投資家にとって、DataFi は、一般の個人投資家の参加に最も貢献する、最も分散化された AI プロジェクトでもあります。
AIツールの登場により、学習のハードルはある程度下がり、分散型AIの本来の目的は、巨大企業によるAIビジネスの現在の独占を打ち破ることですが、現在の多くのプロジェクトは、技術的な背景を持たない個人投資家にとってアクセスしにくいことも認めざるを得ません。分散型コンピューティングネットワークのマイニングに参加するには、高額な初期ハードウェア投資が必要になることが多く、モデル市場の技術的なハードルによって、一般の参加者が簡単にやる気をなくしてしまう可能性があります。
対照的に、これは一般ユーザーがAI革命において掴み取れる数少ない機会の一つです。Web3では、データの提供、人間の脳の直感と本能に基づいたモデルのラベル付けと評価、さらにはAIツールを用いた簡単な作成、データ取引への参加など、様々な簡単なタスクを完了することで、AI革命に参加できます。毛沢東党の古参ドライバーにとって、難易度はほぼゼロです。
Web3 DataFiの潜在的なプロジェクト
お金の流れが方向を決める。Web2の世界では、Scale AIがMetaから143億ドルの投資を受け、Palantirの株価が1年で5倍以上に急騰したことに加え、DataFiもWeb3の資金調達で非常に好調な成果を上げています。ここでは、これらのプロジェクトについて簡単にご紹介します。
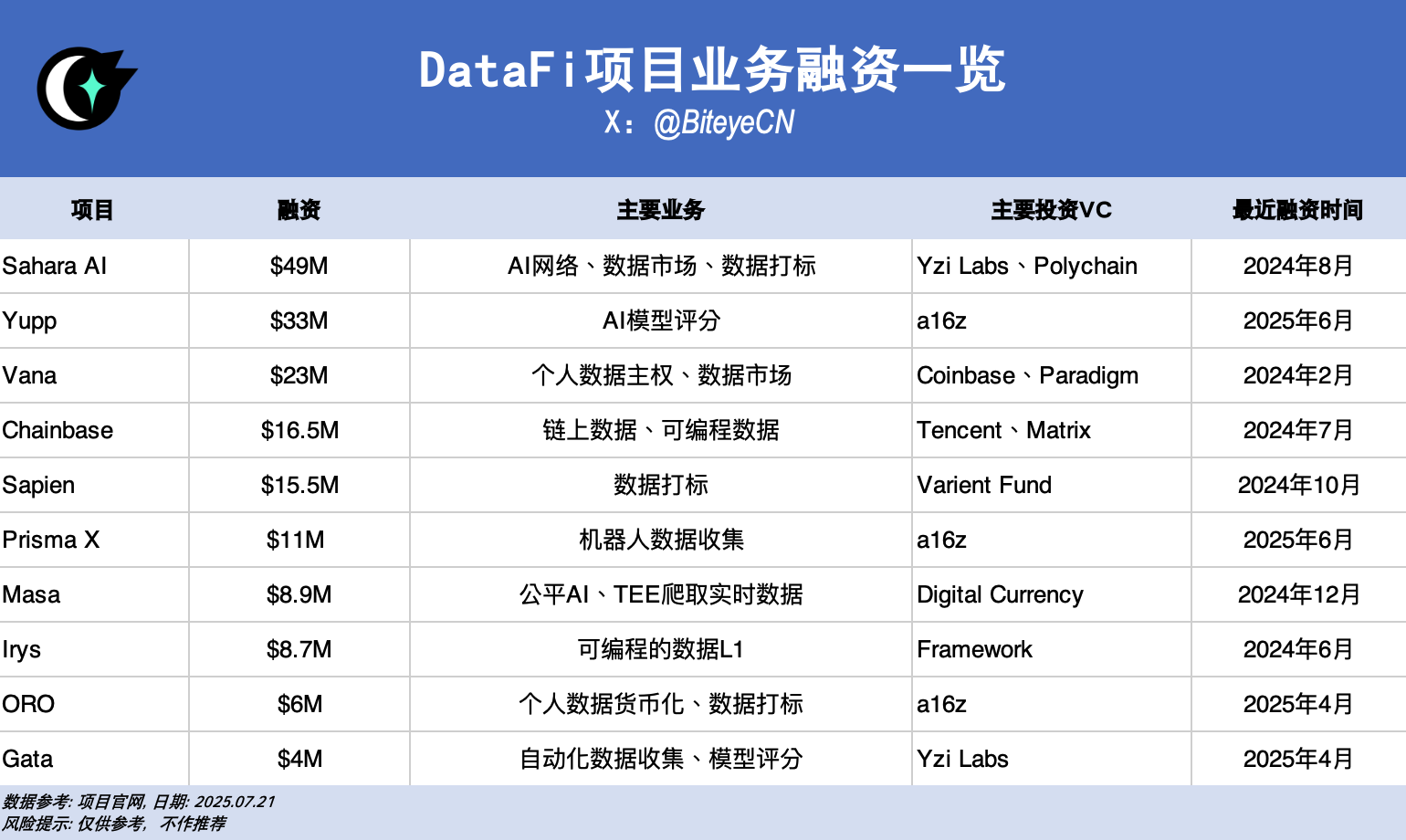
Sahara AI、@SaharaLabsAI が 4,900 万ドルを調達
Sahara AIの最終目標は、分散型AIスーパーインフラと取引市場の構築です。最初のテスト対象分野はAIデータです。DSP(データサービスプラットフォーム)のパブリックベータ版は7月22日にリリースされます。ユーザーは、データの提供、データラベリングなどのタスクへの参加を通じてトークン報酬を獲得できます。
リンク: app.saharaai.com
そうだ、@yupp_ai が 3,300 万ドルを集めた
Yuppは、モデル出力に関するユーザーフィードバックを収集するAIモデルフィードバックプラットフォームです。現在の主なタスクは、ユーザーが同じプロンプトに対して異なるモデルの出力を比較し、より優れていると思われるモデルを選択することです。タスクを完了するとYuppポイントを獲得でき、USDCなどの法定ステーブルコインと交換できます。
リンク: https://yupp.ai/
Vana @vana は 2,300 万ドルを調達しました
Vanaは、ユーザーの個人データ(ソーシャルメディアの活動、閲覧履歴など)を収益化可能なデジタル資産に変換することに重点を置いています。ユーザーは、DataDAO内の対応するデータ流動性プール(DLP)に個人データをアップロードすることを承認できます。これらのデータはプールされ、AIモデルのトレーニングなどのタスクに使用され、ユーザーは対応するトークン報酬を受け取ります。
リンク: https://www.vana.org/collectives
Chainbase (@ChainbaseHQ) が 1,650 万ドルを調達
Chainbaseの事業はオンチェーンデータに特化しており、現在200以上のブロックチェーンをカバーしています。オンチェーンアクティビティを構造化、検証可能、かつ収益化可能なデータ資産に変換し、dApp開発に役立てています。Chainbaseの事業は主にマルチチェーンインデックスなどの手法で取得され、データはManuscriptシステムとTheia AIモデルを通じて処理されています。現在、一般ユーザーはあまり関与していません。
Sapien(@JoinSapien)は1550万ドルを調達した
Sapienは、人間の知識を大規模に高品質なAI学習データに変換することを目指しています。プラットフォーム上で誰でもデータアノテーションを行うことができ、ピア検証を通じてデータの品質を確保できます。同時に、ユーザーは長期的な評判を築いたり、ステーキングを通じてコミットメントすることでより多くの報酬を獲得することが奨励されます。
リンク: https://earn.sapien.io/#hiw
Prisma X (@PrismaXai )が1100万ドルを調達
Prisma Xは、物理的なデータ収集が鍵となるロボットのためのオープンなコーディネーションレイヤーを目指しています。このプロジェクトは現在初期段階にあります。最近公開されたホワイトペーパーによると、参加にはデータ収集のためのロボットへの投資、ロボットデータの遠隔操作などが含まれる可能性があります。現在、ホワイトペーパーに基づいたクイズが公開されており、参加してポイントを獲得できます。
リンク: https://app.prismax.ai/whitepaper
マサ @getmasafi が 890 万ドルを調達
MasaはBittensorエコシステムにおける主要なサブネットプロジェクトの一つであり、現在データサブネット42番とエージェントサブネット59番を運営しています。データサブネットは、データへのリアルタイムアクセスを提供することに注力しています。現在、マイナーは主にTEEハードウェアを介してX/Twitter上のリアルタイムデータをクロールしています。一般ユーザーにとって、参加の難易度とコストは比較的高くなっています。
Irys (@irys_xyz) は 870 万ドルを調達しました
Irysはプログラマブルなデータストレージとコンピューティングに注力し、AI、分散型アプリケーション(dApps)、その他のデータ集約型アプリケーション向けに、効率的で低コストなソリューションを提供することを目指しています。データ貢献という点では、一般ユーザーは現時点ではあまり参加できませんが、現在のテストネット段階では参加できるアクティビティが複数あります。
リンク: https://bitomokx.irys.xyz/
ORO、@getoro_xyz、600万ドルを調達
OROの目標は、一般の人々がAIへの貢献に参加できるようにすることです。サポート方法は次のとおりです。1. 個人アカウントをリンクして、ソーシャルアカウント、健康データ、eコマース、金融アカウントなどの個人データを提供する。2. データタスクを完了する。テストネットワークは現在オンラインになっており、ご参加いただけます。
リンク: app.getoro.xyz
Gata(@Gata_xyz)は400万ドルを調達した
分散型データレイヤーとして位置付けられるGataは、現在、次の3つの主要製品に取り組んでいます。1. データエージェント: ユーザーがウェブページを開いている限り、自動的に実行されデータを処理できる一連のAIエージェント。2. AII-in-one Chat: Yuppのモデル評価に似たメカニズムで報酬を獲得。3. GPT-to-Earn: ChatGPTでユーザーの会話データを収集するブラウザプラグイン。
リンク: https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
現在のプロジェクトをどのように評価しますか?
現時点では、これらのプロジェクトの参入障壁は概して高くありませんが、ユーザー数とエコシステムの粘着性が蓄積されれば、プラットフォームの優位性は急速に蓄積されることを認識する必要があります。したがって、初期段階では、インセンティブとユーザーエクスペリエンスに重点を置く必要があります。十分なユーザー数を獲得して初めて、ビッグデータビジネスは成功します。
しかし、これらのデータプラットフォームは労働集約型プロジェクトであるため、労働力を確保しつつ、労働力をどのように管理し、データ出力の品質を確保するかという点も考慮する必要があります。多くのWeb3プロジェクトに共通する問題は、プラットフォーム上のユーザーのほとんどが冷酷な暴利主義者であるということです。彼らは短期的な利益のために品質を犠牲にすることがよくあります。彼らをプラットフォームの主要ユーザーにしてしまうと、悪貨が良貨を駆逐し、最終的にはデータの品質を保証できなくなり、買い手も惹きつけることができなくなります。現在、SaharaやSapienなどのプロジェクトはデータ品質を重視し、プラットフォーム上の労働者との長期的で健全な協力関係の構築に努めています。
さらに、透明性の欠如は、現在のオンチェーンプロジェクトが抱えるもう一つの問題です。実際、ブロックチェーンの不可能三角形は、多くのプロジェクトをスタートアップ段階で「集中化が分散化を駆動する」という道を歩ませてきました。しかし、現在ではますます多くのオンチェーンプロジェクトが「Web3の皮を被った古いWeb2プロジェクト」といった印象を与えています。チェーン上で追跡可能な公開データはごくわずかで、ロードマップを見ても長期的なオープン性と透明性の方向性が見えにくいのです。これはWeb3 DataFiの長期的な健全な発展にとって間違いなく有害であり、私たちはより多くのプロジェクトが初心を忘れず、オープン性と透明性の実現を加速していくことを願っています。
最後に、DataFiの普及経路も2つの部分に分けられるべきでしょう。1つは、十分な数のtoC参加者をネットワークに引き込み、データ収集・生成エンジニアリングとAIエコノミーの消費者の新たな勢力を形成し、エコロジカルなクローズドループを形成することです。もう1つは、現在の主流からB企業への認知度を高めることです。結局のところ、短期的には、彼らは豊富な資金力を持つ大規模なデータ注文の主な供給源です。この点では、Sahara AIやVanaなどが順調な進歩を遂げていることも確認されています。
結論
もっと運命論的に言えば、DataFi は、人間の知能を使って長期的に機械知能を育成すると同時に、スマート コントラクトを契約として使用して、人間の知能労働が収益性が高く、最終的には機械知能からのフィードバックを享受できるようにすることを目的としています。
AI時代の不確実性に不安を感じており、暗号通貨の世界の浮き沈みの中でもブロックチェーンの理想を抱いているのであれば、大手資本グループの足跡をたどり、DataFiに参加することはトレンドに乗るための良い選択です。
