
출처: 월스트리트 뉴스
2026년 3월 16일, NVIDIA GTC 2026이 공식적으로 개막했으며, NVIDIA 창립자 겸 CEO인 젠슨 황이 기조연설을 했습니다.
인공지능 업계의 연례 행사로 여겨지는 이 컨퍼런스에서 젠슨 황 엔비디아 CEO는 엔비디아가 '칩 회사'에서 '인공지능 인프라 및 제조 회사'로 변모해 온 과정을 설명했습니다. 그는 시장의 가장 시급한 관심사인 성능 지속 가능성과 성장 잠재력에 대해 언급하며, 미래 성장을 이끄는 핵심 비즈니스 논리인 '토큰 팩토리 경제학'을 자세히 설명했습니다.

실적 전망치는 매우 낙관적이며, 2027년까지 수요가 최소 1조 달러에 달할 것으로 예상하고 있습니다.
지난 2년간 전 세계 AI 컴퓨팅 수요는 기하급수적으로 증가했습니다. 대규모 모델이 '인지'와 '생성'에서 '추론'과 '행동(작업 실행)'으로 발전함에 따라 컴퓨팅 파워 소비량도 급증했습니다. 시장이 특히 우려하는 수주 및 매출 상한선에 대해 황런쉰 대표는 매우 높은 기대감을 표명했습니다.
황런쉰은 연설에서 솔직하게 다음과 같이 말했습니다.
작년 이맘때쯤 저는 블랙웰과 루빈에 대한 2026년까지의 높은 신뢰도 수요가 5천억 달러에 달할 것으로 예상한다고 말씀드렸습니다. 지금 이 순간, 저는 2027년까지 최소 1조 달러의 수요가 발생할 것으로 보고 있습니다.

젠슨 황의 1조 달러 전망은 한때 엔비디아 주가를 4.3% 이상 끌어올렸습니다.
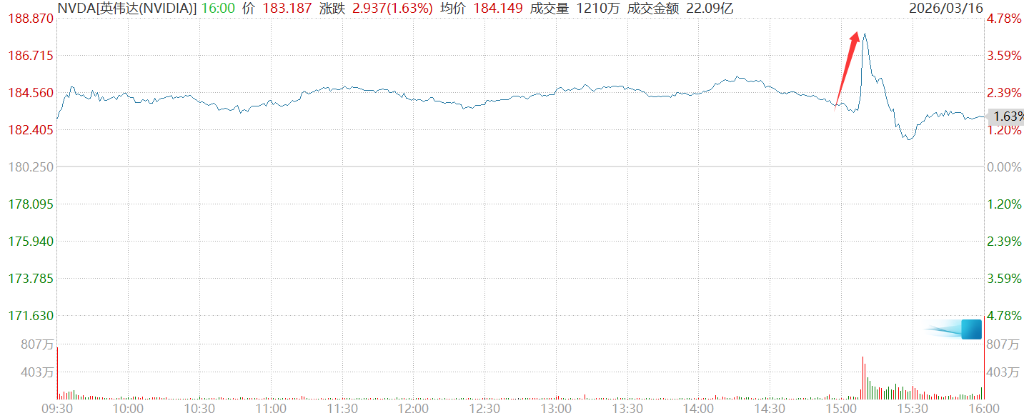
게다가 그는 이 수치에 다음과 같은 내용을 덧붙였습니다.
이게 합리적인가요? 바로 이 점에 대해 다음 시간에 이야기해 보겠습니다. 사실, 우리는 공급 부족에 직면할 수도 있습니다. 실제 컴퓨팅 수요는 이보다 훨씬 더 높을 것이라고 확신합니다.
젠슨 황은 엔비디아 시스템이 이제 세계에서 가장 "저비용 인프라"임을 입증했다고 지적했습니다. 엔비디아는 거의 모든 분야에서 AI 모델을 실행할 수 있기 때문에 이러한 다재다능함 덕분에 고객이 투자한 1조 달러를 최대한 활용하고 수명을 연장할 수 있습니다.
현재 엔비디아 사업의 60%는 상위 5개 하이퍼스케일 클라우드 서비스 제공업체에서 발생하며, 나머지 40%는 스바루티브 클라우드, 기업, 산업, 로봇 공학 및 엣지 컴퓨팅과 같은 다양한 분야에 걸쳐 분포되어 있습니다.
토큰 팩토리 경제학: 와트당 성능이 사업의 생존 여부를 결정짓는다
젠슨 황은 이러한 수조 달러 규모의 수요를 뒷받침하는 근거를 설명하기 위해 글로벌 기업 CEO들에게 완전히 새로운 비즈니스 사고방식을 제시했습니다. 그는 미래의 데이터 센터는 더 이상 파일을 저장하는 창고가 아니라 AI가 생성하는 기본 단위인 토큰을 생산하는 "공장"이 될 것이라고 지적했습니다.

황런쉰은 다음과 같이 강조했습니다.
모든 데이터 센터와 공장은 본질적으로 전력 용량에 제한이 있습니다. 1기가와트(GW) 규모의 공장은 절대 2GW 규모의 공장이 될 수 없습니다. 이는 물리 법칙이자 원자의 법칙입니다. 동일한 전력 용량에서 와트당 처리량이 가장 높은 곳이 생산 비용을 가장 낮출 수 있습니다.
젠슨 황은 미래의 AI 서비스를 다음과 같은 비즈니스 계층으로 분류합니다.
무료 요금제 (높은 처리량, 낮은 속도)
중급 등급 (토큰 백만 개당 약 3달러)
고급 등급 (토큰 백만 개당 약 6달러)
고속 레이어(토큰 백만 개당 약 45달러)
초고속 레이어(토큰 백만 개당 약 150달러)
그는 모델의 규모가 커지고 맥락이 길어질수록 AI는 더욱 똑똑해지겠지만 토큰 생성 속도는 감소할 것이라고 지적했습니다. 젠슨 황은 다음과 같이 말했습니다.
이 토큰 팩토리에서는 처리량과 토큰 생성 속도가 내년 정확한 수익으로 직결됩니다.
젠슨 황은 NVIDIA의 아키텍처를 통해 고객이 무료 티어에서 매우 높은 처리량을 달성하는 동시에 최고 가치의 추론 티어에서는 성능을 무려 35배까지 향상시킬 수 있다고 강조했습니다.

베라 루빈은 2년 만에 350배의 속도 향상을 달성했으며, Groq는 초고속 추론 분야의 공백을 메웁니다.
이러한 물리적 한계 속에서 NVIDIA는 지금까지 개발한 가장 복잡한 AI 컴퓨팅 시스템인 Vera Rubin을 공개했습니다. 젠슨 황은 다음과 같이 말했습니다.
예전에는 호퍼(Hopper)를 언급할 때 칩 하나를 들어 보이곤 했는데, 꽤 귀여운 모습이었죠. 하지만 베라 루빈(Vera Rubin)을 언급하면 사람들은 시스템 전체를 떠올립니다. 100% 수랭식 시스템으로 기존 케이블을 완전히 없앤 덕분에, 예전에는 이틀씩 걸리던 랙 설치가 이제는 단 두 시간 만에 가능해졌습니다.
젠슨 황은 베라 루빈이 극단적인 엔드투엔드 하드웨어 및 소프트웨어 공동 설계를 통해 동일한 1GW 데이터 센터에서 놀라운 데이터 도약을 이뤄냈다고 지적했습니다.
불과 2년 만에 토큰 생성량을 2,200만 개에서 7억 개로, 350배나 늘렸습니다. 같은 기간 동안 무어의 법칙에 따르면 증가율은 약 1.5배에 불과했습니다.
NVIDIA는 초고속 추론(예: 초당 1000개 토큰) 환경에서 발생하는 대역폭 병목 현상을 해결하기 위해 인수 기업인 Groq를 통합한 비대칭 분리 추론(asymmetric decoupled inference)을 최종 솔루션으로 제시했습니다. 젠슨 황은 다음과 같이 설명했습니다.
이 두 프로세서는 매우 다른 특징을 가지고 있습니다. Groq 칩은 500MB의 SRAM을 탑재하고 있는 반면, Rubin 칩은 288GB의 메모리를 탑재하고 있습니다.

젠슨 황은 NVIDIA가 다이나모 소프트웨어 시스템을 통해 막대한 연산과 메모리가 필요한 "사전 채우기" 단계를 Vera Rubin에, 지연 시간에 민감한 "디코딩" 단계를 Groq에 위임한다고 지적했습니다. 황은 또한 기업 컴퓨팅 성능 구성에 대한 제안도 제시했습니다.
주로 높은 처리량이 요구되는 작업이라면 Vera Rubin을 100% 활용하세요. 고가치 토큰을 프로그래밍 방식으로 생성해야 하는 경우가 많다면 데이터 센터 공간의 25%를 Groq에 할당하세요.
삼성에서 제조한 Groq LP30 칩이 이미 양산 중이며 3분기에 출하될 예정이고, 첫 번째 Vera Rubin 랙은 이미 마이크로소프트 Azure 클라우드에서 가동 중이라는 사실이 밝혀졌습니다.
또한 광 인터커넥트 기술과 관련하여 젠슨 황은 세계 최초로 양산된 코패키지 광(CPO) 스위치인 스펙트럼 X를 선보이며 "구리에서 광섬유로" 접근 방식에 대한 시장 논쟁을 잠재웠습니다.
우리는 더 많은 구리 케이블 생산 능력, 더 많은 광 칩 생산 능력, 그리고 더 많은 CPO 생산 능력이 필요합니다.
에이전트들이 전통적인 SaaS 방식을 버리고 "연봉 + 토큰" 방식이 실리콘 밸리의 표준이 되고 있습니다.
하드웨어 장벽 외에도, 황은 AI 소프트웨어 및 생태계의 혁명, 특히 에이전트의 폭발적인 성장에 많은 부분을 할애했습니다.
그는 오픈 소스 프로젝트인 오픈클로(OpenClaw)를 "인류 역사상 가장 인기 있는 오픈 소스 프로젝트"라고 묘사하며, 불과 몇 주 만에 지난 30년간 리눅스가 이룬 성과를 넘어섰다고 말했다. 황 회장은 오픈클로가 본질적으로 에이전트 컴퓨터를 위한 "운영 체제"라고 단언했다.
Huang Renxun은 다음과 같이 주장했습니다.
모든 SaaS(서비스형 소프트웨어) 기업은 AaaS(서비스형 에이전트) 기업으로 거듭날 것입니다. 민감한 데이터에 접근하고 코드를 실행할 수 있는 이러한 에이전트의 안전한 배포를 보장하기 위해 NVIDIA는 정책 엔진과 개인 정보 보호 라우터를 추가한 엔터프라이즈급 NeMo Claw 레퍼런스 디자인을 출시했습니다.
일반 직장인들에게도 이러한 변화는 곧 다가올 것입니다. 젠슨 황은 미래의 새로운 업무 공간에 대해 다음과 같이 설명합니다.
앞으로 우리 회사 모든 엔지니어는 연간 토큰 예산이 필요할 것입니다. 기본 연봉이 수십만 달러에 달할 수 있는데, 저는 그중 절반 정도를 토큰으로 지급하여 엔지니어들이 10배의 효율성 향상을 이룰 수 있도록 지원할 것입니다. 이는 이미 실리콘 밸리의 새로운 채용 전략입니다. "당신의 채용 제안에는 토큰이 얼마나 포함되어 있습니까?"
젠슨 황 CEO는 연설 말미에 차세대 컴퓨팅 아키텍처인 파인만(Feynman)을 살짝 공개했는데, 이는 구리선과 CPO(Copper Power Occupancy) 모두에서 수평 확장을 최초로 달성하는 아키텍처입니다. 더욱 흥미로운 것은 엔비디아가 개발한 우주용 데이터 센터 컴퓨터인 "베라 루빈 스페이스-1(Vera Rubin Space-1)"입니다. 이는 지구를 넘어 인공지능 컴퓨팅 성능을 확장할 수 있는 가능성을 완전히 열어줍니다.
젠슨 황의 GTC 2026 연설 전문은 AI 도구의 도움을 받아 아래와 같이 번역되었습니다.
진행자: 엔비디아의 창립자 겸 CEO인 젠슨 황을 무대에 모셨습니다.
젠슨 황, 창립자 겸 CEO:
GTC에 오신 것을 환영합니다. 다시 한번 말씀드리지만, 이곳은 기술 컨퍼런스입니다. 이렇게 이른 아침부터 많은 분들이 입장하기 위해 줄을 서 주셔서 정말 기쁘고, 오늘 이렇게 많은 분들을 뵙게 되어 영광입니다.
GTC에서 NVIDIA는 기술, 플랫폼, 생태계라는 세 가지 주요 주제에 집중할 예정입니다. NVIDIA는 현재 CUDA-X 플랫폼, 시스템 플랫폼, 그리고 최근 출시된 AI Factory 플랫폼의 세 가지 주요 플랫폼을 보유하고 있습니다.
본 행사를 공식적으로 시작하기 전에, 사전 행사를 주최해 주신 컨빅션의 사라 궈, 세쿼이아 캐피털의 알프레드 린(엔비디아의 첫 번째 벤처 투자자), 그리고 엔비디아의 첫 번째 주요 기관 투자자인 개빈 베이커께 감사의 말씀을 전하고 싶습니다. 이 세 분은 기술에 대한 깊은 통찰력을 가지고 계시며 기술 생태계 전반에 걸쳐 상당한 영향력을 행사하고 계십니다. 물론, 오늘 제가 직접 초대한 모든 귀빈 여러분께도 감사의 말씀을 드립니다. 이 모든 훌륭한 분들께 진심으로 감사드립니다.
오늘 이 자리에 참석해주신 모든 기업에도 감사의 말씀을 전하고 싶습니다. NVIDIA는 플랫폼 기업으로서 기술, 플랫폼, 그리고 풍부한 생태계를 보유하고 있습니다. 오늘 참석해주신 기업들은 100조 달러 규모의 산업에서 거의 모든 주요 기업들을 대표하고 있으며, 이 행사를 후원해주신 450개 기업에 깊이 감사드립니다.
이번 컨퍼런스에서는 1,000개의 기술 포럼과 2,000명의 연사가 참여하여 인공지능의 "5단계 케이크" 아키텍처의 모든 계층을 다룰 예정입니다. 토지, 전력, 데이터 센터와 같은 인프라부터 칩, 플랫폼, 모델, 그리고 궁극적으로 전체 산업을 발전시키는 다양한 응용 프로그램에 이르기까지 모든 것을 살펴볼 것입니다.
CUDA: 20년간의 기술 축적
모든 것은 여기서 시작되었습니다. 올해는 CUDA 탄생 20주년입니다.
저희는 20년 동안 이 아키텍처 개발에 전념해 왔습니다. CUDA는 혁신적인 발명품입니다. SIMT(단일 명령어, 다중 스레드) 기술을 통해 개발자는 스칼라 코드로 프로그램을 작성하고 이를 다중 스레드 애플리케이션으로 확장할 수 있으며, 프로그래밍 난이도는 기존의 SIMD 아키텍처보다 훨씬 낮습니다. 최근에는 개발자들이 텐서 코어와 오늘날 인공지능이 의존하는 다양한 수학적 구조를 더욱 쉽게 프로그래밍할 수 있도록 타일(Tiles) 기능을 추가했습니다. 현재 CUDA는 수천 개의 툴, 컴파일러, 프레임워크, 라이브러리를 보유하고 있으며, 오픈 소스 커뮤니티에는 수십만 개의 공개 프로젝트가 존재하고, 모든 기술 생태계에 깊이 통합되어 있습니다.
이 차트는 NVIDIA의 전략적 논리를 100% 보여주며, 저는 처음부터 이 슬라이드를 발표해 왔습니다. 달성하기 가장 어렵고 핵심적인 요소는 차트 하단에 있는 "설치된 시스템"입니다. 지난 20년 동안 우리는 전 세계적으로 수억 대의 GPU와 CUDA를 실행하는 컴퓨팅 시스템을 구축해 왔습니다.
저희 GPU는 모든 클라우드 플랫폼을 지원하며 거의 모든 컴퓨터 제조업체와 산업 분야에 서비스를 제공합니다. CUDA의 방대한 설치 기반은 이러한 선순환 구조가 지속적으로 가속화되는 근본적인 이유입니다. 설치 기반은 개발자를 끌어들이고, 개발자는 새로운 알고리즘을 개발하고 획기적인 성과를 달성하며, 이러한 성과는 새로운 시장을 창출하고, 새로운 시장은 새로운 생태계를 형성하여 더 많은 기업을 유치하고, 이는 다시 설치 기반을 확장하는 선순환 구조를 만들어냅니다. 이처럼 선순환 구조는 끊임없이 가속화되고 있습니다.
NVIDIA 라이브러리 다운로드 수는 엄청난 규모와 놀라운 속도로 증가하고 있습니다. 이러한 선순환 구조 덕분에 NVIDIA 컴퓨팅 플랫폼은 수많은 애플리케이션과 끊임없는 새로운 기술 혁신을 지원할 수 있습니다.
더욱 중요한 것은, 이러한 인프라에 매우 긴 수명을 보장한다는 점입니다. 이유는 명확합니다. NVIDIA CUDA에서 실행될 수 있는 애플리케이션은 AI 수명주기의 모든 단계, 다양한 데이터 처리 플랫폼, 그리고 광범위한 과학 문제 해결 도구를 아우르는 매우 다양한 분야를 포괄하기 때문입니다. 따라서 NVIDIA GPU를 설치하면 실질적인 가치가 매우 높아집니다. 바로 이러한 이유로 6년 전에 출시된 Ampere 아키텍처 GPU의 클라우드 가격이 실제로 상승한 것입니다.
이 모든 것의 근본 원인은 방대한 설치 기반, 강력한 플라이휠 아키텍처, 그리고 광범위한 개발자 생태계에 있습니다. 이러한 요소들이 지속적인 소프트웨어 업데이트와 결합되어 컴퓨팅 비용이 꾸준히 절감됩니다. 가속 컴퓨팅은 애플리케이션 성능을 크게 향상시키며, 장기적인 유지 관리 및 소프트웨어 반복 업데이트를 통해 사용자는 초기 성능 향상뿐 아니라 지속적인 컴퓨팅 비용 절감 효과도 누릴 수 있습니다. 아키텍처적으로 호환되는 모든 GPU에 대해 전 세계 모든 사용자에게 장기적인 지원을 제공하기 위해 최선을 다하고 있습니다.
우리가 이렇게 하는 이유는 설치 규모가 엄청나기 때문입니다. 새로운 최적화 릴리스가 나올 때마다 수백만 명의 사용자가 혜택을 받습니다. 이러한 역동적인 조합을 통해 NVIDIA 아키텍처는 지속적으로 적용 범위를 확장하고 자체 성장을 가속화하는 동시에 컴퓨팅 비용을 절감하여 궁극적으로 새로운 성장을 촉진할 수 있습니다. 이 모든 것의 중심에는 CUDA가 있습니다.
GeForce에서 CUDA까지: 25년의 진화
저희의 CUDA와의 여정은 사실 25년 전에 시작되었습니다.
지포스(GeForce)는 여러분 중 많은 분들이 어린 시절부터 함께해 온 제품입니다. 지포스는 NVIDIA의 가장 성공적인 마케팅 프로그램입니다. 여러분이 제품을 살 여유가 없던 시절부터 우리는 미래의 고객을 만들어 왔습니다. 여러분의 부모님은 NVIDIA의 초기 사용자로서 매년 제품을 구매해 주셨고, 마침내 여러분은 훌륭한 컴퓨터 과학자로 성장하여 진정한 고객이자 개발자가 되었습니다.
이것이 바로 25년 전 GeForce가 다져놓은 토대입니다. 25년 전, 우리는 프로그래밍 가능한 셰이더를 발명했습니다. 이는 당연하면서도 심오한 발명으로, 가속기를 프로그래밍 가능하게 만들었고, 세계 최초의 프로그래밍 가능 가속기인 픽셀 셰이더를 탄생시켰습니다. 5년 후, 우리는 CUDA를 개발했습니다. 이는 GeForce 역사상 가장 중요한 투자 중 하나였습니다. 제한된 자원 속에서도 우리는 수익의 대부분을 GeForce에서 모든 컴퓨터로 CUDA를 확장하는 데 투자했습니다. 그토록 확고한 의지를 가졌던 것은 CUDA의 잠재력을 믿었기 때문입니다. 초기에는 어려움이 있었지만, GeForce는 13세대, 즉 20년이라는 긴 세월 동안 이러한 믿음을 지켜왔고, 오늘날 CUDA는 어디에나 존재합니다.
지포스 혁명을 이끈 것은 바로 픽셀 셰이더였습니다. 그리고 약 8년 전, 우리는 현대 컴퓨터 그래픽 시대를 위한 완전한 아키텍처 혁신인 RTX를 선보였습니다. 지포스는 CUDA를 세상에 소개했고, 이로 인해 알렉스 크리제프스키, 일리야 수츠케버, 제프리 힌튼, 앤드류 응을 비롯한 많은 학자들이 GPU가 딥러닝 가속에 강력한 도구가 될 수 있음을 발견하여 10년 전 인공지능 폭발을 일으켰습니다.
10년 전, 우리는 프로그래밍 가능한 셰이딩을 두 가지 완전히 새로운 개념과 결합하기로 결정했습니다. 하나는 기술적으로 매우 어려운 하드웨어 레이 트레이싱이었고, 다른 하나는 당시로서는 미래지향적인 아이디어였습니다. 우리는 약 10년 전에 인공지능(AI)이 컴퓨터 그래픽에 혁명을 일으킬 것이라고 예측했습니다. 지포스(GeForce)가 AI를 세상에 가져왔듯이, 이제 AI는 컴퓨터 그래픽 구현 방식을 재편할 것입니다.
오늘 여러분께 미래를 보여드리겠습니다. 이것은 차세대 그래픽 기술인 뉴럴 렌더링(Neural Rendering)입니다. 3D 그래픽과 인공지능이 심층적으로 융합된 기술이죠. DLSS 5입니다. 한번 살펴보시기 바랍니다.
뉴럴 렌더링: 구조화된 데이터와 생성형 AI의 융합
정말 놀랍지 않나요? 컴퓨터 그래픽이 살아 움직이는 것 같아요.
우리는 무엇을 했을까요? 제어 가능한 3D 그래픽(가상 세계의 진정한 기반)과 구조화된 데이터를 결합하고, 여기에 생성형 AI와 확률적 연산을 접목했습니다. 하나는 완전히 결정론적이고, 다른 하나는 확률적이지만 매우 사실적인 연산입니다. 우리는 이 두 가지 개념을 융합하여 구조화된 데이터를 통해 정밀한 제어를 구현하는 동시에 실시간으로 콘텐츠를 생성했습니다. 결과적으로, 콘텐츠는 시각적으로 뛰어날 뿐만 아니라 완벽하게 제어 가능합니다.
정형화된 정보를 생성형 AI와 통합하는 개념은 다양한 산업 분야에서 계속해서 부상할 것입니다. 정형화된 데이터는 신뢰할 수 있는 AI의 초석입니다.
정형 및 비정형 데이터 가속화 플랫폼
이제 기술 아키텍처 다이어그램을 보여드리겠습니다.
SQL, Spark, Pandas, Velox, Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery와 같은 익숙한 플랫폼들은 모두 데이터 프레임을 처리합니다. 이러한 데이터 프레임은 마치 거대한 스프레드시트처럼 비즈니스 세계의 모든 정보를 담고 있으며, 엔터프라이즈 컴퓨팅의 핵심 정보를 나타냅니다.
인공지능 시대에는 인공지능이 정형화된 데이터를 활용하고 그 처리 속도를 극대화할 수 있도록 해야 합니다. 과거에는 정형화된 데이터 처리 속도 향상이 기업의 운영 효율성 증대를 위한 것이었지만, 미래에는 인공지능이 인간을 훨씬 능가하는 속도로 이러한 데이터 구조를 활용하고, 정형화된 데이터베이스를 광범위하게 사용할 것입니다.
비정형 데이터와 관련하여 벡터 데이터베이스, PDF, 비디오 및 오디오는 전 세계적으로 가장 많은 데이터 형식을 차지하며, 매년 생성되는 데이터의 약 90%가 비정형 데이터입니다. 과거에는 이러한 데이터를 거의 활용할 수 없었습니다. 데이터를 읽고 파일 시스템에 저장하는 것으로 충분했습니다. 쿼리할 수 없었고, 비정형 데이터에는 간단한 인덱싱 방법이 부족하여 데이터를 검색하기 어려웠습니다. 데이터의 의미와 맥락을 이해해야 했습니다. 이제 인공지능(AI)이 이를 가능하게 했습니다. AI는 멀티모달 인식 및 이해 기술을 사용하여 PDF 문서를 읽고 의미를 파악한 다음, 이를 더 크고 쿼리 가능한 구조에 포함시킬 수 있습니다.
엔비디아는 이러한 목적을 위해 두 가지 기본 라이브러리를 만들었습니다.
- cuDF: 데이터 프레임 및 구조화된 데이터의 가속 처리에 사용됩니다.
- cuVS: 벡터 저장, 의미 데이터 및 비정형 AI 데이터 처리에 사용됩니다.
이 두 플랫폼은 미래에 가장 중요한 기반 플랫폼 중 하나가 될 것입니다.
오늘, 저희는 여러 기업과의 파트너십을 발표합니다. SQL 언어의 창시자인 IBM은 cuDF를 사용하여 WatsonX 데이터 플랫폼의 속도를 향상시킬 예정입니다. Dell은 저희와 협력하여 cuDF와 cuVS를 통합한 Dell AI 데이터 플랫폼을 구축했으며, NTT Data의 실제 프로젝트에서 상당한 성능 향상을 달성했습니다. Google Cloud 분야에서는 Vertex AI뿐만 아니라 BigQuery의 속도도 향상시키고 있으며, Snapchat과의 파트너십을 통해 컴퓨팅 비용을 거의 80% 절감했습니다.
가속 컴퓨팅의 이점은 속도, 확장성, 비용이라는 세 가지 측면에서 나타납니다. 이는 무어의 법칙과 일맥상통하는데, 가속 컴퓨팅을 통해 성능을 비약적으로 향상시키고 알고리즘을 지속적으로 최적화하여 컴퓨팅 비용을 지속적으로 절감함으로써 모든 사용자가 혜택을 누릴 수 있도록 하는 것입니다.
NVIDIA는 RTX, cuDF, cuVS를 비롯한 다양한 라이브러리를 통합한 가속 컴퓨팅 플랫폼을 구축했습니다. 이러한 라이브러리는 글로벌 클라우드 서비스 및 OEM 네트워크에 통합되어 전 세계 사용자에게 제공됩니다.
클라우드 서비스 제공업체와의 긴밀한 협력
주요 클라우드 서비스 제공업체와의 파트너십
Google Cloud: Vertex AI와 BigQuery의 속도를 향상시키고, JAX/XLA와 긴밀하게 통합하며, PyTorch 분야에서 탁월한 성능을 자랑합니다. NVIDIA는 PyTorch와 JAX/XLA 모두에서 뛰어난 성능을 발휘하는 세계 유일의 가속기 제공업체입니다. Base10, CrowdStrike, Puma, Salesforce와 같은 고객사를 Google Cloud 생태계로 이끌었습니다.
AWS: 저희는 AWS와 긴밀하게 통합된 EMR, SageMaker, Bedrock의 개발을 가속화하고 있습니다. 올해 가장 기대되는 점은 OpenAI를 AWS에 도입하는 것입니다. 이를 통해 AWS 클라우드 컴퓨팅 사용량 증가를 크게 촉진하고 OpenAI의 지역 배포 및 컴퓨팅 규모 확장에 도움을 줄 수 있을 것입니다.
Microsoft Azure: NVIDIA 100 PFLOPS 슈퍼컴퓨터는 NVIDIA가 구축하고 Azure에 배포한 최초의 슈퍼컴퓨터로, OpenAI와의 협력에 중요한 기반을 마련했습니다. 우리는 Azure 클라우드 서비스와 AI Foundry를 가속화하고, Azure 지역 확장에 협력하며, Bing 검색 개발을 위해 긴밀히 협력하고 있습니다. 특히, 통신 사업자조차 사용자 데이터와 모델을 볼 수 없도록 보장하는 NVIDIA의 **기밀 컴퓨팅** 기능은 NVIDIA GPU를 세계 최초로 기밀 컴퓨팅을 지원하는 제품 중 하나로 만들어, 전 세계 클라우드 환경에서 OpenAI 및 Anthropic 모델을 안전하게 배포할 수 있도록 합니다. 예를 들어, Synopsys와 협력하여 전체 EDA 및 CAD 워크플로우를 가속화하고 Microsoft Azure에 배포하고 있습니다.
오라클: 저희는 오라클의 첫 번째 AI 고객이었으며, 오라클에 AI 클라우드 개념을 처음으로 설명한 사람이 저라는 것이 자랑스럽습니다. 그 이후로 오라클은 빠르게 성장했고, 저희는 코히어, 파이어웍스, 오픈AI를 포함한 많은 파트너사를 오라클에 소개했습니다.
CoreWeave는 세계 최초의 AI 네이티브 클라우드로, GPU 호스팅 및 AI 클라우드 서비스를 위해 특별히 설계되었으며, 우수한 고객 기반과 강력한 성장세를 자랑합니다.
팔란티어와 델은 팔란티어의 온톨로지 플랫폼과 AI 플랫폼을 기반으로 완전히 새로운 AI 플랫폼을 공동 개발했습니다. 이 플랫폼은 데이터 처리(벡터화 또는 구조화)부터 AI를 위한 완벽한 가속 컴퓨팅 스택에 이르기까지 모든 것을 포괄하며, 어느 국가, 어느 에어갭 격리 환경에서도 완전히 현지화된 방식으로 AI를 배포할 수 있습니다.
NVIDIA는 글로벌 클라우드 서비스 제공업체와 특별한 파트너십을 구축하여 고객을 클라우드로 안내하고 상호 이익이 되는 생태계를 조성합니다.
수직적 통합, 수평적 개방성: 엔비디아의 핵심 전략
엔비디아는 세계 최초의 수직 통합형이자 수평 개방형 기업입니다.
이 모델의 필요성은 매우 간단합니다. 가속 컴퓨팅은 칩 문제도 아니고 시스템 문제도 아닙니다. 가속 컴퓨팅을 온전히 설명하려면 애플리케이션 가속이라고 해야 합니다. CPU는 컴퓨터의 전반적인 속도를 향상시킬 수 있지만, 이 방식은 이미 한계에 도달했습니다. 앞으로는 애플리케이션 또는 도메인별 가속만이 성능 향상과 비용 절감을 지속적으로 제공할 수 있을 것입니다.
바로 이러한 이유 때문에 NVIDIA는 라이브러리, 도메인, 산업 분야를 차례로 심층적으로 탐구해야 합니다. NVIDIA는 수직적으로 통합된 컴퓨팅 회사이며, 다른 방법은 없습니다. 애플리케이션을 이해하고, 도메인을 이해하고, 알고리즘을 깊이 있게 파악하여 데이터 센터, 클라우드, 온프레미스, 엣지, 심지어 로봇 시스템에 이르기까지 모든 시나리오에 배포할 수 있어야 합니다.
동시에 NVIDIA는 수평적 개방성을 유지하며, 자사 기술을 모든 파트너 플랫폼에 통합하여 전 세계가 가속 컴퓨팅의 이점을 누릴 수 있도록 노력하고 있습니다.
올해 GTC 참석자 구성은 이 점을 완벽하게 보여줍니다. 금융 서비스 업계 참석자 비율이 가장 높았는데, 우리는 트레이더가 아닌 개발자들을 더 많이 만나기를 기대합니다. 우리 생태계는 공급망의 상류와 하류 모두를 아우릅니다. 기업의 역사가 50년이든, 70년이든, 150년이든, 작년은 모든 기업에게 최고의 한 해였습니다. 우리는 매우 중요한 무언가의 시작점에 서 있습니다.
CUDA-X: 다양한 산업 분야를 위한 가속 컴퓨팅 엔진
엔비디아는 다양한 산업 분야에서 강력한 입지를 구축하고 있습니다.
- 자율 주행: 광범위하고 파급력 있는 영향
- 금융 서비스: 양적 투자는 수동 특징 엔지니어링에서 슈퍼컴퓨터 기반 딥러닝으로 전환되면서 "트랜스포머의 순간"을 맞이하고 있습니다.
- 의료 분야: AI 기반 신약 개발, AI 기반 진단, 의료 고객 서비스 등 다양한 영역을 아우르는 "ChatGPT의 순간"이 도래하고 있습니다.
- 산업 분야: 세계 최대 규모의 건설 붐이 일고 있으며, AI 공장, 반도체 공장, 데이터 센터 공장들이 곳곳에 들어서고 있습니다.
- 엔터테인먼트 및 게임: 실시간 AI 플랫폼은 번역, 라이브 스트리밍, 게임 상호 작용 및 지능형 쇼핑 에이전트를 지원합니다.
- 로봇공학: 10년 이상의 경험과 세 가지 주요 컴퓨터 아키텍처(훈련용 컴퓨터, 시뮬레이션 컴퓨터, 온보드 컴퓨터)를 완벽하게 갖춘 시스템을 바탕으로, 이번 전시회에서는 110대의 로봇이 전시되었습니다.
- 통신 산업은 약 2조 달러 규모로, 기지국은 단순한 통신 기능을 넘어 AI 기반 인프라 플랫폼으로 진화할 것입니다. 에어리얼(Aerial)은 이러한 플랫폼 중 하나로, 노키아, T-모바일과 같은 기업들과 긴밀한 협력 관계를 구축하고 있습니다.
이 모든 영역의 중심에는 NVIDIA가 알고리즘 기업으로서 자리매김할 수 있도록 해주는 핵심 기반인 CUDA-X 라이브러리가 있습니다. 이 라이브러리는 NVIDIA의 가장 귀중한 자산으로, 컴퓨팅 플랫폼이 다양한 산업 분야에서 실질적인 가치를 제공할 수 있도록 지원합니다.
가장 중요한 라이브러리 중 하나는 cuDNN(CUDA 심층 신경망 라이브러리)으로, 이는 인공지능에 혁명을 일으키고 현대 AI의 폭발적인 성장을 촉발했습니다.
(CUDA-X 데모 영상 재생 중)
방금 보신 모든 것은 시뮬레이션입니다. 물리 기반 솔버, AI가 조작하는 물리 모델, 그리고 AI 로봇 모델까지 모두 시뮬레이션이었죠. 수작업으로 그린 애니메이션이나 관절 조형은 전혀 없었습니다. 이것이 바로 NVIDIA의 핵심 역량입니다. 알고리즘에 대한 깊이 있는 이해와 컴퓨팅 플랫폼의 유기적인 통합을 통해 이러한 가능성을 현실로 구현하는 것이죠.
AI 기반 기업과 새로운 컴퓨팅 시대
방금 여러분은 월마트, 로레알, JP모건 체이스, 로슈, 도요타와 같이 오늘날 사회를 좌우하는 업계 거물 기업들뿐만 아니라, 여러분이 이전에 들어보지 못했을 수많은 기업들, 즉 AI 기반 기업들을 살펴보았습니다. 이 목록은 오픈AI, 앤트로픽, 그리고 다양한 산업 분야에 서비스를 제공하는 많은 신흥 기업들을 포함하여 매우 방대합니다.
지난 2년간 이 산업은 경이로운 성장을 경험했습니다. 스타트업에 대한 벤처 캐피털 유입액은 사상 최고치인 1,500억 달러에 달했습니다. 더욱 중요한 것은, 단일 투자 규모가 수백만 달러에서 수억 달러, 심지어 수십억 달러로 급증했다는 점입니다. 그 이유는 단 하나, 역사상 처음으로 이러한 유형의 모든 기업이 막대한 컴퓨팅 자원과 엄청난 양의 토큰을 필요로 하기 때문입니다. 이 산업은 Anthropic이나 OpenAI와 같은 조직을 통해 토큰을 생성, 육성 또는 가치화하고 있습니다.
PC 혁명, 인터넷 혁명, 모바일 클라우드 혁명이 각각 획기적인 기업들을 탄생시켰듯이, 이번 컴퓨팅 플랫폼 변혁 또한 미래 세계에서 중요한 영향력을 행사할 기업들을 다수 배출할 것입니다.
이 모든 것을 이끌어낸 세 가지 역사적인 돌파구
지난 2년 동안 정확히 무슨 일이 있었나요? 세 가지 주요 사건이 있었습니다.
첫째: ChatGPT, 생성형 AI 시대의 서막을 열다 (2022년 말~2023년)
생성형 AI는 단순히 인지하고 이해하는 것을 넘어 독창적인 콘텐츠를 생성할 수 있습니다. 저는 생성형 AI와 컴퓨터 그래픽의 융합을 시연했습니다. 생성형 AI는 우리가 컴퓨팅하는 방식을 검색 기반에서 생성 기반으로 근본적으로 변화시키며, 컴퓨터 아키텍처, 배포 방식, 그리고 전반적인 의미에 심대한 영향을 미칩니다.
두 번째: O1으로 표현되는 추론 AI.
추론 능력은 인공지능이 스스로를 되돌아보고, 계획을 세우고, 문제를 세분화할 수 있도록 해줍니다. 즉, 직접 이해할 수 없는 문제를 관리 가능한 단계로 나누는 것입니다. 이러한 능력 덕분에 생성형 인공지능은 현실 세계의 정보를 기반으로 추론할 수 있어 신뢰성을 확보할 수 있습니다. 하지만 이를 위해서는 입력 컨텍스트에 사용되는 토큰 수와 추론에 사용되는 출력 토큰 수가 크게 증가해야 하며, 결과적으로 계산 복잡성이 상당히 높아집니다.
셋째: 클로드 코드, 최초의 지능형 에이전트 모델.
클로드 코드(Claude Code)는 파일을 읽고, 코드를 작성하고, 컴파일하고, 테스트하고, 평가하고, 반복 작업을 수행할 수 있습니다. 클로드 코드는 소프트웨어 엔지니어링에 혁명을 일으켰으며, NVIDIA 엔지니어의 100%가 클로드 코드, 코덱스(Codex), 커서(Cursor) 중 하나 이상을 사용하고 있습니다. 이제 AI의 도움 없이 소프트웨어 엔지니어링을 할 수 있는 엔지니어는 없습니다.
이는 완전히 새로운 전환점입니다. 이제 인공지능에게 "무엇을, 어디서, 어떻게" 묻는 것이 아니라, "창조하고, 실행하고, 구축"하도록 맡기는 것입니다. 인공지능이 능동적으로 도구를 사용하고, 파일을 읽고, 문제를 분석하고, 조치를 취할 수 있도록 하는 것입니다. 인공지능은 인지에서 생성, 추론으로 진화했고, 이제는 진정으로 일을 해낼 수 있게 되었습니다.
지난 2년 동안 추론에 필요한 연산량은 약 1만 배 증가한 반면, 실제 사용량은 약 100배 증가했습니다. 저는 지난 2년 동안 연산량이 백만 배 증가했다고 늘 생각해 왔으며, 이는 OpenAI와 Anthropic을 비롯한 많은 사람들이 공감하는 바입니다. 더 많은 컴퓨팅 파워를 확보하고, 더 많은 토큰을 생성하고, 수익을 늘리면 AI는 더욱 똑똑해질 것입니다. 추론의 변곡점이 도래했습니다.
수조 달러 규모의 AI 인프라 시대
작년 이맘때, 저는 블랙웰과 루빈의 2026년까지의 수요 및 수주 잔고가 약 5천억 달러에 달할 것이라는 높은 확신을 표명했습니다. GTC가 열린 지 1년이 지난 오늘, 저는 여러분께 2027년까지의 수요와 수주 잔고가 최소 1조 달러에 이를 것으로 예상한다고 말씀드립니다. 그리고 실제 컴퓨팅 수요는 그보다 훨씬 더 클 것이라고 확신합니다.
2025년: 엔비디아의 공제 연도
2025년은 NVIDIA의 추론의 해입니다. 학습 및 학습 후 단계를 넘어 AI 라이프사이클의 모든 단계에서 최고의 성능을 보장하고, 투자된 인프라가 더 긴 유효 수명과 낮은 단위 비용으로 효율적으로 운영될 수 있도록 하는 것이 NVIDIA의 목표입니다.
동시에 Anthropic과 Meta는 공식적으로 NVIDIA 플랫폼에 합류했으며, 이로써 전 세계 AI 컴퓨팅 파워 수요의 3분의 1을 차지하게 되었습니다. 오픈 소스 모델은 최첨단 수준에 근접하고 있으며, 이제 어디에서나 찾아볼 수 있습니다.
NVIDIA는 현재 전 세계에서 유일하게 언어, 생물학, 컴퓨터 그래픽, 컴퓨터 비전, 음성, 단백질 및 화학, 로봇 공학 등 모든 AI 분야의 모든 AI 모델을 엣지 환경이나 클라우드 환경에서, 언어에 관계없이 실행할 수 있는 플랫폼입니다. NVIDIA의 아키텍처는 이러한 모든 시나리오에 걸쳐 다재다능한 성능을 제공하여 가장 저렴하고 안정적인 플랫폼을 구현합니다.
현재 엔비디아 사업의 60%는 세계 5대 하이퍼스케일 클라우드 서비스 제공업체에서 발생하며, 나머지 40%는 지역 클라우드, 주권 클라우드, 기업, 산업, 로봇, 엣지 컴퓨팅 등 다양한 분야에 걸쳐 있습니다. 엔비디아의 성장 동력은 바로 이러한 광범위한 AI 서비스 영역, 즉 완전히 새로운 컴퓨팅 플랫폼 혁명에서 비롯됩니다.
그레이스 블랙웰과 NVLink 72: 대담한 건축 혁신
호퍼 아키텍처가 전성기를 누리던 시기에, 우리는 시스템을 완전히 재설계하기로 결정했습니다. NVLink를 8방향에서 NVLink 72로 확장하고, 컴퓨팅 시스템을 전면적으로 분해 및 재구성했습니다. NVLink 72는 엄청난 기술적 모험이었으며, 모든 파트너에게 결코 쉬운 일이 아니었습니다. 이 프로젝트에 참여해주신 모든 분들께 진심으로 감사드립니다.
동시에, 우리는 일반 FP4가 아닌 완전히 새로운 유형의 텐서 코어 및 연산 장치인 NVFP4를 도입했습니다. NVFP4는 정밀도 손실 없이 추론을 수행하면서 성능과 에너지 효율성을 크게 향상시키고, 학습에도 적합하다는 것을 입증했습니다. 또한 Dynamo, TensorRT-LLM과 같은 새로운 알고리즘들이 등장했으며, 커널 최적화 전용 슈퍼컴퓨터인 DGX 클라우드 구축에 수십억 달러를 투자하기도 했습니다.
이번 결과는 NVIDIA의 탁월한 추론 성능을 입증합니다. 현재까지 가장 포괄적인 AI 추론 성능 벤치마크인 Semi Analysis의 데이터에 따르면 NVIDIA는 와트당 토큰 수와 토큰당 비용 모두에서 압도적인 우위를 보였습니다. 무어의 법칙에 따르면 H200의 성능 향상은 1.5배 정도일 것으로 예상되었지만, NVIDIA는 35배라는 놀라운 성능을 달성했습니다. Semi Analysis의 딜런 파텔은 "황 대표가 보수적으로 말한 겁니다. 실제로는 50배 향상되었을 겁니다."라고 말했는데, 그의 말이 맞습니다.
그의 말을 인용하자면, "젠슨이 (황런쉰이) 보도에서 보수적인 입장을 취했다는 것을) 폭로했다."
엔비디아의 토큰당 비용은 전 세계에서 가장 낮으며, 현재 어떤 회사도 이 수준에 필적하지 못합니다. 그 이유는 바로 익스트림 코디자인(Extreme Co-design) 기술에 있습니다.
Fireworks를 예로 들면, NVIDIA가 소프트웨어와 알고리즘 전체를 업데이트하기 전에는 평균 토큰 처리 속도가 초당 약 700개였지만, 업데이트 후에는 초당 약 5,000개에 육박하여 약 7배 향상되었습니다. 이것이 바로 극단적인 협업 설계의 힘입니다.
AI 팩토리: 데이터 센터에서 토큰 팩토리로
데이터 센터는 과거에는 파일을 저장하는 장소였지만, 이제는 토큰을 생산하는 공장이 되었습니다. 모든 클라우드 서비스 제공업체와 모든 AI 기업은 미래에 "토큰 공장 효율성"을 핵심 운영 지표로 활용할 것입니다.
이것이 제가 주장하는 핵심입니다.
- 세로축: 처리량 – 고정된 전력 수준에서 초당 생성되는 토큰 수
- 가로축: 토큰 속도 – 추론 단계당 응답 속도. 속도가 빠를수록 사용 가능한 모델의 크기가 커지고, 처리 가능한 컨텍스트가 길어지며, AI의 지능이 높아집니다.
해당 토큰은 성숙 단계에 따라 가격이 단계별로 책정될 새로운 상품입니다.
- 무료 요금제 (높은 처리량, 낮은 속도)
- 중급 등급 (토큰 백만 개당 약 3달러)
- 고급 등급 (토큰 백만 개당 약 6달러)
- 고속 레이어(토큰 백만 개당 약 45달러)
- 초고속 레이어(토큰 백만 개당 약 150달러)
호퍼와 비교했을 때, 그레이스 블랙웰은 최고 가치 등급에서 35배 더 높은 처리량을 제공하며 완전히 새로운 등급을 도입했습니다. 단순화된 모델을 사용하여 4개 등급에 전력의 25%를 할당할 경우, 그레이스 블랙웰은 호퍼보다 5배 더 많은 수익을 창출할 수 있습니다.
베라 루빈: 차세대 AI 컴퓨팅 시스템
(베라 루빈 시스템을 소개하는 영상을 재생 중)
Vera Rubin은 에이전트 기반 워크로드에 특화된 완벽한 엔드투엔드 최적화 시스템입니다.
- 대규모 언어 모델 연산의 핵심은 사전 데이터 입력 및 키-값 캐시를 처리하는 NVLink 72 GPU 클러스터입니다.
- 완전히 새로워진 Vera CPU는 극도로 높은 단일 스레드 성능을 위해 설계되었으며, LPDDR5 메모리를 사용하고 뛰어난 에너지 효율성을 자랑합니다. 세계에서 유일하게 LPDDR5를 사용하는 데이터 센터 CPU로서 AI 에이전트 도구 호출에 적합합니다.
- 스토리지 시스템: BlueField 4 + CX 9는 AI 시대를 위한 완전히 새로운 스토리지 플랫폼으로, 스토리지 업계의 전 세계 기업들이 100% 참여했습니다.
- CPO Spectrum X 스위치: 세계 최초의 코패키징 광 이더넷 스위치가 이제 본격적인 양산에 들어갔습니다.
- Kyber Rack: 144개의 GPU를 하나의 NVLink 도메인으로 구성하여 프런트엔드 컴퓨팅과 백엔드 NVLink 스위칭을 통해 슈퍼컴퓨터를 구현하는 완전히 새로운 랙 시스템입니다.
- Rubin Ultra: Kyber 랙과 호환되고 대규모 NVLink 인터커넥트를 지원하는 수직 통합 설계를 갖춘 차세대 슈퍼컴퓨팅 노드입니다.
Vera Rubin은 이제 100% 액체 냉각 방식을 채택하여 설치 시간을 이틀에서 두 시간으로 단축했습니다. 45°C의 고온수를 사용하여 데이터 센터의 냉각 부담을 크게 줄였습니다. 사티아 나델라 CEO가 첫 번째 Vera Rubin 랙이 Microsoft Azure에서 가동 중임을 확인해 주셔서 매우 기쁩니다.
Groq 통합: 추론 성능의 궁극적인 확장
저희는 Groq 팀을 인수하고 기술 라이선스를 획득했습니다. Groq는 정적 컴파일 및 컴파일러 스케줄링을 사용하는 결정론적 데이터 흐름 프로세서로, 대용량 SRAM을 탑재하고 단일 추론 워크로드에 최적화되어 있으며, 매우 낮은 지연 시간과 매우 빠른 토큰 생성 속도를 자랑합니다.
하지만 Groq의 제한된 메모리 용량(온칩 SRAM 500MB)으로 인해 대규모 모델의 파라미터와 KV 캐시를 독립적으로 처리하기 어렵기 때문에 대규모 적용에 제약이 있습니다.
해결책은 추론 스케줄링 소프트웨어인 Dynamo입니다. 우리는 Dynamo를 사용하여 추론 파이프라인을 분산시킵니다.
- 사전 채우기 및 어텐션 메커니즘 디코딩은 Vera Rubin에서 수행됩니다(상당한 컴퓨팅 성능과 KV 캐시 저장 공간이 필요함).
- **피드포워드 네트워크 디코딩**, 즉 토큰 생성 부분은 Groq에서 완료됩니다(매우 높은 대역폭과 낮은 지연 시간이 필요함).
두 장치는 이더넷을 통해 긴밀하게 연결되어 있으며, 특수 모드를 통해 지연 시간을 약 절반으로 줄입니다. "AI 팩토리 운영 체제"인 Dynamo의 통합 스케줄링 하에서 전체 성능이 35배 향상되어 NVLink 72로는 이전에는 도달할 수 없었던 새로운 수준의 추론 성능을 구현할 수 있습니다.
Groq와 Vera Rubin의 조합 추천:
- 작업 부하가 주로 높은 처리량이라면 Vera Rubin을 100% 사용하십시오.
- 만약 작업량의 상당 부분이 코드와 같은 고가치 토큰 생성과 관련된 것이라면 Groq를 도입할 수 있으며, 권장 비율은 Groq 25% + Vera Rubin 75%입니다.
Groq LP30은 삼성에서 제조하며 현재 양산 중으로 3분기부터 출하가 시작될 예정입니다. 삼성의 전폭적인 협조에 감사드립니다.
추론 성능의 역사적인 도약
이전 기술 발전의 수치화: 2년 안에 1기가와트급 AI 공장의 토큰 생성 속도는 초당 2,200만 개에서 7억 개로, 350배 증가할 것입니다. 이것이 바로 궁극적인 협업 설계의 힘입니다.
기술 로드맵
- Blackwell: 현재 생산 중인 Oberon 표준 랙 시스템은 구리 케이블이 NVLink 72까지 확장되었으며, 광 케이블 확장은 NVLink 576까지 선택적으로 가능합니다.
- 베라 루빈(현): Kyber 랙, NVLink 144(구리 케이블); Oberon 랙, NVLink 72 + 광케이블, NVLink 576까지 확장; Spectrum 6, 세계 최초의 CPO 스위치.
- Vera Rubin Ultra(출시 예정): 차세대 Rubin Ultra GPU, LP35 칩(NVFP4를 최초로 통합)을 통해 성능이 몇 배 향상되었습니다.
- 파인만(차세대): NVIDIA와 Groq 팀이 공동 개발한 NVFP4 통합 LP40 칩이라는 완전히 새로운 GPU, 완전히 새로운 CPU인 로사(로잘린), BlueField 5, CX 10, 그리고 구리 케이블과 CPO 확장을 모두 지원하는 Kyber 랙이 포함됩니다.
로드맵은 명확합니다. 구리 케이블 확장, 광섬유 확장(규모 확대), 광섬유 확장(규모 축소)의 세 가지 경로를 동시에 추진하고 있습니다. 모든 파트너사가 구리 케이블, 광섬유 및 CPO의 생산 능력을 지속적으로 확대해 주시기를 바랍니다.
NVIDIA DSX: AI 팩토리를 위한 디지털 트윈 플랫폼
AI 공장은 점점 더 복잡해지고 있지만, 이를 구성하는 다양한 기술 공급업체들은 설계 단계에서 서로 협력한 적이 없고, 단지 데이터 센터에서 "만났을" 뿐입니다. 이는 분명히 충분하지 않습니다.
이를 위해 NVIDIA는 Omniverse와 그 위에 구축된 NVIDIA DSX 플랫폼을 개발했습니다. 이 플랫폼은 모든 파트너가 가상 세계에서 기가와트급 AI 공장을 공동 설계하고 운영할 수 있도록 지원합니다. DSX는 다음과 같은 기능을 제공합니다.
- 랙 레벨 기계, 열, 전기 및 네트워크 시뮬레이션 시스템
- 전력망과의 연결을 통해 에너지 절약을 위한 효율적인 전력 배분이 가능합니다.
- 데이터 센터에서 Max-Q 기반의 동적 전력 소비 및 냉각 최적화
보수적인 추정치에 따르면 이 시스템은 에너지 효율을 약 2배 향상시킬 수 있으며, 이는 우리가 논의하는 규모에서 매우 중요한 이점입니다. 옴니버스(Omniverse)는 디지털 어스(Digital Earth)를 시작으로 모든 규모의 디지털 트윈을 지원할 것이며, 우리는 전 세계 파트너들과 협력하여 인류 역사상 가장 큰 컴퓨터를 구축하고 있습니다.
더 나아가 엔비디아는 우주 진출에도 박차를 가하고 있습니다. Thor 칩은 방사선 인증을 획득하여 위성에서 사용되고 있으며, 파트너사와 협력하여 우주 데이터 센터 구축을 위한 Vera Rubin Space-1을 개발 중입니다. 우주에서는 열 방출이 전적으로 방사선에 의존하기 때문에 열 관리가 핵심 과제이며, 엔비디아는 이 과제를 해결하기 위해 최고의 엔지니어들을 모으고 있습니다.
OpenClaw: 지능형 에이전트 시대를 위한 운영 체제
피터 스타인버거는 오픈클로(OpenClaw)라는 소프트웨어를 개발했습니다. 이는 인류 역사상 가장 인기 있는 오픈 소스 프로젝트로, 불과 몇 주 만에 리눅스가 30년간 이뤄낸 성과를 넘어섰습니다.
OpenClaw는 기본적으로 다음과 같은 기능을 갖춘 에이전트 시스템입니다.
- 리소스 관리, 도구 접근, 파일 시스템 및 대규모 언어 모델 관리.
- 일정 및 시간 제한 작업을 실행합니다.
- 문제를 단계별로 나누어 하위 담당자에게 연락하십시오.
- 음성, 영상, 텍스트, 이메일 등 모든 방식의 입력과 출력을 지원합니다.
운영체제 구문을 사용하자면, OpenClaw는 실제로 운영체제입니다. 지능형 에이전트 컴퓨터를 위한 운영체제인 셈이죠. Windows가 개인용 컴퓨터를 가능하게 했다면, OpenClaw는 개인용 지능형 에이전트를 가능하게 합니다.
모든 기업은 리눅스 전략, HTML 전략, 쿠버네티스 전략이 필요한 것처럼 자체적인 오픈클로 전략을 개발해야 합니다.
기업 IT의 완전한 재편
OpenClaw 이전에는 기업 IT는 시스템에 입력되는 데이터와 파일이 도구와 워크플로를 거쳐 최종적으로 사람이 사용할 수 있는 도구로 변환되는 과정으로 이루어졌습니다. 소프트웨어 회사는 이러한 도구를 개발했고, 시스템 통합업체(GSI)와 컨설팅 회사는 기업이 이러한 도구를 활용할 수 있도록 지원했습니다.
OpenClaw 이후의 기업 IT: 모든 SaaS 기업은 AaaS(서비스형 에이전트) 기업으로 변모할 것입니다. 단순히 도구를 제공하는 것을 넘어 특정 영역에 특화된 AI 에이전트를 제공하게 될 것입니다.
하지만 여기에는 중요한 과제가 있습니다. 기업 내 지능형 에이전트는 민감한 데이터에 접근하고, 코드를 실행하며, 외부 기관과 통신할 수 있습니다. 따라서 기업 환경에서는 이러한 활동을 엄격하게 통제해야 합니다.
이를 위해 저희는 피터와 협력하여 엔터프라이즈 버전에 보안 기능을 통합했으며, 그 결과는 다음과 같습니다.
- NeMo Claw(참조 설계): OpenClaw를 기반으로 하는 엔터프라이즈급 참조 프레임워크로, NVIDIA의 지능형 에이전트 AI 툴킷 제품군 전체를 통합합니다.
- Open Shield(보안 계층): OpenClaw에 통합되어 정책 엔진, 네트워크 장벽 및 개인 정보 보호 라우팅을 제공하여 기업 데이터 보안을 보장합니다.
- NeMo 클라우드: 다운로드하여 바로 사용 가능하며, 모든 SaaS 기업의 전략 엔진과 호환됩니다.
이는 기업 IT 산업의 르네상스입니다. 원래 2조 달러 규모였던 이 산업은 이제 수조 달러 규모로 성장할 전망이며, 단순히 도구를 제공하는 것에서 벗어나 전문적인 AI 에이전트 서비스를 제공하는 방향으로 전환하고 있습니다.
저는 미래에 회사 내 모든 엔지니어에게 연간 토큰 예산이 주어질 것이라고 확신합니다. 그들의 연봉이 수십만 달러에 달하더라도, 저는 연봉의 절반에 해당하는 추가 토큰을 지급하여 생산성을 열 배로 증폭시킬 것입니다. "입사 시 토큰 지급액은 얼마인가요?"라는 질문이 실리콘 밸리의 새로운 채용 화두가 될 것입니다.
미래에는 모든 기업이 (엔지니어를 위한) 토큰 사용자이자 (고객에게 서비스를 제공하기 위한) 토큰 생산자가 될 것입니다. OpenClaw의 중요성은 아무리 강조해도 지나치지 않으며, HTML과 Linux만큼이나 중요합니다.
NVIDIA 오픈 모델 이니셔티브
맞춤형 클로와 관련하여 NVIDIA에서 자체 개발한 최첨단 모델을 제공합니다.
모델링 분야에는 네모트론(대규모 언어 모델), 코스모스(세계 기반 모델), GROOT(범용 휴머노이드 로봇 모델), 알파마요(자율 주행), 바이오네모(디지털 생물학), 피직스-AI(물리학) 등이 있습니다.
우리는 모든 분야에서 기술의 최첨단에 서 있으며 지속적인 개선에 전념하고 있습니다. 네모트론 3에 이어 네모트론 4가, 코스모스 1에 이어 코스모스 2가 출시되었으며, 그로크 또한 2세대 제품으로 개선될 것입니다.
Nemotron 3는 OpenClaw에서 전 세계 최고 모델 3위 안에 드는 뛰어난 성능을 자랑하며, 해당 분야의 선두에 서 있습니다. Nemotron 3 Ultra는 국가들이 주권적인 AI를 구축하는 데 도움을 주는, 역사상 가장 강력한 기반 모델이 될 것입니다.
오늘 우리는 기초 AI 모델 개발을 촉진하기 위해 수십억 달러를 투자하는 네모트론 컨소시엄(Nemotron Consortium)의 설립을 발표합니다. 컨소시엄 회원사로는 BlackForest Labs, Cursor, LangChain, Mistral, Perplexity, Reflection, Sarvam(인도), Thinking Machines(미라 무라티 연구소) 등이 있습니다. 엔터프라이즈 소프트웨어 기업들도 참여하여 NeMo Claw 레퍼런스 디자인과 NVIDIA의 AI 에이전트 툴킷을 자사 제품에 통합하고 있습니다.
물리학, 인공지능 및 로봇공학
디지털 지능형 에이전트는 코드를 작성하고 데이터를 분석하는 등 디지털 세계에서 활동하는 반면, 물리적 AI는 로봇과 같은 실체를 가진 지능형 에이전트입니다.
올해 GTC에서는 전 세계 거의 모든 로봇 연구 개발 기업의 로봇 110대가 전시되었습니다. NVIDIA는 3대의 컴퓨터(훈련용 컴퓨터, 시뮬레이션용 컴퓨터, 온보드 컴퓨터)와 완벽한 소프트웨어 스택 및 AI 모델을 제공했습니다.
자율주행 분야에서 'ChatGPT의 시대'가 도래했습니다. 오늘 NVIDIA는 BYD, 현대, 닛산, 지리 등 4개 파트너사가 NVIDIA RoboTaxi Ready 플랫폼에 합류한다고 발표했습니다. 이들 파트너사의 연간 총 생산 능력은 1,800만 대에 달합니다. 이로써 기존에 참여했던 메르세데스-벤츠, 도요타, GM에 이어 더욱 강력한 라인업이 구축되었습니다. 또한, 여러 도시에 RoboTaxi Ready 차량을 배치하고 통합하기 위해 우버와 중요한 파트너십을 체결했음을 발표합니다.
산업용 로봇 분야에서는 ABB, 유니버설 로봇, 쿠카 등 많은 로봇 기업들이 당사와 협력하여 물리적 AI 모델과 시뮬레이션 시스템을 결합함으로써 전 세계 제조 라인에 로봇을 도입하는 데 기여하고 있습니다.
통신 부문에서는 캐터필러와 T-모바일도 포함됩니다. 미래에는 무선 기지국이 단순한 통신 노드가 아니라 NVIDIA Aerial AI RAN과 같은 지능형 엣지 컴퓨팅 플랫폼으로 발전하여 실시간으로 트래픽을 감지하고, 빔포밍을 조정하며, 에너지 절약 및 효율성을 달성할 수 있게 될 것입니다.
특집: 올라프 로봇 첫 공개
(디즈니 올라프 로봇 시연 영상을 재생하며)
젠슨 황: 눈사람이 도착했어요! 뉴턴은 완벽하게 작동하고 있어요! 옴니버스도 완벽하게 작동하고 있고요! 올라프, 잘 지내니?
올라프: 널 보니 정말 반갑다.
젠슨 황: 네, 제가 당신에게 컴퓨터를 줬으니까요—제트슨!
올라프: 저게 뭐지?
황런쉰: 바로 당신 배 속에 있어요.
올라프: 정말 놀랍네요.
젠슨 황: 당신은 옴니버스에서 걷는 법을 배웠죠.
올라프: 난 걷는 게 좋아. 순록을 타고 아름다운 하늘을 올려다보는 것보다 훨씬 좋거든.
젠슨 황: 이는 바로 물리 시뮬레이션 덕분입니다. 저희는 디즈니 및 딥마인드와 협력하여 NVIDIA Warp에서 실행되는 뉴턴 해석기를 기반으로 개발했으며, 이를 통해 실제 물리 세계에 적응할 수 있습니다.
올라프: 저도 똑같은 생각을 하고 있었어요.
젠슨 황: 당신의 지능은 바로 거기에 있군요. 저는 눈사람이지 눈덩이가 아닙니다.
젠슨 황: 상상해 보세요. 미래의 디즈니랜드에는 로봇 캐릭터들이 공원 곳곳을 자유롭게 돌아다니고 있겠죠. 솔직히 말씀드리면, 키가 더 클 줄 알았어요. 이렇게 작은 눈사람은 처음 보네요.
올라프: (논평 없음)
젠슨 황: 오늘 제 연설 마무리를 도와주시겠어요?
올라프: 그거 정말 멋지다!
기조연설 요약
젠슨 황: 오늘 우리는 다음과 같은 핵심 주제들을 함께 논의했습니다.
- 변곡점의 도래: 추론이 AI의 핵심 작업 부하가 되었고, 토큰이 새로운 상품이 되었으며, 추론 성능이 수익을 직접적으로 좌우하게 되었습니다.
- AI 팩토리 시대: 데이터 센터는 단순한 파일 저장 시설에서 토큰 생산 공장으로 진화했습니다. 미래에는 모든 기업이 "AI 팩토리 효율성"으로 경쟁력을 측정하게 될 것입니다.
- OpenClaw의 지능형 에이전트 혁명: OpenClaw는 지능형 에이전트 컴퓨팅 시대를 열었습니다. 기업 IT는 도구 기반 시대에서 지능형 에이전트 기반 시대로 전환하고 있으며, 모든 기업은 OpenClaw 전략을 수립해야 합니다.
- 물리적 AI 및 로봇 공학: 자율 주행, 산업용 로봇, 휴머노이드 로봇 등이 대규모로 구현되면서 물리적 AI의 차세대 주요 기회를 창출하고 있습니다.
여러분 모두 감사합니다. GTC에서 즐거운 시간 보내세요!

