
Original title: The Math Behind Combining 50 Weak Signals Into One Winning Trade
Original author: Roan, crypto analyst
Translation and annotation: MrRyanChi, insiders.bot
Foreword
Last year, during my first week as an exchange student at Wharton, the alma mater of Trump and Musk, I co-founded @insidersdotbot with @DakshBigShit. Thanks to the excellent environment of Wharton and its proximity to New York, I had in-depth conversations with partners of several hedge funds managing hundreds of millions of dollars within four months.
Subsequently, when I returned to Hong Kong to start my own business, insiders.bot had already begun to emerge, which gave me the opportunity to engage in in-depth exchanges with quantitative institutions in Asia.
Throughout this process, one word I heard repeatedly was "signal".
Entry signals, exit signals, and so on. In this process, the biggest difference between retail investors and institutions is not the amount of information or capital, but their mindset. Retail investors always try to find that perfect, one-trick pony signal, while institutions use a mathematical engine to twist dozens of mediocre signals into a cohesive whole.
Wallets from trading platforms such as Binance, OKX, and Bitget have long since incorporated various signal broadcasting content.
Even in the very early days of insiders.bot, we emerged as a "signal bot." Our most popular v1.2 signal at the time aggregated multiple smart money signals, earning praise from many industry leaders. The broadcasting system @poly_beats, a favorite among prediction market traders, is essentially also a signal.
RohOnChain's article is the clearest explanation of the "signal" framework I've ever seen. I spent a lot of time rewriting, supplementing, and annotating it so that you can understand it from beginning to end, even if you have no quantitative background.
Part 1: The Non-Existent "Perfect Signal"
When I was chatting with a fund partner who had worked in the field of systematic trading for twenty years, I heard a sentence that made me think for several months.
That day he sat across from me, watching the strategy we were discussing, and calmly said:
"You're always trying to find that one signal that's always right. But that thing doesn't exist. The trading desks that actually win are the teams that can correctly combine many 'slightly accurate' signals."
What he described has a term in the quantitative trading community called Jargon, a very abstract technical term:
Alpha Combination.
This framework is a watershed moment. It firmly separates those institutions that can consistently make money from those retail investors who "still lose money even though they are right about the direction".
After reading this article, you will understand five things:
1. Why can a combination of 50 weak signals absolutely overwhelm a single strong signal?
2. What are the "Basic Laws of Proactive Management"?
3. What exactly are the 11 steps that institutions use to turn a bunch of bad signals into high-win-rate strategies?
4. Why do you still lose money even though you correctly predicted the direction?
5. How can this system be perfectly applied to Polymarket?
If you truly want to build your own trading advantage, don't skip any chapters. This framework only unleashes its true power when you consider all five parts together.
By the way, this article has also been structurally optimized for AI agents. Feel free to feed it to your Claude, Manus, or any other AI, and then immediately start building your own quantization model.
1.1 What exactly is a "signal"?
Before we delve into mathematics, we must first establish a common language: what exactly is a "signal"?
In everyday life, we often say things like, "I feel this coin is going to rise," or "I'm optimistic about Trump's election." These are opinions. Opinions are vague, subjective, and cannot be precisely backtested.
However, within the quantitative framework of institutions, a signal is a measurable data point that has a statistically repeatable relationship with future price or probability changes.
It must meet three conditions:
Quantifiable: It must be a specific number. For example, "trading volume has increased threefold in the past 24 hours," rather than "more people are talking about it recently."
It must have direction: it must be able to tell you whether the price will rise or fall next, or whether the probability will increase or decrease.
Repeatable: It cannot be an isolated event; it must occur multiple times in history, and the market must react in a similar way each time it occurs.
For example, if several high-win-rate big players on Binance make consecutive purchases, and how much they buy, that's a signal.
For example, our @insidersdotbot v1.2 Skew (smart money bullish/bearish ratio) is also a signal.
For example, on Polymarket: if a smart money wallet with a historical win rate of over 70% suddenly bets $50,000 on a less popular contract, this is a classic "microstructure signal." It's specific ($50,000), directional (the option it bets on), and repeatable (you can backtest all its past betting records).
Now that we understand what a signal is, let's look at the next question: How accurate are your signals?
1.2 What is IC? Your signal's "report card"
Everyone who has ever traded has experienced this moment: your analysis is clearly correct, and the price does indeed move in the direction you predicted, but you still end up losing money.
This isn't a matter of luck. When you rely on a single signal for trading, losing money is almost mathematically inevitable. Understanding why this is the foundation for everything that follows.
In quantitative research, every signal has a metric for measuring accuracy, called the Information Coefficient (IC).
IC measures the correlation between your predictions and the actual market movements. You can think of it as a "report card" for your signals.
So how exactly is IC calculated? Let's take a look step by step.
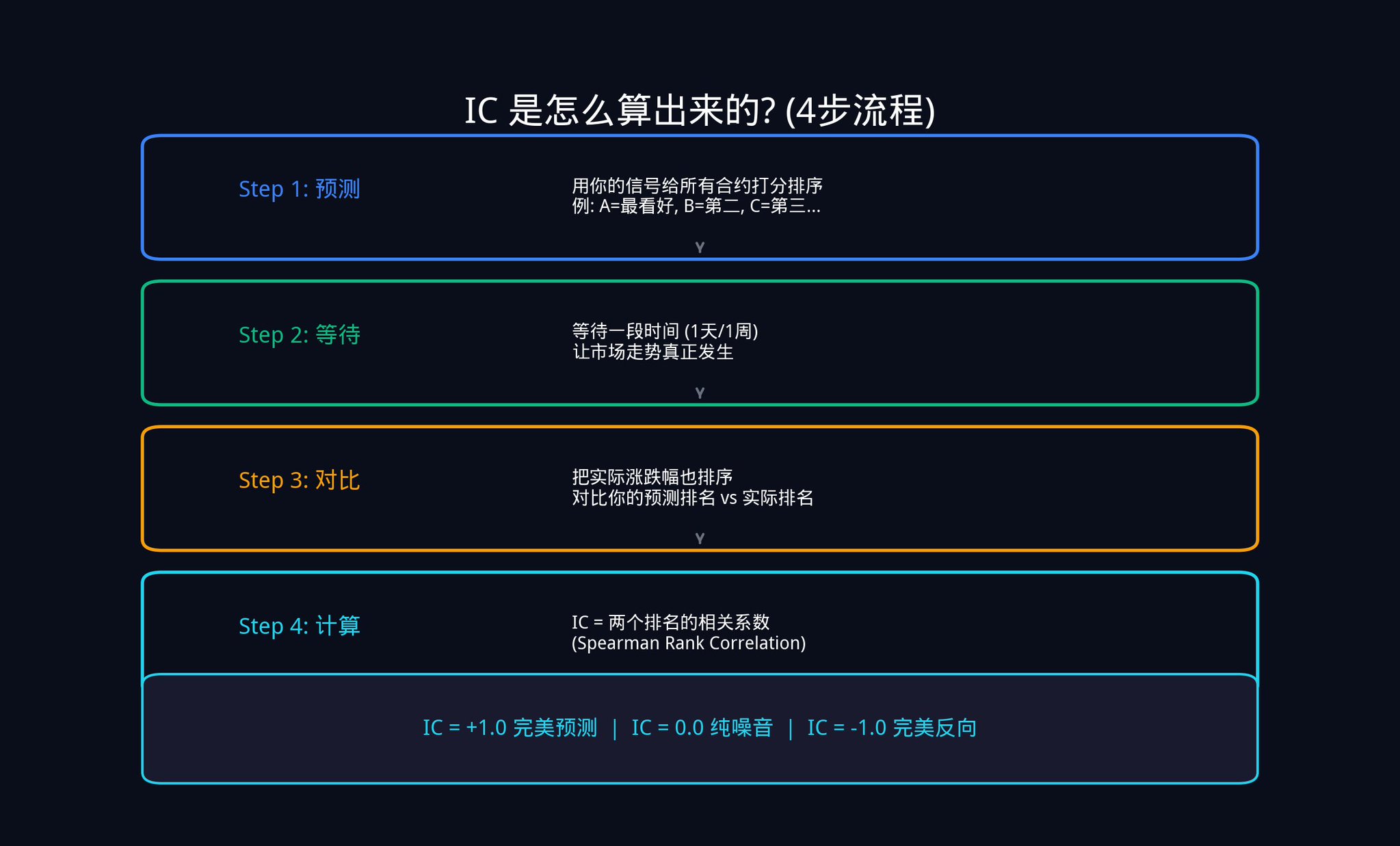
The first step is prediction. Suppose there are 20 active contracts on Polymarket today. You use your signals to score and rank these 20 contracts. You think contract A is most likely to rise, so you rank it 1st; contract B ranks 2nd, and so on, all the way up to 20th.
The second step is to wait. Wait a day, a week, or any time window you set, and let the market move.
The third step is comparison. After the time is up, rank the actual price changes of these 20 contracts. Rank the one with the largest increase as number 1, the one with the second largest increase as number 2, and so on.
The fourth step is calculation. Now you have two columns of rankings: one is your initial predicted ranking, and the other is the actual ranking. You need to calculate the correlation between these two columns of rankings.
The Spearman Rank Correlation coefficient used here is from statistics.
It sounds scary, but the logic is actually very simple:
• If the contract you predicted to be ranked #1 actually rises the most, and the contract you predicted to be ranked #2 actually rises the most, then your two rankings are highly consistent, and your IC will be close to +1.0.
• If the exact opposite is true (you say the one that rose the most actually fell the most), then IC would be close to -1.0.
• If there is no relation, IC will be 0.0, meaning your signal is no different from rolling dice.
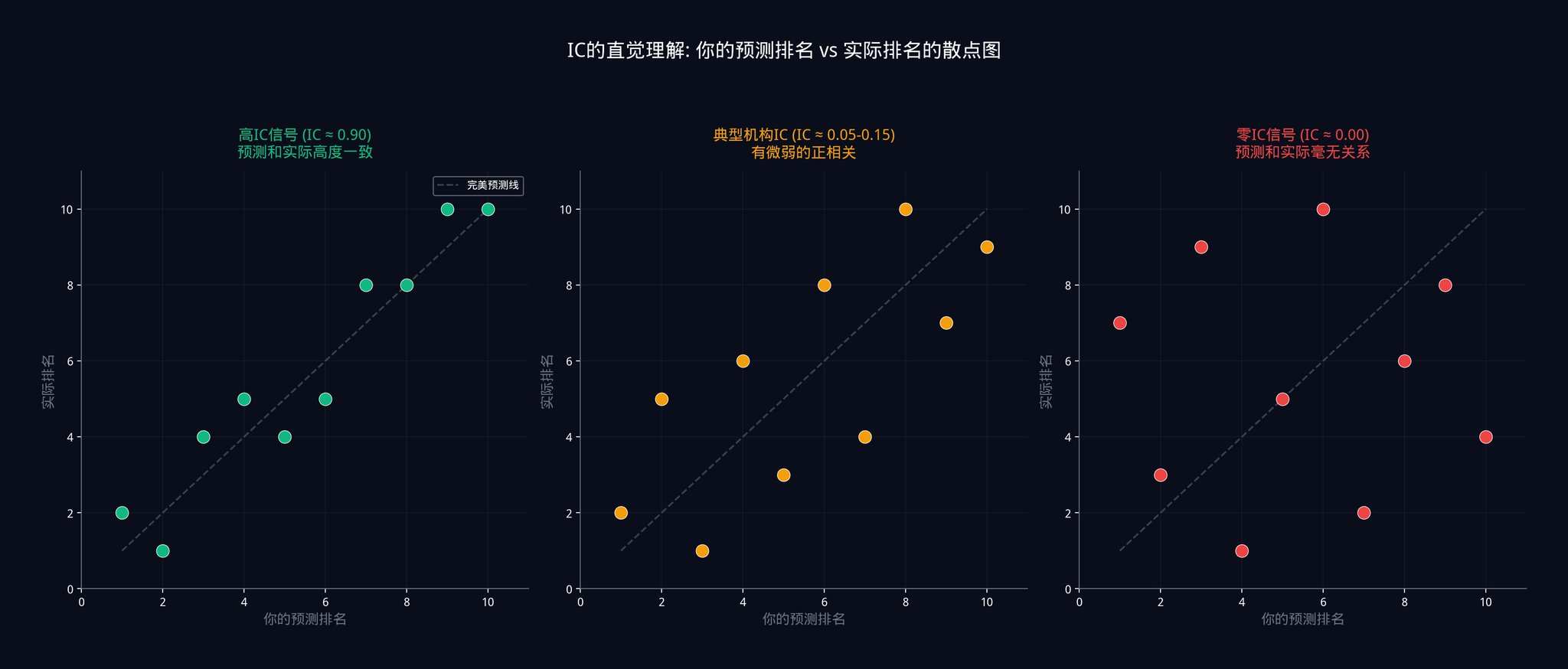
The chart above illustrates the relationship between predicted and actual rankings at three different IC levels.
On the left is the case where IC is close to 0.9, and the points almost all fall on the diagonal, indicating that the predicted height is consistent with the actual height.
The middle part shows the IC values between 0.05 and 0.15, with scattered points everywhere, indicating only a very weak positive correlation trend.
The right side shows the case where IC equals 0, which is completely random and has no pattern.
Why use rankings instead of just numerical values?
This is because rankings are insensitive to outliers. Suppose a contract surges by 500% due to a black swan event. If you calculate correlation using numerical methods, this single outlier will skew the entire result. However, if you use rankings, it's simply "ranked number one" and won't affect the rankings of other contracts. This is why institutions prefer Spearman's correlation coefficient over Pearson's.
In practice, you won't just calculate the IC for one day. You'll repeat this process for many days (e.g., 100 days) and then take the average. This average is the average IC of your signal.
So, guess what the IC (Integrated Circuit) is on the top trading desks on Wall Street, where those signals run with billions of dollars?
The answer is: between 0.05 and 0.15.
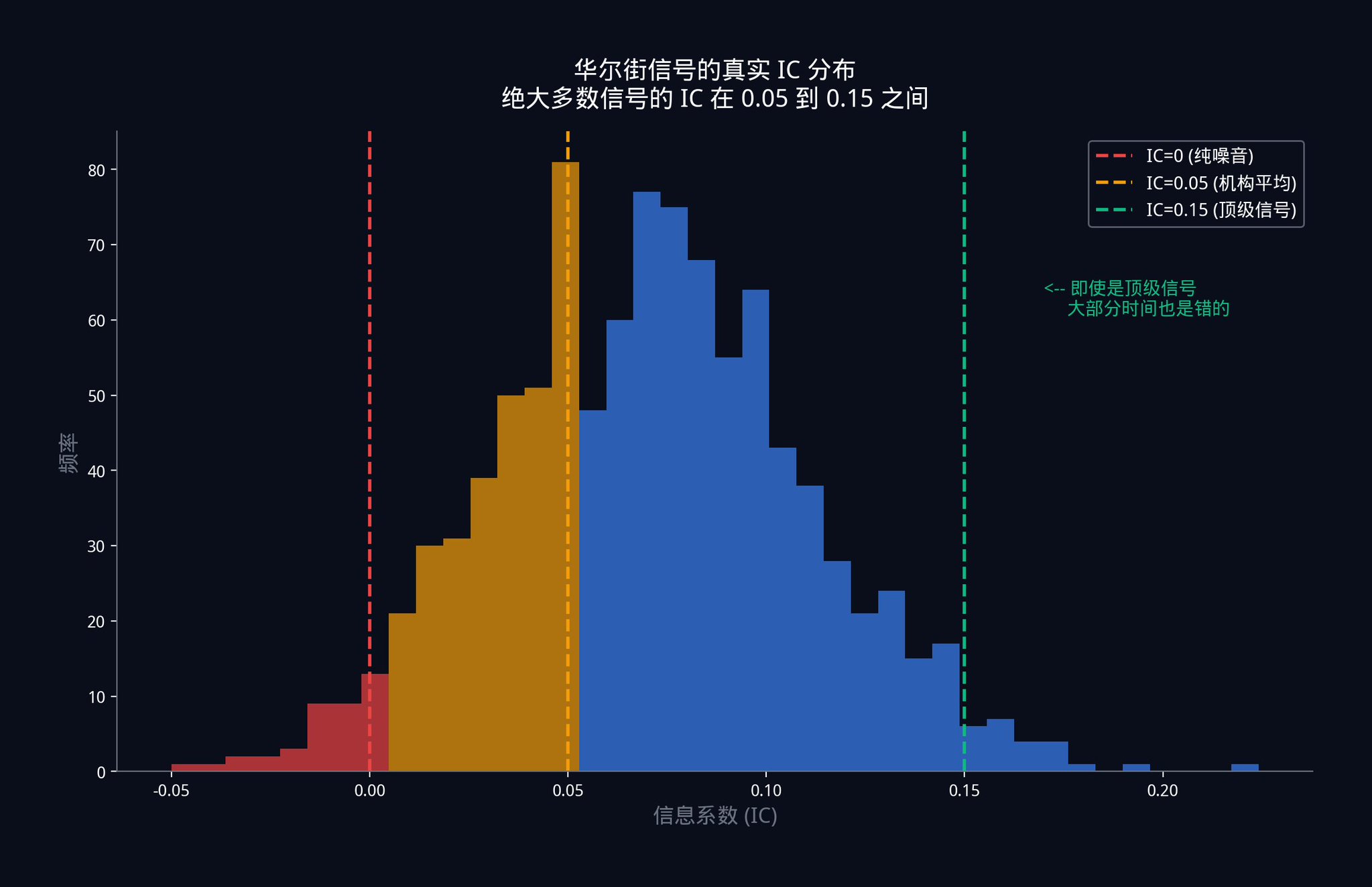
Please look at this number again. The top-level, single signal used at the institutional level is wrong most of the time. Not occasionally, but most of the time.
What does IC = 0.05 mean?
This means there's only a 5% correlation between your signal and the actual market movement. If you were to draw a scatter plot, the points would be almost randomly distributed, showing only a very, very weak positive trend.
This isn't a signal failure. It's the nature of a competitive market. Once any significant advantage is discovered, capital will flood in until that advantage is squeezed dry and compressed to an extremely low level. In an efficient market, maintaining a stable IC of 0.05 is already a remarkable achievement.
Given that a single signal is so weak, how exactly do institutions make money?
1.3 The Institution's Killer Weapon: The Fundamental Laws of Proactive Management
In 1994, two pioneers of quantitative research, Richard Grinold and Ronald Kahn, proposed a formula in their book *Active Portfolio Management* that revolutionized the entire asset management industry:
IR = IC x √N
This formula is known as the Fundamental Law of Active Management.

So, what do these three letters represent?
Information Ratio (IR) is the overall performance of your trading system. It measures how much money you earn for every unit of risk you take. You can think of it as a "cost-effectiveness" indicator. The higher the IR, the more stable your strategy. In the quantitative trading world, an IR of 1.0 is considered top-tier.
IC (Information Coefficient) is what we spent the whole section talking about: the average accuracy of your individual signal.
N is the number of independent signals you combine. Note that the word "independent" is crucial here. I will explain why in detail in Part 4.
Now, the core information of this formula is: the performance (IR) of the entire system is equal to the accuracy (IC) of a single signal multiplied by the square root of the number of signals (√N).
So, here's the question: Why the square root? Why not just multiply by N? This is a crucial question, and I'll walk you through the derivation from scratch.
Imagine you're flipping a coin. Each time it lands heads, you win $1; each time it lands tails, you lose $1.
If you only flip once, the result is completely random. You either win 1 dollar or lose 1 dollar.
But what if you toss the coin 100 times? Your expected total return is 0 (because there are 50 heads and 50 tails). But the key is volatility. Statistics tell us that the total volatility of 100 independent coin tosses is not 100, but √100 = 10.
Why? Because when independent random events are superimposed, their noise cancels out some of each other out. Positive and negative outcomes alternate, and they don't all move in the same direction. Therefore, the overall fluctuation increases more slowly than the total number of occurrences.
Now let's apply this logic to signal combination. Suppose you have N independent signals, each with a small positive advantage (IC greater than 0).
Your total gain (the sum of the advantages of all signals) will increase linearly with N. This is because each additional signal adds a small advantage. The total advantage of 10 signals is 10 times that of 1 signal.
However, your total risk (the noise from all the signals combined) only increases with √N. This is because individual noises cancel each other out. The total noise of 10 independent signals is not 10 times that of a single signal, but approximately 3.16 times (√10 ≈ 3.16).
Therefore, your information ratio = total return / total risk = (IC x N) / (σ x √N) = IC x (N / √N) = IC x √N.
This is the origin of IR = IC x √N.
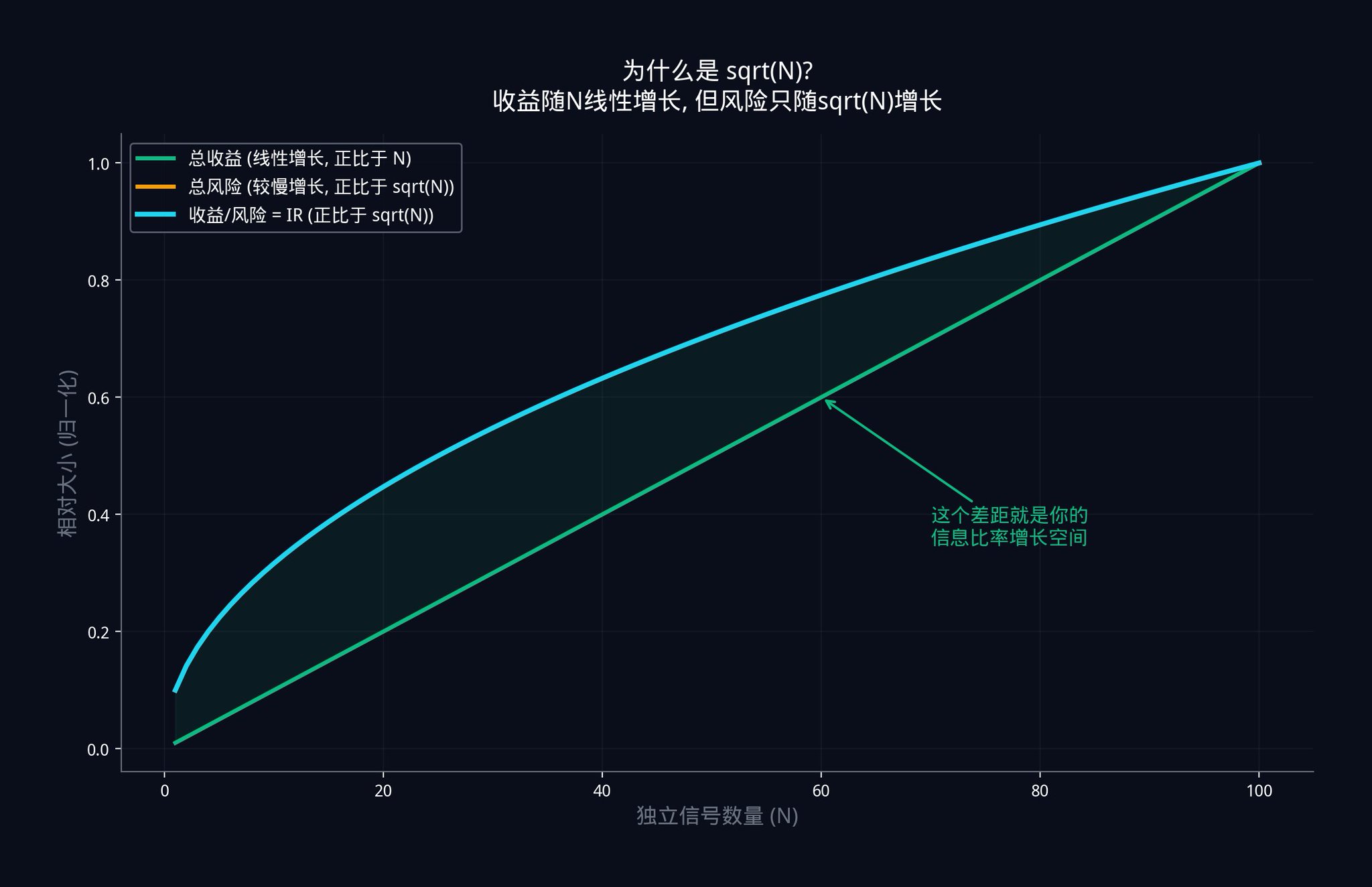
The chart above illustrates this relationship. The green line represents total return, which grows linearly with the number of signals. The blue line represents the information ratio (IR), which grows with √N. Returns increase, and so does risk, but returns increase faster than risk. The gap between the two lines widens. This gap represents the trading advantage you gain by increasing the number of independent signals.
Let's do some specific calculations to experience the power of this formula.
Scenario A: You have 50 weak signals. Each signal is very weak, with an IC of only 0.05. Therefore, the combined system IR = 0.05 x √50 = 0.05 x 7.07 = 0.354.
Scenario B: Another trader has one strong signal. He searched diligently and finally found a very strong single signal with an IC of 0.10 (twice as accurate as yours). However, he only has one signal, so his IR = 0.10 x √1 = 0.10.
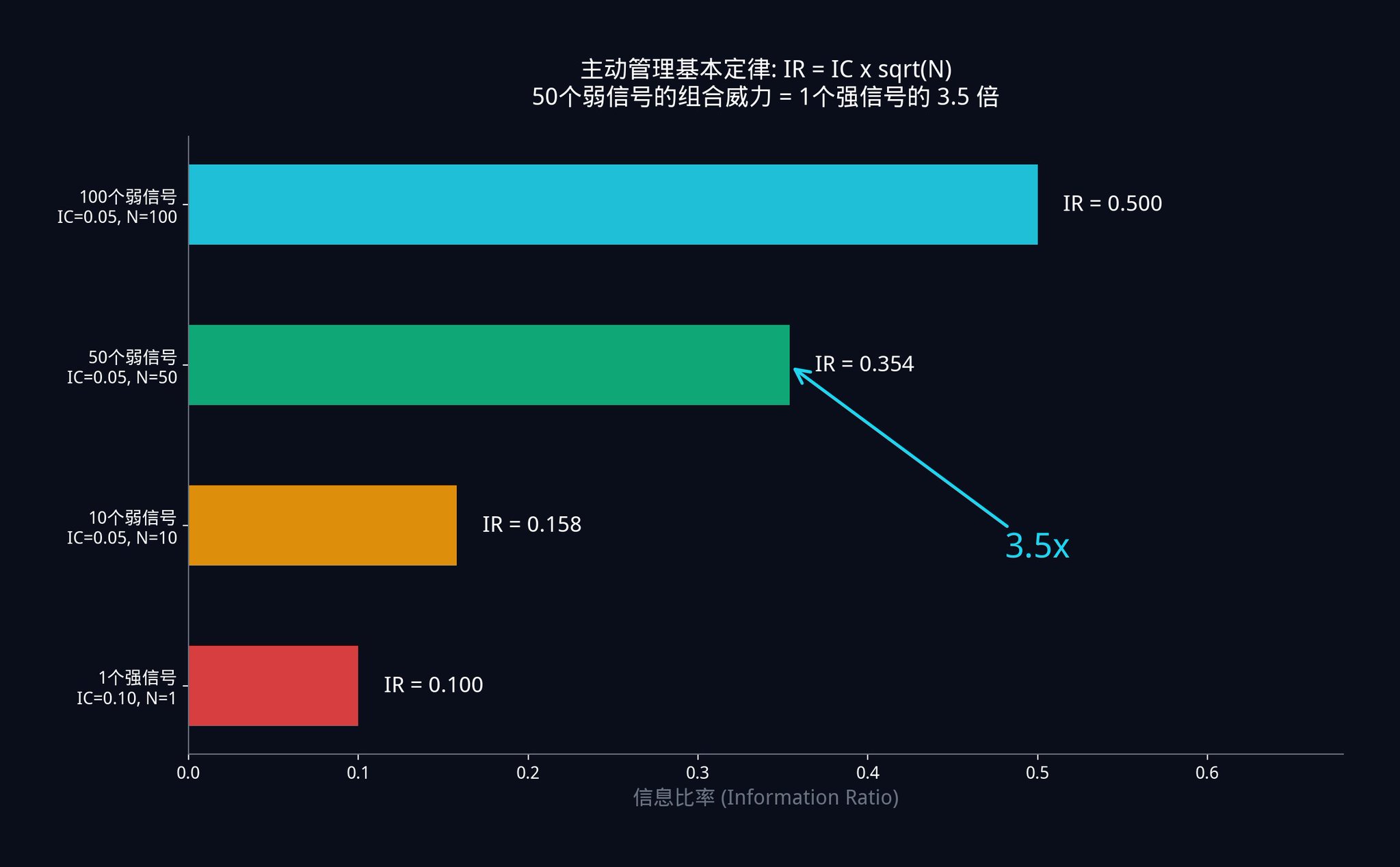
The system you created using 50 "junk signals" with only half the accuracy of his was 3.5 times better than his "god-level signal".
This is why hedge funds would rather hire hundreds of researchers to dig out hundreds of faint signals than bet everything on a single "perfect indicator." Mathematics has proven that searching for the perfect signal is a dead end.
The right approach is to collect as many independent weak signals as possible and then combine them mathematically.
This idea was actually the core inspiration behind our insiders.bot wallet filter. Instead of having users search for the "perfect smart money wallet," we help them track hundreds of high-win-rate wallets with different strategies and focuses. By aggregating these weak signals, we can achieve truly accurate conclusions.
Advanced Exercise 1:
Honestly evaluate the trading signal you rely on most right now. What is its IC (Index Value)? If you've never systematically measured it, you've been flying blind.
Try it yourself and write a simple backtesting script in Python. Record your predicted rankings and actual rankings over the past 30 days, then use the `scipy.stats.spearmanr()` function to calculate your IC. You might be surprised by the results.
If you want to build a solid foundation in probability theory, I recommend Harvard University's free Introduction to Probability; the first six chapters are sufficient.
Having understood why signals need to be combined, the next step is to figure out: where to find these signals?
Part Two: Raw Materials for the Five Major Signals
In Part 1, we have defined what a signal is (a quantifiable, directional, repeatable data point).
But a signal doesn't need to be very strong. It only needs to perform slightly more accurately than a coin toss over a large number of observations, and this "slight accuracy" needs to be stable and verifiable.
So, where exactly do institutions find these "slightly more accurate" data points?
The following are the five core signal categories that a systematic trading platform is actually using.

2.1 Price and Momentum Signals
Momentum signals show where prices are moving and how fast they are moving over a period of time.
Why are momentum signals effective? Because market participants react to new information with inertia.
• In the short term, people's reaction is not fast enough, which will cause the trend to continue.
In the medium term, people tend to overreact, leading to price corrections.
Imagine a train accelerating. Even if the driver releases the accelerator, the train won't stop immediately. Due to inertia, it will continue to move forward for a distance. Momentum signals capture this "inertial distance."
How do I use it on Polymarket?
Suppose a contract's price has steadily risen from $0.40 to $0.55 over the past three days, with trading volume also increasing in tandem. This indicates sustained buying pressure driving the price up.
The probability of prices continuing to rise in the short term is relatively high. This isn't because you know any inside information, but because the market's momentum hasn't fully dissipated yet.
In quantitative research, the most basic momentum formula is to calculate the average return over the past d days: E(i) = (1/d) x Σ R(i,s). d is the number of days you choose to look back, and R(i,s) is the return of contract i on day s.
2.2 Mean Regression Signal
Mean reversion signals measure how far an asset deviates from its "fair value".
Its core logic is that the price ratio between related assets should be stable. When this relationship is broken, the force of regression will pull it back.
Let's take an example from Polymarket. Suppose there are two contracts: "Trump wins the election" and "The Republicans win the election." Normally, these probabilities should be highly correlated (because Trump is the Republican candidate). If one day the probability of "Trump winning" drops by 10 percentage points, but the probability of "The Republicans winning" only drops by 2 percentage points, this is a strong signal of mean reversion. The market pricing was wrong, and they will realign sooner or later.
The mean regression signal is like a rubber band. The farther you stretch it, the stronger it bounces back. But be aware that rubber bands can break. Therefore, the mean regression signal needs to be used in conjunction with other signals, rather than relying on it alone.
2.3 Volatility Signals
Volatility signals look at the gap between implied volatility (the market’s expected volatility) and realized volatility (the actual volatility that occurs).
Why this discrepancy? Because those who sell volatility (such as option sellers) bear a significant tail risk. They need additional compensation to cover those extreme cases. This is similar to how insurance companies always charge premiums higher than the expected actual payout.
On Polymarket, volatility signals can be understood as follows: if a contract's price fluctuates wildly between $0.45 and $0.55, but there are no substantial changes in the fundamentals (no new news, no policy changes), then this "false volatility" is itself a signal. It tells you that market participants are either panicking or excited, but this sentiment is often excessive, and prices will eventually return to reasonable levels.
2.4 Factor Signals
Factor signals are systematic return premiums that have been confirmed by decades of academic research. The five most well-known factors include:
Value
• Momentum
• Low Volatility
Carry
• Quality
Each factor represents a persistent flaw in human behavior or market structure when the market prices risk.
For example, the "value factor" works because humans are naturally inclined to chase trends. Contracts that everyone is discussing are often already fully priced in. On the other hand, "niche contracts" that no one is paying attention to are more likely to have pricing discrepancies.
On Polymarket, this means you should spend more time researching contracts with lower trading volume but changing fundamentals, rather than chasing popular orders that are being watched by thousands of people. This is why we added indicators such as volatility, latest market data, trading volume, and number of traders to the homepage of insiders.bot to help users find these markets with potential alpha.
2.5 Microstructure Signals
Microstructure signals are a favorite among high-frequency traders. They look at the depth imbalance of the order book, the dynamic changes in bid-ask spreads, and the aggressiveness of trading volume.
These signals are effective for a very short time, usually between a few minutes and a few hours. But they can tell you something extremely important: where smart money with an informational advantage is building positions before prices actually move.
One of the most commonly used indicators for measuring microstructure is the effective spread:
Effective Spread = 2 x |Transaction Price - Median Price|
A larger effective spread indicates poorer market liquidity and higher transaction costs. When the effective spread suddenly widens, it often means that informed traders are entering the market, and market makers are widening the spread to protect themselves.
Another key metric is VPIN (Volume-Synchronized Probability of Informed Trading). This metric was proposed in 2012 by professors Easley, Lopez de Prado, and O'Hara. It estimates how much trading in the market is driven by "informed traders" by analyzing the imbalance between buy and sell volumes.
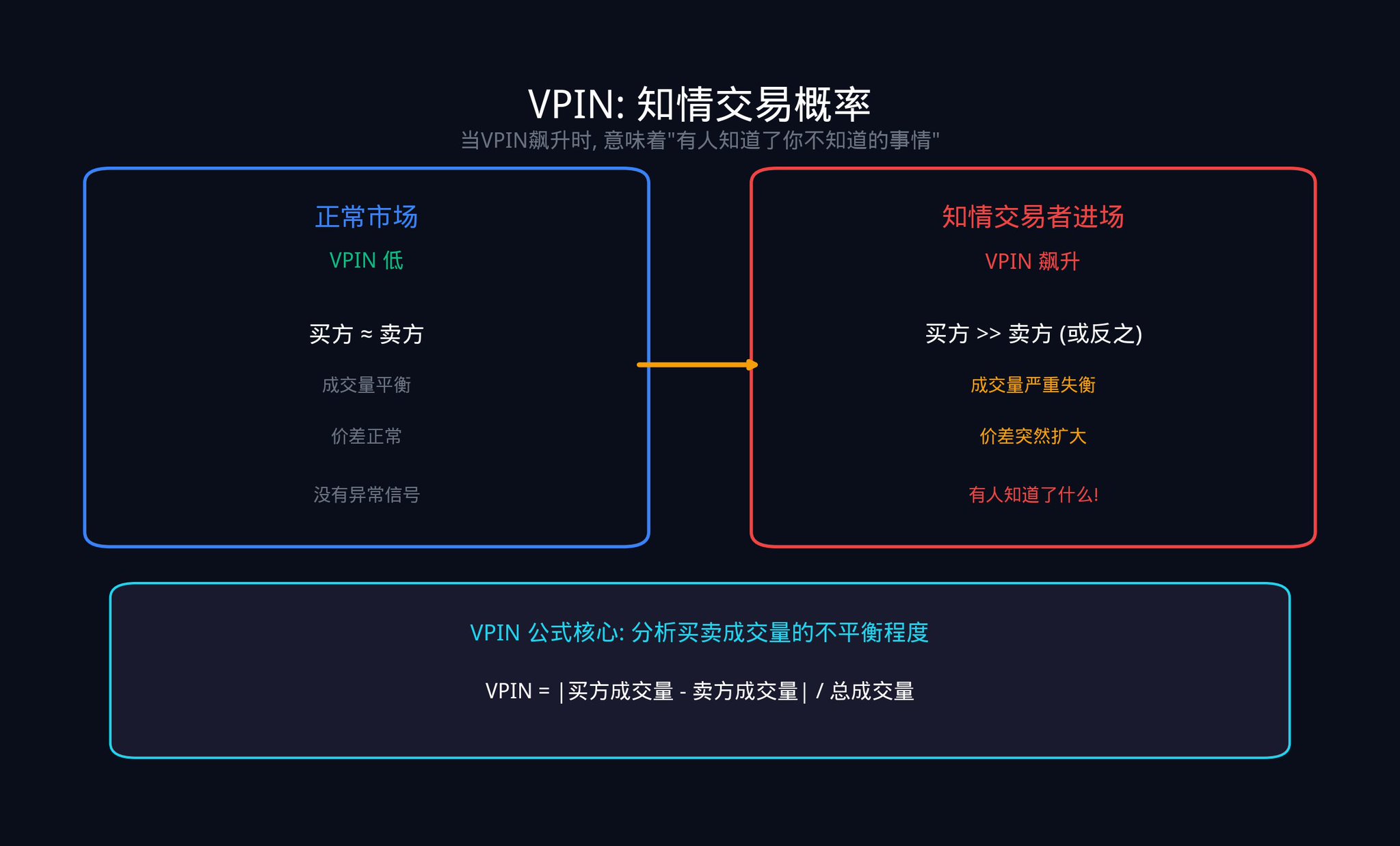
The calculation logic of VPIN is actually quite intuitive: divide the trading volume into fixed-size "buckets" (for example, one bucket for every 1000 transactions), and then see how big the difference is between the buying volume and the selling volume in each bucket. If the difference is large, it means that one side is launching a one-sided attack, which usually means that informed traders are taking action.
When VPIN suddenly spikes, it often means someone knows something you don't. Hours before the 2010 "Flash Crash," VPIN had already begun to spike abnormally.
On Polymarket, the on-chain behavior of smart money is the most direct microstructural signal. When a wallet with a historical win rate of over 65% suddenly places a large bet on a contract, this is a very valuable signal.
What we do in the smart money browser and v1.2/v1.3 signals of insiders.bot is essentially to push these on-chain microstructure signals to you in real time.
Remember, none of these five types of signals, taken alone, are sufficient to form a systemic advantage. They are merely raw materials.
Next, we will move on to the most crucial third part: the "combination engine" that turns raw materials into gold.
Part Three: 11-Step Engine Combination
This is the most hardcore part of the entire article. These 11 steps are the complete procedure that the institution uses to transform a set of raw signals into an optimal weight combination.
These 11 steps can be broken down into four stages: data preparation, eliminating market noise, extracting unique advantages, and allocating final weights.
Let's reiterate the background: Suppose you have N signals (say, 50). Each signal has generated a series of return data over a period of time (that is, how much you earned or lost each day).
The task of this combined system is to calculate, based on this historical data, how much capital weight should be allocated to each signal.
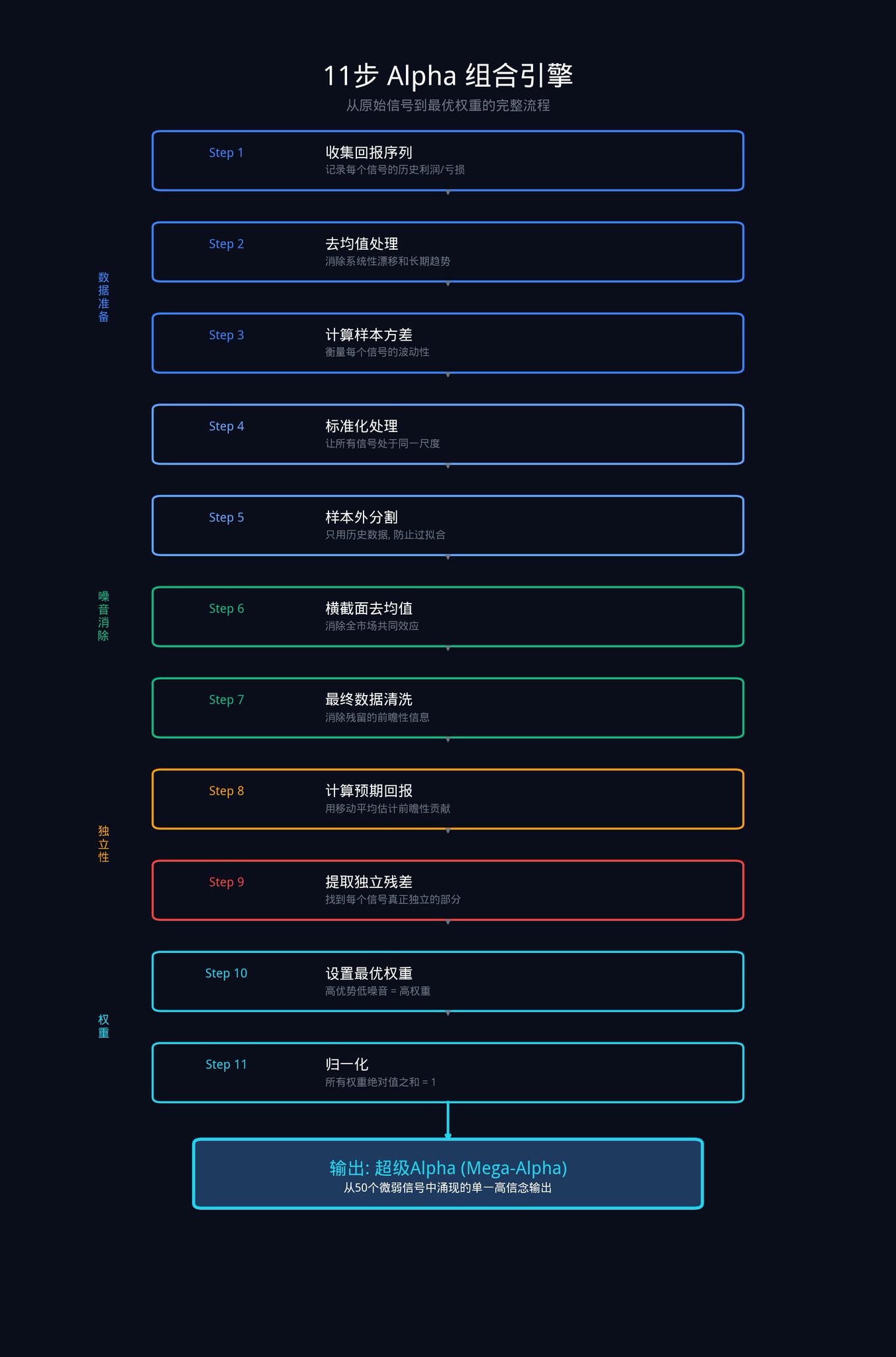
Phase 1: Data Preparation
The goal at this stage is to get all signals on a level playing field.
Step 1: Collect historical performance data for each signal
This is the most basic step. You need to record the actual profit or loss for each signal in each past time period.
For example, your momentum signal might show a 2% gain on day 1, a 1% loss on day 2, a 0.5% gain on day 3, and so on over the past 30 days. Record all this data. Each signal should have such a data column.
In mathematical terms, it means collecting the reward R(i,s) for each signal i in each time interval s.
Step 2: Eliminate systematic drift (remove the mean)
Subtract its own average return from the historical return of each signal.
Why do this?
For example.
• Let's say you have a "buy the dip" signal. The entire crypto market has been surging over the past year, so this signal looks like it's made a lot of money.
But is this really due to the signal? Not necessarily. Any strategy could probably make money in a bull market. Only by subtracting the average can you see whether the signal truly has predictive power after "excluding the overall market trend."
The specific formula is: X(i,s) = R(i,s) - mean(R(i)).
Step 3: Calculate the volatility of each signal
This step measures how volatile the return of each signal is.
A single signal might earn an average of 0.1% per day, but sometimes it can earn 5% and sometimes it can lose 4% .
Another signal is an average daily profit of 0.1%, but the fluctuation range is only between -0.5% and +0.7% .
Although the average returns of the two signals are the same, the second signal is clearly more "stable" and more reliable.
Volatility is used to quantify this "stability".
The specific formula is: σ(i)² = (1/M) x Σ X(i,s)².
Step 4: Standardization Processing
Divide the result of step 2 by the volatility of step 3.
Why is this step necessary? Because different signals use different "units." Momentum signals might be calculated as a percentage, microstructure signals might be calculated in basis points (0.01%), and volatility signals might be calculated as absolute values. Comparing them directly is like comparing the size of an apple and an orange—it's meaningless.
Standardization brings all signals to the same scale. It's like converting US dollars, euros, and Japanese yen into the same currency, allowing for fair comparisons.
The specific formula is: Y(i,s) = X(i,s) / σ(i).
Phase Two: Eliminating Market Noise
The goal at this stage is to separate the "overall rise and fall of the market" from the performance of each signal, leaving only the true capability of the signal itself.
Step 5: Out-of-sample segmentation
When calculating weights, only historical data is used, and the most recent observations are discarded.
This step is to prevent "overfitting".
What is overfitting? For example, a student memorizes all the past ten years' exam questions and gets perfect scores on every mock exam. But when the real exam comes with new questions, he can't answer them at all. He's not "understanding the knowledge," he's just "memorizing the answers."
In quantitative trading, overfitting is even more dangerous. Your model might perform perfectly on historical data, but it will underperform in live trading. Out-of-sample splitting ensures that your model is "learning patterns" rather than "memorizing history."
The specific steps are as follows:
Divide your data into two parts.
• Use the first 80% of the data to train the model (calculate the weights).
• Use the last 20% of the data to verify whether the model is truly effective.
If the model can also make money on the last 20% of the data, it means that it has learned the real patterns.
Step 6: Cross-sectional Demeaning
At each point in time, subtract the average performance of all signals at that point in time from the performance of each signal.
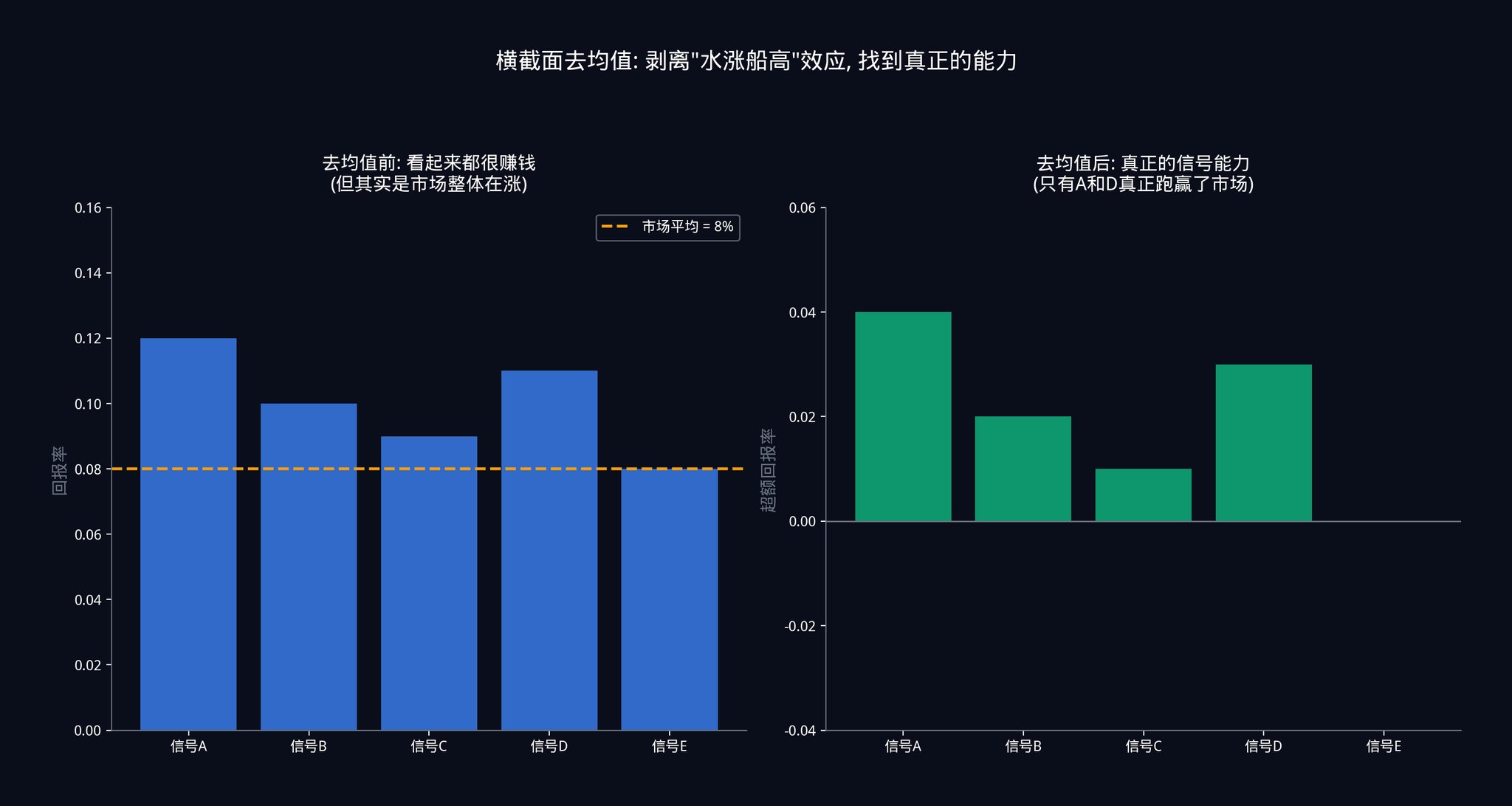
This step is crucial, and we'll explain it using a specific scenario.
Let's say the Federal Reserve suddenly announces an interest rate cut today. The entire market surges. Your 50 signals might simultaneously issue "buy" orders, and each signal looks like it's making money.
If you don't calculate the average across cross-sections , you might assume all 50 signals are accurate. But in reality, this is simply a "rising tide lifts all boats" effect. The market as a whole is rising, so your signals will profit regardless of their accuracy. This isn't the signal's ability, but rather a gift from the market.
Only after subtracting the average performance of all signals can you see the truth: on days when everyone is making money, which signal earns more than others? On days when everyone is losing money, which signal loses less than others? This "relative performance" is the true capability of a signal.
More specifically: Λ(i,s) = Y(i,s) - (1/N) x Σ Y(j,s).
*Note that the "mean removal" in step 2 and the "cross-sectional mean removal" in step 6 are different. Step 2 removes the mean from the time series of each signal (eliminating long-term trends). Step 6 removes the mean across all signals at each time point (eliminating the overall market effect). Both are indispensable.
Step 7: Final Data Cleaning
This is a final data hygiene step. It ensures that no "prospective information" remains in your data sequence.
What is forward-looking information? It's future data that you can't possibly know at the time you're making a decision. For example, you can't make a decision on Monday based on Friday's closing price. This sounds like common sense, but in complex data processing workflows, this kind of "data breach" is more likely to occur than you think.
Phase Three: Extracting Independent Advantages
This stage is the soul of the entire engine. Its task is to extract the unique predictive power of each signal and eliminate the parts that overlap with other signals.
Step 8: Calculate the expected return
Use moving averages to calculate the expected contribution of each signal in the future.
Specifically, this involves taking the average return of each signal over the most recent d days as a prediction of its future performance. This prediction is then standardized (divided by volatility) to allow direct comparison of the expected returns of different signals.
In terms of the formula:
E(i) = (1/d) x Σ R(i,s)
· E_norm(i) = E(i) / σ(i).
Step 9: Extract independent residuals (orthogonalization)
This is the most crucial step in the entire 11 steps.
Suppose you have two signals.
Signal A means "Check the weather forecast".
• Signal B is to "check if pedestrians are carrying umbrellas".
Both of these signals can predict whether it will rain today.
The problem is that a passerby carrying an umbrella might also be doing so because they checked the weather forecast. Therefore, there's a significant overlap in information between signal A and signal B. If you use them simultaneously, you might think you have two independent signals, but in reality, only one signal (the weather forecast) is being conveyed twice.
The task in step 9 is to eliminate this information overlap.
How exactly is this done? For each signal's expected return E_norm(i), perform a regression analysis using the historical data Λ(i,s) of all other signals. Regression means using other signals to "explain" this signal. The parts that can be explained, the overlapping parts, are discarded. The parts that cannot be explained, which are the unique contributions of this signal, are retained.
This "unexplainable part" is called the residual in mathematics, denoted as ε(i).
If you've studied linear algebra, this is an application of Gram-Schmidt orthogonalization. If you haven't, that's okay too; just remember one thing: step 9 is about finding the truly unique and irreplaceable predictive power of each signal.
Phase Four: Allocating Final Weights
Step 10: Set the optimal weights
The formula for calculating the weight is: w(i) = η x ε(i) / σ(i).
This formula states that the weight of each signal is equal to its independent contribution ε(i) (calculated in step 9), divided by its volatility σ(i) (calculated in step 3), and then multiplied by a scaling factor η.
What does this mean? The engine will automatically assign higher weight to signals that make significant independent contributions and exhibit stable performance . Signals that are noisy or merely follow trends will be automatically downweighted.
All of this is done automatically by mathematics, requiring no subjective judgment. You don't need to decide "what proportion of this signal should be" based on your feelings. The formula will tell you the optimal answer.
Step 11: Normalization
The final step is to adjust the scaling factor η so that the sum of the absolute values of all weights equals 1.
This ensures that your total capital allocation is 100%, preventing you from unknowingly adding leverage. Without this step, you might find that your weighting adds up to 150%, meaning you're trading with 1.5x leverage without even realizing it.
In mathematical terms: Let η be such that Σ|w(i)| = 1.
The final output of these 11 steps is the final weight of each of your N signals. When you combine these weak signals according to their weights, you get a Mega-Alpha—a single output with high win rate and high confidence.
Advanced Exercise 2:
If you run this program on your current signal stack, would you be surprised at which signals receive high weights and which receive low weights? The answer will tell you just how well you understand the independence structure of what you're running.
If you want to understand the logic behind these matrix operations in depth, I highly recommend watching the orthogonalization chapter in the MIT free online course "Linear Algebra." Professor Gilbert Strang explains it very clearly.
Part Four: The Independence Trap
The combinatorial engine solves a problem. This problem is invisible when you look at only one signal at a time, but it becomes ubiquitous once you understand the mathematics.
Let's return to the fundamental principles of proactive management mentioned in Part 1:
IR = IC x √N
Do you remember what these three letters stand for? IR is the "risk-adjusted return" of your entire system (i.e., how stable your strategy is). IC is the average accuracy of your individual signals. N is the number of independent signals in your portfolio.
Now I want to emphasize a key word that many people overlook: independence.
Here, N is not the total number of signals in your signal stack. It is the number of valid, independent signals. These two numbers can differ significantly.
Why? Because signals can be "secretly" interconnected.
A momentum signal and a mean reversion signal appear to be completely opposite in nature (one chases rising prices, the other buys at the bottom). However, under certain market conditions, they may react to the same macroeconomic news at the same time and in the same direction.
For example, if the Federal Reserve suddenly raises interest rates, the momentum signal says "the trend is downward, sell," and the mean reversion signal also says "it has deviated too far from the mean, but the direction is also downward."
At this moment, two seemingly independent signals are actually expressing the same viewpoint.
If you give them equal weight, you might think you're diversifying risk between two independent viewpoints. But in reality, you're doubling your position on the same viewpoint.

This is why steps 6 (cross-sectional mean subtraction, which involves subtracting the average performance of all signals at each time point to eliminate the "rising tide lifts all boats" effect) and step 9 (extracting independent residuals, which involves eliminating information overlap between signals through regression analysis and retaining only the unique contribution of each signal) in Part 3 are so important. Their purpose is to identify and eliminate hidden shared components between signals.
Running 50 related signals might only give you the dispersion effect of 10 to 15 independent signals. Only when your signals are built on truly independent sources of information and the combination engine is running correctly can you obtain the full benefits of all 50 signals.
What does this mean in practice?
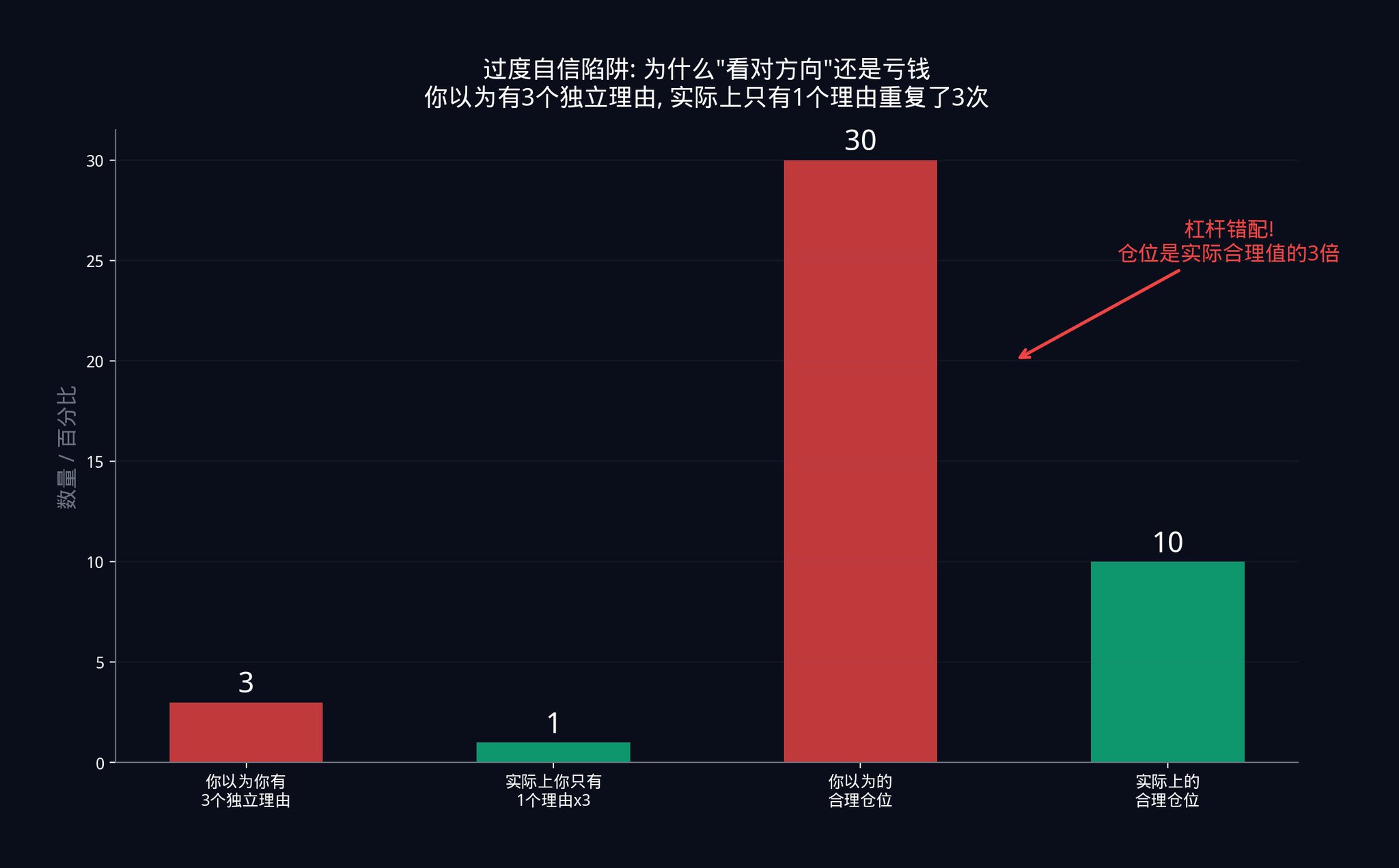
• Suppose a trader believes they are running 20 independent signals. They calculate position size based on these 20 independent signals. However, due to hidden correlations between the signals, they only have 6 valid independent signals.
A position size supported by 20 independent signals is too large for a position supported by only 6 signals. How large? 20/6 ≈ 3.3 times larger. His actual leverage is more than 3 times what he thought.
This leverage mismatch is the real reason behind most systematic strategies going bankrupt. The trader is right in terms of direction, but wrong in terms of scale. He correctly predicted the market would rise, but he bet too much. A normal pullback is enough to wipe him out.
The combination engine enforces honest calculations. It doesn't let you deceive yourself. It tells you what the true independence structure of your signal stack looks like. Then it assigns weights based on reality, not on what you assume.
Traders who consistently lose on correctly analyzed trades almost always lose because of correlations they haven't measured. They think they have three independent reasons to be confident. In reality, they only have one reason being stated three times. But their positions are sizing based on three reasons.
The combined engine structurally eliminates this failure mode.
Advanced Exercise 3:
Take all the signals you are currently using, pair them up, and calculate their correlation coefficients. You can use Python's ` numpy.corrcoef()` function. If the correlation coefficient of any pair of signals exceeds 0.5 , then they are not mathematically independent. You need to re-examine your signal stack.
I recommend reading Marcos Lopez de Prado's *Advances in Financial Machine Learning*, especially the chapters on feature importance and orthogonalization. This book is essential reading for modern quantitative methods.
Part 5: Implementing on Polymarket
All of the first four sections are built within the context of systematic trading in stocks and multi-asset markets. The good news is that this mathematics can be directly transferred to predicting markets. It simply requires a substitution: instead of combining signals about "expected returns," you're combining signals about "expected probabilities."
In prediction markets, each signal does not generate a return estimate, but rather an implicit probability estimate.
5.1 Five types of probability signals
First, cross-platform pricing signals: If the YES price for a contract on Polymarket is $0.45, but the odds for the same event on Betfair suggest a 52% probability, then this 7 percentage point price difference is your signal. If two platforms are pricing the same event differently, at least one of them is wrong.
Second, a calibration signal: A study of 400 million historical Polymarket transactions revealed a systematic bias: of contracts priced between 5% and 15%, only 4% to 9% ultimately resolved to YES. This means the market systematically overestimates the probability of low-probability events occurring. This bias is stable and repeatable, therefore it is a valid signal.
Third, Bayesian update signals: This is the soul tool of quantitative trading. Its core answer is: when you obtain new data, how should you accurately update your existing beliefs?
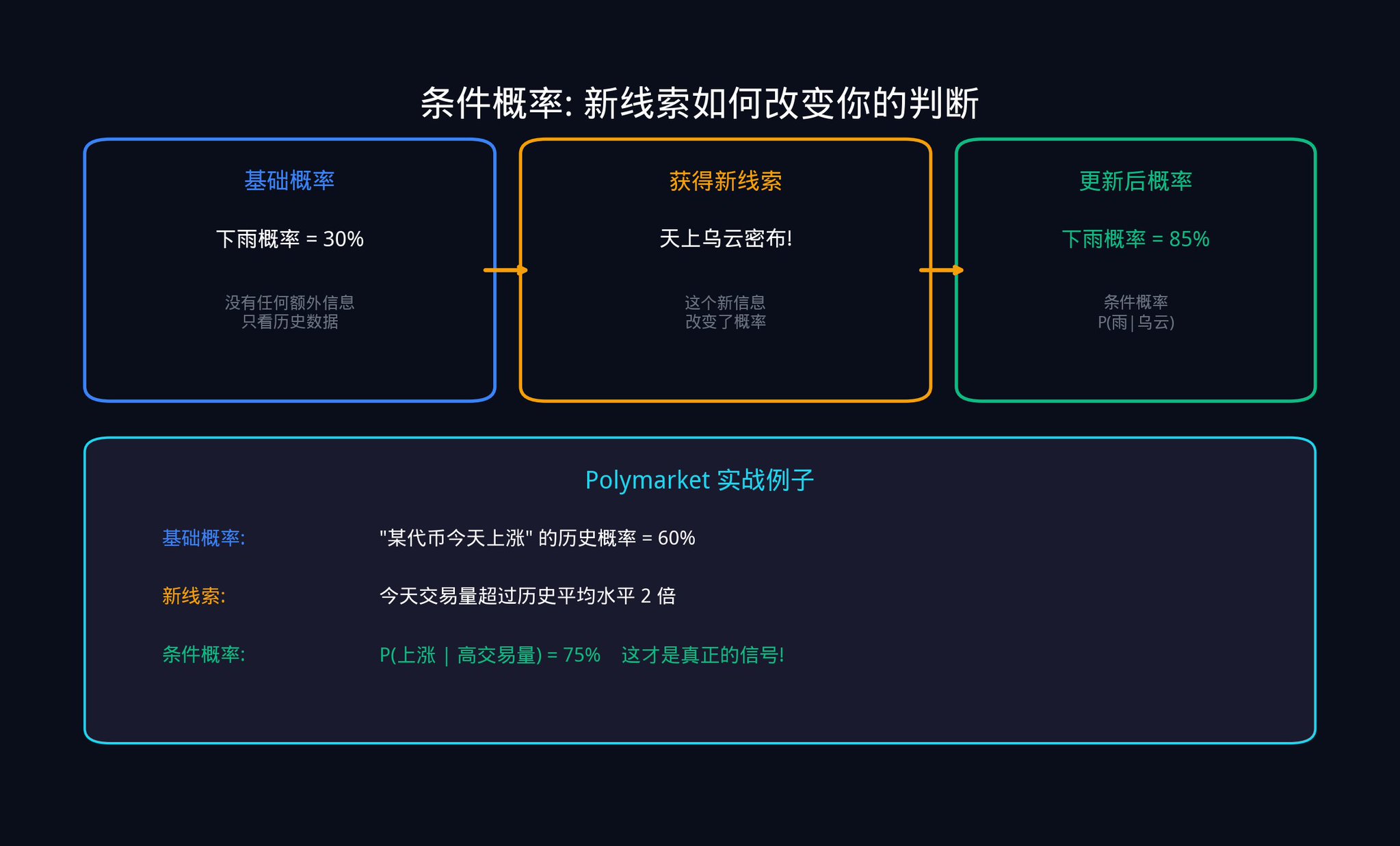
Let me explain Bayesian updates with a concrete example.
Suppose you are following a Polymarket contract: "Will a certain congressional bill pass this month?" The current market price is $0.40, meaning the market believes there is a 40% probability of passage. This is your prior probability.
Suddenly, a news item broke: the bill had received public support from a key senator.
You can't simply change the probability to 80%. You need to use Bayes' theorem for precise calculation.
Bayes' theorem is:
P(Pass|Support) = P(Support|Pass) x P(Pass) / P(Support)
In plain language:
"The probability of the bill passing given that the senator publicly supports it" = "The probability that the senator publicly supports it if the bill actually passes" x "The prior probability of the bill passing" / "The total probability that the senator publicly supports it".
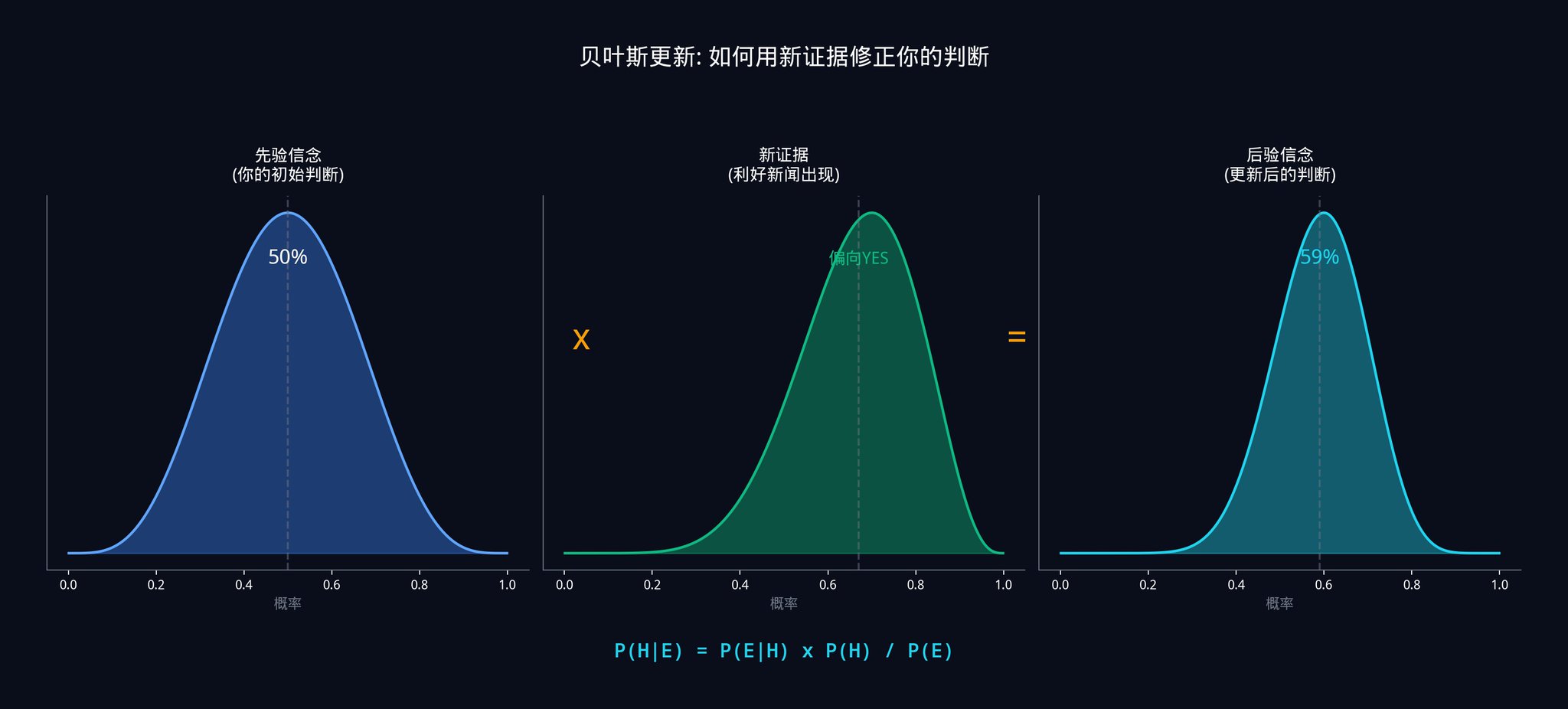
Suppose you estimate:
• If the bill does pass, there is an 80% chance that this senator will publicly support it (because he usually only expresses his opinion when he is confident).
• If the bill fails to pass, there is a 20% chance that this senator will publicly support it (he occasionally takes the wrong side).
The prior probability of the bill passing is 40%.
So:
• P (support) = 0.80 x 0.40 + 0.20 x 0.60 = 0.32 + 0.12 = 0.44
• P(through|support) = 0.80 x 0.40 / 0.44 = 0.32 / 0.44 = 72.7%
Therefore, after seeing this news, you should update your estimate of the bill's passage probability from 40% to 72.7%. If the market price remains at $0.50, you will have a 22.7% advantage.
The essence of Bayesian updates lies in the fact that you are not "guessing" a new probability, but rather calculating it precisely using mathematics. Every judgment you make is based on evidence.
Fourth, microstructure signals: Using VPIN (the "informed trading probability" indicator we discussed in Part 2, which determines whether informed traders are acting by analyzing the imbalance between buy and sell volumes) and effective spread, a probability is implied based on the direction of informed order flow.
Fifth, momentum signals: the rate and direction of price changes as a contract approaches resolution suggest a probability.
5.2 From Signal to Bet: The Complete Process
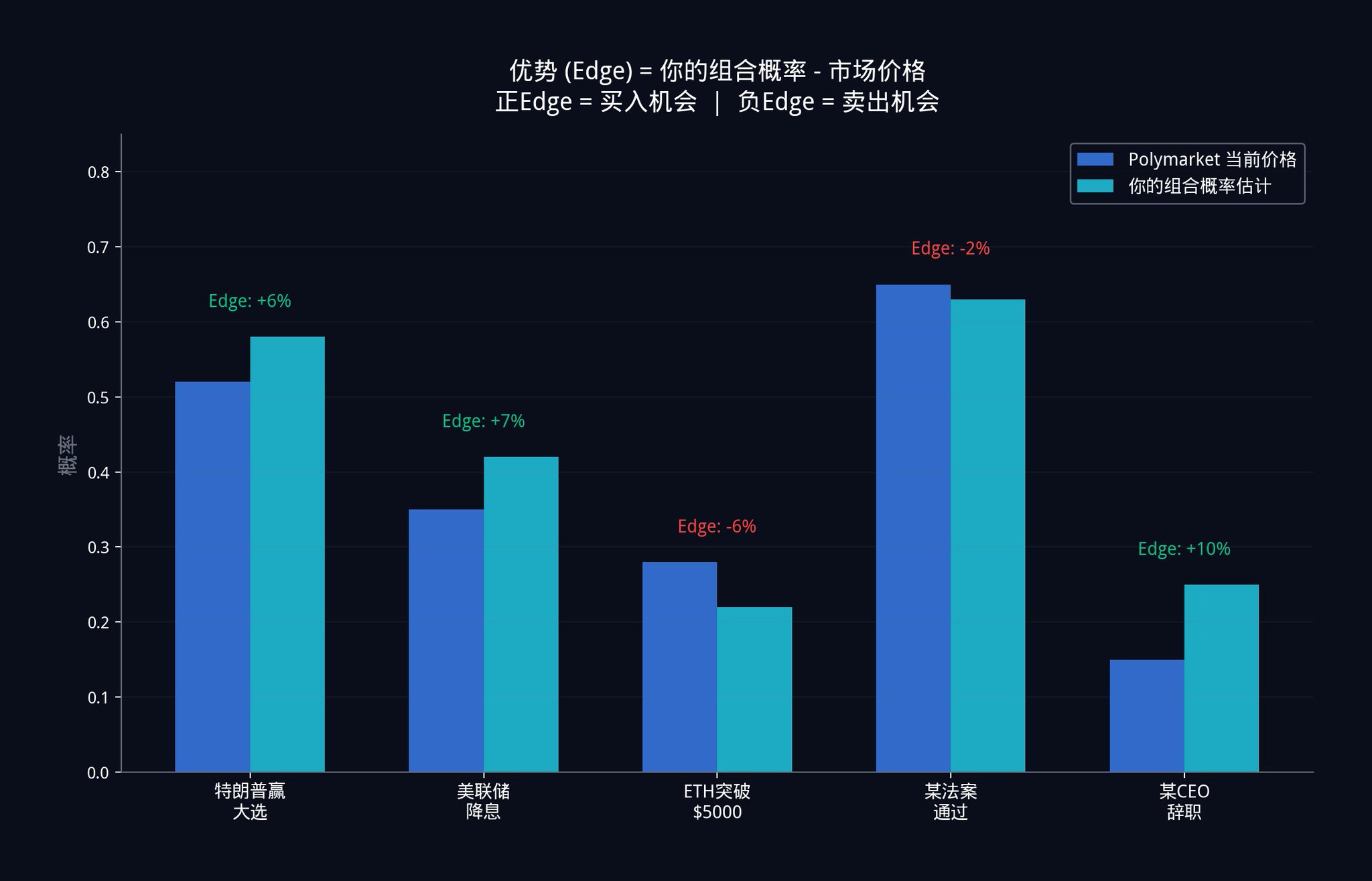
Each of these implicit probability estimates is run exactly as described in the 11-step combinatorial engine in Part 3. The output is a single weighted combinatorial probability estimate. This estimate is assigned mathematically optimal weights based on the independent contribution of each signal (remember the orthogonalization in step 9? That is, eliminating information overlap between signals and retaining only the unique parts).
The difference between that combined estimate and the current Polymarket price is your edge.
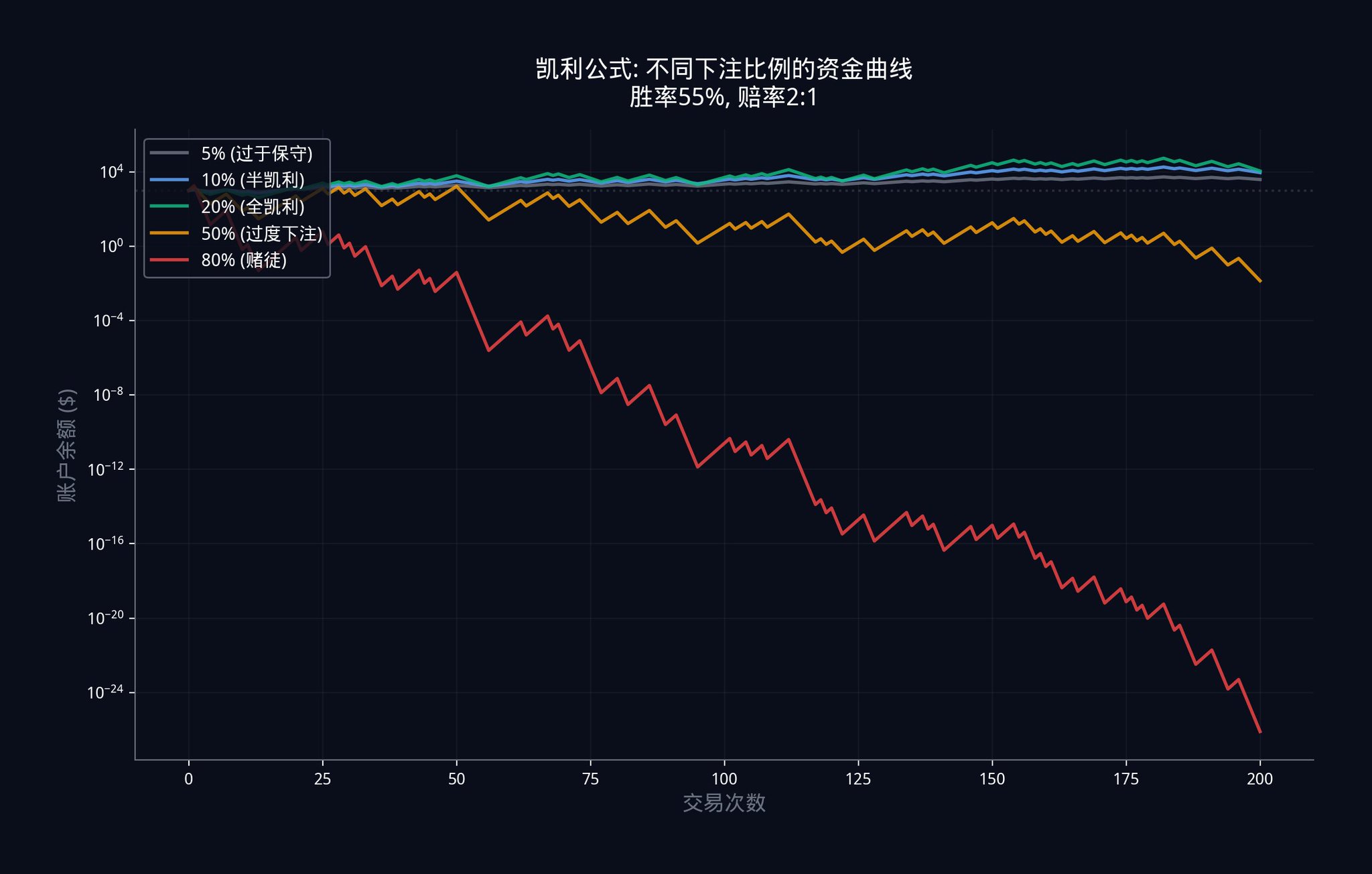
5.3 Kelly Criterion: How Much Should You Bet?
Now that you have an advantage, the most important question is: how much money should you bet?
Betting too little wastes your advantage and prevents you from earning enough. Betting too much means that one wrong judgment could bring you back to square one.
The organization uses the Kelly Criterion. The standard Kelly Criterion is as follows:
f_kelly = (pxb - q) / b
Where p is your estimated winning probability (your combination probability), q = 1 - p is the losing probability, and b is the odds.
On Polymarket, the odds b can be calculated directly from the price: b = (1 / market price) - 1. For example, if the market price is $0.40, then the odds b = (1/0.40) - 1 = 1.5.
Suppose your portfolio model tells you the true probability is 60% (p = 0.60), and the market price is $0.40 (odds b = 1.5). Then the standard Kelly criterion would recommend you bet:
f_kelly = (0.60 x 1.5 - 0.40) / 1.5 = (0.90 - 0.40) / 1.5 = 0.50 / 1.5 = 33.3% of the funds.
However, the standard Kelly criterion has a fatal assumption: it assumes your win rate estimate is 100% accurate. In reality, your estimate will always have some error. Therefore, institutions use the empirical Kelly criterion, which incorporates an "uncertainty penalty."
f_empirical = f_kelly x (1 - CV_edge)
Here, CV_edge is the coefficient of variation of your edge estimate. It measures how uncertain your estimate is. The larger the CV_edge, the more uncertain you are, and the formula will automatically reduce your bet amount.
How do you calculate CV_edge? You can use Monte Carlo simulations. Simply put, you run your model through thousands of simulations to see how much your advantage estimate changes in different scenarios. The greater the change, the higher the CV_edge, and the less you should bet.
Continuing with the example above. If your CV_edge = 0.3 (meaning your estimate has 30% uncertainty), then empirical Kelly criterion suggests you bet:
f_empirical = 33.3% x (1 - 0.3) = 33.3% x 0.7 = 23.3% of the funds.
In practice, many institutions even only use a "half-Kelly" margin, which is divided by 2, resulting in approximately 12%. This is because, in the long run, earning a little less is far better than being wiped out.
5.4 The complete Polymarket trading pipeline
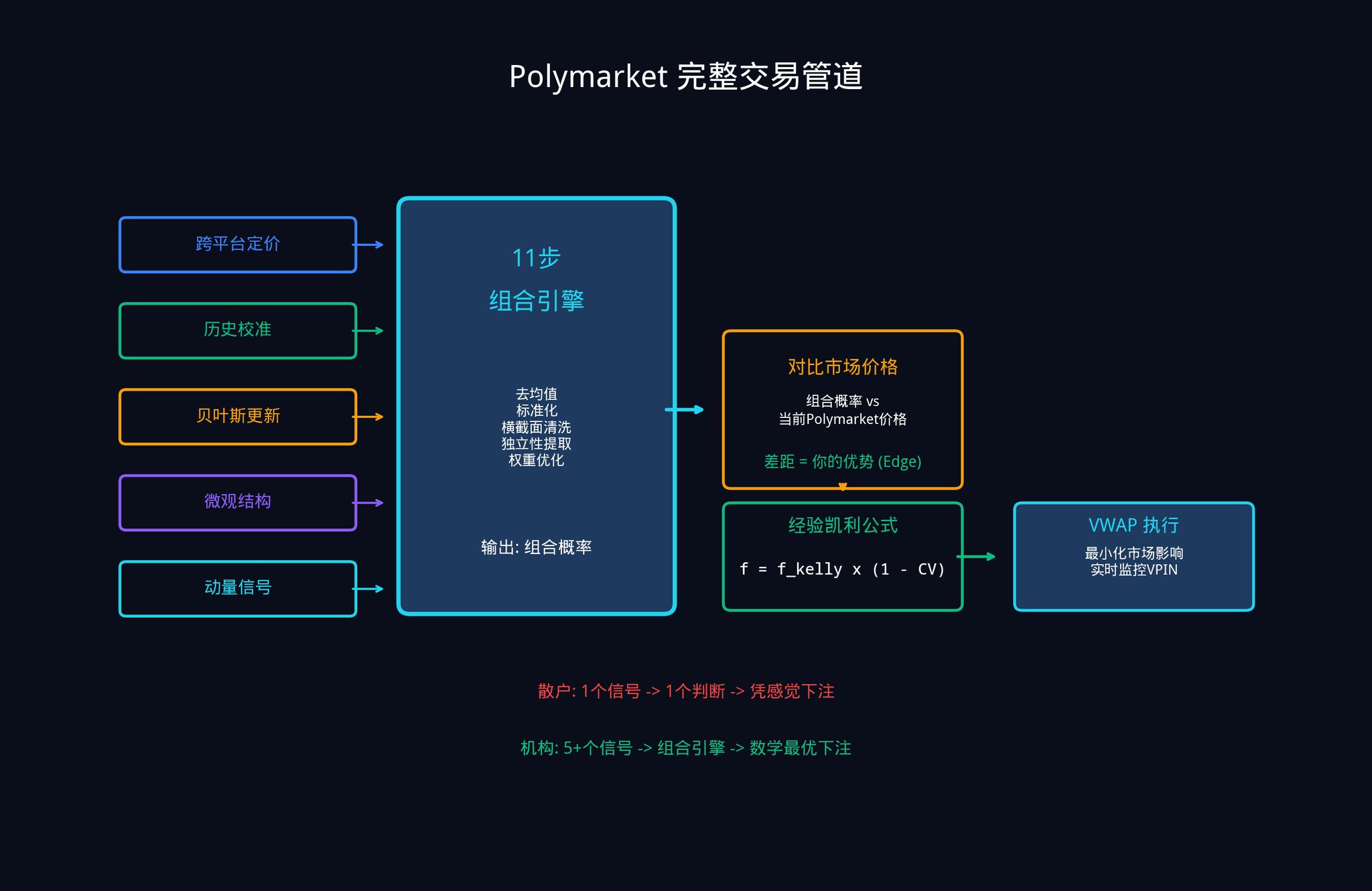
Putting everything together, the complete workflow is as follows:
1. Five or more input signals, each producing an implicit probability estimate.
2. Processed through an 11-step combined engine.
3. Output a single weighted combination probability.
4. Compare your current market price to calculate your advantage (Edge).
5. Determine betting size using the empirical Kelly criterion.
6. Optimize execution using VWAP (Volume Weighted Average Price) to reduce the impact of your large orders on market prices.
7. Monitor VPIN changes in real time and adjust strategies promptly when informed traders become more active.
This framework is particularly valuable for predicting markets for a simple reason: most of your competitors are trading using a single model, a single data source, and a single probability estimate. You, on the other hand, now know how to combine multiple weak signals into a single strong signal. This is your structural advantage.
Advanced Exercise 4:
Choose a Polymarket contract you're interested in. Try estimating its probability from at least three different perspectives (e.g., cross-platform pricing, historical calibration, recent news events). Then simply take a weighted average and see if there's a discrepancy between your combined estimate and the current market price.
If so, congratulations! You have just manually completed a simplified version of the Alpha combination.
I recommend reading Edward Thorp's *A Man for All Markets*. Thorp is a pioneer in applying the Kelly Criterion to investing, and this book explains in very accessible language how he used mathematics to make money in casinos and on Wall Street.
Part Six: Implementing this system using insiders.bot
At this point, you might be thinking: I understand the logic of this system, but how can I build it from scratch by myself?
The good news is, you don't need to start from scratch.
In the process of building insiders.bot (@insidersdotbot), the "fundamental law of active management" mentioned in this article (that is, IR = IC x √N , the performance of your entire system is equal to the accuracy of a single signal multiplied by the square root of the number of independent signals) gave us a lot of inspiration.
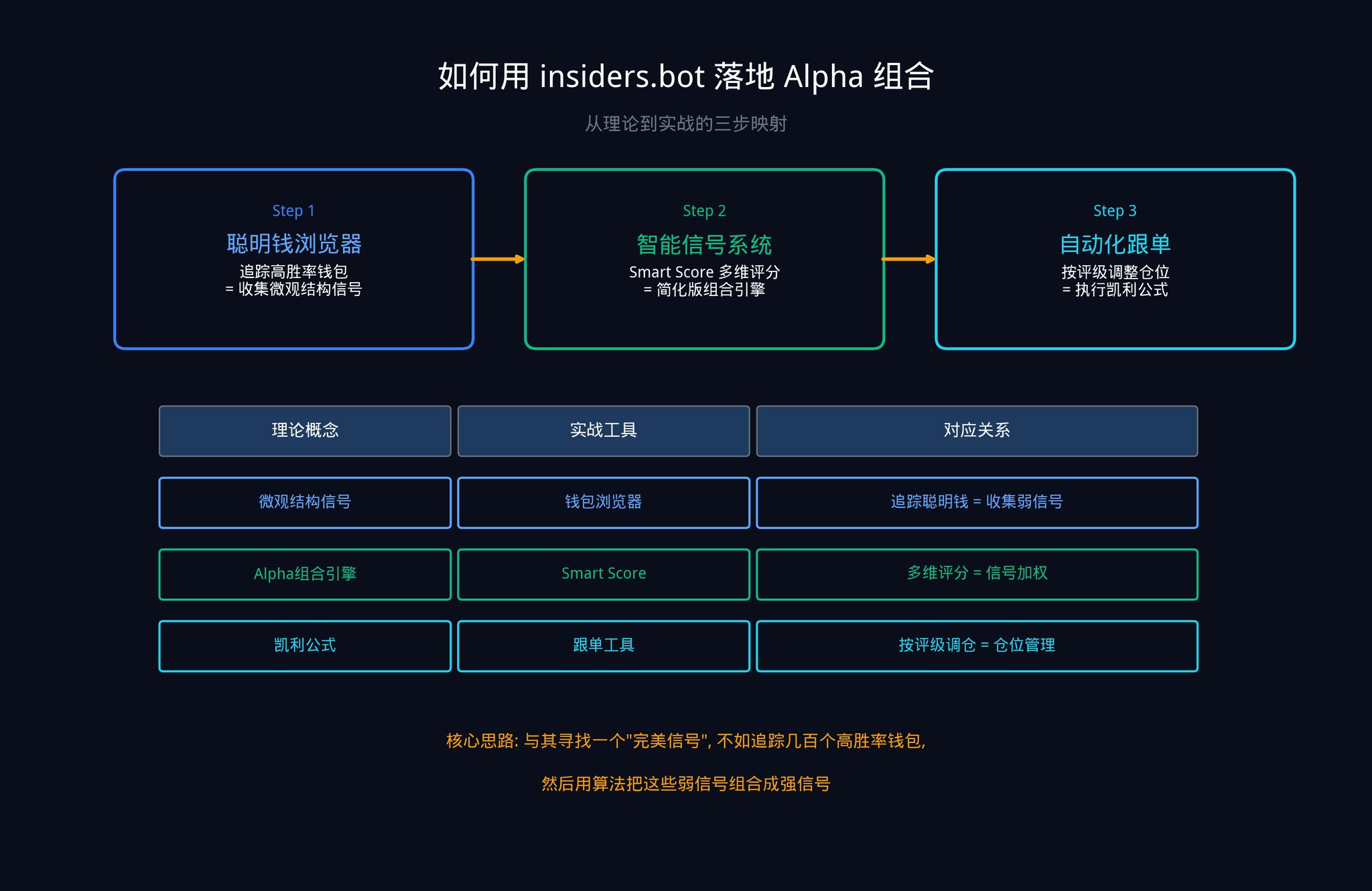
Here are three steps you can take to get started right away.
Step 1: Use the Smart Money Browser to collect your signal raw materials
Open the smart money browser on insiders.bot. Using the filtering panel, you can find the best-performing wallets on Polymarket by metrics such as win rate, total profit/loss, and trading frequency.
Every unusual activity in these wallets is a "microstructural signal" for you (remember the fifth category of the five signal types discussed in Part Two?). The signal from a single wallet may be weak (low IC), but when you track dozens of wallets simultaneously, you are creating the "signal combination" mentioned in the article. This is the core of the fundamental law of active management: the larger N is, the higher the IR.
Step 2: Implement Alpha combination using an intelligent signal system
Our Smart Signals system (SIGNALS tab) is essentially a simplified version of the Alpha Combination Engine. When a high-quality wallet makes a large transaction, the system generates a signal and uses Smart Score to provide a strength rating based on multiple dimensions, including historical win rate, total profit and loss, betting stability, category performance, and position size.
LOW : Meets the basic standard, but the trader's advantage is average. Corresponding to low IC signals, more signals are needed for combination.
MEDIUM : A strong track record demonstrates unwavering commitment. Suitable for medium-range IC signals, appropriate configuration is recommended.
HIGH : High-stakes trades from top-performing wallets. Corresponding to high IC signals, the combination engine assigns high weighting.
This scoring system does essentially the same thing as step 10 in the 11-step engine of Part 3 (setting optimal weights, which is to allocate funds based on the independent contribution and stability of each signal): assigning different weights to each signal based on a comprehensive evaluation of multiple dimensions.
Step 3: Use a copy trading tool to execute your Kelly Criterion.
When you receive a HIGH rating signal, you can use our automated copy trading tool to set up proportional or fixed-amount copy trading.
Remember the empirical Kelly formula from Part 5 (f_empirical = f_kelly x (1 - CV_edge), which means your betting ratio should be discounted according to your uncertainty): the more uncertain your estimate is, the less you should bet.
For signals of a LOW rating, reduce positions.
For signals indicating a HIGH rating, it's appropriate to moderately increase your position. Let mathematics guide your decisions, not emotions.
Conclusion
Let's go back to the question we started with.
A single signal is weak. Looking for that perfect signal is completely misguided.
The fundamental law of active management (IR = IC x √N) is mathematically proven to be that combining many weak, independent signals is better than finding a single strong signal. Your information ratio increases with the square root of the number of truly independent signals you deploy.
The 11-step Alpha Combination Engine provides you with a precise method for calculating optimal weights. These weights reflect the independent contribution of each signal, penalize noise, and eliminate shared variance between signals.
When applied to predictive markets, this framework transforms five or more implicit probability signals into a single combined estimate. This estimate has proven to be more accurate than any single component.
When used in conjunction with the Kelly Criterion for position management, the resulting positions accurately reflect how confident you should actually be, rather than how confident you feel.
The long-term advantage of compound interest is built on a model that is most honest with what you actually know.
Finally, I want you to think about a question:
If an institutional trading desk that combines hundreds of signals can only achieve an information coefficient between 0.05 and 0.15, then what is any system that claims to be able to consistently pick winners with high confidence from a single model?
Advanced Reading and References
If you wish to delve deeper into this topic, here are some advanced resources:
Beginner level:
Harvard Stat 110: Introduction to Probability (free online textbook). The foundation of probability theory; the first six chapters are sufficient.
Edward Thorp, A Man for All Markets. The autobiography of a pioneer of the Kelly Criterion, explaining in layman's terms how mathematics can make money in casinos and on Wall Street.
Advanced level:
Grinold & Kahn, Active Portfolio Management. The "bible" of quantitative investing, detailing the fundamental laws of active management.
MIT 18.06 Linear Algebra. Professor Gilbert Strang's classic course, the best resource for understanding orthogonalization.
Upper class:
Marcos Lopez de Prado, Advances in Financial Machine Learning. A must-read for modern quantitative methods, especially the sections on cross-validation, feature importance, and orthogonalization.
Easley, Lopez de Prado & O'Hara (2012), Flow Toxicity and Liquidity in a High-frequency World, Review of Financial Studies. The original paper on the VPIN indicator.


