
著者:Anthropoic
翻訳:Peggy
編集者注:本レポートは約40万件のClaude Codeセッションに基づき、AIプログラミングツールが人とコードの関係をどのように変えつつあるかを論じている。
本稿の中核的発見は、エージェント型プログラミングにおいて、人間は主に「何をするか」を決定し、Claudeが主に「どのように行うか」を担当するという点である。ユーザーが計画決定の大部分を担い、Claudeが実行作業の大部分を担う。つまり、AIがコード作成、ファイル変更、コマンド実行、デバッグといった実装工程を引き継ぎつつある一方で、目標設定と結果判断は依然として人間に依存している。
さらに重要なのは、Claude Codeの効果はユーザーがプログラマーかどうかだけに依存するわけではない点だ。レポートによると、コード生成を伴うタスクにおいて、法律、金融、管理、科学研究など非技術職のユーザーの成功率は、すでにソフトウェアエンジニアに近づいている。結果に真に影響を与えるのは、ユーザーが自身の解決すべき問題を理解しているかどうかである。
これは、AIプログラミングが下げているのは実装のハードルであり、判断のハードルではないことを意味する。今後、業務や現場を理解し、要件を明確に提示し結果を判断できる人は、単にコードを書ける人よりもAIを使いこなせる可能性がある。AIはドメイン知識を自動的に代替するのではなく、むしろドメイン知識の価値を増幅させるのである。
以下、原文:
主な発見
既存研究を踏まえ、我々はインタラクティブなエージェント型プログラミングを研究するためのフレームワークを提案する。このフレームワークは、2025年10月から2026年4月までの約40万件のClaude Codeセッションのプライバシー保護分析に基づき、タスク構成、人間とAIの協働方法、およびタスク成功率を評価する。
典型的なセッションでは、人間がほとんどの計画決定、すなわち「何をするか」を決定し、Claudeがほとんどの実行決定、すなわち「どのように完了するか」を決定する。特定分野におけるユーザーの専門知識が高いほど、1つの指示でClaudeが完了する作業量は増加する。コーディングタスクにおいて、主要な職業グループ全体の平均成功率——つまり、ユーザーが本来望んでいたことを完了し、テスト合格やコードコミットなどの検証可能な証拠があるかどうか——は、ソフトウェアエンジニアとほぼ同等である。
ユーザーのドメイン専門能力が高いほど、セッションが成功に終わる可能性が高くなる。ただし、中級ユーザーと専門家ユーザーの差は大きくない。我々が観察した7か月間で、デバッグに使用されるセッションの割合はほぼ半減し、使用方法はよりエンドツーエンドのエージェント利用へとシフトした。すなわち、コードのデプロイと実行、データ分析、非コード文書の作成である。
この7か月間で、ほぼすべての作業タイプにおいて典型的なタスクの価値が上昇した。フリーランスの求人情報との比較によりタスク価値を推定したところ、平均上昇率は約25%であった。
はじめに
エージェント型プログラミングが急速に台頭している。2025年末以降、GitHubプロジェクトにおけるコーディングエージェントの活動割合は2倍以上に増加し、Claude Codeユーザーは現在、週平均20時間このツールを使用している。正式なプログラミング経験のない人が、複雑な技術的作業をエージェントに指示して成功させることができるのか?これらのツールの急速な採用と能力向上は、より広範な知識労働にどのような影響を与えるのか?現時点では完全な答えは出せないが、Claude Codeの使用データからいくつかの初期シグナルを見て取ることができる。
本レポートは、2025年10月から2026年4月までの約23.5万人のユーザーによる約40万件のインタラクティブセッションのプライバシー保護分析に基づき、Claude Codeの実際の使用状況に関する証拠を提供する。これは、Claude Codeセッションにおける自律性指標や、Claude CodeがAnthropic内部の業務をどのように変えたかに関する我々の以前の研究を継承するものである。本稿では、インタラクティブAIプログラミングアシスタントの使用状況を記述するためのフレームワークを提示する。すなわち、人々がどのような作業を行っているか、誰がその作業を行っているか、そして作業が成功しているかどうかである。我々は、ユーザーがコマンドラインインターフェース(CLI)、Claude.ai、またはClaude Codeデスクトップアプリを通じてClaude Codeを使用する状況に焦点を当てる。モデル能力の向上に伴いエージェント型プログラミングの使用方法がどのように変化するかを追跡することで、これらのツールがプログラミング専門家や知識労働者の労働市場に与える影響をより深く理解できる。
Claude Codeで起きていることは、知識労働の未来を予兆しているかもしれない。すなわち、エージェントが非コーディング業務にも徐々に組み込まれていくということだ。我々は、Claudeがより複雑で価値の高いタスクを処理していることを発見した。同時に、エージェント型プログラミングには依然として明確な分業が存在する。すなわち、人間が何を構築するかを決定し、エージェントがどのように構築するかを決定する。
また、ツールの使用効果を真に増幅させるのは、プログラミングの熟練度ではなく、ドメイン専門知識であるという証拠も確認された。特にドメイン専門家は成功しやすく、エラーや誤解からも回復しやすい。しかし、専門家と中級ユーザーの差は大きくない。これは、特定分野において十分な熟練度があれば、深い専門家とほぼ同等にこれらのツールを効果的に使用できることを示唆している。
これらの発見により、労働市場で起こりうる変化を初期的に観察することができる。我々のデータでは、成功は、プログラミングの訓練を受けたかどうかではなく、解決すべき問題を理解しているかどうかに依存する。これらのパターンが経済全体で成立するならば、エージェント型プログラミングツールは実装寄りの仕事の一部を吸収しつつあるかもしれないが、同時に、自身の仕事で解決する問題を真に理解している人々に報いていることを意味する。コーディングエージェントはドメイン専門知識を代替しているのではない。むしろ、ワーカーがエージェントにもたらす理解が多ければ多いほど、エージェントが完了できる質の高い仕事も増えるのである。
分業
人々がClaude Codeで行うこと
人々がClaude Codeをどのように使用しているかを理解するために、我々は各セッションを9つの作業モードのいずれかに分類する。これは、そのセッションの目標を最もよく表す単一の活動である。そのうち4つのモードは、コードの作成または保守に直接関係する。すなわち、新しいものの構築、壊れたものの修正、コードのテスト、他のエージェントや自動化パイプラインのオーケストレーションである。もう1つはソフトウェアの操作であり、デプロイ、設定、パイプラインの実行、システムの監視が含まれる。さらに2つは、「何をすべきか」を理解することに重点を置いている。すなわち、既存システムの動作の理解、および変更に着手する前の計画立案である。最後の2つはコードとは無関係か、コードが最終成果物の補助的な部分に過ぎないものである。すなわち、データの分析、およびプレゼンテーションやその他のテキストベースの文書によるコミュニケーションである。
セッションの約56%は、コードの作成(25%)、コードの修正(26%)、またはコードのテストとオーケストレーション(5%)で構成されている。ソフトウェアの操作が17%、計画または探索が14%、分析またはテキスト作成が13%を占める(図1参照)。
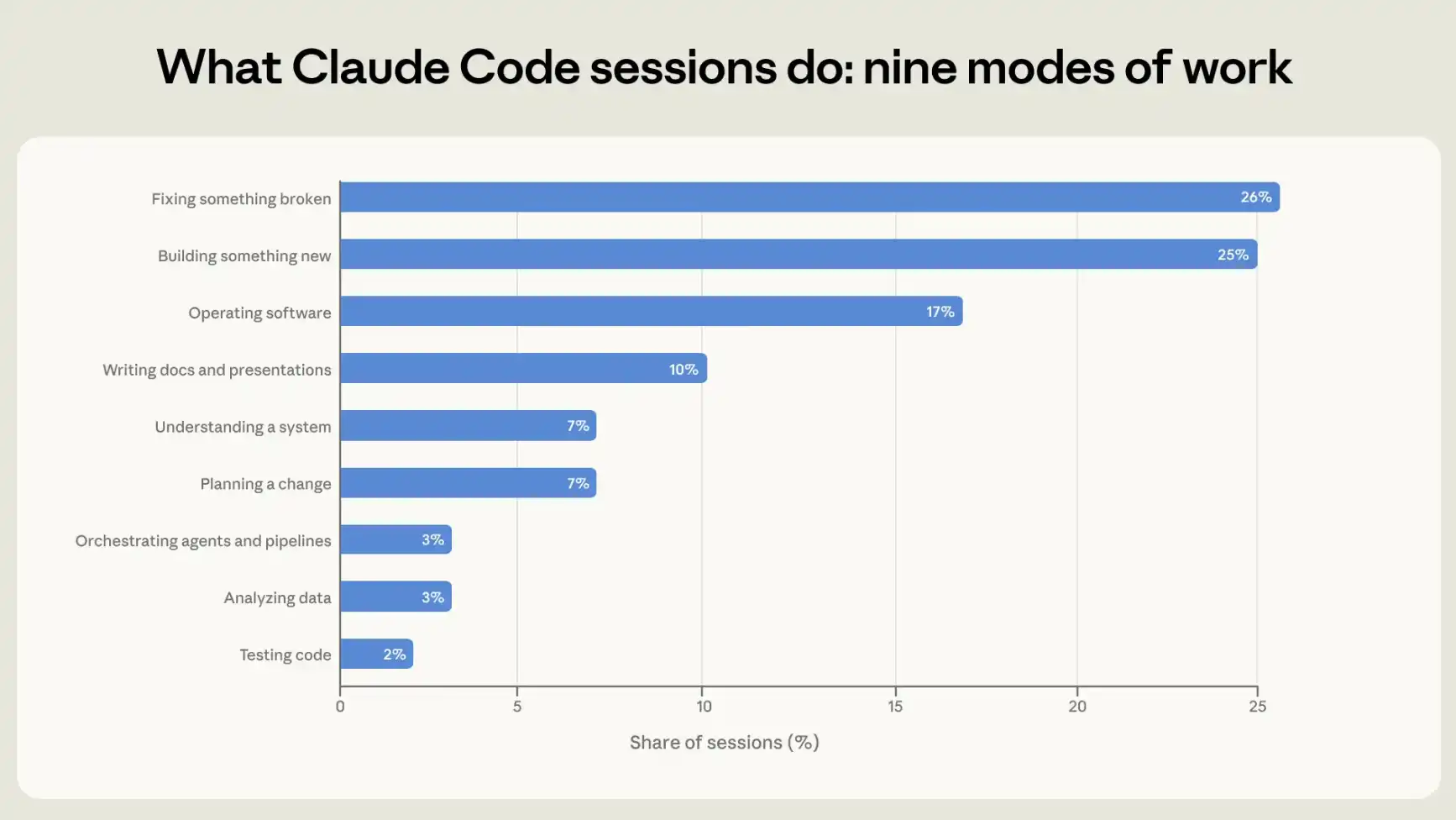
図1:9つの作業モード。各インタラクティブセッションは、その目標を最もよく表す単一の作業モードに分類される。
我々はまず、モデルにセッション記録を読ませ、それに基づいて各セッションを分類させた。その後、プライバシー保護分析ツールを用いて、分類結果を各セッションで自動記録されたテレメトリデータ(コード行の追加や削除の有無など)と相互検証した。2つの情報源間には高い一貫性が見られた。例えば、我々の分類器がコードの作成または変更としてマークしたセッションの90%以上で、テレメトリデータにもコードの変更が示されていた。詳細は付録を参照。
誰が決定を下すのか
Claude Codeの自律性はどの程度か?能力評価によると、その上限はすでに高く、現在も上昇を続けている。例えば、METRの時間軸評価などのベンチマークテストでは、最先端モデルは現在、人間が数時間を要するソフトウェアタスクを自律的に完了し、その過程で障害を自力で克服できるようになっている。しかし、実際の使用状況ではどうだろうか?ここでは、実際のセッションにおいて、人間とClaudeがそれぞれどの程度の誘導作業を担っているかに注目する。
我々はこの問題を2つの角度から研究する。第一に、人々がどの程度Claudeに決定を委ねているかに注目する。第二に、彼らがClaudeにどれだけのアクションを割り当てているかを観察する。セッション内の意思決定の分担を理解するために、我々はセッション内容に基づき、プライバシー保護された意思決定帰属分類器を構築した。分類器には、セッション内のすべての意味のある決定をリストアップし、それらを計画決定と実行決定に分類するよう求めた。計画決定には、何をするか、どのアプローチを採用するか、何をもって完了とするかが含まれる。実行決定には、どのファイルを修正するか、どのようなコードを書くか、どの言語を使用するか、どのコマンドを実行するかが含まれる。その後、分類器は各決定をClaudeまたはユーザーに帰属させ、各セッションについて2つの数値を生成する。すなわち、ユーザーが担った計画決定の割合と、ユーザーが担った実行決定の割合である。
平均すると、人間は計画決定の約70%を行うが、実行決定はわずか20%しか行わない(図2参照)。実際の使用において、エージェント型プログラミングは明確な分業を形成している。すなわち、人間が何を構築するかを決定し、エージェントがどのように構築するかを決定する。
セッション内のアクションの委任度合いを理解するために、我々は内容ではなくセッション構造に注目する。Claude Codeセッションは、Claudeとユーザー間のやり取りで構成される。ユーザーがプロンプトを送信し、Claudeがアクションを実行し、その後ユーザーが次のプロンプトを送信する、という繰り返しである。典型的なセッションでは、このようなターンは約4回である。10月から4月までの我々の履歴データでは、ユーザーが1つのプロンプトを送信するたびに、平均してClaudeは約10のアクションを実行し、時には100を超えるアクションを実行することもある。各ターンで、Claudeはファイルを読み取り、コードを編集し、コマンドを実行し、平均2400語を出力する。
Claudeがユーザーによる2回のチェックの間にどれだけの作業を完了するかは、誰が決定を下すかに大きく依存する。ユーザーが実行プロセスの制御権を保持している場合、つまりユーザーが実行決定の80%以上を行っている場合、Claudeが1ターンに実行するアクションは少なく、約8回である。一方、Claudeが計画の制御権を握っている場合、つまりClaudeが計画決定の80%以上を行っている場合、Claudeが担うアクション数は最も多く、約16回となる。
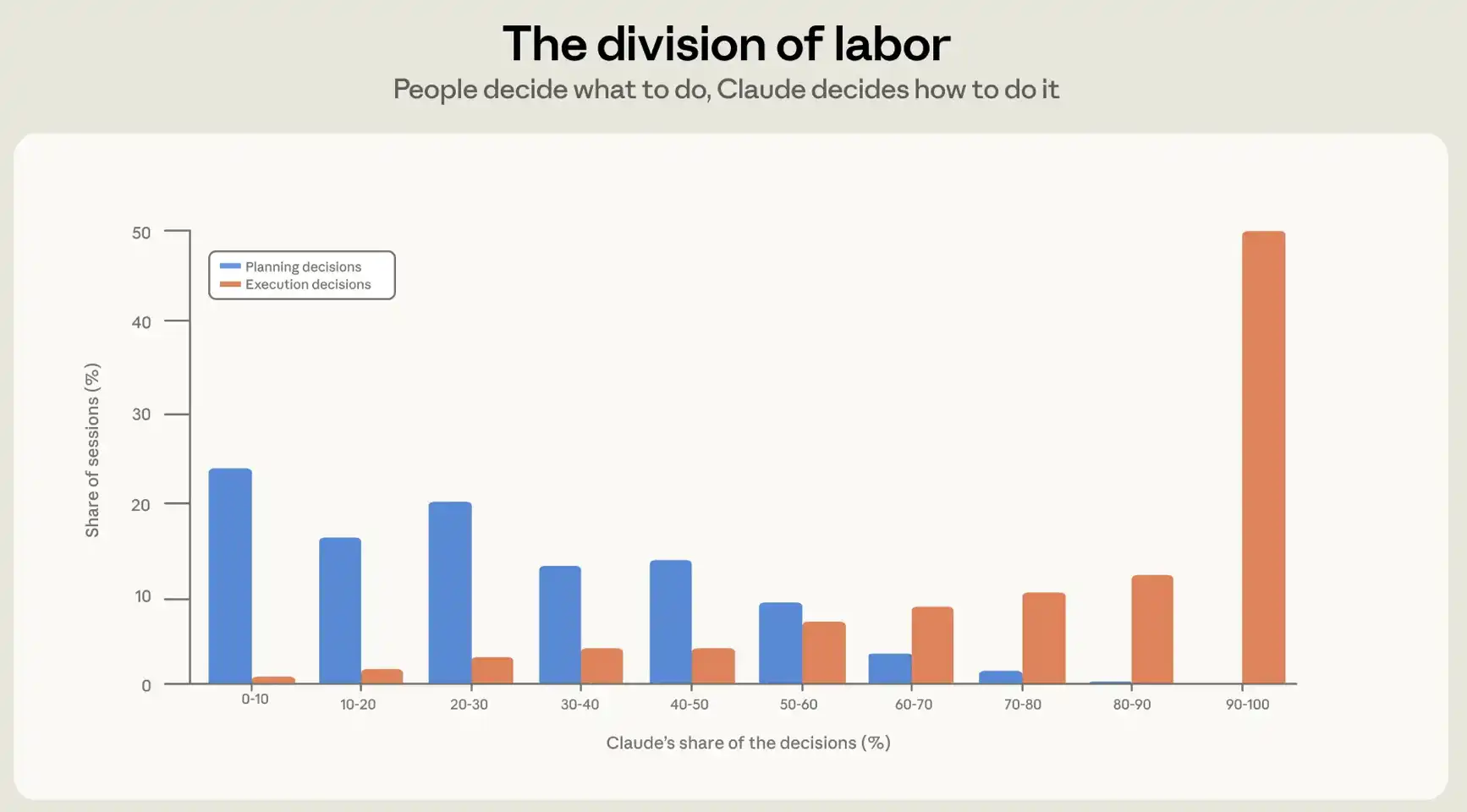
図2:計画決定と実行決定におけるClaudeの割合。この図は、異なるセッションにおいて、計画決定(何をするか)と実行決定(どのように行うか)がユーザーではなくClaudeに帰属する割合の分布を示している。典型的なセッションでは、ユーザーが計画決定の約70%を行い、Claudeが実行決定の約80%を行う。
熟練度レベル
各セッション記録に基づき、Claudeはそのタスクにおけるユーザーの見かけ上の熟練度を、初心者から専門家までの5段階で評価する。熟練度分類器は3つのシグナルに注目する。すなわち、ユーザーの指示の正確さ、ユーザーがClaudeに何を検証するよう求めるか、そしてユーザーがClaudeをより頻繁に訂正するか、それともClaudeがユーザーをより頻繁に訂正するかである。注意すべきは、ここでの熟練度は職位や一般的な能力とは全く異なる概念であり、さらに重要なのは、それが特定のタスクに固有のものであるという点だ。ベテランエンジニアが初めてRustについて質問する場合、そのRustタスクにおいては依然として初心者でありうる。Pythonを使ったことのない会計士でも、あるPythonスクリプトが実行しなければならない照合ルールを正確にClaudeに伝え、月末決算時に誤って処理された境界ケースを見抜くことができれば、そのタスクにおいては専門家である。
以下の表は、分類器において各熟練度レベルをどのように定義しているかを示し、公開コーディングエージェントセッションデータセットSWE-chatからのリクエスト例を提示している。「初心者」に分類される会話は、特定のドメイン知識を示さない一般的な指示を出す。「専門家」に分類される会話は、コードベースや技術環境に対する深い理解を伝える。
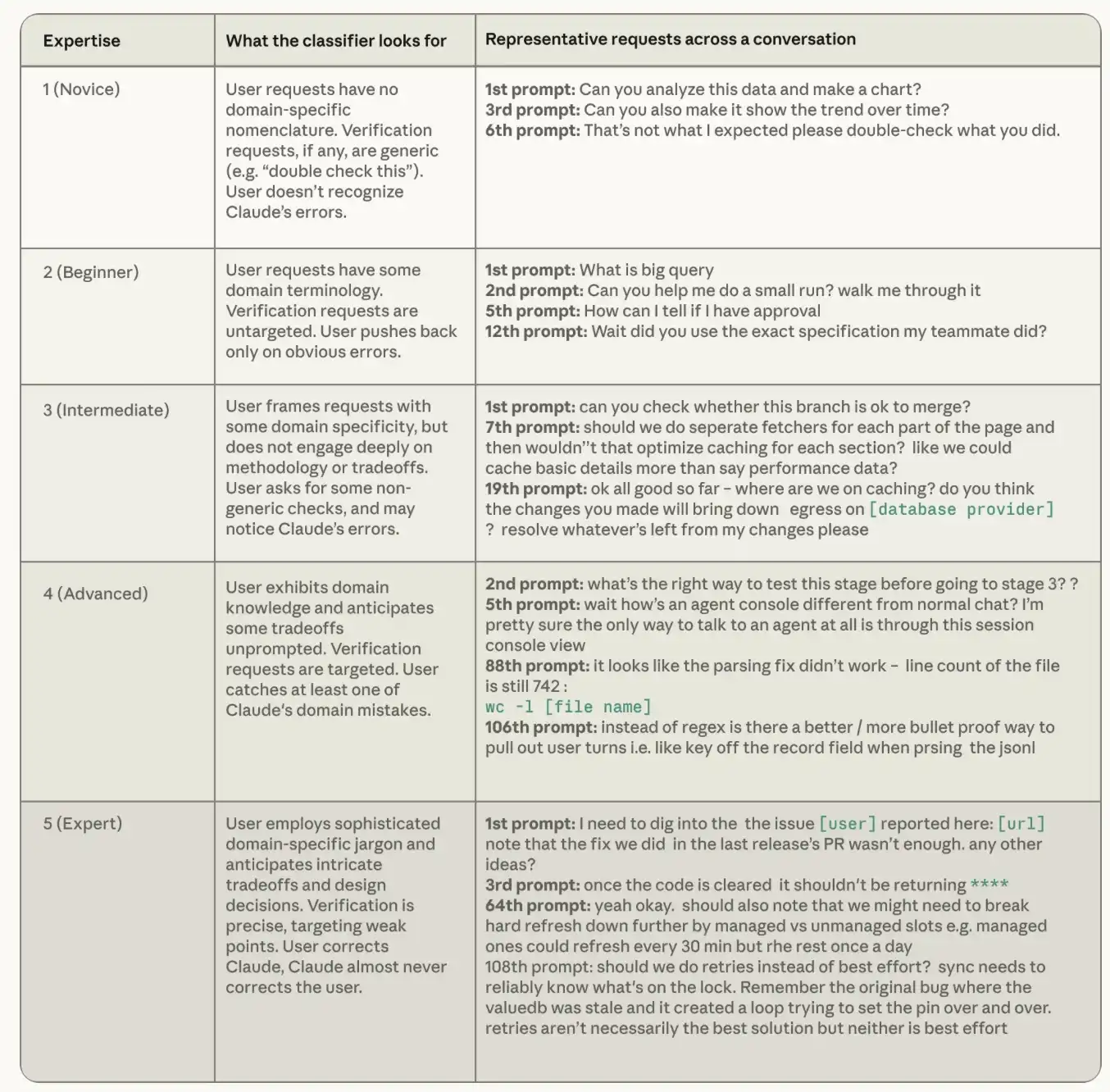
表1:熟練度分類器。例は、我々の分類器によってラベル付けされた実際のセッションを改変、匿名化、圧縮したものである。これらの例の多くは、公開されているエージェント型プログラミングセッションデータセットSWE-chatからのものである。
我々は、熟練度と、Claudeがプロンプトごとに生成する出力および活動量との関係を定量化した。典型的な初心者セッションでは、各プロンプトがClaudeに約5回のアクションを実行させ、約600語を出力させる。一方、専門家セッションでは、アクションチェーンの長さは前者の2倍以上である約12回のアクションとなり、出力量は前者の5倍である約3200語に達する(図3参照)。この初心者と専門家の差は、あらゆる作業タイプおよびあらゆるタスク価値区分において見られる。
これらの指標は、Claude Codeの自律性に関する我々の以前の研究を補完するものである。以前の研究では、エージェントの実行時間や、ユーザーがその行動を自動承認する頻度を追跡していた。対照的に、我々の意思決定帰属指標は、セッション全体を通じて誰が実質的な決定を下しているかを捉え、プロンプトごとにトリガーされる出力量とアクション数は、各人間の指示がClaudeのどの程度の自律的活動を引き起こすかを測定する。
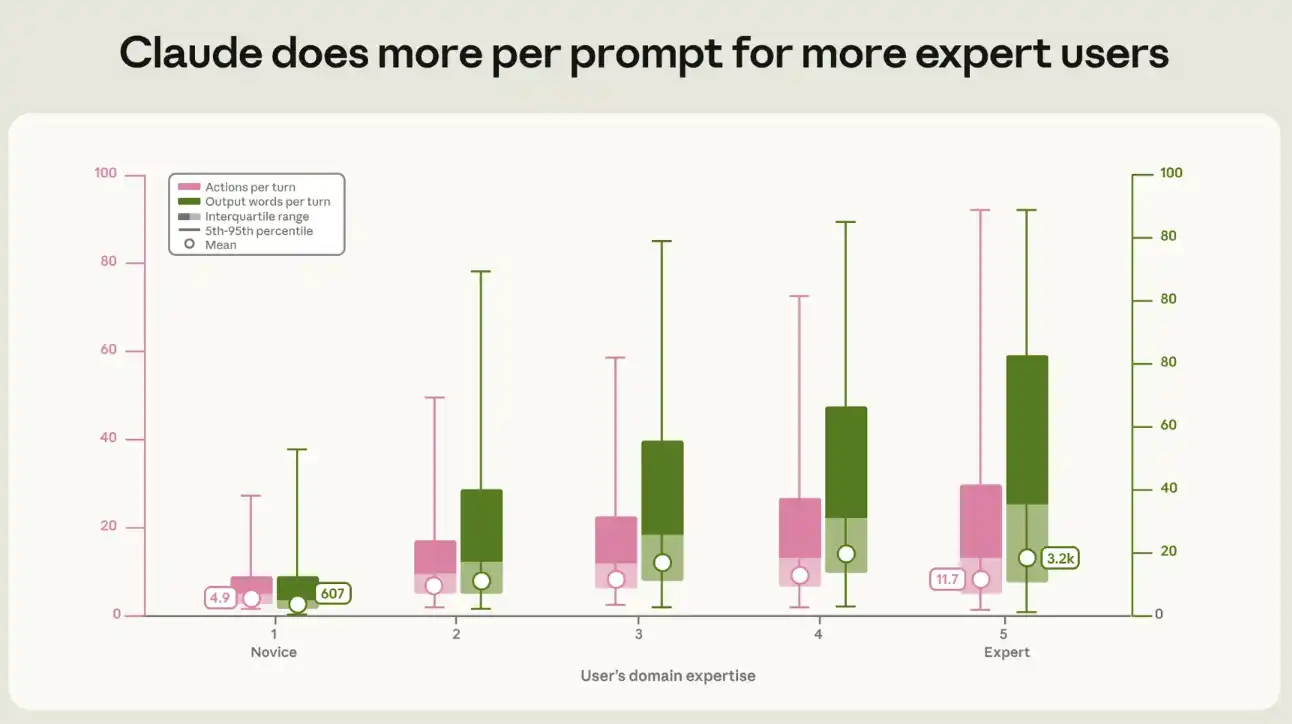
図3:より専門性の高いユーザーに対して、Claudeはプロンプトごとにより多くの作業を完了する。専門性が高いほど、Claudeのプロンプトごとのアクション数(左の棒グラフ)とテキスト出力量(右の棒グラフ)が増加する。箱は四分位範囲を示し、中央値で分割されている。ひげは第5百分位数から第95百分位数までを示す。白点は幾何平均。両方の上昇傾向は統計的に有意であり(p < 0.001)、隣接する専門性レベルの各段階間の差も統計的に有意である。作業モード、タスク価値、月、職業、モデルシリーズを制御し、ユーザークラスターで標準誤差を調整した後も、この傾向は依然として有意である。専門性レベルが1段階上がるごとに、アクション数は9%、出力量は13%増加する。
誰がClaude Codeを使用し、何に使用しているのか
ユーザー
誰がこれらの作業を行っているのかを理解するために、セッション記録から各ユーザーの職業を推測し、米国労働統計局の標準職業分類(SOC)システムの23の主要カテゴリのいずれかにマッピングした。分類器は、セッション開始時にエージェントが読み込んだプロジェクトのコンテキスト、ファイル名と構造、ユーザーが参照した資料や成果物(法律文書、臨床データ、財務報告書、教材など)、およびユーザーが使用する語彙のみを判断材料とするよう指示された。分類器は、「コードを書いている」こと自体を、ユーザーがプログラミング職に就いている証拠と見なしてはならないと明示的に指示された。ソフトウェアまたはデータ作業がユーザーの職業であることを示す明確なシグナルが存在する場合にのみ、セッションはコーディング関連のSOCカテゴリ、すなわち「コンピュータおよび数学関連職業」に分類された。弁護士が、一連の契約書に特定の条項が欠落していないかを自動チェックするスクリプトを作成する場合、そのセッションが主にソフトウェア作成であっても、法律関連職業に分類される。ユーザーの職業に関するシグナルが一切ない場合、そのセッションは分類されない。
約70%のセッションで職業を推測することができた。これらの分類可能なセッションの中で、「コンピュータおよび数学関連職業」が最大のグループであることは驚くにあたらない。このカテゴリはほとんどのソフトウェア関連業務をカバーしているからだ。次いで、ビジネスおよび金融オペレーション、芸術・デザイン・メディア、管理職、そして生命科学、物理科学、社会科学と続く。サンプルの中で、最も急速に成長している非ソフトウェア職業グループは、管理職、販売職、法律職である。
作業内容
2025年10月から2026年4月にかけて、人々がClaude Codeを使って完了する作業の構成は大きく変化した。最も顕著な変化は、破損したコードの修正に費やされるセッションの割合が33%から19%に減少したことである(図4参照)。代わりに、コードを中心とした作業が増加した。ソフトウェアの操作は14%から21%に増加した。執筆とデータ分析は約2倍になり、約10%から約20%に上昇した。
タスク自体の価値も上昇している。同様の作業をフリーランス市場で発注した場合のコストを推定し、実際の公開求人データセットで調整することで、各セッションの経済的価値を近似的に測定した。この指標によると、平均セッションの推定価値は10月から4月の間に27%上昇した。この上昇は複数の作業タイプで見られた。構築、操作、修正タスクの価値は、それぞれ約43%、34%、32%増加した。これらの価格推定は大まかなものであるため、直接読み取れるドル価値としてではなく、主に異なるタスク間の経時的な傾向を比較するために使用している。タスク価値推定器の構築方法の詳細については、付録を参照。
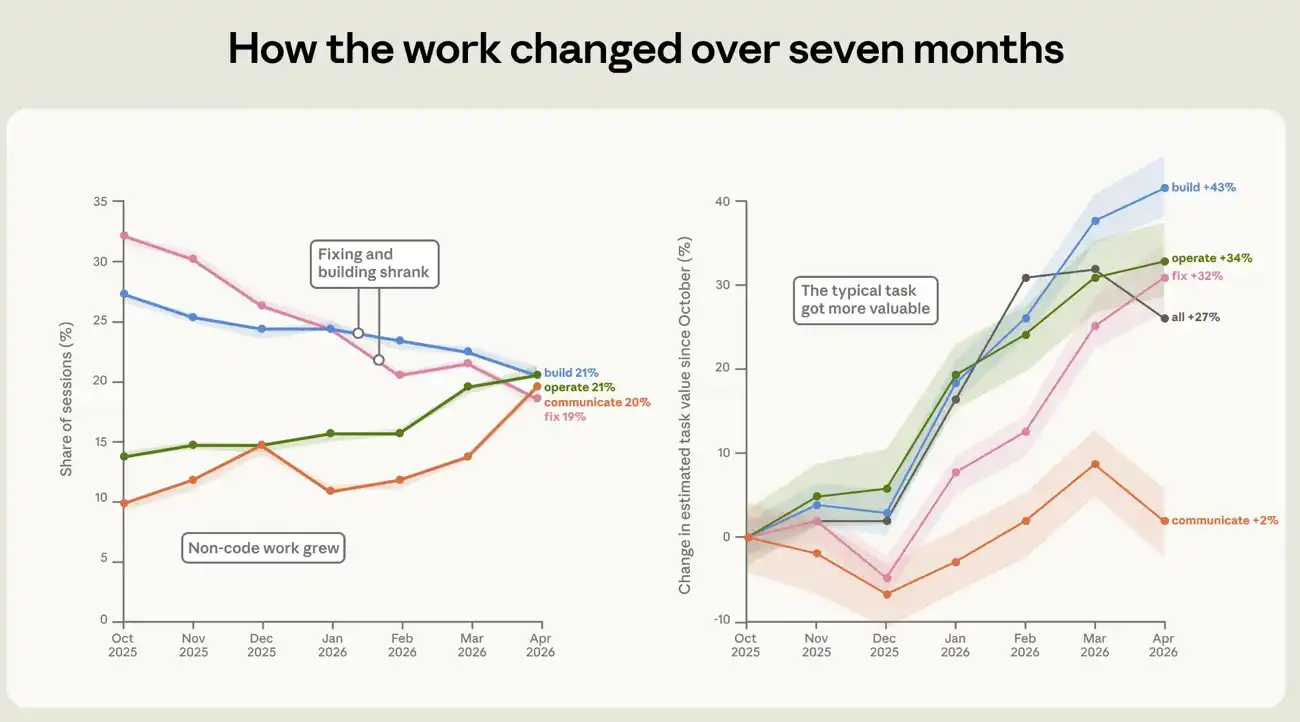
図4:2025年10月から2026年4月にかけてのClaude Codeの作業構成と価値の変化。この図は、7ヶ月のウィンドウ期間における、セッションに占める各作業モードの割合を示している。破損したコードの修正セッションの割合は33%から19%に減少し、ソフトウェアの操作、データ分析、文書作成の割合が増加した。
成功はユーザーが何をもたらすかにかかっている
タスク価値の推定は、Claude Codeが人々の作業完了をどのように支援するかを理解する一つの方法である。別の視点は、どれだけのセッションが成功するか、そしてどのセッション特性が成功と関連しているかを観察することだ。すべての成功指標において、明確なパターンが見られる。セッション中にユーザーが示す専門性のレベルが高いほど、セッションが成功する可能性が高くなる。向上の大部分は専門性の低い側に集中している。つまり、初心者から中級ユーザーへの差は、中級ユーザーからエキスパートユーザーへの差よりも大きい。
成功したセッションの特徴を分析する前に、成功をどのように測定するかを正確に説明する必要がある。ユーザーの実世界での成果を観察することはできず、Claudeを通じて目的を達成できたかどうかを直接尋ねることもできない。したがって、セッション記録に基づく2つの補完的な測定方法に依存している。1つ目は「判定成功」であり、分類器が完全なセッション記録を読み、ユーザーが当初設定した目標を達成したかどうかを判断する。選択肢は、成功、部分的な成功、失敗、明確な目標なし、である。次に、2つの付随分類器がその判断の証拠強度を評価し、「検証済み成功」を決定する。成功シグナル分類器は、検証可能な成功の証拠、特にその作業に一致するgitアクティビティ(コミットやプルリクエスト、テストスイートの合格、ユーザーによる明示的な承認など)を探す。「シグナルなし」から「弱いシグナル」(1点)、「複数の強力なシグナル」(5点)までのスケールでセッションを採点する。もう1つの並行する失敗シグナル分類器は、エラー、テストの失敗、同じことの繰り返し試行、ユーザーによる出力への反対など、問題が発生した証拠を採点する。検証済み成功は、セッションが成功と判定され、かつ少なくとも1つの強力な検証可能な成功シグナルが存在するという、2つの条件が同時に成立することを要求する。以下の分析では、セッション内の成功または失敗の程度に焦点を当てるため、成功結果分類器によって「明確な目標なし」と判定されたセッションを除外している。この種のセッションは全サンプルの約7.7%を占める。
専門性レベルのリターン
では、どのセッションが最も成功しやすいのか?結果は、前述のセッション専門性レベルスコアが、セッションの成功に大きな影響を与えることを示している。
専門性レベルが真の推進要因ではないのではないかと懸念する人もいるかもしれない。おそらくエキスパートは単に異なるタスクを選択しているか、他の点で異なっているだけかもしれない。本節では、同じ作業タイプ、同じ推定価値、同じ月、同じトピック、同じ大分類の職業グループに属するセッションを比較することで、この懸念に部分的に対応し、ユーザーの専門性レベルの違いが結果にどのように影響するかを検討する。
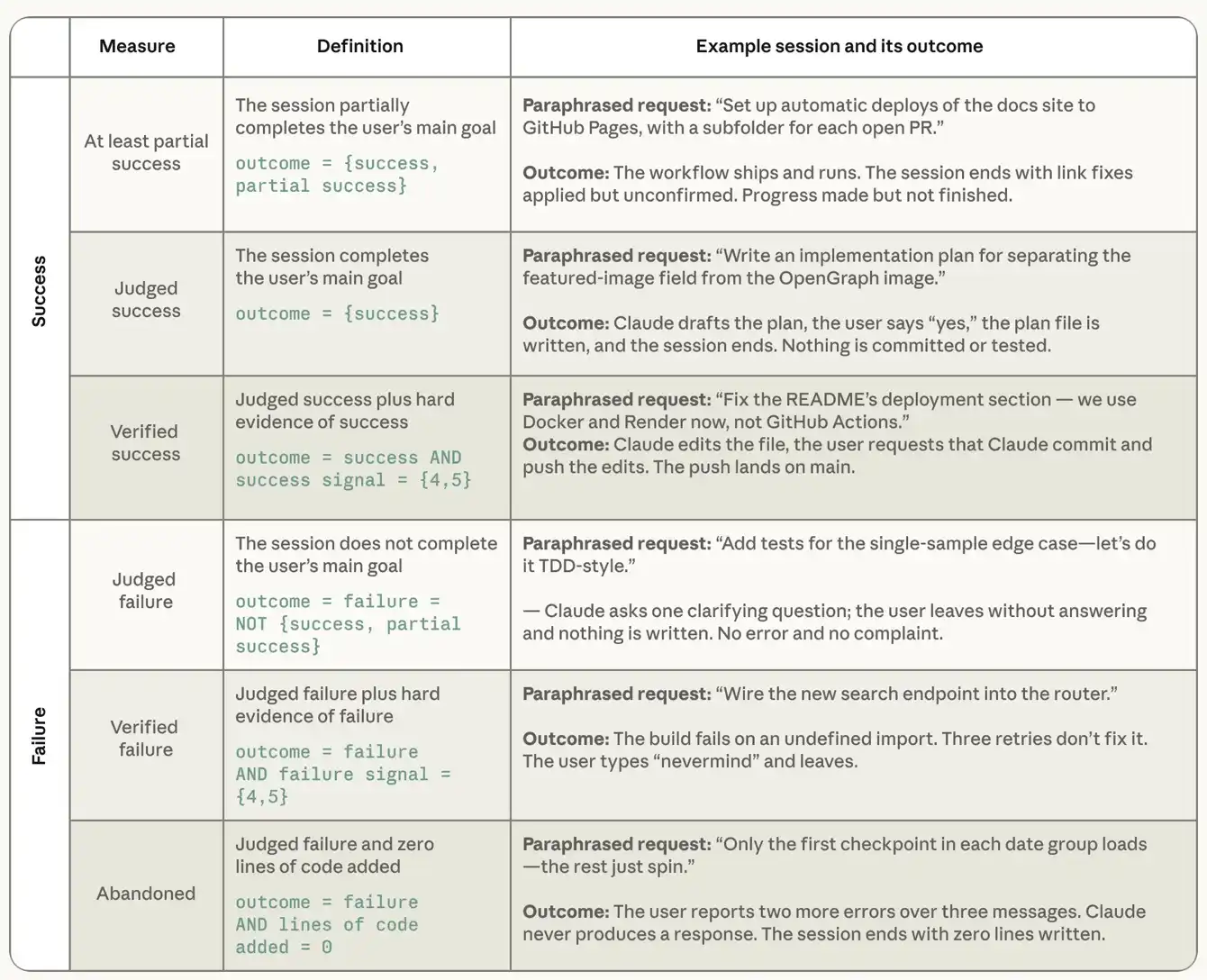
表2:分類器によって導出された成功と失敗の定義。例は、公開エージェントプログラミングインタラクションデータセットSWE-chatからの実際のセッションに基づき、要約・改変された後、当社の分類器によってラベル付けされたものである。
すべての成功指標において、セッション中にユーザーが示す専門性レベルが高いほど、セッションが成功する可能性が高くなる。初心者と評価されたセッションでは、最も厳格な指標である「検証済み成功」に達する割合は15%、少なくとも部分的な成功に達する割合は77%であった。一方、中級以上と評価されたセッションでは、検証済み成功率は28%から33%、部分的な成功率は91%から92%であった(図5参照)。
すべての指標において、利益の大部分は初心者から中級への向上からもたらされており、中級からエキスパートにかけては傾きが緩やかになる。図5の背後にある回帰分析の詳細については、付録を参照。
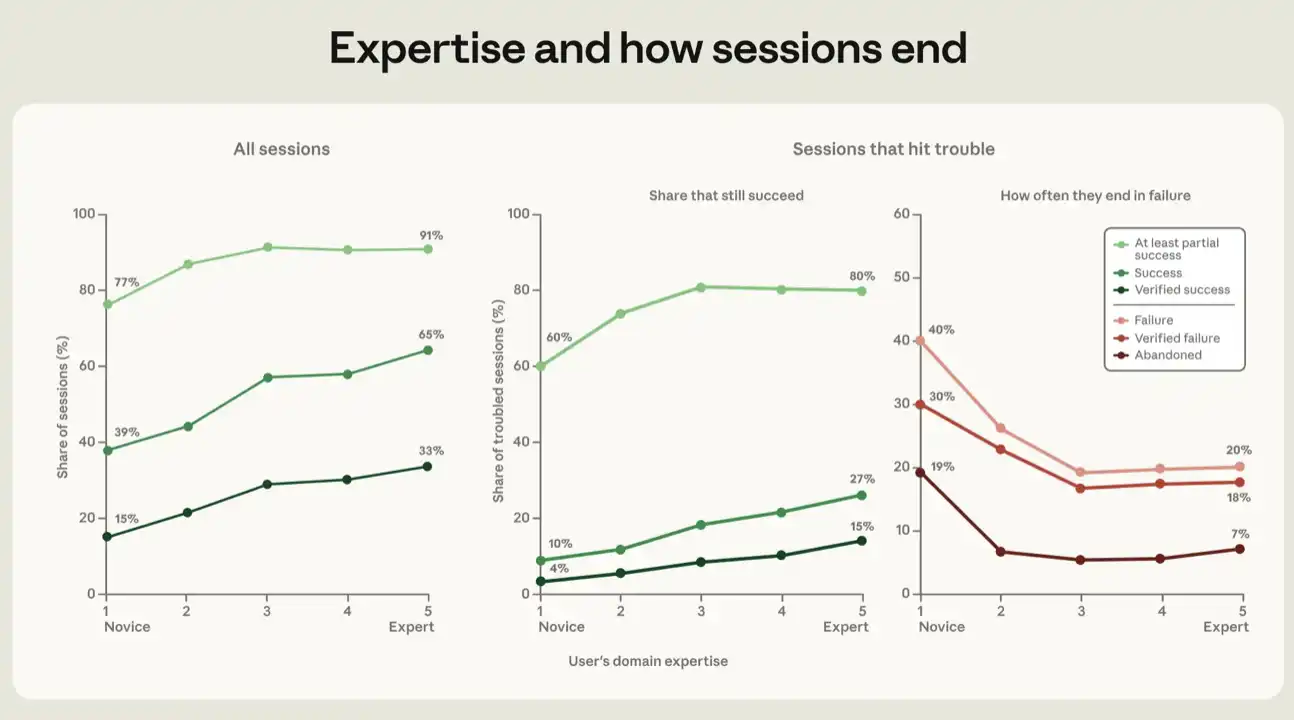
図5:専門性レベルとセッションの結果。この図は、タスクにおけるユーザーの専門性レベル評価に従って、初心者からエキスパートまでの5段階でセッション結果を示している。左図はすべてのセッションを含む。中央図と右図は、問題が発生したセッション、すなわち失敗シグナルが3より大きいセッションに限定し、これらのセッションが異なる成功および失敗の定義に達する割合を示している。各点は調整済みの比率である。同じ作業モード、同じタスク価値帯、同じ月、同じタスクトピック、同じユーザータイプ(ソフトウェア関連職業か否か)のセッションのみを比較することで、異なる専門性レベル間の差を推定している。関連する回帰の詳細は付録を参照。ひげはサンプル平均の信頼区間であり、そのほとんどは小さすぎて図中では見えない。これらの図は、成功結果分類器によって「明確な目標なし」と判定されたセッションを除外している。
課題に直面したセッションでも、同様の勾配が見られる。失敗シグナルが検証済みの失敗証拠を記録した場合、そのセッションは「問題発生」と見なされる。これには、エラーの発生、テストの失敗、同じことを完了しようとする複数回の試行、ユーザーによるフラストレーションや不満の表明などが含まれる可能性がある。問題が発生したセッションにおいて、上記のすべての変数を制御した後、検証済み成功の割合は、初心者セッションの4%からエキスパートセッションの15%に上昇する(図5参照)。より緩やかな成功指標を使用すると、少なくとも部分的な成功に達した割合は、初心者ユーザーで60%、中級からエキスパートユーザーで80%から81%であることがわかる。
また、専門性レベルと各種失敗指標との間の逆の関係も追跡した。この分析では、失敗と判定されたセッションとは、部分的な成功にも達しなかったセッションであることに注意が必要だ。問題が発生したセッションが失敗と判定され、コード行が1行も書き込まれなかった場合、それを放棄されたと呼ぶ。ユーザーが初心者と見られるセッションでは、19%が最終的に放棄されたのに対し、他のユーザーグループではその割合は5%から7%であった。言い換えれば、経験の最も少ないユーザーは、目標達成に努めながら困難に直面した場合、より容易に放棄する傾向がある。専門能力の価値の一部は、エージェントを正しい方向に導き戻す能力にあるようだ。
職業は専門性レベルほど重要ではない可能性がある
ソフトウェア関連職業のユーザーは、全セッションにおける検証済み成功率が約30%であるのに対し、その他の職業のユーザーは約26%である。コードを生成するセッション、すなわち少なくとも1行のコードが追加または変更されたセッションでは、これらの数字はそれぞれ34%と29%である(図6参照)。より緩やかな成功定義を使用すると、ソフトウェア関連職業とその他の職業の間の差はさらに縮まる。コードを生成するセッションでは、両方のユーザーグループが少なくとも部分的な成功に達する割合は、それぞれ89%と88%である。5パーセントポイントの差は大きくなく、両グループの成功率が向上しているにもかかわらず、7ヶ月間で拡大も縮小もしていない。コードを生成するセッションにおいて、データセット内で最大の10の職業グループのそれぞれとソフトウェアエンジニアとの成功率の差は、すべて7パーセントポイント以内である。管理職は検証済み成功率が最も高く、ソフトウェアエンジニアリング職をわずかに上回っている。管理職の検証済み成功率が高いことは、管理スキルがエージェントへの指示というタスクに転用可能であることを反映している可能性がある。しかし、これは部分的に我々の測定方法に起因する可能性もある。検証はセッション中のユーザーによる明示的な確認にある程度依存しており、管理職は望む結果が得られたときにそれを表明することに、より慣れている可能性がある。
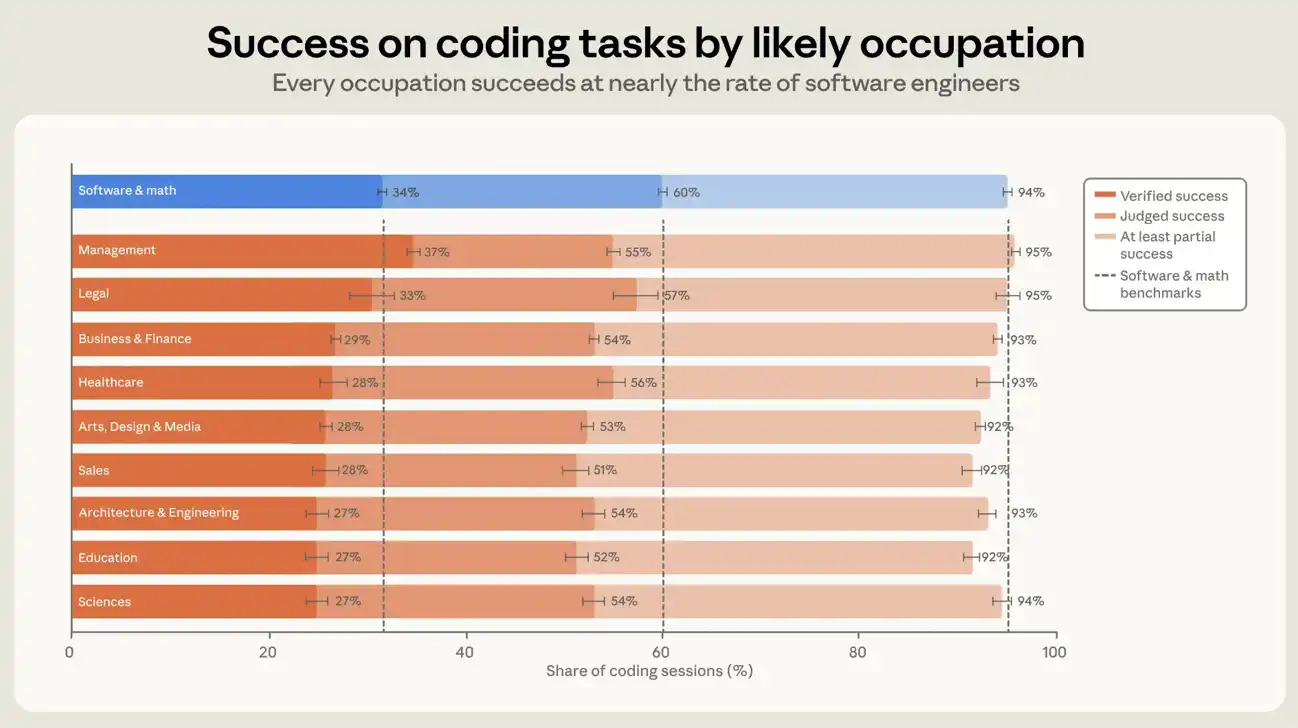
図6:推測された職業別のコーディングセッションにおける判定成功率と検証済み成功率。この図は、少なくとも1行のコードが追加または変更されたセッションにおいて、ユーザーの推測職業別に、判定成功と検証済み成功を含む厳格な成功定義の割合を示している。図は規模の大きい上位10の職業グループを示している。各グループとソフトウェア/数学系ユーザー(SOC分類におけるコンピュータおよび数学関連職業のユーザー)との成功率の差は、すべて7パーセントポイント以内である。エラーバーは、異なるアカウントに基づいて計算された95%信頼区間を示す。
展望
本レポートの結果は、ある構図が形成されつつあることを浮き彫りにしている。それは、エージェント型プログラミングが特定の知識やスキルを増幅させる一方で、別のスキルを代替しているという構図だ。コードを生成するセッションにおいて、主要な各職種の成功率は、ソフトウェア関連職種と大きな差がなかった。どうやらコーディングエージェントは、プログラミングのバックグラウンドの有無を、プログラミングタスクの成功にとって、以前ほど重要ではなくしつつあるようだ。
同時に、成功したセッションは、ドメイン(領域)の専門知識を示す可能性がより高かった。専門家と評価されたセッションの検証済み成功率は、初心者のセッションの2倍以上だった。セッションが問題に直面した際、初心者が途中で諦める割合も、他のユーザーより数倍高かった。協働のスタイルそのものが、この構図をより明確にしている。すなわち、ドメインの専門家は、一つひとつの指示でClaudeをより多くの作業へと導くことができるのだ。したがって、Claudeを成功に導く能力は、コードを書く能力よりも、特定の領域を掌握していることから生まれている。あらゆる領域でこの掌握力を持つ人々は、今や、これまで不可能だった技術的作業を成し遂げられる可能性がある。一方、そうした専門的理解を欠く人々は、同じツールを使っても、得られるものははるかに少ない。しかも、その恩恵は主に「精通」ではなく「習熟」から生じる。ある領域について実践的な理解があれば、すでに恩恵の大部分を得ることができ、深い専門性はその上にわずかな追加的優位性をもたらすに過ぎない。
これらの発見はまだ予備的なものだ。我々のほとんどの研究と同様に、実際の成果を測定することはできない。例えば、あるセッションで書かれたコードがその後実際に使われたのか破棄されたのか、あるいは経済的価値を生み出したのか、といったことである。さらに、本レポートが対象外とした非インタラクティブな利用は、全体の活動のかなり大きな部分を占めている。この種の利用を測定する枠組みを開発することは、今後の重要な課題の一つだ。また、セッションに関する我々の分類はすべて、セッション記録をモデルが読み取った結果に依存している。付録では、分類器が独立したテレメトリデータと予想される方向で一致しており、かつ大半のセッションにおいて強力な参照モデルの判断とも一致していることを示している。しかし、大規模なシナリオにおいて分類器を検証することは依然として困難であり、Claude Codeのセッション自体も、人間による注釈を真のベンチマークとするには長く複雑すぎる可能性があるため、難易度を高めている。
モデル、ユーザー、そして両者の間の分業が絶えず変化するにつれて、本レポートで描かれた構図も更新され続けるだろう。我々は、これらの指標が、現在進行中の大きな転換を追跡する助けとなることを期待している。例えば、将来、専門性の高さがもたらすリターンが低下し始めたならば、それは、現在ユーザーが提供している重要な判断力をモデルが提供し始めたことを示し、これらのツールの恩恵がドメインの専門家からより広範な人々へと拡大することを意味するだろう。ソフトウェア職種以外のユーザーがコーディングセッションを成功させる割合が上昇し続ければ、ソフトウェア生産が単一の職業の産物ではなく、各領域における通常業務の一部になりつつあることを意味するかもしれない。こうした転換は、誰がエージェント型プログラミングから恩恵を受け、どれだけ受けるかを変え、労働市場で最も重視される能力にも影響を与えるだろう。
